2.レスポンスデータ設計
2.1. レスポンスデータ設計
2.1.1. レスポンスデータフォーマット
エンドポイントへアクセスされた場合のレスポンスされるデータフォーマットは以下のようなものがある。
| データフォーマット | 説明 |
|---|---|
| XML | XMLは個別の目的に応じたマークアップ言語群を創るために汎用的に使える |
| JSON | JavaScript Object Notation |
| JSONP | scriptタグを使用してクロスドメインな(異なるドメインに存在する)データを取得する仕組み |
JSONPはCSRF脆弱性がある
基本的にはJSONをレスポンスのデフォルトとして対応し必要があればXMLなどに対応する方針が良い。
データフォーマットの指定方法は以下の3種類がある。
- クエリパラメータを使う方法・・・もっとも主流な方法
- 拡張子を使う方法
- リクエストヘッダでメディアタイプを指定する方法・・・HTTP仕様に厳格に合わせようと思ったらファーストチョイス
2.1.2. JSONPの扱い
JSONPに対応する必要がないのであれば、無理に対応しない方が無難である。 同一生成元ポリシーによって守られている攻撃手法の対象になりえるため。
2.1.3. データ内部構造の設計方針
APIで返すレスポンスデータを決定する際にまず優先に考えることは、APIのアクセス回数がなるべく減るようにすることである。
そのためには API のユースケースをきちんと考えることが重要だ。
ひとつの作業を完了させるために複数回のアクセスが必要となるAPIはChatty APIと呼ばれるが、Chatty API はネットワークのトラフィックを増加させ、クライアント実装の手間も増やしてしまうため基本的には使わないようにする。
レスポンス内容をユーザが選べるようにする
もっともシンプルな解決策は全ての API で「できる限り多くのデータを返す」というもの。
送受信されるデータサイズはできるだけ小さい方が望ましいため、「取得する項目を利用者が選択可能にする」という手法が取られることがある。 (例:クエリパラメータを使って、ユーザ情報のうち名前と年齢を取得したい、みたいなことを指定できるようにする、など)
他にはSmall、Medeium、Large などのレスポンスグループを指定して必要なデータだけを取得させるというやり方がある。
エンベロープは必要かどうか
レスポンスが正常時もエラー時も200 OKで返ってきて本当に成功したかどうかはヘッダに載せるというやり方。 これはHTTPの仕様を無視している且つ冗長なので絶対にやるべきではない。
HTTP自体がエンベロープの役割を果たしているためエラーかどうかの判断はステータスコードに基づいて行うのが良い。
データはフラットにすべきか
なるべくフラットな方が良いが階層構造を持った方がわかりやすいケースについてはそうするべきである。
Google JSON style Guideより
配列とフォーマット
配列をそのまま返すべきか、オブジェクトに包んで返すべきか迷う場合がある。 基本的にはオブジェクトで包んで返すべきであり、以下のようなメリットがある。
- レスポンスデータが何を示しているのかがわかりやすくなる
- レスポンスデータをオブジェクトに統一することができる
- セキュリティ上のリスクを避けるこができる(トップレベルが配列だとJSONインジェクションの危険がある)
配列の件数あるいは続きがあるかをどう返すべきか
本当に件数を返す必要があるかどうかはしっかり見極めた方が良い。
全件数を取る必要がなかったとしても「次の20件」のようなリンクを表示するために、「今取得したデータに続きはあるのか」は返した方が良い。
例えば、続きがあれば "hasNext": "true" をつけて返すなど。
2.1.4. 各データのフォーマット
各データ項目の命名規則に関してのポイントは以下の通りである。
- 他の多くのAPIで同じ意味に利用されている一般的な単語を用いる
- なるべく少ない単語数で表現する
- 複数の単語を連結する場合、その連結方法は API 全体を通して統一する
- 変な省略形は極力利用しない
- 単数形・複数形に気をつける
日付のフォーマットについては、広く一般に公開する場合RFC 3339を使うのが良い。 このフォーマットが読みやすく使いやすいものを目指してインターネット上で用いる標準形式として定められたものであるためである。
2.1.5. エラー表現
ステータスコードでエラーを表現する
エラーを返す際にまず真っ先にやるべきことは適切なステータスコードを使うことである。
| ステータスコード | 説明 |
|---|---|
| 100番台 | 情報 |
| 200番台 | 成功 |
| 300番台 | リダイレクト |
| 400番台 | クライアントサイド起因エラー |
| 500番台 | サーバサイド起因エラー |
エラー詳細をクライアントに返す
エラーの内容を返す方法は大きく分けて2つある。
- HTTP のレスポンスヘッダに入れて返す
- レスポンスボディで返す(こちらの方が主流)
例えばTwitter APIのレスポンスボディは以下のようになっている。
{
"errors":[
{
"message":"Bad Authentication data",
"code":215
}
]
}
2.2. HTTPリクエストとレスポンスの仕様
2.2.1. ステータスコード
主にAPIで利用する可能性のあるステータスコードは以下の通り。
| ステータスコード | 名前 | 説明 |
|---|---|---|
| 200 | OK | リクエストは成功した |
| 201 | Created | リクエストが成功し、新しいリソースが作られた |
| 202 | Accepted | リクエストは成功した |
| 204 | No Content | コンテンツなし |
| 300 | Multiple Choices | 複数のリソースが存在する |
| 301 | Moved Permanently | リソースは恒久的に移動した |
| 302 | Found | リクエストしたリソースは一時的に移動している |
| 303 | See Other | 他を参照 |
| 304 | Not Modified | 前回から更新されていない |
| 307 | Temporary Redirect | リクエストしたリソースは一時的に移動している |
| 400 | Bad Request | リクエストが正しくない |
| 401 | Unauthorized | 認証が必要 |
| 403 | Forbidden | アクセスが禁止されている |
| 404 | Not Found | 指定したリソースが見つからない |
| 405 | Method Not Allowd | 指定されたメソッドは使うことができない |
| 406 | Not Acceptable Accept | 関連のヘッダに受理できない情報が含まれている |
| 408 | Request Timeout | リクエストが時間以内に完了しなかった |
| 409 | Conflict | リソースが矛盾した |
| 410 | Gone | 指定したリソースは消滅した |
| 413 | Request Entity Too Large | リクエストボディが大きすぎる |
| 414 | Request-URI Too Long | リクエストされた URI が長すぎる |
| 415 | Unsupported Media Type | サポートしていないメディアタイプが指定された |
| 429 | Too Many Requests | リクエスト回数が多すぎる |
| 500 | Internal Server Error | サーバ側でエラーが発生した |
| 503 | Service Unavailable | サーバが一時的に停止している |
200番台:成功
201 は Created つまりリクエストの結果サーバ側でデータ作成が行われた場合に返す
202 の Accepted はリクエストした処理が非同期で行われ、処理は受け付けたけれど完了していない場合に利用する
204 は No Conent という言葉の通りレスポンスが空のときに返す
PUT や PATCH の場合は 200 とともに操作したデータを返し(POST の場合は 201)、DELETE の場合は 204 を使うのが良い。
こうしておけば、どちらの場合も返ってきたデータを見れば変更が正しく行われたことが理解できる。
300 番台:追加で処理が必要
300 番台のステータスコードでよく知られている利用目的は「リダイレクト」。 リダイレクトの場合は Location というレスポンスヘッダにリダイレクト先の新しいURIが含まれる。
API の場合もリダイレクトを利用することはありえるが、Web サイトのように URI の変更、サイトの移転や一時的な移動に伴ってリダイレクトを行うことはあまり好ましくない(クライアントの実装によっては、動かなくなってしまうため)。
400番台:クライアントのリクエストに問題
400 Bad Request はその他のエラーコード
送られてきたパラメータに間違いがある場合など、他のステータスコードに該当しない場合は 400 を使う
401 Unauthorized は認証のエラー(あなたが誰かわからない)
403 Forbidden は認可のエラー(あなたが誰かはわかったけど、この操作は許可されていない)
404 Not Found はアクセスしようとしたデータが存在しない場合に返す
ただし、何が存在しないかはケースバイケースなので、エラーメッセージをきちんと返す必要がある
405 Method Not Allowed はエンドポイントは存在するがメソッドが許可されていない
(GET の API に POST でアクセスしようとした場合など)
406 Not Acceptable はクライアントが指定してきたデータ形式に API が対応していない
(JSON と XML しか対応していないのに YAML を指定した場合など)
408 Request Timeout は、リクエストをクライアントがサーバに送るのに時間がかかりすぎて、サーバ側でタイムアウトを起こした場合
409 Conflict は、リソース競合が発生した際のエラー
(重複した ID のデータを登録しようとした場合など)
410 Gone は 404 と同じく、リソースが存在しない場合に返すコードだが、こちらは単に存在しないのではなく、かつて存在したけれど今はもう存在しない、ということを表す
413 Request Entity Too Large はリクエストボディが大きすぎるときのエラー
ファイルアップロードに、許容されるサイズ以上のデータが送られてきたような時に発生する
414 Request-URI Too Long は GET 時のクエリパラメータに長すぎるデータが指定された場合などに発生する
415 Unsupported Media Type は、リクエストヘッダの Content-Type で指定されているデータ形式にサーバが対応していないケースで発生する
例えば、XML に対応していない API に XML を送り、Content-Type に application/xml を指定している場合などが該当する
429 Too Many Requests は、アクセスの許容範囲の限界を超えた場合に返るエラー
500 番台:サーバに問題がある場合
500 Internal Server Error は、サーバ側のコードにバグがあってエラーを吐いている場合
503 Service Unavailable は、サーバが一時的に利用できない状態になっていることを示すエラー
2.2.2. キャッシュとHTTPの仕様
HTTP のキャッシュには以下の2つのタイプがある。
- Expiration Model(期限切れモデル)・・・レスポンスデータに保存期限を決めておき期限が切れたら再アクセスさせる
- Validaton Model(検証モデル)・・・今保持しているキャッシュが最新であるかを問い合わせ、更新されていた場合にのみ取得を行う
Expiration Model(期限切れモデル)
HTTP 1.1 の定義によると、実現方法は以下の2つ。
- Cache-Control レスポンスヘッダを使う
- Expires レスポンスヘッダを使う
特定の日時に変更されることがあらかじめわかっているデータの場合は Expires で日時を指定する。 今後更新される可能性のない静的なデータの場合は、一年後の日時を指定することで、キャッシュをしばらく有効にできる。 Cache-Control は定期更新ではないものの更新頻度がある程度限られているものや、更新頻度は低くないものの、あまり頻繁にアクセスして欲しくない場合に利用できる。
max-age の計算にはDateヘッダを使う。 HTTP の仕様により500番台のエラーの場合などいくつかの例外を除き、必ずつけなければならない。
Validation Model(検証モデル)
検証モデルを行うには条件付きリクエストに対応する必要がある。
条件付きリクエストとは「もし今保持している情報が更新されていたら情報をください」というもの。
更新されていたときのみデータを返し、更新されていなかったら 304 Not Modified を返す、
条件付きリクエストを行うには、「クライアントが現在保持している情報の状態」をサーバに伝える必要がある。 そのためには最終更新日付とエンティティタグのどちらかを指標として使う。
キャッシュをさせたくない場合
APIの性格によってはキャッシュを全くさせたくない場合もある。 そうした場合は HTTP ヘッダを使って明示的に「キャッシュをして欲しくない」と伝えることができる。
Cache-Control: no-cache
no-cache は厳密には「キャッシュをしない」という指定ではなく、最低限「検証モデルを用いて必ず検証を行う」必要があることを意味する。 機密情報などを含むデータで、中継するプロキシサーバには保存をして欲しくないという場合には no-store を返す。
Varyでキャッシュの単位を指定する : キャッシュを行う際にURI 以外にどのリクエストヘッダ項目をデータを一意に特定するために> 利用するかを指定する。 例えば、緯度経度から住所に変換できる API が、返す住所情報の表示言語を Accept-Language の内容によって切り替える、といったケースで必要になる(URI だけでは内容が同一ではなくなるため、キャッシュに残った誤った情報が表示されてしまう)。
そこで、Vary ヘッダを使いキャッシュするかどうかの判断条件にどのリクエストヘッダを使うかを指定する。
Vary: Accept-Language
Cache-Controlヘッダ : Cache-Control ヘッダに指定できるディレクティブを以下に示す。
- public・・・キャッシュはプロキシにおいてユーザが異なっても共有することができる
- private・・・キャッシュはユーザごとに異なる必要がある
- no-cache・・・キャッシュしたデータは検証モデルによって確認が必要
- no-store・・・キャッシュをしてはならない
- no-transform・・・プロキシサーバはコンテンツのメディアタイプやその他内容を変更してはならない
- must-revalidate・・・いかなる場合もオリジナルのサーバへの再検証が必要
- proxy-revalidate・・・プロキシサーバはオリジナルのサーバへの再検証が必要
- max-age・・・データが新鮮である期間を示す
- s-maxage・・・max-age と同様だが中継するサーバでのみ利用される
2.2.3. メディアタイプの指定
レスポンスではContent-Typeというヘッダを利用してメディアタイプを指定を行う。 例えば以下のように。
Content-Type: application/json
Content-Type: image/png
メディアタイプを Content-Type で指定する必要性
全ての API は適切なメディアタイプをクライアントに返すべきである。
なぜならクライアントの多くは、Content-Type の値を使ってデータ形式をまずは判断しており、その指定を間違えるとクライアントが正しくデータを読み出すことができないケースが出てくるから。
x- で始まるメディアタイプ
サブタイプが x- で始まるメディアタイプがある。 これはそのメディアタイプが IANA に登録されていないことを意味する。
データ形式が新しく登場したものであったり、あまり一般的ではない場合にはIANAに登録されていないケースがある。
- application/x-msgpack
- application/x-yaml
- application/x-plist
また、現在は IANA に登録済みであっても、かつて登録前に x- で始まるサブタイプが利用されていて、現在もその歴史的経緯が残っているという場合もある。
- application/x-javascript
- application/x-json
- application/x-png
自分でメディアタイプを定義する場合 : インターネット上に広く API を公開する場合はベンダツリーを使うのが最も適している。 vnd. に続いて団体名などがきて、具体的なフォーマット名を指定するような書式になる。
application/vnd.companyname.awesomeformat
JSONやXMLを用いた新しいデータ形式を定義する場合 : +xml や +json のように用いたデータ形式を + に続けて記述するべきとされている。 RSS や Atom のデータ形式はこのルールにしたがっている。
- application/rss+xml
- application/atom+xml
GitHubでは以下のように定義している。
HTTP/1.1 200 OK Server: GitHub.com Content-Type: application/json; charset=utf-8 X-GitHub-Media-Type: github.v3
リクエストデータとメディアタイプ
リクエストの際にもメディアタイプは利用される。 主に使われるヘッダは以下の2つ。
| ヘッダ | 説明 |
|---|---|
| Content-Type | レスポンスヘッダの場合と同様リクエストボディがどんなデータ形式で送られているのかを示す |
| Accept | クライアントが「どんなメディアタイプを受け入れ可能か」をサーバに伝えるために利用する |
2.2.4. 同一生成ポリシとクロスオリジンリソースの共有
同一オリジンポリシー
同一オリジンポリシーは重要なセキュリティの仕組みであり、あるオリジンによって読み込まれた文書やスクリプトが他のオリジンにあるリソースにアクセスできる方法を制限するものである。
クロスオリジンリソース(CORS)
CORSはブラウザで実行されているスクリプトから開始されるクロスオリジン HTTP リクエストを制限するブラウザのセキュリティ機能である。
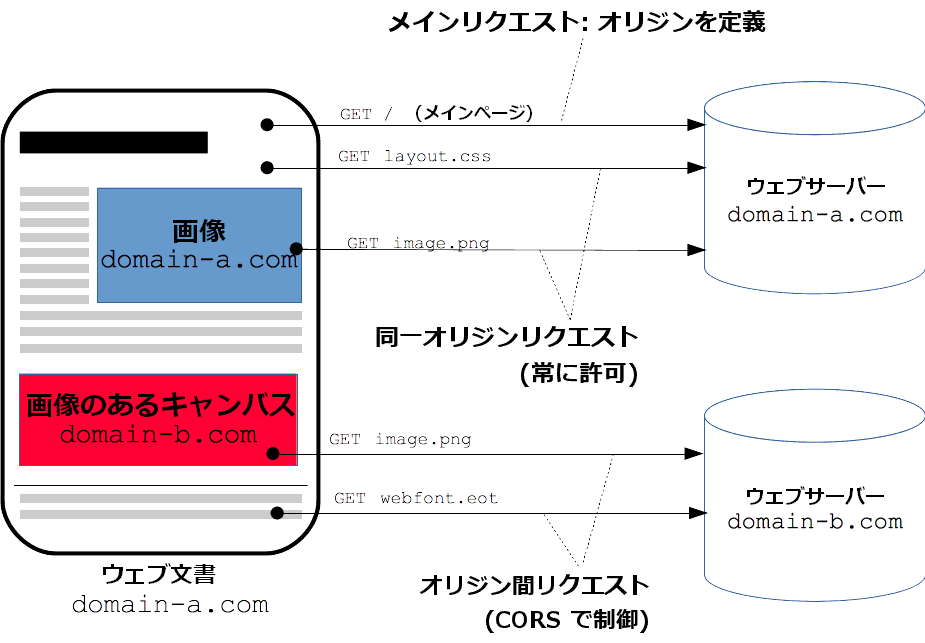
REST APIが非CORSのリクエストを受け取りたいとき: この場合CORSを許可する必要があります。
2.2.5. 独自HTTPヘッダの定義
適切なヘッダが存在しないメタデータを送りたい場合は、独自の HTTP ヘッダを定義する。 例えば以下のように。
X-AppName-PixelRatio: 2.0
HTTP ヘッダを新しく定義する場合はこのように X- という接頭辞を最初につけて、次にサービスやアプリケーションや組織などの名前をつけるというのが一般的である。
2.3. 設計変更しやすいWeb APIの作成方法
2.3.1. 設計変更しやすさの利点
基本的に一度リリースしたWebAPIはその中身を変更しようとするとそのAPIを使っているシステム(APIユーザ)にも影響が出てしまうため、不具合を除けば変更しないことが望ましい。 WebAPIをバージョン管理することで管理側が設計を変更しやすくできます。
2.3.2. APIのバージョン管理
古いVersionでアクセスしてきているクライアントに対してはそれまでと変わらないデータを送り、新しい形式でのアクセスには新しい形式のデータを返す。(複数のバージョンの API を提供する)
例えば TumblrのAPIはこのように提供されている。
http://api.tumblr.com/v2/blog/good.tumblr.com/info
ほかにも以下のような指定方法があるが、特に強いこだわりがなければURIにパスで指定する方式が無難である。
- バージョンをクエリ文字列に入れる方法
- メディアタイプでバージョンを指定する方法
バージョン情報の表現
バージョン情報の表現方法は以下の4つのいずれかになることが多い。
2019-12-04のような日付形式v1.2.3のようなセマンティックバージョニング形式v1.2のようなメジャーバージョン.マイナーバージョンの形式v1のようなメジャーバージョンだけの形式
APIの規模や改修頻度にもよるが多くの場合は3か4で十分であると言えるだろう。
バージョン管理の単位
本来であれば v1 にすべての機能が網羅されており、 v2 にバージョン変更しても同じようにすべての機能が網羅されているという形の方がすっきりしているように見えます。
この形だと一部の機能だけ後方互換性のない変更を行いたいにも関わらず、すべての機能に対してバージョン変更が必要になってしまいます。
そこで機能(エンドポイント)ごとにバージョン管理を行うという形を取ることがあります。
例えば、以下の2つのエンドポイントがある場合。
/v1.0/users
/v1.0/companies
users側にのみ変更があった場合は、
/v1.1/users
/v1.0/companies
のようにバージョン管理をしていく形になります。
2.3.3. バージョン変更の指針
Versioningのルールとしては、Semantic versioningが広く知られている。 メジャー、マイナー、パッチの数値を繋いで 1.2.3 のような表記で表現され、以下のようなルールが適用される。
- パッチバージョンはソフトウェアの API に変更がないバグ修正などを行った時に増える
- マイナーバージョンは後方互換性のある機能変更、あるいは特定の機能が今後廃止されることが決まった場合に増える
- メジャーバージョンは後方互換性のない変更が行われた場合に増える
FacebookやTwitterはマイナーバージョンまでを含めているが、このパターンは少ない。 URIに含めるのはメジャーバージョンまでで基本的にはよい。
2.3.4. API提供の終了
API のバージョンを増やすと、API を公開する側のメンテナンスコストも、それを利用する側のメンテナンスコストも増えてしまうため、古いバージョンのサポートを終了していく必要がある。 広く一般に公開している API の場合、事前に終了日をアナウンスしてそれまでに対応してくれるように周知徹底する必要がある。 API の終了を告知してから、最低6ヶ月はAPIの公開を続けるのが良いとされる。
2.3.5. オーケストレーション層
オーケストレーション層はLSUDsなAPIを色々叩いたり処理してSSKDsなAPIに変換する層である。
オーケストレーション:コンピュータシステム、アプリケーション、およびサービスにおける、設定、管理、調整の自動化を意味する LSUDs:大多数向けの未知の外部開発者に向けたAPI SSKDs:利用者が自分が知っている開発者向けのAPI
メリット
- クライアントごとに最適化したAPIを実装できる
- 複数クライアントで書かなければいけないロジックをオーケストレーション層に集約できる
- A/Bテストしやすい
- バックエンドの開発完了を待たずにAPIスタブを作れるので、クライアントの開発を妨げない
- APIリリースサイクルをバックエンド本体側から分離できる
- バックエンドの仕組みを知らなくてもクライアント開発者がAPI開発することも可能
デメリット
- APIの数が爆増する
- バックエンドのAPIが増えると、オーケストレーション層でも対応しないといけない
- 一段レイヤーが増えるのでネットワークコストも増える(実装次第)