これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
データベース入門
- 1: 1.データベース基礎知識
- 2: 2.SQLの基本
- 3: 3.RDBデータベース設計基礎
1 - 1.データベース基礎知識
1.1. データベース概論
1.1.1. データベースとは
データベースはある特定の条件に当てはまる「データ」を複数集めて、後で使いやすい形に整理した情報のかたまりのことを表のようなものを指す。
特にコンピュータ上で管理するデータをデータベースと呼ぶことが多いが、紙の上で管理する「電話帳」や「住所録」なども、立派なデータベースである。
また、コンピュータ上でデータベースを管理するシステム(DBMS:Database Management System)のことや、そのシステム上で扱うデータ群のことを、単に「データベース」と呼ぶ場合もある。
データベースを使ってデータを管理するメリットには、次のようなものが挙げられる。
- 複数のデータをまとめて管理できる
- 目的のデータを簡単に探すことができる
- 簡単に編集して使うことができる
1.1.2. DBMS(Data Base Management System)
DBMSはDBを管理するためのシステム。
RDBMS
RDBMS(関係データベース管理システム)は様々な会社が提供しており、有料のものには以下のようなものがある。
- Oracle DB
- SQL Server
RDB
有名どころのRDB。
- MySQL
- PostgreSQL
- SQLite
1.1.3. RDB(Relational Data Base)
RDB(リレーショナルデータベース)は表の形でデータを管理するデータベース。 以下の要素で構成される。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
RDBの例
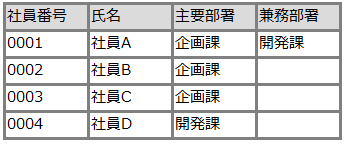
1.1.4. SQL(Structured Query Language)
SQLとはデータベースを操作するための言語。 DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令することができる。
基本的に1行ずつ入力して確定し、直ちに実行される。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできるが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもある。
ストアドプロシージャ
ストアドプロシージャはDBMSにSQL文を1つのプログラムにまとめ保存しておくことを指す。 一連の処理が実行される。
また、メリットは以下の通り。
- ネットワークの負荷削減
- 処理速度の向上
1.1.5. NoSQL
NoSQLはNot only SQLの略で、SQLに限定されることなく非定型な構造を持つデータを柔軟に管理することができるもの。 NoSQLはデータモデルによって、「キー・バリュー型」「カラムストア型」「グラフ型」「ドキュメント型」の4つに大きく分けられる。
NoSQLのメリット
- 非定型データの格納に対応可能な、柔軟かつ動的なデータモデルを利用できる
- データスキーマ/戦略の大幅な見直し、あるいはパフォーマンスの低下をともなわずに、データベースのスケーリングが可能
- ビッグデータ運用にも耐えうる大容量データ処理を実現できる
NoSQLの有名どころ
- redis
- MongoDB
1.1.6. ORM
ORM(Object-Relational Mapping)ことオブジェクト関係マッピングはオブジェクトと関係(RDB)とのマッピングを行うもの。
ORMを使うとSQLを直接書くことなく、オブジェクトのメソッドでDB操作ができると言う特徴がある。
1.2. データベース基礎
1.2.1. カラムとデータ型
テーブルをつくる時、どんなデータを入れるか構造を指定する。カラム型には以下のようなものがある。
ここではMySQLの場合の例を記載する。
数値型
UNSIGNED を指定すると正の数しか格納できなくなる。(UNSIGNEDでデータ範囲:0~2n)
| 名称 | 型 | 概要 |
|---|---|---|
| TINYINT | 整数型 | -128 ~ 127 |
| SMALLINT | 整数型 | -32768 〜 32767 |
| MEDIUMINT | 整数型 | -8388608 〜 8388607 |
| INT、INTEGER | 整数型 | -2147483648 〜 2147483647 |
| BIGINT | 真数型 | -9223372036854775808 〜 9223372036854775807 |
| BOOL、BOOLEAN | Boolean型 | TINYINT(1) で指定した場合と同じ。true と false の2択を保存したいときに使うことが多い。 |
| BIT | BIT型 | 111 や 10000000 といったビットフィールド値を格納するのに使う。ビット値を指定するには、b'111’ や b'10000000’ のように指定する。 |
| DECIMAL、DEC、NUMERIC | 小数点型 | 誤差のない正確な小数を格納できる。 |
| FLOAT | 小数点型 | おおよそ小数第7位まで正確な小数を格納できる。 |
| DOUBLE | 小数点型 | おおよそ小数第15位まで正確な小数を格納できる。 |
日付型・時間型
| 型 | 用途 | フォーマット |
|---|---|---|
| DATE | 日付 | ‘年-月-日’(例: ‘2020-01-01’) |
| DATETIME | 日付と時間 | ‘年-月-日 時:分:秒’(例: ‘2020-01-01 12:15:03’) |
| TIMESTAMP | タイムスタンプ | ‘年-月-日 時:分:秒’(例: ‘2020-01-01 12:15:03’)) |
| TIME | 時間 | ‘時:分:秒’(例: ‘12:15:03’) |
| YEAR | 年 | 年(例: 2020) |
値の指定方法
日付や時間を扱う型のカラムに値を挿入する場合、以下のような基本フォーマット以外の形も使える。
- ‘2020-01-01 12:15:05’ (基本)
- ‘20-1-1 12:15:5’
- ‘2020/01/01 12:15:05’
- ‘20200101121505’
文字列型
文字列を扱う型は以下の種類があり、それぞれ用途が違いがある。
| 型 | 用途 |
|---|---|
| CHAR | 固定長文字列を格納。CHAR(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARCHAR | 可変長文字列を格納。VARCHAR(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| BINARY | 固定長バイナリバイト文字列を格納。BINARY(10) のようにして格納できる文字数(0〜255・デフォルトは1)を指定できる。 |
| VARBINARY | 可変長バイナリバイト文字列を格納。VARBINARY(10) のようにして格納できるバイト数(0〜65,535)を指定できる。 |
| TINYBLOB | バイナリデータを格納。最大長は 255 (2^8 − 1) バイト。 |
| BLOB | バイナリデータを格納。最大長は 65,535 (216 − 1) バイト。BLOB(10) のようにして格納できるバイト数を指定できる。 |
| MEDIUMBLOB | バイナリデータを格納。最大長は 16,777,215 (2^24 − 1) バイト。 |
| LONGBLOB | バイナリデータを格納。最大長は 4,294,967,295 または 4G バイト (2^32 − 1) バイト。 |
| TEXT | 文字列を格納。最大長は 65,535 (216 − 1) 文字。TEXT(10) のようにして格納できる文字数を指定できる。 |
1.2.2. 正規化
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的。 同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれる。
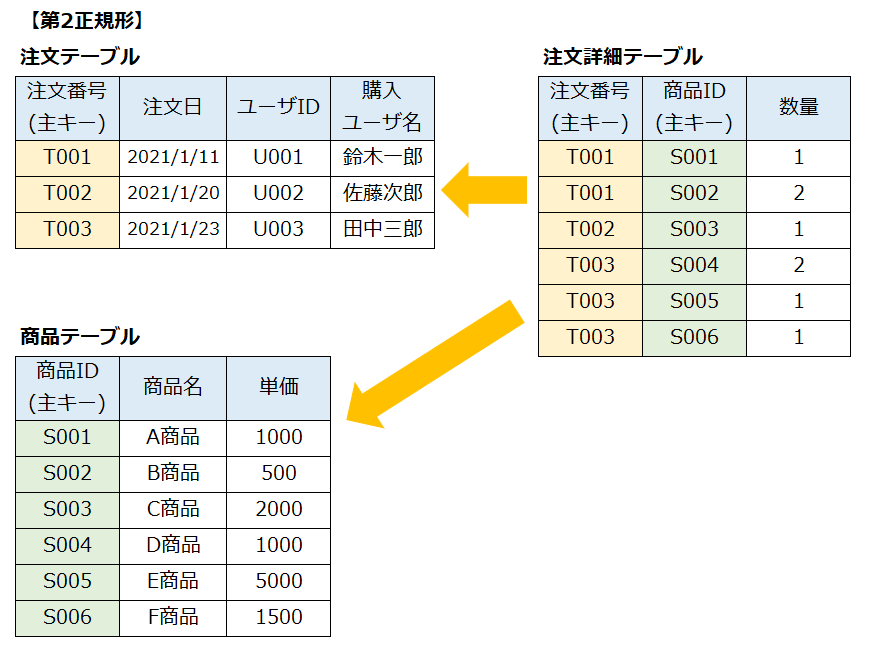
正規化の実行
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行う。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
非正規形
非正規型の表は繰り返し部分を持ち、関係データベースで扱えない表の形である。
第1正規形
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。 また表の形は2次元の表となる。
第2正規形
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第3正規形
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
1.2.3. 関係演算
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。 選択、射影、結合などがある。
- 選択 ・・・ 行を取り出す演算
- 射影 ・・・ 列を取り出す演算
- 結合 ・・・ 表同士を結合する演算
このような演算を行い仮想的に作る一時的な表はビュー表と呼ばれる。
1.2.4. スキーマ
スキーマは「概念、要旨」という意味を持ち、データベース構造や使用の定義をするものである。 標準使用されているスキーマにはANSI/X3/SPARC規格は3層スキーマ構造をとり、外部スキーマ、概念スキーマ、内部スキーマという3層に定義を分けることでデータの独立性を高める。

1.2.5. 主キーと外部キー
データベースの表には行を識別できるようにキーとなる情報が含まれており、それは主キーと呼ばれる。また表同士を関連付けするときの主キーは外部キーと呼ばれる。
また複数列を組み合わせて主キーにしたものは複合キーと呼ばれる。
関数従属と部分関数従属
- 関数従属 ・・・ 主キーが決まったとき列が一意に定まる関係
- 部分関数従属 ・・・ 複合キーの一部の項目のみで列の値が一意に定まる関係
1.2.6. トランザクション管理と排他制御
トランザクション管理と排他処理は複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理。
トランザクション
データベースにおいてトランザクションは一連の複数の処理をひとまとめにしたもののことを指す。 具体的にはデータの整合性を保つための概念と言える。
トランザクションが必要なケースは以下のようなものがある。
- 手動でSQLを操作する場合
- 複数データの整合性を保つ場合
排他制御
排他制御は処理中のデータをロックし他の人が読み書きできないようにする機能である。 ロックする方法には共有ロックと専有ロックがある。
- 共有ロック ・・・ 各ユーザはデータを読むことはできるが、書き込みができない状態
- 専有ロック ・・・ 他ユーザはデータを読み書きすることができない
また、デットロックと呼ばれる現象がロック機能を使いすぎると起こる場合がある。
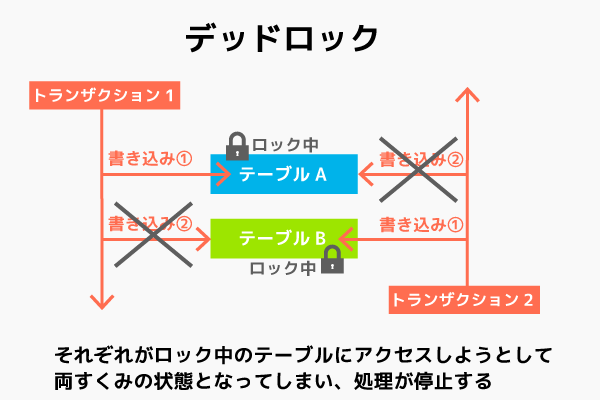
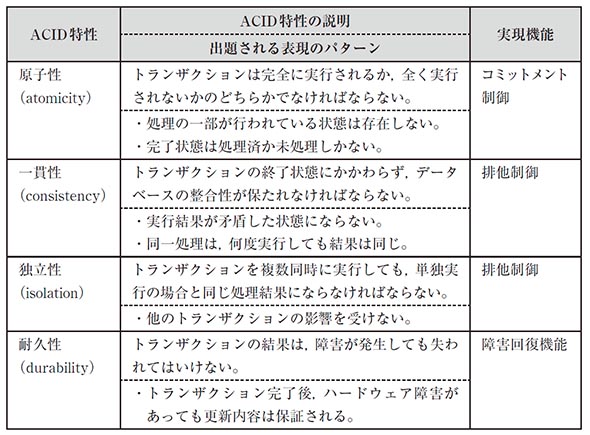
ACID特性
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
1.2.7. データベースの障害対策
データベースは定期的にバックアップを作ったり、更新前後の状態をジャーナルファイルに記録したりし障害の発生に備える。 バックアップ後の更新はジャーナルと呼ばれるログファイルに更新前の状態と更新後の状態を逐一記録しデータベースの更新履歴を管理するようにする。
障害が発生した際にはこれらのファイルを用いてロールバックやロールフォワードなどの障害回復処理を行い、元の状態に復旧する。
コミットとロールバック
データベースでは更新処理をトランザクション単位で管理しる。 トランザクションは一連の処理が問題なく完了できたときに、最後にその更新を確定することでデータベースへ更新内容を反映させる。これはコミットと呼ばれる。 またトランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得しデータベースをトランザクション処理直前の状態に戻す。この処理はロールバックと呼ばれる。
分散データベースと2相コミット
分散データベースシステムは物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムのこと。
これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。 そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。
ロールフォワード
データベース自体が突然障害に見舞われた場合、バックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理がある。
この処理はロールフォワードと呼ばれる。
1.3. DBホスティングサービス
一部のみの記載。
1.3.1. DB
| 名称 | 種類 | ホスト元 |
|---|---|---|
| Amazon Aurora | RDBMS | AWS |
| Cloud SQL | RDBMS | GCP |
| Azure SQL Database | RDBMS | Azure |
| Amazon Aurora | NoSQL | AWS |
| Cloud Bigtable | NoSQL | GCP |
1.3.2. サーバレスDB
サーバレスDBではサーバ管理を考える必要がないため、開発者はプログラムの開発に集中できる。
| 名称 | 種類 | ホスト元 |
|---|---|---|
| AWS Lambda(NoSQL) | - | AWS |
| Amazon Aurora Serverless | - | AWS |
| PlanetScale | RDB |
2 - 2.SQLの基本
2.1. SQLとは
SQL(Structured Query Language)とはデータベースを操作するための言語。
DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令することができる。
基本的に1行ずつ入力して確定し、直ちに実行される。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできるが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもある。
2.1.1. ストアドプロシージャ
DBMSにSQL文を1つのプログラムにまとめ保存しておくことはストアドプロシージャと呼ばれる。
一連の処理が実行される。
また、メリットは以下の通り。
- ネットワークの負荷削減
- 処理速度の向上
2.1.2. SQLの種類
標準SQL規格では大きく以下の3つが定義されている。
- データ定義言語(DDL)…..例:CREATE,DROP,ALTER等
- データ操作言語(DML)…..例:INSERT,UPDATE,DELETE,SELECT
- データ制御言語(DCL)…..例:GRANT,REVOKE,SET TRANSACTION,BEGIN,COMMIT,ROLLBACK,SAVEPOINT,LOCK
2.1.3. SQLの4大命令
| 命令 | 説明 | 文法 |
|---|---|---|
| INSERT | データを追加する | INSERT INTO テーブル名 (カラム名1, カラム名2, …) VALUES (値1, 値2, …); |
| SELECT | データを参照する | SELECT カラム名1, カラム名2, … FROM テーブル名 [WHERE 絞込条件]; |
| UPDATE | データを更新する | UPDATE テーブル名 SET カラム名1=値1 [, カラム名2=値2 …] [WHERE 絞込条件]; |
| DELETE | データを削除する | DELETE FROM テーブル名 [WHERE 絞込条件]; |
2.2. SQL基本操作
操作例を用いて解説。
操作例のテーブル
membersテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | tarou | male | 1999-11-30 |
| 2 | hanako | female | 1993-01-14 |
2.2.1. INSERT文
INSERT はテーブルにレコードを追加するSQL文。
INSERT INTO members (name,sex,birth_day)
VALUES ('tarou', 'male', '1992-11-30');
INSERT INTO members (name,sex,birth_day)
VALUES ('hanako', 'femal','1993-01-14');
2.2.2. SELECT文
全件全列を参照する
SELECT * FROM members; -- 全件検索
特定の列だけを参照する
全ての列は要らない時はカラム名で絞込をしよう。
SELECT name FROM members; -- 全件検索(名前だけ見たい)
特定の条件に一致するデータだけを参照する
SELECT * FROM members WHERE name = 'tarou'; -- 名前が"tarou"のレコードを検索
2.2.3. UPDATE文
全件特定のカラムを更新
--membersのレコードのnameをすべて'jirou'に更新する
UPDATE members SET name = 'jirou';
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | jirou | male | 1999-11-30 |
| 2 | jirou | female | 1993-01-14 |
絞込条件に該当するデータの特定のカラムを更新
--membersのレコードでidが1のレコードのname,birth_dayを更新
UPDATE members SET name = 'saburo', birth_day = '2015-03-11' WHERE id = 1;
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 1 | aburo | male | 2015-03-11 |
| 2 | jirou | female | 1993-01-14 |
2.2.4. DELETE文
特定条件に該当するデータを削除
--idが1のレコードを削除する
DELETE FROM members WHERE id = 1;
実行後のテーブル
| id | name | sex | birthday |
|---|---|---|---|
| 2 | jirou | female | 1993-01-14 |
全件データを削除
--membersのレコード全てを削除する
DELETE FROM members;
実行後のテーブル
| id | name | sex | birthday |
|---|
2.2.5. 絞り込み WHERE
データの全体母数からWHERE句を使ってデータ集合を絞り込むために利用する。 WHERE句が使えるのはSQL4大命令のうち「SELECT」、「UPDATE」、「DELETE」。
SELECTのWHEREによる絞り込み
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" = "値";
利用できる比較演算子
| 記号 | 説明 |
|---|---|
| = | 等価演算子 |
| <=> | 安全等価演算子(NULL) |
| > | 右不等演算子 |
| >= | 以上演算子 |
| < | 左不等演算子 |
| <= | 以下演算子 |
| !=, <> | 不等価演算子 |
なおWHERE句内の比較演算はAND,ORで絞り込みが可能。
SELECT * from users WHERE age >= 20 AND age <= 30;
2.2.6. BETWEEN句
〇〇以上、〇〇未満の情報を取得するというケースは不等号を使っても表現することが出来るが、BETWEENを使うことでも表現することが可能。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" BETWEEN "最小値" AND "最大値";
BETWEEN句以降に最小値と最大値を指定する。 この時最小値と最大値の順番は重要となる。 BETWEEN句が使えるのは、整数型を代表する以上以下で表現が出来る型のみ。
2.2.7. LIKE句
部分一致で検索するときに用いる。 LIKE句で使う"%“は、ワイルドカードと読んでおり、"%ky%“としたときには、kyを含む文字列を取得することが出来る。 これを応用して、“ky%“と書いた時には、kyから始まる文字列の絞込が出来る。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" LIKE "%絞込をしたい文字列%";
2.2.8. INとNOT IN
INで指定するときには、カンマ区切りの配列で複数の条件を指定することができる。 文字列の場合にも(“foo”,“bar”,“baz”)という形で指定をすることができる。
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" in ("指定したい情報をカンマ区切りで指定");
SELECT ”取得したい情報” from "テーブル名" WHERE "絞込をしたいcolumn名" not in ("指定したい情報をカンマ区切りで指定");
2.2.9. EXISTS
2つのテーブルが関係する場合の検索処理に用いる。
SELECT ”取得したい情報” from "テーブル名" WHERE EXISTS (SELECT "column名" FROM "判定に使うテーブル名" WHERE "テーブル名.column名" = "判定に使うテーブル名.判定に使うcolumn名");
SQLの中にSQLが書かれている形のことをサブクエリーと呼ぶ。 サブクエリーが何なのか?という説明よりも、()の中で問い合わせた結果を使って再度検索が動いているのをイメージ出来るようになるとレベルアップ出来る。
2.10. ORDER BY文
ORDER BYはソートを行ってくれる機能。
SELECT [表示要素名] FROM [テーブル名] ORDER BY [ソートする要素名] [昇順・降順の指定];
昇順・降順の指定
| 指定 | 順 |
|---|---|
| ASC | 昇順 |
| DESC | 降順 |
並び順の指定を省略した場合はASCがデフォルト。 複数のソートキーも対応している。はじめに書くほど優先でカラムが実行される。
2.2.11 表示件数の制限
LIMITはデータの表示件数を制限できる。
select * from テーブル名 LIMIT 取得件数;
2.2.12. テーブル定義の確認
DESCRIBEはテーブルの定義情報を確認することができる。
DESCRIBE テーブル名;
2.2.13. SQLの集合関数
集合関数とは、SQLに備わっている演算機能。 集合関数には主に次の5つがある。
| 関数名 | 説明 |
|---|---|
| COUNT | 総数を求める |
| SUM | 総和を求める |
| MAX | 最大値を求める |
| MIN | 最小値を求める |
| AVG | 平均を求める |
COUNT
SELECT COUNTはデータの件数を数える。
select count(*) from テーブル名;
SUM
sumは総和です。
select sum(カラム名) from テーブル名;
MAX
maxは最大値です。
select max(age) from users where birthplace = '大分県';
MIN
MINは最小値です。
select count(*),max(age),min(age) from users where birthplace = '大分県' and gender_id = 0;
AVG
avgは平均値です。
SELECT count(*) AS 総数,
max(age) AS 最高齢,
min(age) AS 最年少,
avg(age) AS 平均年齢
FROM users
WHERE birthplace = '大分県';
2.2.14. グループ
GROUP BY
group byは「〜ごと」という処理を行う。
SELECT 関数名(カラム名1),カラム名2 FROM テーブル名 GROUP BY カラム名2;
HAVING
having は集合関数の結果をもとに絞り込むことができる。
SELECT 関数名(カラム名1),カラム名2 FROM テーブル名 GROUP BY カラム名2 HAVING 関数名(カラム名1);
2.3. テーブルの結合
テーブルの結合には幾つかのパターンがある。
- 内部結合 : 指定された共通列で、紐付いているレコード”のみ” で結合テーブルが作成される
- 外部結合 : 指定された共通列で、紐付いているレコード”以外” も結合テーブルとして作成される
2.3.1. 内部結合
内部結合とは、2つのテーブルを結合しデータを取得する方法において、共通列が一致するレコード"のみ” 取得する方法が内部結合になります。
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
INNER JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
内部結合では、FROM句で指定したテーブルAと、結合するテーブルBをINNER JOIN句で指定する。 そして、テーブル同士の紐付け条件としてON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う事でテーブルが結合される。
2.3.2. 外部結合
左外部結合
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
LEFT OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
左外部結合では、FROM句で指定したテーブルAと、結合するテーブルBをLEFT JOIN句で指定する。 テーブル同士の紐付け条件は、内部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
右外部結合
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
RIGHT OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
右外部結合では、左外部結合とは反対で、RIGHT JOIN句で指定したテーブルBを基に、FROM句で結合するテーブルAをで指定する。 テーブル同士の紐付け条件は、左外部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
完全外部結合
SELECT
テーブルA.カラム1,
テーブルB.カラム1,
......
FROM
テーブルA
FULL OUTER(省略可) JOIN テーブルB ON テーブルA.カラム2 = テーブルB.カラム2
完全外部結合は、サンプルのSQLを見て頂くと解る通り、左外部結合と右外部結合の機能を併せ持っている。 テーブル同士の紐付け条件は、左/右外部結合と同様にON句を利用し、共通列となるテーブルA.カラム2、テーブルB.カラム2を指定し紐付けを行う。
3 - 3.RDBデータベース設計基礎
3.1. データベースの設計方法
3.1.1. データベーステーブルの設計
テーブルは基本的に以下のフローで設計します。
- システム要件の確認
- テーブル概要設計
- テーブル詳細設計
システムの要件の確認
この工程ではシステムの要件と機能を明確化します。 どんなデータを保存するのか、どういうアプリのためのデータベースなのかetc…より検討。
テーブルの概要設計
システムの要件と機能から必要となるデータのテーブルを大雑把に書きだします。 機能一覧より処理のシナリオに沿ってデータを洗い出します。
テーブル詳細設計
このステップでは概要設計で洗い出したデータテーブルに以下の仕様を追加します。
- 日本語データ名(論理名)を英語(物理名)に変える
- カラムに型を定義する
- ER図を書きながら各テーブルを正規化する
- 制約条件やインデックスをつける
また注意としてカラム名やデータ名に予約語を用いてはいけないという暗黙の規則がある。
3.1.2. インデックス
検索キーになりうるカラムにつける番号です。 主キーや外部キーにはつけません。
3.1.3. 制約条件
- NOT NULL制約 ・・・ 列のデータがNULL値ではないことを保証する制約
- ユニークキー制約 ・・・ 列のデータが重複しないことを保証する制約
- 外部キー制約 ・・・ 他のテーブルの列を参照し、その列にないデータを禁止する制約
外部キー制約の説明

3.1.4. 命名規則
テーブルやカラムの名称の命名のルールとして基本的には以下の通りです。
- 読んで意味の分かる名称を英語でつける
- テーブル名・カラム名ともに大文字
- 単語のセパレータには
_を使う - 英語の長い連語(例: Purchase Orderなら
PO)は略称にする - テーブル名は複数形(s)
3.2. 作図
データベースの設計のためには非正規形の表の正規化を行う以外に、図の作成などを用いてデータベースの機能の設計や操作をまとめることができます。
3.2.1. DFD
DFDは「システムの機能」と「システムで扱うデータ」の流れを表現する図です。
DFDを作成する目的としては、
- 他のメンバーとシステムイメージを共有
- 既存システムの全体像を説明するのに活用
- 機能の漏れ、重複がないように分割
- プロセスの詳細化
プロセスの詳細化を行うと、一度に検討するプログラム量が最小限になり、コーディング時に部分ごと集中して取り組むことができます。
例
3.2.2. CRUD図
システム開発において属人化を未然に防いだり影響調査のコスト圧縮のためにCRUD図という図を作成したりします。 CRUD図はSQLの4大命令に即した形で「Create」、「Read」、「Update」、「Delete」の操作がどのテーブルに対して行われているかを画面(機能やユースケース)ごとに記載する資料です。
| 省略形(意味) | SQL | 説明 |
|---|---|---|
| C(Create) | INSERT | データの追加 |
| R(Read) | SELECT | データの参照 |
| U(Update) | UPDATE | データの更新 |
| D(Delete) | DELETE | データの削除 |
例

3.2.3. ER図
ER図はデータベースを設計する際に利用します。
ER図を作成することで、複数個所でマスタとなるデータをばらばらに持ってないか確認できたり、データの関連性を説明するのに活用することができます。 実体と関係という概念を用いてデータ構造を図にします。
| 要素 | 概要 |
|---|---|
| エンティティ | データのまとまり。実体のあるもの(人、物、場所、金)だけでなく、概念(やりとり、分類)も対象となります。 |
| アトリビュート(属性) | エンティティに関する情報です。 |
| リレーション(関係) | 「1対多」など数の関係を表します。 |
| カーディナリティ(多重度) | 「1対1」「1対多」「多対多」など |

ER図のデータモデルの形態
ER図の初期形態
概念モデル: ものと出来事をエンティティ・リレーションシップとして表した図
ER図の中期形態
論理モデル: 概念モデルに情報を肉付けしたもの。属性(アトリビュート)・アイデンティファイア(主キー)・外部キーとかの要素が入る
ER図の最終形態
物理モデル: 特定の物理DB向けに論理モデルを変換する。データ型の追加とか、アルファベットに変換したりとかする
表的なER図の要素と物理データベース項目の関係は以下になります。
| ER設計 | 物理データベース |
|---|---|
| エンティティ名 | テーブル名 |
| アトリビュート(物理名) | カラム名 |
| アイデンティファイア | 主キー制約 |
| リレーションシップ | 外部キー制約 |