これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
アプリ開発事前知識
- 1: 1.システム開発基礎知識
- 2: 2.Git/Github基礎
- 2.1: 1.Gitの基礎知識
- 2.2: 2. Git&GitHubの使い方
- 2.3: 3. gitにおける各種ファイルと補足情報
- 3: 9.Web技術各種用語集
- 3.1: 1.OS/システム用語
- 3.2: 2.システム開発用語
- 3.3: 3.インフラ/セキュリティの用語
- 3.4: 4.ネットワーク/無線の用語
1 - 1.システム開発基礎知識
1.1. 基本の開発工程
システム開発は以下のフローを用いて開発が行われる。
- 企画
- 計画(要件定義)
- 設計
- 実装
- テスト
- デプロイ(リリース)/保守運用
1.1.1. 企画
企画ではどのようなアプリやサービスを開発するか決める。
企画で考慮すべき内容は以下の通り。
基本内容
- どんなアプリ/サービスを作るのか明確にする
- それがどのような価値/役割を提供する(何を解決する)を大まかにまとめる
その他
- Webアプリ/ソフトウェア開発の場合
- ペルソナ(クライアントやユーザ)像を明確にする
- 類似アプリやサービスがあればそれに関して調査する場合もある
- ゲーム系の場合
- 類似ゲームや元ネタ(世界感の構成材料)に関する調査
- デザイン(ビジュアル)のガイドライン的なものを決める
- 提供する世界観(ゲームカラー)を決める
- Webアプリ/ソフトウェア開発の場合
1.1.2. 計画(要件定義)
要件定義
要件定義は初めに以下の項目を行う。
- 実装する機能の整理
- 機能要件(実装機能一覧)を整理する
- 非機能要件(UX, 性能, 拡張性, セキュリティなど)を整理する
- 技術選定 ・・・ アプリ/サービスの構築のために必要な技術を調査
- 開発人員のバックボーンやスキル/意欲も踏まえる
- 実装したい機能や特性も踏まえる
- 開発期間や技術の学習コストも踏まえる
- 非機能要件(UX, 性能, 拡張性, セキュリティなど)も踏まえる
- システムの構成(アーキテクチャ設計)を行う
- 開発人員の体制
- PM(プロジェクトマネージャー)を決める
- 開発人員が複数いる場合は担当や役割などを決める
- タスクの管理体制の確立
- 開発ワークフローに用いるgitリポジトリの決定
- 開発に関するドキュメント(機能/DB/API/コーディング規則などの書類)の管理や参照フローの決定
- 開発する際のコミニケーションやり取りを行うツール(discord, slackなど)の決定
一般的(組織やプロジェクトにおける)な全体における実装順序は以下の通り。(2,3は同時に進む場合もある)
- インフラストラクチャの構築
- バックエンド(APIサーバ)の機能実装
- フロントエンドの機能実装
個人開発のWebアプリでは「バックエンド」=>「フロントエンド」=>「インフラストラクチャ」の開発が無難である。
1.1.3. 設計
基本設計(外部設計)
基本設計では実装機能のドキュメント的なものを作成します。
- フロント/バック共通
- 機能設計 … 機能や動作のリストアップ(機能一覧表など)
- 方式設計 … フロント/バックエンド(DB含む)/インフラごとの技術選定
- バックエンド
- データベース設計 … データベースのスキーマの設計(ER図, CRUD図など含む)
- API設計 … 機能一覧からAPI設計(API仕様書など)
- フロントエンド
- 画面設計 … ワイヤフレーム, 画面一覧, ディレクトリマップ, 画面遷移図等
- インフラストラクチャ
- アーキテクチャ設計 … アーキテクチャ図など
詳細設計(内部設計)
詳細設計とは、基本設計で決定した内容を基に、ユーザーからは見えないシステム内部の動作・機能を設計して、実際にプログラミングできる内容に詳しく落とし込む工程。(Web系の場合は基本設計に含めてしまうことが多い)
- モジュール設計 ・・・ Webアプリの機能実装に必要なモジュールの選定や分割を細かく設計します
- データ設計 ・・・ Webアプリのデータを保存するデータベースの選定・データ処理の流れ・データの保存場所などの細かい設計を行います
- プログラム設計 ・・・ 設計した内容を実装できるように、プログラミング可能なレベルまで詳しく設計します。具体的には、実装内容・手順をドキュメントに直した設計書の作成等を行います
1.1.4. 実装
設計が完了したあとは開発作業に入って実際にプログラミングを行い実装する。
Gitを用いたタスク管理
Gitを用いた分散型開発の場合は基本的に以下の繰り返しで開発を進める。
- タスクごとにブランチを作成
- 何らかの機能や改修を実装
- 単体テストや結合テストを実装
- github上でプルリクエスト作成
- レビューを受け修正
- マージ7. 1に戻る
1.1.5. テスト
設計された内容を取りこぼし無く実装出来ているのかをテストする。
開発中のアプリをどういった方法でテストするか、どんなテストツールを使用するかを決める。
具体的には入力値のバリテーションチェックや複数の機能のユニットを連結した動作のチェックなどが含まれる。
単体テスト(ユニットテスト)
実装されたコードが設計書に記載された通りにきちんと動くのか検証するテスト。 画面上に見える部分と裏側のデータ双方で、細かい部分の洗い出しが必要となる。
結合テスト(インターフェーステスト)
結合テストとは、モジュール間の結合状態などについて確認するテスト。
統合テスト
全てのモジュールを結合した最終テスト。
1.1.6. デプロイと保守/運営
デプロイ
構築されたインフラストラクチャへ開発したアプリをデプロイする。
個人開発の場合はインフラストラクチャの構築と学習はデプロイする場合に行うと良い。
保守/運営
保守運営を行う。
1.2. 作成すべき設計資料
また設計にあたって作成する文書や図は以下のようなものがある。
Web系で基本的に使いそうなものには○がついてある。他は作るアプリやサービスによる。
| 図・文書 | 説明 | Web系 |
|---|---|---|
| 機能一覧表 | 開発する機能を一覧にまとめます。新規アプリケーション開発の場合は外部設計のベースとなります | ○ |
| 業務フロー図 | 要件定義フェーズで確定していない場合は外部設計として作成します | |
| 画面設計書 | ユーザーが操作する各画面の構成、及び画面遷移図を設計します | ○ |
| 帳票設計書 | 帳簿、伝票などの出力項目、レイアウト、出力タイミングなどを設計します | |
| インターフェース設計書 | アプリケーションが外部とインターフェースする部分を設計します | △ |
| データベース設計書 | データを格納するテーブルを定義します。一般的にはER図を用います | ○ |
| 外部ファイル設計書 | 入出力するファイルのフォーマットを定義します | |
| ハードウェアインターフェース設計書 | ハードウェアの制御方法を記載します | |
| 他アプリケーションとの関連図 | 他アプリケーションとの関連、接続方法を記載します | |
| セキュリティ設計 | 要件定義のセキュリティ要件に対する具体的な対応内容を記載します | △ |
1.2.1. 画面設計に関する資料
これらはフロントエンド設計でほぼ必ず使うはず。
- ワイヤーフレーム(画面レイアウト) ・・・ webページのレイアウトを決める設計図
- 画面一覧表 ・・・ 各画面にどういう機能や文があるかをまとめて一覧にしたもの
- ディレクトリマップ ・・・ webサイトを構成するすべてのwebページの情報をまとめて、一覧にしたもの
- 画面遷移図(サイトマップ) ・・・ システムの画面遷移を図で表したもの
1.2.2. データベース設計に関する資料
バックエンド開発におけるDB周りでは必須。
- テーブル定義書 ・・・ テーブルを作成するための定義書(最悪ER図のみでもよい)
- ER図 ・・・ 実体と関係という概念を用いてデータ構造を図にしたもの
- CRUD図 ・・・ 「Create」「Read」「Update」「Delete」の操作がどのテーブルに対して行われているかを画面(機能やユースケース)ごとに記載したもの
1.3. ソフトウェア開発工程のモデル
ソフトウェアの開発モデルにはウォーターフォール、アジャイル、プロトタイプ、スパイラルがある。

1.3.1. ウォーターフォールモデル
ウォーターフォールは上流工程から計画にもとづいてそれぞれの段階を経て1つのシステムを完成させる開発工程。
多くのシステム会社ではウォーターフォール型でシステム開発を行なっている。
向いているのは以下の場合となる。
- 作りたいシステムが明確
- 変更の可能性がない業務システム開発
- 大規模開発
メリット
- スケジュール管理がしやすい
- 予算が組みやすい
デメリット
- リリースまで時間がかかる
- 仕様変更やトラブル対応に難しい
1.3.2. アジャイルモデル
アジャイルはアプリ/システム開発を小さな単位に分け、実装とテストを繰り返しながら開発を行う工程。
優先順位の高い機能から順に、「設計」「開発」「テスト」「リリース」を繰り返すことで、システムの機能を充実させていくのが特徴となる。 Web系企業で多く用いられている開発手法。
向いているのは以下の場合となる。
- 要件や仕様が細かく定まっていない場合
- 市場の動向や顧客の反応などによって、システムに変更や修正が生じる可能性が高い場合
- 短期間でサービスをローンチしたい場合
メリット
- 短期間でリリース可能
- 仕様変更や不具合に対応しやすい
- ユーザの要望に反映しやすい
デメリット
- 方向性がずれやすい
- スケジュール/進捗の管理がしづらい
1.3.3. スパイラルモデル
スパイラルは機能ごとに開発の小さなサイクルを繰り返し、完成後にリリースする開発手法。
向いているのは以下の場合となる。
- スピード感よりクオリティが求められる場合
- 最初に要件や仕様が詳しく定まらず、途中で仕様変更が生じる可能性が高い場合
メリット
- 仕様変更や修正に柔軟に対応できる
- クオリティの高いシステムを開発できる
- 手戻りを最小限に抑えられる
デメリット
- プロジェクト全体を把握しづらい
- 開発期間が長期化する恐れがある
1.3.4. プロトタイプモデル
プロトタイプは試作品を作り発注者のレビューを受けて修正する開発手法。
Web制作系やゲーム系企業で多く用いられている開発手法。
向いているのは以下の場合となる。
- これまでにないシステムの開発
- 小規模開発や中規模開発
- 発注者側が開発に慣れていない場合
- 欲しいシステムの明確なイメージがない場合
メリット
- 作りたいシステムが具体的でなくても開発を始められる
- 機能の追加や変更に柔軟に対応可能
- 大きな修正や手戻りを防ぐことが可能
デメリット
- プロトタイプ作成のための期間とコストがかかる
- 計画やコストの予測を立てづらい
- 当初の目的とは異なるシステムができてしまう場合がある
1.4. アジャイル開発
1.4.1. アジャイル開発とは
アジャイル開発はアプリ/システム開発を小さな単位に分け、実装とテストを繰り返しながら開発を行うもの。
アジャイル開発では技術選定やアーキテクチャ設計は初めの計画で行うと良い。 機能要件を洗いざらい書きだした後はマイルストーン(開発サイクル)ごとに実装する。
1.4.2. アジャイル開発の種類
スクラム
チーム単位で開発を行う手法。
メンバー各自の役割を決めるが、明確なタスクや工程の振り分けは行われない。 メンバー自身がそれぞれ計画を立て進めるため、メンバー全員で責任を共有する。
スクラムマスター(リーダ)が内部の調整やインシデント管理を行い、他メンバーにもそれぞれ役割(ロール)を設定して開発する。
チーム主体の開発手法のため、コミュニケーションが重視となる。 メンバーのスキルをそれぞれが把握することにより、臨機応変かつ効率的な開発を実現可能。
エクストリームプログラミング(XP)
要件や仕様の変更に対して柔軟に対応するための手法。
エンジニアがペアを組み、コーディングをお互いにサポートしながら作業を行うペアプログラミングが基本となる。 エラーや仕様変更に対応しやすい点が強み。 エンジニアのスキルに依存しやすい手法であるため、未熟なエンジニアの場合、開発の効率が大きく低下してしまう場合がある。
ユーザ機能駆動開発(FDD)
ユーザーの目線から価値のある機能を選定し、その機能を中心に開発する手法。
発注側(システムのクライアント)にヒアリングを行い、必要な機能を適切な計画で開発する。 また、機能ごとにチームを編成して開発を行う。
価値が高い機能を実装しやすい手法だが、計画段階から発注側との入念なコミュニケーションが必要となる。
ドメイン駆動開発(DDD)
ドメインモデルをもとにコミュニケーションを取りコードを書いて開発していく手法。
以下の原則を守るように進める。
- 顧客の課題を正しく理解する
- 業務の専門家とソフトウェアの専門家が協力しドメインモデルをつくる
- エンジニアである方もそうでない者も理解できる共通言語を使ってコミュニケーションを進める
ドメインモデル : アプリケーションが対象とする業務領域
1.4.3. アジャイルの開発哲学
リーンソフトウェア開発(LSD)
無駄を省いて品質の高い開発を行うことを重視する。
名前はリーン生産方式に由来。 以下の7つの原則に当てはまるもの。

適応的ソフトウェア開発(ASD)
継続的な仕様変化に適応することを重視する。 複雑なシステムや状況変化の激しい場合に適した開発哲学。
2 - 2.Git/Github基礎
2.1 - 1.Gitの基礎知識
Gitは分散型のバージョン管理システムの1つ。
ファイルのバージョン管理が簡単にできるツールといえる。
また以下のような特徴がGitにはある。
- 古いバージョンに簡単に戻せる
- 新旧のファイルを一元管理できる
- 編集した履歴を複数人で共有できる
- 複数人で修正した部分を一つに統合できる
1.1. リポジトリ(Repository)
リポジトリとは、ファイルやディレクトリを入れて保存しておく貯蔵庫のこと。 Gitにおけるリポジトリは以下の2種類に分かれている。
- リモートリポジトリ(共有リポジトリ) ・・・ 特定のサーバー上に設置して複数人で共有するためのリポジトリ
- ローカルリポジトリ(個人リポジトリ) ・・・ ユーザーごとに配置される手元のマシンで編集できるリポジトリ
2種類のリポジトリに分けることで、普段の作業はそれぞれのユーザーが手元のローカルリポジトリで行い、作業内容を共有するときにリモートリポジトリで公開するという使い方になる。 リモートリポジトリを介して他のユーザーの作業内容を把握することも可能。
1.2. コミット(Commit)
コミットは、ファイルやディレクトリの編集作業をローカルリポジトリに記録するために必要な操作のこと。 コミットを実行するとファイルを編集した日時を記録したファイルが生成される。 コミットを実行するごとにファイルが生成され、時系列順にならんで格納されるので、ファイルを編集した履歴やその内容を確認することができる。
1.3. プッシュ(Push)
プッシュとは、ローカルリポジトリにあるファイルをリモートリポジトリに送信して保存する機能。 共有リポジトリへの反映が行われるため、アップロードともいえる。
クローンと異なるのはローカルリポジトリとの差分のみをダウンロードして更新する点
1.4. プル(Pull)
プルとは、共有されているリモートリポジトリに保存されているファイルの内、ローカルリポジトリ(あなたのローカル環境)に無いファイルや他のユーザーが更新したファイルのみをダウンロードする機能。 ようするにリモートリポジトリの内容を同期させるとも言える。
1.5. クローン(Clone)
クローンとは、ダウンロードに近いものもの。 複数人で共有しているファイル(リモートリポジトリ)をまるごと自分のローカル環境(ローカルリポジトリ)に保存する機能。 まったく新規で開発の共有を始める場合に最初に行う作業といえる。
1.6. ブランチ(Branch)
ブランチとは、ファイルの編集履歴を分岐させて記録していく機能のこと。 WEBサービスやソフトウェアの開発において、バグの修正や、機能の追加などのファイル編集作業は複数のユーザーが同時に行うことも少なくない。 並行して同時に行われる作業を正確に管理するためにGitにはブランチという機能が用意されています。これがGitのバージョン管理を効率的にし、間違いを減らすためにもっとも活かされている機能ともいえる。
例としてマスターブランチであるメインのブランチと、そこから分岐してバグの修正や、機能の追加を行っているブランチを記すと以下のようになる。
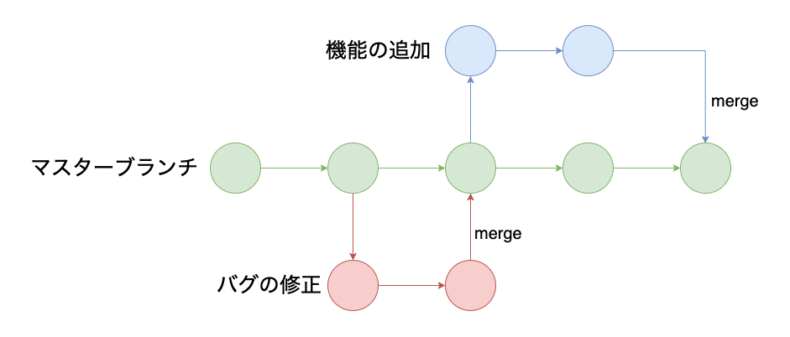
1.7. マージ(Merge)
複数のブランチを一つにまとめて、完成形に近づけることをマージと呼ぶ。 ブランチの図で言うとバグの修正や、機能の追加を行ったブランチがマスターブランチに統合されている部分のこと。
1.8. フェッチ(Fetch)
リモートリポジトリからファイルの最新情報を取得してくる操作のこと。共有されているファイル(リモートリポジトリ)の更新を確認したり、複数人の作業の擦り合わせのために使う機能といえる。
- プルと異なる点はローカルのファイルを更新することはないこと。
- 複数人で同じファイルを編集しているときでもお互い干渉しないようにするための機能と言える。
2.2 - 2. Git&GitHubの使い方
2.1. ローカルリポジトリにおける作業フロー(Git)
2.1.1. GitへのGitHubアカウントへの設定
Git BashまたはターミナルへのGitHubのアカウントの登録は以下のコマンドで行う。
git config --global user.name GitHub登録ユーザ名
git config --global user.email Github登録メールアドレス
GitHub登録ユーザ名とGithub登録メールアドレスは各自用意したものを代入してください。 またGitBashやターミナルへGitHubへのユーザ情報を登録できたかどうかの確認は以下のコマンドで行う。
git config --list
2.1.2. ローカルリポジトリの作成
Git管理したいフォルダに「cdコマンド」で移動する。 その後、リポジトリの新規作成は以下コマンドで行う。 これを行うことでローカルリポジトリが作成できる。 .gitファイルが作成される。
git init
2.1.3. ローカルリポジトリでのGitフロー
ステージングエリアへのファイル追加は以下のコマンドで行う。
git addコマンドでは内容を変更したファイルをステージングエリアに追加します
git add ファイル名
git add .
git commit -m "コメント"コマンドでローカルリポジトリへコミットを行います。
git commit -m "コメント1行目(概要)" -m "" -m "コメント3行目(詳細/理由)"
または
git commit -F- << EOM
>
>
>EOM
一般的な概要のコメント(英語)
- add: 機能やファイルの追加
- update: 機能の修正(リファクタリングを含む)
- fix: バグの修正
- remove: ファイルの削除
- refactor: バグ修正/機能追加ではないコードの変更
- feat: 新機能
- style: 見た目だけの変更(スペースやセミコロンなど)
- test: テストの追加か既存テストの修正
詳細に管理したい場合のコメント(英語)
- change: 仕様変更
- clean:リファクタリングなど
- upgrade: バージョンアップ
- revert: 変更取り消し
2.1.4. ブランチの切り方と切り替え方
ブランチの作成は以下のコマンドで行います。(ブランチ名なしで現在のブランチを確認可能)
git branch ブランチ名
ブランチの移動は以下コマンドで行います。
git checkout ブランチ名
git switch ブランチ名
git checkoutに-bを付けるとブランチ作成と切り替えをまとめて実行可能。
2.1.5. リポジトリの状態の確認
git status
2.1.6. コミットした履歴の確認
git log
| オプション | 詳細 |
|---|---|
| –oneline | 1行での表示 |
| -p ファイル名 | ファイル差分の表示 |
| -n 数字 | 表示数の制限表示 |
2.1.7. ファイルの削除とステージングエリアへの追加
ファイル削除後に以下のコマンドを実行
git rm ファイル名
オプション-rをつけると完全削除
2.1.8. ファイルの変更差分の確認
git diff
2.1.9. ファイルの状態を直前のバージョンに戻す
git addをする前の状態で戻す場合
git checkout .
git checkout ファイル名
git addをした後の状態で戻す場合
git reset --hard HEAD
git commitをした後に戻す場合(直前にcommitしたものも取り消す)
git reset --hard HEAD~
特定のファイルのみのバージョンを戻す場合
git checkout コミットID ファイル名
2.1.10. ファイルを古いバージョンに戻す
git logでCommit履歴を確認しコミットIDを取得git checkout <ID>を行うことでIDのCommitバージョンに戻せる
なお、特定のファイルのみバージョン戻す場合は2.1.9項目を参照。
戻したバージョン(以前のバージョン)の編集を行い、そこから最新バージョンにする場合のcommitは以下の通り。
git commit -a -m "<summary>" -m " " -m "<discription>"
2.1.11. Git管理下のフォルダ名を変更する
git mv フォルダ名/ 変更後のフォルダ名/
2.1.12. 既にGit管理化となっているファイルやディレクトリをgit管理化から外す
git rm --cached ファイル名
git rm -r --cached ディレクトリ名
2.1.13 Commitしたメッセージを変更する
変更したいコミットの履歴を確認、git commit --amendで最新のコミットが修正モードにする。
git log
git commit --amend
2.2. リモートリポジトリを含めた作業フロー(GitHub)
2.2.1. リモートリポジトリの作成
GitHubにブラウザからアクセスしてリモートリポジトリを用意する。
2.2.2. リモートリポジトリへのプッシュ
初期設定は以下のコマンドを実行する。
git remote add origin "GitHubURL"
以下コマンドを実行する。(ローカルリポジトリのブランチ名はこの場合はmaster)
git push -u origin master
2.2.3. リモートリポジトリからプル(ローカルへの反映)
git pull
または
git fetch origin
git merge <マージするブランチ名>
2.2.4. リモートリポジトリの確認と変更(上書き)方法
リモートリポジトリの確認は以下コマンドまたは.git/configで確認可能。
git remote -v
リモートリポジトリの変更は以下コマンドより
git remote set-url リモートレポジトリ名(masterなど) 新しいリモートリポジトリのURL
2.2.5. リモートリポジトリの削除
rmで完全削除
git remote rm リモートレポジトリ名
2.2.6. リモートリポジトリからのクローン
git clone リモートリポジトリのURL
2.3. その他のGitコマンド
| コマンド | 詳細 | オプション |
|---|---|---|
| git ls-files | Gitで管理しているファイル一覧の表示 |
2.3 - 3. gitにおける各種ファイルと補足情報
3.1. .gitignoreに関して
.gitignoreではgitで管理したくないファイルを指定できる。 例えば以下のようなもの。
- 自動生成されるファイル
- パスワード・IDなどが記載されるファイル(.env)など
#拡張子ファイルを無視
.拡張子
#指定したファイルの除外
ファイル名
#ディレクトリ以下で除外(特定ファイルの無視)
フォルダ名/
3 - 9.Web技術各種用語集
3.1 - 1.OS/システム用語
1.1. OS/Systemの用語
1.1.1. OSの処理能力(32bit/64bit)
OSのエディションには32bit/64bitがあり、それぞれ処理速度、扱えるメモリ量が異なる。
| 扱えるメモリ容量 | 扱えるHDD容量 | |
|---|---|---|
| 32bit版 | 2~4GB | 2TBまで |
| 64bit版 | 8GB~2TB | 2TB以上 |
1.1.2. CPUのアーキテクチャ(x86, x64, arm)
x86(32bit)
x86はインテル(Intel)およびAMDなどのCPUアーキテクチャに関連する用語。 x86アーキテクチャは32bitプロセッサを指す。
32bitプロセッサは、32bitのデータ幅を持ち、通常、32bitの命令を処理する。
x64(64bit)
x64は64bitプロセッサアーキテクチャを指す。 x86の拡張バージョンであり、インテルおよびAMDの64bitプロセッサに関連する。
64bitプロセッサは、64bitのデータ幅とアドレッシングをサポートし、大容量のメモリと高性能処理を可能にする。
arm
ARM(Advanced RISC Machines)は、ARMホールディングスが開発した低電力のRISC(Reduced Instruction Set Computer)アーキテクチャ。 arm64で64bit、arm32で32bitの動作となる。
1.2. 言語特性/仕様の用語
1.2.1. GC(ガベージコレクション)
コンピュータプログラムの実行環境などが備える機能の1つであり、実行中のプログラムが占有していたメモリ領域のうち不要になったものを自動的に解放し、空き領域として再利用できるようにするもののことを言う。
1.2.2. クロージャ
あるコードブロック内で定義された関数などが、そのブロックをスコープとする変数などを参照できること。
また、そのような機能を利用してブロック内部で定義された関数のこと。
1.2.3. カリー化
複数の引数をとる関数を、1引数関数の連続した呼び出しに置き換えること.
JavaScriptの例
function greet (name, age) {
console.log('My name is ' + name + '. I am ' + age + ' years old.');
}
greet('taro', 27); // 引数を2つ渡す
// ↓↓↓
function greet (name) {
return function (age) {
console.log('My name is ' + name + '. I am ' + age + ' years old.');
}
}
greet('taro')(27); // 引数の渡し方が変わる
1.2.4. 高階関数
関数を引数や戻り値とする関数。
1.2.6. デコレータ
デコレータは関数やクラスの前後に特定の処理を追加できる機能。
1.2.7. サブルーチン
コンピュータプログラムの中で特定の機能や処理をひとまとまりの集合として定義し、他の箇所から呼び出して実行できるようにしたもの。
1.3. 開発言語の用語
1.3.1. WebAssembly
WebAssemblyは仮想マシン上で動作するバイナリ形式の命令のこと。 WebAssemblyには2つのフォーマットがあり、「Binary Format(WASM)」と「Teaxt Format(WAT)」がある。
公式ドキュメント:https://webassembly.org/getting-started/developers-guide/
WebAssemblyはCやC++、Rust、Goなどの様々な言語から上記のWebAssemblyの命令形式へコンパイルして利用する。
WebAssemblyを用いることにより得られるメリットは以下の3つ。
- JavaScriptではできなかった負荷の大きな処理をブラウザで実行可能
- C/C++など既存のソースコードをブラウザで実行可能
- フロントとバックの処理を同じ言語で記述できる
WebAssemblyが適用できる場面(ユースケース)としては負荷の大きな処理をブラウザで実装したいときに役に立つ。
- 動画、画像編集
- 画像認識
- 低遅延のVR・AR
- CAD
- ゲーム開発
- 圧縮や暗号化など
Qiitaの解説記事:https://qiita.com/t_katsumura/items/ff379aaaba6931aad1c4
1.3.2. JVM言語
処理系がJVM(Java仮想マシン)上で動作する言語の総称。 OS環境に実行が依存しない特徴がある。
Scala, Kotlinなどがある。
1.3.3. SSML
音声マークアップ言語。
3.2 - 2.システム開発用語
2.1. 開発系全般の用語
2.1.1. バージョン管理ツール
ファイルやデータのバージョンを管理する仕組みやツール。
リビジョン管理システムとも呼ばれる。
集中型と分散型の2種類がある。
集中型バージョン管理ツール
集中型バージョン管理ツールで1つのリポジトリのみを使用する。
リポジトリへの反映にはリポジトリと端末がネットワークで繋がっている必要があり、繋がっていなければファイルの変更履歴をリポジトリに反映することができない。
代表的な集中型のバージョン管理ツールにはSVNやCVSがある。
分散型バージョン管理ツール
分散型バージョン管理ツールは各ローカル環境にリポジトリの複製を作成し、ローカルごとにバージョン管理を行える特徴がある。
ローカルごとにバージョン管理を行い、そのあとで中心のリポジトリとバージョン管理の情報を共有する。
代表的な分散型のバージョン管理ツールにはGitがある。
2.1.2. コーディング・実装原則
YAGNI原則
後で使うと設計した機能は後から使わないという原則。
DRY原則
重複管理を避けて1か所で管理するというルール。
KISSの原則
複雑にせず単純にするという原則。
2.1.3. CMS/HeadlessCMS
CMS
WordPressやEC-CUBE、Drupalなどの従来のCMS。
HeadlessCMS
ヘッドレスCMSはコンテンツ管理機能に特化したCMS。
ヘッドレスCMSと従来のCMSは、管理機能であるバックエンドのみか、表示機能であるフロントエンド・バックエンド機能を同時に持つかに違いがある。
ヘッドレスCMSでは管理機能のみになるため、別に表示画面の用意と専門知識が必要となっている。その分表示画面の自由度が高まり、APIの受け取り先が格段に増えることから、さまざまなデバイス・チャネルに対応が可能と言える。
具体的なサービスにはStrapi、microCMS、GraphCMSなどがある。
2.2. フロントエンドの用語
2.2.1. SPA/MPA
SPA
SPA(Single Page Application)は単一のWebページで構成するアプリケーション。
ページ遷移を行わずにページやコンテンツの切り替えが可能なのが特徴。
言い換えると、他のページへ移動せずにコンテンツの切り替えができる技術。
具体的にはユーザーがひとつのサービスを通じて得られる体験であるUXの向上に効果があり、ブラウザの挙動に縛られることがないUIの実現が可能となっている。
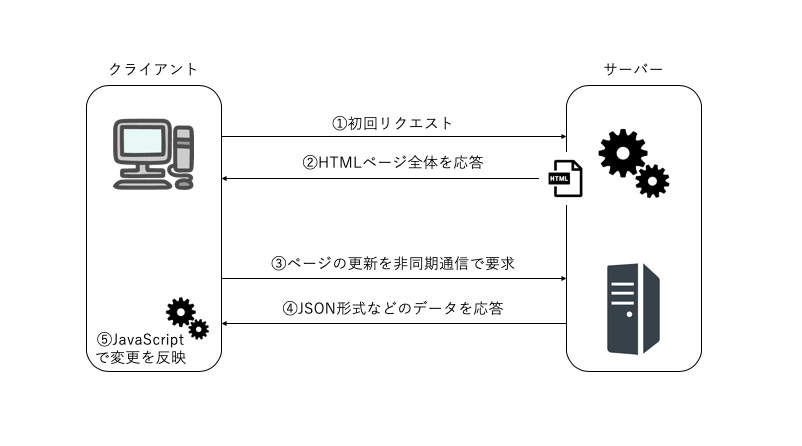
SPAの開発はJavaScriptにより実現される。
またOSSで提供されているSPAを構築可能なフレームワークは以下のようなものがある.
- React ・・・ Facebook主導のフレームワーク、UIデザインの知識がなくても最先端のフロントエンドが作れる、スマホアプリにも拡張可能
- Vue ・・・ シンプルなフレームワークで使いやすい、日本語のドキュメントが充実している、学習コストが低い
- Angular ・・・ Google主導のフレームワーク、動作端末を考慮する必要がなく汎用性が高い、機能が多いため大規模開発に向いている
MPA
MPA(Multiple Page Application)は複数のページで構成されるアプリケーションです。
HTTP GETが来たら、リクエストに応じたHTMLを1つ1つ組み上げてブラウザに返すオーソドックスで昔ながらの特徴となっている。
Railsやlaravelなどのサーバサイドフレームワークを公式ドキュメント通り作るとこの設計になる。
またWordPressなどのCMSもMPA構成となっている。
2.2.2. SSR/CSR/SSG
SSR
SSR(Server Side Rendering)はページ遷移のたびサーバーにリクエストが走り、そのままサーバー側でAPIと連携をしてレンダリングが行われ、生成されたHTMLをブラウザに返すアーキテクチャのこと。
サーバー側でレンダリングが行われる特徴がある。
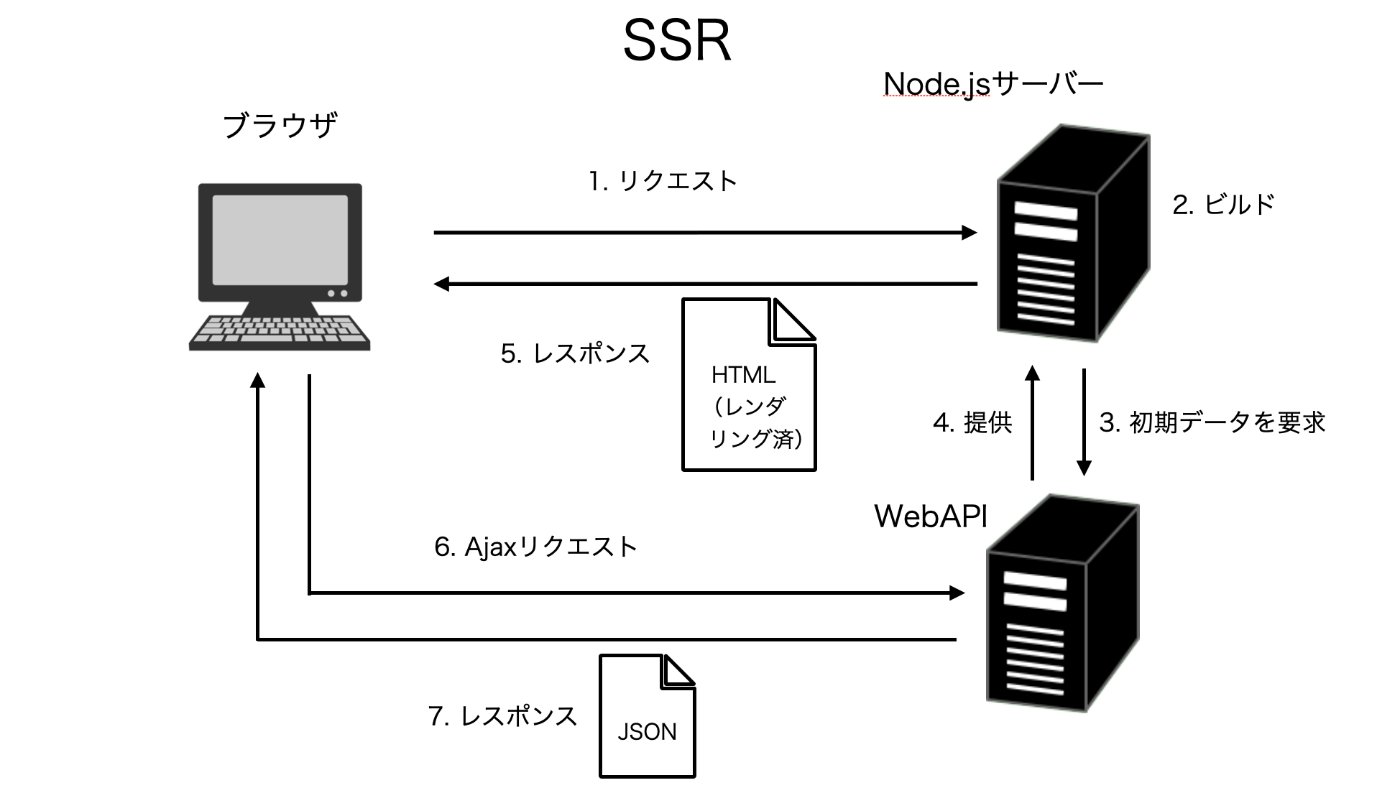
サーバーサイドレンダリング(SSR)は、その名の通りサーバー側でアプリケーションの HTML を生成しレスポンスとして返すことを言う。 一般的に利用されている MPA(Multiple Page Application)では言うまでもなく行われていることなので、SSR というワードは自ずと SPA(Single Page Application)を構築する際のオプション機能を指すことが多い。
SSRのメリットを整理すると、まず一番に挙がるのはレンダリングをサーバー側で行えるので、通常のSPAと比べて初回読み込みに時間がかからないということである。 厄介なレンダリング処理をサーバー側で行えるので、ブラウザの負担が減り、すなわちブラウザのスペックの高くない機器(スマホなど)でも安定した表示速度を保つことが可能となっている。
CSR
CSR(Client Side Rendering)は、クライアント側のJavaScriptを使用し直接ブラウザでページをレンダリングすることを言う。
大きいアプリケーションの場合クライアントで処理するJavascriptの量も増える(クライアントで処理する情報量が増加する)。
SEO的には弱い。
SSG
SSG(Static Site Generation)はビルド時に、サーバー側で、APIからのデータ取得とそれに伴ったHTMLの構築を終わらせておき、ユーザーからリクエストされた際にこの事前につくっておいたHTMLを渡すアーキテクチャ。
Next.jsやNuxt.jsなどを利用することで構築できる。
SEO対策が可能。
2.2.3. Cookie
Cookieは簡単に言うとサイト訪問者のユーザ情報をブラウザに一時保存(キャッシュ)する仕組み。
ファストパーティCookieとサードパーティCookieの2種類がある。
ファストパーティCookie
通常のログインに関する情報やショッピングカートの中身などの1つのサイト用のCookie。
サードパーティCookie
サードパーティクッキーは訪れたサイト以外のドメインから(第三者)から発行されたクッキーであり、ドメインを横断したトラッキングができるのでWEB広告で広く活用されている。
Googleにより、2024年に廃止が決定された。 個人情報保護の観点からクッキーへの規制を強める動きがあるため廃止される可能性が高い。
2.3. バックエンドの用語
2.3.1. モノリス/マイクロサービス
モノリスアーキテクチャ
モノリスアーキテクチャは1つのサービスや機能で構築される従来型のアーキテクチャである。
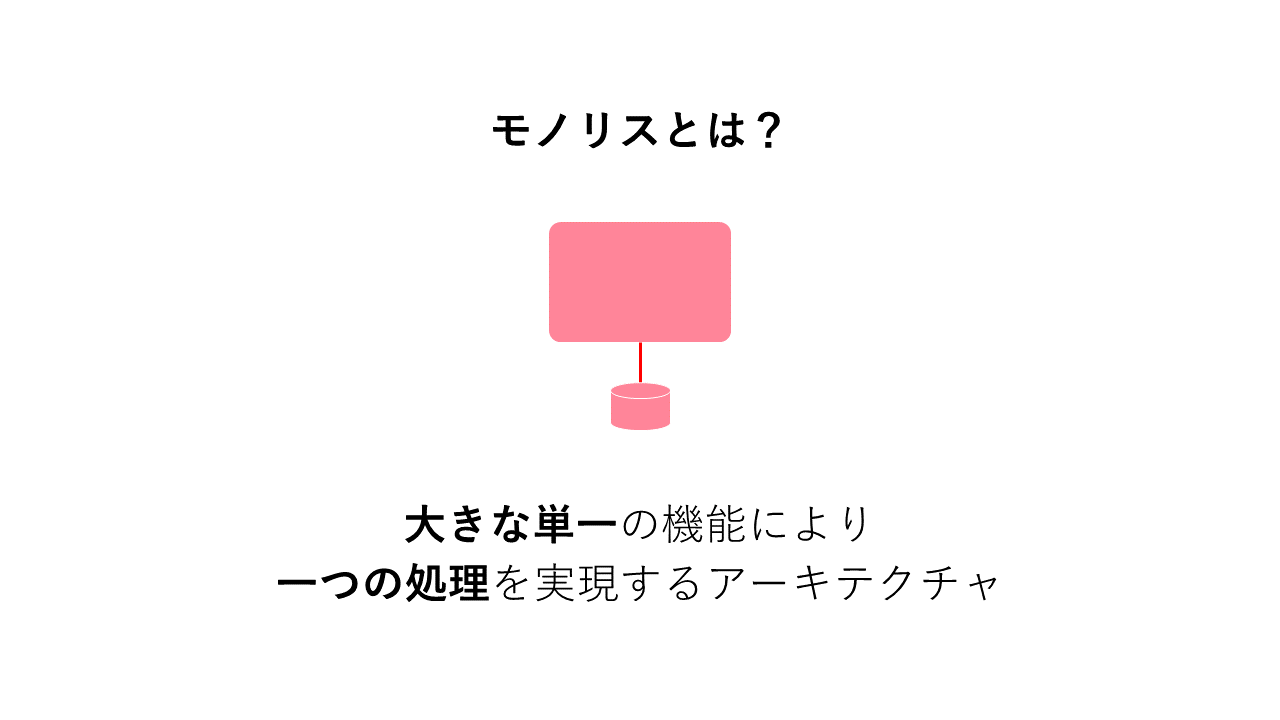
マイクロサービスアーキテクチャ
マイクロサービスアーキテクチャは複数のサービスや機能を疎結合させて構築されるアーキテクチャ。
メリットとしてはマイクロサービスのアーキテクチャでは、大規模で複雑なアプリケーションを提供する際のスピードと信頼性が向上することが上げられる。

マイクロサービスをWeb系システムで組むための関連技術としては、Go言語やKubernetesなどが注目されている。
2.3.2. サーバレスアーキテクチャ
サーバーレスアーキテクチャーは常時稼働する物理サーバーや仮想化基盤上の仮想マシンを極力使わずにアプリを構築するアーキテクチャーのこと。
具体的にはクラウドであるIaaSやPaaSの登場によりシステム開発側がサーバを意識する必要がなくなったことから登場した概念といえる。
AWSで言うと、ECSやEKS基盤、Amplifyなどで構成されるようなアプリケーションはサーバレスアーキテクチャと言える。
2.3.3. NoSQL
NoSQL(Not Only SQL)は非リレーショナルデータベース(RDB)なデータベースの総称のこと。 近年RDBでは対応できないケースが増えてきたことから、昨今ではNoSQLが注目されている。

特徴としてはNoSQLでは音声や画像など、Excelのセルに入らないデータも扱える。 速度を優先する構造であるためビッグデータなど大量データの処理に向くことも注目を集める大きな要因である。
NoSQLは4種類に分類される。
- キーバリュー型
- ワイドカラムストア型
- ドキュメント型
- グラフ型
NoSQLが適するケースは以下の通り。
- 非構造化データや半構造化データを扱うとき
- スピードが第一に要求されるシステム
- 拡張する可能性が高いシステム
2.3.4. ORM
ORM(Object-Relational Mapping)はオブジェクトと関係(RDB)とのマッピングを行うもの。 内部的にはORMがSQLをラッピングした構成となっている。
ORMを使うとSQLを直接書くことなく、オブジェクトのメソッドでDB操作ができると言う特徴がある。
フレームワークごとのORMは以下の通り。
| 言語 | ORM | 説明 |
|---|---|---|
| Ruby | ActiveRecord | RailsのORM |
| Python | Django ORM | DjangoのORM |
| Node.js | Prisma, TypeORM |
2.3.5. RPC
RPC(遠隔手続き呼出し)はコンピュータで動作するソフトウェアから、通信回線やコンピュータネットワークを通じて別のコンピュータ上で動作するための規格であり、互いに互換性がない場合があることからプロトコルというほどの堅い規約というよりも分類である。
有名どころ: XML-RPC, JSON-RPC, tRPC, gRPC
tRPC
簡単に言うと、server側で定義したInterfaceをそのままclient側で取り込んで繋ぎ込みができるもの。
Node.js(Type Script)向きのRPC実装。
公式ドキュメント:https://trpc.io/
関連するパッケージyarn add @trpc/server zod
gRPC
Googleが開発したRPC実装。 マイクロサービスアーキテクチャと相性が良い。
公式ドキュメント:https://grpc.io/
2.3.6. Open API
言語に依存しない標準の RESTful API へのインターフェイス仕様。 関連するものにswaggerがある。
API設計が巨大化したときに使える。
swagger: Open API Specific を記述するための、OSSのツール https://swagger.io/docs/specification/about/
3.3 - 3.インフラ/セキュリティの用語
3.1. インフラストラクチャの用語
3.1.1. CI/CD
CI(継続的インテグレーション)
テストや静的コード解析などの作業を自動化し、継続的に実行する手法。
CD(継続的デリバリー)
各環境へのデプロイ作業を自動化し継続的に実行する手法。
CI/CD
CIとCDを合わせたもの。 以下のことを実行できる。
- ビルドの自動化 ソースコードから実行可能なアプリケーションを構築する。 具体的には、Dockerイメージのpull、依存パッケージのインストール、コンパイルなど。
- テストの自動化 UTなどのテストコードを実行して動作確認をしたり、Rubocop(Ruby)などのコードスタイルチェックなどを行う。
- デプロイの自動化 ビルドしてテストが通ったものを本番環境や検証環境などに自動デプロイする。
代表的なCI/CDツールにはCircleCI、GitHub Actions、PipeCDなどがある。
3.1.2. CDN
CDN(コンテンツデリバリネットワーク)はユーザーになるべく近い場所でコンテンツを配信することにより、高速かつ信頼性の高いサービス提供するというもの。
CDNは分散されたキャッシュサーバー群によるネットワークとも言うことができる。 具体的にはWebアプリケーションで表示する画像や文章を世界中のサーバにキャッシュすることで実現する。
また以下の問題を解決できる。
- 世界中からアクセスのあるWEBアプリケーションやWEBサイトのレスポンスの改善
- Webサーバがダウンした際でもWebアプリケーションの機能の一部が提供できる
- ユーザが直接サーバにアクセスしないのでDDos攻撃やWebサイト改竄の被害をほとんど押さえることができる
代表的なCDNを提供するサービスにはCloudFlareやAWSのCloudFront、Akanamiなどがある。
3.2. セキュリティの用語
3.2.1. SSO
シングルサインオン(Single Sign-On)は「シングル 」と「サインオン」を組み合わせたもの。
「1度システム利用開始のユーザー認証 (ログイン) を行うと複数のシステムを利用開始する際に、都度認証を行う必要がない仕組み」や「1度の認証で、以後その認証に紐づけられている複数のシステムやアプリ・サービスにも、追加の認証なしで利用できる製品・システム・ツール」を指す。
3.2.2. ハニーポット
ハニーポットは、不正な攻撃者の行動・手法などを観察/分析する受動的な目的で設置される罠システム。
ハニーポットには以下のような種類がある。
- 高対話型ハニーポット … 実際のOSやアプリケーションを利用し、そこに残存している脆弱性などをそのまま不正攻撃者に対して弱点として見せる形式のハニーポット
- 低対話型ハニーポット … 特定のOSやアプリケーションをエミュレーションして監視する形式のハニーポット
3.2.3. ピボッティング
ピボッティングは侵入したマシンをルータとして利用して他のネットワークにアクセスする技法のことをいう。
ピボッティングでは攻撃者側から直接アク セスできないネットワークに対し侵入したマシンを足掛かりにアクセスすることを可能にする。
3.2.4. SIEM
SIEM(Security Information and Event Management:セキュリティ情報イベント管理)はシステムを構成する機器から自動的にログを収集・分析したり、異常時に通知したりできるソリューション。
具体的にファイアウォールやIDS/IPS、プロキシーなどから出力されるログやデータを一元的に集約し、それらのデータを組み合わせて相関分析を行うことで、ネットワークの監視やサイバー攻撃やマルウェア感染などのインシデントを検知することを目的とした仕組み。
3.2.5. C&Cサーバ(C2サーバ)
C&Cサーバは外部から侵入して乗っ取ったコンピュータを利用したサイバー攻撃を行う際に踏み台のコンピュータを制御したり命令を出したりする役割を担うサーバのこと。
主に防弾ホスティング上で展開される。
3.2.6. UTM
UTM(Unified Threat Management)は統合脅威管理とも呼ばれる1つのハードウェアに複数の異なるセキュリティ機能を統合し、ハッキングやコンピュータウイルスなどの脅威から、ネットワークを包括的かつ効率的に保護する手法のこと。
UTM機器は、ファイアウォール、IDS/IPS、アンチスパム、Webフィルタリング、アンチウイルス、アプリケーション制御などでネットワーク全体を保護する。 UTMはファイヤーウォールと異なり、ファイアウォールや複数の脅威検知機能を組み合わせ、ネットワークを包括的に防御する。
3.2.7. HSTS
RFC 6797で定義されるWebサイトがWebブラウザーにHTTPSでのアクセスを指示することで中間者攻撃を防止するための技術のこと。
3.2.8. SOC
SOC(Security Operation Center)はシステム・ネットワークの状態を監視し、サイバー攻撃の検知や分析・対策を行うことで企業の情報資産を守るための組織のこと。 セキュリティ専門の部署またはサービスとして、24時間365日体制で以下のような対応を行う。
- サイバー攻撃の検知や分析
- システム・ネットワークの状態を監視
- ネットワーク機器やセキュリティ装置・サーバーの監視
- ログ情報の解析や分析
3.2.9. CSIRT
CSIRT(Computer Security Incident Response Team)はセキュリティインシデントが発生した場合に対応する組織のこと。
インシデントが発生した際に行う対応は以下の通り。
- システムの停止から復旧の対応
- SOCが解析した情報を基に再発させないための防止策導入
セキュリティインシデントが発生していない際に行う対応は以下の通り。
- インシデント防止のため脆弱性に関連する情報収集から対策の導入
- インシデント発生時に対応するための社員教育
- CSIRTメンバー内での情報共有
3.2.10. IoC
IoC(Indicator of Compromise)はセキュリティ侵害インジケータなどとも呼ばれる、攻撃発生やどのようなツールが使われたかなどを明らかにする手掛かりとなる情報のこと。
IoCで掲載される情報には以下のようなものがある。
- 攻撃者が使用するマルウェアのファイル名
- 攻撃によって変更されるレジストリ
- 使用されるプロセスの名称
- 通信先のURIやIPアドレス
3.2.11. SCAP
SCAPは脆弱性管理・測定・評価を自動化するための基準のこと。 代表的なものにはCVSSやCVEなどがある。
3.4 - 4.ネットワーク/無線の用語
4.1. ネットワークの用語
4.1.1. IPマスカレード
NAPT(PAT)と同じ意味。
詳しくはコチラ
4.1.2. ポートフォワーディング
ポートフォワーディングはインターネットから特定のポート番号宛に通信が届いたときにあらかじめ設定しておいたLAN側の機器にパケットを転送する機能のこと。静的IPマスカレードとも呼ばれる。
この設定は外部からの通信を内部で処理するのに必須の設定と言える。
4.1.3. ダイナミックDNS(DDNS)
DDNSはIPアドレスが変更されたときに DNSレコードを自動的に更新できるサービスのこと。
4.1.4. VPNパススル
VPNを実現するための機能。
PPTPパススル
PPTPパススルはPPTP(Point-to-Point トンネリング プロトコル)によるVPN接続を許可する機能。
IPsecパススル
IPsecパススルーはNAT機器配下にあるIPsec端末が、NAT機器の先にあるIPsec端末とIPsec通信ができるようにするための機能。
4.1.5. PPPoEパススル
PPPoEパススルはLAN・WANインターフェース間でPPPoEパケットを転送することにより、LAN側インターフェース配下の端末が直接PPPoE接続できるようにするための機能。
4.1.6. 透過型プロキシ
透過型プロキシはクライアントにプロキシの設定をしていない状態でもプロキシサーバ経由によるWebアクセスをさせる方法。
Squidなどで実現可能
特徴
- ブラウザにプロキシの設定を入れる必要がない
- そのままではhttpsで警告が出てしまう
- 回避策:プロキシサーバでの動的な証明書作成およびクライアントでのプロキシサーバルート証明書インストール
- PBR(Policy Base Routing)などのNW設計が必要
4.1.7. PBR(Policy Base Routing)
PBRはルーティングテーブルに従ってパケットを転送するのではなく,管理者が設定した「送信元アドレス、プロトコル、ポート番号、パケットサイズ、入力I/F」の情報に基づきルーティングを行える技術のこと。