これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
WebAPI/認証技術入門
- 1: 1.Web API基礎
- 1.1: 1.Web APIの基礎知識
- 1.2: 2.レスポンスデータ設計
- 1.3: 3.堅牢なWebAPI設計
- 2: 2.Web認証技術基礎
1 - 1.Web API基礎
1.1 - 1.Web APIの基礎知識
1.1. Web APIの基礎知識
1.1.1. APIとは
API(Application Programming Interface)はプログラムの機能の一部を別のプログラム上で利用できるように共有する仕組み。
Web APIはHTTPプロトコル(httpやhttpsなど)のWeb技術を用いて実現されるAPIの一種。 言い換えると、ある URI にアクセスすることで、サーバ側の情報を書き換えたり、サーバ側に置かれた情報を取得したりできる Web システムで、プログラムからアクセスしてそのデータを機械的に利用するためのものである。
1.1.2. 様々なAPIの実装
開発者が Web API を設計しなければならない機会は以下のようなものがある。
- 公開している Web サービスのデータや機能のAPI公開
- 他のページに貼り付けるウィジェットの公開
- モダンなWebアプリケーションの構築
- スマートフォンアプリケーションの開発
- ソーシャルゲームの開発
- 社内システムの連携
1.1.3. Web APIの種類
XML-RPC
データ形式にXMLを利用しインターネット上でリモートプロシージャコール(遠隔手続き呼び出し)を行うタイプのAPIである。
返り値はXML形式で返ってくる。
SOAP
2000年代前半まで主流だったWeb API。 SOAPのようなXMLベースで仕様が複雑なものは近年ではあまり使われなくなってきている。
REST
最近では主流なWeb API。Web API = RESTほどなまで注目されている。
1.1.4. Web APIをきれいに設計するには
APIをきれいに設計しなければならない理由は以下の通り。
設計の美しいWeb APIは使いやすい
APIを作り公開する場合、そのAPIを利用するのは自分ではないケースが多い。APIを設計するからには多くの人に利用してもらいたいので、そのためにもAPIを利用する側にはストレスなく使ってもらえるよう、使いやすさを意識する必要がある。
設計の美しいWeb APIは変更しやすい
Webサービスやシステムはどんどん進化していく。公開した当時と同じ状態のまま2年も3年も運用が続けられるケースは少ない。進化していけばインターフェースであるAPIも変化を余儀なくされる。
ただ、APIは自分たちと関係ない第三者が使っている場合も多く、その場合いきなりAPIの仕様が変わってしまうと、そうした人たちの作ったシステムやサービスがいきなり動かなくなる、といったことも考えられる。こうした事態はAPIを提供する側としては避けなければならない。そのためにもAPIの変更をいかに利用者に影響なく変更できるかを意識する必要がある。
設計の美しいWeb APIは頑強である
Web APIはインターネットを通じて提供するため、誰でもアクセス可能になってしまう。 そのため、セキュリティの問題が必ず発生する。APIといえど、ウェブサイトと同じHTTPを利用している以上、ほぼ同等のセキュリティの問題を意識する必要がある。
1.2. エンドポイント設計とリクエスト形式
1.2.1. APIの機能設計とAPIエンドポイント
APIの機能設計
公開したAPIがどのように使われるのかユースケースをきちんと考えることが重要である。
APIエンドポイント
Web APIにおけるエンドポイントはAPIにアクセスするためのURI。
基本的にはURI が「リソース」を指すものであり、URIとHTTP メソッドの組み合わせで処理の内容を表すのが良い設計であるとされている。
1.2.2. APIエンドポイントの設計
覚えやすくどんな情報をもつURIなのかがひと目でわかるという原則に従い設計する。 設計のポイントは以下の通り。
短く入力しやすいURI
不要な情報が入っていたり、意味が重複していたりするURIは避けるべきである。
- ダメな設計
http://api.example.com/service/api/search
- 良い設計
http://api.example.com/search
人間が読んで理解しやすいURI
URIだけで何を目的としたものが理解できることが重要である。 また意味不明な略語や一般的に使用される英語以外をURIに用いるのは避けるべきである。
一般的にAPIで使われる単語を知るには、実際に他のAPIやProgrammableWebを参照する。 単語の複数形や過去形については間違いが混入しやすいので特に注意する。 慣れてる人にしか伝わらない省略表現をむやみに使うことは避けたほうが無難である。
大文字小文字が混在していないURI
標準的に選択されているのは小文字なので小文字で統一する方が好ましい。
大文字のURIで呼び出された場合には、単に 404 NotFound で返すのが良い(小文字の URI にリダイレクトする必要ナシ)
改造しやすいURI
URIを修正して別のURI にするのが容易かどうか。 あるURIから他のURIを想像することが可能であれば、あまりドキュメントを読まなくても開発を進めることができAPI利用者の負担を軽減できる。
サーバアーキテクチャが反映されたURI
下記のようなエンドポイント設計はセキュリティ脆弱性を招く場合がある。
http://api.example.com/cgi-bin/get_user.php?user=100
上記の場合、API利用者に「PHPで書かれていてCGIとして動作しているんだろう」という情報を与えてしまう。 API利用者にどの言語やどのフレームワークなどでAPIが設計・構成されているかの情報を与える必要はない。
またアーキテクチャが反映されていると、攻撃者に対して脆弱性を突くためのヒントを与えてしまうことになる。
ルールが統一されたURI
例えば以下のようなルールが統一されていないAPIは避けるべきである。
http://api.example.com/friends?id=100
http://api.example.com/friend/100/message
エンドポイントを設計する中で注意すべき点
- 複数形の名詞を利用する(複数形の方が適切)
- 利用する単語に気をつける
- スペースエンコードを必要とする文字を使わない
- 単語をつなげる必要がある場合はハイフンを利用する
HTTPメソッドとエンドポイント
URIとメソッドは「操作するもの」と「操作方法」の関係にあると言える。
| メソッド名 | 説明 |
|---|---|
| GET | リソースの取得 |
| POST | リソースの登録(リソース名は指定しない) |
| PUT | リソースの登録/更新(リソース名を指定する) |
| DELETE | リソースの削除 |
| PATCH | リソースの一部変更 |
| HEAD | ソースのメタ情報の取得 |
POSTとPUTの使い分け
- POST と PUT の使い分けは、 URI の指定の仕方にある。
POST /photosとすると、リソース名がサーバ側で割り振られて、GET /photos/25252などの新しい URI がアクセス可能になる。- PUT は、
PUT /photos/25252のように、使用者がリソースを指定する場合に使う。
PUTとPATCHの使い分け
- PUT はデータを完全に上書きしたい場合に使う。
- PATCH はデータの一部だけを更新したい場合に使う。
1.3. 検索とクエリパラメータ設計
1.3.1. ページネーション
ページネーションの仕組みを実現する方法は主に2つある。
- per_pageとpageで取得数と取得位置を指定
- limitとoffsetで取得数と取得位置を指定
相対位置でデータを取得する方法にはパフォーマンス上の問題がある。 (∵ offsetを使った場合はレコードを先頭から数えてしまう可能性があるから)
また更新頻度の高いデータにおいてデータに不整合が生じるという問題もある。 最初の20件を取得してから、次の20件を取得する間にデータの更新が入ってしまった場合、実際に取得したい情報と取得された情報にズレが生じてしまう。
offsetで相対位置を指定する代わりに、これまで取得した最後のデータのIDや時刻を記録しておいて、「このIDよりも前のもの」「このIDよりも後のもの」といった指定を行う方法もある(絶対位置による指定)。
1.3.2. 絞り込みのためのパラメータ
完全一致で検索する場合、以下のようなURIとするのが直感的である。
http://api.example.com/v1/users?name=ken
検索するフィールドがほぼ一つに決まる場合は q というパラメータが使われる場合もある。
こちらは部分一致での検索というニュアンスが強くなる。
http://api.example.com/v1/users?q=ken
1.3.3. クエリパラメータとパスの使い分け
クエリパラメータに入れる情報はURI中のパスの中に入れることも設計上は可能である。
クライアントが指定する特定のパラメータをクエリパラメータに入れるか、パスに入れるかを決める際の基準は以下の通り。
- 一意なリソースを表すのに必要な情報かどうか
- 省略可能かどうか
1.4. ログインとOAuth2.0
1.4.1. OAuth
OAuthは基本的に広く第三者に公開されるAPIでデータや機能へのアクセス権限の許可を行う仕組み。
OAuthにより権限の許可を付与することで本来であれば利用することができない他サービスのリソースを連携してもらうことができる。
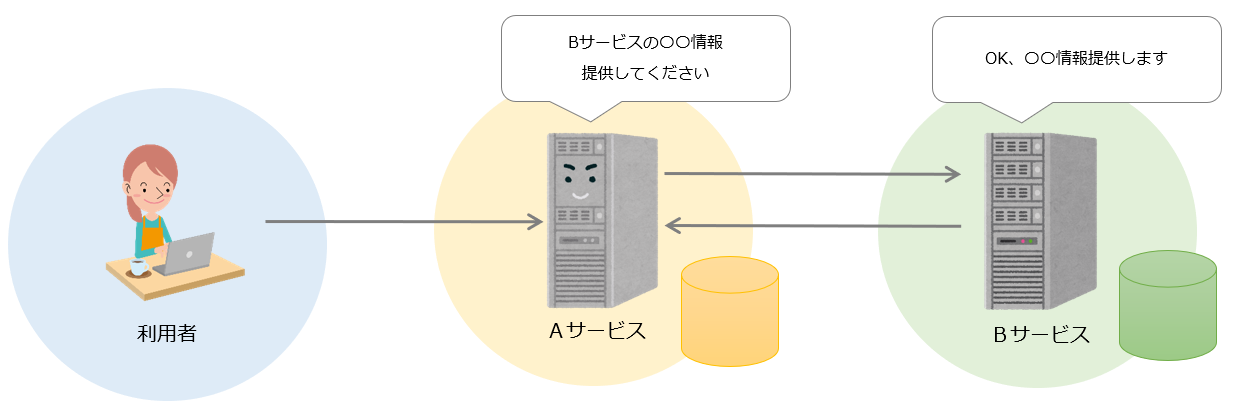
OAuthには 1.0 と 2.0 があり、2.0 は2012年10月にRFC6749として標準化されている。 OAuth 1.0を利用する理由は特にないため、実装する場合は2.0を利用するのが良い。
1.4.2. OAuth2.0の認証手順(Grand typeの設定)
| 名称 | 説明 |
|---|---|
| Authentication Code | サーバサイドで多くの処理を行うWebアプリケーション向け |
| Implicit | スマートフォンアプリやJavaScriptを用いたクライアントサイドで多くの処理を行うアプリケーション向け |
| Resource Owner Password Credentials | サーバサイド(サイトB)を利用しないアプリケーション向け |
| Client Credentials | ユーザ単位での認可を行わないアプリケーション向け |
Resource Owner Password Credentialsの認証における指定パラメータ
- grant_type・・・password という文字列。Resource Owner Password Credentials であることを表す
- username・・・ログインするユーザ名
- password・・・ログインするパスワード
- scope・・・アクセスのスコープを指定する(省略可)
scopeはどんな権限にアクセスをさせるかを指定するもの。 スコープを使うことで外部サービスがトークンを得る際にアクセス内容を制限し、またユーザに「このサービスは以下の情報にアクセスできますよ」と表示することができる。
クライアントのリクエストは例えば以下のようになる。
POST /v1/oauth2/token HTTP/1.1
Host: api.example.com
Authorization: Basic Y2xpZW50X21kOmNsaWVudF9zZWNyZXQ
Content-Type: application/x-www-form-urlencoded
grant_type=password&username&takaaki&password&abcde&scope=api
正しくサーバに送られるとサーバは以下のようなJSONをレスポンスする。
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-store
Pragma: no-cache
{
"access_toke": "b77yz37w7kzy8v5fuga6zz93",
"token_type": "bearer",
"expires_in": 2620743,
"refresh_token": ""
}
bearerトークンの送信方法はRFC 6750によれば以下の3種類ある。
- リクエストヘッダに入れる方法
- リクエストボディに入れる方法
- URI にクエリパラメータとして入れる方法
expires_inはアクセストークンが後何秒で有効期限切れになるかを表したもの。
有効期限が切れた場合、サーバは invalid_token というエラーを 401 で返すことになっている。
invalid_token が発生した場合にはリフレッシュトークンを使ってアクセストークンを再度要求することができる。 リフレッシュトークンは返さないことも可能(その場合は再ログインが必要となる)。
ユーザ名やパスワードによらず API を利用させたい場合はClient Credentialsを使うのが良い ClientID と ClientSecret さえ取得してアプリケーションに埋め込んでおけばpublicな情報にアクセスできる。
1.5. SSKDsとAPIのデザイン
Web APIは大きく2種類に分けられる。
- LSUDs 向け ・・・一般に公開し多くの人たちに使ってもらうためのAPI
- SSKDs 向け ・・・自社のスマホアプリなど特定の人だけが使うAPI
SSKDs 向けのAPIでは必ずしも汎用的な美しいAPIを提供する必要はない。 ユーザ体験を考えるとホーム画面に表示する情報を1つに詰め込んだAPIを1個提供する方がいい場合もある。
1.6. HATEOASとREST API
1.6.1. HATEOAS(Hypermedia as the Engine of Application State)
HATEOASはRESTの一部であり、リソースに対する情報や操作について前情報なしに扱うことができるアーキテクチャパターンである。
言い換えるとRestful原則に対する追加的な制約であり、HTMLアプリの画面遷移を抽象化した状態遷移を表現するRestful APを設計するための具体的な方法論ともいえる。
例えば以下のようなAPIを設計したとする。
/books/isbn
これはAmazonの本の情報を得られるAPIであるとした場合、アクセスしたときのレスポンスは以下のようなものが考えれる。
- タイトル
- 作者
- 在庫数
- 評価 などなど
Book に対する情報が含まれることを期待します。 HATEOASではさらにBook に対してなにが出来るのかがすべて表現されます。
- 購入
- 作者の詳細をみる
- 評価の詳細をみる
- 評価を追加する などなど
最大の特徴はリソースにアクセスすることができる= ソースに対する操作が出来る(できないことは表現されない)。
1.7. GraphQL
GraphQLはGraphとQL(クエリー言語)を合わせたREST APIの代替規格。
GraphはGraphQLで扱うデータが以下の図のようにnodeとedgeを使ってグラフのように表されることからGraphという名前が利用されている。
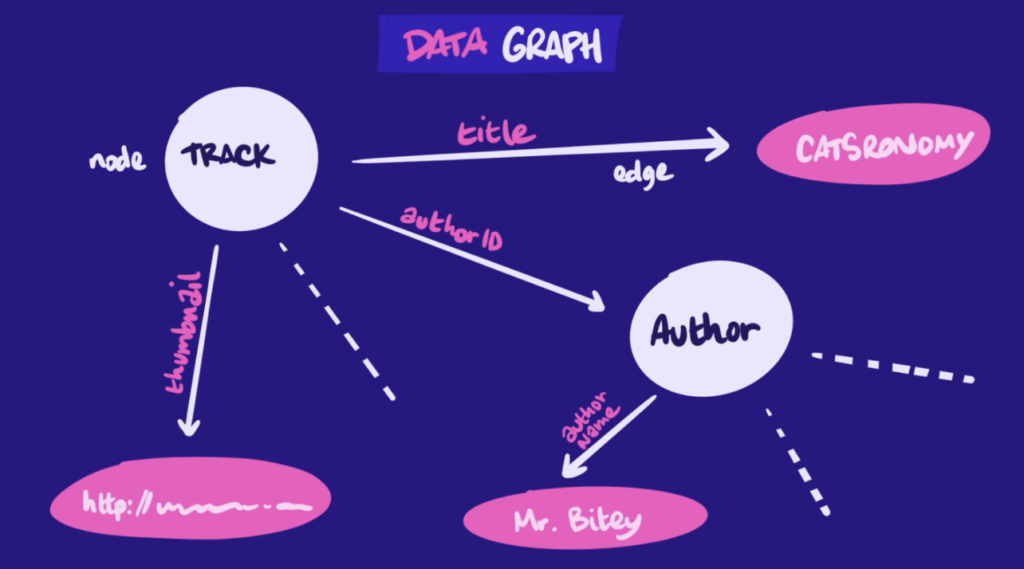
クライアントからサーバに対してCRUDを行う際に利用するREST APIと同様にGraphQLもクライアントからサーバに対してCRUDする際に利用することができる。
REST APIではデータを取得する際に複数のエンドポイントを利用したが、GraphQLでは1つのエンドポイントのみ持ちクエリーを設定(問い合わせなのか更新または削除なのか、どのデータが欲しいかを指定)することでサーバからデータを取得することができる。
クエリーの設定によって一度のHTTPリクエストで一括でユーザ情報、ブログ記事情報を取得することも可能な上、ユーザ情報の中からはemailのみ選択して取得するといったことも可能。
1.7.1. GraphQLが解決したREST APIの問題
GraphQLはREST APIの抱える以下の問題を解決できる。
- 必要なデータを取得する際に1つのエンドポイントから十分なデータが取得できない場合に複数のエンドポイントに対してリクエストを送信しなければならなかったこと
- Overfetchingと呼ばれる問題
Overfetchingとは: ユーザデータの中からemailのみ取得するといったことができず必ず一緒に必要でない情報(ブラウザ上に描写しないデータ)を取得してしまうこと
1.2 - 2.レスポンスデータ設計
2.1. レスポンスデータ設計
2.1.1. レスポンスデータフォーマット
エンドポイントへアクセスされた場合のレスポンスされるデータフォーマットは以下のようなものがある。
| データフォーマット | 説明 |
|---|---|
| XML | XMLは個別の目的に応じたマークアップ言語群を創るために汎用的に使える |
| JSON | JavaScript Object Notation |
| JSONP | scriptタグを使用してクロスドメインな(異なるドメインに存在する)データを取得する仕組み |
JSONPはCSRF脆弱性がある
基本的にはJSONをレスポンスのデフォルトとして対応し必要があればXMLなどに対応する方針が良い。
データフォーマットの指定方法は以下の3種類がある。
- クエリパラメータを使う方法・・・もっとも主流な方法
- 拡張子を使う方法
- リクエストヘッダでメディアタイプを指定する方法・・・HTTP仕様に厳格に合わせようと思ったらファーストチョイス
2.1.2. JSONPの扱い
JSONPに対応する必要がないのであれば、無理に対応しない方が無難である。 同一生成元ポリシーによって守られている攻撃手法の対象になりえるため。
2.1.3. データ内部構造の設計方針
APIで返すレスポンスデータを決定する際にまず優先に考えることは、APIのアクセス回数がなるべく減るようにすることである。
そのためには API のユースケースをきちんと考えることが重要だ。
ひとつの作業を完了させるために複数回のアクセスが必要となるAPIはChatty APIと呼ばれるが、Chatty API はネットワークのトラフィックを増加させ、クライアント実装の手間も増やしてしまうため基本的には使わないようにする。
レスポンス内容をユーザが選べるようにする
もっともシンプルな解決策は全ての API で「できる限り多くのデータを返す」というもの。
送受信されるデータサイズはできるだけ小さい方が望ましいため、「取得する項目を利用者が選択可能にする」という手法が取られることがある。 (例:クエリパラメータを使って、ユーザ情報のうち名前と年齢を取得したい、みたいなことを指定できるようにする、など)
他にはSmall、Medeium、Large などのレスポンスグループを指定して必要なデータだけを取得させるというやり方がある。
エンベロープは必要かどうか
レスポンスが正常時もエラー時も200 OKで返ってきて本当に成功したかどうかはヘッダに載せるというやり方。 これはHTTPの仕様を無視している且つ冗長なので絶対にやるべきではない。
HTTP自体がエンベロープの役割を果たしているためエラーかどうかの判断はステータスコードに基づいて行うのが良い。
データはフラットにすべきか
なるべくフラットな方が良いが階層構造を持った方がわかりやすいケースについてはそうするべきである。
Google JSON style Guideより
配列とフォーマット
配列をそのまま返すべきか、オブジェクトに包んで返すべきか迷う場合がある。 基本的にはオブジェクトで包んで返すべきであり、以下のようなメリットがある。
- レスポンスデータが何を示しているのかがわかりやすくなる
- レスポンスデータをオブジェクトに統一することができる
- セキュリティ上のリスクを避けるこができる(トップレベルが配列だとJSONインジェクションの危険がある)
配列の件数あるいは続きがあるかをどう返すべきか
本当に件数を返す必要があるかどうかはしっかり見極めた方が良い。
全件数を取る必要がなかったとしても「次の20件」のようなリンクを表示するために、「今取得したデータに続きはあるのか」は返した方が良い。
例えば、続きがあれば "hasNext": "true" をつけて返すなど。
2.1.4. 各データのフォーマット
各データ項目の命名規則に関してのポイントは以下の通りである。
- 他の多くのAPIで同じ意味に利用されている一般的な単語を用いる
- なるべく少ない単語数で表現する
- 複数の単語を連結する場合、その連結方法は API 全体を通して統一する
- 変な省略形は極力利用しない
- 単数形・複数形に気をつける
日付のフォーマットについては、広く一般に公開する場合RFC 3339を使うのが良い。 このフォーマットが読みやすく使いやすいものを目指してインターネット上で用いる標準形式として定められたものであるためである。
2.1.5. エラー表現
ステータスコードでエラーを表現する
エラーを返す際にまず真っ先にやるべきことは適切なステータスコードを使うことである。
| ステータスコード | 説明 |
|---|---|
| 100番台 | 情報 |
| 200番台 | 成功 |
| 300番台 | リダイレクト |
| 400番台 | クライアントサイド起因エラー |
| 500番台 | サーバサイド起因エラー |
エラー詳細をクライアントに返す
エラーの内容を返す方法は大きく分けて2つある。
- HTTP のレスポンスヘッダに入れて返す
- レスポンスボディで返す(こちらの方が主流)
例えばTwitter APIのレスポンスボディは以下のようになっている。
{
"errors":[
{
"message":"Bad Authentication data",
"code":215
}
]
}
2.2. HTTPリクエストとレスポンスの仕様
2.2.1. ステータスコード
主にAPIで利用する可能性のあるステータスコードは以下の通り。
| ステータスコード | 名前 | 説明 |
|---|---|---|
| 200 | OK | リクエストは成功した |
| 201 | Created | リクエストが成功し、新しいリソースが作られた |
| 202 | Accepted | リクエストは成功した |
| 204 | No Content | コンテンツなし |
| 300 | Multiple Choices | 複数のリソースが存在する |
| 301 | Moved Permanently | リソースは恒久的に移動した |
| 302 | Found | リクエストしたリソースは一時的に移動している |
| 303 | See Other | 他を参照 |
| 304 | Not Modified | 前回から更新されていない |
| 307 | Temporary Redirect | リクエストしたリソースは一時的に移動している |
| 400 | Bad Request | リクエストが正しくない |
| 401 | Unauthorized | 認証が必要 |
| 403 | Forbidden | アクセスが禁止されている |
| 404 | Not Found | 指定したリソースが見つからない |
| 405 | Method Not Allowd | 指定されたメソッドは使うことができない |
| 406 | Not Acceptable Accept | 関連のヘッダに受理できない情報が含まれている |
| 408 | Request Timeout | リクエストが時間以内に完了しなかった |
| 409 | Conflict | リソースが矛盾した |
| 410 | Gone | 指定したリソースは消滅した |
| 413 | Request Entity Too Large | リクエストボディが大きすぎる |
| 414 | Request-URI Too Long | リクエストされた URI が長すぎる |
| 415 | Unsupported Media Type | サポートしていないメディアタイプが指定された |
| 429 | Too Many Requests | リクエスト回数が多すぎる |
| 500 | Internal Server Error | サーバ側でエラーが発生した |
| 503 | Service Unavailable | サーバが一時的に停止している |
200番台:成功
201 は Created つまりリクエストの結果サーバ側でデータ作成が行われた場合に返す
202 の Accepted はリクエストした処理が非同期で行われ、処理は受け付けたけれど完了していない場合に利用する
204 は No Conent という言葉の通りレスポンスが空のときに返す
PUT や PATCH の場合は 200 とともに操作したデータを返し(POST の場合は 201)、DELETE の場合は 204 を使うのが良い。
こうしておけば、どちらの場合も返ってきたデータを見れば変更が正しく行われたことが理解できる。
300 番台:追加で処理が必要
300 番台のステータスコードでよく知られている利用目的は「リダイレクト」。 リダイレクトの場合は Location というレスポンスヘッダにリダイレクト先の新しいURIが含まれる。
API の場合もリダイレクトを利用することはありえるが、Web サイトのように URI の変更、サイトの移転や一時的な移動に伴ってリダイレクトを行うことはあまり好ましくない(クライアントの実装によっては、動かなくなってしまうため)。
400番台:クライアントのリクエストに問題
400 Bad Request はその他のエラーコード
送られてきたパラメータに間違いがある場合など、他のステータスコードに該当しない場合は 400 を使う
401 Unauthorized は認証のエラー(あなたが誰かわからない)
403 Forbidden は認可のエラー(あなたが誰かはわかったけど、この操作は許可されていない)
404 Not Found はアクセスしようとしたデータが存在しない場合に返す
ただし、何が存在しないかはケースバイケースなので、エラーメッセージをきちんと返す必要がある
405 Method Not Allowed はエンドポイントは存在するがメソッドが許可されていない
(GET の API に POST でアクセスしようとした場合など)
406 Not Acceptable はクライアントが指定してきたデータ形式に API が対応していない
(JSON と XML しか対応していないのに YAML を指定した場合など)
408 Request Timeout は、リクエストをクライアントがサーバに送るのに時間がかかりすぎて、サーバ側でタイムアウトを起こした場合
409 Conflict は、リソース競合が発生した際のエラー
(重複した ID のデータを登録しようとした場合など)
410 Gone は 404 と同じく、リソースが存在しない場合に返すコードだが、こちらは単に存在しないのではなく、かつて存在したけれど今はもう存在しない、ということを表す
413 Request Entity Too Large はリクエストボディが大きすぎるときのエラー
ファイルアップロードに、許容されるサイズ以上のデータが送られてきたような時に発生する
414 Request-URI Too Long は GET 時のクエリパラメータに長すぎるデータが指定された場合などに発生する
415 Unsupported Media Type は、リクエストヘッダの Content-Type で指定されているデータ形式にサーバが対応していないケースで発生する
例えば、XML に対応していない API に XML を送り、Content-Type に application/xml を指定している場合などが該当する
429 Too Many Requests は、アクセスの許容範囲の限界を超えた場合に返るエラー
500 番台:サーバに問題がある場合
500 Internal Server Error は、サーバ側のコードにバグがあってエラーを吐いている場合
503 Service Unavailable は、サーバが一時的に利用できない状態になっていることを示すエラー
2.2.2. キャッシュとHTTPの仕様
HTTP のキャッシュには以下の2つのタイプがある。
- Expiration Model(期限切れモデル)・・・レスポンスデータに保存期限を決めておき期限が切れたら再アクセスさせる
- Validaton Model(検証モデル)・・・今保持しているキャッシュが最新であるかを問い合わせ、更新されていた場合にのみ取得を行う
Expiration Model(期限切れモデル)
HTTP 1.1 の定義によると、実現方法は以下の2つ。
- Cache-Control レスポンスヘッダを使う
- Expires レスポンスヘッダを使う
特定の日時に変更されることがあらかじめわかっているデータの場合は Expires で日時を指定する。 今後更新される可能性のない静的なデータの場合は、一年後の日時を指定することで、キャッシュをしばらく有効にできる。 Cache-Control は定期更新ではないものの更新頻度がある程度限られているものや、更新頻度は低くないものの、あまり頻繁にアクセスして欲しくない場合に利用できる。
max-age の計算にはDateヘッダを使う。 HTTP の仕様により500番台のエラーの場合などいくつかの例外を除き、必ずつけなければならない。
Validation Model(検証モデル)
検証モデルを行うには条件付きリクエストに対応する必要がある。
条件付きリクエストとは「もし今保持している情報が更新されていたら情報をください」というもの。
更新されていたときのみデータを返し、更新されていなかったら 304 Not Modified を返す、
条件付きリクエストを行うには、「クライアントが現在保持している情報の状態」をサーバに伝える必要がある。 そのためには最終更新日付とエンティティタグのどちらかを指標として使う。
キャッシュをさせたくない場合
APIの性格によってはキャッシュを全くさせたくない場合もある。 そうした場合は HTTP ヘッダを使って明示的に「キャッシュをして欲しくない」と伝えることができる。
Cache-Control: no-cache
no-cache は厳密には「キャッシュをしない」という指定ではなく、最低限「検証モデルを用いて必ず検証を行う」必要があることを意味する。 機密情報などを含むデータで、中継するプロキシサーバには保存をして欲しくないという場合には no-store を返す。
Varyでキャッシュの単位を指定する : キャッシュを行う際にURI 以外にどのリクエストヘッダ項目をデータを一意に特定するために> 利用するかを指定する。 例えば、緯度経度から住所に変換できる API が、返す住所情報の表示言語を Accept-Language の内容によって切り替える、といったケースで必要になる(URI だけでは内容が同一ではなくなるため、キャッシュに残った誤った情報が表示されてしまう)。
そこで、Vary ヘッダを使いキャッシュするかどうかの判断条件にどのリクエストヘッダを使うかを指定する。
Vary: Accept-Language
Cache-Controlヘッダ : Cache-Control ヘッダに指定できるディレクティブを以下に示す。
- public・・・キャッシュはプロキシにおいてユーザが異なっても共有することができる
- private・・・キャッシュはユーザごとに異なる必要がある
- no-cache・・・キャッシュしたデータは検証モデルによって確認が必要
- no-store・・・キャッシュをしてはならない
- no-transform・・・プロキシサーバはコンテンツのメディアタイプやその他内容を変更してはならない
- must-revalidate・・・いかなる場合もオリジナルのサーバへの再検証が必要
- proxy-revalidate・・・プロキシサーバはオリジナルのサーバへの再検証が必要
- max-age・・・データが新鮮である期間を示す
- s-maxage・・・max-age と同様だが中継するサーバでのみ利用される
2.2.3. メディアタイプの指定
レスポンスではContent-Typeというヘッダを利用してメディアタイプを指定を行う。 例えば以下のように。
Content-Type: application/json
Content-Type: image/png
メディアタイプを Content-Type で指定する必要性
全ての API は適切なメディアタイプをクライアントに返すべきである。
なぜならクライアントの多くは、Content-Type の値を使ってデータ形式をまずは判断しており、その指定を間違えるとクライアントが正しくデータを読み出すことができないケースが出てくるから。
x- で始まるメディアタイプ
サブタイプが x- で始まるメディアタイプがある。 これはそのメディアタイプが IANA に登録されていないことを意味する。
データ形式が新しく登場したものであったり、あまり一般的ではない場合にはIANAに登録されていないケースがある。
- application/x-msgpack
- application/x-yaml
- application/x-plist
また、現在は IANA に登録済みであっても、かつて登録前に x- で始まるサブタイプが利用されていて、現在もその歴史的経緯が残っているという場合もある。
- application/x-javascript
- application/x-json
- application/x-png
自分でメディアタイプを定義する場合 : インターネット上に広く API を公開する場合はベンダツリーを使うのが最も適している。 vnd. に続いて団体名などがきて、具体的なフォーマット名を指定するような書式になる。
application/vnd.companyname.awesomeformat
JSONやXMLを用いた新しいデータ形式を定義する場合 : +xml や +json のように用いたデータ形式を + に続けて記述するべきとされている。 RSS や Atom のデータ形式はこのルールにしたがっている。
- application/rss+xml
- application/atom+xml
GitHubでは以下のように定義している。
HTTP/1.1 200 OK Server: GitHub.com Content-Type: application/json; charset=utf-8 X-GitHub-Media-Type: github.v3
リクエストデータとメディアタイプ
リクエストの際にもメディアタイプは利用される。 主に使われるヘッダは以下の2つ。
| ヘッダ | 説明 |
|---|---|
| Content-Type | レスポンスヘッダの場合と同様リクエストボディがどんなデータ形式で送られているのかを示す |
| Accept | クライアントが「どんなメディアタイプを受け入れ可能か」をサーバに伝えるために利用する |
2.2.4. 同一生成ポリシとクロスオリジンリソースの共有
同一オリジンポリシー
同一オリジンポリシーは重要なセキュリティの仕組みであり、あるオリジンによって読み込まれた文書やスクリプトが他のオリジンにあるリソースにアクセスできる方法を制限するものである。
クロスオリジンリソース(CORS)
CORSはブラウザで実行されているスクリプトから開始されるクロスオリジン HTTP リクエストを制限するブラウザのセキュリティ機能である。
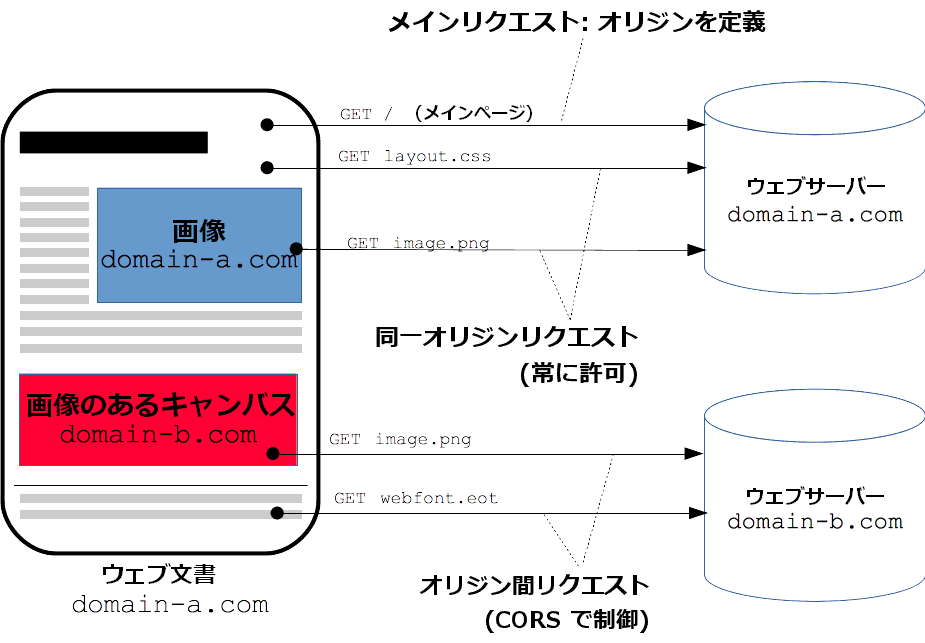
REST APIが非CORSのリクエストを受け取りたいとき: この場合CORSを許可する必要があります。
2.2.5. 独自HTTPヘッダの定義
適切なヘッダが存在しないメタデータを送りたい場合は、独自の HTTP ヘッダを定義する。 例えば以下のように。
X-AppName-PixelRatio: 2.0
HTTP ヘッダを新しく定義する場合はこのように X- という接頭辞を最初につけて、次にサービスやアプリケーションや組織などの名前をつけるというのが一般的である。
2.3. 設計変更しやすいWeb APIの作成方法
2.3.1. 設計変更しやすさの利点
基本的に一度リリースしたWebAPIはその中身を変更しようとするとそのAPIを使っているシステム(APIユーザ)にも影響が出てしまうため、不具合を除けば変更しないことが望ましい。 WebAPIをバージョン管理することで管理側が設計を変更しやすくできます。
2.3.2. APIのバージョン管理
古いVersionでアクセスしてきているクライアントに対してはそれまでと変わらないデータを送り、新しい形式でのアクセスには新しい形式のデータを返す。(複数のバージョンの API を提供する)
例えば TumblrのAPIはこのように提供されている。
http://api.tumblr.com/v2/blog/good.tumblr.com/info
ほかにも以下のような指定方法があるが、特に強いこだわりがなければURIにパスで指定する方式が無難である。
- バージョンをクエリ文字列に入れる方法
- メディアタイプでバージョンを指定する方法
バージョン情報の表現
バージョン情報の表現方法は以下の4つのいずれかになることが多い。
2019-12-04のような日付形式v1.2.3のようなセマンティックバージョニング形式v1.2のようなメジャーバージョン.マイナーバージョンの形式v1のようなメジャーバージョンだけの形式
APIの規模や改修頻度にもよるが多くの場合は3か4で十分であると言えるだろう。
バージョン管理の単位
本来であれば v1 にすべての機能が網羅されており、 v2 にバージョン変更しても同じようにすべての機能が網羅されているという形の方がすっきりしているように見えます。
この形だと一部の機能だけ後方互換性のない変更を行いたいにも関わらず、すべての機能に対してバージョン変更が必要になってしまいます。
そこで機能(エンドポイント)ごとにバージョン管理を行うという形を取ることがあります。
例えば、以下の2つのエンドポイントがある場合。
/v1.0/users
/v1.0/companies
users側にのみ変更があった場合は、
/v1.1/users
/v1.0/companies
のようにバージョン管理をしていく形になります。
2.3.3. バージョン変更の指針
Versioningのルールとしては、Semantic versioningが広く知られている。 メジャー、マイナー、パッチの数値を繋いで 1.2.3 のような表記で表現され、以下のようなルールが適用される。
- パッチバージョンはソフトウェアの API に変更がないバグ修正などを行った時に増える
- マイナーバージョンは後方互換性のある機能変更、あるいは特定の機能が今後廃止されることが決まった場合に増える
- メジャーバージョンは後方互換性のない変更が行われた場合に増える
FacebookやTwitterはマイナーバージョンまでを含めているが、このパターンは少ない。 URIに含めるのはメジャーバージョンまでで基本的にはよい。
2.3.4. API提供の終了
API のバージョンを増やすと、API を公開する側のメンテナンスコストも、それを利用する側のメンテナンスコストも増えてしまうため、古いバージョンのサポートを終了していく必要がある。 広く一般に公開している API の場合、事前に終了日をアナウンスしてそれまでに対応してくれるように周知徹底する必要がある。 API の終了を告知してから、最低6ヶ月はAPIの公開を続けるのが良いとされる。
2.3.5. オーケストレーション層
オーケストレーション層はLSUDsなAPIを色々叩いたり処理してSSKDsなAPIに変換する層である。
オーケストレーション:コンピュータシステム、アプリケーション、およびサービスにおける、設定、管理、調整の自動化を意味する LSUDs:大多数向けの未知の外部開発者に向けたAPI SSKDs:利用者が自分が知っている開発者向けのAPI
メリット
- クライアントごとに最適化したAPIを実装できる
- 複数クライアントで書かなければいけないロジックをオーケストレーション層に集約できる
- A/Bテストしやすい
- バックエンドの開発完了を待たずにAPIスタブを作れるので、クライアントの開発を妨げない
- APIリリースサイクルをバックエンド本体側から分離できる
- バックエンドの仕組みを知らなくてもクライアント開発者がAPI開発することも可能
デメリット
- APIの数が爆増する
- バックエンドのAPIが増えると、オーケストレーション層でも対応しないといけない
- 一段レイヤーが増えるのでネットワークコストも増える(実装次第)
1.3 - 3.堅牢なWebAPI設計
3.1. 堅牢なWeb API設計
3.1.1. Web APIの安定化
APIでのセキュリティの問題に注目し、APIについて最低限やっておくべき対策は以下の通りである。
- サーバとクライアント間での情報不正入手
- サーバの脆弱性による情報の不正入手や改竄
- ブラウザからのアクセスを想定しているAPIにおける問題
3.1.2. サーバ・クライアント間での情報不正入手
HTTPSによるHTTP通信の暗号化
最も簡単でなおかつ効果のある方法はHTTPによる通信を暗号化することである。 HTTP通信を暗号化する方法として最も多く使われ、簡単に導入できるのがHTTPSというTLSによる暗号化である。
HTTPSを利用すると、サーバとクライアントの間の通信は暗号化され、途中で経由する中継サーバやネットワーク上でその中身を見ることができなくなる。
HTTPS による通信を行う場合には、サーバが送ってきた SSL サーバ証明書を受け取るが、その際にその証明書が不正なものでないかをきちんと確かめる必要がある。 それを確かめていない場合、中間者攻撃(MITM)による盗聴などが行われる危険性がある。
MITM:クライアントとサーバの通信経路の間に入り込んで中継を行うことで情報を盗み出す手法
3.1.3. ブラウザでアクセスする際の問題
XSS
Web アプリケーションにおいてHTMLにデータが埋め込まれる場合だけでなく、APIとしてJSONのようなデータを返す場合でも注意する必要がある。
例えばユーザ名に埋め込まれたJavaScript が入力のチェックをすり抜けて JSON にも格納されてしまい、それを受け取ったブラウザが画面上に表示してしまうみたいなケースがありうる。こういったことを悪用した攻撃がXSSである。
XSS対策のために一般的にはユーザからの入力をチェックしデータをユーザに返す際におかしな値を取り除く必要がある。
APIの場合は以下の通りである。
- Content-Type に application/json を必ず返す
- Content Sniffering を無効にするため X-Content-Type-Options: nosniff を指定する
X-Content-Type-Options はIE7以前のブラウザには効果がない。 そこで、さらなる対策として「追加のリクエストヘッダのチェック」と「JSON 文字列のエスケープ」を施す必要がある。
XSRF(CSRF)
サイトをまたいで偽造したリクエストを送りつけることにより、ユーザが意図していない処理をサーバに実行させる攻撃がXSRFである。
一般的に取られる XSRF 対策は、XSRFトークンを使う方法である。
送信元となる正規のフォームに、そのサイトが発行したワンタイムトークン、あるいは少なくともセッションごとにユニークなトークンを埋め込んでおき、そのトークンがないアクセスは拒否するというもの。
JSONハイジャック
JSONハイジャックはAPIからJSONで送られてくる情報を悪意ある第三者が盗み取ることである。 JSONハイジャックを防止するためには、現在のところ以下のような対策が有効である。
- JSONをScript要素では読み込めないようにする
- JSONをブラウザが必ずJSONと認識するようにする
- JSONをJavaScriptとして解釈不可能、あるいは実行時にデータを読み込めないようにする
3.1.4. 悪意のあるアクセスへの対策
パラメータの改ざん
サーバに送信するパラメータを勝手に変更してサーバに送信することで、本来取得できない情報を取得したり、サーバ側のデータを本来ならありえない側に変更したりすること。
こうしたことを避けるために重要なのは本来アクセスができないはずの情報はサーバ側できちんとチェックし、アクセスを禁止するようにしておくことである。
3.1.5. セキュリティ関連のHTTPヘッダ
X-Content-Type-Options
X-Content-Type-Options: nosniff
X-XSS-Protection
ブラウザが備えているXSSの検出、防御機能を有効にするヘッダ。 IE8以上、Chrome と Safari にこの機能が実装されている。
X-XSS-Protetion: 1; mode=block
X-Frame-Options
このヘッダを設定することで指定したページがフレーム内で読み込まれるかどうかを制御することができる。 IE8以上、Chrome や Safari、FireFox などのブラウザが対応している。
X-Frame-Options: deny
Content-Security-Policy
読み込んだ HTML 内の img 要素、script 要素、link 要素などの読み込み先としてどこを許可するのかを指定するためのヘッダ。
XSS の危険性を低減することができる。
Content-Security-Policy: default-src `none`
Strict-Transport-Security
Http Strict Transport Security(HSTS) を実現するためのヘッダ。 このヘッダを利用すると、あるサイトへのブラウザからのアクセスを HTTPS のみに限定させることができる。
Strict-Transport-Security: max-age=15768000
Public-Key-Pins
HTTP-based public key pinning(HPKP) のためのヘッダ。 SSL証明書が偽造されたものでないかをチェックするために利用する。
Public-Key-Pins: max-age=2592000;
pin-sha256="(省略)";
pin-sha256="(省略)"
Set-Cookieヘッダとセキュリティ
ブラウザでセッションを扱う場合はクッキーをセッション管理に使う場合が多いが、その際にもセキュリティを考慮しておくことが可能。 そのために使うことができるのが Secure および HttpOnly という属性である。
Set-Cookie: session=(省略); Path=/; Secure; HttpOnly
Secure 属性をつけることでそのクッキーは HTTPS での通信の際のみサーバに送り返される。 HttpOnly 属性をつけることでそのクッキーは HTTP の通信のみで使われ、ブラウザで JavaScript などのスクリプトを使ってアクセスすることができないものであることを示せる。
3.1.6. 大量アクセスへの対策
ユーザごとのアクセスを制限する
一度の大量のアクセスがやってきてしまう問題を解決するための最も現実的な方法はユーザごとのアクセス数を制限することである。
単位時間あたりの最大アクセス回数(レートリミット)を決め、それ以上のアクセスがあった場合にエラーを返すようにする。
レートリミットを行うにあたっては以下のようなことを決める必要がある。
- 何を使ってユーザを識別するか
- リミット値をいくつにするか
- どういう単位でリミット値を設定するか
- リミットのリセットをどういうタイミングで行うか
制限値を超えてしまった場合の対応
レートリミットを超えた場合は 429 Too Many Requests を返す。
RFC の中でこのステータスコードについては以下のように書かれている。
- エラーの詳細をレスポンスに含めるべきである(SHOULD)
- Retry-After ヘッダを使って次のリクエストをするまでにどれくらい待てば良いかを指定しても良い(MAY)
レートリミットをユーザに伝える
レートリミットを行なった場合、現在のリミットアクセス数やどれくらいすでにアクセスしているのか、それがリセットされるのはいつか、などの情報をユーザに知らせてあげた方が親切である。
TwitterやGitHubでは、レートリミットを知るための専用のAPIを用意している。
HTTP のレスポンスでレートリミットを渡す場合は、HTTP ヘッダに入れるのが現時点でのデファクトスタンダード。
- X-RateLimit-Limit・・・単位時間あたりのアクセス上限
- X-RtaeLimit-Remaining・・・アクセスできる残り回数
- X-RateLimit-Reset・・・アクセス数がリセットされるタイミング
3.2. Web APIの関連資料
3.2.1. Web API チェックリスト
REST API設計におけるチェックリスト。
英) https://www.kennethlange.com/rest-api-checklist/
3.2.2. Web APIの資料
| 資料名 | URL | 提供機関 |
|---|---|---|
| REST API Reference | https://nec-baas.github.io/baas-manual/latest/developer/ja/rest-ref/index.html | NEC |
| REST API Checklist | https://www.kennethlange.com/rest-api-checklist/ | |
| mdn web docs HTTP | https://developer.mozilla.org/ja/docs/Web/HTTP | MDN |
| RFC 6749 OAuth2.0 | https://tex2e.github.io/rfc-translater/html/rfc6749.html | IETF |
| Google JSON style Guide | https://google.github.io/styleguide/jsoncstyleguide.xml | |
| API設計まとめ | https://qiita.com/KNR109/items/d3b6aa8803c62238d990 |
2 - 2.Web認証技術基礎
2.1. 認証とは
2.1.1. 認証と認可
認証と認可は下記のように定義される。
- 認証(Authentication) … ある個人を特定すること
- 認可(Authorization) … 行動やリソースの許可をすること
Web系サービスの場合は認証を行った時点でそのユーザが使用できる機能が決まるため認証されたと同時に認可もされていると言える。
2.1.2. 様々な認証の方法
HTTP上で認証を行う場合。
- セッションベースの認証
- トークンベースの認証
- Authorizationヘッダを用いた認証
など様々な方法がある。
2.2. セッションベースの認証
セッションベースの認証はセッション管理をクッキー(cookie)の仕組みを使ってログイン者の認証状態をサーバー側に保持しておくやり方である。
セッション管理で保持した状態にアクセスするキーとして、セッションIDを使用する。 セッションベースの認証ではログインの成功したら新たにセッションIDを発行してブラウザ側に送り、あとはそのセッションIDをやり取りすることで、認証状態を維持していくやり方をとる。
この手法は実装も比較的簡単でありユーザにとっても使いやすく優れた方法といえる。
ただしセッションIDが流出した場合セッションベースの認証は意味を失う。
2.2.1. セッションIDの流出を防ぐチェックポイント
- クッキー発行の際の属性に不備がないか(特にDomain、Source、HttpOnlyなど)
- セッションIDをURLに保持などしてRefererヘッダから漏洩するリスクがないか
- TLS等で暗号化されていないためネットワークの盗聴で漏洩するリスクがないか
- セッションIDが推測可能になっていないか(セッション管理機構の自作はNG)
また、セッションベースの認証はCSRF(クロスサイト・リクエストフォージェリ)攻撃に対して弱いことが知られているため、CSRF対策とあわせて使う必要がある。
2.3. トークンベースの認証
2.3.1. JWT認証
JWT(JSON Web Token)認証はJavaScriptのオブジェクトの形をした認証情報を用いた認証のこと。
JWTの構成
JWTは以下の3要素で構成される。
- ヘッダー … 署名に使われている暗号化アルゴリズムや、トークンタイプなどのメタ情報が入る
- クレーム情報 … 任意の情報を含ませることができ、ここにユーザー認証情報を記述する
- 署名 … ヘッダーに記述した暗号化アルゴリズムにより、ヘッダーとクレーム情報をBase64urlに変換したものから生成される
JWT認証のメリット
- 安全
- JWTに署名が含まれているため、改ざんがあってもチェックできるようになっている。
- 実装のしやすさ
- セキュアなToken発行が楽に実装できる。
- 管理のしやすさ
- URLに含むことができる文字で構成されているから、HTTPリクエストでの取り扱いが楽。
- 認証に必要となる情報はすべてJWTの中に入っているため、ユーザー認証情報をサーバーで管理する必要がない。DB問い合わせを行う必要がない。
JWT認証の脆弱性
基本的にJWT認証を実現するライブラリの使い方や秘密鍵の長さに気を付けていれば問題ないが、以下のような脆弱性がある。
- アルゴリズムでnoneを許容すると署名作成の際にハッシュ化されないため、改ざんができてしまう = none attack * ライブラリの設定で防げるし秘密鍵を指定したらデフォルトで受け付けない場合がほとんどである
- 秘密鍵が短いとbrute force attackで突破できてしまう * 256bitなどの長さならほぼ問題ない * 256bit以上が推奨されている
2.3.2. OAuth/OAuth2またはOpenIDによる認証
OAuth/OAuth2
OAuthは基本的に広く第三者に公開されるAPIでデータや機能へのアクセス権限の許可を行う仕組みのこと。 OAuthにより権限の許可を付与することで本来であれば利用することができない他サービスのリソースを連携してもらうことができる。
OAuthには 1.0 と 2.0 があり、2.0 は2012年10月にRFC6749として標準化されている。 OAuth 1.0を利用する理由は特にないため、実装する場合は2.0を利用するのが良い。
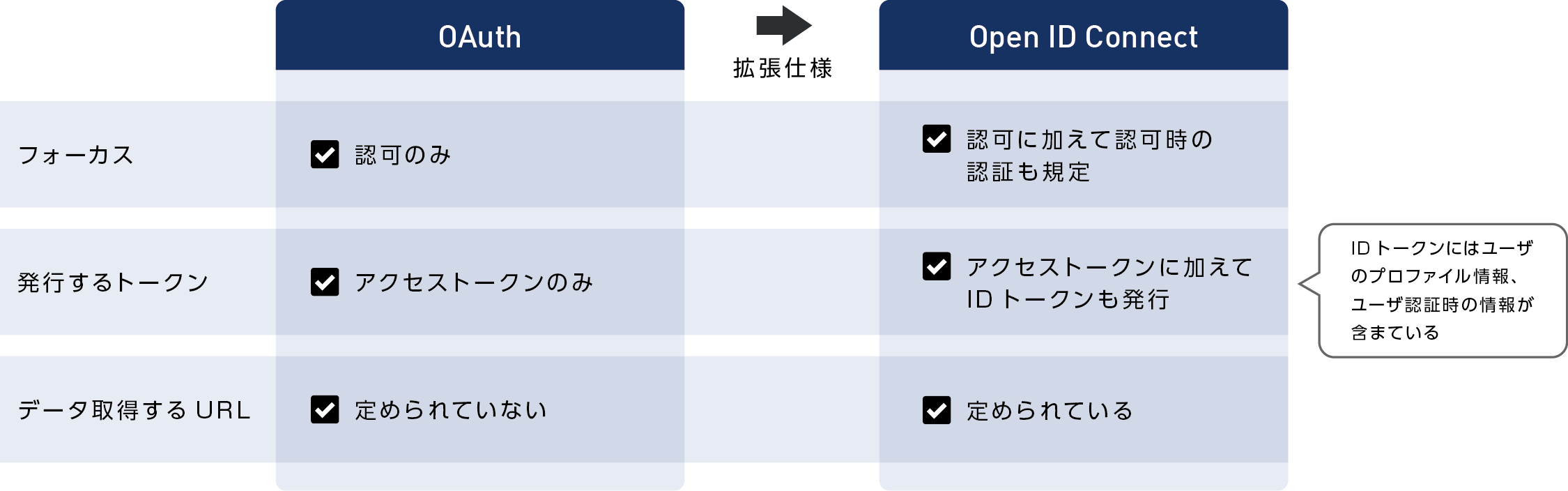
Open ID Connect
Open ID Connect はシンプルなIDプロトコルであり、OAuth 2.0 プロトコルを使用して構築されたオープン・スタンダードです。( OAuth2.0の拡張版 )
OpenID
Open IDはユーザーのIDや認証、アクセス先に関する情報を、特定のサービスに依存しない形で連携するためのプロトコルである。
仕組みとしては、利用者からログイン要求のあった「クライアントアプリ」が「OpenID Provider」と呼ばれる認証サーバへ利用者を誘導し、利用者は「ログインID」と「パスワード」を入力して認証を行う。
2.4. Authorizationヘッダを用いた認証
2.4.1. Basic認証
Basic認証は特定のディレクトリに設定をすることでIDとパスワードがなければそのディレクトリ以下のコンテンツを閲覧できなくすることができる機能のこと。
この仕組みはWebサーバの設定(.htaccessなど)でも実現できる場合が多いが、各種フレームワークや言語の機能で実装できる場合もある。
2.4.2. Digest認証
Digest認証(ダイジェスト認証)はBasic認証の平文で「ユーザーID」と「パスワード」を送信してしまう欠点を改善した認証方式である。
具体的には「ユーザーID」と「パスワード」をハッシュ化して送信する。
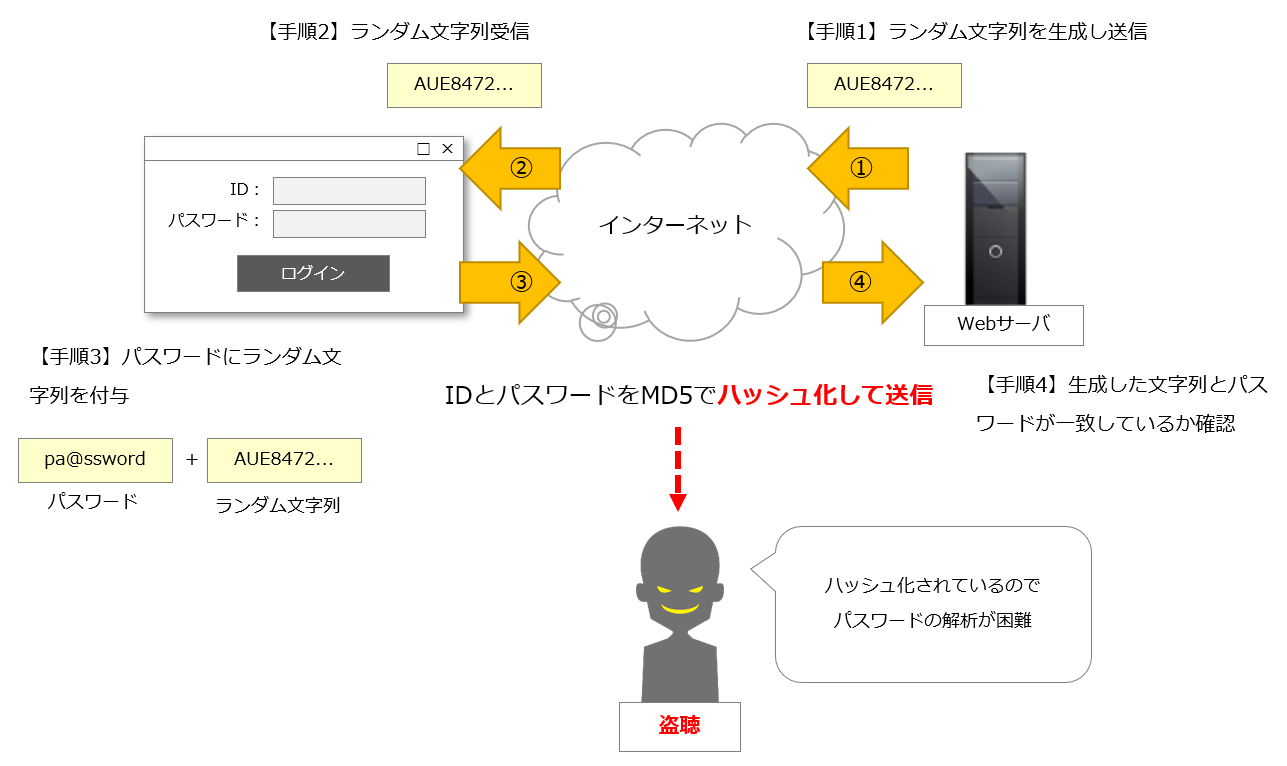
SSL/TLS(HTTPS)を使用すればBasic認証の平文でパスワードを送信する欠点を改善できるため、Digest認証は、HTTPS通信ができない環境で使われるHTTP認証方式と言える。
4.3. Bearer認証
Bearer認証(アクセストークン認証)はログインID・パスワードなどでユーザー認証を行なった後に、サービスから発行されるアクセストークンを受け取って、APIのリクエスト時に送信する認証方式のこと。
具体的には、HTTPリクエストヘッダーにアクセストークンを記述して送る。 設定するヘッダー項目は「Authorizationヘッダー」です。
Authorization: Bearer {アクセストークン}
この認証はトークンを利用した認証・認可に使用されることを想定しており, OAuth 2.0の仕様の一部として定義されているが, その仕様内でHTTPでも使用しても良い。
トークンの形式はtoken68の形式で指定することが定められている。
token68は1文字以上の半角英数字, - (ハイフン), . (ドット), _ (アンダーバー), ~ (チルダ), + (プラス), / (スラッシュ)から構成された文字列を指す. 文字列の末尾に任意個の = (イコール)が挿入されていても良い。
2.5. アプリやサービスのセキュリティ認証
2.5.1. パスワード認証
ユーザーを「ID」と「パスワード」により認証するもので、インターネットの初期から使われている認証方式。 ほかの認証方式に比べて突破しやすいため、パスワード認証方式を対象とするサイバー攻撃は数多くある。
パスワードの設定時に、「英字(大文字/小文字)、数字、記号を混在させること」、「6文字以上にすること」などの規定を設けて、複雑なパスワードの設定を促す。単純なパスワードを使えなくすることでブルートフォースアタックを防ぎ、認証を強化できる。
パスワード認証に関連する技術
| 名称 | 内容 |
|---|---|
| PINコード | いわゆる暗証番号で「数桁の数字の組み合わせ」を認証に利用する。突破されやすいため他の認証を組み合される |
| ワンタイムパスワード | 1回しか使えないパスワードです。流出しても再利用はできないため不正アクセスを防ぐことができる |
| ニーモニック認証 | 写真の組み合わせを使った認証方式 |
| 秘密の質問 | あらかじめ決めておいた質問とその回答による認証方式 |
2.5.2. CAPTURE認証
CAPTURE認証はコンピューター(プログラム)と人間を識別するためのテストのこと。
画面に「判別しにくい歪んだ文字列の画像」を表示しその文字を入力させるのが代表的。パズルを完成させるケースもある。 近年ではAIが歪んだ文字列を認識できるようになっているためあまり使われなくなってきた。
2.5.3. SNS認証
SNSのアカウントを利用して認証します。Facebook、Twitterなどのアカウントで他のWebサイトにログインできるようになる。
「OpenID」という認証を行うためのプロトコルや、「OAuth」と呼ばれる別のサービスに特定の権限のみ与える仕組みを利用して実装される。
2.5.4. 生体認証
生体そのものが持っている特徴を利用して本人確認を行う認証を指す。
指紋認証、顔認証、虹彩認証など様々な種類があるため、パスワード認証と比べると盗用のリスクが低くユーザーはIDやパスワードを覚えたり、カードを持ち歩いたりする必要が無いので利便性も高くなる。 しかしけがや事故により認証できなくなる可能性がある。