7.データベース
7.1. データベースの基礎
7.1.1. DBMSと関係データベース
DBMSはデータベース管理システムのことであり、データベースの定義や操作制御などの機能を持つミドルウェアである。
データベースには関係型、階層型、ネットワーク型の3種類があり、関係型が現在の主流である。
階層型データベース
階層型データベースはデータを木のような形の階層構造で表す。
関係型データベース
関係型データベースはデータを行と列による二次元表で表し福栖の表を組み合わせてデータを管理するもの。**リレーショナルデータベース(RDB)**とも呼ばれる。
ネットワーク型データベース
ネットワーク型データベースはデータを網目のような構造で表す。
7.2. 関係データベース
7.2.1. 関係型データベース
関係データベースは表の形でデータを管理するデータベースであり、表で構成される。 また関係データベースはリレーショナルデータベース(RDB) と呼ばれる。
| 種類 | 説明 |
|---|---|
| 表(テーブル) | 複数のデータを収容する場所 |
| 行(レコード) | 1件分のデータを表す |
| 列(フィールド) | データを構成する項目を表す |
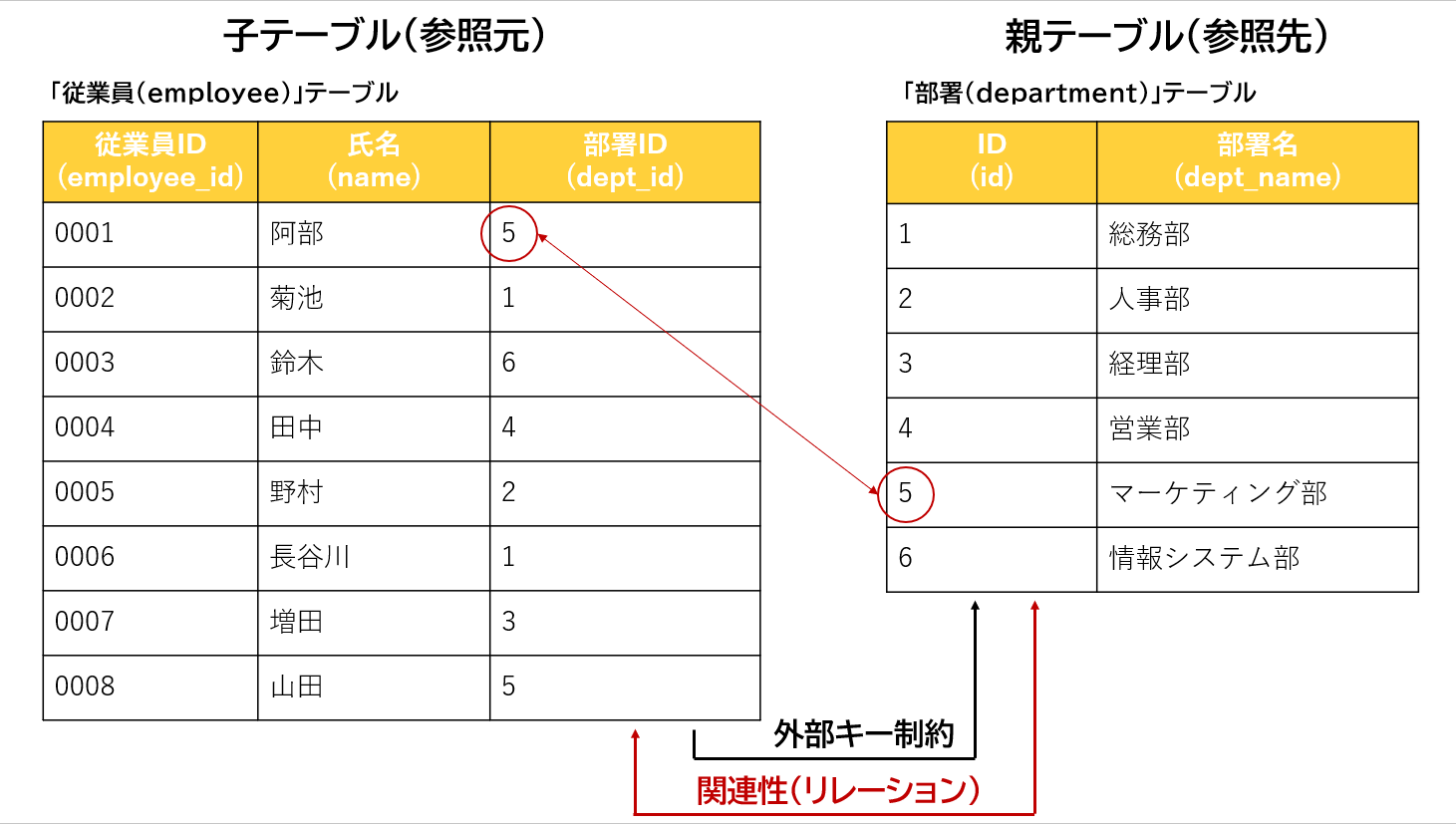
7.2.2. 主キーと外部キー
主キー
主キーは行を一意に識別するための列のこと。 また、値が空でなく他の行と重複しないことは主キー制約と呼ばれる。
外部キー
外部キーは表の列のうち他の表の主キーとして使われている列のこと。
7.3. 表の操作
7.3.1. 関係演算
関係演算は表の中から特定の行や列を取り出したり、表と表をくっつけ新しい表を作り出したりする演算のことである。
関係演算には選択、射影、結合などがある。
- 選択 ・・・ 行を取り出す演算
- 射影 ・・・ 列を取り出す演算
- 結合 ・・・ 表同士を結合する演算
7.3.2. ソートマージ結合法
ソートマージ結合法は結合する列の値で並べ替えたそれぞれの表の行を先頭から準備結合する方法のこと。
7.4. データの正規化
7.4.1. 正規化とは
関係データベースにおいて蓄積データの重複や矛盾が発生しないように最適化するのが一般的である。
同じ内容を表のあちらこちらに書かないように表を分割するなどすることは正規化と呼ばれる。
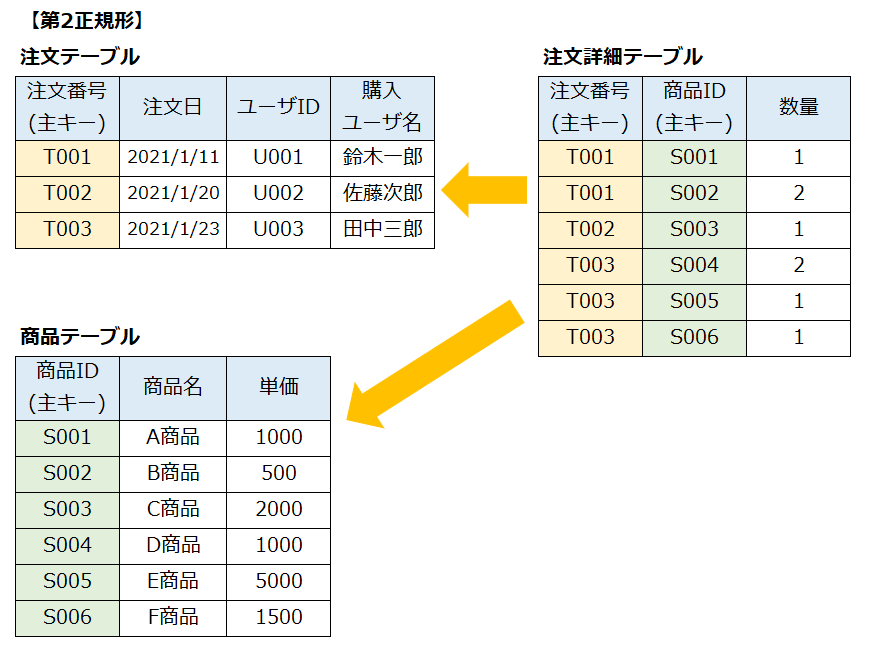
7.4.2. 第N正規化
非正規形(正規化を行っていない元の形の表)を何回か正規化を行い最適化行う。
| 正規化 | 説明 |
|---|---|
| 非正規形 | 正規化されていない繰り返し部分を持つ表 |
| 第1正規形 | 繰り返し部分を分離させ独立したレコードを持つ表 |
| 第2正規形 | 部分関数従属しているところを切り出した表 |
| 第3正規形 | 主キー以外の列に関数従属している列を切り出した表 |
第1正規形
非正規形の表から繰り返し部分を取り除いたものは第1正規形となる。
第2正規形
第1正規形の表から部分関数従属している列を分離した表が第2正規形の表である。
第3正規形
第2正規形の表から主キー以外の列に関数従属している列を分離した表が第3正規形の表である。
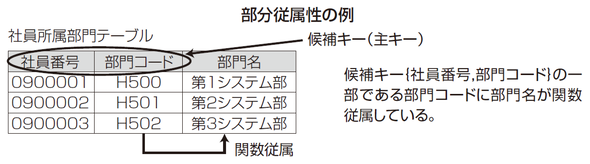
7.4.3. 関数従属と部分関数従属
- 関数従属 ・・・ 主キーが決まったとき列が一意に定まる関係
- 部分関数従属 ・・・ 複合キー日舞の項目のみで列の値が一意に定まる関係
7.5. SQL
7.5.1. SQLによるデータベース操作
SQL(Structured Query Language)はDBMSへ指示を伝えるために用いる言語である。 SQLには表の定義(CREATE)やレコードの挿入(INSERT)、削除(DELETE)、レコードの一部を更新(UPDATE)する命令がある。
これらの命令はスキーマ定義や表の作成を担当するデータ定義言語(DDL) とデータの抽出や挿入、更新、削除といった操作を担当するデータ操作言語(DML) に区別できる。
7.5.2. SELECT文
SELECT文の基本書式は以下の通り。
SELECT 列名 FROM 表名 WHERE 条件
特定の列の抽出(射影)
SELECT 列名 FROM 表名
特定の行の抽出(選択)
SELECT * FROM 表名 WHERE 条件式
なお条件式には比較演算子や論理演算子を用いる。
表同士の結合(結合)
SELECT * FROM 表名1, 表名2 WHERE 表名1.ID = 表名2.ID
7.5.3. ORDER文
ORDER文は抽出結果を整列させておきたい場合に用いる。
ORDER BY 列名 ASC(or DESC)
ASC:昇順、DESC:降順
例)商品表の価格順に商品表を並べる場合
SELECT * FROM 商品表 ORDER BY 単価
7.5.4. 関数を使った集計
SQLにはデータを取り出す際に集計を行う様々な関数が用意されている。
| 関数 | 説明 |
|---|---|
| MAX(列名) | 列の最大値を求める |
| MIN(列名) | 列の最小値を求める |
| AVG(列名) | 列の平均値を求める |
| SUM(列名) | 列の合計を求める |
| COUNT(*) | 行数を求める |
| COUNT(列名) | 列の値が入っている行の数を求める |
例)扱う商品の数を取り出す場合 SELECT COUNT(*) FROM 表
7.5.5. GROUP文
グループ化は特定の列が一致する項目をまとめて1つにすることを指す。
グループ化には以下文を用いる。
GROUP BY 列名
グループの条件絞り込み
グループ化なおかつそこから条件を絞り込む場合はHAVINGを用いる。
GROUP BY 列名 HAVING 絞り込み条件
7.6. データベース管理システム
7.6.1. データベース管理システム(DBMS)
7.6.2. トランザクション管理機能
トランザクションはデータベースにおいて一連の処理をひとまとめにしたもの。複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理の1つ。
7.6.3. 排他制御機能
排他制御は処理中のデータをロックし、他の人が読み書きできないようにする機能である。複数人がデータベースにアクセスし同時変更などをした際にデータ内容に不整合が生じる問題からデータベースを守る処理の1つ。
ロックする方法には共有ロックと専有ロックがある。
共有ロック
各ユーザはデータを読むことはできるが、書き込みができない状態。 データベースを参照する際にかけるロックのこと。
専有ロック
他ユーザはデータを読み書きすることができない。 データベースを更新する際にかけるロックのこと。
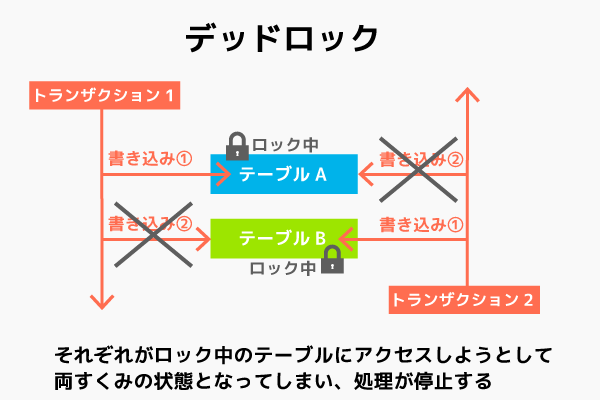
7.6.4. デットロック
デットロックはロック機能を使いすぎると起こる可能性があるもの。
7.6.5. ACID特性
DBMSではトランザクション処理に対して4つの特性(ACID特性)が必要とされる。
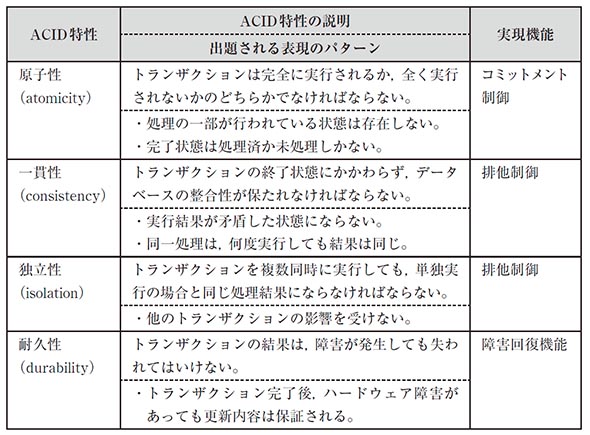
7.6.6. データベースのリカバリ機能
ロールフォワード
データベース自体が突然障害に見舞われた場合、ロールフォワードと呼ばれるバックアップ以降の更新ジャーナルから更新情報を取得し、データベースを障害発生直前の状態に復旧させる一連の処理を行う。
ロールバック
トランザクション処理中に障害が発生し更新に失敗した場合、データベース更新前の状態を更新前ジャーナルから取得し、ロールバックと呼ばれるデータベースをトランザクション処理直前の状態に戻す処理を行う。
7.6.7. 再編成機能
再編成機能はアクセス効率を向上させるための機能で、データベースが頻繁に更新されるとデータの物理的な格納位置が不規則になるといったものを修復するものである。
7.6.8. インデックス機能
DBMSはインデックスを用いてデータ検索を高速化する機能がある。
オプティマイザ
オプティマイザはSQLを実行するときに実行時間を最小化するように処理の方法を決める機能のこと。データ検索などのときにテーブル全体にアクセスするのとインデックスを使用して探すのどちらが効率が良いか予測して選択する。
7.7. データベースの応用技術
7.7.1. 分散データベースと2相コミット
物理的に分かれている複数のデータベースを見かけ上1つのデータベースとして扱えるようにしたシステムは分散データベースシステムと呼ばれる。
これはトランザクション処理が各サイトにわたり行われるので、全体の同期をとりコミット、ロールバックを取らないと、データの整合性が取れなくなる恐れがある。 そのため全サイトに問い合わせを行い、その結果を見てコミット、ロールバックを行う。この処理は2相コミットと呼ばれる。